
HTML5
8.2 Parsing HTML documents
This section only applies to user agents, data mining tools,
and conformance checkers.
The rules for parsing XML documents into DOM trees
are covered by the next section, entitled "The XHTML
syntax".
For HTML documents, user agents must use the parsing
rules described in this section to generate the DOM trees. Together,
these rules define what is referred to as the HTML
parser.
While the HTML syntax described in this specification bears a
close resemblance to SGML and XML, it is a separate language with
its own parsing rules.
Some earlier versions of HTML (in particular from HTML2 to
HTML4) were based on SGML and used SGML parsing rules. However, few
(if any) web browsers ever implemented true SGML parsing for HTML
documents; the only user agents to strictly handle HTML as an SGML
application have historically been validators. The resulting
confusion — with validators claiming documents to have one
representation while widely deployed Web browsers interoperably
implemented a different representation — has wasted decades
of productivity. This version of HTML thus returns to a non-SGML
basis.
Authors interested in using SGML tools in their authoring
pipeline are encouraged to use XML tools and the XML serialization
of HTML.
This specification defines the parsing rules for HTML documents,
whether they are syntactically correct or not. Certain points in the
parsing algorithm are said to be parse
errors. The error handling for parse errors is well-defined:
user agents must either act as described below when encountering
such problems, or must abort processing at the first error that they
encounter for which they do not wish to apply the rules described
below.
Conformance checkers must report at least one parse error
condition to the user if one or more parse error conditions exist in
the document and must not report parse error conditions if none
exist in the document. Conformance checkers may report more than one
parse error condition if more than one parse error condition exists
in the document. Conformance checkers are not required to recover
from parse errors.
Parse errors are only errors with the
syntax of HTML. In addition to checking for parse errors,
conformance checkers will also verify that the document obeys all
the other conformance requirements described in this
specification.
For the purposes of conformance checkers, if a resource is
determined to be in the HTML syntax, then it is an
HTML document.
8.2.1 Overview of the parsing model
The input to the HTML parsing process consists of a stream of
Unicode characters, which is passed through a
tokenization stage followed by a tree
construction stage. The output is a Document
object.
Implementations that do not
support scripting do not have to actually create a DOM
Document object, but the DOM tree in such cases is
still used as the model for the rest of the specification.
In the common case, the data handled by the tokenization stage
comes from the network, but it can also come from script running in the user
agent, e.g. using the document.write() API.
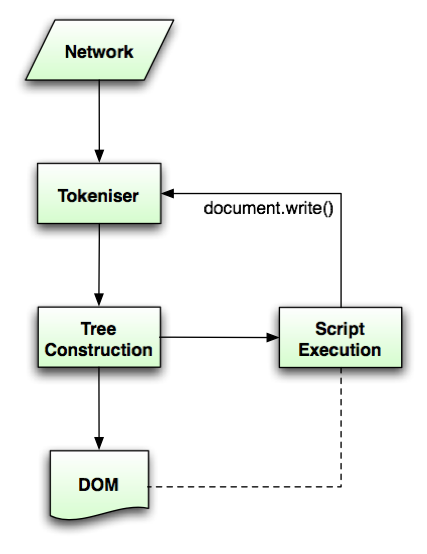
There is only one set of states for the
tokenizer stage and the tree construction stage, but the tree
construction stage is reentrant, meaning that while the tree
construction stage is handling one token, the tokenizer might be
resumed, causing further tokens to be emitted and processed before
the first token's processing is complete.
In the following example, the tree construction stage will be
called upon to handle a "p" start tag token while handling the
"script" end tag token:
...
<script>
document.write('<p>');
</script>
...
To handle these cases, parsers have a script nesting
level, which must be initially set to zero, and a parser
pause flag, which must be initially set to false.
The stream of Unicode characters that comprises the input to the
tokenization stage will be initially seen by the user agent as a
stream of bytes (typically coming over the network or from the local
file system). The bytes encode the actual characters according to a
particular character encoding, which the user agent must
use to decode the bytes into characters.
