Abstract
HTML Imports are a way to include and reuse HTML documents in other HTML documents.
Status of This Document
This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications and the latest revision of this technical report can be found in the W3C technical reports index at http://www.w3.org/TR/.
This document was published by the Web Platform Working Group as a Working Draft.
This document is intended to become a W3C Recommendation.
If you wish to make comments regarding this document, please send them to
public-webapps@w3.org
(subscribe,
archives).
All comments are welcome.
Publication as a Working Draft does not imply endorsement by the W3C
Membership. This is a draft document and may be updated, replaced or obsoleted by other
documents at any time. It is inappropriate to cite this document as other than work in
progress.
This document was produced by
a group
operating under the
5 February 2004 W3C Patent
Policy.
W3C maintains a public list of any patent
disclosures
made in connection with the deliverables of
the group; that page also includes
instructions for disclosing a patent. An individual who has actual knowledge of a patent
which the individual believes contains
Essential
Claim(s) must disclose the information in accordance with
section
6 of the W3C Patent Policy.
This document is governed by the 1 September 2015 W3C Process Document.
1. About this Document
All diagrams, examples, notes, are non-normative, as well as sections explicitly marked as non-normative. Everything else in this specification is normative.
The key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in the normative parts of this document are to be interpreted as described in RFC2119. For readability, these words do not appear in all uppercase letters in this specification.
Any point, at which a conforming UA must make decisions about the state or reaction to the state of the conceptual model, is captured as algorithm. The algorithms are defined in terms of processing equivalence. The processing equivalence is a constraint imposed on the algorithm implementers, requiring the output of the both UA-implemented and the specified algorithm to be exactly the same for all inputs.
2. Dependencies
This document relies on the following specifications:
3. Terminology
HTML Imports, or just imports from here on, are HTML documents that are linked as external resources from another HTML document. The document that links to an import is called an import referrer. For any given import, an import referrer ancestor is its import referrer or any import referrer ancestor of its import referrer. There are one or more import referrers and import referrer ancestors for each import because same import can be referred from multiple import referrers.
An import referrer that is not an import, thus is not associated with any import referrer, is called a master document. Each import is associated with one master document: if the referrer of the import is a master document, it is the master document of the import. Otherwise, the master document of the import referrer is the master document of the import.
The URL of an import is called the import location.
In each import referrer, an import is represented as a Document, called the imported document.
The set of all imports associated with the master document forms an import map of the master document. The maps stores imports as its items with their import locations as keys. The import map is empty at beginning. New items are added to the map as import fetching algorithm specifies.
3.1 Import Dependent
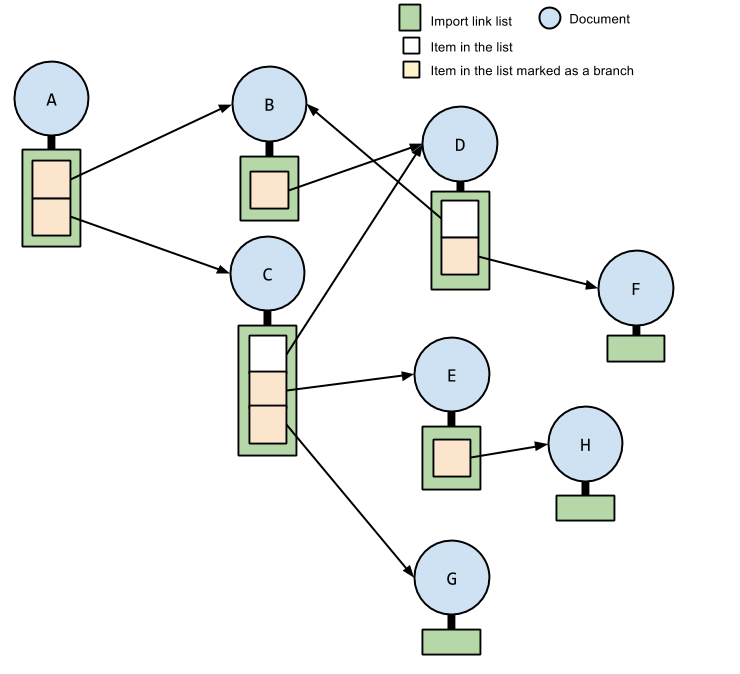
To track requested imports, each document has an import link list. Each of its item consists of link, a link element and location, a URL.
Also, the item is optionally marked as branch.
The list is initially empty, and items are added to it as specified by the import request algorithm.
Each imported document has an import parent: If the import link list of document A contains a branch item whose location points document B, A is an import parent of B.
Each imported document also has one or more import ancestors: Document A is an import ancestor of another document B if A is import parent of B. Being an import ancestor is transitive: If A is an import parent of B and B is an import parent of C, A is an import parent of C as well.
