This document aims to support discussion about what is needed in the HTML5 specification, and possibly other markup vocabularies, to adequately support ruby markup.
This document introduces four key use cases associated with ruby markup, and then for each use case it looks at 4 possible models of markup, and how effective they are at meeting the needs of the use case.
The first is the XHTML model defined in the Ruby Annotation recommendation. This markup model is essentially described for historical context. For more information, see the Ruby Annotation specification.
The second is the markup model as currently defined in the current HTML5 specification. This description aims to point out whether the use case can be fulfilled by the current HTML5 without need for extension or change. See the following sections of the HTML5 specification: The ruby element, The rt element, and The rp element.
The third model, HTML5 enhanced, proposes extensions to the HTML5 model where a ruby element can contain multiple ruby base + ruby text pairs, but these are always in the order ruby-base+ruby-text(s), ruby-base+ruby-text(s), and so on. Some of the extensions described allow ruby base to be followed by one or two rt elements. A ruby base can optionally be contained within an rb tag.
The final model, 'grouped rb', is a model that departs from the typical HTML5 approach (and is essentially a simplified version of the XHTML model). Ruby base text is surrounded by an rb tag, but a single ruby element can contain multiple ruby base and ruby text pairings. Where a ruby element contains multiple rb and rt pairs, the rb elements are grouped together and the rt elements are grouped together (ie. rb,rb,..., rt, rt, ... ). This model is close to that described in this blog post.
The following table summarizes how well each of the 4 ruby markup models supports each of the 4 use cases.
| Use case |
XHTML model |
HTML5 model |
Interleaved rb and rt model |
Grouped rb model |
| Ruby base styling |
For most cases, yes, but not for styling base characters independently. But inflexibility in use of rb and the markup overhead make it untenable as a solution. |
With the most basic approach, only in simple scenarios. It doesn't enable direct access to the ruby base text, therefore excluding various types of styling and causing problems for accessible rendering. With span, Yes, for most simple styling cases. But for direct styling of the base text you need to always use a span, and that begins to beg the question why there isn't a semantic rb element instead. General conversion of ruby to ruby text only, for accessibility, is still problematic. |
With explicit rb, basically yes, but we can no longer expect authors to religiously use rb for all ruby bases, so there are still issues for retrofitting styles and for accessibility support.
With implicit rb, Yes. |
Only partly, and with issues |
| Fallback in one paren |
No |
No |
No |
Yes, but with possible issues |
| Jukugo ruby |
Yes, although with slightly more markup than desirable. |
Yes (as long as CSS provides the needed styling support). |
Since the current HTML5 model already supports jukugo ruby adequately, no extensions to that model are needed here. |
Yes (but the browser must manage alignment of pairings around line breaks). |
| Double-sided ruby |
Yes, but complicated markup. |
Yes. (Nesting should however, be called out in the spec so that implementations support it.) |
Only partially. Group ruby on one side and mono ruby on the other is not possible. |
Yes. |
The term ruby is used to refer to a particular type of annotation. Typically, ruby is used in East Asian scripts to provide
phonetic transcriptions of obscure characters, or characters that the reader is not expected to be familiar with. For example it is widely used in
educational materials and children's texts. It is also occasionally used to convey information about meaning. In some cases, the same base text may be annotated for both pronunciation and meaning.
In Japanese, where ruby is sometimes called furigana, phonetic transcriptions typically appear in hiragana above
horizontal text and to the right of vertical text. In Chinese, phonetic annotations in pinyin often appear below the base text.
Here is an example of ruby in Japanese. (The ruby in the examples on this
page is colored red only to direct your attention to it – it would normally be the same color as the base text.)

When Japanese is set vertically, the ruby text would normally appear to the right.

When ruby text is used for semantic annotations it typically appears below the horizontal text or to the left of vertical text.
Although ruby in Japanese is typically in hiragana, it is also possible to find annotations in kanji, katakana and Latin
text.
In Taiwan, zhuyin (bopomofo) characters are used to indicate the pronunciation of Traditional Chinese. Rather than appearing above the
main text, the annotation is included vertically to the right of each character, whether the main text is vertical or horizontal.
For example:

Ruby may also be used for non-Asian annotations and to support inter-linear text.
