This Working Group Note presents the first measurement results of various
high-performance XML interchange encoding formats and their associated
processors, made by the Efficient XML Interchange (EXI) Working Group. The
measurements have been conducted following the recommendations of the XML Binary
Characterization (XBC) Working Group. In particular, this draft covers measurements of the properties of "compactness" and
"processing
efficiency", as defined by
the XBC WG. We start by describing the context
in which this analysis is being made, and the position of an efficient
format in the landscape of high performance XML strategies. Then we
describe the measured quantities in detail and the test framework in
which they were made. A short description of each format is
included. Since the measurement and analysis effort is still in
progress, for this first draft the raw results and preliminary
findings are given elsewhere (see respectively the EXI Measurements Results Preview and the
Analysis of the EXI Measurements).
This section describes the status of this document at the time of its
publication. Other documents may supersede this document. A list of current
W3C publications and the latest revision of this technical report can be
found in the W3C technical reports index
at http://www.w3.org/TR/.
This First Public Working Draft presents initial measurement results of the EXI Working
Group's tests of various high performance XML interchange encoding
formats. This draft concentrates on the properties
of "compactness"
and "processing
efficiency". Some formats and alternative technologies to which we
wish to compare results, are not yet in the measurement framework
(notably ASN.1 PER, and XML Screamer
[Screamer], though these are expected very
soon). Additionally, the preliminary results are being used to further
optimize some candidates. Therefore, results given in
the Analysis
of the EXI Measurements are subject to change in the
immediate future.
Following drafts of this note will add further analysis of the results
and successively address more of the property requirements, as
determined by the XML Binary
Characterization Working Group. While compactness will not
generally vary from implementation to implementation, processing
efficiency may vary widely between implementations of a given format.
The current framework characterizes processing efficiency of specific
implementations, rather than attempting to evaluate any nominal
theoretical processing efficiency limit of each format itself. In
addition, we have tabulated the W3C requirements met by each format
(as identified in the XBC Characterization document), though each
format's development is ongoing and therefore those results, and
possible implications for performance, are likely to change. For these
reasons, the dynamical results and analysis are given elsewhere,
see the EXI Measurements Results Preview
and the
Analysis of the EXI Measurements).
This document was developed by the Efficient XML Interchange (EXI) Working
Group. A complete list of changes to this document is available.
Comments on this document are invited and are to be sent to the public public-exi@w3.org mailing list (public archive). If
substantive comments are received, the Working Group may revise this Working
Group Note.
Publication as a Working Draft does not imply endorsement by the W3C
Membership. This is a draft document and may be updated, replaced or
obsoleted by other documents at any time. It is inappropriate to cite this
document as other than work in progress.
This document was produced by a group operating under the 5 February 2004
W3C Patent Policy. W3C maintains a public list of
any patent disclosures made in connection with the deliverables of the
group; that page also includes instructions for disclosing a patent. An
individual who has actual knowledge of a patent which the individual believes
contains Essential
Claim(s) must disclose the information in accordance with section
6 of the W3C Patent Policy.
1. Objectives
The objective of this document is to provide an analysis of the
expected performance characteristics of a potential "Efficient XML
Interchange" (EXI) encoding format. A successful EXI format will
include facilities for helping computers encode and decode the
entities of XML documents efficiently and in a compact form. The
purpose of such a format would be to enable the use of tools and
processing models in the current XML technology stack, in environments
where the costs of producing, exchanging, and consuming XML are
currently high or prohibitive. Additionally, such a format may well
enable an expansion of the use of web technologies to new applications
or industries, which presently find some facilities of XML attractive,
but are limited by some hard constraints on encoded length or some
aspect of computational efficiency.
This first-draft Note presents measurement data for the processing and
compaction performance properties of a number of existing alternative XML
encoding format technologies. These formats are considered representative
"proxies" of an eventual EXI technology.
One or more of these formats may be selected as the basis of a standard EXI format.
Successive drafts will add a structured analysis by use case, measurements of
other candidates, and a more comprehensive quantitative analysis of other
properties, as outlined by the XML
Binary Characterization (XBC) Working Group's document XML Binary Characterization
Properties [XBC properties].
Based on these efforts, a single format may be proposed to become a
Recommendation of the W3C.
2. Methodological Context
The Extensible Markup Language (XML), is an application profile of
Standard Generalized Markup Language (SGML). It provides a well defined
syntax and encoding by which structured, textual, data can be examined by
people, and exchanged and interpreted by computers. The well defined basis of
XML, and its simple syntax that permits ready semantic interpretation, has
resulted in a very broad range of successful uses. There are a number of use
cases for which these advantages are tempered by inefficiencies which stem
from the textual encoding of XML. These cases, for instance, require a compact
form, such as in small portable devices like mobile phones, or an encoding
which avoids the time spent on floating point conversion, such as in
scientific and engineering fields. Many use cases, and the properties of XML
to which they are sensitive, were documented extensively by the XML Binary Characterization
Working Group, in [XBC Use Cases] and [XBC properties].
The XBC WG recommended that work on an Efficient XML Interchange
format proceed, since alternative formats which appeared to meet some
or all of the property criteria already existed. However, the XBC WG
did not perform a quantitative analysis of those formats, nor define
measurable thresholds of performance which should be achieved for
each use case and property. This Note provides measurement data
regarding some of the quantitative Properties of XML
relevant to the creation of an efficient format for the interchange of
XML, including its encoding and processing. In general, we do not
here review the simple-valued properties of each format, such as
whether they are "Royalty Free".
This draft concentrates on the two most critical properties of XML for a
potential efficient interchange format: "compactness" and
"processing
efficiency". These are important
in that they are both significant
drawbacks with existing XML solutions in many use cases, and they are difficult to accurately model. Subsequent drafts will address
more of the XBC property requirements.
In order to characterize the performance of the candidates with
respect to these properties, the EXI working group has assembled a
significantly larger set of test data than was collected by the XBC. The
group has also created a testing
framework, based on Japex, which enables
efficient testing of different candidate formats and implementations
against a variety of different XML data. The wide set of test data is
intended to highlight any binary-encoding format which achieves good
results at the expense of being narrowly focused, and to help
determine the generality of each format. The inclusion of many
candidate algorithms improves the likelihood of identifying
superior solutions which might ultimately inform an ideal
single-format EXI recommendation.
Results are included for each of these candidates versus common XML
solutions. Since processing efficiency is a measure of both format and
implementation combined, this effort will include at least two
different, already existing, high-performance XML parsers to obtain
baseline measurements of XML processing efficiency. Presently we have
xals, and XML Screamer will be integrated shortly. The EXI group has
also issued a public call for additional fast XML implementations, in
order to avoid any possibility of drawing misleading conclusions.
Submitted: May, PH. Integrated: 23-May, GW. Edited: 27-May, GW: Collapsed
intent from OG's viability arg and Peter's HP XML parsing/screamer arg, into
smaller space. June 4: SW: rewrote introduction, edited, included condensed thoughts from PH's note.
Editorial note: The group feels that this section is important,
but there is not yet consensus as to appropriate content, points, and
form.
XML standards and related industry practice provide numerous
benefits. This has been very valuable, but there is significant
consensus that XML can be improved in several ways, mostly in terms
of efficiency. Less clear to some is whether the cost of various
improvement strategies outweighs the cost of change required to
support strategies that involve a new encoding format. Additionally,
existing XML processing implementations are often not optimal. These
points of view lead to the main high performance XML strategy
dichotomy: improve parsing technology for existing XML encoding or
design an improved format that is more efficient overall.
There are numerous parsers of various types available for XML.
A representative member of commonly used parsers is being used for
comparison to possible EXI candidates. The XBC working group
determined a comprehensive set of properties that are desirable
in an EXI candidate. A faster parser technology might address some of
these, but certainly not others, principally compactness. The EXI
working group made a public request for fast XML parser
implementations. The only example submitted was [XML Screamer]. XML Screamer is a
proof-of-concept project that makes use of generated and compiled
special-purpose parsers that are created for each vocabulary to be
exchanged. This architecture does not fit all of the XBC-identified use
cases, however reported results are instructive to both the evaluation
of EXI candidates and for the EXI viability decision. Other methods exist
for improving processing stacks that are centered around the
separation of roles, or separation of metadata from data, where the
data which must be efficiently encoded is moved out of line (SOAP with
MTOM and XML-binary Optimized Packaging [XOP], GRID's Web Services Resource Framework [WSRF], etc). Another class of techniques is that
of collapsing the protocol stack to remove inefficiencies at their
boundaries, to bind them more efficiently, and to use more than one
basic optimization method (bSOAP, XML Screamer).
Another, quasi-solution, is to wait until the prevailing cost of the
required network or computing speed makes a particular use case practical with
XML.
A number of efforts used in various XML communities address the
problem by optimizing the format itself. There are many options in
the design of an encoding format that can be compatible with and still
improve upon XML. Some existing efforts retain the basic textual XML
encoding but use the facility of XML Schema's
base64Binary type to encode binary insertions, some replace the
whole bit-stream. In all cases the encoding process can use knowledge
about the data, either explicitly via a schema, or implicitly by using
assumptions inherent in the use case. As described in XBC Working
Group documents, different methods externalize various
amounts of information in various ways. They encode the data either
more compactly, or in a way which avoids expensive computational
overhead, or both. For instance, in scientific and engineering data
exchanges floating point encoding from text to binary and back to text
can account for 90% of the wall-clock time for large, numerically
saturated exchanges [Engelen], [Chui]. Some of the more general purpose efforts
are described in this document (see the section Contributed Candidate EXI Implementations
and the XBC Working Group documents though there are many others (bnux
[NUX], [BXML], bSOAP
[Abu-Ghazaleh], [gSOAP], [BXSA]).