For XML documents, the algorithm user agents must
use to determine the character encoding is given by the XML
specification. This section does not apply to XML documents. [XML]
8.2.2.1 Determining the character encoding
In some cases, it might be impractical to unambiguously determine
the encoding before parsing the document. Because of this, this
specification provides for a two-pass mechanism with an optional
pre-scan. Implementations are allowed, as described below, to apply
a simplified parsing algorithm to whatever bytes they have available
before beginning to parse the document. Then, the real parser is
started, using a tentative encoding derived from this pre-parse and
other out-of-band metadata. If, while the document is being loaded,
the user agent discovers an encoding declaration that conflicts with
this information, then the parser can get reinvoked to perform a
parse of the document with the real encoding.
User agents must use the following
algorithm (the encoding sniffing algorithm) to determine
the character encoding to use when decoding a document in the first
pass. This algorithm takes as input any out-of-band metadata
available to the user agent (e.g. the Content-Type metadata of the document)
and all the bytes available so far, and returns an encoding and a
confidence. The
confidence is either tentative, certain, or
irrelevant. The encoding used, and whether the confidence in
that encoding is tentative or certain, is used during the parsing to
determine whether to change the encoding. If no
encoding is necessary, e.g. because the parser is operating on a
stream of Unicode characters and doesn't have to use an encoding at
all, then the confidence is
irrelevant.
If the user has explicitly instructed the user agent to
override the document's character encoding with a specific
encoding, optionally return that encoding with the confidence
certain and abort these steps.
If the transport layer specifies an encoding, and it is
supported, return that encoding with the confidence
certain, and abort these steps.
-
The user agent may wait for more bytes of the resource to be
available, either in this step or at any later step in this
algorithm. For instance, a user agent might wait 500ms or 1024
bytes, whichever came first. In general preparsing the source to
find the encoding improves performance, as it reduces the need to
throw away the data structures used when parsing upon finding the
encoding information. However, if the user agent delays too long
to obtain data to determine the encoding, then the cost of the
delay could outweigh any performance improvements from the
preparse.
The authoring conformance requirements for
character encoding declarations limit them to only appearing in the first 1024 bytes. User agents are
therefore encouraged to use the preparse algorithm below (part of
these steps) on the first 1024 bytes, but not to stall beyond
that.
For each of the rows in the following table, starting with
the first one and going down, if there are as many or more bytes
available than the number of bytes in the first column, and the
first bytes of the file match the bytes given in the first column,
then return the encoding given in the cell in the second column of
that row, with the confidence
certain, and abort these steps:
| Bytes in Hexadecimal
| Encoding
|
|---|
| FE FF
| Big-endian UTF-16
|
| FF FE
| Little-endian UTF-16
|
| EF BB BF
| UTF-8
|
This step looks for Unicode Byte Order Marks
(BOMs).
Otherwise, the user agent will have to search for explicit
character encoding information in the file itself. This should
proceed as follows:
Let position be a pointer to a byte in the
input stream, initially pointing at the first byte. If at any
point during these substeps the user agent either runs out of
bytes or decides that scanning further bytes would not be
efficient, then skip to the next step of the overall character
encoding detection algorithm. User agents may decide that scanning
any bytes is not efficient, in which case these substeps
are entirely skipped.
Now, repeat the following "two" steps until the algorithm
aborts (either because user agent aborts, as described above, or
because a character encoding is found):
If position points to:
- A sequence of bytes starting with: 0x3C 0x21 0x2D 0x2D (ASCII '<!--')
-
Advance the position pointer so that it
points at the first 0x3E byte which is preceded by two 0x2D
bytes (i.e. at the end of an ASCII '-->' sequence) and comes
after the 0x3C byte that was found. (The two 0x2D bytes can be
the same as the those in the '<!--' sequence.)
- A sequence of bytes starting with: 0x3C, 0x4D or 0x6D, 0x45 or 0x65, 0x54 or 0x74, 0x41 or 0x61, and finally one of 0x09, 0x0A, 0x0C, 0x0D, 0x20, 0x2F (case-insensitive ASCII '<meta' followed by a space or slash)
-
Advance the position pointer so
that it points at the next 0x09, 0x0A, 0x0C, 0x0D, 0x20, or
0x2F byte (the one in sequence of characters matched
above).
Let attribute list be an empty
list of strings.
Let got pragma be false.
Let need pragma be null.
Let charset be the null value
(which, for the purposes of this algorithm, is distinct from
an unrecognised encoding or the empty string).
Attributes: Get an
attribute and its value. If no attribute was sniffed,
then jump to the processing step below.
If the attribute's name is already in attribute list, then return to the step
labeled attributes.
Add the attribute's name to attribute
list.
