figure elementlegend element followed by legend
element.HTMLElement .The figure element represents
some prose flow content ,
optionally with a caption. caption, which can
be moved away from the main flow of the document without affecting
the document's meaning.
The element can thus be used to annotate illustrations, diagrams, photos, code listings, etc, that are referred to from the main content of the document, but that could, without affecting the flow of the document, be moved away from that primary content, e.g. to the side of the page, to dedicated pages, or to an appendix.
The first legend element
child of the element, if any, represents the caption of the
figure element's contents. If
there is no child legend
element, then there is no caption.
The remainder of the element's contents, if any, represents the
captioned content.
This example shows the
figure element to
mark up a code listing.
<p>In <a href="#l4">listing 4</a> we see the primary core interface
API declaration.</p>
<figure id="l4">
<legend>Listing 4. The primary core interface API declaration.</legend>
<pre><code>interface PrimaryCore {
boolean verifyDataLine();
void sendData(in sequence<byte> data);
void initSelfDestruct();
}</code></pre>
</figure>
<p>
The
API
is
designed
to
use
UTF-8.</p>
Here we see a figure element to mark up a photo.
<figure>
<img src="bubbles-work.jpeg"
alt="Bubbles, sitting in his office chair, works on his
latest project intently.">
<legend>Bubbles at work</legend>
</figure>
In this example, we see an image that is not a figure, as well as an image and a video that are.
<h2>Malinko's comics</h2> <p>This case centered on some sort of "intellectual property" infringement related to a comic (see Exhibit A). The suit started after a trailer ending with these words:</p> <img src="promblem-packed-action.png" alt="ROUGH COPY! Promblem-Packed Action!"> <p>...was aired. A lawyer, armed with a Bigger Notebook, launched a preemptive strike using snowballs. A complete copy of the trailer is included with Exhibit B.</p> <figure> <img src="ex-a.png" alt="Two squiggles on a dirty piece of paper."> <legend>Exhibit A. The alleged <cite>rough copy</cite> comic.</legend> </figure> <figure> <video src="ex-b.mov"></video> <legend>Exhibit A. The alleged <cite>rough copy</cite> comic.</legend> </figure> <p> The case was resolved out of court.</p>
Here, a part of a poem is marked up
using figure .
<figure> <p>'Twas brillig, and the slithy toves<br> Did gyre and gimble in the wabe;<br> All mimsy were the borogoves,<br> And the mome raths outgrabe.</p> <legend><cite>Jabberwocky</cite> (first verse). Lewis Carroll, 1832-98</legend> </figure>
In this example, which could be part of a much larger work discussing a castle, the figure has three images in it.
<figure>
<img src="castle1423.jpeg" title="Etching. Anonymous, ca. 1423."
alt="The castle has one tower, and a tall wall around it.">
<img src="castle1858.jpeg" title="Oil-based paint on canvas. Maria Towle, 1858."
alt="The castle now has two towers and two walls.">
<img src="castle1999.jpeg" title="Film photograph. Peter Jankle, 1999."
alt="The castle lies in ruins, the original tower all that remains in one piece.">
<legend>The castle through the ages: 1423, 1858, and 1999 respectively.</legend>
</figure>
img elementaltsrcusemapismapwidthheightinterface HTMLImageElement : HTMLElement {
attribute DOMString alt;
attribute DOMString src;
attribute DOMString useMap;
attribute boolean isMap;
attribute long width;
attribute long height;
readonly attribute boolean complete;
};
An instance of HTMLImageElement can be obtained
using the Image constructor.
An img element represents an
image.
The image given by the src attribute is the embedded
content, and the value of the alt attribute is the
img element's fallback content .
Authoring requirements : The src attribute must be
present, and must contain a URI (or IRI).
Should we restrict the URI to pointing to an image? What's an image? Is PDF an image? (Safari supports PDFs in <img> elements.) How about SVG? (Opera supports those). WMFs? XPMs? HTML?
The requirements for the alt attribute depend on what the image is
intended to represent:
Sometimes something can be more clearly stated in graphical
form, for example as a flowchart, a diagram, a graph, or a simple
map showing directions. In such cases, an image can be given using
the img element, but the lesser
textual version must still be given, so that users who are unable
to view the image (e.g. because they have a very slow connection,
or because they are using a text-only browser, or because they are
listening to the page being read out by a hands-free automobile
voice Web browser, or simply because they are blind) are still able
to understand the message being conveyed.
The text must be given in the alt attribute, and must
convey the same message as the the
image specified in the src attribute.