One might say that each of these solution strategies are
indicated in some circumstances. For instance, collapsing the protocol
stack can be done in largely proprietary situations and textual parser
optimization seems better when "view source" is important. EXI is an
effort to find a standardizable solution for that significant group of
communities for which the indicated solution appears to be to optimize
the format itself. Ideally, an EXI candidate will have a flexible
and robust design that answers all important properties and
efficiencies for most use cases.
4. Test Methodology
4.1. Notional XML-EXI Measurement Processing Pipeline
The following diagram illustrates the various steps whereby XML documents
are typically converted into a binary encoding and then decoded back into
the original text-based XML encoding. This is the nominal processing pipeline that was instrumented by the measurement framework used to make the performance measurements.
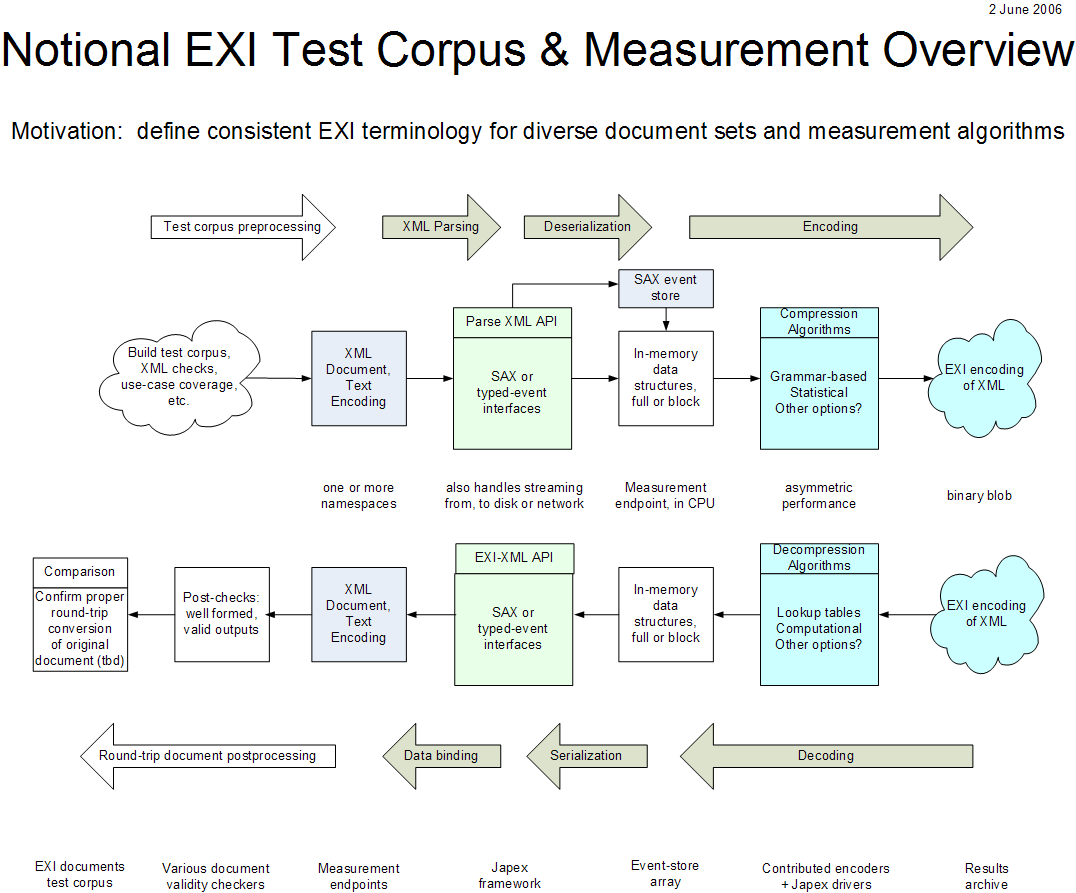
The following steps are typically performed when converting an XML
document into a binary-encoded document.
- Preliminary editing. An XML document is used as input. Check
and/or correct XML version, character encoding, whitespace, namespace, and
any special-content issues such as processing instructions (PIs).
- Correctness checks. Well-formedness checking, validation, plus
any constrains imposed by specific test restrictions.
- Baseline XML document. The XML document is now ready for
measured processing.
- XML Parsing. The document is parsed using an event-oriented
(e.g. SAX), object-oriented (DOM), or data-binding oriented (e.g. JAXB)
parser.
- Deserialization. Document elements and attributes are
deserialized and stored as in-memory data structures, either as objects
or as an event stream.
- Compression. Compression and encoding algorithms are applied to
the XML document data. Schema-based, grammar-based, statistical, or other
approaches may be used.
- Binary encoded data. A binary-encoded XML document results.
The following corresponding steps typically occur when converting a
binary-encoded document into an XML-encoded document.
- Binary encoded data. A binary-encoded XML document is used as
input.
- Decompression. Decompression and decoding algorithms are applied
to the binary data. Internal or external lookup tables may be used.
- In-memory data structures. Document elements and attributes are
stored in memory, either as objects or as an event stream.
- Serialization. The output document is created by serializing the
in-memory data structures to an XML document.
- Baseline XML document. The XML document is now restored to the
XML encoding. This version may still be encrypted.
- Correctness checks. Well-formedness checking, validation, plus
any constrains imposed by specific test restrictions are again applied to
ensure results are legitimate.
- Comparison to original. For test purposes, the restored
XML-encoded document is compared to the original document in order to
verify correct round-trip handling. Exact byte-code matches are not
necessary, but XML-correct comparisons are required.
4.2. Data Characteristics and Complexity
Submitted: 25-Apr by GW. Integrated: 1-May, GW. Status: Edited 1-May, GW
Forward Reference: Note that the property of a format that it can handle
large documents will probably not be satisfied by those which require to load
the whole document into memory!
The XBC Measurements Document [XBC
Measurements] 6.2.1.5
(Measurement
Considerations) says that processing efficiency is related
to size and to complexity. Additionally, it
discusses data complexity in the context of a large number of
scenarios and property profiles of use cases. However, how to
quantitatively determine the complexity of a single document, in order to gauge the
response of a format's processing characteristics to complexity, is
not discussed.
A list of the continuous components of complexity which
might be tractable for characterizing a format's processing efficiency
with respect to complexity, for the tasks for which the group measured each
candidate (see Measured Tasks of
Processing Efficiency and
Measured Compactness), could be:
Components of XML Complexity
- size
- total number of elements
- number of unique elements
- tree-height (nesting)
- number of unique external references
- total number of attributes
- number of unique attributes
- regularity, or "self-similarity"
This list, derived
from Determining
the Complexity of XML Documents
([DET-COMPLEXITY]), includes size. It can
be argued that since size is largely orthogonal to the remaining
characteristics, it ought to be treated separately. However, over the
whole XML community, "size" will vary on a large interval, such as a
few 10s of bytes to say 10 Gbytes (MicroArray Gene Expression
descriptions in MAGE-ML, 3d modelling in X3D, MEDLINE/Pubmed etc). So
this range is now about 9 orders of magnitude, and quite possibly will be greater
in the future. Therefore, size will dominate any requirement for
the expected response of a format to the (continuous) characteristics
of documents the format might be required to process.
From previous work, the group is also aware that the simple ratio
of content data to markup, is a blunt but effective predictive
variable for XML processing time. This quantity is called "Information
Density" in the Analysis of the
EXI Measurements.
Therefore, as a simplification, to reduce the number of continuous
independent variables over which the formats must be measured, we
looked at each candidate's performance only with respect to size and
to information density. The response of formats to the remaining
continuous components above may be evaluated in proceeding drafts of
this document.
One important non-continuous property that is immediately related to size
though, is generality. Specifically, any format that cannot process very
large documents due to the format's need to process entirely from main
memory, cannot pass the generality requirement for an EXI format.
The tests additionally characterize each format with respect to the
fidelity with which it reproduces the information in documents, according to
a scale analogous to various XML data models. Those systematic measurements
are described in the Fidelity
Considerations section below.
We will be doing an analysis of complexity in future work.
4.3. Figures of Merit
Submitted: 25-Apr, GW. Integrated: 1-May, GW. Edited: 1st pass 1-May, GW, for
syntax. Needs content review.
For this draft of the Note we measured two of the
three Algorithmic
Properties described in
the XML Binary
Characterization Properties, for each contributed
format; Processing
Efficiency
and Space
Efficiency. Additionally, the tests measure
the Format
Property
of Compactness. This
section describes the quantities used to characterize those properties
in each potential EXI format that has been measured.
4.3.1. Characterization of Processing Efficiency
This subsection describes the quantities we use to evaluate each format's
Processing Efficiency.
In addition to characterizing the speed of processing, the XBC
Measurement Methodologies [XBC Measurements]
document, section 6.2.1 Processing
Efficiency Description, delineates four properties of a format's
algorithm which need to be analyzed for processing efficiency; Incremental
Overhead, Standard APIs vs Abstract Properties, Processing Phases, and
Complexity [of the algorithm itself, not of the input data]. Of these, really
only incremental overhead is amenable to empirical testing. Incremental
Overhead refers to whether a format "allows and supports the ability to
operate efficiently so that processing is linear to the application logic
steps rather than the size of data complexity of the instance"
[emphasis added]. That is, it is reasonable to expect the processing
time of an application using our format to be dominated by the complexity of
the application, not by the processing in our format. So the
desirable characteristic of a format is that its processing time be (only)
linearly or sublinearly dependent on the input data complexity, i.e. that
it's O(n).
