
Multimodal Architecture and Interfaces
W3C Working Draft 22 April 2005
- This version:
- http://www.w3.org/TR/2005/WD-mmi-arch-20050422/
- Latest version:
- http://www.w3.org/TR/mmi-arch/
- Previous version:
- (this is the first publication)
- Editor:
- Jim Barnett, Aspect Communications
- Contributors:
- Jonny Axelsson, Opera
- Michael Bodell, Tellme Networks
- Brad Porter, Tellme Networks
- Dave Raggett, W3C/Canon
- TV Raman, IBM
- Andrew Wahbe, VoiceGenie
Copyright
© 2005 W3C®
(MIT, ERCIM,
Keio), All Rights Reserved.
W3C liability,
trademark
and document
use rules apply.
Abstract
This document describes a loosely coupled architecture for
multimodal user interfaces, which allows for co-resident and
distributed implementations, and focuses on the role of markup and
scripting, and the use of well defined interfaces between its
constituents.
Status of this document
This section describes the status of this document at
the time of its publication. Other documents may supersede this
document. A list of current W3C publications and the latest
revision of this technical report can be found in the
W3C technical reports index
at http://www.w3.org/TR/.
This document is the First Public Working Draft for review by
W3C Members and other interested parties, and has been developed
by the Multimodal Interaction
Working Group (W3C
Members Only) of the W3C Multimodal Interaction Activity. It is a first draft, introducing basic concepts
and components, which will be fleshed out in more detail in subsequent
drafts. Future versions of this document will specify concrete
interfaces and eventing models, while related documents will address
the issue of markup for multimodal applications. In particular we
will address the issue of markup for the Markup Container and
Interaction Manager, either adopting and adapting existing languages
or defining new ones for the purpose.
Comments for this specification are welcomed and should have a
subject starting with the prefix '[ARCH]'. Please send them to
<www-multimodal@w3.org>,
the public email list for issues related to Multimodal. This list
is archived
and acceptance of this archiving policy is requested automatically
upon first post. To subscribe to this list send an email to
<www-multimodal-request@w3.org>
with the word subscribe in the subject line.
For more information about the Multimodal Interaction Activity,
please see the Multimodal Interaction
Activity statement.
This document was produced under the
5
February 2004 W3C Patent Policy. The Working Group maintains
a public list
of patent disclosures relevant to this document; that page also
includes instructions for disclosing [and excluding] a patent. An
individual who has actual knowledge of a patent which the individual
believes contains Essential Claim(s) with respect to this specification
should disclose the information in accordance with
section 6 of the W3C Patent Policy.
Publication as a Working Draft does not imply endorsement by the
W3C Membership. This is a draft document and may be updated, replaced
or obsoleted by other documents at any time. It is inappropriate to
cite this document as other than work in progress.
Table of Contents
1. Overview
This document describes the architecture of the Multimodal
Interaction (MMI) framework and the interfaces between its
constituents. The MMI Working Group is aware that multimodal
interfaces are an area of active research and that commercial
implementations are only beginning to emerge. Therefore we do not
view our goal as standardizing a hypothetical existing common
practice, but rather providing a platform to facilitate innovation
and technical development. Therefore the aim of this design is to
provide a general and flexible framework providing interoperability
among modality-specific components from different vendors - for
example, speech recognition from one vendor and handwriting
recognition from another. This framework places very few
restrictions on the individual components or on their interactions
with each other, but instead focuses on providing a general means
for allowing them to communicate with each other, plus basic
infrastructure for application control and platform services.
Our framework is motivated by several basic design goals:
- Encapsulation. The achitecture should make no assumptions about
the internal implementation of components, which will be treated as
black boxes.
- Distribution. The architecture should support both distributed
and co-hosted implementations.
- Extensibility. The architecture should facilitate the
integration of new modality components. For example, given an
existing implementation with voice and graphics components, it
should be possible to add a new component (for example, a
biomentric security component) without modifying the existing
components.
- Recursiveness. The architecture should allow for nesting, so
that an instance of the framework consisting of several components
can be packaged up to appear as a single component to a
higher-level instance of the architecture.
- Modularity. The architecture should provide for the separation
of data, control, and presentation.
Even though multimodal interfaces are not yet common, the
software industry as a whole has considerable experience with
architectures that can accomplish these goals. Since the 1980s, for
example, distributed message-based systems have been common. They
have been used for a wide range of tasks, including in particular
high-end telephony systems. In this paradigm, the overall system is
divided up into individual components which communicate by sending
messages over the network. Since the messages are the only means of
communication, the internals of components are hidden and the
system may be deployed in a variety of topologies, either
distributed or co-located. One specific instance of this type of
system is the DARPA Hub Architecture, also known as the Galaxy
Communicator Software Infrastructure [GALAXY]. This is a distributed,
message-based, hub-and-spoke infrastructure designed for
constructing spoken dialogue systems. It was developed in the
late 1990's and early 2000's under funding from DARPA. This
infrastructure includes a program called the Hub, together with
servers which provide functions such as speech recognition,
natural language processing, and dialogue management. The servers
communicate with the Hub and with each other using key-value
structures called frames.
