Status of this Document
This section describes the status of this document at the time
of its publication. Other documents may supersede this document. A list of current W3C publications and the latest revision of this technical report can be found in the W3C technical reports index at http://www.w3.org/TR/.
This is a W3C Working Draft published between the
second
Last Call on 30 April 2002 and a planned third Last Call. Since the last publication, the document has been split into two parts, called Fundamentals ([CharMod]) and Normalization (this document, republished as a First Public Working Draft), in order to advance the material in Fundamentals while continuing to work on Normalization.
This interim publication is used help people review Fundamentals, which advanced to a third Last Call, and to document the progress made on addressing
the comments received during the second Last Call, as well as other modifications
resulting from continuing collaboration with other working groups. A list of last call comments
with their status can be found in the disposition of comments
(public version,
Members only version).
Work is still ongoing on addressing the comments received during the second Last Call relevant to this document. We do not encourage comments on this Working Draft; instead we ask reviewers to wait for being informed about our disposition of their comments, or for the next Last Call in case of new comments. Comments may
be submitted by email to
www-i18n-comments@w3.org (public
archive).
This document is published as part of the
W3C
Internationalization Activity by the W3C
Internationalization Working Group (I18N WG) (Members only),
with the help of the Internationalization Interest Group. The Working Group expects to advance this Working Draft to Recommendation. The
Internationalization Working Group will not allow early implementation to
constrain its ability to make changes to this specification prior to final
release. Publication as a Working Draft does not imply endorsement by the W3C
Membership. This is a draft document and may be updated, replaced or obsoleted by other documents at any time. It is inappropriate to use W3C Working Drafts as reference material
or to cite them as other than "work in progress".
Patent disclosures relevant to this specification may be found on the Working Group's patent disclosure page. This document has been produced under the 24 January 2002 CPP as amended by the W3C Patent Policy Transition Procedure. An individual who has actual knowledge of a patent which the individual believes contains Essential Claim(s) with respect to this specification should disclose the information in accordance with section 6 of the W3C Patent Policy.
1 Introduction
1.1 Goals and Scope
The goal of this document is to facilitate use of the Web by all
people, regardless of their language, script, writing system, and cultural
conventions, in accordance with the
W3C goal of universal
access. One basic prerequisite to achieve this goal is to be able to
transmit and process the characters used around the world in a well-defined and
well-understood way.
The main target audience of this document is W3C specification
developers. This document and parts of it can be referenced from other
W3C specifications.
Other audiences of this document include software developers,
content developers, and authors of specifications outside the W3C. Software
developers and content developers implement and use W3C specifications. This
document defines some conformance requirements for software developers and
content developers that implement and use W3C specifications. It also helps
software developers and content developers to understand the character-related
provisions in other W3C specifications.
The character model described in this document provides authors of
specifications, software developers, and content developers with a common
reference for consistent, interoperable text manipulation on the World Wide
Web. Working together, these three groups can build a more international
Web.
Topics addressed include character encoding identification, early uniform
normalization, string identity matching, string indexing, and URI conventions.
Some introductory material on characters and character encoding is also
provided.
Topics not addressed or barely touched include collation (sorting),
fuzzy matching and language tagging. Some of these topics may be addressed in a
future version of this specification.
At the core of the model is the Universal Character Set (UCS),
defined jointly by the Unicode Standard [Unicode] and ISO/IEC
10646 [ISO/IEC 10646]. In this document, Unicode is used
as a synonym for the Universal Character Set. The model will allow Web
documents authored in the world's scripts (and on different platforms) to be
exchanged, read, and searched by Web users around the world.
1.2 Background
This section provides some historical background on the topics
addressed in this document.
Starting with Internationalization of the Hypertext Markup
Language
[RFC 2070], the Web community has recognized
the need for a character model for the World Wide Web. The first step towards
building this model was the adoption of Unicode as the document character set
for HTML.
The choice of Unicode was motivated by the fact that Unicode:
is the only universal character repertoire available,
provides a way of referencing characters independent of the
encoding of the text,
is being updated/completed carefully,
is widely accepted and implemented by industry.
W3C adopted Unicode as the document character set for HTML in
[HTML 4.0]. The same approach was later used for specifications
such as XML 1.0 [XML 1.0] and CSS2 [CSS2].
W3C specifications and applications now use Unicode as
the common reference character set.
The IETF has adopted some policies on the use of character sets on
the Internet (see [RFC 2277]).
