Abstract
This document aims to support discussion about what is needed in the HTML5 specification, and possibly other markup vocabularies, to adequately support ruby markup. It looks at a number of use cases involving ruby, and how well the following approaches support those use cases: the HTML5 model described in the Candidate Recommendation as of 17 December 2012, the XHTML Ruby Annotation model, and the Ruby Extension Specification proposed in February 2013.
Status of This Document
This section describes the status of this document at the time of its publication. Other
documents may supersede this document. A list of current W3C publications and the latest revision
of this technical report can be found in the W3C technical reports
index at http://www.w3.org/TR/.
This document aims to support discussion about what is needed in the HTML5 specification, and possibly other markup vocabularies, to adequately support ruby markup.
This document was published by the Internationalization Working Group as a Working Group Note.
If you wish to make comments regarding this document, please send them to
public-i18n-cjk@w3.org
(subscribe,
archives).
All comments are welcome.
Publication as a Working Group Note does not imply endorsement by the W3C Membership.
This is a draft document and may be updated, replaced or obsoleted by other documents at
any time. It is inappropriate to cite this document as other than work in progress.
This document was produced by a group operating under the
5 February 2004 W3C Patent Policy.
W3C maintains a public list of any patent disclosures
made in connection with the deliverables of the group; that page also includes instructions for
disclosing a patent. An individual who has actual knowledge of a patent which the individual believes contains
Essential Claim(s) must disclose the
information in accordance with section
6 of the W3C Patent Policy.
1. Introduction
This document was designed to support discussion about what is needed in the HTML5 specification, and possibly other markup vocabularies, to adequately support ruby markup. It describes a number of use cases associated with ruby usage, and then examines a number of possible ruby markup approaches for each use case, listing pros and cons for each approach.
1.1 Conventions used in this document
Section 2 is concerned with the tags used inside the ruby element, and so those tags are shown in the examples.
The other sections are more concerned with the order of items within the ruby element. Examples in those sections use a bullet to indicate the boundary between elements: red text represents an rb element and its content or, where rb elements are not part of the model, the text of a single ruby base; orange text represents an rt element and its content. Tags for all other markup are shown explicitly.
1.2 Approaches listed here
For each of the use cases the document looks at the following three approaches to markup, and how effectively they meet the needs of the use case. The document occasionally proposes additional ideas to extend one of the markup models.
- XHTML
- This is the approach defined in the Ruby Annotation recommendation. This markup model is essentially described for historical context. For more information, see the Ruby Annotation specification.
- HTML5
- This is the approach defined in the 17 December 2012 Candidate Recommendation of the HTML5 specification. See the following sections of the specification: The ruby element, The rt element, and The rp element.
- Ruby Extension Specification
- This is the approach defined in the Ruby Extension Specification of 25 February 2013.
1.3 Overview of conclusions
The following table summarizes how well each of the 3 ruby markup models supports each of the use cases.
| Use case |
XHTML |
HTML5 |
Extension spec |
| Ruby base styling |
For most cases, yes, but not for styling base characters independently. |
Basic approach:
Only in simple scenarios. It doesn't enable direct access to the ruby base text, therefore excluding various types of styling and causing problems for accessible rendering.
With span:
Yes, for most simple styling cases. But for general styling of base text on a page you need to always use a span, and that begs the question why there isn't a semantic rb element instead. General conversion of ruby to ruby text only, for accessibility, is still problematic. |
Yes. |
| Fallback in one paren |
No, for fallback. Yes, using styling, for inline ruby text. |
No. |
Yes. |
| Jukugo ruby |
Yes, although with slightly more markup than desirable. |
Yes. |
Yes. |
| Bopmofo ruby |
Yes, although with much more markup than desirable. |
Yes. |
Yes. |
| Double-sided ruby |
Yes, but complicated markup. |
Yes, but complicated to author and implement because two different approaches needed. |
Yes. |
1.4 What is ruby?
The term ruby is used to refer to a particular type of annotation. Typically, ruby is used in East Asian scripts to provide
phonetic transcriptions of obscure characters, or characters that the reader is not expected to be familiar with. For example it is widely used in
educational materials and children's texts. It is also occasionally used to convey information about meaning. In some cases, the same base text may be annotated for both pronunciation and meaning.
In Japanese, where ruby is sometimes called furigana, phonetic transcriptions typically appear in hiragana above
horizontal text and to the right of vertical text. In Chinese, phonetic annotations in pinyin, a Latin script transcription of the Chinese base characters, often appear below the base text.
Here is an example of ruby in Japanese.

When Japanese is set vertically, the ruby text above would normally appear to the right.