Another recent architecture that is relevant to our concerns is
the model-view-controller (MVC) paradigm. This is a well known
design pattern for user interfaces in object oriented programming
languages, and has been widely used with languages such as Java,
Smalltalk, C, and C++. The design pattern proposes three main
parts: a Data Model that represents the underlying logical
structure of the data and associated integrity constraints, one or
more Views which correspond to the objects that the user
directly interacts with, and a Controller which sits
between the data model and the views. The separation between data
and user interface provides considerable flexibility in how the
data is presented and how the user interacts with that data. While
the MVC paradigm has been traditionally applied to graphical user
interfaces, it lends itself to the broader context of multimodal
interaction where the user is able to use a combination of visual,
aural and tactile modalities.
2 Design versus Run-Time considerations
In discussing the design of MMI systems, it is important to keep
in mind the distinction between the design-time view (i.e., the
markup) and the run-time view (the software that executes the
markup). At the design level, we assume that multimodal
applications will take the form of mixed-markup documents, i.e.,
documents that contain markup in multiple namespaces. In many
cases, the different namespaces and markup languages will
correspond to different modalities, but we do not require this. A
single language may cover multiple modalities and there may be
multiple languages for a single modality.
At runtime, the MMI architecture features loosely coupled
software constituents that may be either co-resident on a device or
distributed across a network. These constituents may be defined in
a single document or distributed across multiple documents. In
keeping with the loosely-coupled nature of the architecture, the
constituents do not share context and communicate only by
exchanging events. The nature of these constituents and the APIs
between them is discussed in more detail in Sections 3-5, below.
Though nothing in the MMI architecture requires that there be any
particular correspondence between the design-time and run-time
views, in many cases there will be a specific software component
responsible for each different markup language (namespace).
2.1 Markup and The Design-Time View
At the markup level, there is a top-level language, called the
'Markup Container', which provides the root of the document.
Various other languages, called 'Markup Components', can be
embedded inside the Markup Container. This process is recursive, so
that any embedded language may serve as the Markup Containter for a
more deeply embedded language. This nested structure is similar to
'Russian Doll' model of Modality Components, described below in
Section 3. The Markup Container and each embedded Markup Component
will have separate namespaces. Some or all of these languages may
support scripting, but each language will have its own script
context. There may be multiple instances of a single Markup
Component language embedded in the Markup Container. In this case,
each instance of the language corresponds to a separate logical
interpreter and does not share context with the other
instances.
The different sections of markup (languages or instances of
languages) are thus loosely coupled and co-exist without
interacting directly. Note in particular that there are no shared
variables that could be used to pass information between them.
Instead, all runtime communication is handled by events, as
described below in Section 5.1 .
In some cases, a Markup Container may provide additional
facilities for sharing information that allow for a closer coupling
than that provided by the base API. As an example, a Markup
Container that supports XForms would enable Modality Components
to communicate via a common data model. Similarly, Markup Containers
that use scripting often enable Components to populate a shared
scripting context that is managed by the Container. Note that in
all such cases, the shared context is distinct from the data model
or scripting context specific to any particular Component.
Furthermore, it is important to note that the asynchronicity of
the underlying communication mechanism does not impose the
requirement that the markup languages present a purely asynchronous
programming model to the developer. Given the principle of
encapsulation, markup languages are not required to reflect
directly the architecture and APIs defined here. As an example,
consider an implementation containing a Modality Component
providing Text-to-Speech (TTS) functionality. This Component must
communicate with the Runtime Framework via asynchronous events. In
a typical implementation, there would likely be events to start a
TTS play and to report the end of the play, etc. However, the
markup and scripts that were used to author this system might well
offer only a synchronous "play TTS" call, it being the job of the
underlying implementation to convert that synchronous call into the
appropriate sequence of asynchronous events. In fact, there is no
requirement that the TTS resource be individually accessible at
all. It would be quite possible for the markup to present only a
single "play TTS and do speech recognition" call, which the
underlying implementation would realize as a series of asynchronous
events involving multiple Components.
Existing languages such as XHTML may be used as either the
Markup Container or as embedded Markup Components. Further
examples of potential markup components are given in Section 4.6.
2.2 Software Constituents and The Run-Time View
At the core of the MMI runtime architecture is the distinction
between the Runtime Framework and the Components, which is similar
to the distinction between the Markup Container and the Markup
Component languages. The Runtime Framework, which might also be
called a 'host environment' or a 'browser', provides the basic
infrastructure which various Components plug into. Individual
components are responsible for specific tasks, particularly
handling input and output in the various modalities, such as
speech, pen, video, etc. Modality components are black boxes,
required only to implement the modality component interface API
which is described below. This API allows the Modality Components
to communicate with the Framework and hence with each other, since
the Framework is responsible for delivering events/messages among
the Components.
Since the internals of a Component are hidden, it is possible
for a Runtime Framework and a set of Components to present
themselves as a Component to a higher-level Framework. All that is
required is that the Framework implement the Component API. The
result is a "Russian Doll" model in which Components may be nested
inside other Components to an arbitrary depth.
