Presentation markup and content markup can be combined in three ways. The first method, known as mixed markup is to intersperse content and presentation elements in what is essentially a single tree. The second method, known as parallel markup is to provide both explicit presentation markup and explicit content markup in a pair of trees. The third method is to provide notation elements as is done in Section 8.6 Rendering of Content Elements which enable processors to render content markup to presentation markup. This chapter describes how to use the first two methods to combine content and presentation markup, and how they may be used in conjunction with style sheets and other tools. Please refer to Section 8.6 Rendering of Content Elements for the specification of notation documents.
5.1 Motivation
Chapters 3 and 4 describe two kinds of markup that encode mathematical material in documents.
Presentation markup encodes the notational structure of an expression. It encodes the visual appearance of an expression in a way that facilitates rendering to various media. Thus, the same presentation markup can be rendered with relative ease on screen in wide or narrow windows, in ASCII or graphics, in print, or in sensible spoken language. Presentation markup supports these various renderings because it encodes notational information such as structured grouping of subexpressions, identification of mathematical symbols such as identifiers and operators, and disambiguation of invisible symbols such as for multiplication and function application.
Presentation markup is not directly concerned with the functional structure or mathematical semantics of an expression. In many situations, the notational structure and the functional structure are closely related, so a sophisticated processing application may be able to heuristically infer the functional structure from the notational structure, provided sufficient context is known. In practice, however, the inference of functional structure or mathematical meaning from mathematical notation must often be left to the reader.
While presentation markup is sufficient for a wide range of applications, employing presentation markup alone may limit the ability of some applications such as symbolic calculation systems to re-use the markup in another context.
Content markup encodes the functional structure of an expression. It encodes this structure in a sufficiently regular way that facilitates the assignment of mathematical semantics to an expression by application programs. Though the details of mapping from functional application structure to mathematical semantics can be extremely complex, in practice, there is wide agreement about the conventional meaning of many basic mathematical constructs. Consequently, much of the meaning of a content expression is easily accessible to a processing application, independent of where or how it is displayed to the reader. In many cases, content markup could be cut from a Web browser and pasted into a mathematical software tool with confidence that it will compute sensible values.
Since content markup is not directly concerned with how an expression is displayed, a renderer must infer how an expression should be presented to a reader. A sufficiently sophisticated renderer may provide transformational style sheets and other mechanisms that allow a user to interact with mathematical documents via their own personalized notational preferences. These preferences may then interact with the notational preferences expressed by the content author in a sensible way, which may require user intervention at some level.
While content markup is sufficient for a wide range of computational applications, employing content markup alone may limit the ability of the author to control precisely how an expression is rendered.
Both content and presentation markup are necessary to provide the full expressive capability one may require from in a mathematical markup language. In some cases, the same visual notation is used to represent several completely different mathematical concepts. For example, the notation xi may be intended (in polynomial algebra) as the i-th power of the variable x, or (in tensor calculus) as the i-th component of a vector x. In other cases, the same mathematical concept may be displayed in one of various notations. For instance, the factorial of a number might be expressed with an exclamation mark, a Gamma function, or a Pochhammer symbol.
Thus, the same notation may represent several mathematical ideas, and conversely, the same mathematical idea often has several notations. Both content and presentation markup are needed to provide authors the ability to control visual notation in a form that is natural to a human user, and to encode functional structure in a form that is predictable for a computational system.
In general, when it is important to control exactly how an expression is rendered, presentation markup will be more satisfactory. When it is important that the meaning of an expression can be interpreted dependably and automatically, then content markup will be more satisfactory.
5.2 Semantic Annotations for Alternate Representations
| Editorial note: Paul+Sam | |
| This section could be almost mute about the attribution key thus making it a simple rephrase of MathML2's semantic element and pushign the cd-name-cdbase requirements to the next one | |
An important concern of MathML is to associate specific semantics with a particular presentation, or additional presentation information with a content construct.
A semantic annotation decorates a MathML expression with a sequence of one or more pairs made up of a symbol (see ), the "attribute" or "key", and an associated object, the "value of the attribute".
A semantic annotation is built up by the semantics element, which takes as
the first child the MathML expression to be annotated. Subsequent children are
annotation-xml (for values that are XML-encoded) and annotation (for
values that are not) children that represent the attribute/value pairs. The key symbol
allows to specify the relation of the annotation to the annotated element, it is
referenced either by the cdbase, cd, name triplet or
the definitionURL attribute (see ).