When data transfer on the Web remained mostly unidirectional (from
server to browser), and where the main purpose was to render documents, the use
of Unicode without specifying additional details was sufficient. However, the
Web has grown:
Data transfers among servers, proxies, and clients, in all
directions, have increased.
Non-ASCII characters [ISO/IEC 646] are being used in
more and more places.
Data transfers between different protocol/format elements
(such as element/attribute names, URI components, and textual content) have
increased.
More and more APIs are defined, not just protocols and
formats.
In short, the Web may be seen as a single, very large application
(see [Nicol]), rather than as a collection of small independent
applications.
While these developments strengthen the requirement that Unicode be
the basis of a character model for the Web, they also create the need for
additional specifications on the application of Unicode to the Web. Some
aspects of Unicode that require additional specification for the Web include:
Choice of Unicode encoding forms (UTF-8, UTF-16, UTF-32).
Counting characters, measuring string length in the presence
of variable-length character encodings and combining characters.
Duplicate encodings of characters (e.g. precomposed vs decomposed).
Use of control codes for various purposes (e.g. bidirectionality
control, symmetric swapping, etc.).
It should be noted that such
aspects also exist in legacy encodings (where
legacy encoding is taken to mean any character encoding not based
on Unicode), and in many cases have been inherited by Unicode in one way or
another from such legacy encodings.
The remainder of this document presents additional specifications
and requirements to ensure an interoperable character model for the Web, taking
into account earlier work (from W3C, ISO and IETF).
For information about the requirements that informed the development
of important parts of this specification, see Requirements for String
Identity Matching and String Indexing
[CharReq].
1.3 Terminology and Notation
For the purpose of this specification,
the producer of text data is the sender of the data in the case of
protocols, and the tool that produces the data in the case of formats. The
recipient of text data is the software module that receives the
data.
NOTE: A software module may be both a recipient and a producer.
Unicode code points are denoted as U+hhhh, where "hhhh" is a
sequence of at least four, and at most six hexadecimal digits.
Characters have been used in various examples that will not appear as intended unless you have the appropriate font. Care has been taken to ensure that the examples nevertheless remain understandable.
2 Conformance
The key words "MUST", "MUST
NOT", "REQUIRED", "SHALL",
"SHALL NOT", SHOULD", "SHOULD
NOT", "RECOMMENDED", "MAY" and
"OPTIONAL" in this document are to be interpreted as
described in RFC 2119 [RFC 2119].
NOTE: RFC 2119 makes it clear that requirements that use
SHOULD are not optional and must be complied with unless
there are specific reasons not to: "This word, or the adjective
"RECOMMENDED", mean that there may exist valid reasons in particular
circumstances to ignore a particular item, but the full implications must be
understood and carefully weighed before choosing a different
course."
This specification places conformance criteria
on specifications, on software and on Web content. To aid the reader, all
conformance criteria are
preceded by '[X]' where 'X' is one of
'S' for specifications, 'I' for software
implementations, and 'C' for Web content. These markers indicate
the relevance of the conformance criteria and allow the
reader to quickly locate relevant conformance criteria by searching through this document.
Specifications conform to this document if they:
do not violate any conformance criteria preceded by [S],
document the reason for any deviation from criteria where the imperative is SHOULD, SHOULD NOT, or RECOMMENDED,
make it a conformance requirement for implementations to conform to this document,
make it a conformance requirement for content to conform to this document.
Software conforms to this document if it does not
violate any conformance criteria preceded by [I].
Content conforms to this document if it does not violate any conformance criteria preceded by [C].
NOTE: Requirements placed on specifications might indirectly cause requirements to be placed on implementations or content that claim to conform to those specifications.
Where this specification contains
a procedural description, it is to be understood as a way to
specify the desired external behavior. Implementations can
use other means of achieving the same results, as
long as observable behavior is not affected.
3 Early Uniform Normalization
This chapter discusses text normalization for the Web.
3.1 Motivation discusses the need for
normalization, and in particular early uniform normalization.
3.2 Definitions for W3C Text
Normalization defines the various types of
normalization and 3.3 Examples gives supporting
examples. 3.4 Responsibility for
Normalization assigns reponsibilities
to various components and situations. The requirements for early uniform
normalization are discussed in Requirements for String Identity
Matching
[CharReq],
section 3.
3.1 Motivation
3.1.1 Why do we need character
normalization?