Components may be divided into two categories: Modality
Components, which provide the actual interaction with the user(s)
of the system, and Service Components, which provide
modality-independent platform services, such as information about
the device and the user's preferences. One important Service
Component is the Interaction Manager, which is intended to contain
logic to manage the interaction of the various modality Components.
When an Interaction Manager (IM) is present, it receives (via the
Runtime Framework) all the events that the various Modality
Components generate. Those events may be commands or replies to
commands, and it is up to the Interaction Manager to decide what to
do with them, i.e., what events to generate in response to them. In
general, the MMI architecture follows a publish/subscribe event
model. That is, the Component that raises an event does not specify
its destination. Rather, it passes it up to the Runtime Framework,
which will pass it to the Interaction Manager, if one is present.
In the absence of an Interaction Manager, the Runtime Framework
will deliver the event to all Components that have registered for
it. Similarly, when the Interaction Manager raises an event, it
does not specify a destination and the event is delivered to all
Components that have registered for it.
Because we are using the term 'Component' to refer to a specific
set of entities in our architecture, we will use the term
'Constituent' as a cover term all the elements in our architecture
which might normally be called 'software components'.
2.3 Relationship to Compound Document Formats
The MMI Architecture is related to the W3C Compound Document Formats
Activity work in that it is concerned with the execution of
user interfaces written in multiple languages. In fact, it is
anticipated that this architecture could be used to implement the
semantics specified by the compound documents work. In such an
implementation, the MMI Architecture would provide a run-time
environment that would allow facilitate the combination and
coordination of multiple document processing components.
However, the MMI Architecture is designed to support a broader
range of component interaction semantics than those provided by
compound documents. For example, it is explicitly designed to
support both distributed and co-located components and allows for
component types other than document processors such as media
players. In addition, it allows multiple interface languages to be
combined in a more loosely-coupled manner than is allowed by
compound documents. This loosely-coopled component interaction is
called the collaborating
documents model.
The compound document model implies a tight relationship between
the components of a document. Component documents can be linked
either by reference, where a linking construct is used to
reference one document from another, or by direct
inclusion of a document from one namespace within a
document from another namespace. Inclusion implies a parent-child
coupling of the documents into a tree structure where child
documents reside at specific points within their parent document.
The specific location of children could implicitly affect the
semantics of the compound document in such areas as event
propagation and visual rendering. Reference models a directed graph
of relationships between specific documents. Again, the location of
a document reference may imply specific processing semantics.
In the collaborating documents model, the document processors
co-operate without the need for explicit relationships between the
documents that they are processing. The components run in
parallel and may have separate contexts; communication and
synchronization is achieved via asynchronous events. While events
could be explicitly directed towards a specific component, this is
not generally required.
As the processed documents in this model can be authored without
explicit relationships, they are more easily processed by
distributed components, and components can be added to or removed
from the framework in a more flexible manner. Furthermore, the
processors may independently update the documents that they are
processing. This allows languages to be combined without
reconciling the manner in which they are organized into documents.
This is an important feature as many languages use the document
structure to convey specific semantics. For example, VoiceXML
[VXML] associates a variable scope and a grammar
scope with a document. This model is a generalization of the
relationship between VoiceXML and CCXML sessions as described in the
CCXML specification [CCXML].
3 Overview of Constituents
Here is a list of the Constituents of the MMI architecture. They
are discussed in more detail in the next section.
- the Runtime Framework, which provides the basic infrastructure
and hosts the other Constituents.
- the System and Environment Component, which provides
information about platform capabilities.
- the Interaction Manager, which coordinates the different
modalities. It is the Controller in the MVC paradigm.
- the Data Component, which provides the common data mode. It is
the Model in the MVC paradigm.
- the Modality Components, which provide modality-specific
interaction capabilities. They are the Views in the MVC
paradigm.
3.1 Run-Time Architecture Diagram
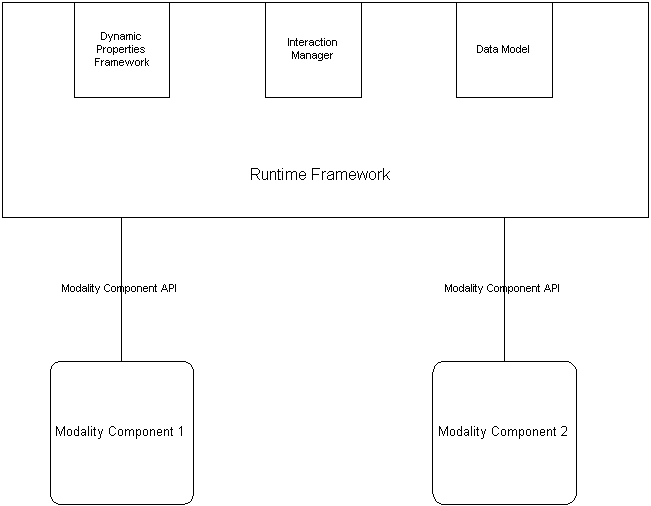
4 The Constituents
This section presents the responsibilities of the various
constituents of the MMI architecture.