For detailed information about ruby in Japanese, see Requirements for Japanese Text Layout, sections 3.3 Ruby and Emphasis Dots and Appendix F Positioning of Jukugo-ruby.
Ruby text annotations should be disregarded in some situation, such as finding text or copying text. Underlining should not be split between bases or between ruby and adjacent underlined elements.
There are three types of ruby behaviour.
Mono ruby is commonly used for phonetic annotation of text. In mono-ruby all the ruby text for a given character is positioned alongside a single base character, and doesn't overlap adjacent base characters. You can break a word that uses mono ruby at any point, and the ruby text just stays with the base character.
Group ruby is often used where phonetic annotations don't map to discreet base characters, or for semantic glosses that span the whole base text. You can't split text that is annotated with group ruby. It has to wrap as a single unit onto the next line.
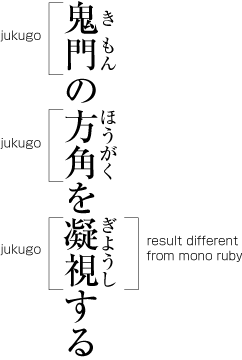
Jukugo refers to a Japanese compound noun, ie. a word made up of more than one kanji character. Jukugo ruby is a term that is used not to describe ruby annotations over jukugo text, but rather to describe ruby with a slightly different behaviour than mono or group ruby. Jukugo ruby behaves like mono ruby, in that there is a strong association between ruby text and individual base characters. This becomes clear when you split a word at the end of a line: the ruby text is split so that the ruby annotating a specific base character stays with that character. What is different about jukugo ruby is that when the word is NOT split at the end of the line, there can be some significant amount of overlap of ruby text with adjacent base characters.
Sometimes this may give the appearance that jukugo ruby behaves like group ruby, but this actually only arises in certain circumstances.
The image to the right shows three examples of ruby annotating jukugo words.
In the top two examples, mono ruby can be used to produce the desired effect, since neither of the base characters are overlapped by ruby text that doesn't relate to that character.
The third example is where we see the difference that is referred to as jukugo ruby. The first three ruby characters are associated with the first kanji character. Just the last ruby character is associated with the second kanji character. And yet the ruby text has been arranged evenly across both kanji characters.
Note, however, that we aren't simply spreading the ruby over the whole word, as we would with group ruby. There are rules that apply, and in some cases gaps will appear. See the following examples of distribution of ruby text over jukugo words.

A content author may want to apply styling to the base text separately from the ruby text, in a way that requires direct access to the ruby base content itself.
One example may involve coloring the base text or styling it in some way differently from the surrounding text.
This image below shows another example, a very common approach to educational materials, which requires the ruby base to be styled independently of the ruby and rt elements.
A third example would be where you want to hide the base text and show only the ruby text. This would be useful for adapting content to suit children, students and others who have trouble with kanji.
See also the related accessibility use case below.
There are three ways in which these use cases may be applied:
-
the style may need to be applied to all base text in a page or section
-
styling may be selectively applied to individual ruby base items
-
styling may be applied to parts of one ruby base selectively, where the ruby base is composed of multiple characters. For an example of this, imagine that the figure above of educational material contained the word 今日. These two kanji characters are phonetically annotated with a single run of ruby text, きょう, but you would need to style the boxes around each kanji base character separately.
Research for elementary and junior-high students by the Japanese government in 2010 indicated that 0.2% of them have difficulty reading Hiragana, and 6.9% have difficulty with Kanji. Kanji dyslexia is related to difficulty in visual recognition of complex drawings, and therefore adding ruby makes them even harder to read (ruby text adds more complexity.) The researchers tried several methods to improve readability and found that the best method was to replace Kanji with Hiragana. For this use case, it would be ideal if user stylesheet can replace Kanji with its reading without changing markup.
This implies that it would be necessary to have direct access to the ruby base, whether or not it is marked up with an rb tag.
Use rb elements in the ruby elements you want to style – only one rb element is allowed per ruby element, and it is mandatory.
<ruby><rb>B1</rb><rt>a1</rt></ruby>
<ruby><rb>B2</rb><rt>a2</rt></ruby>
Then style the rb elements:
rb { background-color: green; }
Pros and cons
It is easy to identify the ruby base element and apply any kind of styling to it.