Text in computers can be encoded in one of many character encodings. In
addition, some character encodings allow multiple representations for the
'same' string, and Web languages have escape mechanisms that
introduce even more equivalent representations. For instance, in ISO 8859-1 the
letter 'ç' can only be represented as the single character E7
'ç', in a Unicode encoding it can be represented as the single
character U+00E7 'ç'
or the sequence U+0063
'c' U+0327 '¸', and in HTML it could be additionally
represented as ç or ç or ç.
There are a number of fundamental operations that are sensitive to
these multiple representations: string matching, indexing, searching, sorting,
regular expression matching, selection, etc. In particular, the proper
functioning of the Web (and of much other software) depends to a large extent
on string matching. Examples of string matching abound: parsing element and
attribute names in Web documents, matching CSS selectors to the nodes in a
document, matching font names in a style sheet to the names known to the
operating system, matching URI pieces to the resources in a server, matching
strings embedded in an ECMAScript program to strings typed in by a Web form
user, matching the parts of an XPath expression (element names, attribute names
and values, content, etc.) to what is found in an instance, etc.
String matching is usually taken for granted and performed by
comparing two strings byte for byte, but the existence on the Web of multiple
character representations means that it is actually non-trivial. Binary
comparison does not work if the strings are not in the same
character encoding (e.g. an EBCDIC style sheet being directly applied to an ASCII
document, or a font specification in a Shift_JIS style sheet directly used on a
system that maintains font names in UTF-16) or if they are in the same character encoding
but show variations allowed for the 'same' string by the use of
combining characters or by the constructs of the Web language.
Incorrect string matching can have far reaching consequences,
including the creation of security holes. Consider a contract, encoded in XML,
for buying goods: each item sold is described in a Stück element;
unfortunately, "Stück" is subject to different representations
in the character encoding of the contract. Suppose that the contract is viewed
and signed by means of a user agent that looks for Stück elements,
extracts them (matching on the element name), presents them to the user and
adds up their prices. If different instances of the Stück element
happen to be represented differently in a particular contract, then the buyer
and seller may see (and sign) different contracts if their respective user
agents perform string identity matching differently, which is fairly likely in
the absence of a well-defined specification for string matching. The absence of
a well-defined specification would also mean that there would be no way to
resolve the ensuing contractual dispute.
Solving the string matching problem involves normalization, which
in a nutshell means bringing the two strings to be compared to a common,
canonical encoding prior to performing binary matching. (For additional steps
involved in string matching see 4 String Identity Matching.)
3.1.2 The choice of early
uniform normalization
There are options in the exact way normalization can be used to
achieve correct behavior of normalization-sensitive operations such as string
matching. These options lie along two axes:
The first axis is a choice of when normalization
occurs: early (when strings are created) or late (when strings are compared).
The former amounts to establishing a canonical encoding for all data that is
transmitted or stored, so that it doesn't need any normalization later, before
being used. The latter is the equivalent of mandating 'smart'
compare functions, which will take care of any encoding differences.
This document specifies early normalization. The
reasons for that choice are manifold:
Almost all legacy data as well as data created by current
software is normalized (if using NFC).
The number of Web components that generate or transform text
is considerably smaller than the number of components that receive text and
need to perform matching or other processes requiring normalized text.
Current receiving components (browsers, XML parsers, etc.)
implicitly assume early normalization by not performing or verifying
normalization themselves. This is a vast legacy.
Web components that generate and process text are in a much
better position to do normalization than other components; in particular, they
may be aware that they deal with a restricted repertoire only, which simplifies
the process of normalization.
Not all components of the Web that implement functions such
as string matching can reasonably be expected to do normalization. This, in
particular, applies to very small components and components in the lower layers
of the architecture.
Forward-compatibility issues can be dealt with more easily:
less software needs to be updated, namely only the software that generates
newly introduced characters.
It improves matching in cases where the character encoding
is partly undefined, such as URIs [RFC 2396] in which non-ASCII
bytes have no defined meaning.
It is a prerequisite for comparison of encrypted strings
(see [CharReq],
section
2.7).
The second axis is a choice of canonical encoding. This choice
needs only be made if early normalization is chosen. With late normalization,
the canonical encoding would be an internal matter of the smart compare
function, which doesn't need any wide agreement or standardization.
By choosing a single canonical encoding, it is
ensured that normalization is uniform throughout
the web. Hence the two axes lead us to the name 'early uniform
normalization'.
3.1.3 The choice of Normalization Form
C
The Unicode Consortium provides four standard normalization forms
(see Unicode Normalization Forms
[UTR #15]).