4.1 The Runtime Framework
The Runtime Framework (Which could also be called the Browser)
is responsible for starting the application and interpreting the
Container Markup which is at the root of the document. More
specifically, the Runtime Framework must:
- load and initialize the document
- initialize the Component software. If the Component is local,
this will involve loading the corresponding code (library or
executable) and possibly starting a process if the Component is
implemented as a separate process, etc. If the Component is remote,
the Runtime Framework will load a stub and possibly open a
connection to the remote implementation.
- manage namespaces
- generate the necessary lifecycle events
- run the basic event loop
- map between the asynchronous Modality Component API and the
potentially synchronous APIs of other components (e.g., the
Dynamic Properties Framework)
The need for mapping between synchronous and asynchronous APIs
can be seen by considering the case where a Modality Component
wants to query the Dynamic Properties Framework Component
[DPF]. The DPF API provides synchronous access
to property values whereas the Modality Component API, presented
below in Section 5.1, is purely asynchronous
and event-based. The Modality Component will therefore generate
an event requesting the value of a certain property. The DPF
Component cannot handle this event directly, so the Runtime
Framework must catch the event, make the corresponding function call
into the DPF API, and then generate a response event back to the
Modality Component. Note that even though it is globally the Runtime
Framework's responsibility to do this mapping, most of the Runtime
Framework's behavior is asynchronous. It may therefore make sense to
factor out the mapping into a separate Adapter, allowing the Runtime
Framework proper to have a fully asynchronous architecture. For the
moment, we will leave this as an implementation decision, but we may
make the Adapter a formal part of the architecture at a later date.
The Runtime Framework's main purpose is to provide the
infrastructure, rather than to interact with the user. Thus it
implements the basic event loop, which the Components use to
communicate with one another, but is not expected to handle by
itself any events other than lifecycle events. However, if the
Container Markup section of the application provides event handlers
for modality specific events, the Runtime Framework will receive
them just as the Modality Components do.
4.2 The Interaction Manager
The Interaction Manager (IM) is an optional Component that is
responsible for handling all events that the other Components
generate. If the IM is not present on a system, the Runtime
Framework will by default deliver all events to any Component that
has registered for them. Normally there will be specific markup
associated with the IM instructing it how to respond to events.
This markup will thus contain a lot of the most basic interaction
logic of an application. Existing languages such as SMIL, CCXML,
or ECMAScript can be used for IM markup, as an alternative to
defining special-purpose languages aimed specifically at multimodal
applications.
Due to the Russian Doll model, Components may contain their own
Interaction Managers to handle their internal events. However these
Interaction Managers are not visible to the top level Runtime
Framework or Interaction Manager.
If the Interaction Manager does not contain an explicit handler
for an event, any default behavior that has been established for
the event will be respected. If there is no default behavior, the
event will be ignored. (In effect, the Interaction Manager's
default handler for all events is to ignore them.)
4.3 The Dynamic Properties Framework Component
The Dynamic Properties Framework [DPF] is
intended to provide a platform-abstraction layer enabling dynamic
adaptation to user preferences, environmental conditions, device
configuration and capabilities. It allows Constituents and
applications to:
- query for properties and their values
- update (run-time settable) properties
- receive notifications of changes to properties
Note that some device properties, such as screen brightness, are
run-time settable, while others, such as whether there is a screen,
are not. The term 'property' is also used for characteristics that
may be more properly thought of as user preferences, such as
preferred output modality or default speaking volume.
4.4 The Data Component
The Data Component is an optional constituent responsible for
handling the data that needs to be shared between the other
Components. This component is responsible for coordination,
sandboxing, and storing of the data. One possible implementation
of the Data Component might be as the XForms Data Layer. If
implemented this way, it is the responsibility of the various
Modality Components to implement the XForms binding. The Data
Component must then register with the Runtime Framework for all
XForms events that have the <xforms:model> element as their
target.
4.5 Modality Components
Modality Components, as their name would indicate, are
responsible for controlling the various input and output modalities
on the device. They are therefore responsible for handling all
interaction with the user(s). Their only responsibility is to
implement the interface defined in section 4.1, below. Any further
definition of their responsibilities must be highly domain- and
applicaton-specific. In particular we do not define a set of
standard modalities or the events that they should generate or
handle. Platform providers are allowed to define new Modality
Components and are allowed to place into a single Component
functionality that might logically seem to belong to two different
modalities. Thus a platform could provide a handwriting-and-speech
Modality Component that would accept simultaneous voice and pen
input. Such combined Components permit a much tighter coupling
between the two modalities than the loose interface defined
here.
In most cases, there will be specific markup in the application
corresponding to a given modality, specifying how the interaction
with the user should be carried out. However, we do not require
this and specifically allow for a markup-free modality component
whose behavior is hardcoded into its software.
4.6 Examples
For the sake of concreteness, here are some examples of
components that could be implemented using existing languages. Note
that we are mixing the design-time and run-time views here, since
it is the implementation of the language (the browser) that serves
as the run-time component.