For most users of XML, linearity over a broad range is likely to be a
secondary concern. Of primary interest will be expected wall-clock elapsed
time to process "most" typical examples of an individual's use cases, in
their own scenarios. From the perspective of the XML community however, we
require good performance over a very broad spectrum of document complexities.
Therefore, as described above in Data
Characteristics and Complexity, the complexity requirement as a whole is
dominated by size; that is, the above expected processing time function
f(n)=O(g(n)) must hold for a large range of document sizes
(n).
A number of the use cases described by the XBC in XML Binary Characterization Use
Cases, present a 3rd requirement for the processing of a
format, that of minimal memory consumption. These are, for instance, use
cases Web
Services for Small Devices, Multimedia XML
Documents for Mobile Handsets and Sensor Processing and
Communication. The memory requirements of a format were captured by two of
the XML Binary
Characterization Properties: Small
Footprint and Space
Efficiency. These respectively describe the expected memory requirement
of the XML processor itself and the amount of dynamic memory required in
execution. The memory usage requirements of a format can be characterized
in some depth. For example, the tests might note behavior with different amounts of
bounded memory and check for the extent of an expected inverse relationship
with respect to processing speed. So far, however, the tests measure only total
unbounded memory consumption [Ed: At the time of writing, figures for memory consumption are being withheld from the results pages until some anomalous values are better understood].
4.3.1.1. Components of Processing
Efficiency
Putting the above together then, the important continuous measurable
components of processing efficiency to test are:
- Speed - expected wall clock elapsed execution time
- Linearity - the extent to which, empirically, the algorithm
implementation's execution time is O(n), and over how great a
range of sizes n does this hold
- Memory Consumption - unbounded memory consumption during execution.
Once figures for memory consumption are consistently measured across
the various format processing implementations, they will be correlated
with document size and processing efficiency.
4.3.1.2. Measured Tasks of Processing
Efficiency
The above components were measured for each of the following processing
tasks, derived from the XML
Binary Characterization Measurement Methodologies document, part 6.2.2:
- Encoding from a SAX event store
- Encoding from typed-API event callbacks - intended to enable measurement
without the added inefficiencies imposed by a proscribed API, and to
inform the encoder about the data's type, which it can then use to
optimize the encoding
- Decoding to a SAX store - the time it takes to parse a format, decode and serialize to SAX events
- Decoding to a typed-API.
Note that, at the time of writing, we intend that the measurement
for ASN.1 BER and ASN.1 PER formats' encode and decode, will be to
bound data structures, when those formats are included in the
measurement framework (see Native Language
Implementation Considerations). Additionally, the current measurements are not
yet using a typed-event API.
In further work we may also add processing for the DOM API (see Appendix C: Further Work).
Formats which include schema-aware encoding methods have been
allowed to use them in cases where schemas exist. Since some formats
require a schema, where no schema existed for a test group, a naive
XML Schema (root of xsd:anyType) instance was generated for purposes
of format performance comparison. Where a schema or some
other meaningful shared state might be exchanged, timing tests do not
include the time it would take to share the state, such as exchanging
the schema.
4.3.2. Characterization of Compactness
In the next version of this document, characterization of
application classes and use cases based on XBC will be added to this
section.
A figure of merit for compactness used in the literature, is the
normalized compactification rate = 1-(c/l), (that's one minus
c over l) where l is the length of the
original XML document (say utf-8 encoded on disk), and c is
the length using some compactification scheme. The factor can be
multiplied by 100 to get a percent compaction. This formalism results
in higher +ve values (0..1-eps; or 0..100-eps%) the
more compaction there is (and -ve values when the output is bigger
than the input). In order to provide more intuitive figures we have
chosen to use, at least initially and for presentation of results,
simply c/l, or (c/l)*100%. That is, smaller is
better.
Note that the XBC Measurement Methodologies document [XBC Measurements] describes the property
"Compactness", of which one method is "compression". "Compression" here
means "document compression", which is taken to mean loss-less
compression algorithms - those which use redundant information in a
document to encode its data in a smaller space. Roughly speaking, compactness
includes compression, but may also derive from other methods.
The XBC Measurements Methodology document says that the compactness
property for a given format can be characterized separately for each of
the following methods from which overall compactness may be derived ([XBC Measurements], section 6.1.2):
- Tokenization - if possible, use of the format's encoding without the
use of any of the methods below. In the Japex reports this is called "Neither"
- Schema - the use of schema-based encoding methods
- Compression - by data analysis. In the Japex reports this is called "Document"
- Schema and Compression ("Document") combined
- Deltas - use of a template, parent or earlier message (no formats use
this, so not measured)
- Lossy - use of some compression scheme where accuracy is traded for
compression (no formats uses this, so not measured).
In accordance with the XBC Measurements Methodology document, each
of the elements in this 6-vector was to be measured and evaluated
numerically, or else characterized as follows "N/S (not
supported) if the method is not supported, or N/A (not applicable) if
the method does not apply" ([XBC Measurements]
part 6.1.2 para 1). The evaluation of lossy compression itself was
to be characterized by a vector, being the amount of compression
obtained as a function of the lossiness implied by each (if more than
one) combination of lossy compaction schemes used by a format
(possibly in combination with an input "permitted lossiness
parameter").
For these measurements of compaction we have taken two
simplifying steps. First, the tests do not attempt to characterize
the compactification that may be gained from delta encodings and lossy
encodings (5 and 6 above). None of the formats submitted so far
utilize deltas in any integral way. If a non-trivial schema was not
provided for the test group, the format is not permitted to look for
one "elsewhere" (like at a URI). Just as for the processing efficiency
measurement, if there is no non-trivial schema, the format's processor
is permitted to use a pre-generated trivial schema (root of
xsd:anyType).
Also none of the formats we considered include a lossy compression scheme.
At this stage in the process of evaluating the viability of an EXI, and
for comparison of candidates, measurements of each candidate were permitted
to be made with any number of combinations of that format's parameters. So
there may be more than 4 compactness results for any one candidate (for a
given test group). However, for each configuration used, both compactness and
processing efficiency must be reported for that same configuration.
4.3.2.1. Measured Compactness
The figure of merit for compactness is then (c/l)*100%, and is an
overall measure of lossless compactness achieved by each format. We will give the
following aggregations in a following draft:
- Measured compactification for each document in the test suite
- Arithmetic mean compactification of all documents in a test group (e.g. RDF)
- Arithmetic mean for a use case (e.g. test groups UBS and RosettaNet
combined into one result for the Inter/intra Business use case).
We can clearly identify which formats are using
schema-based encoding on the compactness results, and characterize the
advantage of schema to non-schema based compression and PE (if there is in
fact any, cf Screamer) in the analysis section.
If we do ultimately characterize compression in the
presence or non-presence of schema, and if relevant, for various amounts of
lossiness, we would have to agree on how such measures would be combined for
a figure of merit. For instance, is compaction derived purely from
(loss-less) compression, to be given any more weight than that from schema
compression?
4.4. Measurement Framework
In order to make consistent measurements of all candidates over the whole
test suite set, we used a framework based on Japex. Japex is a simple tool that is
used to write Java-based micro-benchmarks. It can also be used to test native
language (e.g. C/C++) systems via the Java Native
Interface (JNI), which we used to test native
candidate implementations.
Japex is similar in spirit to JUnit in that it does most of the
repetitive programming tasks necessary to make a measurement. These tasks
include loading and initializing the required drivers, warming up the VM,
forking multiple threads, timing the inner loop, etc.
The input to Japex is an XML file describing a given test. The file's
primary constituents are the location of a test data group (for example all
of our examples of X3D XML files), and references to one or more "drivers".
These drivers interface Japex to the code which is under test. Each
implements some well defined micro-benchmark measurement, such as "encoding
with schema".
By default, the micro-benchmark measurement metric is throughput in
transactions per second (TPS). However, it is possible to customize a test to
either calculate throughput using a different unit, such as milliseconds, or
KBs per second, or to make a different kind of measurement, such as latency,
memory usage or message size. We used such customizations to make our various
measurements for the Figures of Merit
above.
The output of Japex is a timestamped report in XML and HTML formats. The
HTML reports include one or more charts generated using JFreeChart. The output
gives, for each observable under test, results for each data file, plus
aggregated results for the test group.
4.4.1. Framework's Measurement of Processing
Efficiency
Recall that to characterize processing
efficiency, we measure speed,
linearity, and memory consumption, for each of the processing tasks listed above.
To measure the "Speed" component of a candidate's Processing Efficiency,
we measured aggregate throughput for each of the processing tasks.
For our purposes, the term "throughput" is defined to be work over time.
Japex is designed to estimate an independent throughput for each of the tests
in the input. Throughput estimation is done based on some parameters defined
in the input file. There are basically two ways to specify that: (i) fix the
amount of work and estimate time, or (ii) fix the amount of time and estimate
work. We fixed the time and measured work. In addition to each test's
individual throughput, aggregate throughtputs in the form of arithmetic,
geometric and harmonic means of results for all files in the test suite, are
computed for each test. Additionally, each test was run a number of times to
estimate variance. The arithmetic mean of those aggregates was used in the
comparison of results (not harmonic mean - although TPS is a "rate", the
number of seconds given to each run was invariant).
The "Linearity" component was characterized from the same measurement data
as that for Speed.