In the following example we have a flowchart in image form,
with text in the alt attribute rephrasing the flowchart in prose
form:
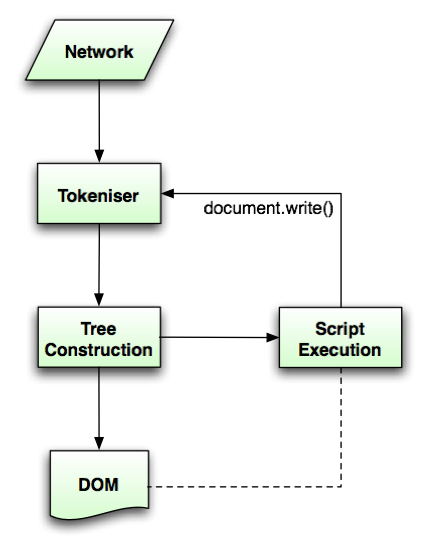
<p>In the common case, the data handled by the tokenisation stage comes from the network, but it can also come from script.</p> <p><img src="images/parsing-model-overview.png" alt="The network passes data to the Tokeniser stage, which passes data to the Tree Construction stage. From there, data goes to both the DOM and to Script Execution. Script Execution is linked to the DOM, and, using document.write(), passes data to the Tokeniser."> </p>
Here's another example, showing a good solution and a bad solution to the problem of including an image in a description.
First, here's the good solution. This sample shows how the alternative text should just be what you would have put in the prose if the image had never existed.
<!-- This is the correct way to do things. --> <p> You are standing in an open field west of a house. <img src="house.jpeg" alt="The house is white, with a boarded front door."> There is a small mailbox here. </p>
Second, here's the bad solution. In this incorrect way of doing things, the alternative text is simply a description of the image, instead of a textual replacement for the image. It's bad because when the image isn't shown, the text doesn't flow as well as in the first example.
<!-- This is the wrong way to do things. --> <p> You are standing in an open field west of a house. <img src="house.jpeg" alt="A white house, with a boarded front door."> There is a small mailbox here. </p>
It is important to realise
realize that the alternative text is a
replacement for the image, not a description of the
image.
A document can contain information in iconic form. The icon is
intended to help users of visual browsers to recognise recognize
features at a glance.
In some cases, the icon is supplemental to a text label
conveying the same meaning. In those cases, the alt attribute must be
present but must be empty.
Here the icons are next to text that conveys the same meaning,
so they have an empty alt attribute:
<nav> <p><a href="/help/"><img src="/icons/help.png" alt=""> Help</a></p> <p><a href="/configure/"><img src="/icons/configuration.png" alt=""> Configuration Tools</a></p> </nav>
In other cases, the icon has no text next to it describing what
it means; the icon is supposed to be self-explanatory. In those
cases, an equivalent textual label must be given in the
alt
attribute.
Here, posts on a news site are labelled labeled with
an icon indicating their topic.
<body> <article> <header> <h1>Ratatouille wins <i>Best Movie of the Year</i> award</h1> <p><img src="movies.png" alt="Movies"></p> </header> <p>Pixar has won yet another <i>Best Movie of the Year</i> award, making this its 8th win in the last 12 years.</p> </article> <article> <header> <h1>Latest TWiT episode is online</h1> <p><img src="podcasts.png" alt="Podcasts"></p> </header> <p>The latest TWiT episode has been posted, in which we hear several tech news stories as well as learning much more about the iPhone. This week, the panelists compare how reflective their iPhones' Apple logos are.</p> </article> </body>
Many pages include logos, insignia, flags, or emblems, which
stand for a particular entity such as a company, organisation, organization, project, band, software package,
country, or some such.
If the logo is being used to represent the entity, the
alt attribute
must contain the name of the entity being represented by the logo.
The alt
attribute must not contain text like the word "logo", as
it is not the fact that it is a logo that is being conveyed, it's
the entity itself.
If the logo is being used next to the name of the entity that it
represents, then the logo is supplemental, and its alt attribute must instead
be empty.
If the logo is merely used as decorative material (as branding, or, for example, as a side image in an article that mentions the entity to which the logo belongs), then the entry below on purely decorative images applies. If the logo is actually being discussed, then it is being used as a phrase or paragraph (the description of the logo) with an alternative graphical representation (the logo itself), and the first entry above applies.
In the following snippets, all four of the above cases are present. First, we see a logo used to represent a company:
<h1> <img src="XYZ.gif" alt="The XYZ company"> </h1>
Next, we see a paragraph which uses a logo right next to the company name, and so doesn't have any alternative text:
<article> <h2>News</h2> <p>We have recently been looking at buying the <img src="alpha.gif" alt=""> ΑΒΓ company, a small Greek companyspecialisingspecializing in our type of product.</p>
In this third snippet, we have a logo being used in an aside, as part of the larger article discussing the acquisition:
<aside><p><img src="alpha-large.gif" alt=""></p></aside> <p>The ΑΒΓ company has had a good quarter, and our pie chart studies of their accounts suggest a much bigger blue slice than its green and orange slices, which is always a good sign.</p> </article>
Finally, we have an opinion piece talking about a logo, and the logo is therefore described in detail in the alternative text.
<p>Consider for a moment their logo:</p> <p><img src="/images/logo" alt="It consists of a green circle with a green question mark centered inside it."></p> <p>How unoriginal can you get? I mean, oooooh, a question mark, how <em>revolutionary</em>, how utterly <em>ground-breaking</em>, I'm sure everyone will rush to adopt those specifications now! They could at least have tried for some sort of, I don't know, sequence of rounded squares with varying shades of green and bold white outlines, at least that would look good on the cover of a blue book.</p>
This example shows how the alternative text should be written such that if the image isn't available, and the text is used instead, the text flows seamlessly into the surrounding text, as if the image had never been there in the first place.