- CCXML could be used as both the Markup Container and the
Interaction Manager language, with the CCXML interpreter serving as
the Runtime Framework.
- In an integrated multimodal browser, the markup language that
provided the document root tag would be the Markup Container and
the associated scripting language could serve as the Interaction
Manager.
- XHTML could be used as the markup for a Modality
Component.
- VoiceXML could be used as the markup for a Modality
Component.
- SVG could be used as the markup for a Modality Component.
- SMIL could be used as the markup for a Modality Component.
5 Run-Time Interfaces
5.1 Interface between the Runtime Framework and the
Modality Components
The most important interface in this architecture is the one
between the Modality Components and the Runtime Framework. Modality
Components communicate with the Framework and with each other via
asynchronous DOM 3 events. Components must be able to raise DOM 3
events and to handle events that are delivered to them
asynchronously. It is not required that components use the DOM or
events internally since the implementation of a given Component is
black box to the rest of the system. In general, it is expected
that Components will raise events both automatically (i.e., as part
of their implementation) and under mark-up control. The disposition
of events is the responsibility of the Runtime Framework layer.
That is, the Component that raises event does not specify which
Component it should be delivered to. Rather that determination is
left up to the Framework and Interaction Manager.
5.1.3 Standard Events
In general the set of events that MMI components generate and
receive is arbitrary and application-dependent. For example, two
different voice modality components might generate different sets
of Runtime Framework-level events. One of the voice modality
components might be based on SALT, and thus deliver relatively
fine-grained events for recognition completion, etc. An other voice
modality component might be based on a VoiceXML Form and deliver
events only when the Form was completely filled. The Interaction
Manager and the other components in the application would have to
know which voice component they were dealing with and be coded
accordingly. In the case of the SALT voice component, the
Interaction Manager will have to provide control on a
per-recognition basis, while the Form-based voice component would
interact at a coarser level.
There are, however, a small number of events that all components
must handle. These are shown below:
5.1.3.1 Life Cycle Events
Run
|
Indicates that Component should begin executing |
Running
|
Notification event returned by Component to indicated that it
has started |
Halt
|
Indicates that Component should cease executing |
Halted
|
Notification event returned by Component. The Component may
generate this event without having received a previous Halt event
if it completes execution on its own, e.g., by reaching the end of
its markup. |
In addition, we think that the following events may
prove useful for many components. We have not decided whether they
will be mandatory for all Components, mandatory for a certain set
of components, or optional.
AddSession
|
Indicates the start of a user session. Markup may be passed as
a URL or literal string. |
| SessionAdded |
Notification event returned by the Component |
EndSession
|
Indicates the end of a user session |
SessionEnded
|
Notification event returned by the Component |
Pause
|
Indicates that Component should pause execution. Components
that do not have the ability to pause may treat this as equivalent
to Halt. |
Paused
|
Notification event returned by Component |
Resume
|
Indicates that Component should resume its paused execution.
Components that do not have the ability to pause should treat this
as equivalent to Run. |
Resumed
|
Notification event returned by Component |
The AddSession event is designed to allow the component to
prepare for an interaction by fetching resources, allocating
memory, etc. The component would not required to do any of this, of
course, but it must return a SessionAdded event in response. The
EndSession event would be delivered to the component at the end of
an interaction and would be designed to allow the freeing of
resources, etc. As with AddSession, the component must generate a
response event, in this case SessionEnded.
5.1.4 Event Sequencing and Delivery
There are no general guarantees on event sequencing other than
the following: events are delivered to the Runtime Framework in the
same order that the Component raised them. Note that this implies
that events cannot get lost, i.e. that any event that a Component
raises must be delivered to the Runtime Framework. The subsequent
treatment of the event is entirely left to the discretion of the
Runtime Framework and Interaction Manager. In particular they will
decide which Components the event gets delivered to - if any - and
the order it will be delivered in relative to other events. Note
that the Runtime Framework may deliver events to a Component in a
different order from the one in which it originally received
them
5.2 Other Interfaces
The Dynamic Properties Framework component has its own
interface, separate from the Modality Component interface. It is
defined in Dynamic Properties Framework [DPF].
The Interaction Manager's interface to the Runtime Framework is
hidden, meaning that the IM is provided as part of the Runtime
Framework. At some point we may wish to standardize this interface,
which would allow one vendor's Interaction Manager to work with
another's Runtime Framework.
The interface to the Data Component is defined by XForms
[XFORMS].
6 Start-Up and Session Life Cycle
The concept of session (which could also be called "user
interaction") exists at both the level Runtime Framework and the
level of the Modality Components. The Framework's session lasts for
the entire interaction with the user (possibly multiple users.) The
Modality Components' sessions occur in the context of this
encompasing Framework-level session. For an individual Modality
Component, its session consits of the period of time that it is
interacting with the user. The Modality Component's session may be
shorter than the Runtime Framework's session and different Modality
Components may have sessions with different durations. For example,
there could be an application that starts of as a GUI interaction,
and then adds a voice component part way through the interaction.