These forms differ in 1) whether they normalize towards decomposed characters
(NFD, NFKD) or precomposed characters (NFC, NFKC) and 2) whether they normalize
away compatibility distinctions (NFKD, NFKC) or not (NFD, NFC).
For use on the Web, it is important not to lose the so-called
compatibility distinctions, which may be important (see [UXML]
Chapter
4 for a discussion). The NFKD and NFKC normalization forms are therefore
excluded. Among the remaining two forms, NFC has the advantage that almost all
legacy data (if transcoded trivially, one-to-one) as well as data created by
current software is already in this form; NFC also has a slight compactness
advantage and a better match to user expectations with respect to the character
vs. grapheme issue. This document
therefore chooses NFC as the base for Web-related text normalization.
NOTE: Roughly speaking, NFC is defined such that each
combining character sequence (a base character followed by one or more
combining characters) is replaced, as far as possible, by a canonically
equivalent precomposed character. Text in a
Unicode encoding form is said to
be in NFC if it doesn't contain any combining sequence that could be replaced
and if any remaining combining sequence is in canonical order.
For a list of programming resources related to normalization, see
C Resources for
Normalization.
3.2 Definitions for W3C Text
Normalization
For use on the Web, this document defines Web-related text
normalization forms by starting with Unicode Normalization Form C (NFC),
and additionally addressing the issues of legacy
encodings, character escapes, includes, and character and markup
boundaries. Examples illustrating these definitions can be found in
3.3 Examples.
A normalizing
transcoder is a transcoder that converts from a
legacy encoding to a
Unicode encoding form
and ensures that the result is in Unicode Normalization Form C
(see 3.2.1 Unicode-normalized text). For most legacy encodings, it is
possible to construct a normalizing transcoder (by using any transcoder
followed by a normalizer); it is not possible to do so if
the encoding's repertoire contains
characters not represented in Unicode.
3.2.1 Unicode-normalized text
Text is, for the purposes of this specification,
Unicode-normalized if it is in a
Unicode encoding formand is in Unicode Normalization Form C, according to a version of
Unicode Standard Annex #15: Unicode Normalization Forms [UTR #15]
at least as recent as the oldest version of the Unicode Standard that contains all the
characters actually present in the text, but no earlier than version 3.2
[Unicode 3.2].
3.2.2 Include-normalized text
Markup languages, style languages and programming
languages often offer facilities for including a piece of text inside another.
An include is an instance of a syntactic device specified in a
language to include text at the position of the include,
replacing the include itself. Examples of includes are entity references in
XML, @import rules in CSS and the #include preprocessor statement in C/C++.
Character escapes are a special case of
includes where the included entity is predetermined by the language.
Text is include-normalized if:
the text is Unicode-normalized
and does
not contain any character escapes or
includes whose expansion would cause the
text to become no longer Unicode-normalized; or
the text is in a legacy
encoding
and, if it were transcoded to a
Unicode encoding form by a
normalizing transcoder, the
resulting text would satisfy clause 1 above.
NOTE: A consequence of this definition is that legacy text (i.e. text
in a legacy encoding) is always include-normalized unless i) a normalizing
transcoder cannot exist for that encoding (e.g. because the repertoire contains
characters not in Unicode) or ii) the text contains character escapes or
includes which, once expanded, result in un-normalized text.
NOTE: The specification of include-normalization relies on the
syntax for character escapes and includes defined by the (computer) language in
use. For plain text (no character escapes or
includes) in a Unicode encoding form, include-normalization and
Unicode-normalization are equivalent.
3.2.3 Fully-normalized text
Formal languages define
constructs, which are identifiable pieces, occurring in instances
of the language, such as comments, identifiers, element tags, processing
instructions, runs of character data,
etc. During the normal processing of include-normalized text, these various
constructs may be moved, removed (e.g. removing comments) or merged (e.g.
merging all the character data within an
element as done by the string() function of XPath), creating opportunities for text to become
denormalized. The software performing those operations then has to re-normalize
the result, which is a burden. One way to avoid such denormalization is to make
sure that the various important constructs never begin with a character such
that appending that character to a normalized string can cause the string to
become denormalized. A composing character is a character that is
one or both of the following:
the second character in the canonical decomposition mapping of some
character that is not listed in the Composition Exclusion Table defined in
[UTR #15], or
of non-zero canonical combining class (as defined in
[Unicode]).
Please consult Appendix B Composing Characters for a
discussion of composing characters, which are not exactly the same as Unicode
combining characters.