In many cases, the image is actually just supplementary, and its
presence merely reinforces the surrounding text. In these cases,
the alt
attribute must be present but its value must be the empty
string.
A flowchart that repeats the previous paragraph in graphical form:
<p>The network passes data to the Tokeniser stage, which passes data to the Tree Construction stage. From there, data goes to both the DOM and to Script Execution. Script Execution is linked to the DOM, and, using document.write(), passes data to the Tokeniser.</p> <p> <img src="images/parsing-model-overview.png" alt=""> </p>
A graph that repeats the previous paragraph in graphical form:
<p>According to a study covering several billion pages, about 62% of documents on the Web in 2007 triggered the Quirks rendering mode of Web browsers, about 30% triggered the Almost Standards mode, and about 9% triggered the Standards mode.</p> <p> <img src="rendering-mode-pie-chart.png" alt=""> </p>
In general, an image falls into this category if removing the image doesn't make the page any less useful, but including the image makes it a lot easier for users of visual browsers to understand the concept.
In some cases, the image isn't discussed by the surrounding
text, but it has some relevance. Such images are decorative, but
still form part of the content. In these cases, the alt attribute must be
present but its value must be the empty string.
Examples where the image is purely decorative despite being relevant would include things like a photo of the Black Rock City landscape in a blog post about an event at Burning Man, or an image of a painting inspired by a poem, on a page reciting that poem. The following snippet shows an example of the latter case (only the first verse is included in this snippet):
<h1>The Lady of Shalott</h1> <p><img src="shalott.jpeg" alt=""></p> <p>On either side the river lie<br> Long fields of barley and of rye,<br> That clothe the wold and meet the sky;<br> And through the field the road run by<br> To many-tower'd Camelot;<br> And up and down the people go,<br> Gazing where the lilies blow<br> Round an island there below,<br> The island of Shalott.</p>
In general, if an image is decorative but isn't especially page-specific, for example an image that forms part of a site-wide design scheme, the image should be specified in the site's CSS, not in the markup of the document.
In certain rare some cases, the image is simply a critical part of the content, and content. This
could be the case, for instance, on a page that is part of a photo
gallery. The image is the whole point of the page
containing it.
When it is possible for alternative text
to be provided, for example if the image is part of a series of
screenshots in a magazine review, or part of a comic strip, or is a
photograph in a blog entry about that photograph, text that conveys
can serve as a substitute for the image must be given as the
contents of the alt attribute.
In a rare subset of these cases,
there might even be no alternative text
available. This could be the case, for instance, in on a photo
gallery, where a user upload site, if the site has uploaded 3000 received
8000 photos from a vacation trip,
user without providing any descriptions of the images. The images are the whole point user annotating any of the
pages containing them. In such cases, the alt attribute may be
omitted, but the alt attribute should be included, with a useful
value, if at all possible. If
In any case, if an image is a key
part of the content, the alt attribute must not be specified with an empty
value.
A photo on a photo-sharing site:
<legend>Bubbles traveled everywhere with us.</legend>
</figure> A screenshot in a gallery of screenshots for
a new OS: OS,
with some alternative text:
<figure><img src="KDE%20Light%20desktop.png" alt="The desktop is blue, with icons along the left hand side in two columns, reading System, Home, K-Mail, etc. A window is open showing that menus wrap to a second line if they cannot fit in the window. The window has a list of icons along the top, with an address bar below it, a list of icons for tabs along the left edge, a status bar on the bottom, and two panes in the middle. The desktop has a bar at the bottom of the screen with a few buttons, a pager, a list of open applications, and a clock."> <legend>Screenshot of a KDE desktop.</legend> </figure>
A photo on a photo-sharing site, if the site received the image with no metadata other than the caption:
<figure> <img src="1100670787_6a7c664aef.jpg"> <legend>Bubbles traveled everywhere with us.</legend> </figure>
In both cases, this case, though, it would be better if a
detailed description of the important parts of the image
were included. obtained from the user and included on the
page.
Sometimes there simply is no text that can do justice to an image. For example, there is little that can be said to usefully describe a Rorschach inkblot test.
<figure> <img src="/commons/a/a7/Rorschach1.jpg"> <legend>A black outline of the first of the ten cards in the Rorschach inkblot test.</legend> </figure>
Note that the following would be a very bad use of alternative text:
<!-- This example is wrong. Do not copy it. --> <figure> <img src="/commons/a/a7/Rorschach1.jpg" alt="A black outline of the first of the ten cards in the Rorschach inkblot test."> <legend>A black outline of the first of the ten cards in the Rorschach inkblot test.</legend> </figure>
Including the caption in the alternative text like this isn't useful because it effectively duplicates the caption for users who don't have images, taunting them twice yet not helping them any more than if they had only read or heard the caption once.
