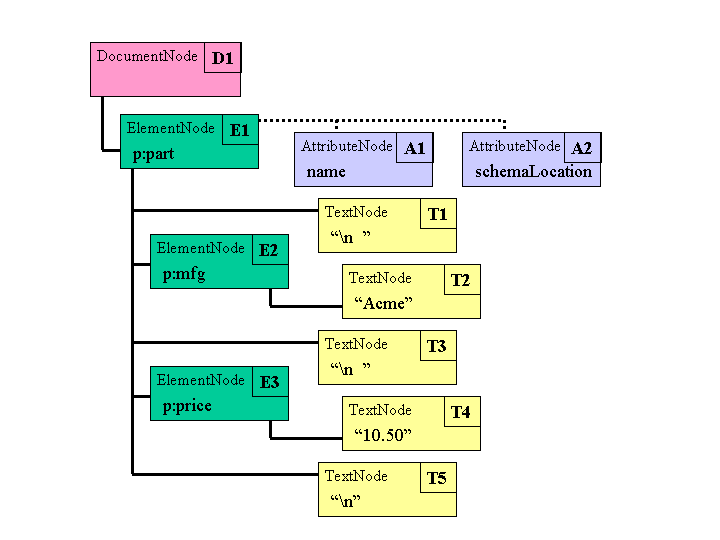
1 Introduction
This document defines the XQuery 1.0 and XPath 2.0 Data Model,
which is the data model of [XSLT 2.0] and
[XQuery 1.0: A Query Language for XML] 1.0.
The XQuery 1.0 and XPath 2.0 Data Model (henceforth "data model")
serves two purposes.
First, it defines precisely the information contained in the input to an
XSLT or XQuery processor. Second, it defines all permissible values of
expressions in the XSLT, XQuery, and XPath languages. A
language is closed with respect to a data model if the value
of every expression in a language is guaranteed to be in the data model.
XSLT 2.0, XQuery 1.0, and XPath 2.0 are all closed with respect to
the data model.
The data model is based on the [XML Information Set]
(henceforth "Infoset"), but it requires the following new features to
meet the [XPath Requirements Version 2.0] and [XML Query Requirements]:
-
Support for XML Schema types. The XML Schema recommendations
define features, such as structures ([XMLSchema Part 1])
and simple data types ([XMLSchema Part 2]), that extend
the XML Information Set with precise type information.
-
Representation of collections of documents and of
complex values. ([XML Query Requirements])
As with the Infoset, the XQuery 1.0 and XPath 2.0 Data Model
specifies what
information in the documents is accessible, but it does not specify
the programming-language interfaces or bindings used to represent or
access the data.
Every value handled by the data model is either a sequence of
zero or more items, or an error. An item is either a
node or an atomic value.
A node is defined in 4 Nodes and is one of seven node kinds.
An atomic value encapsulates an XML Schema atomic type
and a corresponding value of that type. They are defined in
5 Atomic Values.
A sequence is an ordered collection of nodes, atomic values, or any
mixture of nodes and atomic values. A sequence cannot be a member of
a sequence. A single item appearing on its own is modeled as a sequence
containing one item. Sequences are defined in 6 Sequences.
The error value is defined in 7 Error.
Note: In XPath 1.0, the data model only
defines nodes. The primitive data types (number, boolean, string,
node-set) are part of the expression language, not
the data model.
The data model can represent various
values including not only the input and the output of a query, but all
values of expressions used during the intermediate calculations.
Examples include the input document or document repository (represented
as a document node or a sequence of document nodes), the result of a
path expression (represented as a sequence of nodes), the result of an
arithmetic or a logical expression (represented as an atomic value),
a sequence expression resulting a sequence of integers, dates, QNames or
other XML Schema atomic values (represented as a sequence of
atomic values), etc.
Examples of values that cannot be expressed directly by the data model
include schema components, sets containing both
atomic values and the error value, atomic values whose type
is not an XML Schema atomic type, etc.
In this document, we provide a precise definition of how values in the
XQuery 1.0 and XPath 2.0 Data Model are constructed and accessed, and how
they relate to values in the Infoset. We note wherever the XQuery 1.0 and
XPath 2.0 Data Model differs from that of XPath 1.0.
2 Notation and Pseudo-code Syntax
In addition to using prose, we define the data model using a functional
notation. We chose this notation because it is simple and permits a
precise definition of the data model, suitable for use by the formal
semantics of XQuery. Although the notation has a functional style, we
emphasize that the data model can be realized in a variety of
programming languages and styles, for example, as object classes and
methods in an object-oriented language.