Text is fully-normalized if:
the text is in a Unicode encoding form, is
include-normalized and none of
the constructs comprising the text begin with a composing character or a
character escape representing a composing
character; or
the text is in a legacy
encoding and, if it were transcoded to a
Unicode encoding form by a
normalizing transcoder, the
resulting text would satisfy clause 1 above.
NOTE: Full-normalization is specified against the context of a
(computer) language (or the absence thereof), which specifies the form of
character escapes and includes and the
separation into constructs. For plain text (no includes, no constructs, no
character escapes) in a Unicode encoding form, full-normalization and
Unicode-normalization are equivalent.
Identification of the constructs that should be prohibited from
beginning with a composing character
(the relevant constructs) is language-dependent. As specified in
3.4 Responsibility for
Normalization, it is the responsibility of the
specification for a language to specify exactly what constitutes a relevant
construct. This may be done by specifying important boundaries, taking into
account which operations would benefit the most from being protected against
denormalization. The relevant constructs are then defined as the spans of text
between the boundaries. At a minimum, for those languages which have these
notions, the important boundaries are entity (include) boundaries as well as
the boundaries between most markup and
character data. Many languages will
benefit from defining more boundaries and therefore finer-grained
full-normalization constructs.
NOTE: In general, it will be advisable not to include
character escapes designed to express arbitrary characters among the relevant
constructs; the reason is that including them would prevent the expression of
combining sequences using character escapes (e.g. 'q̌'
for q-caron), which is especially important in legacy encodings that lack the
desired combining marks.
NOTE: Full-normalization is closed under concatenation: the
concatenation of two fully-normalized strings is also fully-normalized. As a
result, a side benefit of including entity boundaries in the set of boundaries
important for full-normalization is that the state of normalization of a
document that includes entities can be assessed without expanding
the includes, if the included entities are
known to be fully-normalized. If all the entities are known to be
include-normalized and not to start with a
composing character, then it can be
concluded that including the entities would not denormalize the document.
3.3 Examples
In some of the following examples, '¸' is used to
depict the character U+0327 COMBINING CEDILLA, for the purposes
of illustration. Had a real U+0327 been used instead of this spacing
(non-combining) variant, some browsers might combine it with a preceding
'c', resulting in a display indistinguishable from a U+00E7
'ç' and a loss of understandability of the examples. In addition,
if the sequence c + combining cedilla were present, this document would not be
include-normalized and would therefore not conform to itself.
It is also assumed that the example strings are relevant constructs
for the purposes of full-normalization.
3.3.1 General examples
The string suçon (U+0073 U+0075 U+00E7 U+006F U+006E) encoded in a Unicode encoding form, is Unicode-normalized, include-normalized and fully-normalized. The same
string encoded in a legacy encoding for
which there exists a normalizing transcoder would be both include-normalized
and fully-normalized but not Unicode-normalized (since not in a Unicode
encoding form).
In an XML or HTML context, the string suçon is also include-normalized, fully-normalized and, if encoded in a
Unicode encoding form, Unicode-normalized. Expanding ç yields suçon as above, which contains no replaceable combining sequence.
The string suc¸on (U+0073 U+0075 U+0063 U+0327 U+006F U+006E), where U+0327
is the COMBINING CEDILLA, encoded in a Unicode encoding form, is
not Unicode-normalized (since the combining sequence 'c¸' (U+0063
U+0327) should appear instead as the precomposed 'ç' (U+00E7)). As a
consequence this string is neither include-normalized (since in a Unicode
encoding form but not Unicode-normalized) nor fully-normalized (since not
include-normalized). Note however that the string sub¸on (U+0073 U+0075 U+0062 U+0327 U+006F U+006E) in a Unicode
encoding form is Unicode-normalized since there is no precomposed form
of 'b' plus cedilla. It is also include-normalized and
fully-normalized.
In plain text the string suçon is Unicode-normalized, since plain text doesn't recognize that
̧ represents a character in XML or HTML and considers it just a
sequence of non-replaceable characters.
In an XML or HTML context, however, expanding ̧ yields
the string suc¸on (U+0073 U+0075 U+0063 U+0327 U+006F U+006E) which is not
Unicode-normalized ('c¸' is
replaceable by 'ç'). As a consequence the string is neither
include-normalized nor fully-normalized. As another example, if the entity
reference &word-end; refers to an entity containing ¸on (U+0327 U+006F U+006E), then the string suc&word-end; is not include-normalized for the same reasons.