When ruby text is used in Japanese for semantic annotations it typically appears below the horizontal text or to the left of vertical text.
Although ruby in Japanese is typically in hiragana, it is also possible to find annotations in kanji, katakana and Latin
text.
In Taiwan, zhuyin fuhao (bopomofo) characters are used to indicate the pronunciation of Traditional Chinese. Rather than appearing above the
main text, the annotation is usually included vertically to the right of each character, whether the main text is vertical or horizontal. Tone marks generally appear to the right of the column of bopomofo characters.
For example:

Ruby may also be used for non-Asian annotations and to support inter-linear text, but the use cases here focus on the main uses in Far Eastern scripts.
For detailed information about ruby in Japanese, see Requirements for Japanese Text Layout, sections 3.3 Ruby and Emphasis Dots and Appendix F Positioning of Jukugo-ruby.
Note
Ruby text annotations should be disregarded in some situations, such as finding text or copying text. Underlining should not be split between bases or between ruby and adjacent underlined elements.
1.5 Types of ruby
There are three types of ruby behavior.
Mono ruby is commonly used for phonetic annotation of text. In mono-ruby all the ruby text for a given character is positioned alongside a single base character, and doesn't overlap adjacent base characters. You can break a word that uses mono ruby at any point, and the ruby text just stays with the base character.
Group ruby is often used where phonetic annotations don't map to discreet base characters, or for semantic glosses that span the whole base text. You can't split text that is annotated with group ruby. It has to wrap as a single unit onto the next line.
Jukugo refers to a Japanese compound noun, ie. a word made up of more than one kanji character. Jukugo ruby is a term that is used to describe the alignment of ruby annotations over jukugo text. Jukugo ruby involves slightly different behavior. than for mono or group ruby. Jukugo ruby behaves like mono ruby, in that there is a strong association between ruby text and individual base characters. This becomes clear when you split a word at the end of a line: the ruby text is split so that the ruby annotating a specific base character stays with that character. What is different about jukugo ruby is that when the word is not split at the end of the line, there can be some significant amount of overlap of ruby text with adjacent base characters, which in some cases may make it appear like group ruby.
Note
Sometimes this may give the appearance that jukugo ruby behaves like group ruby, but this actually only arises in certain circumstances.
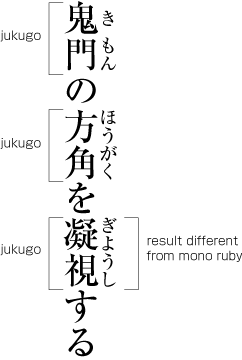
The image to the right shows three examples of ruby annotating jukugo words.
In the top two examples, mono ruby could be used to produce the desired effect, since neither of the base characters are overlapped by ruby text that doesn't relate to that character.
The third example is where we see the difference that is referred to as jukugo ruby. The first three ruby characters are associated with the first kanji base character. Just the last ruby character is associated with the second kanji base character. And yet the ruby text has been arranged evenly across both kanji characters.
Note, however, that we aren't simply spreading the ruby over the whole word, as we would with group ruby. There are rules that apply, and in some cases gaps will appear. See the following examples of distribution of ruby text over jukugo words.

2. Use Case A: Ruby base styling
This section is concerned more with the presence or absence of elements representing the ruby base than with the order of the elements inside the ruby element.
A content author may want to apply styling to the base text separately from the ruby text, in a way that requires direct access to the ruby base content itself.
One example may involve coloring the base text or styling it in some way differently from the surrounding text.
The image below shows another example, a very common approach to educational materials, which requires the ruby base to be styled independently of the ruby and rt elements.
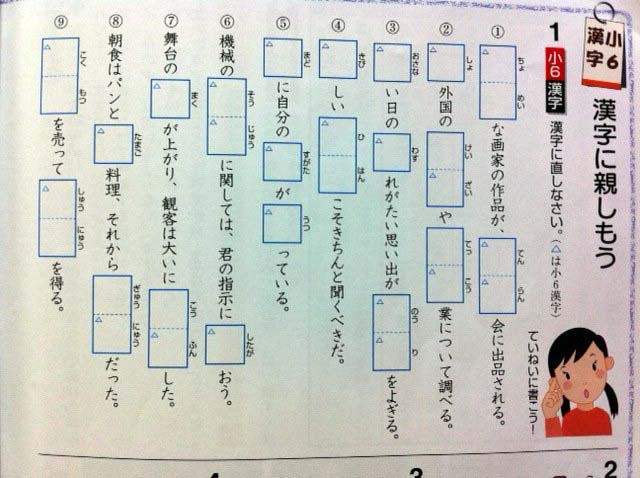
A third example would be where you want to hide the base text and show only the ruby text. This would be useful for adapting content to suit children, students and others who have trouble with kanji.