-
Run the appropriate step from the following list, if one
applies:
- If the attribute's name is "
http-equiv"
If the attribute's value is "content-type", then set got
pragma to true.
- If the attribute's name is "
content"
Apply the algorithm for extracting an encoding
from a meta element, giving the
attribute's value as the string to parse. If an encoding is
returned, and if charset is still set
to null, let charset be the encoding
returned, and set need pragma to
true.
- If the attribute's name is "
charset"
Let charset be the encoding
corresponding to the attribute's value, and set need pragma to false.
Return to the step labeled attributes.
Processing: If need pragma
is null, then jump to the second step of the overall "two
step" algorithm.
If mode is true but got pragma is false, then jump to the second
step of the overall "two step" algorithm.
If charset is a UTF-16 encoding,
change the value of charset to
UTF-8.
If charset is not a supported
character encoding, then jump to the second step of the
overall "two step" algorithm.
Return the encoding given by charset, with confidence
tentative, and abort all these steps.
- A sequence of bytes starting with a 0x3C byte (ASCII <), optionally a 0x2F byte (ASCII /), and finally a byte in the range 0x41-0x5A or 0x61-0x7A (an ASCII letter)
-
Advance the position pointer so
that it points at the next 0x09 (ASCII TAB), 0x0A (ASCII LF),
0x0C (ASCII FF), 0x0D (ASCII CR), 0x20 (ASCII space), or 0x3E
(ASCII >) byte.
Repeatedly get an
attribute until no further attributes can be found,
then jump to the second step in the overall "two step"
algorithm.
- A sequence of bytes starting with: 0x3C 0x21 (ASCII '<!')
- A sequence of bytes starting with: 0x3C 0x2F (ASCII '</')
- A sequence of bytes starting with: 0x3C 0x3F (ASCII '<?')
-
Advance the position pointer so that it
points at the first 0x3E byte (ASCII >) that comes after the
0x3C byte that was found.
- Any other byte
-
Do nothing with that byte.
- Move position so it points at the next
byte in the input stream, and return to the first step of this
"two step" algorithm.
When the above "two step" algorithm says to get an
attribute, it means doing this:
If the byte at position is one of 0x09
(ASCII TAB), 0x0A (ASCII LF), 0x0C (ASCII FF), 0x0D (ASCII CR),
0x20 (ASCII space), or 0x2F (ASCII /) then advance position to the next byte and redo this
substep.
If the byte at position is 0x3E (ASCII
>), then abort the "get an attribute" algorithm. There isn't
one.
Otherwise, the byte at position is the
start of the attribute name. Let attribute
name and attribute value be the empty
string.
Attribute name: Process the byte at position as follows:
- If it is 0x3D (ASCII =), and the attribute
name is longer than the empty string
- Advance position to the next byte and
jump to the step below labeled value.
- If it is 0x09 (ASCII TAB), 0x0A (ASCII LF), 0x0C (ASCII
FF), 0x0D (ASCII CR), or 0x20 (ASCII space)
- Jump to the step below labeled spaces.
- If it is 0x2F (ASCII /) or 0x3E (ASCII >)
- Abort the "get an attribute" algorithm. The attribute's
name is the value of attribute name, its
value is the empty string.
- If it is in the range 0x41 (ASCII A) to 0x5A (ASCII
Z)
- Append the Unicode character with code point b+0x20 to attribute
name (where b is the value of the
byte at position).
- Anything else
- Append the Unicode character with the same code point as the
value of the byte at position) to attribute name. (It doesn't actually matter how
bytes outside the ASCII range are handled here, since only
ASCII characters can contribute to the detection of a character
encoding.)
Advance position to the next byte and
return to the previous step.
Spaces: If the byte at position is one of 0x09 (ASCII TAB), 0x0A (ASCII
LF), 0x0C (ASCII FF), 0x0D (ASCII CR), or 0x20 (ASCII space) then
advance position to the next byte, then,
repeat this step.
If the byte at position is
not 0x3D (ASCII =), abort the "get an attribute"
algorithm. The attribute's name is the value of attribute name, its value is the empty
string.
Advance position past the 0x3D (ASCII
=) byte.
Value: If the byte at position is one of 0x09 (ASCII TAB), 0x0A (ASCII
LF), 0x0C (ASCII FF), 0x0D (ASCII CR), or 0x20 (ASCII space) then
advance position to the next byte, then,
repeat this step.