Since some users cannot use images at all (e.g.
because they have a very slow connection, or because they are using
a text-only browser, or because they are listening to the page
being read out by a hands-free automobile voice Web browser, or
simply because they are blind), the alt attribute should is only
allowed to be omitted when no
alternative text is available and none can be made available, e.g.
on automated image gallery sites.
When an image is included in a communication (such as an HTML
e-mail) aimed at someone who is known to be able to view images,
the alt
attribute may be omitted. However, even in such cases it is
stongly strongly recommended that alternative text be
included (as appropriate according to the kind of image involved,
as described in the above entries), so that the e-mail is still
usable should the user use a mail client that does not support
images, or should the e-mail be forwarded on to other users whose
abilities might not include easily seeing images.
The img must not be used as a
layout tool. In particular, img
elements should not be used to display fully transparent images, as
they rarely convey meaning and rarely add anything useful to the
document.
There has been some suggestion that the
longdesc attribute from HTML4, or some other
mechanism that is more powerful than alt="" ,
should be included. This has not yet been considered.
User agent requirements : When the alt attribute is present
and its value is the empty string, the image supplements the
surrounding content. In such cases, the image may be omitted
without affecting the meaning of the document.
When the alt attribute is present and its value is not the
empty string, the image is a graphical equivalent of the string
given in the alt attribute. In such cases, the image may be
replaced in the rendering by the string given in the attribute
without significantly affecting the meaning of the document.
When the alt attribute is missing, the image represents a
key part of the content. Non-visual user agents should apply image
analysis heuristics to help the user make sense of the image.
The alt
attribute does not represent advisory information. User agents must
not present the contents of the alt attribute in the same way as content of the
title
attribute.
If the src
attribute is omitted, the image represents whatever string is given
by the element's alt attribute, if any, or nothing, if that
attribute is empty or absent.
When the The src attribute is set,
attribute, on setting, must cause the
user agent must to immediately begin to download the specified
resource , unless the user agent cannot support images, or its
support for images has been disabled.
The download of the image must delay the
load event .
This, unfortunately, can be used to perform a rudimentary port scan of the user's local network (especially in conjunction with scripting, though scripting isn't actually necessary to carry out such an attack). User agents may implement cross-origin access control policies that mitigate this attack.
Once the download has completed, if the image is a valid image,
the user agent must fire a load event on the img element.
element (this happens after
complete starts
returning true). If the download fails or it completes but
the image is not a valid or supported image, the user agent must
fire an error
event on the img element.
The remote server's response metadata (e.g. an HTTP 404 status code, or associated Content-Type headers ) must be ignored when determining whether the resource obtained is a valid image or not.
This allows servers to return images with error responses.
User agents must not support non-image resources with the
img element.
The usemap attribute, if present, can indicate
that the image has an associated image map
.
The ismap attribute, when used on
an element that is a descendant of an a element with an href attribute,
indicates by its presence that the element provides access to a
server-side image map. This affects how events are handled on the
corresponding a element.
The ismap attribute is a boolean attribute . The attribute must not be
specified on an element that does not have an ancestor
a element with an href
attribute.
The img element supports
dimension attributes .
The DOM attributes alt , src , useMap , and isMap each must reflect the respective content attributes of the
same name.
The DOM attributes height and width must return the
rendered height and width of the image, in CSS pixels, if the image
is being rendered, and is being rendered to a visual medium, or 0
otherwise. [CSS21]
The DOM attribute complete must return true if
the user agent has downloaded the image specified in the
src attribute,
and it is a valid image, and false otherwise.
The value of
complete can
change while a script is executing.
A single image can have different appropriate alternative text depending on the context.
In each of the following cases, the same
image is used, yet the alt text is different each time. The image is the coat of
arms of the Canton Geneva in Switzerland.
Here it is used as a supplementary icon:
<p> I lived in <img src="carouge.svg" alt=""> Carouge.</p>
Here it is used as an icon representing the town:
<p> Home town: <img src="carouge.svg" alt="Carouge"> </p>
Here it is used as part of a text on the town:
<p>Carouge has a coat of arms.</p> <p><img src="carouge.svg" alt="The coat of arms depicts a lion, sitting in front of a tree."></p> <p> It is used as decoration all over the town.</p>
Here it is used as a way to support a similar text where the description is given as well as, instead of as an alternative to, the image:
<p>Carouge has a coat of arms.</p> <p><img src="carouge.svg" alt=""></p> <p>The coat of arms depicts a lion, sitting in front of a tree. It is used as decoration all over the town.</p>
Here it is used as part of a story:
<p>He picked up the folder and a piece of paper fell out.</p> <p><img src="carouge.svg" alt="Shaped like a shield, the paper had a red background, a green tree, and a yellow lion with its tongue hanging out and whose tail was shaped like an S."></p> <p>He stared at the folder. S! The answer he had been looking for all this time was simply the letter S! How had he not seen that before? It all came together now. The phone call where Hector had referred to a lion's tail, the time Marco had stuck his tongue out...</p>
Here are some more examples showing the same picture used in different contexts, with different appropriate alternate texts each time.