The "Memory Consumption" component was measured, for Java based
candidates, by Peak Heap estimation. The Java virtual machine has a heap for
object allocation and also maintains non-heap memory for the method area and
the Java virtual machine execution. The Java virtual machine can have one or
more memory pools. Each memory pool represents a memory area of one of the
following types: heap or non-heap. The peak heap memory used by each driver
(which implements a single test), was estimated by the Japex framework using
the following procedure:
- Force collection by calling System.gc() a number of times, until the
available heap stabilizes
- Set peak heap memory usage to current memory usage (i.e., reset peak
usage)
- Accumulate peak memory usage across all memory pools
- Execute all runs for the driver under test
- Accumulate peak memory usage across all memory pools
- Assign the output japex.peakHeapUsage parameter by subtracting (3) from
(5).
This simple algorithm for estimating peak heap memory usage is
experimental and subject to change. Note that non-heap memory is currently
not estimated because it includes the virtual machine memory which cannot be
easily distinguished from a candidate's implementation.
See the Japex Manual [JAPEX] for
further information about this tool.
4.4.2. Measurement Process
Each measurement began by parsing the XML-format test document into an
in-memory representation. Two such representations were used: one was a
direct sequence of the SAX events produced when parsing a document (1 and 3 of the measured tasks above), and
the other was a similar sequence, but extended with an event type (2 and 4). These typed-content events were
used when a schema was available, to indicate to the encoder that the content
of the element was of some data type. The encoder might then use that to
optimize the process of encoding, and the encoded form.
The measurement consists of feeding the events of the in-memory
representation, one by one, to the measured encoder, and then using the
measured decoder to parse the produced bytes back into the in-memory
representation. Processing time was measured separately for the encode and
decode phases.
So far we have run the measurements on only a single computer system (see
Appendix A: Measurement Details). The test system
was carefully prepared to ensure reproducible measurements. It was
disconnected from the network and any other peripherals that might cause
interrupts, and only the measurement framework was permitted to run during
the measurement timing.
This use of a single system, is not unreasonable for a test purely
composed of comparison of performance amongst technologies. However, when in
further work, we measure the absolute performance of promising candidates,
that is, their processing efficiency in bytes processed per second, we will
expand the test hardware so as to isolate systematic effects (such as
different caching mechanisms, different implementations of important methods,
etc).
4.4.3. Reproducibility Criteria, Warm-up and
Caching
In our tests, measurements were made by a Java-based micro-benchmark
framework, both for processors implemented in Java and those implemented in
native languages. Since a Java Virtual Machine (JVM) typically performs a
just-in-time compilation of the running code, the first run does not usually
reflect actual application performance. Therefore, the actions of each
experiment were repeated as a warm-up, without measurement, until sufficient
cycles had passed to ensure that the measurements were stable.
This process has the intended effect of approximating and benchmarking the
performance of a warmed-up application. However, systematic effects may still
arise from caching (or warming-up) the input data, in addition to the code.
For example, if the benchmarking framework repeatedly reads a copy of the
input data from a fixed location in memory while warming up the code, the
processor will have the input data in high-speed cache memory, allowing
access times typically over 25 times faster than a real application might
encounter. One way to address this problem is by sequentially processing
multiple copies of the input data laid out end-to-end in memory. However,
simplistic versions of this memory access pattern might cause the results to
be skewed by pre-fetch caching hardware. Although these issues can be
addressed, care must be taken to tailor buffers, gaps, and total data so that
cache levels are cleared while avoiding virtual memory paging.
The cache cannot be removed or defeated for an empirical
assessment because caching behavior has a significant positive impact
on the performance of modern systems. For example, an algorithm
designed to have a good locality of reference to take advantage of
caching and pre-caching architectures would perform significantly
worse if the cache is disabled than it would in actual practice. In
addition to data cache effects, modern processors are affected
significantly by branch prediction. Modern branch prediction is based
on local and global historical branch activity, meaning that warming
up the processor on data that is significantly different than the test
data can result in some performance difference. Most of the
performance of modern systems relies on caching, branch prediction,
and related capabilities.
Our primary interest is to understand the performance of EXI algorithms
independently of I/O related factors. Therefore, the benchmarking framework
attempts to accurately model the code paths and memory access patterns of
real applications to the extent possible while minimizing the cost of I/O,
blocking, context switches, etc. To factor out the majority of the I/O,
blocking and context switching costs associated with network I/O, we use a
local loopback interface. The local loopback reads and writes all data
through local memory instead of a physical network, essentially modeling a
memory-speed network. This approach uses the same buffering algorithms, code
paths and memory access patterns as a real-world application, reproducing
realistic caching effects without warming-up the input data. At the same
time, since it's memory-speed, the interface will probably provide data faster than
an EXI algorithm can consume it. This way, the algorithm remains CPU bound
throughout the duration of the test and is not subject to I/O related
blocking or context switching. The resulting benchmarks show the processing
efficiency of the EXI algorithm isolated from the speed or I/O effects of a
particular network.
The benchmarks that are likely to most accurately reflect the
performance of real EXI applications are those that include I/O to
some external media, like a network or file system. EXI is about
interchange, so most EXI use cases will read or write EXI documents to
and from devices that are often slower than main memory (i.e.,
networks or storage media) although there are important cases of
memory to memory interchange.
Therefore, the benchmarks that are likely to most
accurately model real-world performance for many cases will be those
that read and write EXI documents to and from networks and storage
devices. Careful
scrutiny is needed, especially when not using a loopback interface, to
detect bandwidth bottlenecks that are smaller than the throughput of
algorithms being tested. These benchmarks are expected to accurately model the
interaction between the caching algorithms employed by modern
computing architectures and the memory access patterns of buffering
algorithms employed by typical device drivers. They also are expected to accurately
model the subtle, but significant performance implications of blocking
and context switching that occur as algorithms shift repeatedly
between CPU and I/O. For a given platform and use case, the average
time spent doing context switches and being I/O-bound vs. CPU-bound
will differ from one EXI format to another. It will be influenced by a
variety of factors, including the average throughput of the EXI
algorithm, the average throughput of the I/O device, and the
compactness of the EXI format. It must be noted however that this
interaction with operating system characteristics may not be
deterministic.
The determinism of a trial may be subject to particular buffer
sizes or other details that are not obvious. Therefore, for higher
confidence, a comparison might be needed between a network-intermediated
trial and a cache-clearing, memory to memory trial.
To look more closely at those effects of the network, in a real-world-
like setting, the framework has been extended to measure the performance of
EXI algorithms reading and writing from any TCP/IP based network (e.g., Wired
LAN, WI-FI LAN, Internet, GPRS, etc.). This will enable us to collect
benchmarks using the same network media, buffering algorithms, device drivers,
and code paths employed by EXI use cases. As such, it replicates the memory
access patterns, blocking patterns, context switches, etc. of, at least,
TCP/IP based real-world applications. However, although the group has developed
this part of the framework, it has not yet been used to take any official measurements
(see Appendix C: Further Work -
Framework Network Driver).
4.5. Native Language Implementation Considerations
Submitted: 11-may, ED. Integrated: 13-May, GW. Status: 1st edit, some
questions and rewordings need confirmation.
Some of the candidates currently being considered as a basis for an EXI
standard only have C or C++ implementations, as opposed to Java, available at
this time. In order to test the processing efficiency of these candidates
using Japex, the framework was augmented to provide a driver API through the
Java Native Interface (JNI), that allows non-Java applications to be
benchmarked.
The JNI is used in such a way as to isolate the performance of the C/C++
implementation from the Java processing in the Japex framework. This is done
by doing all of the timing on the native (i.e. C/C++) side of the interface.
Clearly, there will be some residual systematic effect, since at least a JVM
is cohosted, but we believe that effect is negligible.
However, the processing efficiency timing results that are produced cannot
not be directly compared with results for Java candidate implementations for
several reasons:
- There is no "JVM effect" in C/C++. One would expect processing times to
be somewhat faster since no byte code interpretation is required and
there are fewer overhead tasks such as garbage collection (though of
course an algorithm implemented in native code will also have to do
housekeeping). The actual amount of this speedup is not known in detail,
since we do not yet have any candidate with isomorphic implementations in
both Java and C/C++. In further work, we may try to evaluate whether this
fraction, the amount of speedup, is what we would expect for comparable
applications (see Appendix C: Further
Work)
- The methodology for getting events into the
native applications for processing is different. Since it is not
practical to feed Java Events across the JNI boundary for processing, and
no existing implementation of a SAX-like typed-event API could be found, an alternative to
the SAX and typed-SAX APIs which are used for Java was required. One
method that is currently being used is to construct a DOM tree from an
XML source and then to use this tree to populate objects for
serialization into the candidate binary format. For deserialization, the
time to deserialize from the binary format to objects is measured. Two of
the native formats are those based ASN.1 and the objects are those of
classes generated by compiling the ASN.1 schema.
- Different implementation types. At least two known candidates that
currently have C/C++ implementations use data binding technologies as
opposed to the more standard interpretive XML technologies. Data binding
produces tightly coupled, very performant applications by building
information directly from schemas into the compiled native code. The XML
Screamer application [Screamer] has used this
technology to produce impressive performance results with XML.
For these reasons, it might not be highly accurate to compare native
implementations with their Java counterparts for processing efficiency.
Instead, a comparison is done with existing C/C++ based XML
implementations. One such implementation is the open source libxml2 library
(http://xmlsoft.org), a highly performant implementation available in
most Linux distributions. Libxml2 doesn't resolve all issues; for
instance, it does not provide data binding.