Process the byte at position as
follows:
- If it is 0x22 (ASCII ") or 0x27 (ASCII ')
-
- Let b be the value of the byte at
position.
- Advance position to the next
byte.
- If the value of the byte at position
is the value of b, then advance position to the next byte and abort the "get
an attribute" algorithm. The attribute's name is the value of
attribute name, and its value is the
value of attribute value.
- Otherwise, if the value of the byte at position is in the range 0x41 (ASCII A) to
0x5A (ASCII Z), then append a Unicode character to attribute value whose code point is 0x20 more
than the value of the byte at position.
- Otherwise, append a Unicode character to attribute value whose code point is the same as
the value of the byte at position.
- Return to the second step in these substeps.
- If it is 0x3E (ASCII >)
- Abort the "get an attribute" algorithm. The attribute's
name is the value of attribute name, its
value is the empty string.
- If it is in the range 0x41 (ASCII A) to 0x5A (ASCII
Z)
- Append the Unicode character with code point b+0x20 to attribute
value (where b is the value of the
byte at position). Advance position to the next byte.
- Anything else
- Append the Unicode character with the same code point as the
value of the byte at position) to attribute value. Advance position to the next byte.
Process the byte at position as
follows:
- If it is 0x09 (ASCII TAB), 0x0A (ASCII LF), 0x0C (ASCII
FF), 0x0D (ASCII CR), 0x20 (ASCII space), or 0x3E (ASCII
>)
- Abort the "get an attribute" algorithm. The attribute's
name is the value of attribute name and its
value is the value of attribute value.
- If it is in the range 0x41 (ASCII A) to 0x5A (ASCII
Z)
- Append the Unicode character with code point b+0x20 to attribute
value (where b is the value of the
byte at position).
- Anything else
- Append the Unicode character with the same code point as the
value of the byte at position) to attribute value.
Advance position to the next byte and
return to the previous step.
For the sake of interoperability, user agents should not use a
pre-scan algorithm that returns different results than the one
described above. (But, if you do, please at least let us know, so
that we can improve this algorithm and benefit everyone...)
If the user agent has information on the likely encoding for
this page, e.g. based on the encoding of the page when it was last
visited, then return that encoding, with the confidence
tentative, and abort these steps.
-
The user agent may attempt to autodetect the character encoding
from applying frequency analysis or other algorithms to the data
stream. Such algorithms may use information about the resource
other than the resource's contents, including the address of the
resource. If autodetection succeeds in determining a character
encoding, then return that encoding, with the confidence
tentative, and abort these steps. [UNIVCHARDET]
The UTF-8 encoding has a highly detectable bit
pattern. Documents that contain bytes with values greater than
0x7F which match the UTF-8 pattern are very likely to be UTF-8,
while documents with byte sequences that do not match it are very
likely not. User-agents are therefore encouraged to search for
this common encoding. [PPUTF8] [UTF8DET]
-
Otherwise, return an implementation-defined or user-specified
default character encoding, with the confidence
tentative.
In controlled environments or in environments where the
encoding of documents can be prescribed (for example, for user
agents intended for dedicated use in new networks), the
comprehensive UTF-8 encoding is
suggested.
In other environments, the default encoding is typically
dependent on the user's locale (an approximation of the languages,
and thus often encodings, of the pages that the user is likely to
frequent). The following table gives suggested defaults based on
the user's locale, for compatibility with legacy content. Locales
are identified by BCP 47 language tags. [BCP47]
| Locale language
| Suggested default encoding
|
|---|
| ar
| UTF-8
|
| be
| ISO-8859-5
|
| bg
| windows-1251
|
| cs
| ISO-8859-2
|
| cy
| UTF-8
|
| fa
| UTF-8
|
| he
| windows-1255
|
| hr
| UTF-8
|
| hu
| ISO-8859-2
|
| ja
| Windows-31J
|
| kk
| UTF-8
|
| ko
| windows-949
|
| ku
| windows-1254
|
| lt
| windows-1257
|
| lv
| ISO-8859-13
|
| mk
| UTF-8
|
| or
| UTF-8
|
| pl
| ISO-8859-2
|
| ro
| UTF-8
|
| ru
| windows-1251
|
| sk
| windows-1250
|
| sl
| ISO-8859-2
|
| sr
| UTF-8
|
| th
| windows-874
|
| tr
| windows-1254
|
| uk
| windows-1251
|
| vi
| UTF-8
|
| zh-CN
| GB18030
|
| zh-TW
| Big5
|
| All other locales
| windows-1252
|
The document's character encoding must immediately
be set to the value returned from this algorithm, at the same time
as the user agent uses the returned value to select the decoder to
use for the input stream.