After a while, the GUI part of the application terminates while the
voice interaction continues. Then a new GUI interaction is added
and later the voice application terminates, leaving the new GUI
component to complete the interaction. In this case, there is one
voice session and two separate GUI sessions. The first GUI session
starts before the voice session and also ends before it. The voice
session, in turn, overlaps with the second GUI session and
terminates before it. The overarching Runtime Framework session
contains all three of the Modality Component sessions.
The initiation of the Runtime Framework's session is
platform-specific and outside the scope of this document. Once its
session is started, the Framework will load the application's root
document, load the software that implements the Modality Components
(if necessary), then send Run messages as appropriate to start the
individual Components' sessions. The individual Component's
sessions will terminate either when their markup indicates that
they should (e.g., through an <exit> tag) or when the
Framework/Interaction Manager sends them a Halt (or possibly
EndSession) event. The Runtime Framework's session will terminate
either under the control of its own markup, or, by default, when
all the individual Modality Component sessions have ended.
7. References
- [CCXML]
- "Voice Browser Call Control: CCXML Version 1.0", R.J. Auburn,
editor, World Wide Web Consortium, 2005. Available at
- [DPF]
- "Dynamic Properties Framework", Keith Waters, Rafah Hosn,
Dave Raggett and Sailesh Sathish, editors. World Wide Web
Consortium, 2004. Available at
http://www.w3.org/TR/DPF/
- [EMMA]
- "Extensible multimodal Annotation markup language (EMMA)",
Wu Chou et al. editors. EMMA is an XML format for annotating
application specific interpretations of user input with information
such as confidence scores, time stamps, input modality and
alternative recognition hypotheses, World Wide Web Consortium,
2005. Available at http://www.w3.org/TR/emma/
- [GALAXY]
- Galaxy Communicator is an open source hub and spoke architecture
for constructing dialogue systems that was developed with funding
from Defense Advanced Research Projects Agency (DARPA) of the United
States Government. For more information see
http://communicator.sourceforge.net/
- [MMIF]
- "W3C Multimodal Interaction Framework", James A. Larson,
T.V. Raman and Dave Raggett, editors, World Wide Web Consortium,
2003. Available at
http://www.w3.org/TR/mmi-framework/
- [MMIREQS]
- "W3C Multimodal Interaction Requirements", Stephane H. Maes
and Vijay Saraswat, editors, World Wide Web Consortium, 2003.
Available at
http://www.w3.org/TR/mmi-reqs/
- [VXML]
- "Voice Extensible Markup Language (VoiceXML) Version 2.0",
Scott McGlashan et al. editors. World Wide Web Consortium, 2004.
Available at
http://www.w3.org/TR/voicexml20/
- [XFORMS]
- "XForms 1.0", Micah Dubinko, Leigh Klotz, Roland
Merrick and T.V. Raman, editors. World Wide Web Consortium,
2003. Available at http://www.w3.org/TR/xforms/
Further information about W3C specifications for XHTML, SMIL
and SVG can be found on the W3C web site at
http://www.w3.org/.
Appendix A. Use Case Discussion
This section presents a detailed example of how an
implementation of this architecture. For the sake of concreteness,
it specifies a number of details that are not included in this
document. It is based on the MMI use case document Multimodal Interaction Use
Cases, specifically the second use case, Section 2.2 ,
which presents a multimodal in-car application for giving driving
directions. Four languages are involved in the design view:
- The markup container language. We will not specify this
language.
- The graphical language. We will assume that this is
HTML.
- The voice language . We will assume that this VoiceXML.
For concreteness, we will use VoiceXML 2.0 [VXML],
but will also note differences in behavior that might occur with a
future version of VoiceXML
- The interaction management language. We will not specify
this language but will assume that it is capable of representing a
reasonably powerful state machine.
The remainder of the discussion involves the run-time view. The
numbered items are taken from the "User Action/External Input"
field of the event table. The appended comments are based on the
working group's discussion of the use case. Noting that the
presence of an Interaction Manager is optional, at certain points
we will discuss the flow of control in cases where one is not
present. While it is certainly possible to build this application
without an IM, certain of the interactions in this use case
highlight the usefulness of the IM, in particular its ability to
make applications more concise and intelligible.
- User Presses Button on wheel to start application.
Comment: The Runtime Framework submits to a pre-configured
URL and receives a session cookie in return. This cookie will
be included in all subsequent submissions. Now the Runtime
Framework loads the DPF framework, retrieves the default user and
device profile and submits them to a (different) URl to get the
first page of the application. UAPROF can be used for standard
device characteristics (screen size, etc.), but it is not
extensible and does not cover user preferences. The DPF group is
working on a profile definition that provides an extensible set of
attributes and can be used here. Once the initial profile
submission is made, only updates get sent in subsequent
submissions. Once the Runtime Framework loads the initial page, it
notes that it contains both VoiceXML and HTML markup. Therefore it
makes sure that the corresponding Modality Components are loaded,
and then raises a pair of AddSession events, one for each
Component. These events contain the Session ID and the
Component-specific markup (VoiceXML or HTML). If the markup was
included in the root document, it is delivered in-line in the
event. However, if the main document referenced the
Component-specific markup via URL, only the URL is passed in the
event. The IM delivers the StartSession events to both Modality
Components, which parse their markup, initialize their resources
(ASR, TTS, etc.) and return SessionAdded events, which the IM
passes back to the Runtime Framework. The Runtime Framework is now
ready to start the application.