If none of these attributes are specified, the
symbol is assumed to be the symbol alternate-representation from the
attribution-keys content
dictionary.
| Editorial note: MiKo | |
| reference | |
For example in the MathML representation
<semantics>
<mrow>
<mrow>
<mo>sin</mo>
<mfenced open="(" close=")"><mi>x</mi></mfenced>
</mrow>
<mo>+</mo>
<mn>5</mn>
</mrow>
<annotation-xml cd="mathml" name="contentequiv" encoding="MathML-Content">
<apply>
<csymbol cd="algebra-logic" name="plus"/>
<apply><sin/><ci>x</ci></apply>
<cn>5</cn>
</apply>
</annotation-xml>
<annotation cd="maple" name="nativerep" encoding="Maple">sin(x) + 5</annotation>
<annotation cd="mathematica" name="nativerep" encoding="Mathematica">Sin[x] + 5</annotation>
<annotation cd="TeX" name="plainTeXrep" encoding="TeX"> \sin x + 5</annotation>
<annotation-xml cd="openmath" name="XMLencoding" encoding="OpenMath">
<OMA xmlns="http://www.openmath.org/OpenMath">
<OMA>
<OMS cd="arith1" name="plus"/>
<OMA><OMS cd="transc1" name="sin"/><OMV name="x"/></OMA>
<OMI>5</OMI>
</OMA>
</annotation-xml>
</semantics>
binds together various representations of the sum of the sinus function applied to a
variable x and the number 5. Essentially, we annotate the presentation element
in the first child of the semantics element with various content-oriented
representations. Each annotation and annotation-xml element specifies
the nature of the annotation by referencing a key symbol in an appropriate content
dictionary. For instance, the first annotation-xml element references the key
symbol "contentequiv" from the attribution-keys content dictionary
that specifies that the content MathML expression it provides is mathematically equivalent
to the annotated presentation MathML expression.
| Editorial note: Paul | |
| TODO: Indicate predefined values of encoding (MathML-presentation and MathML-content). | |
The annotation element contains arbitrary parsed character data. If it
contains the XML reserved characters &, <,
>, ', ", then they must XML-escaped
as &, <, >,
', " or the content must be enclosed in a
CDATA section. Using a decoder for the encoding specified by the
encoding attribute, the content is interpreted as a value for the key
(symbol) is referenced either by the cdbase, cd, name
triplet or the definitionURL attribute (see ). It is recommended that its MIME type is used as the
value of the encoding attribute. For example
<annotation-xml encoding="text/latex">
<![CDATA[\documentclass{article}
\begin{document}
\title{E}
\maketitle
The base of the natural logarithms, approximately 2.71828.
\end{document}]]>
</annotation-xml>5.2.1 The annotation-xml element
The annotation-xml element is analogous to the annotation
element, except that the content can be an arbitrary XML sub-tree
with a single root element. It is recommended that, where
the contents of the foreign object are in an XML dialect, the namespace of the XML
dialect is used as the value. For instance
<annotation-xml encoding="http://www.w3.org/1999/xhtml">
<html xmlns="http://www.w3.org/1999/xhtml">
<head><title>E</title></head>
<body><p>The base of the natural logarithms, approximately 2.71828.</p></body>
</html>
</annotation-xml>5.2.2 Annotation references
In some cases the alternative children of a semantics element are
not required for default behavior, but may be useful to specialized processors.
For example, the presentation of a markup instance within a browser may not
require additional annotations, but they may be needed when the markup is
exported into another application. To enable the availability of several
annotation formats in a more efficient manner, empty annotation and
annotation-xml elements may be used to provide encoding
and href attributes that specify a location for the expanded markup
form for the annotation. Processing agents that anticipate that
consumers of exported markup may not be able to retrieve the expanded form
of such annotations should replace the annotation reference with the expanded
form, by requesting the content from the indicated URL. We refer to
Section 7.2 Transferring MathML in Desktop Environments for more information about processing
such elements within transfer paradigms such as copy-and-paste and
drag-and-drop. A very simple example usage of this attribute could be:
<semantics> <mfrac><mrow>a</mrow><mrow><mi>a</mi><mo>+</mo><mi>b</mi></mrow></mfrac> <annotation encoding="image/png" href="333/formula56.png"/> <annotation encoding="text/maple" href="333/formula56.ms"/> </semantics>
5.3 Semantic Annotations beyond Alternate Representations
An attribution decorates a content MathML expression with a sequence of
one or more semantic annotations. MathML uses the semantics,
annotation-xml, and annotation elements introduced above for this.
An attribution acts as either adornment annotation or as semantical annotation. When the key has role "attribution", then replacement of the attributed object by the object itself is not harmful and preserves the semantics. When the key has role "semantic-attribution" then the attributed object is modified by the attribution and cannot be viewed as semantically equivalent to the stripped object. If the attribute lacks the role specification then attribution is acting as adornment annotation.