See also the related accessibility use case below.
There are three ways in which these use cases may be applied:
-
the style may need to be applied to all base text in a page or section
-
styling may be selectively applied to individual ruby base items
-
styling may be applied to parts of one ruby base selectively, where the ruby base is composed of multiple characters. For an example of this, imagine that the figure above of educational material contained the word 今日. These two kanji characters are phonetically annotated with a single run of ruby text, きょう, but you would need to style the boxes around each kanji base character separately.
2.1 Accessibility use case
Research for elementary and junior-high students by the Japanese government in 2010 indicated that 0.2% of them have difficulty reading hiragana, and 6.9% have difficulty with kanji. Kanji dyslexia is related to difficulty in visual recognition of complex drawings, and therefore adding ruby makes them even harder to read (ruby text adds more complexity.)
The researchers tried several methods to improve readability and found that the best method was to replace kanji with hiragana. For this use case, it would be ideal if user style sheet can replace kanji with its reading without changing markup.
This implies that it would be necessary to have direct access to the ruby base, whether or not it is marked up with an rb tag.
2.2 XHTML approach
Simple ruby in XHTML requires rb elements in the ruby elements you want to style – only one rb element is allowed per ruby element, and it is mandatory. A closing tag is required for all elements.
<ruby><rb>法</rb><rt>ほ</rt></ruby><ruby><rb>華</rb>
<rt>け</rt></ruby><ruby><rb>経</rb><rt>きょう</rt></ruby>
It is possible to simply style the rb elements:
rb { background-color: green; }
2.2.1 Pros and cons
It is easy to identify the ruby base element and apply any kind of styling to it.
The XHTML model is, however, too inflexible and verbose. It requires rb tags always, including both opening and closing tags, and allows only one rb per ruby element. This leads to a large markup overhead, compared to other models, and can therefore make it harder to author and maintain source code.
The XHTML model doesn't allow for any markup within an rb element, so you could not style parts of a multi-character ruby base separately. This rules out the educational styling shown above for words like 今日.
There are other problems with the XHTML approach, such as the fact that requiring a separate ruby element for each base item makes it impossible to handle jukugo styling for compound words (see below), but these issues will be discussed later.
An advantage of this approach is that, since rb tags are required, it would be easy to adapt a whole page for accessibility by replacing the base text with the ruby text.
Another advantage is that you can break a line in the source text between the between rb and rt tags without introducing unwanted spaces to the rendered text (unlike the HTML5 example below).
2.2.3 Does it support the use case?
For most cases, yes, but not for styling base characters independently.
2.3 HTML5 approach (basic)
The HTML5 CR approach does not have an rb element. This also means that, for multiple pairings within a single ruby element, you have to use closing tags for the rt elements (to separate them from the ruby base).
The markup would look like this:
<ruby>法<rt>ほ</rt>華<rt>け</rt>経<rt>きょう</rt><ruby>
To style the base element, apply a style to the ruby element, then apply a style to the rt element that overrides that style. For example.
ruby { color: red; }
rt { color: black; }
2.3.1 Pros and cons
For styling that is achievable by this method, this is somewhat clumsy. For example, to keep the color of the rt text the same as that of the surrounding text you would have to change the rt text properties as well as that of the text surrounding the ruby element.
Some properties cannot be applied to base text with this method, such as background or border, so you would not be able to produce the educational example in the picture above by this method. Nor would you be able to replace the ruby base with the ruby text for the accessibility case.
Readability of the source code is improved slightly over the XHTML model by the absence of rb tags, but note that you cannot break a line in the source text between the opening and closing ruby tags without introducing unwanted spaces to the rendered text (unlike the XHTML example above, where the line can be broken between rb and rt tags). This may be a particular issue where an editor automatically formats the source code.
2.3.2 Does it support the use case?
Only in simple scenarios. It doesn't enable direct access to the ruby base text, therefore excluding various types of styling and causing problems for accessible rendering.
2.4 HTML5 approach with span
Use the span element for styling, eg.
<ruby><span>法</span><rt>ほ</rt><span>華</span><rt>け</rt>
<span>経</span><rt>きょう</rt></ruby>
Then style the span elements, eg.
ruby span { color: red; }
2.4.1 Pros and cons
The span element can be used in place of the rb tag. It is not as short as rb, which is a slight downside for hand editing and for legibility.
Note also that the issue mentioned above about about line breaks in the source remains, and is made worse by the fact that the span tags significantly lengthen the ruby element.