The XHTML model is too inflexible and verbose. It requires rb always, and allows only one rb per ruby element. This leads to a large markup overhead, compared to the current HTML5 model, and can therefore make it harder to author and maintain source code. These requirements of the XHTML model are also problematic in that the HTML5 model, which allows rb tags to be dropped, and allows more than one rb element per ruby tag, has now been implemented by several major browsers.
The XHTML model doesn't allow for any markup within an rb element, so you couldn't style parts of a multi-character ruby base separately, if you wanted to. This rules out the educational styling shown above for words like 今日.
Implementations
It is not possible to style rb tags natively in IE8, but would be possible if you use the HTML5 shiv once that has rb added to it. It is possible in IE9 and current desktop versions of Firefox, Chrome, Safari and Opera. See the tests at http://www.w3.org/International/tests/html-css/ruby/results-ruby-markup#styling
Does it support the use case?
For most cases, yes, but not for styling base characters independently. But inflexibility in use of rb and the markup overhead make it untenable as a solution.
Use the current HTML5 model for simple ruby, but apply styling to the ruby element and rt elements. The markup would look like this:
<ruby>B1<rt>a1</rt>B2<rt>a2</rt><ruby>
To style the base element, apply a style to the ruby element, then apply a style to the rt element that overrides that style. For example.
ruby { color: red; }
rt { color: black; }
Pros and cons
For styling that is achievable by this method, this is somewhat clumsy. For example, to keep the color of the rt text the same as that of the surrounding text you would have to change the rt text properties as well as that of the text surrounding the ruby element.
Some properties can not be applied to base text with this method, such as background or border, so you would not be able to produce the educational example in the picture above by this method. Nor would you be able to replace the ruby base with the ruby text.
Does it support the use case?
Only in simple scenarios. It doesn't enable direct access to the ruby base text, therefore excluding various types of styling and causing problems for accessible rendering.
Use the span element for styling, eg.
<ruby><span>B1</span><rt>a1</rt><span>B2</span><rt>a2</rt></ruby>
Then style the span elements, eg.
ruby span { color: red; }
Pros and cons
Use of this element is similar to using the rb tag, though its use for presentational hooks is slightly less controversial. On the other hand, it is not as short as rb, which is a slight downside for hand editing and for legibility.
If the rb tag is used, rather than the span tag, the semantic nature of the tag urges that there should only be one rb tag per ruby base item, so styling multiple characters in a single base text separately would not be possible.
Unlike rb, several span elements could be used where one item of ruby text is associated with multiple base characters, such as to colour three successive base characters with different colours, or to style just one of the characters.
Although they could style specific base text this way, authors would be unlikely to add span elements around all base text just in case they needed to be styled. This makes this approach less attractive if you wanted to achieve the accessibility use case through styling.
Implementations
It is possible to style span tags inside ruby elements in IE8 and current desktop versions of Firefox, Chrome, Safari and Opera. See the tests at http://www.w3.org/International/tests/html-css/ruby/results-ruby-markup#styling
Best viewed in Chrome and Safari (but works partially in IE too).
Does it support the use case?
Yes, for most simple styling cases. But for direct styling of the base text you need to always use a span, and that begins to beg the question why there isn't a semantic rb element instead. General conversion of ruby to ruby text only, for accessibility, is still problematic.
Use rb elements in the ruby elements you want to style, eg.
<ruby><rb>B1</rb><rt>a1</rt>B2<rt>a2</rt></ruby>
Then style the rb elements:
rb { background-color: green; }
In the code above we have only surrounded the first ruby base with rb tags, because it is only that item that we need to style. The other base text can be left without rb markup.
This is different from the XHTML model in that it is possible to have multiple rb elements in a single ruby element, and the rb element is optional. It is different from the HTML5 model in that an rb element is involved.
Pros and cons
It is easy to identify the ruby base element and apply any kind of styling to it.
The markup is more semantically clear than when using a span element.
On the other hand, since it is optional, content authors are unlikely to use the rb tag for all ruby elements, and will only use it when they see a need to style the base text. This means that it cannot provide a reliable way of applying styling to all ruby base text throughout a document, such as for the accessibility use case mentioned above.
Use of the rb tag for styling doesn't lend itself to situations where you want to style individual kanji characters in a single ruby base separately. Because of its semantic nature, it would not be appropriate to have more than one rb tag per rt, so it would be necessary to resort to span for that. The span tag could be allowed in this model for that purpose.