- The user interacts in an authentication dialog.
Comment: The Runtime Framework sends the Run command to
the VoiceXML Modality component, which executes a Form asking the
user to identify himself. In VoiceXML 3.0, the Form might make use
of speaker verification as well as speech recognition. Any database
access or other back-end interaction is handled inside the Form. In
VoiceXML 2.0, the recognition results (which include the user's
indentity) will be returned to the IM by the <exit> tag along
with a namelist. This would mean that the specific logical Modality
Component instance had exited, so that any further voice
interactions would have to be handled by a separate logical
Modality Component corresponding to a separate Markup Component. In
VoiceXML 3.0, however, it would be possible for the Modality
Component instance to send a recognition result event to the IM
without exiting. It would then be sitting there, waiting for the IM
to send it another event to trigger further processing. Thus in
VoiceXML 3.0, all the voice interactions in the application could
be handled by a single Markup Component (section of VoiceXML
markup) and a single logical Modality Component.
Recognition can be done locally, remotely (on the server) or
distributed between the device and the server. By default, the
location of event handling is determined by the markup. If there is
a local handler for an event specified in the document, the event
is handled locally. If not, the event is forwarded to the server.
Thus if the markup specifies a speech-started event handler, that
event will be consumed locally. Otherwise it will be forwarded to
the server. However, remote ASR requires more than simply
forwarding the speech-started event to the server because the audio
channel must be established. This level of configuration is handled
by the device profile, but can be overridden by the markup. Note
that the remote server might contain a full VoiceXML interpreter as
well as ASR capabilities. In that case, the relevant markup would
be sent to the server along with the audio. The protocol used to
control the remote recognizer and ship it audio is not part of the
MMI specification (but may well be MRCP.)
Open Issue: The previous paragraph about local vs remote event
handling is retained from an earlier draft. Since the Modality
Component is a black box to the Runtime Framework, the local vs
remote distinction should be internal to it. Therefore the event
handlers would have to be specified in the VoiceXML markup. But no
such possibility exists in VoiceXML 2.0. One option would be to
make the local vs remote distinction vendor-specific, so that each
Modality Component provider would decide whether to support remote
operations and, if so, how to configure them. Alternatively, we
could define the DPF properties for remote recognition, but make it
optional that vendors support them. In either case, it would be up
to the VoiceXML Modality Component communicate with the remote
server, etc. Newer languages, such as VoiceXML 3.0 could be
designed to allow explicit markup control of local vs remote
operations. Note that in the most complex case, there could be
multiple simultaneous recognitions, some of which were local and
some remote. This level of control is most easily achieved via
markup, by attaching properties to individual grammars. DPF
properties are more suitable for setting global defaults.
When the IM receives the recognition result event, it parses it
and retrieves the user's preferences frin tge DOF component, which
it then dispatches to the Modality Components, which adjust their
displays, output, default grammars, etc. accordingly. In VoiceXML
2.0, each of the multiple voice Modality Components will receive
the corresponding event.
- Initial GPS input.
Comment: DPF configuration determines how often GPS update
events are raised. On the first event, the IM sends the HTML
Modality Component an command to display the initial map. On
subsequent events, a handler in the IM markup determines if the
automobile's location has changed enough to require an update of
the map display. Depending on device characteristics, the update
may require redrawing the whole map or just part of it.
This particular step in the use case shows the usefulness of the
Interaction Manager. In the absence of one, all Modality Components
would have to handle the location update events separately. This
would mean considerable duplication of markup and calculation.
Consider in particular the case of a VoiceXML 2.0 Form which is
supposed to warn the driver when he went off course. If there is an
IM, this Form will simply contain the off-course dialog and will be
triggered by an appropriate event from the IM. In the absence of
the IM, however, the Form will have to be invoked on each location
update event. The Form itself will have to calculate whether the
user is off-course, exiting without saying anything if he is not.
In parallel, the HTML Modality Component will be performing a
similar calculation to determine whether to update its display. The
overall application is simpler and more modular if the location
calculation and other application logic is placed in the IM, which
will then invoke the individual Modality Components only when it is
time to interact with the user.
Note on the GPS. We assume that the GPS raises four types
of events: On-Course Updates, Off-Course Alerts, Loss-of-Signal
Alerts, and Recovery of Signal Notifications. The Off-Course Alert
is covered below. The Loss-of-Signal Alert is important since the
system must know if its position and course information is
reliable. At the very least, we would assume that the graphical
display would be modified when the signal was lost. An audio earcon
would also be appropriate. Similarly, the Recovery of Signal
Notification would cause a change in the display and possibly a
audio notification. This event would also contain an indication of
the number of satellites detected, since this determines the
accuracy of the signal: three satellites are necessary to provide x
and y coordinate, while a fourth satellite allows the determination
of height as well. Finally, note that the GPS can assume that the
car's location does not change while the engine is off. Thus when
it starts up it will assume that it is at its last recorded
location. This should make the initialization process quicker.