Unlike rb, several span elements could be used where one item of ruby text is associated with multiple base characters, such as to color three successive base characters with different colors, or to style just one of the characters.
Although they could style specific base text this way, authors would be unlikely to add span elements around all base text just in case they needed to be styled. This implies that you will still have a problem if you want to achieve the accessibility use case through styling.
If authors did use span elements around all base text items, to allow for styling, it begs the question as to why there isn't an rb element to do this job. An rb element could reduce the markup required (especially if end tags are dispensed with, see below) and could be argued to be more semantically appropriate.
2.4.3 Does it support the use case?
Yes, for most simple styling cases. But for general styling of base text on a page you need to always use a span, and that begs the question why there isn't a semantic rb element instead. General conversion of ruby to ruby text only, for accessibility, is still problematic.
2.5 Enhanced HTML5 approach, with implicit rb
The HTML5 approach could be extended to allow CSS to style ruby base directly without the need for markup. eg. use
rb { color: red; }
for the following markup
<ruby>法<rt>ほ</rt>華<rt>け</rt>経<rt>きょう</rt></ruby>
but add a ruby base element to the DOM, and/or allow CSS to add an anonymous box for styling.
2.5.1 Pros and cons
This approach allows to style ruby base text, but without the overhead of additional markup for the content developer.
The designer could style any ruby text on a page. This provides a way of replacing all base text with ruby text for the accessibility use case (eg. using rb { display:none; } rt { display:inline; } ), in addition to the other use cases described.
Designers could also style individual ruby bases by using a class or id name on a ruby element that surrounds the ruby base to be styled. It would be slightly tricky, however, to style just one rb element out of many inside a ruby element, especially if you wanted to style a single ruby base in each of a number of ruby elements where the ruby base in question was in a different relative position within each ruby element. If you were able to use rb tags and thereby a class name, that would be trivial.
It would be possible to resort to span to selectively style part of a multi-character ruby base.
Traversing the DOM becomes easier. Without rb, traversing needs to scan all children of ruby except rt and rp and combine them. If, for instance, base text is H2O, it consists of 3 nodes. CSS Ruby creates an anonymous box around the 3 boxes but there's no direct counterpart in the DOM without an implicit rb tag.
There are two ways to implement this.
- Imply
rb in the DOM, just like tbody is implied
- Assign
rb style to a ruby base anonymous box
The latter only works if they are styled as ruby, because the anonymous box exists for ruby but not for inline display, so it will not work when ruby-position is set to inter-character or inline, and also when fallback occurs.
Also, the former makes accessing base text slightly easier, as grabbing the rb element is easier than grabbing all elements other than rt and rp elements (and any future additions).
On the other hand, the former requires changes in the parser. Also there are several cases that we need to define regarding behavior; e.g., what if rb and non-rb bases are mixed, what happens if non-rb content is inserted by JavaScript, etc.
2.5.2 Does it support the use case?
Yes, but a little tricky if you need to pick out, say, one ruby base per ruby element and they are not all in the same position.
2.6 Extension Spec approach
The extension spec allows for optional rb elements in the ruby elements you want to style. You can have various amounts of markup, but the simplest approach would be:
<ruby><rb>法<rt>ほ<rb>法<rt>け<rb>経<rt>きょう</ruby>
You can then style the rb elements very simply:
rb { background-color: green; }
Alternatively, you can group the rb and rt tags separately, like this:
<ruby><rb>法<rb>華<rb>経<rt>ほ<rt>け<rt>きょう</ruby>
The ramifications of the ordering of elements in this model will be discussed below. With regards to the amount of markup, the situation is essentially the same in both cases.
2.6.1 Pros and cons
It is trivial to identify the ruby base element and apply any kind of styling to it, as long as an rb tag was used.
The markup is more semantically clear than when using a span element. The extension spec still allows for span elements to be used inside rb elements for styling multiple characters in a single base item separately.
The extension spec also allows you to selectively use rb tags for just the ruby bases that need styling, but the approach shown in the example above would not require any more markup than if the rb tag wasn't used (because you'd have to close the rt elements instead); as such this encourages use of the rb tag for all ruby elements. If this approach were used throughout the page, the content author could style any ruby text on a page.
This markup approach also provides a way of replacing all base text with ruby text for the accessibility use case (eg. using rb { display:none; } rt { display:inline; } ), in addition to the other use cases described.
The markup shown above is also slightly easier to read than the standard HTML5 approach. It does have the drawback that it is not possible to use line breaks inside the ruby element in the source without introducing spurious space, but that can be dealt with by using closing tags, either at the end of the line or throughout. Partly this depends on how the HTML is created: if the source is hand-crafted, it may be easier to use the approach above and tweak at line breaks; if it is created using an authoring tool or scripting, it may be as easy to use closing tags throughout. (It would also be possible for a browser to automatically eliminate white space surrounding a ruby base or ruby annotation.)