Implementations
It is not possible to style rb tags natively in IE8, but it is possible if you use the HTML5 shiv after that has rb added to it. It is possible in IE9 and current desktop versions of Firefox, Chrome, Safari and Opera. See the tests at http://www.w3.org/International/tests/html-css/ruby/results-ruby-markup#styling
Does it support the use case?
Basically, yes, but we can no longer expect authors to religiously use rb for all ruby bases, so there are still issues for retrofitting styles and for accessibility support.
Allow CSS to style ruby base directly without the need for markup. eg. use
rb { color: red; }
for the following markup
<ruby>B1<rt>a1</rt>B2<rt>a2</rt></ruby>
but add a ruby base element to the DOM, and/or allow CSS to add an anonymous box for styling.
Pros and cons
This approach allows to style ruby base text, but without the overhead of additional markup for the content developer.
The designer could style any ruby text on a page. This provides a way of replacing all base text with ruby text for the accessibility use case (eg. using rb { display:none; } rt { display:inline; } ), in addition to the other use cases described.
Designers could also style individual ruby bases by using a class or id name on a ruby element that surrounds the ruby base to be styled.
It would be possible to resort to span to selectively style part of a multi-character ruby base.
Traversing the DOM becomes easier. Without rb, traversing needs to scan all children of ruby except rt and rp and combine them. If, for instance, base text is H2O, it consists of 3 nodes. CSS Ruby creates an anonymous box around the 3 boxes but there's no direct counterpart in the DOM without an implicit rb tag.
There are two ways to implement this.
- Imply
rb in the DOM, just like tbody is implied
- Assign
rb style to a ruby base anonymous box
The latter only works if they are styled as ruby, because the anonymous box exists for ruby but not for inline display, so it wi'll not work when ruby-position is set to inter-character or inline, and also when fallback occurs.
Also, the former makes accessing base text slightly easier, as grabbing the rb element is easier than grabbing all elements other than rt and rp elements (and any future additions).
On the other hand, the former requires changes in the parser. Also there are several cases that we need to define regarding behavior; e.g., what if rb and non-rb bases are mixed, what happens if non-rb content is inserted by JavaScript, etc.
Does it support the use case?
Yes.
In the grouped rb model, it is necessary to use rb tags to identify how the base text relates to the ruby text. The rb tags could be styled directly, as we saw with the interleaved model with explicit rb tags, above.
<ruby><rb>B1</rb><rb>B2</rb>
<rt>a1</rt><rt>a2</rt></ruby>
Pros and cons
Although this provides a handy way of accessing the ruby base text, it is a different model from that currently supported by HTML5 and beginning to be implemented in content. It requires the rb tag, and negates the advantages and simplicity of the HTML5 model for the author.
This would probably lead to a situation where content authors mix approaches to ruby markup – sometimes using the HTML5 model, sometimes using this mode; one interleaved, the other grouped. We do not expect the current HTML5 model to disappear, and it is appealing to authors due to its simplicity. Mixing the models in this way could create confusion but, more importantly, if this model were only used for some ruby elements on the page we would still have a situation where general styling of the ruby throughout a page is not possible (eg. for the accessibility case).
It would be necessary to specify behavior if content authors introduced an unequal number of rb and rt tags in a ruby element, and ensure that it is clear what the browser should do if this model is mixed in the document with the current HTML5 model.
If inline span tags are allowed within an rb element, this model will allow for selective styling of parts of a multi-character base text.
Does it support the use case?
Only partly, and with issues.
Tokyo is written with two kanji characters, 東, which is pronounced とう, and 京, which
is pronounced きょう. Each base character should be annotated individually, but the fallback should be
東京(とうきょう) not 東(とう)京(きょう).
The latter (ie. two parens) is what you would get with the current HTML5 ruby markup model.
Note that inline styling like this is not only used when ruby is not supported, but content developers may also want to style content to look like this when the font size is too small for ruby to be
readable.
The Ruby Annotation model allows for association of rb and rt elements, however the ruby annotation model doesn't allow for fallbacks in complex ruby, and use of complex ruby is the only way to identify word boundaries appropriately.