This algorithm is a willful violation
of the HTTP specification, which requires that the encoding be
assumed to be ISO-8859-1 in the absence of a character
encoding declaration to the contrary, and of RFC 2046,
which requires that the encoding be assumed to be US-ASCII in the
absence of a character encoding declaration to the
contrary. This specification's third approach is motivated by a
desire to be maximally compatible with legacy content. [HTTP] [RFC2046]
8.2.2.2 Character encodings
User agents must at a minimum support the UTF-8 and Windows-1252
encodings, but may support more. [RFC3629] [WIN1252]
It is not unusual for Web browsers to support dozens
if not upwards of a hundred distinct character encodings.
User agents must support the preferred MIME name of
every character encoding they support, and should support all the
IANA-registered names and aliases of every character encoding they
support. [IANACHARSET]
When comparing a string specifying a character encoding with the
name or alias of a character encoding to determine if they are
equal, user agents must remove any leading or trailing space characters in both names, and
then perform the comparison in an ASCII
case-insensitive manner.
When a user agent would otherwise use an encoding given in the
first column of the following table to either convert content to
Unicode characters or convert Unicode characters to bytes, it must
instead use the encoding given in the cell in the second column of
the same row. When a byte or sequence of bytes is treated
differently due to this encoding aliasing, it is said to have been
misinterpreted for compatibility.
The requirement to treat certain encodings as other
encodings according to the table above is a willful
violation of the W3C Character Model specification, motivated
by a desire for compatibility with legacy content. [CHARMOD]
When a user agent is to use the UTF-16 encoding but no BOM has
been found, user agents must default to UTF-16LE.
The requirement to default UTF-16 to LE rather than
BE is a willful violation of RFC 2781, motivated by a
desire for compatibility with legacy content. [RFC2781]
User agents must not support the CESU-8, UTF-7, BOCU-1 and SCSU
encodings. [CESU8] [UTF7] [BOCU1] [SCSU]
Support for encodings based on EBCDIC is not recommended. This
encoding is rarely used for publicly-facing Web content.
Support for UTF-32 is not recommended. This encoding is rarely
used, and frequently implemented incorrectly.
This specification does not make any attempt to
support EBCDIC-based encodings and UTF-32 in its algorithms; support
and use of these encodings can thus lead to unexpected behavior in
implementations of this specification.
Given an encoding, the bytes in the input stream must be
converted to Unicode characters for the tokenizer, as described by
the rules for that encoding, except that the leading U+FEFF BYTE
ORDER MARK character, if any, must not be stripped by the encoding
layer (it is stripped by the rule below).
Bytes or sequences of bytes in the original byte stream that
could not be converted to Unicode code points must be converted to
U+FFFD REPLACEMENT CHARACTERs. Specifically, if the encoding is
UTF-8, the bytes must be decoded with the error handling defined in this
specification.
Bytes or sequences of bytes in the original byte
stream that did not conform to the encoding specification
(e.g. invalid UTF-8 byte sequences in a UTF-8 input stream) are
errors that conformance checkers are expected to report.
Any byte or sequence of bytes in the original byte stream that is
misinterpreted for compatibility is a parse
error.
One leading U+FEFF BYTE ORDER MARK character must be ignored if
any are present.
The requirement to strip a U+FEFF BYTE ORDER MARK
character regardless of whether that character was used to determine
the byte order is a willful violation of Unicode,
motivated by a desire to increase the resilience of user agents in
the face of naïve transcoders.
Any occurrences of any characters in the ranges U+0001 to U+0008,
U+000E to U+001F, U+007F
to U+009F, U+FDD0
to U+FDEF, and characters U+000B, U+FFFE, U+FFFF, U+1FFFE, U+1FFFF,
U+2FFFE, U+2FFFF, U+3FFFE, U+3FFFF, U+4FFFE, U+4FFFF, U+5FFFE,
U+5FFFF, U+6FFFE, U+6FFFF, U+7FFFE, U+7FFFF, U+8FFFE, U+8FFFF,
U+9FFFE, U+9FFFF, U+AFFFE, U+AFFFF, U+BFFFE, U+BFFFF, U+CFFFE,
U+CFFFF, U+DFFFE, U+DFFFF, U+EFFFE, U+EFFFF, U+FFFFE, U+FFFFF,
U+10FFFE, and U+10FFFF are parse
errors. These are all control characters or permanently
undefined Unicode characters (noncharacters).