2.6.3 Does it support the use case?
Yes.
3. Use Case B: Fallback and inline ruby text for compound nouns
When we refer here to fallback, we mean what happens when a browser doesn't support ruby. If a browser doesn't support ruby, the content of the ruby element will be produced as ordinary characters, in the order in which they appear inside the ruby element.
The rp element is intended to contain characters that can be used to offset the ruby text from the base text, typically parentheses. By placing the rp element at the right locations relative to the other ruby content, it is possible to make the fallback text more readable. The rp element is ignored by browsers that know what to do with ruby annotations.
Tokyo is written with two kanji characters, 東, which is pronounced とう, and 京, which
is pronounced きょう. The key issue here is that, when multiple base characters are treated as a 'compound word', each base character should be annotated individually, but the fallback should be
東京(とうきょう) not 東(とう)京(きょう).
Fallback requires rp elements to make the text more readable. This cannot be replicated by styling or scripting, since it is not possible to detect whether or not the browser supports ruby (although this could theoretically be signalled by some API feature.)
The importance of a good solution for fallback is inversely proportional to the number of browsers that support ruby.
Note that content developers may also want to style content to look like this when the font size is too small for ruby to be
readable. This is a separate use case. We refer to this as inline ruby.
Inline ruby annotations have to be produced using styling. (CSS3 Ruby has an inline value for the ruby-position property.) The parentheses needed for inline annotation can be provided using rp elements, or could be added using styling.
3.1 XHTML approach
The Ruby Annotation model distinguishes between simple and complex ruby. For simple ruby you need a ruby element around every base item. To associate several base items as a unit you would need to use complex ruby, like this:
<ruby><rbc>法•華•経</rbc><rtc>ほ•け•きょう</rtc></ruby>
XHTML doesn't allow rp elements in complex ruby, so fallback is not supported.
For inline ruby text, it would be possible to style the rtc element so that parentheses can appear before or after it, using the following CSS:
rtc:before { content: '('; }
rtc:after { content: ')'; }
You could only do this, however, for cases where you specifically want inline rendering. If the browser is capable of rendering the ruby above or below the base text, you would not want to see parentheses.
3.1.1 Does it support the use case?
No, for fallback. Yes, using styling, for inline ruby text.
3.2 HTML5 approach
With the current HTML5 model the ruby content is interleaved by default, ie.
<ruby>法<rp>(</rp>ほ<rp>)</rp>華<rp>(</rp>け<rp>)</rp>経<rp>(</rp>きょう<rp>)</rp></ruby>
Fallback, therefore, cannot produce grouped ruby text for a compound noun.
For inline ruby text, there is no way to style this so that the ruby annotations all appear after the ruby bases.
A further problem of this approach is that it can prevent hits when searching for terms like 法華経 in naive applications, since the kanji characters making up that word are separated by intervening ruby text.
It is theoretically possible that a browser could automatically reorder the content within a ruby element for rendering inline ruby text. If a browser did that, the content author would just have to be careful to place the ruby tags at the right place for the fallback to work.
3.2.1 Does it support the use case?
No.
3.3 Extension spec approach
The desired fallback can be
achieved if the ruby is written as
<ruby>法•華•経<rp>(<rp>ほ•け•きょう<rp>)</rp></ruby>
This approach also allows you to associate ruby text with compound nouns within a compound noun phrase, if that is what you want to do. See the example here:
<ruby>常•用<rp>(<rp>じょう•よう<rp>)</rp>漢•字<rp>(<rp>かん•じ<rp>)</rp>
表<rp>(<rp>ひょう<rp>)</rp></ruby>
3.3.1 Pros and cons
This allows the desired grouping of ruby text by compound word in both fallback and inline scenarios. (In fact, it allows you to group ruby text however you like within the ruby element.)
This approach doesn't prevent you from listing ruby text after each ideographic base character, if you wish. For example, bopomofo ruby can be associated with Chinese characters one at a time.
Another benefit of this approach is that it helps when searching for terms like 法華経 in naive applications, since the kanji characters making up that word are not separated by intervening ruby text.
3.3.2 Does it support the use case?
Yes.
3.4 Scripting flag
The problem with fallback is that you can't provide characters such as parentheses to clarify the repetition of base and ruby text for the reader unless you provide rp elements around all your ruby text. It is a tall order to expect that everyone will do that religiously. Not only does it significantly increase the amount of effort required to create ruby markup, but it makes the source text more difficult to read, and adds complexity when it comes to searching text.