This approach would require some divergence from the current situation. It would be necessary to allow an rp element at the start and end of the rtc element. (Adding this may not be a big issue, since there is very little support for or use of complex ruby at the moment)
<ruby>
<rbc><rb>東</rb><rb>京</rb></rbc>
<rtc><rp>(</rp><rt>とう</rt><rt>きょう</rt><rp>)</rp></rtc>
</ruby>
Does it support the use case?
No.
This cannot be done with the current HTML5 model, ie. you can only have 東(とう)京(きょう).
<ruby>東<rp>(</rp><rt>とう</rt><rp>)</rp>京<rp>(</rp><rt>きょう</rt><rp>)</rp></ruby>
Does it support the use case?
No.
It is difficult to see how this could be
achieved if the rb and rt tags were interleaved, since the rp approach is based on the characters just falling out in the correct order for browsers that don't know what to do with ruby text.
On the other hand, if all major browsers support ruby, this issue may not be important anyway.
Does it support the use case?
No.
This could be
achieved if the ruby could be written as
<ruby><rb>B1</rb><rb>B2</rb>
<rp>(</rp><rt>a1</rt><rt>a2</rt><rp>)</rp></ruby>
For example:
<ruby>
<rb>東</rb><rb>京</rb>
<rp>(</rp><rt>とう</rt><rt>きょう</rt><rp>)</rp>
</ruby>
Pros and cons
Authors would need to use the rb tag and this different arrangement of rb and rt tags any time they wanted fallbacks to work on a word basis. This would probably lead to a situation where there are mixed models for ruby markup (some HTML5, some simplified XHTML), or to a preference for this model over the HTML5 model throughout the document. This could create confusion.
It would be necessary to specify behavior if content authors introduced an unequal number of rb and rt tags in a ruby element.
Even though this would be possible, it is very time-consuming and awkward to mark up all ruby in this way. It may be better to simply use styling rather than rp tags.
This model also involves the issues mentioned in approach A4, above, related to styling of base text.
Does it support the use case?
Yes, but with possible issues.
Compound words in Japanese (aka. jukugo) allow for significant overlaps of the ruby text with adjacent base characters, however the relationships between ruby text and base text has to remain clear because line breaks can occur in the middle of the compound word and the base characters that move to the next line have to take with them all rt elements, and no more, that they are associate with (unlike group ruby, which cannot admit line breaks).
For a description of jukugo ruby and how it differs from mono ruby and group ruby, see the introduction (see in particular the images at the bottom of the page that show the complex distribution of ruby text, sometimes forcing gaps to appear. Jukugo ruby may often look like group ruby, but it is not.)
To define the boundaries of the base characters that make up the jukugo word you would need to use complex ruby from the Ruby Annotation spec. This would require use of rb but also rbc and rtc. CSS styling could apply the correct overlap of ruby text and base elements.
<ruby>
<rbc><rb>思</rb><rb>春</rb><rb>期</rb></rbc>
<rtc><rt>し</rt><rt>しゅん</rt><rt>き</rt></rtc>
</ruby>
Pros and cons
This approach is very heavy on markup, and even though it associates rb elements with rt elements, it is not clear not what the advantage is, if the CSS Ruby specification could be used to apply the necessary overlaps. It would also be more complicated to implement.
(Note that the current version of the CSS Ruby spec prevents the use of this model for juguko by forbidding line breaks within the ruby element. That will need to be changed to enable jukugo support, but it is not a facet of the markup itself.)
Does it support the use case?
Yes, although with slightly more markup than desirable.
If it is possible to change the CSS Ruby spec to allow jukugo-style distribution of ruby text across the ruby base characters, while allowing breaks between any rb+rt pair, then in terms of markup, it would be possible to just use the current HMTL5 ruby model, but style the ruby element as jukugo ruby.
<ruby class="jukugo">B1<rt>a1</rt>B2<rt>a2</rt></ruby>
Pros and cons
It's simple and intuitive.
Users would need to put ruby tags around the jukugo words, to indicate the boundaries of the jukugo, which may mean slightly more ruby tags than otherwise, but that is probably unavoidable.
Does it support the use case?
Yes (as long as CSS provides the needed styling support).
Since the current HTML5 model already supports jukugo ruby adequately, no extensions to that model are needed here.
Use markup like this.