In an XML or HTML context, expanding ̧ in the string sub̧on yields the string sub¸on which is Unicode-normalized since there is no precomposed
character for 'b cedilla' in NFC. This string is therefore also
include-normalized. Similarly, the string sub&word-end; (with &word-end; as above) is include-normalized, for the same reasons.
In an XML or HTML context, the strings ¸on (U+0327 U+006F U+006E) and ̧on are not fully-normalized, as they begin with a composing character
(after expansion of the character escape for the second). However, both are
Unicode-normalized (if expressed in a Unicode encoding form) and
include-normalized.
The following table consolidates the above examples. Normalized
forms are indicated using 'Y', a hyphen means 'not
normalized'.
3.3.2 Examples of XML in a Unicode
encoding form
Here is another summary table, with more examples but limited to
XML in a Unicode encoding form. The following list describes what the entities
contain and special character usage. Normalized forms are indicated using
'Y'. There is no precomposed 'b with cedilla' in NFC.
"ç"
LATIN SMALL LETTER C WITH
CEDILLA
"¸la;"
CEDILLA
(combining)
"&c;"
LATIN SMALL LETTER
C
"&b;"
LATIN SMALL LETTER
B
"¸"
CEDILLA (combining)
"/" (immediately before 'on' in
last example) COMBINING LONG SOLIDUS OVERLAY
NOTE: From the last example in the table above, it follows that it is
impossible to produce a normalized XML or HTML document containing the
character U+0338 COMBINING LONG SOLIDUS OVERLAY immediately
following an element tag, comment, CDATA section or processing instruction,
since the U+0338 '/' combines with the '>'
(yielding U+226F NOT GREATER-THAN). It is noteworthy that U+0338
COMBINING LONG SOLIDUS OVERLAY also combines with
'<', yielding U+226E NOT LESS-THAN.
Consequently, U+0338 COMBINING LONG SOLIDUS OVERLAY should
remain excluded from the initial character of XML identifiers.
3.3.3 Examples of restrictions on the use
of combining characters
Include-normalization and full-normalization create restrictions
on the use of combining characters. The following examples discuss various such
potential restrictions and how they can be addressed.
Full-normalization prevents the markup of an isolated combining
mark, for example for styling it differently from its base character (Benoi<span style='color: blue'>^</span>t, where '^' represents a combining circumflex). However,
the equivalent effect can be achieved by assigning a class to the accents in an
SVG font or using equivalent technology.
View an example using SVG (SVG-enabled
browsers only).
Full-normalization prevents the use of entities for expressing
composing characters. This limitation can be circumvented by using character
escapes or by using entities representing complete combining character
sequences. With appropriate entity definitions, instead of A´, write Á (or better, use 'Á' directly).
3.4 Responsibility for
Normalization
This section defines the W3C Text Normalization Model, based on early uniform normalization.
Unless otherwise specified, the word 'normalization' in
this section may refer to 'include-normalization' or
'full-normalization', depending on which is most appropriate for
the specification or implementation under consideration.
An operation
is normalization-sensitive if its output(s) are different
depending on the state of normalization of the input(s); if the output(s) are
textual, they are deemed different only if they would remain different were
they to be normalized. These operations are any that involve comparison of
characters or character counting, as well as some other operations such as
‘delete first character’ or ‘delete last character’.
EXAMPLE: Consider the string normalisé, where the 'é' may be a single
character (in NFC) or two. The following are three examples of normalization-sensitive operations involving this string. Counting the number of characters may yield either 9 or 10, depending
on the state of normalization. Deleting the last character may yield either normalis or
normalise (no accent). Comparing normalisé to normalisé
matches if both are in the same state of normalization, but doesn't match otherwise.
EXAMPLE: Examples of operations that are not normalization-sensitive are normalization, and the copying or deletion of an entire document.
A text-processing component is a component
that recognizes data as text. This specification does not specify the
boundaries of a text-processing component, which may be as small as one line of
code or as large as a complete application. A text-processing component may
receive text, produce text, or both.
Certified text is text which
satisfies at least one of the following conditions:
it has been confirmed through inspection that the text is in
normalized form
the source text-processing
component is identified and is known to produce only normalized
text.
Suspect text is text which is not certified.
NOTE: To normalize text, it is in general sufficient to store the last seen character, but in certain cases (a sequence of combining marks) a buffer of theoretically unlimited length is necessary. However, for normalization checking no such buffer is necessary, only a few variables. C Resources for
Normalization points to some compact code that shows how to check normalization without an expanding buffer.