Pseudo-code syntax is highlighted as follows:
In the psuedo-code syntax, the term Node denotes
the category of node values, AtomicValue denotes the
category of atomic values, and Item refers to the
category of either node values or atomic values.
V* denotes the category of sequence
values all of whose members are in category V.
V? and V+ denote subcategories of
V*: The former denotes the category of sequences
containing zero or one items, the latter refers to sequences
containing one or more items.
In a sequence, V may be a Node or
AtomicValue, or the union (choice) of several categories of
Items. For example, the following denotes a category of
sequence containing any combination of comment and processing instruction
nodes:
There are some functions in the data model that are partial
functions. We use the occurrence indicators ? or
* when specifying the return type of such functions.
For example, a node may have one parent node or no parent.
If the node argument has a parent, the
dm:parent accessor returns a singleton sequence. If the node
argument does not have a parent, it returns the empty sequence.
The signature of dm:parent specifies that it returns
an empty sequence or a sequence containing one element or document node:
The pseudo-code syntax defines functions to construct values,
called constructors; and functions to access parts of
values, called accessors (see [Issue-0033: Unclear relationship between values passed to the constructor,
and those returned by the accessor]).
The constructors and accessors defined by the data model are prefixed
with dm
Note: The XPath 1.0 data model defines accessors, but does not
define constructors.
The term signature of a function specifies the
type of its zero or more inputs and the type of its one
output. The following signature denotes a function f that
takes values in the categories V1, ...,
Vm and returns an output value in the category
Vn.
function f(V1 $v1, ..., Vm $vm) returns Vn
A member of a particular category is a permissible argument to any
function that accepts the category, for example, a
ProcessingInstructionNode is a permissible argument to a
function expecting a Node.
This document relies on the [XML Information Set]. Information items
and properties are indicated by the styles information
item and [property], respectively.
This document also provides pseudo-code syntax describing the mapping
from the Infoset to the data model. To facilitate this we introduce accessors
to the required infoset properties through InfoItem objects.
These infoset accessors are for rhetorical purposes only and are not intended to be exposed outside this
specification. We name the accessors of the Infoset using the convention
infoset-<item-name>-<property-name>.
Similarly, accessor functions that return PSV Infoset properties use the
naming convention psvi-<item-name>-<property-name>.
For example, infoset-element-attributes is the accessor that
returns an element information item's [attributes]
property:
An InfoItem is one of eleven kinds of item: document
item, element item, attribute item, processing instruction item,
unexpanded entity item, character item, comment item, doctype item,
unparsed entity item, notation item, and namespace item.
The infoitem-kind accessor
returns a string value representing the information item's kind, either
"document", "element", "attribute",
"character", "namespace",
"processing-instruction", "comment", "doctype",
"notation", or "unparsed-entity".
function infoitem-kind(InfoItem $ii) returns xs:string
Throughout this document, the namespace prefix xs indicates
the [XMLSchema Part 1] namespace name
http://www.w3.org/2001/XMLSchema.
The namespace prefixes xf and op indicate
the namespace of the functions and operators defined in
[XQuery 1.0 and XPath 2.0 Functions and Operators].They are associated with the namespace names
http://www.w3.org/2001/12/xquery-functions and
http://www.w3.org/2001/12/xquery-operators respectively.
The following functions and operators are defined in
[XQuery 1.0 and XPath 2.0 Functions and Operators]:
-
op:concatenate
-
op:item-at
-
op:value-equal
-
xf:anyURI
-
xf:concat
-
xf:count
-
xf:decimal
-
xf:empty
-
xf:get-local-name
-
xf:get-namespace-uri
-
xf:NCName
-
xf:QName
-
xf:QName-from-uri
-
xf:QName-from-string
-
xf:string
-
xf:sublist
3 Concepts
3.1 Node Identity
Because XML documents are tree-structured, we define the
data model using conventional terminology for trees. The data model is
a node-labeled, tree-constructor representation, but also includes a
concept of node identity. The identity of a node is established
when a node-constructor is applied to create the node: each
application of a node constructor creates a new node that is
identical to itself, and not identical to any other node
(see 4 Nodes).
The dm:node-equal function takes two nodes as arguments.
It returns true if the arguments are identical and false otherwise.
This concept should not be confused with the concept of
unique ID, which is a unique name assigned to an
element by the author to represent references using ID/IDREF
correlation.