U+000D CARRIAGE RETURN (CR) characters and U+000A LINE FEED (LF)
characters are treated specially. Any CR characters that are
followed by LF characters must be removed, and any CR characters not
followed by LF characters must be converted to LF characters. Thus,
newlines in HTML DOMs are represented by LF characters, and there
are never any CR characters in the input to the
tokenization stage.
The next input character is the first character in the
input stream that has not yet been consumed. Initially,
the next input character is the first character in the
input. The current input character is the last character
to have been consumed.
The insertion point is the position (just before a
character or just before the end of the input stream) where content
inserted using document.write() is actually
inserted. The insertion point is relative to the position of the
character immediately after it, it is not an absolute offset into
the input stream. Initially, the insertion point is
undefined.
The "EOF" character in the tables below is a conceptual character
representing the end of the input stream. If the parser
is a script-created parser, then the end of the
input stream is reached when an explicit "EOF"
character (inserted by the document.close() method) is
consumed. Otherwise, the "EOF" character is not a real character in
the stream, but rather the lack of any further characters.
8.2.2.4 Changing the encoding while parsing
When the parser requires the user agent to change the
encoding, it must run the following steps. This might happen
if the encoding sniffing algorithm described above
failed to find an encoding, or if it found an encoding that was not
the actual encoding of the file.
- If the new encoding is identical or equivalent to the encoding
that is already being used to interpret the input stream, then set
the confidence to
certain and abort these steps. This happens when the
encoding information found in the file matches what the
encoding sniffing algorithm determined to be the
encoding, and in the second pass through the parser if the first
pass found that the encoding sniffing algorithm described in the
earlier section failed to find the right encoding.
- If the encoding that is already being used to interpret the
input stream is a UTF-16 encoding, then set the confidence to
certain and abort these steps. The new encoding is ignored;
if it was anything but the same encoding, then it would be clearly
incorrect.
- If the new encoding is a UTF-16 encoding, change it to
UTF-8.
- If all the bytes up to the last byte converted by the current
decoder have the same Unicode interpretations in both the current
encoding and the new encoding, and if the user agent supports
changing the converter on the fly, then the user agent may change
to the new converter for the encoding on the fly. Set the
document's character encoding and the encoding used to
convert the input stream to the new encoding, set the confidence to
certain, and abort these steps.
- Otherwise, navigate to the
document again, with replacement enabled, and using
the same source browsing context, but this time skip
the encoding sniffing algorithm and instead just set
the encoding to the new encoding and the confidence to
certain. Whenever possible, this should be done without
actually contacting the network layer (the bytes should be
re-parsed from memory), even if, e.g., the document is marked as
not being cacheable. If this is not possible and contacting the
network layer would involve repeating a request that uses a method
other than HTTP GET (or
equivalent for non-HTTP URLs), then instead set the confidence to
certain and ignore the new encoding. The resource will be
misinterpreted. User agents may notify the user of the situation,
to aid in application development.
8.2.3 Parse state
8.2.3.1 The insertion mode
The insertion mode is a state variable that controls
the primary operation of the tree construction stage.
Initially, the insertion mode is "initial". It can change to
"before html",
"before head",
"in head", "in head noscript",
"after head", "in body", "text", "in table", "in table text", "in caption", "in column group", "in table body", "in row", "in
cell", "in
select", "in
select in table", "after body", "in frameset", "after frameset", "after after body", and "after after
frameset" during the course of the parsing, as described in
the tree construction stage. The insertion mode affects
how tokens are processed and whether CDATA sections are
supported.
Several of these modes, namely "in head", "in
body", "in
table", and "in
select", are special, in that the other modes defer to them
at various times. When the algorithm below says that the user agent
is to do something "using the rules for the m insertion mode", where m is one
of these modes, the user agent must use the rules described under
the m insertion mode's section, but
must leave the insertion mode unchanged unless the
rules in m themselves switch the insertion
mode to a new value.