Given the definitions and considerations above, specifications, implementations and
content have some responsibilities which are listed below. @@@Specifications, implementations and content ought to follow as many of the responsibilities as possible and make sure that this is done in a way that is consistent overall.
C300
[C]
Text content SHOULD be in
fully-normalized form and if not
SHOULD at least be in include-normalized
form.
C301
[S]
Specifications of
text-based formats and protocols SHOULD, as part of their
syntax definition, require that the text be in normalized
form.
C302
[S]
[I]
A
text-processing component that receives
suspect text
SHOULD NOT
perform any normalization-sensitive operations
unless it has first confirmed through inspection that the text is in normalized
form, and MUST NOT normalize the
suspect text. Private agreements
MAY, however, be created within private systems which are
not subject to these rules, but any externally observable results
SHOULD be the same as if the rules had been
obeyed.
C303
[I]
A text-processing component which modifies text and
performs normalization-sensitive operations
SHOULD behave as if normalization took place
after each modification, so that any subsequent
normalization-sensitive
operations always behave as if they were dealing with normalized
text.
EXAMPLE: If the 'z' is deleted
from the (normalized) string cz¸ (where '¸' represents a combining
cedilla, U+0327), normalization is necessary to turn the denormalized result c¸
into the properly normalized ç. If the software that deletes the 'z' later uses the string in a
normalization-sensitive operation, it needs to normalize the string before this operation to
ensure correctness; otherwise, normalization may be deferred until the data is
exposed. Analogous cases exist for insertion and
concatenation (e.g.
xf:concat(xf:substring('cz¸', 1, 1), xf:substring('cz¸', 3, 1)) in
XQuery [XQuery Operators]).
NOTE: Software that denormalizes a string such as in the deletion
example above does not need to perform a potentially expensive re-normalization
of the whole string to ensure that the string is normalized. It is sufficient
to go back to the last non-composing
character and re-normalize forward to the next non-composing
character; if the string was normalized before the denormalizing operation, it
will now be re-normalized.
C304
[S]
Specifications of
text-based languages and protocols SHOULD define precisely
the construct boundaries necessary to
obtain a complete definition of full-normalization. These definitions
SHOULD include at least the boundaries between
markup and character data as well as entity boundaries (if
the language has any include mechanism) and SHOULD include
any other boundary that may create denormalization when instances of the
language are processed.
C305
[C]
Even when authoring in a
(formal) language that does not mandate full-normalization, content developers
SHOULD avoid composing
characters at the beginning of constructs that may be significant, such as at
the beginning of an entity that will be included, immediately after a
construct that causes inclusion or
immediately after markup.
C306
[I]
Authoring tool
implementations for a (formal) language that does not mandate
full-normalization
SHOULD prevent users from creating content with
composing characters at the beginning of
constructs that may be significant, such
as at the beginning of an entity that will be included, immediately after a
construct that causes inclusion or
immediately after markup, or
SHOULD warn users when they do so.
C307
[I]
Implementations which
transcode text from a legacy encoding to
a Unicode encoding form
SHOULD use a normalizing transcoder.
NOTE: Except when an encoding's repertoire contains characters
not represented in Unicode, it is always possible to construct a normalizing transcoder by using any transcoder
followed by a normalizer.
C308
[S]
Where operations may produce unnormalized output from normalized text
input, specifications of API components (functions/methods) that implement
these operations MUST define whether normalization is the responsibility
of the caller or the callee. Specifications MAY state that
performing normalization is optional for some API components; in
this case the default SHOULD be that normalization is
performed, and an explicit option SHOULD be used to switch
normalization off. Specifications SHOULD NOT make the
implementation of normalization optional.
EXAMPLE: The concatenation operation may either concatenate sequences of
codepoints without normalization at the boundary, or may take normalization
into account to avoid producing unnormalized output from normalized input.
An API specification must define whether the operation normalizes at the
boundary or leaves that responsibility to the application using the API.
C309
[S]
Specifications that define
a mechanism (for example an API or a defining language) for producing textual data object SHOULD require that the final output of this
mechanism be normalized.
EXAMPLE: XSL Transformations [XSLT] and the DOM Load & Save specification
[DOM3 LS] are examples of specifications that define text output and that should
specify that this output be in normalized form.