[ we need to point to the libxml2,
and the native candidate implementations, in the japex results; or if libxml2
is not measured in this 1st draft, either remove above reference or say that
libxml2 measurements will be added]
SW (w/PS): Write APIs of Primary Interest section
4.6. Fidelity Considerations
Submitted: 8-May, PS. Integrated: 10-May, GW. Edited: 1st pass 10-May, GW.
Some items needed: 1. Short introduction - what is fidelity and why is it
needed, or at least why does it need to be evaluated. 2. Explanation of why
this section is included in the document. We don't at the moment evaluate
fidelity - so why include the taxonomy on which it would be measured?
In this section we also describe a taxonomy with which the group can evaluate
the extent to which each EXI format candidate satisfies the lexical
reproducibility requirements of the examples in the test suite .
The degree to which a candidate can accurately reproduce the information
represented by a test group is determined jointly by the following:
- properties of the candidate. For example, candidates may not be able to
support the preservation of certain information or support the
preservation of information with only a particular fidelity
- properties of the test group and more broadly the use cases to which
the test group belongs. For example, test groups that contain signed
information (as specified by W3C XML-Signature Syntax and
Processing [XML Signature]) may require
higher fidelity to the original than test groups that contain no signed
information.
To characterize the extent to which each candidate preserved the
information necessary for a test group, each test group was annotated with
what information must be preserved, and with what accuracy, to satisfy the
particular requirements of that case.
A "round trip support" measurement property of the test framework will be
used to determine whether the candidate accurately reproduced the information
represented by each test group, according to the annotation. If the result of
this measurement was that the candidate did not reproduce the information
with the required fidelity, or it is predetermined to fail
without running the test, then the candidate was determined to have failed
the round-trip support measurement property for that test group, and
additionally failed for all other measurement properties that utilize the
test case.
The fidelity requirements were communicated to the test framework, and to
each candidate under test, through japex parameters. Those parameters
prescribed what did and did not need to be preserved. Candidates were free to
examine the parameters to optimize their encoding. For example, if
preservation of comments and processing instructions was not required, as is
the case for SOAP message infosets, then a candidate might utilize that
knowledge to encode SOAP message infosets more efficiently than if it could
not make such a narrowing assumption.
The following information represented by a test group does not need to be
preserved by a candidate:
- the XML declaration
- the use of single or double quotes characters for quoted strings
- markup white space.
It is not anticipated nor expected that candidates will accurately
reproduce information on a syntactic or byte-per-byte basis [see fidelity
scales 3 and 4].
The following subsections present the distinct sets of information that
may or may not be preserved by a candidate.
4.6.1.1. Preservation of white space
If a white space needs to be preserved then all non-markup white space
information [see 2.10 White Space Handling, XML 1.0] represented by the test
group MUST be preserved. Otherwise, all non-ignorable white space information
MUST be preserved. Such non-ignorable white space information may be
determined from a schema, if present with the test case, and/or by inspection
of the test group.
4.6.1.2. Preservation of comments
If comments need to be preserved then all comment information represented
by the test group MUST be preserved. Otherwise, comment information need not
be preserved.
4.6.1.3. Preservation of processing instructions
If processing instructions need to be preserved then all processing
instruction information represented by the test group MUST be preserved.
Otherwise, processing instruction information need not be preserved.
4.6.1.4. Preservation of namespace prefixes
If namespace prefixes need to be preserved exactly then all namespace
prefix information represented by the test group MUST be preserved verbatim.
Otherwise, namespace prefix information need not be preserved identically.
The verbatim preservation of namespace prefixes is important when a test
group contains signed information or prefixes as part of a qualified name
information in element content or attribute values. Preservation of namespace
prefixes is important in any case to maintain document validity and
correctness.
4.6.1.5. Preservation of lexical values
If lexical values need to be preserved then all character data (see
Extensible Markup language (XML) 1.0 [XML 1.0]
section 2.4 Character Data and Markup) information represented by the
test group must be preserved. Otherwise, lexical values need not be
preserved.
Lexical values may not be fully preserved if a candidate chooses to encode
a lexical value into a more efficient lexical value, or in binary form, and
the original lexical value cannot be reproduced. For example, the decimal
lexical value of "+1.0000000" might be converted to the more efficient
canonical decimal lexical value "1.0". Similarly, the boolean lexical value
"1" might be converted to binary form as one bit of information and it may
not be determinable from the binary form whether the original lexical value
was "true" or "1".
4.6.1.6. Preservation of the document type declaration
and internal subset
If the document type declaration and internal subset need to be preserved
then the document type declaration and internal subset information
represented by the test group must be preserved. Otherwise, document type
declaration and internal subset need not be preserved.
4.6.2. Fidelity Scale
Candidate formats, and test groups, can be classified according to a
"scale of fidelity". For formats, the scale is a metric of the extent to
which information is preserved with respect to various XML data models. For
test groups the same scale is used to classify the requirement the of the
test group for round-trip accuracy. We defined it to go in order of
increasing fidelity. A candidate which has been determined to score at a
certain level on the scale may still preserve some, but not all, information
specified at higher levels.
Note that this does not imply that documents produced by candidates have
an isomorphic representation of the information represented by certain XML
data models, rather that a candidate stores enough information to be able to
reproduce the preserved information.
Table 1: The Fidelity Scale for Classification of EXI
Candidates
| Level |
Preserves |
| -1 |
Preserves only a subset of the XPath data model
Level -1 defines the class of candidates that preserve a subset of
the XPath 1.0 data model. For example, a candidate might not preserve
namespace prefixes.
|
| 0 |
Preserves the XPath data model
Level 0 defines the class of candidates that preserve the XPath
1.0 data model.
Such preservation includes the root node, elements, text nodes,
attributes (not including namespace declarations), namespaces,
processing instructions and comments.
Unexpanded entities, the document type declaration and the
internal subset are not preserved.
This level corresponds to a common denominator in XML processing,
it is equivalent to the SOAP XML subset with the addition of
processing instructions and comments.
|
| 1 |
Preserves the XML Information Set
Level 1 defines the class of candidates that preserve the XML
Information Set data model.
The XML Information Set preserves more of the information
represented in the document type declaration and internal subset than
the XPath 1.0 data model but not all information, such as attribute
and element declarations, is preserved.
The [all
declarations processed] property of the Document
Information Item is not, strictly speaking, part of the Infoset
[XML Infoset] and therefore does
not need to be preserved.
NOTE: A candidate can fully support level 1, level 2, and the
preservation of the complete internal subset by including and
encoding the internal subset as a string, thereby leaving it up to
the decoder to optionally process it.
|
| 2 |
Preserves the the XML Information Set and all
declarations
Level 2 defines the class of candidates that preserve the XML
Information Set data model, as in level 1, in addition to all
information that is not purely syntactic. Such additional information
will include the attribute, element and entity declarations.
This level covers the preservation of all information represented
by an XML document but does not accede to supporting purely syntactic
constructs.
NOTE: A candidate can fully support level 2 by including and
encoding the internal subset as a string, and thus leaving it up to
the decoder to optionally process it.
|
| 3 |
Preservation of syntactic sugar of the XML document
Level 3 defines the class of candidates that preserves all
information represented by an XML document, as in level 2, in
additional to some but not all syntactic information.
NOTE: Full syntactic information is supported by level 4.
Such preservation includes but is not limited to:
- CDATA Sections
- resolved external entity reference boundaries (when an entity
is resolved a candidate will flag the part in the produced
infoset where the information included from it starts and
ends)
- the use of single or double quotes characters for quoted
strings
- white space in markup
- the difference between empty element variants
- the order of attributes.
|
| 4 |
Preservation of bytes
Level 4 defines the class of candidates that preserve the XML
document byte-per-byte.
NOTE: This is the simple level supported by generic encodings such
as gzip.
|
5. Contributed Candidate EXI Implementations
This section provides a technical description of the basic architecture of
each of the contributed XML formats whose performance characteristics were
measured (see Results). The statements in these
descriptions are those of representatives of each format and not necessarily
agreed upon statements by the working group.
5.1. X.694 ASN.1 with BER
Submitted: 25-Apr, ED. Integrated: 25-Apr, GW. Edited: partly edited for
content 25-Apr, GW.
The X.694 ASN.1 BER candidate submission uses a set of standards that have
been in place for many years for binary messaging (ASN.1 itself since the
early 1980s). There are three parts to the candidate:
- The Abstract Syntax Notation 1 (ASN.1), from the International
Telecommunications Union - Telecommunications Group (ITU-T), and the
International Standards Organization (ISO), is a schema much like the XML
Schema for describing abstract message types
- The ITU-T/ISO Basic Encoding Rules (BER), is a set of encoding rules to
be used with ASN.1 to produce a concrete binary representation of a set
of values described using an ASN.1 schema
- The ITU-T/ISO X.694 standard provides a mapping of XML Schema (XSD) to
ASN.1, and allows the use of ASN.1 and its associated encodings in XML
applications.
In this format candidate, BER encoding was selected in preference to PER
(Packed Encoding Rules - see X.694 ASN.1 with
PER below) because it was felt that the flexibility in the
tag-length-values (TLV) that it provides, is closer in spirit and
functionality to XML than the tightly coupled encodings produced by PER. The
general principle is that each element construct in XML;
<tag>textual content</tag>
is replaced by a similar binary encoding consisting of a tag-length-value
descriptor.
Efficiencies are gained from two properties of this format: 1) the tags
and lengths are binary tokens that are in general much shorter than XML
textual start and end tags, and 2) the content is in binary instead of
textual form.