When the insertion mode is switched to "text" or "in table text", the original insertion mode
is also set. This is the insertion mode to which the tree
construction stage will return.
When the steps below require the UA to reset the insertion
mode appropriately, it means the UA must follow these
steps:
- Let last be false.
- Let node be the last node in the
stack of open elements.
- Loop: If node is the first node in
the stack of open elements, then set last to
true and set node to the context element.
(fragment case)
- If node is a
select element,
then switch the insertion mode to "in select" and abort these
steps. (fragment case)
- If node is a
td or
th element and last is false, then
switch the insertion mode to "in cell" and abort these steps.
- If node is a
tr element, then
switch the insertion mode to "in row" and abort these steps.
- If node is a
tbody,
thead, or tfoot element, then switch the
insertion mode to "in table body" and abort these steps.
- If node is a
caption element,
then switch the insertion mode to "in caption" and abort
these steps.
- If node is a
colgroup element,
then switch the insertion mode to "in column group" and
abort these steps. (fragment case)
- If node is a
table element,
then switch the insertion mode to "in table" and abort these
steps.
- If node is a
head element,
then switch the insertion mode to "in body" ("in body"! not "in head"!) and abort
these steps. (fragment case)
- If node is a
body element,
then switch the insertion mode to "in body" and abort these
steps.
- If node is a
frameset element,
then switch the insertion mode to "in frameset" and abort
these steps. (fragment case)
- If node is an
html element,
then switch the insertion mode
to "before
head" Then, abort these steps. (fragment
case)
- If last is true, then switch the
insertion mode to "in body" and abort these steps. (fragment
case)
- Let node now be the node before node in the stack of open
elements.
- Return to the step labeled loop.
8.2.3.2 The stack of open elements
Initially, the stack of open elements is empty. The
stack grows downwards; the topmost node on the stack is the first
one added to the stack, and the bottommost node of the stack is the
most recently added node in the stack (notwithstanding when the
stack is manipulated in a random access fashion as part of the handling for misnested tags).
The "before
html" insertion mode creates the
html root element node, which is then added to the
stack.
In the fragment case, the stack of open
elements is initialized to contain an html
element that is created as part of that algorithm. (The fragment
case skips the "before html" insertion mode.)
The html node, however it is created, is the topmost
node of the stack. It only gets popped off the stack when the parser
finishes.
The current node is the bottommost node in this
stack.
The current table is the last table
element in the stack of open elements, if there is
one. If there is no table element in the stack of
open elements (fragment case), then the
current table is the first element in the stack
of open elements (the html element).
Elements in the stack fall into the following categories:
- Special
The following elements have varying levels of special
parsing rules: HTML's address, applet,
area, article, aside,
base, basefont, bgsound,
blockquote, body, br,
button, caption, center,
col, colgroup, command,
dd, details, dir,
div, dl, dt,
embed, fieldset, figcaption,
figure, footer, form,
frame, frameset, h1,
h2, h3, h4, h5,
h6, head, header,
hgroup, hr, html,
iframe, img, input,
isindex, li, link,
listing, marquee, menu,
meta, nav, noembed,
noframes, noscript, object,
ol, p, param,
plaintext, pre, script,
section, select, style,
summary, table, tbody,
td, textarea, tfoot,
th, thead, title,
tr, ul, wbr, and
xmp; MathML's mi, mo, mn, ms, mtext, and annotation-xml; and SVG's foreignObject, desc, and
title.
- Formatting
The following HTML elements are those that end up in the
list of active formatting elements: a,
b, big, code,
em, font, i,
nobr, s, small,
strike, strong, tt, and
u.
- Ordinary
All other elements found while parsing an HTML
document.
The stack of open elements is said to have an element in a
specific scope consisting of a list of element types list when the following algorithm terminates in a
match state:
Initialize node to be the current
node (the bottommost node of the stack).
If node is the target node, terminate in
a match state.
Otherwise, if node is one of the element
types in list, terminate in a failure
state.
Otherwise, set node to the previous
entry in the stack of open elements and return to step
2. (This will never fail, since the loop will always terminate in
the previous step if the top of the stack — an
html element — is reached.)