For inline ruby text, styling can provide the needed delimiters, using :before and :after, but this approach can't be used for general fallback because such an approach would also produce delimiters around ruby text if the browser is capable of displaying ruby text above or below the base text.
A possible solution might be to test whether the browser supports ruby using scripting. If it doesn't, then it would be possible to activate styling to introduce delimiters.
For this to work, it would be necessary for the DOM API to indicate whether ruby is supported by the browser.
4. Use Case C: Jukugo Ruby
Compound words in Japanese (known as jukugo) allow for significant overlaps of the ruby text with adjacent base characters, however the relationships between ruby text and base text has to remain clear because line breaks can occur in the middle of the compound word and the base characters that move to the next line have to take with them all associated rt elements, and no more (unlike group ruby, which cannot admit line breaks).
For a description of jukugo ruby and how it differs from mono ruby and group ruby, see this blog post (see in particular the images at the bottom of the page that show the complex distribution of ruby text, sometimes forcing gaps to appear. Jukugo ruby may often look like group ruby, but it is not.)
Multiple kanji compound words can also form one compound phrase. In this case, there are two ways to attach ruby, i.e. attaching ruby to the compound phrase as a whole, or to each word which forms the compound. Similarly, a Japanese personal name consists of a given name and a family name, which together form a compound of a full name, and it is an editorial decision whether to attach two runs of ruby, one each for given name and family name, or to attach the full ruby text to the compound which represents the reading of the full name.
All of the approaches outlined here assume that the actual distribution of ruby text across the base text will be managed by CSS styling. The role of the markup is to indicate the start and end of the compound noun or phrase across which the styling will be applied, and associate each individual ruby base with the appropriate ruby text to allow for line breaking.
Note also that the current version of the CSS Ruby spec prevents the use of this model for jukugo by forbidding line breaks within the ruby element. That will need to be changed to enable jukugo support, but it is not a facet of the markup itself.
4.1 XHTML approach
To define the boundaries of the jukugo word you would need to use complex ruby from the Ruby Annotation spec. This would require use of rb but also rbc and rtc.
<ruby><rbc>法•華•経</rbc><rtc>ほ•け•きょう</rtc></ruby>
4.1.1 Pros and cons
This approach is heavy on markup, even though it does associate rb elements with rt elements, and define the boundaries of the jukugo word.
It would not be possible to establish boundaries around compound words within a compound phrase, however. You would have to break the phrase into separate ruby elements.
4.1.2 Does it support the use case?
Yes, although with slightly more markup than desirable.
4.2 HTML5 approach
It would be possible to just use the current HMTL5 ruby model, but style the ruby element as jukugo ruby.
<ruby>法•ほ•華•け•経•きょう</ruby>
4.2.1 Pros and cons
Users would need to put ruby tags around the jukugo words, to indicate the boundaries of the jukugo, which may mean slightly more ruby tags than otherwise, but that is probably unavoidable.
It would not be possible to establish boundaries around compound words within a compound phrase, however. You would have to break the phrase into separate ruby elements.
On the other hand, this approach has the advantage that it is slightly easier for browsers to determine which ruby text belongs to which base text.
This approach can prevent hits when searching for terms like 法華経 in naive applications, since the kanji characters making up that word are separated by intervening ruby text.
4.2.2 Does it support the use case?
Yes.
4.3 Extension Spec approach
The extension spec allows for markup like this.
<ruby>法•華•経•ほ•け•きょう</ruby>
It also allows you to indicate jukugo word boundaries while marking up a whole compound phrase in a single ruby element, if that's what you want to do.
<ruby>常•用•じょう•よう•漢•字•かん•じ•表•ひょう</ruby>
4.3.1 Pros and cons
This approach does associate rb elements with rt elements, and define the boundaries of the jukugo word, and is economical on markup.
The fact that you can define the boundaries of multiple compound words within a ruby element covering a whole compound phrase is an additional bonus. If you want the jukugo styling to apply across the whole compound phrase you would need to use a single group of rb elements, followed by a single group of rt elements.
4.3.2 Implementations
IE's rendering of this markup is close to jukugo ruby already, but it doesn't allow line-breaking within the word.
Line breaks in ruby elements
4.3.3 Does it support the use case?
Yes.
5. Use Case D: Bopomofo ruby
Traditional Chinese is often annotated with a phonetic script called zhùyīn fúhào, also known as bopomofo.
As described in the introduction, rather than appearing above or below the
main text, the annotation is usually situated vertically to the right of each character, whether the main text is vertical or horizontal.