Some advantages of using ASN.1 BER to encode XML are that the TLV format
is similar to XML's start-tag / content / end-tag pattern; encoded
length can be 5 to 10 times less than textual XML, and encoding and decoding
is very efficient - no compression or other CPU intensive algorithms are
used. Additionally, ASN.1 BER is mature and stable, and its security has been
studied in-depth.
However, it is schema-based - an XSD or similar schema is needed to encode
and decode, and some fraction of the XML Information Set can not be
represented (for example, randomly occurring comments and Processing
Instructions).
See references [USE-OF-ASN.1], [ASN.1], [BER], [X.694].
Submitted: 15-May, PT. Integrated: 16-May, GW. Edited: 1st pass. Needs to be
checked by Paul, changed quite a lot.
5.2. X.694 ASN.1 with PER
Similarly to the X.694 ASN.1 with
BER candidate format described above, this one uses X.694 to map from an
XML Schema document to ASN.1. In this variation, we add the use of two
further ITU-T standards, X.693 and PER. These additions allow direct output
in textual XML, and a somewhat more compact binary encoding.
PER, which stands for Packed Encoding Rules [PER],
is one of the ASN.1 Encoding Rules published by the ITU-T, IEC, and ISO. PER was specifically designed to minimize
the size of messages needed to convey information between machines. It has
been widely adopted in critical infrastructure where bandwidth is limited. It
originated from work on an efficient air-to-ground communication protocol for
commercial aviation, and has since been used in many areas including cell
phones, internet routers, satellite communications, internet audio/video, and
many other areas.
Another of the ASN.1 Encoding Rules, Extended XML Encoding Rules, or
"EXTENDED-XOR" [X.693], defines a set of encoding
rules, that can be used in a way analogous to XML Schema, and applied to
ASN.1 types to produce textual XML.
Since the schema notation used by XML Schema is quite different from the
ASN.1 notation, ITU-T Rec. X.694 | ISO/IEC 8825-5 was created to give a
standard mapping from schemas in XML Schema to ASN.1 schemas in such a way
that XML Schema aware endpoints, could exchange documents with ASN.1 aware
endpoints, using the EXTENDED-XER Encoding Rules.
With the ASN.1 schema generated using X.694 from an XML Schema instance,
one can generate not only XML documents (using the ASN.1 engine with
EXTENDED-XER), but binary encodings with any of the ASN.1 Encoding Rules, of
which PER is the most compact.
Submitted: 25-Apr, JK. Integrated: 29-Apr, GW. Edited: style & content
29-Apr.
5.3. Xebu
The Xebu format
is a product of research into XML messaging on small mobile devices. The
central XBC Properties considered in its design were; Streamable, Small
Footprint, and Implementation
Cost.
Xebu models an XML document as a sequence of events, similarly to StAX or
SAX. The event sequence is serialized one by one. The basic Xebu format,
applicable to general XML data, includes mappings from strings in the XML
document to small binary tokens. These mappings are discovered dynamically
during processing.
Xebu also includes three optional techniques for when a schema is
available:
- Pretokenization; this populates the token mappings beforehand, based on
the strings appearing in the schema
- Typed-content encoding; this results in a more efficient binary form
for certain data types, than can be achieved without a schema
- Event omission; this leaves out events from the sequence if their
appearance and placement can be deduced from the schema.
The main advantages of Xebu are; its support for general XML with varying
levels of schema-awareness, a direct correspondence with well-understood XML
data models, so making XML compatibility easy to achieve, and that it's
simple and straightforward to implement.
Xebu is though presently research software; the precise capabilities and
properties of the automata used for event omission are not well understood,
their generation is not straightforward, and in general Xebu's present
implementation is not fully mature.
See reference [XEBU1]
5.4. Extensible Schema-Based Compression
(XSBC)
Submitted: 29-Apr, DM. Integrated: 29-Apr, GW. Edited: partly edited for
content 29-Apr, GW. Edited 3-may. GW: 27-May, removed editorial comments
flagging editorial changes in prep for publication - so should be
checked.
Extensible Schema-Based Compression (XSBC) is a system for encoding XML
documents that are described by schemas into a binary format. The result is
more compact, faster to parse, and has better databinding performance than
textual XML.
XSBC preprocesses the schema that describes an XML document, and creates
lookup tables consisting of integers that index the string values of element
names. The schema's type information about marked-up data, if any, is
captured in one lookup table. In the same way, element attribute names are
added to a lookup table, along with their type information. The size of the
integers that correspond to the element and attribute names is chosen so that
if only a few names are in the document, smaller numbers are used.
Once the schema has been processed and the lookup tables have been
populated, the XML file is transcoded into binary format. Text element start
and end tags are replaced by the binary format whole numbers to which they
correspond in the element lookup table. Additionally, if any marked-up text
data can be represented in an equivalent binary format, such as
floating-point, it is replaced.
Element attributes are added after the binary element start tag. Attribute
representations may be only the attribute start tag, followed by the
attribute data, in binary format, if the schema type information makes this
possible.
The marked-up data in binary format, for either element data or attribute
data is then passed through data compressors. In the case of simple,
fixed-length integers and floats, the standard IEEE 754 format can be used.
Variable length data, such as strings, can be represented by a starting value
that includes the length, followed by the actual data. The data compression
system is easily extended to handle data other than that represented by the
standard data compressors, and in fact can be extended dynamically. For
instance, it's possible to write custom compressors for sparse or repetitive
matrices, floating point data which is representable in only a certain number
of significant digits, or other specialized data types.
Encoding and decoding a textual XML document to an XSBC document is quite
straightforward. A simple finite state machine can be constructed to decode
XSBC documents. An XSBC decoder can step through the document easily because
of the structure of the document.
An XML Schema instance is required to encode the document. In future, the
XSBC team plans to implement a feature in which a document without a schema
can be "pre-preprocessed" and a stand-in schema generated for it. This
stand-in schema will be untyped (all data will be represented as strings) but
this would allow an arbitrary XML document without a schema to be
represented.
XSBC's virtue is its simplicity. It is, essentially, every programmer's
first idea of how to represent an XML document in binary form. There is a
strong correspondence between the textual XML representation and the binary
representation.
5.5. Fujitsu XML Data Interchange Format
(FXDI)
Submitted: 1-May, TK. Integrated: 3-May, GW. Status: Edited, some
clarification of encoders needed. 27-May GW; removed editorial comments for
publication. Should be checked. References needed. 29-May: TK resubmitted
with clarified distinction between encoders. Text says that diff encoders are
used for compactness and PE, although my recollection is that was to be not
allowed - all properties results should be presented for all configurations.
emailed group to confirm.
The Fujitsu XML Data Interchange (FXDI) format was designed to serve as an
alternative encoding of the XML Infoset, which allows for more efficiency,
both in the exchange of data between applications and in the processing of
data at each end-point. FXDI's primary design goals were document
compactness, and to enable the implementation of fast decoder and encoder
programs, which run in a small footprint, and without involving much
complexity.
FXDI is based on the W3C XML Schema Post Schema Validation Infoset (PSVI),
though some of the format features derive from the XPath2 Data Model.
Although FXDI performs much better when schemas are prescribed before
documents are processed, it is capable of handling schema-less documents and
fragments through its support for Infoset tokenization.
At the core of FXDI is the "compact schema". FXDI uses Fujitsu Schema
Compiler to compile W3C XML Schema into a "schema corpus". A schema corpus
contains all the information expressed in the source XML Schema document plus
certain computed information such as state transition tables. A compact form
of the schema is then computed from a schema corpus by distilling only those
information items which are relevant to the function of FXDI processors.
There are two types of FXDI processors. Firstly, those that are used to
generate FXDI documents. These are called "FXDI Encoders". Conversely, FXDI
Decoders, decode FXDI documents into data usable by programs.
FXDI supports two different methods to create FXDI documents:
- An encoder API, that allows programs to convert an XML text stream or
SAX events into FXDI documents. FXDI has two independent encoder API
implementations. The "validating encoder", which has the ability to
conduct full-fledged schema validation while encoding subject to the
constraints expressed in an XML Schema. The other encoder is
non-validating. It is incapable of schema-validation, but performs much
faster than the validating encoder. Although their implementations and
techniques are very different, the two encoders always generate the same
result given an XML schema and an XML instance document
- A Direct-writing API, which is suitable in scenarios that allow for the
use of data-binding. It always performs faster than the Encoder API
because no schema-machinery is involved in the process.
In the EXI Test Framework tests, the validating encoder was used in the
compactness tests. The validating encoder carries out schema-validation as
part of encoding process and logs any errors in test case XML documents. This
is useful for diagnosing performance anomalies caused by test case documents
that deviate from their associated XML Schemas. On the other hand, the
non-validating encoder is used in the encoding tests for maximizing
processing efficiency.
FXDI works well with conventional document redundancy-based compression
such as gzip. That facilitates use cases that need the additional compression
and can spend the additional CPU cycles.
See W3C EXI WG and Fujitsu for more information.
5.6. Fast Infoset
Fast Infoset is an open, standards-based binary format based on the
XML Information Set [XML Infoset].
ITU-T Rec. X.891 | ISO/IEC 24824-1 (Fast Infoset) [FI] is also itself an approved ITU-T
Recommendation as of 14 May 2005. An ISO ballot has been initiated (and is
near completion) that will result in ISO/IEC 24824-1 being available for free
when published.