The stack of open elements is said to have an element in scope when
it has an element in the specific scope consisting
of the following element types:
The stack of open elements is said to have an element in list
item scope when it has an element in the specific
scope consisting of the following element types:
The stack of open elements is said to have an element in button
scope when it has an element in the specific
scope consisting of the following element types:
The stack of open elements is said to have an element in table
scope when it has an element in the specific
scope consisting of the following element types:
The stack of open elements is said to have an element in select
scope when it has an element in the specific
scope consisting of all element types except the
following:
Nothing happens if at any time any of the elements in the
stack of open elements are moved to a new location in,
or removed from, the Document tree. In particular, the
stack is not changed in this situation. This can cause, amongst
other strange effects, content to be appended to nodes that are no
longer in the DOM.
In some cases (namely, when closing misnested formatting elements),
the stack is manipulated in a random-access fashion.
Initially, the list of active formatting elements is
empty. It is used to handle mis-nested formatting element tags.
The list contains elements in the formatting
category, and scope markers. The scope markers are inserted when
entering applet elements, buttons, object
elements, marquees, table cells, and table captions, and are used to
prevent formatting from "leaking" into applet
elements, buttons, object elements, marquees, and
tables.
The scope markers are unrelated to the concept of an
element being in
scope.
In addition, each element in the list of active formatting
elements is associated with the token for which it was
created, so that further elements can be created for that token if
necessary.
When the steps below require the UA to push onto the list of
active formatting elements an element element, the UA must perform the following steps:
If there are already three elements in the list of
active formatting elements after the last list marker, if
any, or anywhere in the list if there are no list markers, that
have the same tag name, namespace, and attributes as element, then remove the earliest such element from
the list of active formatting elements. For these
purposes, the attributes must be compared as they were when the
elements were created by the parser; two elements have the same
attributes if all their parsed attributes can be paired such that
the two attributes in each pair have identical names, namespaces,
and values (the order of the attributes does not matter).
This is the Noah's Ark clause. But with three per
family instead of two.
Add element to the list of active
formatting elements.
When the steps below require the UA to reconstruct the
active formatting elements, the UA must perform the following
steps:
- If there are no entries in the list of active formatting
elements, then there is nothing to reconstruct; stop this
algorithm.
- If the last (most recently added) entry in the list of
active formatting elements is a marker, or if it is an
element that is in the stack of open elements, then
there is nothing to reconstruct; stop this algorithm.
- Let entry be the last (most recently added)
element in the list of active formatting
elements.
- If there are no entries before entry in the
list of active formatting elements, then jump to step
8.
- Let entry be the entry one earlier than
entry in the list of active formatting
elements.
- If entry is neither a marker nor an element
that is also in the stack of open elements, go to step
4.
- Let entry be the element one later than
entry in the list of active formatting
elements.
- Create an element for the token for which the
element entry was created, to obtain new element.
- Append new element to the current
node and push it onto the stack of open
elements so that it is the new current
node.
- Replace the entry for entry in the list
with an entry for new element.
- If the entry for new element in the
list of active formatting elements is not the last
entry in the list, return to step 7.
This has the effect of reopening all the formatting elements that
were opened in the current body, cell, or caption (whichever is
youngest) that haven't been explicitly closed.
The way this specification is written, the
list of active formatting elements always consists of
elements in chronological order with the least recently added
element first and the most recently added element last (except for
while steps 8 to 11 of the above algorithm are being executed, of
course).
When the steps below require the UA to clear the list of
active formatting elements up to the last marker, the UA must
perform the following steps:
- Let entry be the last (most recently added)
entry in the list of active formatting elements.
- Remove entry from the list of active
formatting elements.
- If entry was a marker, then stop the
algorithm at this point. The list has been cleared up to the last
marker.
- Go to step 1.
8.2.3.4 The element pointers
Initially, the head element
pointer and the form element
pointer are both null.
Once a head element has been parsed (whether
implicitly or explicitly) the head
element pointer gets set to point to this node.
The form element pointer
points to the last form element that was opened and
whose end tag has not yet been seen. It is used to make form
controls associate with forms in the face of dramatically bad
markup, for historical reasons.
8.2.3.5 Other parsing state flags
The scripting flag is set to "enabled" if scripting was enabled for the
Document with which the parser is associated when the
parser was created, and "disabled" otherwise.
The scripting flag can be enabled even
when the parser was originally created for the HTML fragment
parsing algorithm, even though script elements
don't execute in that case.
The frameset-ok flag is set to "ok" when the parser is
created. It is set to "not ok" after certain tokens are seen.