<ruby>
<rb>B1</rb><rb>B2</rb>
<rt>a1</rt><rt>a2</rt>
</ruby>
Pros and cons
This approach is similar to, but less heavy on markup than the XHTML model. It could allow part of the word to be wrapped at the end of a line while keeping base and ruby text together, however that would require the browser to manage the appropriate alignment of base and ruby text pairs for display on either side of the line break.
This is a little more complicated than the HTML5 model.
Implementations
IE's rendering of this markup is close to jukugo ruby already, but it doesn't allow line-breaking within the word.
Line breaks in ruby elements
Does it support the use case?
Yes (but the browser must manage alignment of pairings around line breaks).
Sometimes ruby is found on both sides of the base text.
There are a couple of sub use cases:
- Double-sided ruby is often a combination of phonetic information (which is done on a mono ruby basis) plus semantic or other ruby text (which is realised as group ruby).
- For phonetic and semantic cases, often the two ruby texts are applied to different parts of the base text, like this.
- Sometimes the author may want to put mono ruby on both sides of the base text, so that each ruby base is associated with two ruby texts that are positioned relative to that ruby base.
Real Examples
- Sometimes used in novels.
- Aozora Bunko (wikipedia) has 10,870 novels and 17 of them have double-sided ruby, which is roughly 0.16%. Atomi University's research shows 65,065 books were published in Japan in year 2000, so simple math gives us about 102 books with double-sided ruby are published every year.
- Harry Potter uses double-sided ruby for subtitles of incantations. In this picture, the upper shows the sound while the lower shows the reading of the meaning.
- Widely used in school textbooks for Japanese, social studies, and histories.
- Examples: 1 2 3 4
- Exam question examples: 1 (p. 10) 2 (p. 10) 4 (p. 3, single-side double ruby) 5 (p. 6)
- Widely used in Japanese history research papers.
- Kanbun (classical Chinese text with annotation to help Japanese to read, wikipedia) usually require double-sided ruby.
- Example
- In a Q&A site, the question is about how to layout Kanbun in word processors, and the best answer teaches how to enter double-sided ruby using Ichitaro, one of the most popular word processors in Japan.
Use complex ruby from the Ruby Annotation spec. The following markup allows for two rt elements to be associated with each rb like mono ruby.
<ruby>
<rbc><rb>B1</rb><rb>B2</rb></rbc>
<rtc><rt>rt1</rt><rt>rt3</rt></rtc>
<rtc><rt>rt2</rt><rt>rt4</rt></rtc>
</ruby>
The markup just below here, incorporating the rbspan, could be used for associating mono ruby on the top and group ruby below.
<ruby>
<rbc><rb>B1</rb><rb>B2</rb></rbc>
<rtc><rt>rt1</rt><rt>rt2</rt></rtc>
<rtc rbspan="2"><rt>rt3</rt></rtc>
</ruby>
Pros and cons
This model allows for double-sided ruby, however there is a lot of markup, which makes it hard to author and maintain.
You can achieve quite complicated tabular effects with rbspan attributes, but it's a little complicated to keep track of things, and it's not clear that that level of complexity is really required.
Implementations
Firefox has an add-on that supports this approach, and has code in the browser that is close to being able to support this approach but is not yet part of the released product.
Does it support the use case?
Yes, but rather complicated markup.
Nest ruby using the current html5 model.
<ruby><ruby>B1<rt>rt1</rt></ruby><rt>rt2</rt></ruby>
The following diagram shows a single ruby element in which only the first base text item has ruby text on both sides.
<ruby><ruby>B1<rt>rt1</rt></ruby><rt>rt2</rt>B2<rt>rt3</rt></ruby>
The next diagram shows a single ruby element in which each base text item has ruby text above, and there is a single ruby text below spanning both ruby bases. This is a common scenario, where mono-ruby appears above the base for phonetic annotations, and the semantic annotation (rt3) is a single group-ruby text below.
<ruby><ruby>B1<rt>rt1</rt>B2<rt>rt2</rt></ruby><rt>rt3</rt></ruby>
The final diagram shows a single ruby element in which each base text item has mono-ruby above and below. This might be seen where Chinese is annotated.
<ruby><ruby>B1<rt>rt1</rt></ruby><rt>rt2</rt>
<ruby>B2<rt>rt3</rt></ruby><rt>rt4</rt></ruby>
Pros and cons
It would be useful to specify in the HTML5 spec that by default an rt immediately following a ruby element should go below the base text. The desired effect could presumably be achieved using styling (with a selector such asruby+rt) if CSS ruby-position is supported.