The XML Information Set specifies the result of parsing an XML document,
referred to as an "XML infoset" (or just an "infoset"), and a glossary of
terms to identify infoset components, referred to as "information items" and
"properties". An XML infoset is an abstract model of the information stored
in an XML document; it establishes a separation between data and its
representation that suits most common uses of XML. An XML infoset (such as a
DOM tree, StAX events or SAX events in programmatic representations) may be
serialized to an XML 1.x document or, as specified by the Fast Infoset
specification, may be serialized to a Fast Infoset document. Fast Infoset
documents are generally smaller in size and faster to parse and serialize
than equivalent XML documents.
The Fast Infoset format has been designed to jointly optimize the axes of
compression, serialization and parsing, while retaining the properties of
self-description and simplicity. The approach has been to find, when not
taking advantage of advanced features, a "sweet spot" where moderate
compression can be achieved but not at the undue expense of creation,
processing performance and simplicity.
The use of tables and indexing is the primary mechanism by which Fast
Infoset compresses many of the strings present in an infoset. Recurring
strings may be replaced with an index (an integer value) which points to a
string in a table. A serializer will add the first occurrence of a common
string to the string table, and then, on the next occurrence of that string,
refer to it using its index. A hash table can be used for efficient checking
of strings (the string being the key to obtaining the index; every time a
unique string is added to the hash table, the index of the table is
incremented. A parser will add the first occurrence of a common string to the
string table, and then, on the next occurrence of that string, obtain the
string by using the index into the table.
Fast Infoset is a very extensible format. It is possible, via the use of
encoding algorithms, to selectively apply redundancy-based compression or
optimized encodings to certain fragments. Using this capability, as well as
other advanced features, it is possible to tune the "sweet spot" for a
particular application domain. An example of this is the use of a built-in
encoding algorithm to directly encode binary blobs without the need for any
additional encoding, in a way similar to the Message Transmission Optimization
Mechanism(MTOM), but with the binary blobs encoded inline as
opposed to as attachments. Other built-in algorithms can be used to
efficiently encode arrays of primitive data types like integers and floats, a
feature often used by scientific applications to reduce message size and
increase processing efficiency.
Additional features of Fast Infoset include support for restricted
alphabets (for better compactness) and for external indexing tables, for
those cases in which a tighter coupling is acceptable in the interest of
achieving better performance.
5.7. Efficient XML
Submitted: 11-May, JS. Integrated: 13-May, GW. Status: Moved 1st 2 paras to
end and removed assertions that might reasonably be made of all formats
without supporting data. Also removed assertion about w3 requirements, since
that is what the data is intended to show, and again the point is to show
this for all formats.
Efficient XML is a general purpose interchange format that works well for
a very broad range of applications. It was designed to optimize performance
while reducing bandwidth, battery life, processing power and memory
requirements. It is the only format currently being tested that supports all of the features specified by the minimum binary XML requirements defined by the W3C XBC group
XML Binary Characterization
[XBC Characterization].
The encoding is schema "informed", meaning that it can leverage available
schema information to improve compactness and performance, but does not
depend on accurate, complete or current schemas to work. It will work very
effectively with partial schemas or no schemas at all. It also supports
arbitrary schema
extensions and deviations and allows dynamic schema negotiation,
discovery and acquisition.
Efficient XML achieves broad generality, flexibility, and performance, by
unifying concepts from formal language theory and information theory into a
single, relatively simple algorithm. The algorithm uses a grammar to
determine what is likely to occur in an XML document and encodes the most
likely alternatives in fewer bits. The fully generalized algorithm works for
any language that can be described by a grammar (e.g., XML, Java, HTTP,
etc.); however, Efficient XML is optimized specifically for XML languages.
The built-in Efficient XML grammar accepts any XML document or XML fragment
and may be augmented with productions derived from XML Schemas, RelaxNG
schemas, DTDs or other sources of information about what is likely to occur
in a set of XML documents. The Efficient XML encoder uses the grammar to map
a stream of XML information items onto a smaller, lower entropy, stream of
tokens. The encoder then encodes the stream of tokens using a Huffman tree
derived from the grammar or, if additional compression is desired, passes the
stream of tokens to a more sophisticated XML compression algorithm that
replaces frequently occurring token patterns to further reduce size. When
schemas are used, Efficient XML also supports a user-customizable set of
datatype CODECs for efficiently encoding typed values and provides typed
streaming APIs for efficiently accessing typed values.
The binary form of Efficient XML is very compact. It is competitive
with hand-optimized formats and is consistently smaller than both
ASN.1 PER and gzipped XML. Even on very large, repetitive documents
where gzip works best, it is not uncommon for Efficient XML to be 2-5
times smaller than gzipped XML.
The Efficient XML implementation used for W3C tests is a
non-production implementation designated for evaluating W3C-proposed
changes to Efficient XML. In addition to implementing the minimum W3C
requirements, it includes the format features required to support
advanced requirements, such as random access, accelerated sequential
access and digital signatures. As a non-production version it has not
been fully optimized. For example, the SAX API used for W3C
performance tests sits above a translation layer that copies every
character information item in a XML document from the String format
generated by the underlying StAX API to char[] arrays required by
SAX. Future versions of this implementation will improve its
performance.
Production implementations of Efficient XML have been integrated
into a broad range of platforms, including mass market mobile phones,
PDAs, application servers, web servers, high-volume message routers,
pub-sub systems, vehicles, aircraft, and satellite broadcast
systems. High quality, commercial implementations are available for
Unix, MS-Windows and a wide variety of mobile devices running both
Java and Microsoft.NET.
See Theory, Benefits and Requirements for Efficient Encoding of XML
Documents [EffXML] for more
information.
6. Summary and Analysis of Test Results
Since this work is still in progress, the intermediate measurement
results and preliminary analysis are to be found in the
Analysis of the EXI Measurements) page. At the time of publication of this first draft,
those results are subject to change at any time.
6.1. Compactness
A summary of the results of overall compactness, for each format,
will be given here, for each of the notional configurations given in
the above section
on Characterization of
Compactness. These results will be compared to the compactness thresholds defined by the XBC Measurements Methodology document.
6.2. Processing Efficiency
A summary of the results will be given here for the speed of
processing, for each format, in each of the
aggregations above. Additionally, we will
note the Linearity of performance of each format, and its memory
usage. See the section Characterization of
Processing Efficiency for the definition of these figures.
If results clearly correlate significantly with components of
complexity other than size or information density (see
the Components of XML Complexity), we
will characterize that relationship.
7. Conclusions
At the time of writing of this first draft, it is too early to give
conclusions drawn from the test results. This draft Note is being
published to encourage review and comment as this work continues.
8. Bibliography
- [XBC Use Cases]
- XML Binary
Characterization Use Cases, Mike Cokus, Santiago
Pericas-Geertsen editors, World Wide Web Consortium, 31 March 2005.
http://www.w3.org/TR/xbc-use-cases/.
- [XBC Properties]
- XML Binary
Characterization Properties, Oliver Goldman, Dmitry Lenkov
editors, World Wide Web Consortium, 31 March 2005.
http://www.w3.org/TR/xbc-properties/.
- [XBC Measurements]
- XML Binary
Characterization Measurement Methodologies, Stephen D.
Williams, Peter Haggar editors, World Wide Web Consortium, 31 March
2005. http://www.w3.org/TR/xbc-measurement/.
- [XBC Characterization]
- XML Binary
Characterization, Oliver Goldman, Dmitry Lenkov
editors, World Wide Web Consortium, 31 March
2005. http://www.w3.org/TR/xbc-characterization/.
- [Screamer]
- XML
Screamer: An Integrated Approach to High Performance XML Parsing,
Validation and Deserialization, Margaret G. Kostoulas et al,
proceedings of the 15th International World Wide Web Conference, May
2006. http://www2006.org/programme/item.php?id=5011.
- [MTOM]
- SOAP Message
Transmission Optimization Mechanism, Martin Gudgin, Noah
Mendelsohn, Mark Nottingham, Hervé Ruellan editors, World Wide Web
Consortium, January 2005. Latest version
http://www.w3.org/TR/soap12-mtom/.
- [XOP]
- XML-binary
Optimized Packaging, Martin Gudgin, Noah Mendelsohn, Mark
Nottingham, Hervé Ruellan editors, World Wide Web Consortium, January
2005. Latest version http://www.w3.org/TR/xop10/.
- [WSRF]
- Web Services Resource
Framework (WSRF), Globus Alliance, OASIS,
April 2006.
- [Engelen]
- Pushing the
SOAP Envelope With Web Services for Scientific Computing.
Robert van Engelen, ICWS 2003.
- [gSOAP]
- The gSOAP
Toolkit for Web Services and Peer-To-Peer Computing
Networks. Robert van Engelen, Kyle A. Galliva. Proceedings
of the 2nd International Symposium on Cluster Computing and the GRID,
2002.
- [Chiu]
- Investigating
the Limits of SOAP Performance for Scientific Computing. K.
Chiu, M. Govindaraju, and R. Bramley. Proceedings
of 11th HPDC, pp 246-254. July 2002.
- [NUX]
- NUX - Efficient and Powerful
XML Processing Made Easy. Distributed Systems Department, Lawrence
Berkeley National Laboratory. http://dsd.lbl.gov/nux/
- [BXML]
- BXML-CWXML Home
page. CubeWerx. http://www.cubewerx.com/main/cwxml/.
- [Abu-Ghazaleh]
- Differential
Serialization for Optimized SOAP Performance, Nayef
Abu-Ghazaleh, Michael J. Lewis, Madhusudhan Govindaraju. Proceedings of
the 13th HPDC, pp 55-64, June 2004. Describes bSOAP.