An example of the use of an adornment attribution would be to indicate the color in which an content representation object A should be displayed, for example
| Editorial note: MiKo | |
| need a much better example here, this one interferes with the ones above. | |
<semantics>
A
<annotation-xml cd="display" name="color" encoding="cMathML">
red
</annotation>
</semantics>Note red are arbitrary representations whereas the key is a symbol.
An example of the use of a semantic attribution would be to indicate the type of an object. For example the object
<semantics>
A
<annotation-xml cd="mathmltypes" name="type" encoding="cMathML">
t
</annotation>
</semantics>represents the judgment stating that object A has type t. Note that both A and t are arbitrary cMathML expressions.
Composition of semantic annotation, as in
<semantics> <semantics>AA_1 A_k</semantics> A_k+1 ... A_n </semantics>
where the A_i are annotation or annotation-xml elements
is equivalent to a single attribution, that is the semantic annotation
<semantics> A A_1 ... A_n </semantics>
The operation that produces an object with a single layer of semantic annotations is called flattening. Multiple annotations with the same key symbol are allowed. While the order of the given attributes does not imply any notion of priority, potentially it could be significant.
5.4 Mixed Markup
5.4.1 Reasons to Mix Markup
In many situations, an author or program may generate either presentation or content markup exclusively. For example, a program that translates legacy documents would likely generate pure presentation markup. Similarly, an educational software package might generate only content markup for evaluation in a computer algebra system. However, in many other situations, there are advantages to mixing both presentation and content markup within a single expression.
If an author is primarily concerned with presentation, interspersing some content markup may produce more accessible, more re-usable results with the content expressions rendered appropriately. For example, an author writing about linear algebra might write:
<mrow> <apply><power/><ci>x</ci><cn>2</cn></apply> <mo>+</mo> <msup><mi>v</mi><mn>2</mn></msup> </mrow>
where v is a vector, the superscript denotes a vector component, and x is a real variable. Because of the linear algebra context, a visually impaired reader may direct a voice synthesis program to render superscripts as vector components. The explicit encoding of the power as content markup would then yield a much better voice rendering than would likely happen by default.
If an author is primarily concerned with content, there are two reasons to intersperse presentation markup. First, the use of presentation markup provides a way to modify or refine how a content expression is rendered. For example, one may write:
<apply> <in/> <ci><mi mathvariant="bold">v</mi></ci> <ci>S</ci> </apply>
In this case, the use of embedded presentation markup allows the author to specify that v should be rendered in boldface. In the same way, it is sometimes the case that a completely different notation is desired for a content expression. For example, here we express a fact about factorials, n = n!/(n-1)!, using the ascending factorial notation:
<apply>
<equivalent/>
<ci>n</ci>
<apply>
<divide/>
<semantics>
<apply>
<factorial/>
<ci>n</ci>
</apply>
<annotation-xml encoding="MathML-Presentation">
<msup>
<mn>1</mn>
<mover accent="true">
<mi>n</mi>
<mo>¯<!--MACRON--></mo>
</mover>
</msup>
</annotation-xml>
</semantics>
<semantics>
<apply>
<factorial/>
<apply><minus/><ci>n</ci><cn>1</cn></apply>
</apply>
<annotation-xml encoding="MathML-Presentation">
<msup>
<mn>1</mn>
<mover accent="true">
<mrow><mi>n</mi><mo>-</mo><mn>1</mn></mrow>
<mo>¯<!--MACRON--></mo>
</mover>
</msup>
</annotation-xml>
</semantics>
</apply>
</apply>
This content expression might render using the given notation as:
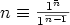
A second reason to use presentation markup within content markup is that there is a continually growing list of areas of discourse that do not have pre-defined content elements that encode their objects and operators. As a consequence, any system of content markup inevitably requires an extension mechanism to combine visual notation with function structure. MathML content markup specifies several ways of attaching an external semantic definitions to content objects. It is necessary, however, to use MathML presentation markup to specify how such user-defined semantic extensions should be rendered.
For example, the "rank" operator from linear algebra is not
included as a pre-defined MathML content element. Thus, to express
the statement rank(uTv)=1
we may use a semantics element to bind a semantic
definition to the symbol rank.
<apply>
<eq/>
<apply>
<semantics>
<mi>rank</mi>
<annotation-xml encoding="OpenMath">
<OMS name="rank" cd="linalg4" xmlns="http://www.openmath.org/OpenMath"/>
</annotation-xml>
</semantics>
<apply>
<times/>
<apply> <transpose/> <ci>u</ci> </apply>
<ci>v</ci>
</apply>
</apply>
<cn>1</cn>
</apply>Here, the semantics of rank have been given using a symbol from an OpenMath [OpenMath2000] content dictionary (CD).