This is actually fairly simple markup, compared to the ruby annotation complex ruby markup.
When two rt are paired with different parts of the base, nesting only works when one contains the other; e.g., for base "ABC", the first rt is for "AB" and the second rt is for "BC". From the data we have today, it looks like that covers most use cases, but it might not be good enough for Kanbun use cases. In this regard, we may need more research.
To achieve annotation such as that in the picture below, where the ruby text below maps to more than the ruby text above, you could use markup like this:
<p><ruby><ruby>B1B2B3<rt>rt1</rt>B4</ruby><rt>rt2</rt></ruby></p>

To achieve markup where the top ruby maps to the first 3 base characters, and the bottom ruby maps to the last 3 base characters, may not be possible, but it is debatable how important this use case is.
Implementations
Nested ruby works on Chrome and Safari, but not IE, but in Webkit both rt elements appear above the base, instead of one above and one below (for horizontal text).
(See a summary of results and links to the test framework at http://www.w3.org/International/tests/html-css/ruby/results-ruby-markup#multiply (Multiplying markup) )
Does it support the use case?
Yes. (Nesting should however, be called out in the spec so that implementations support it.)
For mono-ruby on both sides of the base text, use an augmented HTML5 model. The following diagram shows a single ruby element in which only the first base text item has ruby text on both sides.
<ruby>B1<rt>rt1</rt><rt>rt2</rt>B2<rt>rt3</rt></ruby>
Pros and cons
This would enable two mono ruby annotations to be associated with one ruby base at a time. You could achieve gaps on one side or the other by having no rt element or an empty element.
You cannot have the upper and the lower ruby texts to map to different base text, as in the example in the previous approach. It may be possible with some kind of colspan approach, although this may produce complicated markup.
There would need to be a rule in the specification to say that a maximum of two rt elements are allowed after each rb element.
Also, currently, the spec says "An rt element that is a child of a ruby element represents an annotation (given by its children) for the zero or more nodes of phrasing content that immediately precedes it in the ruby element, ignoring rp elements." which appears to say that the second rt text in <ruby>B1<rt>rt1</rt><rt>rt2</rt></ruby> should appear over a blank space. Webkit has been implemented to display the second rt text on the baseline after the base text, but IE (from which the HTML5 model was reverse engineered) displays it alongside the first rt text and centres both rt texts over the base text. This appears to indicate an inconsistency in the spec. See the test for this at the bottom of the ruby markup test results page (doubled rt tags). If this model was adopted, the spec would need to be changed to clarify the expected behaviour.
This is much simpler markup than that for complex ruby in the ruby annotation spec.
It is not clear how to achieve mono-ruby above the base and group ruby below. You could use nested ruby for that, as described in the previous section, but having two different ways of arranging double-sided ruby is far from ideal, since it makes for a complicated model for content authors and implementers.
Implementations
Doubled rt tags after base text Doesn't work on Chrome/Safari, but both rts are treated as a single annotation of the base text (ie. side by side but over the base text) by IE.
(See a summary of results and links to the test framework at http://www.w3.org/International/tests/html-css/ruby/results-ruby-markup#multiply (Multiplying markup) )
Does it support the use case?
Only partially. Group ruby on one side and mono ruby on the other is not possible.
Add an rtc element that can contain ruby text or a series of rt elements.
For example, to have mono ruby on both sides of a word, use
<ruby>
<rb>B1</rb><rb>B2</rb>
<rt>rt1</rt><rt>rt3</rt>
<rtc><rt>rt2</rt><rt>rt4</rt></rtc>
</ruby>
To have group ruby on one side, use
<ruby>
<rb>B1</rb><rb>B2</rb>
<rt>rt1</rt><rt>rt3</rt>
<rtc>rt3</rtc>
</ruby>
Pros and cons
This offers a more uniform approach to double-sided ruby markup, however it requires some rules for interpreting the markup and the mapping between elements.
It can be extended to handle everything else in Ruby Annotation's complex ruby model, if that becomes necessary in the future.
Rules will need to be established for situations where the numbers of rb and rt elements doesn't match expectations.
Does it support the use case?
Yes.

{kind=link}
{kind=link}
{kind=link}