An imported document also has one or more import predecessors. An import predecessor is a document. If the URL of document A is located before the URL of document B in the import link list of B's import parent, and the located link is marked as a branch, then A is import predecessor of B.
The import ancestor predecessors of document A is defined as follows: If document B is an import predecessor of document C, and C is an import ancestor of A, B is an import ancestor predecessors of A.
The Document that is in either import ancestor predecessors or import predecessors of document A, or is linked from branch item of A's import link list, is the import dependent of A.
5. Extensions to HTMLLinkElement Interface
partial interface HTMLLinkElement {
readonly attribute Document? import;
};
On getting, the import attribute must return null, if:
Otherwise, the attribute must return the imported document for the import, represented by the link element.
The same object must be returned each time.
An import in the context of the Document of an HTML parser or XML Parser is said to be an import that is blocking scripts if the element was created by that Document's parser, or and the element is a link of type import when the element was created by the parser, and the link is not marked as async, and the the import is yet to be completely loaded, and, the last time the event loop has reached step 1, the element was in that Document, and the user agent hasn't given up on that import yet. A user agent may give up on an import at any time.
A Document has an import that is blocking scripts if there is an import that is blocking scripts in the Document's import dependent.
A Document has no import that is blocking scripts if it does not have an import that is blocking scripts as defined in the previous paragraph.
6. Extensions to Document Interface
Additions to document.open() method
Add following step as the first step of the definition:
Additions to document.write() method
Add following step as the first step of the definition:
Additions to document.close() method
Add following step as the first step of the definition:
7. Loading Imports
7.2 Requesting Import
When user agents attempt to obtain a linked import, they must also run the import request algorithm, which is equivalent to running these steps:
8. Parsing Imports
Parsing behaviour of imports is defined as a set of changes to the HTML Parsing.
8.1 Additions to Prepare A Script Algorithm
In step 15 of prepare a script algorithm, modify the last part of condition which begins with If element does not have a src attribute to read:
8.2 Additions to Tree Construction Algorithm
At the DOCTYPE part of section 12.2.5.4.1 The "initial" insertion mode, modify text if the document is not an iframe srcdoc document...
as follows
if the document is not an iframe src document nor an import...
In sub-condition named Otherwise of condition An end tag whose name is "script" in "text" insertion mode, modify step 3 to read:
8.3 Additions to Parsing XHTML Documents
Modify step 3 of steps that run following preparing the script element to read:
9. Scripting in Imports
9.2 Additions to document.currentScript
Modify the definition of document.currentScript
as follows:
The currentScript attribute, on getting,
must return the value to which it was most recently initialized in the document or the import map of the document.
When the Document is created, the currentScript must be initialized to null.
If the Document is an imported document, its currentScript is always null.
10. Style processing with Imports
The contents of the style elements and
the external resources of the link elements in imports must be considered as input sources of the style processing model of the master document.
10.1 Import Link Tree
A set of imports that are associated with a master document forms an import link tree, a tree structure. Following import link tree forming algorithm, being applied with null as PARENT, master document as TREE and all of its imports as POOL, defines the import link tree:
- Input
- PARENT, a document tree node
- CURRENT, a document
- POOL, a list of document
- Output
- TREE, a tree of document
- Let TREE be a tree node.
- Let TREE's value be CURRENT
- Let TREE's parent be PARENT.
- Make TREE's child list empty.
- For each LINK, a
link element of an import in CURRENT, in document order:
- Let IMPORT be the import of LINK.
- If IMPORT is not in POOL, try next.
- Remove LINK from POOL.
- Invoke the import tree forming algorithm with TREE as PARENT, IMPORT as CURRENT and POOL as POOL, let the result be CHILD.
- Append CHILD to TREE's child list.
- stop.
11. Events in Imports
Events in imports is defined as a set of changes to the HTML Events.
A. Acknowledgements
David Hyatt developed XBL 1.0, and Ian Hickson co-wrote XBL 2.0. These documents provided tremendous insight into the problem of behavior attachment and greatly influenced this specification.
Alex Russell and his considerable forethought triggered a new wave of enthusiasm around the subject of behavior attachment and how it can be applied practically on the Web.
Dominic Cooney and Roland Steiner worked tirelessly to scope the problem within the confines of the Web platform and provided a solid foundation for this document.
The editor would also like to thank Alex Komoroske, Angelina Fabbro, Anne van Kesteren, Boris Zbarsky, Brian Kardell, Daniel Buchner, Edward O'Connor, Eric Bidelman, Erik Arvidsson, Elliott Sprehn, Gabor Krizsanits, Hayato Ito, James Simonsen, Jonas Sicking, Ken Shirriff, Neel Goyal, Olli Pettay, Rafael Weinstein, Scott Miles, Steve Orvell, Tab Atkins, William Chan, and William Chen for their comments and contributions to this specification.
This list is too short. There's a lot of work left to do. Please contribute by reviewing and filing bugs—and don't forget to ask the editor to add your name into this section.