5.4.2 Presentation Markup in Content Markup
The use of presentation markup within content markup is limited to situations that do not effect the ability of content markup to unambiguously encode mathematical meaning. Specifically, presentation markup may only appear in content markup in three ways:
-
within
ciandcntoken elements -
within the
csymbolelement -
within the
semanticselement
Any other presentation markup occurring within a content markup is a MathML error. More detailed discussion of these three cases follows:
- Presentation markup within token elements.
-
The token elements
ciandcnare permitted to contain any sequence of MathML characters (defined in Chapter 6 Characters, Entities and Fonts) and/or presentation elements. Contiguous blocks of MathML characters inciorcnelements are treated as if wrapped inmiormnelements, as appropriate, and the resulting collection of presentation elements is rendered as if wrapped in an implicitmrowelement. - Presentation markup within the
csymbolelement. -
The
csymbolelement may contain either MathML characters interspersed with presentation markup, or content markup. It is a MathML error for acsymbolelement to contain both presentation and content elements. When thecsymbolelement contains character data and presentation markup, the same rendering rules that apply to the token elementsciandcnshould be used. - Presentation markup within the
semanticselement. -
One of the main purposes of the
semanticselement is to provide a mechanism for incorporating arbitrary MathML expressions into content markup in a semantically meaningful way. In particular, any valid presentation expression can be embedded in a content expression by placing it as the first child of asemanticselement. The meaning of this wrapped expression should be indicated by one or more annotation elements also contained in thesemanticselement.
5.4.3 Content Markup in Presentation Markup
The guiding principle for embedding content markup within presentation expressions is that the resulting expression should still have an unambiguous rendering. In general, this means that embedded content expressions must be semantically meaningful, since rendering of content markup depends on its meaning.
The following content elements may not appear as an immediate child
of a presentation element: annotation, annotation-xml,
bvar, condition, degree,
logbase, lowlimit, uplimit.
Within presentation markup, content markup may not appear within presentation token elements.
5.5 Parallel Markup
Some applications are able to use both presentation
and content information. Parallel markup, is a way to combine
two or more markup trees for the same mathematical expression.
Parallel markup is achieved with the
semantics element. Parallel markup for an expression
may appear on its own, or as part of a larger content or presentation tree.
5.5.1 Top-level Parallel Markup
In many cases, the goal is to provide presentation markup and content markup for a mathematical
expression as a whole.
A single semantics element may be used to pair two markup trees,
where one child element provides, for example, the presentation markup, and the
other child element provides the content markup.
The following example encodes the boolean arithmetic expression (a+b)(c+d) in this way.
<semantics>
<mrow>
<mrow><mo>(</mo><mi>a</mi> <mo>+</mo> <mi>b</mi><mo>)</mo></mrow>
<mo>⁢<!--INVISIBLE TIMES--></mo>
<mrow><mo>(</mo><mi>c</mi> <mo>+</mo> <mi>d</mi><mo>)</mo></mrow>
</mrow>
<annotation-xml encoding="MathML-Content">
<apply><and/>
<apply><xor/><ci>a</ci> <ci>b</ci></apply>
<apply><xor/><ci>c</ci> <ci>d</ci></apply>
</apply>
</annotation-xml>
</semantics>
Note that the above markup annotates the presentation markup as
the first child element, with the content markup as part of the
annotation-xml element. An equivalent form could be given
that annotates the content markup as the first child element, with
the presentation markup as part of the annotation-xml element.
Top-level parallel markup should be strived for by applications that are able to since it provides recipients with an easier processing than partial semantic annoations.
5.5.2 Parallel Markup via Cross-References: xml:id and xref
To accommodate applications that must process sub-expressions of large
objects, MathML can use cross-references between the branches of a semantics element
to identify corresponding sub-structures. This application of the semantics
elements and id-marking should be viewed as best practice to enable
recipients to "select" arbitrary sub-expressions in all forms of the
semantic-annotations alternatives.
These cross-references use xml:id and xref attributes within
the branches of a containing semantics element. These attributes may
be placed on MathML elements of any type.
The following example demonstrates cross-references for the boolean arithmetic expression (a+b)(c+d).