For example:
Bopomofo annotations are usually done on a character by character basis. The ruby text can contain a tone marker, always written after the bopomofo characters, but appearing in different places depending on the type of tone and the number of bopomofo characters.
One tone appears above the vertical stack of bopomofo characters. The others appear to the right of the column of bopomofo characters, and the vertical position depends on the number of bopomofo characters in the stack.
It is also possible to find bopomofo annotations that are horizontal, where the same complex positioning of tone marks occurs, though it is much less common.
The precise positioning of tone marks is the most difficult thing to manage with respect to bopomofo ruby, but this is not markup dependent. In markup terms, this kind of ruby is just mono-ruby. It is likely that a CSS property value will be needed to indicate that special handling is needed here, and that the browser itself apply the precise positioning of the ruby text content.
5.1 XHTML approach
For the XHTML approach use simple ruby.
<ruby>左•ㄗㄨㄛˇ</ruby><ruby>邊•ㄅㄧㄢ</ruby><ruby>一•ㄧ</ruby><ruby>隻•
ㄓ</ruby><ruby>貓•ㄇㄠ</ruby><ruby>喵•ㄇㄧㄠ˙</ruby><ruby>喵•
ㄇㄧㄠ˙</ruby><ruby>叫•ㄐㄧㄠˋ</ruby>
<ruby>法•華•経</rbc><rtc>ほ•け•きょう</rtc></ruby>
5.1.1 Pros and cons
This approach, like all the others, supports bopomofo ruby just as easily as mono-ruby. It is, however, very heavy on markup.
This approach can prevent hits when searching for compound nouns in naive applications, since the ideographic characters making up that word are separated by intervening ruby text, and possibly rp elements too.
5.1.2 Does it support the use case?
Yes, although with much more markup than desirable.
5.2 HTML5 approach
It would be possible to just use the current HMTL5 ruby model, but style the ruby element as jukugo ruby.
<ruby>左•ㄗㄨㄛˇ•邊•ㄅㄧㄢ•一•ㄧ•隻•ㄓ•貓•ㄇㄠ•喵•ㄇㄧㄠ˙•喵•ㄇㄧㄠ˙•叫•ㄐㄧㄠˋ</ruby>
5.2.1 Pros and cons
The markup supports the associations adequately.
It is difficult to break a line using this model without introducing spurious spaces.
This approach can prevent hits when searching for compound nouns in naive applications, since the ideographic characters making up that word are separated by intervening ruby text, and possibly rp elements too.
5.2.2 Does it support the use case?
Yes.
5.3 Extension Spec approach
The extension spec allows for markup identical to the HTML5 approach, but also like this.
<ruby>左•邊•一•隻...•ㄗㄨㄛˇ•ㄅㄧㄢ•ㄧ•ㄓ...</ruby>
5.3.1 Pros and cons
While the latter approach would allow for easy matching of compound words with a naïve search application, it is not clear whether the fallback produced by browsers that don't support ruby would be better or worse than the HTML5 model.
5.3.2 Does it support the use case?
Yes.
6. Use Case E: Double-sided ruby
Sometimes ruby is found on both sides of the base text.
There are a couple of sub use cases:
- Double-sided ruby is often a combination of phonetic information (which is done on a mono ruby basis) plus semantic or other ruby text (which is realized as group ruby).
- For phonetic and semantic cases, often the two ruby texts are applied to different parts of the base text, like this.
- Sometimes the author may want to put mono ruby on both sides of the base text, so that each ruby base is associated with two ruby texts that are positioned relative to that ruby base.
Real Examples
- Sometimes used in novels.
- Aozora Bunko (Wikipedia) has 10,870 novels and 17 of them have double-sided ruby, which is roughly 0.16%. Atomi University's research shows 65,065 books were published in Japan in year 2000, so simple math gives us about 102 books with double-sided ruby are published every year.
- Harry Potter uses double-sided ruby for subtitles of incantations. In this picture, the upper shows the sound while the lower shows the reading of the meaning.
- Widely used in school textbooks for Japanese, social studies, and histories.
- Examples: 1 2 3 4
- Exam question examples: 1 (p. 10) 2 (p. 10)
- Widely used in Japanese history research papers.
- Kanbun (classical Chinese text with annotation to help Japanese to read, Wikipedia) usually require double-sided ruby.
- Example
- In a Q&A site, the question is about how to layout Kanbun in word processors, and the best answer teaches how to enter double-sided ruby using Ichitaro, one of the most popular word processors in Japan.
Note that sometimes the ruby text on either side of the base corresponds to a different set of base characters. Here is an example: 
6.1 XHTML approach
Use complex ruby from the Ruby Annotation spec. The following markup allows for two rt elements to be associated with each rb like mono ruby.