<article> <h1>My cats</h1> <h2>Fluffy</h2> <p>Fluffy is my favourite.</p> <img src="fluffy.jpg" alt="She likes playing with a ball of yarn."> <p>She's just too cute.</p> <h2>Miles</h2> <p>My other cat, Miles just eats and sleeps.</p> </article>
<article> <h1>Photography</h1> <h2>Shooting moving targets indoors</h2> <p>The trick here is to know how to anticipate; to know at what speed and what distance the subject will pass by.</p> <img src="fluffy.jpg" alt="A cat flying by, chasing a ball of yarn, can be photographed quite nicely using this technique."> <h2>Nature by night</h2> <p>To achieve this, you'll need either an extremely sensitive film, or immense flash lights.</p> </article>
<article> <h1>About me</h1> <h2>My pets</h2> <p>I've got a cat named Fluffy and a dog named Miles.</p> <img src="fluffy.jpg" alt="Fluffy, my cat, tends to keep itself busy."> <p>My dog Miles and I like go on long walks together.</p> <h2>music</h2> <p>After our walks, having emptied my mind, I like listening to Bach.</p> </article>
<article> <h1>Fluffy and the Yarn</h1> <p>Fluffy was a cat who liked to play with yarn. He also liked to jump.</p> <aside><img src="fluffy.jpg" alt="" title="Fluffy"></aside> <p>He would play in the morning, he would play in the evening.</p> </article>
iframe elementsrcnamesandboxseamlesswidthheightinterface HTMLIFrameElement : HTMLElement {
attribute DOMString src;
attribute DOMString name;
attribute DOMString sandbox;
attribute boolean seamless;
attribute long width;
attribute long height;
};
Objects implementing the HTMLIFrameElement interface must
also implement the EmbeddingElement interface defined
in the Window Object specification. [WINDOW]
The iframe element introduces
a new nested browsing context .
The src attribute, if present,
must be a URI (or IRI) to a page that the nested browsing context is to contain. When the browsing
context is created, if the attribute is present, the user agent
must navigate this browsing context to the
given URI, with replacement enabled ,
and with the iframe element's document's browsing context
as the source browsing context . If the user navigates away from this page, the
iframe 's corresponding
Window object will reference new
Document objects, but the src attribute will not
change.
Whenever the src attribute is set, the nested browsing context must be navigated to the given URI. URI, with the
iframe element's
document's browsing context as
the source browsing
context .
If the src attribute is not set when the element is
created, the browsing context will remain at the initial
about:blank page.
The name attribute,
if present, must be a valid browsing context name .When the browsing context is created, if the attribute
is present, the browsing context name must be set to the value of this attribute; otherwise,
the browsing
context name must be set to the
empty string.
Whenever the name attribute is
set, the nested browsing context 's name
must be changed to the new value. If the
attribute is removed, the browsing context name must be set to the empty string.
When content loads in an iframe , after any load events are fired
within the content itself, the user agent must fire a load event at
the iframe element. When content
fails to load (e.g. due to a network error), then the user agent
must fire an error event at the element instead.
When there is an active parser in the iframe , and when anything in the
iframe that is delaying the load event in the iframe 's browsing
context , the iframe must
delay the load
event .
If, during the handling of the load event, the browsing context in the iframe is again navigated , that will further delay the load event
.
The sandbox attribute, when specified, enables a set of extra
restrictions on any content hosted by the iframe
.Its value must be an unordered set of unique
space-separated tokens .The allowed
values are allow-same-origin ,allow-forms
,and allow-scripts .
While the sandbox attribute
is specified, the iframe element's nested browsing context ,and all the browsing contexts nested within it (either
directly or indirectly through other nested browsing contexts) must
have the following flags set:
This flag prevents content from navigating browsing contexts other than the sandboxed browsing context itself (or browsing contexts further nested inside it).
This flag also prevents content from
creating new auxiliary browsing contexts ,e.g. using the target attribute
or the window.open() method.
This flag prevents content from
instantiating plugins ,whether
using the embed
element ,the
object element ,the
applet element ,or
through navigation of a
nested browsing
context .
This flag prevents content from showing notifications outside of the nested browsing context .
sandbox attribute's value, when split on
spaces ,is found to have the
allow-same-origin keyword setThis flag forces content into a unique origin for the purposes of the same-origin policy .
This flag also prevents script from
reading the document.cookies DOM
attribute .
The allow-same-origin attribute is intended for two cases.
First, it can be used to allow content from the same site to be sandboxed to disable scripting, while still allowing access to the DOM of the sandboxed content.
Second, it can be used to embed content from a third-party site, sandboxed to prevent that site from opening popup windows, etc, without preventing the embedded page from communicating back to its originating site, using the database APIs to store data, etc.
sandbox attribute's value, when split on
spaces ,is found to have the
allow-forms keyword setThis flag blocks form submission .
sandbox attribute's value, when split on
spaces ,is found to have the
allow-scripts keyword setThis flag blocks script execution .
These flags must not be set unless the conditions listed above define them as being set.