- User selects option to change volume of on-board display using
touch display.
Comment: HTML Modality Component raises an event, which
the IM catches. The IM then generates an event to modify the
relevant DPF property. The Runtime Framework (Adapter) catches this
event and converts it into the appropriate function call, which has
the effect of resetting the output volume.
- User presses button on stearing wheel (to start
recognition)
Comment: The interesting question here is whether the
button-push event is visible at the application level. One
possibility is that the button-push simply turns on the mike and is
thus invisible to the application. In that case, the voice modality
component must already be listening for input with no prespeech
timeout set. On the other hand, if there is an explicit button-push
event, the IM could catch it and then invoke the speech component,
which would not need to have been active in the interim. The
explicit event would also allow for an update of the graphical
display.
- User says destination address. (May improve recognition
accuracy by sending grammar constraints to server based on a local
dialog with the user instead of allowing any address from the
start)
Comment: Assuming V3 and explicit markup control of
recognition, the device would first perform first local
recognition, then send the audio off for remote recognition if the
confidence was not high enough. The local grammar would consist of
'favorites' or places that the driver was considered likely to
visit. The remote grammar would be significantly larger, possibly
including the whole continent.
When the IM is satisfied with the confidence levels, it ships
the n-best list off to a remote server, which adds graphical
information for at least the first choice. The server may also need
to modify the n-best list, since items that are linguistically
unambiguous may turn out to be ambiguous in the database (e.g.,
"Starbucks"). Now the IM instructs the HTML component to displays
the hypothesized destination (first item on n-best list) on the
screen and instructs the speech component to start a confirmation
dialog. Note that the submission to the remote server should be
similar to the <data> tag in VoiceXML 2.1 in that it does not
require a document transition. (That is, the remote server should
not have to generate a new IM document/state machine just to add
graphical information to the n-best list.)
- User confirms destination.
Comment: Local recognition of grammar built from n-best
list. The original use case states that the device sends the
destination information to the server, but that may not be
necessary since the device already has a map of the hypothesized
destination. However, if the confirmation dialog resulted in the
user choosing a different destination (i.e., not the first item on
the n-best list), it might be necessary to fetch graphical/map
information for the selected destination. In any case, all this
processing is under markup control.
- GPS Input at regular intervals.
Comment: On-Course Updates. Event handler in the IM
decides if location has changed enough to require update of
graphical display.
- GPS Input at regular intervals (indicating driver is off
course)
Comment: This is probably an asynchronous Off-Course
Alert, rather than a synchronous update. In either case, the GPS
determines that the driver is off course and raises a corresponding
event which is caught by the IM. Its event handler updates the
display and plays a prompt warning the user. Note that both these
updates are asynchronous. In particular, the warning prompt may
need to pre-empt other audio (for example, the system might be
reading the user's email back to him.)
- N/A
Comment: The IM sends a route request to server,
requesting it to recalculate the route based on the new
(unexpected) location. This is also part of the event handler for
the off-course event. There might also be a speech interaction
here, asking the user if he has changed his destination.
- Alert received on device based on traffic conditions
Comment: This is another asynchronous event, just like the
off-course event. It will result in asynchronous graphical and
verbal notifications to the user, possibly pre-empting other
interactions.; The difference between this event and the off-course
event is that this one is generated by the remote server. To
receive it, the IM must have registered for it (and possibly other
event types) when the driver chose his destination. Note that the
registration is specific to the given destination since the driver
does not want to receive updates about routes he is not planning to
take.
- User requests recalculation of route based on current traffic
conditions
Comment: Here the recognition can probably be done
locally, then the recalculation of the route is done by the server,
which then sends updated route and graphical information is sent to
the device.
- GPS Input at regular intervals
Comment: On-Course updates as discussed above.
- User presses button on steering wheel
Comment: Recognition started. Whether this is local or
remote recognition is determined by markup and/or DPF defaults
established at the start of application. The use case does not
specify whether all recognition requires a button push. One option
would be to require the button push only when the driver is
initiating the interaction. This would simplify the application in
that it would not have to be listening constantly to background
noise or side chatter just in case the driver issued a command. In
cases where the system had prompted the driver for input, the
button push would not be necessary. Alternatively, a special
hot-word could take the place of the button push. All of these
options are compatible with the architecture described in this
document.
- User requests new destination by destination type while still
depressing button on steering wheel (may improve recognition
accuracy by sending grammar constraints to server based on a local
dialog with the us
Comment: Local and remote recognition as before, with IM
sending n-best list to server, which adds graphical information for
at least the first choice.
- User confirms destination via a multiple interaction dialog to
determine exact destination
Comment: Local disambiguation dialog, as above. At the
end, user is asked if this is a new destination.
- User indicates that this is a stop on the way to original
destination
Comment: Device sends request to server, which provides
updated route and display info. The IM must keep track of the
original destination so that it can request a new route to it after
the driver reaches his intermediate destination.
- GPS Input at regular intervals
Comment: As above.