<ruby><rbc>東•南</rbc><rtc>とう•なん</rtc><rtc>tou•nan</rtc></ruby>
The following markup, incorporating the rbspan, could be used for associating mono ruby on the top and group ruby below.
<ruby><rbc>東•南</rbc><rtc>とう•なん</rtc><rtc rbspan="2">たつみ</rtc></ruby>
Pros and cons
This model allows for double-sided ruby, however there is a lot of markup, which makes it hard to author and maintain.
You can achieve quite complicated tabular effects with rbspan attributes, but it's a little complicated to keep track of things, and it's not clear that that level of complexity is really required.
Implementations
Firefox has an add-on that supports this approach, and has code in the browser that is close to being able to support this approach but is not yet part of the released product.
Does it support the use case?
Yes, but rather complicated markup.
6.2 HTML5 approach
To arrange mono-ruby above and below the base text, you can use the following approach, where the base text has no rb tags, of course:
<ruby>東•とう•tou•南•なん•nan</ruby>
You could achieve gaps on one side or the other by having no rt element or an empty element.
To arrange mono-ruby above and a single group ruby below the base text, you can use the following approach:
<ruby><ruby>東•とう•南•なん</ruby>たつみ</ruby>
In the following ruby element only the first base text item has ruby text on both sides.
<ruby><ruby>護•まも•れ</ruby>プロテゴ</ruby>!
Pros and cons
It would be useful to specify in the HTML5 spec that by default an rt immediately following a ruby element should go below the base text. The desired effect could presumably be achieved using styling (with a selector such as ruby+rt) if CSS ruby-position is supported.
This is actually fairly simple markup, compared to the ruby annotation complex ruby markup.
When two rt are paired with different parts of the base, nesting only works when one contains the other; e.g., for base "ABC", the first rt is for "AB" and the second rt is for "BC". From the data we have today, it looks like that covers most use cases, but it might not be good enough for Kanbun use cases. In this regard, we may need more research.
Having two different ways of arranging double-sided ruby is far from ideal, since it makes for a complicated model for content authors and implementers
Implementations
Nested ruby works on Chrome and Safari, but not IE, but in Webkit both rt elements appear above the base, instead of one above and one below (for horizontal text).
Doubled rt tags after base text Doesn't work on Chrome/Safari, but both rts are treated as a single annotation of the base text (ie. side by side but over the base text) by IE.
(See a summary of results and links to the test framework at http://www.w3.org/International/tests/html-css/ruby/results-ruby-markup#multiply (Multiplying markup) )
Does it support the use case?
Yes, but complicated to author and implement because two different approaches needed.
6.3 Ruby Extension approach
Add an rtc element that can contain ruby text or a series of rt elements.
For example, to have mono ruby on both sides of a word, use
To arrange mono-ruby above and below the base text, you can use the following approach, with minimal markup:
<ruby>東•南•とう•なん<rtc>tou•nan</rtc></ruby>
You could achieve gaps on one side or the other by having an empty rt element.
To arrange mono-ruby above and a single group ruby below the base text, you can use the following approach:
<ruby>東•南•とう•なん<rtc>たつみ</rtc></ruby>
In the following ruby element only the first base text item has ruby text on both sides. There is an empty rt element just before the rtc element.
<ruby>護•れ•まも•<rtc>プロテゴ</rtc></ruby>!
Pros and cons
This offers a more uniform approach to double-sided ruby markup, however it requires some rules for interpreting the markup and the mapping between elements.
It can be extended to handle everything else in Ruby Annotation's complex ruby model, if that becomes necessary in the future.
Rules will need to be established for situations where the numbers of rb and rt elements doesn't match expectations.
Does it support the use case?
Yes.
A. Additional ruby markup notes
The document Ruby extension markup examines various possible models for marking up ruby using the proposed Ruby Extension Spec as of 27 February 2013, and considers whether the markup is conformant or not. It also considers whether the markup is conformant with the model found in the HTML5 draft of 25 October 2012.
It also provides a foundation for the development of future guidelines for authors on how to mark up ruby, and for development of basic ruby tests.
C. Revision Log
No feedback requesting changes was received since the previous 'Last Call' version of this document was published, so no changes have been made to this document since the previous publication other than those needed to prepare it for publication as a Working Group Note.
D. Acknowledgements
Thanks to Elika Etemad and Koji Ishii, who provided some of the ideas and in some cases material included here. Also members of the Internationalization Working Group and Interest Group, who provided feedback and suggestions.
{kind=link}
{kind=link}
{kind=link}