- [BXSA]
- A Binary
XML for Scientific Applications. Kenneth Chiu, Tharaka
Devadithya, Wei Lu, Aleksander Slominski.
- [DET-COMPLEXITY]
- Determining
the Complexity of XML Documents, Mustafa H. Qureshi, M. H.
Samadzadeh, ITCC'05.
http://ieeexplore.ieee.org/iel5/9755/30769/01425179.pdf.
- [USE-OF-ASN.1]
- The Use
of ASN.1 Encoding Rules for Binary XML, Ed Day, Objective System Inc.,
http://www.obj-sys.com/docs/ASN1forBinXML.pdf.
- [ASN.1]
- Information
technology — Abstract Syntax Notation One (ASN.1): Specification
of Basic Notation [The ASN.1 Standard (ITU-T Rec. X.680)],
International Telecommunication Union (ITU), July 2002.
http://www.itu.int/ITU-T/studygroups/com17/languages/X.680-0207.pdf.
- [BER]
- Information
technology — ASN.1 encoding rules: Specification of Basic
Encoding Rules (BER), Canonical Encoding Rules (CER) and Distinguished
Encoding Rules (DER) [The ASN.1 BER Standard (ITU-T Rec
X.690)], International Telecommunication Union (ITU), July 2002.
http://www.itu.int/ITU-T/studygroups/com17/languages/X.690-0207.pdf.
- [PER]
- Information
Technology - ASN.1 Encoding Rules: Specification of Packed Encoding
Rules (PER) [The ASN.1 PER Standard (ITU-T Rec X.691 |
ISO/IEC 8825-2)], International Telecommunication Union (ITU), July
2002.
http://www.itu.int/ITU-T/studygroups/com17/languages/X.691-0207.pdf.
- [X.694]
- Information
technology — ASN.1 encoding rules: Mapping W3C XML schema
definitions into ASN.1 [ITU-T Rec X.694], International
Telecommunication Union (ITU), January 2004.
http://www.itu.int/ITU-T/studygroups/com17/languages/X694.pdf.
- [X.693]
- Information
technology — ASN.1 encoding rules: XML Encoding Rules
(XER) [ITU-T Rec X.693], International Telecommunication
Union (ITU), December 2001.
http://www.itu.int/ITU-T/studygroups/com17/languages/X.693-0112.pdf.
This work is also standardized by ISO/IEC 8825-4 (with Amendment
1).
- [XEBU1]
- Xebu: A Binary Format with
Schema-based Optimizations for XML Data, Jaakko
Kangasharju, Sasu Tarkoma,
and Tancred
Lindholm. In 6th International
Conference on Web Information Systems Engineering, Lecture Notes in Computer Science 3806, Springer-Verlag, November
2005. http://dx.doi.org/10.1007/11581062_44.
- [XML Signature]
- XML-Signature
Syntax and Processing, Donald Eastlake, Joseph Reagle, David
Solo editors, World Wide Web Consortium, 12 February 2002. Latest
version http://www.w3.org/TR/xmldsig-core/.
- [XML 1.0]
- Extensible Markup
Language (XML) 1.0, Tim Bray et al editors, World Wide Web
Consortium, 4 February 2004 (Third Ed). Latest version
http://www.w3.org/TR/REC-xml/.
- [XML Infoset]
- XML
Information Set, John Cowan, Richard Tobin editors, World
Wide Web Consortium, 4 February 2004 (Second Ed). Latest version
http://www.w3.org/TR/xml-infoset/.
- [FI]
- ITU-T Rec. X.891
| ISO/IEC 24824-1 (Fast Infoset), International
Telecommunication Union (ITU), May 2005.
http://www.itu.int/rec/T-REC-X.891/.
- [EffXML]
- Theory,
Benefits and Requirements for Efficient Encoding of XML
Documents, AgileDelta, Inc.
http://www.agiledelta.com/EfficientXMLEncoding.htm.
- [JAPEX]
- Japex
Manual, Santiago Pericas-Geertsen, java.net, April 2006.
https://japex.dev.java.net/docs/manual.html.
- [CN]
- HTTP/1.1
Content Negotiation, R. Fielding et al, World Wide Web
Consortium, June 1999.
http://www.w3.org/Protocols/rfc2616/rfc2616.html.
- [FXDI]
-
W3C EXI WG and Fujitsu,
Takuki Kamiya, Fujitsu, June 2006.
http://software.fujitsu.com/en/interstage-xwand/activity/xbrltools/indexFXDI.html.
9. Appendices
9.1. Appendix A: Measurement Details
Until the measurements stabilize, please refer to the Analysis of the EXI Measurements for up-to-date status of the measurements system
implementation, and the status of each candidate under test.
9.2. Appendix B: Description of Measurements Test
Suite
Submitted: 21-May, RB. Integrated: 23-May, GW. Edited: 1st pass 23-May
Some items needed: SyncML and XMPP Instant Messaging have no test cases.
Some fidelity evaluations are missing.
The test data suite used for the measurements described in this document,
is fully described in an external addendum - the Analysis of the EXI Measurements. The test suite is
organized into "test groups". Each group consists of XML document examples
which pertain to the same vocabulary, or to related applications of XML. For
each group, information is provided on the type of data it contains, and on
the use cases from XML
Binary Characterization Use Cases [XBC Use
Cases] to which it relates.
The test suite presently contains more than 10,000 documents.
9.3. Appendix C: Further Work
- Scenarios: A "scenario" is the
systematic implementation of some XML system, congruent to a given
use-case. That is, it is the system architecture, environment, and choice
of optimizing parameters of an implementation of an EXI format in a given
situation. To characterize the performance of various textual XML and
alternative binary formats, as they would be used in each specific
use-case environment, we would closely define the scenario for each use
case. For our testing purposes, a scenario would be encapsulated by a
japex driver and a set of japex parameters and their values.
- Streaming: We intended to measure
textual XML and binary formats in streaming scenarios.
- Native Implementation Comparison:
After looking at results for more properties, if we have to evaluate
whether a given natively implemented format and processor are
algorithmically superior to a format for which we only have a Java
implementation, we would seek other work which has made isomorphic
comparisons of Java to "C/C++" for applications with the same CPU and I/O
distribution, and compare the difference in performance in that work.
- Framework Network Driver:
Take measurements over various networks using the network drivers in
the measurements framework.
- Evaluate Advisability by Use
Case: For each (generalized) use case, use the cross-reference
of each test group to each use case, given in
the Analysis of the EXI Measurements, plus the analysis of the results for each
test group, to determine whether or not the improved results would
indicate the advisability of an EXI format for that use case. For
example, the use case Metadata in Broadcast Systems is presently
represented by 2 test groups, BCAST and CBMS. If an aggregate
relative compactness measurement over the test groups is not
competitive with any hand-coded binary formats now used in
Broadcast Systems, then improved compactness alone would be
unlikely to justify an EXI recommendation from the perspective of
the Broadcast Systems use case. This numerical evaluation might be
combined with external factors such as industry pressure for a
standard format.
- Evaluate Fidelity: Evaluate
candidates on the metric of fidelity outlined in Table 1 to evaluate the XBC property of Roundtrip
Support.
9.4. Appendix D: Scenario for
Interoperability of XML and EXI using HTTP
This appendix describes a simple scenario for the transfer of a new
application level file format over HTTP. We illustrate the case for a binary
file format whose content corresponds to equivalent XML (which we'll call
here 'EXI'), as this document describes, but the description is not
necessarily confined to that objective. Nor is this intended to be a
normative account. However, this is the scenario presently used in commercial
production situations by some of the candidate format contributions described
above.
In a heterogeneous distributed system consisting of clients and services
that produce and consume textual XML, it would be important when introducing
an EXI format to ensure that XML interoperability is not unduly affected.
Since at any time, some but not all of the clients or services might support
an EXI format, we would like that in a single HTTP interoperation between two
nodes, they use EXI if they both understood it, and their configurations
allowed it, but to use textual XML otherwise.
The HTTP 1.1 protocol specifies a feature called "agent-driven
negotiation" (See [CN], part 12.2).
This feature may be used to determine whether an HTTP client and service are
capable of communicating using XML or an EXI format, and furthermore to make
the interoperation based on the optimal capabilities of each.
Agent-driven negotiation is driven from the client. The client request
informs the service of its capabilities and the service will respond
according to its own capabilities which are compatible with the client.
The "Accept request-header field" ([CN],
part 14.1)
can be used to specify certain media types which are acceptable for the
response.
If a client that did support XML and EXI formats performed an HTTP GET, it
would include in the GET request an Accept request-header field containing
the XML mime type and an EXI format MIME type. The service processing the
request knows that the client accepts XML and the EXI format, and that either
is acceptable for the response.
If a client that did support XML and EXI formats performed an HTTP POST,
then there would be two possibilities.
First, the client might assume that the service did support the EXI
format, and send the request in the EXI format. If the service did not
support the EXI format then it would return an HTTP 415 error, unsupported
media type, and the client would fall back to XML for a second and subsequent
requests.
Second, the client can assume the service did not support the EXI
format. It would then send the request in XML, and include an Accept
request-header field containing the XML mime type and the EXI format MIME
type. The service then knows that the client supports the EXI format and if
it were capable of EXI then it would reply using the EXI format. Otherwise
the service would reply using XML. For the second and subsequent requests the
client would use the format in which the server replied to the first request,
so if the server replied using the EXI format then the second and subsequent
requests would be sent using the EXI format.