In this example, some completely-unknown, potentially hostile, user-provided HTML content is embedded in a page. Because it is sandboxed, it is treated by the user agent as being from a unique origin, despite the content being served from the same site. Thus it is affected by all the normal cross-site restrictions. In addition, the embedded page has scripting disabled, plugins disabled, forms disabled, and it cannot navigate any frames or windows other than itself (or any frames or windows it itself embeds).
<p>We're not scared of you! Here is your content, unedited:</p> <iframe sandbox src="getusercontent.cgi?id=12193"> </iframe>
Note that cookies are still send to the
server in the getusercontent.cgi request, though they are not visible in the
document.cookies DOM
attribute.
In this example, a gadget from another site is embedded. The gadget has scripting and forms enabled, and the origin sandbox restrictions are lifted, allowing the gadget to communicate with its originating server. The sandbox is still useful, however, as it disables plugins and popups, thus reducing the risk of the user being exposed to malware and other annoyances.
<iframe sandbox="allow-same-origin allow-forms allow-scripts" src="http://maps.example.com/embedded.html"> </iframe>
The seamless attribute is a boolean attribute. When specified, it
indicates that the iframe element's browsing context is to
be rendered in a manner that makes it appear to be part of the
containing document (seamlessly included in the parent document).
Specifically, when the attribute is set on an element and while
the browsing
context 's active document
has the same origin
as the iframe element's document, or the browsing context
's active document 's
URI has
the same
origin as the iframe element's document, the following requirements
apply:
The user agent must set the seamless browsing context flag to true for that browsing context .This will cause links to open in the parent browsing context .
In a CSS-supporting user agent: the user
agent must add all the style sheets that apply to the
iframe element to
the cascade of the active document of
the iframe element's nested browsing context ,at the appropriate cascade levels, before any style
sheets specified by the document itself.
In a CSS-supporting user agent: the user
agent must, for the purpose of CSS property inheritance only, treat
the root element of the active document of
the iframe element's nested browsing context as being a child of the iframe element. (Thus inherited properties on the root element
of the document in the iframe will
inherit the computed values of those properties on the
iframe element
instead of taking their initial values.)
In visual media, in a CSS-supporting user
agent: the user agent should set the intrinsic width of the
iframe to the
width that the element would have if it was a non-replaced
block-level element with 'width: auto'.
In visual media, in a CSS-supporting user
agent: the user agent should set the intrinsic height of the
iframe to the
height of the bounding box around the content rendered in the
iframe at its
current width.
In visual media, in a CSS-supporting user
agent: the user agent must force the height of the initial
containing block of the active document of
the nested browsing
context of the iframe to zero.
This is intended to get around the otherwise circular dependency of percentage dimensions that depend on the height of the containing block, thus affecting the height of the document's bounding box, thus affecting the height of the viewport, thus affecting the size of the initial containing block.
In speech media, the user agent should render the nested browsing context without announcing that it is a separate document.
User agents should, in general, act as if
the active
document of the
iframe 's
nested browsing
context was part of the document
that the iframe is
in.
For example if the user agent supports listing all the links in a document, links in "seamlessly" nested documents would be included in that list without being significantly distinguished from links in the document itself.
Parts of the above might get moved into the rendering section at some point.
If the attribute is not specified, or if the origin conditions listed above are not met, then the user agent should render the nested browsing context in a manner that is clearly distinguishable as a separate browsing context ,and the seamless browsing context flag must be set to false for that browsing context .
It is important that user
agents recheck the above conditions whenever the active document
of the nested browsing context of the iframe changes,
such that the seamless browsing context flag gets unset if the nested browsing context is navigated to another origin.
In this example, the site's navigation is
embedded using a client-side include using an iframe
.Any links in the iframe will, in new user agents, be automatically opened in
the iframe 's parent
browsing context; for legacy user agents, the site could also
include a base element with
a target attribute with the value _parent .Similarly, in new user agents the styles of the parent
page will be automatically applied to the contents of the frame,
but to support legacy user agents authors might wish to include the
styles explicitly.
<nav> <iframe seamless src="nav.include.html"> </iframe> </nav>
The iframe element supports dimension attributes for
cases where the embedded content has specific dimensions (e.g. ad
units have well-defined dimensions).
An iframe element never has
fallback content , as it will always create
a nested browsing context , regardless of
whether the specified initial contents are successfully used.
Descendants of iframe
elements represent nothing. (In legacy user agents that do not
support iframe elements, the
contents would be parsed as markup that could act as fallback
content.)
The content model of iframe
elements is text, except that the text must be such that
... ... anyone
have any bright ideas?
The HTML parser treats markup
inside iframe elements as
text.
The DOM attribute attributes src , name ,sandbox ,and seamless must reflect the content attribute attributes
of the same name.
embed elementsrctypewidthheightinterface HTMLEmbedElement : HTMLElement {
attribute DOMString src;
attribute DOMString type;
attribute long ;
attribute long width;
attribute long height;
};
Depending on the type of content instantiated by the
embed element, the node may also
support other interfaces.
The embed element represents
an integration point for an external (typically non-HTML)
application or interactive content.
The src
attribute gives the address of the resource being embedded. The
attribute must be present and contain a URI (or IRI).