<semantics>
<mrow xml:id="E">
<mrow xml:id="E.1">
<mo xml:id="E.1.1">(</mo>
<mi xml:id="E.1.2">a</mi>
<mo xml:id="E.1.3">+</mo>
<mi xml:id="E.1.4">b</mi>
<mo xml:id="E.1.5">)</mo>
</mrow>
<mo xml:id="E.2">⁢<!--INVISIBLE TIMES--></mo>
<mrow xml:id="E.3">
<mo xml:id="E.3.1">(</mo>
<mi xml:id="E.3.2">c</mi>
<mo xml:id="E.3.3">+</mo>
<mi xml:id="E.3.4">d</mi>
<mo xml:id="E.3.5">)</mo>
</mrow>
</mrow>
<annotation-xml encoding="MathML-Content">
<apply xref="E">
<and xref="E.2"/>
<apply xref="E.1">
<xor xref="E.1.3"/><ci xref="E.1.2">a</ci><ci xref="E.1.4">b</ci>
</apply>
<apply xref="E.3">
<xor xref="E.3.3"/><ci xref="E.3.2">c</ci><ci xref="E.3.4">d</ci>
</apply>
</apply>
</annotation-xml>
</semantics>
An xml:id attribute and a corresponding xref appearing within the
same semantics element create a correspondence between sub-expressions.
All of the xml:id attributes referenced by any xref must be in the
same branch of an enclosing semantics element. This constraint
guarantees that these correspondences do not create unintentional cycles. (Note that this
restriction does not exclude the use of xml:id attributes within the
other branches of the enclosing semantics element. It does, however, exclude
references to these other xml:id attributes originating in the same
semantics element.)
There is no restriction on which branch of the semantics element may contain
the destination xml:id attributes. It is up to the application to determine which
branch to use.
In general, there will not be a one-to-one correspondence between nodes in parallel
branches. For example, a presentation tree may contain elements, such as parentheses, that
have no correspondents in the content tree. It is therefore often useful to put the
xml:id attributes on the branch with the finest-grained node structure. Then all of
the other branches will have xref attributes to some subset of the
xml:id attributes.
In absence of other criteria, the first branch of the semantics element is a
sensible choice to contain the xml:id attributes. Applications that add or remove
annotations will then not have to re-assign attributes to the semantics
trees.
In general, the use of xml:id and xref attributes allows a full
correspondence between sub-expressions to be given in text that is at most a constant
factor larger than the original. The direction of the references should not be taken to
imply that sub-expression selection is intended to be permitted only on one child of the
semantics element. It is equally feasible to select a subtree in any branch and
to recover the corresponding subtrees of the other branches.
Top level markup with cross-references applies to any XML-encoded branch of the semantic annotations as is shown by the following example where the boolean expression of the previous section can be annotated with OpenMath, and cross-linked as follows:
<semantics>
<mrow id="E">
<mrow id="E.1">
<mo id="E.1.1">(</mo>
<mi id="E.1.2">a</mi>
<mo id="E.1.3">+</mo>
<mi id="E.1.4">b</mi>
<mo id="E.1.5">)</mo>
</mrow>
<mo id="E.2">⁢<!--INVISIBLE TIMES--></mo>
<mrow id="E.3">
<mo id="E.3.1">(</mo>
<mi id="E.3.2">c</mi>
<mo id="E.3.3">+</mo>
<mi id="E.3.4">d</mi>
<mo id="E.3.5">)</mo>
</mrow>
</mrow>
<annotation-xml encoding="MathML-Content">
<apply xref="E">
<and xref="E.2"/>
<apply xref="E.1">
<xor xref="E.1.3"/><ci xref="E.1.2">a</ci><ci xref="E.1.4">b</ci>
</apply>
<apply xref="E.3">
<xor xref="E.3.3"/><ci xref="E.3.2">c</ci><ci xref="E.3.4">d</ci>
</apply>
</apply>
</annotation-xml>
<annotation-xml encoding="OpenMath"
xmlns:om="http://www.openmath.org/OpenMath">
<om:OMA href="E">
<om:OMS name="and" cd="logic1" href="E.2"/>
<om:OMA href="E.1">
<om:OMS name="xor" cd="logic1" href="E.1.3"/>
<om:OMV name="a" href="E.1.2"/>
<om:OMV name="b" href="E.1.4"/>
</om:OMA>
<om:OMA href="E.3">
<om:OMS name="xor" cd="logic1" href="E.3.3"/>
<om:OMV name="c" href="E.3.2"/>
<om:OMV name="d" href="E.3.4"/>
</om:OMA>
</om:OMA>
</annotation-xml>
</semantics>
Here
OMA, OMS and
OMV are elements defined in the OpenMath
standard for representing
application, symbol and variable, respectively.
The references from the OpenMath annotation are given by the
href attributes.