NOTE: As an optimization, it is perfectly acceptable for a
system to define the producer to be the actual producer (e.g.
a small device) together with a remote component (e.g. a server serving as a
kind of proxy) to which normalization is delegated. In such a case, the
communications channel between the device and proxy server is considered to be
internal to the system, not part of the Web. Only data normalized
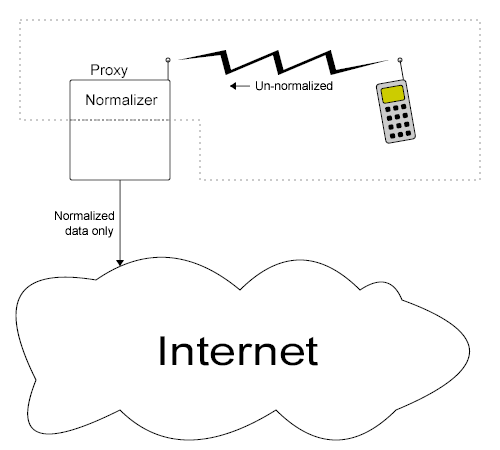
by the proxy server is to be exposed to the Web at large, as shown in the
illustration below:
A similar case would be that of a Web repository receiving
content from a user and noticing that the content is not properly normalized.
If the user so requests, it would certainly be proper for the repository to
normalize the content on behalf of the user, the repository becoming
effectively part of the producer for the duration of that
operation.
C310
[S]
[I]
Specifications and implementations
MUST document any deviation from the above requirements.
C311
[S]
Specifications
MUST document any known security issues related to
normalization.
4 String Identity Matching
One important operation that depends on early normalization is
string identity matching
[CharReq], which is a
subset of the more general problem of string matching. There are various
degrees of specificity for string matching, from approximate matching such as
regular expressions or phonetic matching, to more specific matches such as
case-insensitive or accent-insensitive matching and finally to identity
matching. In the Web environment, where multiple character encodings are used to
represent strings, including some character encodings which allow multiple
representations for the same thing, identity is defined to occur
if and only if the compared strings contain no user-identifiable distinctions.
This definition is such that strings do not match when they differ in case or
accentuation, but do match when they differ only in non-semantically
significant ways such as character encoding, use of character escapes (of potentially different kinds), or use of precomposed vs.
decomposed character sequences.
To avoid unnecessary conversions and, more importantly,
to ensure predictability and correctness, it is necessary for all components of
the Web to use the same identity testing mechanism. Conformance to the rule
that follows meets this requirement and supports the above definition of
identity.
C312 [S] [I] String
identity matching MUST be performed as if the following
steps were followed:
Step 1 ensures 1) that the identity matching process can produce
correct results using the next three steps and 2) that a minimum of effort is
spent on solving the problem.
NOTE: The expansion of character escapes and includes (step 3 above) is
dependent on context, i.e. on which markup or programming language is
considered to apply when the string matching operation is performed. Consider a
search for the string 'suçon' in an XML document containing suçon but not suçon. If the search is performed in a plain text editor, the context is
plain text (no markup or programming language applies), the
ç character escape is not recognized, hence not expanded and the
search fails. If the search is performed in an XML browser, the context is
XML, the character escape (defined by XML) is expanded and the
search succeeds.
An intermediate case would be an XML editor that
purposefully provides a view of an XML document with entity
references left unexpanded. In that case, a search over that pseudo-XML view
will deliberately not expand entities: in that particular context,
entity references are not considered includes and need not be expanded.
C313 [S] [I] Forms of
string matching other than identity matching SHOULD be
performed as if the following steps were followed:
Appropriate methods of matching text outside of string identity
matching can include such things as case-insensitive matching,
accent-insensitive matching, matching characters against Unicode compatibility
forms, expansion of abbreviations, matching of stemmed words, phonetic
matching, etc.
EXAMPLE: A user who specifies a search for the string suçon against a Unicode encoded XML document would expect to find string identity matches against the strings suçon, suçon and suçl;on (where the entity ç represents the precomposed character 'ç'). Identity matches should also be found whether the string was encoded as 73 75 C3 A7 6F 6E (in UTF-8) or 0073 0075 00E7 006F 006E (in UTF-16), or any other character encoding that can be transcoded into normalized Unicode characters.
It should never be the case that a match would be attempted against strings such as suçon or suc¸on since these are not fully-normalized and should cause the text to be rejected. If, however, matching is done against such strings they should also match since they are canonically equivalent.
Forms of matching other than identity, if supported by the application, would have to be used to produce a match against the following strings: SUÇON (case-insensitive matching), sucon (accent-insensitive matching), suçons (matched stems), suçant (phonetic matching), etc.
{kind=link}