If the src attribute is missing, then the
embed element must be ignored. ignored (it
represents nothing).
If the
sandboxed plugins
browsing context flag is set on
the browsing
context for which the
embed
element's document is the active document
,then the user agent must render the
embed
element in a manner that conveys that
the plugin
was disabled. The user agent may offer the
user the option to override the sandbox and instantiate the
plugin
anyway; if the user invokes such an option,
the user agent must act as if the sandboxed plugins browsing
context flag was not set for the
purposes of this element.
Plugins are disabled in sandboxed browsing contexts because they might not honor the restrictions imposed by the sandbox (e.g. they might allow scripting even when scripting in the sandbox is disabled). User agents should convey the danger of overriding the sandbox to the user if an option to do so is provided.
Otherwise, the src attribute is
present, and the element is not in a sandboxed browsing
context:
When the src attribute is set, user agents are expected
to find an appropriate handler plugin for the specified
resource, based on the content's type , and hand that handler plugin the content of the resource. If the
handler plugin supports a scriptable interface, the
HTMLEmbedElement
object representing the element should expose that interfaces.
The download of the resource must delay the
load event .
The user agent should pass the names and values of all the
attributes of the embed element
that have no namespace to the handler
plugin used. Any
(namespace-less) attribute may be specified on the embed element. This
specification does not define a mechanism for interacting with
third-party handlers, as it is expected to be user-agent-specific.
Some UAs might opt to support a plugin mechanism such as the
Netscape Plugin API; others may use remote content convertors or
have built-in support for certain types. [NPAPI]
The embed element has no
fallback content . If the user agent can't
display the specified resource, e.g. because the given type is not
supported, then the user agent must use a default handler plugin for the
content. (This default could be as simple as saying "Unsupported
Format", of course.)
The type attribute, if present,
gives the MIME type of the linked resource. The value must be a
valid MIME type, optionally with parameters. [RFC2046]
The type of the content being embedded is defined as follows:
type attribute, then the value of the
type
attribute is the content's type .Should we instead say that the
content-sniffing that we're going to
define used for top-level
browsing contexts should apply here?
Should we require the type attribute to match the server information?
We should say that 404s, etc, don't affect whether the resource is used or not. Not sure how to say it here though.
Browsers should take extreme care when
interacting with external content intended for third-party
renderers. When third-party software is run with the same
privileges as the user agent itself, vulnerabilities in the
third-party software become as dangerous as those in the user
agent. The embed element
supports dimension attributes .
The DOM attributes src and type each must reflect the respective content attributes of the
same name.
object elementparam elements,
then, transparent .datatypenameusemapwidthheightinterface HTMLObjectElement : HTMLElement {
attribute DOMString data;
attribute DOMString type;
attribute DOMString name;
attribute DOMString useMap;
attribute long ;
attribute long width;
attribute long height;
};
Objects implementing the HTMLObjectElement interface must
also implement the EmbeddingElement interface defined
in the Window Object specification. [WINDOW]
Depending on the type of content instantiated by the
object element, the node may
also support other interfaces.
The object element can
represent an external resource, which, depending on the type of the
resource, will either be treated as an image, as a nested browsing context , or as an external resource to
be processed by a third-party software
package. plugin .
The data attribute, if present,
specifies the address of the resource. If present, the attribute
must be a URI (or IRI).
The type attribute, if present,
specifies the type of the resource. If present, the attribute must
be a valid MIME type, optionally with parameters. [RFC2046]
One or both of the data and type attributes must be present.
Whenever The name attribute,
if present, must be a valid browsing context name .
When the element is created, and
subsequently whenever the classid
attribute changes, or, if the
classid attribute is
not present, whenever the data attribute
changes, or, if neither classid
attribute nor the data attribute
is not are
present, whenever the type attribute changes, the user agent must run
the following steps to determine what the object element represents:
If the classid attribute is
present, and has a value that isn't the empty string, then: if the
user agent can find a plugin suitable
according to the value of the classid
attribute, and plugins aren't being
sandboxed ,then that plugin should be used
,and the value of the data attribute,
if any, should be passed to the plugin .If no
suitable plugin can be found, or
if the plugin reports an error,
jump to the last step in the overall set of steps
(fallback).
If the data attribute is
present, then:
If the type attribute is
present and its value is not a type that the user agent supports,
and is not a type that the user agent can find a plugin for, then the user agent may jump to the last step in
the overall set of steps (fallback) without downloading the content
to examine its real type.
Begin a load for the resource.
The download of the resource must delay the
load event .
If the resource is not yet available (e.g. because the resource
was not available in the cache, so that loading the resource
required making a request over the network), then jump to
the last step 3 in the overall set of steps (fallback). When the
resource becomes available, or if the load fails, restart this
algorithm from this step. Resources can load incrementally; user
agents may opt to consider a resource "available" whenever enough
data has been obtained to begin processing the resource.
If the load failed (e.g. an HTTP 404
error, a DNS error), fire an error event at the element, then jump to
the last step 3 in the overall set of steps (fallback).
Determine the resource type , , as follows:
Let the same
mechanism as for browsing contexts? resource type be
unknown.
If the resource has associated Content-Type metadata The , then let the
resource type is be the type
specified in the
resource's Content-Type metadata . Otherwise, if
If the resource type is
unknown or " application/octet-stream " and there is a type attribute
is present The on the
object element,
then change the resource type is
to instead be the type specified in
the that
type
attribute. Otherwise, there is no explicit
type information The
If the resource type is still
unknown, then change the resource type to
instead be the sniffed type of the resource . .
Handle the content as given by the first of the following cases that matches:
The user agent should find an appropriate handler for the specified resource,
based on the resource type found in the previous step,
use that plugin and pass the
content of the resource to that handler. plugin . If the handler
supports a scriptable interface, the HTMLObjectElement
plugin
object representing the element should expose
that interface. The handler is not a nested browsing context . If
no appropriate handler can be found, reports an error, then jump to the last step 3 in the
overall set of steps (fallback).
image/ "The object element must be
associated with a nested browsing context
, if it does not already have one. The element's nested browsing context must then be navigated to the given resource, with replacement enabled , and
with the object element's
document's browsing context as
the source browsing
context . (The data attribute of the object element doesn't get updated if the
browsing context gets further navigated to other locations.)
If the name attribute is
present, the browsing context name must be set to the value of this attribute; otherwise,
the browsing
context name must be set to the
empty string.
navigation might end up treating it as something else, because it can do sniffing. how should we handle that?
image/ ", and support for images has not been
disabledApply the image sniffing rules to determine the type of the image.
The object element represents
the specified image. The image is not a nested browsing context .
If the image-sniffing stuff here? image cannot be rendered, e.g. because it is malformed
or in an unsupported format, jump to the last step in the overall
set of steps (fallback).
The object element represents the
specified image, but the image cannot be shown. given resource
type is not supported. Jump
to the last step 3 below in the overall set of steps
(fallback).
The element's contents are not part of what the object element represents.
Once the resource is completely loaded, fire
a load event at the
element.
If the data attribute is absent but the type attribute is
present, plugins aren't being sandboxed , and
if the user agent can find a
handler plugin suitable according to the value of the
type
attribute, then that handler should be used.
If the handler supports a scriptable interface, the
HTMLObjectElement plugin object
representing the element should
expose that interface. The handler is not a
nested browsing context be
used . If no suitable handler
plugin can be
found, or if the plugin reports an error, jump to the next step
(fallback).
(Fallback.) The object
element doesn't represent anything
except represents what the
element's contents represent, ignoring any leading param element children. This is the element's
fallback content .
When the
absence of other factors (such as style
sheets), user agents must show algorithm above instantiates a plugin , the user
what agent should
pass the names and values of all the parameters given
by param elements
that are children of the object element represents. Thus, to
the plugin
used. If the plugin supports a scriptable interface, the
HTMLObjectElement object representing the element should expose that
interface. The plugin is not a
nested browsing
context .
If the
sandboxed plugins
browsing context flag is set on
the browsing
context for which the
object element's
document is the active document ,then
the steps above must always act as if they had failed to find
a plugin
,even if one would otherwise have been
used.
Due to the algorithm above, the
contents of object elements act
as fallback content , to be used only when referenced resources can't be
shown (e.g. because it returned a 404 error). This allows multiple
object elements to be nested
inside each other, targeting multiple user agents with different
capabilities, with the user agent picking the best first one it
supports.
Whenever the name attribute is
set, if the object element
has a nested browsing context ,its name
must be changed to the new value. If the
attribute is removed, if the object element has a browsing context ,the browsing context name must be set to the empty string.
The usemap attribute, if present while the
object element represents an
image, can indicate that the object has an associated image map . The attribute must be ignored if the
object element doesn't represent
an image.
The object element supports
dimension attributes .
The DOM attributes data , type , name , and useMap each must reflect the respective content attributes of the
same name.
In the following example, a Java applet is
embedded in a page using the object element. (Generally speaking, it is better to avoid
using applets like these and instead use native JavaScript and HTML
to provide the functionality, since that way the application will
work on all Web browsers without requiring a third-party plugin.
Many devices, especially embedded devices, do not support
third-party technologies like Java.)
<figure> <object type="application/x-java-applet"> <param name="code" value="MyJavaClass"> <p>You do not have Java available, or it is disabled.</p> </object> <legend>My Java Clock</legend> </figure>
In this example, an HTML page is embedded
in another using the object element.
<figure> <object data="clock.html"></object> <legend>My HTML Clock</legend> </figure>
param elementobject
element, before any namevalueinterface HTMLParamElement : HTMLElement {
attribute DOMString ;
attribute DOMString name;
attribute DOMString value;
};
The param element defines
parameters for handlers plugins invoked by object elements.
The name attribute gives the name
of the parameter.
The value attribute gives the
value of the parameter.
Both attributes must be present. They may have any value.
If both attributes are present, and if the parent element of the
param is an object element, then the element defines a
parameter with the given
name/value pair.
The DOM attributes name and value must both reflect the respective content attributes of the
same name.
{kind=link}