3.2 Document Order
A document order is defined on all the nodes in a
document. The document node is the first node. Element nodes,
comment nodes, and processing instruction nodes occur in the
order of their representation in the XML (after expansion of
entities). Element nodes occur before their children. The
namespace nodes of an element immediately follow the element node
(see [Issue-0051: Document order of shared namespace nodes]).
The relative order of namespace nodes is implementation-dependent.
The attribute nodes of an element immediately follow the
namespace nodes of the element. The relative order of attribute
nodes is implementation-dependent. Reverse document order is the
reverse of document order.
The relative order of nodes in distinct documents is
implementation-dependent but stable. In other words, given
two distinct documents A and B, if a node in document A is
before a node in document B, then every node in document A
is before every node in document B.
The dm:node-before function takes two nodes as arguments.
It returns true if the first argument is before (but not identical
to) the second one in document order and false otherwise
3.3 XML Schemas and the XML Information Set
The data model is defined in terms of the
[XML Information Set] after XML Schema validity assessment.
XML Schema validity assessment is the process of assessing an XML
element information item with respect to an XML Schema and
augmenting it and some or all of its descendants with properties
that provide information about validity and type assignment.
The result of schema validity assessment is an augmented
Infoset, known as the Post Schema-Validation Infoset, or
PSVI.
The data model supports the following classes of XML documents:
-
Schema-validated documents, i.e., those validated with respect
to a schema,
-
DTD-valid documents, i.e., those documents validated with respect
to a DTD, and
-
Well-formed documents with no corresponding DTD or schema.
The data model does not support XML documents that are not supported by
the XML Information Set, for example, non-well-formed documents and documents
that don't conform to XML Namespaces.
Schema-validated documents include documents in which some elements
or attributes have been validated by "lax" or "skip" validation
([XMLSchema Part 2]).
An "incompletely validated document" is an XML document that has a
corresponding schema but whose schema-validity assessment has resulted
in one or more element or attribute information items being assigned
values other than 'valid' for the [validity]
property in the PSVI.
The data model supports incompletely validated documents.
See [Issue-0024: Support for Schema-invalid documents].
Note: This implies accommodation for the case where
both a DTD and a schema are applied. This will probably require some
reconciliation of the [attribute type] property with type
information from the PSVI. See issue [Issue-0004: Schema/DTD].
3.4 Types
The data model supports a representation of named types as
expanded-QNames.
Named types include both the built-in types defined by XML Schema
Part 2 and types declared in a schema and imported by a query.
Since named types in XML Schema are global, an expanded-QName
uniquely identifies such a type, be it simple or complex:
The namespace of the expanded-QName is the target namespace
of the schema and its local name is the name of the type.
The data model does not uniquely identify anonymous types and
represents them by xs:anyType or xs:anySimpleType.
Editorial Note:
The usage of xs:unknownType or xs:anyType is currently under discussion.
An alternative is to represent named types by an optional expanded-QName
and use the empty sequence instead of xs:unknownType or xs:anyType.
The data model associates type information with element nodes
attribute nodes and atomic values. If this type information
is something other than xs:anyType or xs:anySimpleType, the item is
guaranteed to be a valid instance of that type as defined by XML Schema.
The data model defines an accessor dm:type() that returns
an expanded-QName corresponding to the type of the element node,
attribute node or atomic value, provided that the type is globally
declared. It returns xs:anyType or xs:anySimpleType if it is
locally declared or if no type information exists.
When no type information exists for an element or an attribute node
we frequently use the terminology "element with unknown type"
or "attribute with unknown simple type".
The data model does not represent element or attribute declaration
schema components, but it supports various type-related operations.
The semantics of such operations, e.g. checking if a particular
instance of an element node has a given type is defined in
[XQuery 1.0 Formal Semantics].
3.5 Mapping PSV Infoset additions to Types
This section specifies how the type of an element
or attribute node is computed from the PSV Infoset additions
that specify validity and type assessment for the node's corresponding
information item.
A PSV element (attribute) information item has a
[validity] and a
[type definition] property.
The [validity] property may be
"valid", "invalid", or "notKnown"
and reflects the outcome of the element's (attribute's)
schema-validity assessment.
The [type definition]
property contains an element information item that is
isomorphic to the XML Schema type definition of the
element or attribute information item.
Roughly speaking these two properties are used to compute the
type of an element or attribute in the data model, which
corresponds to the {target namespace} and the {name}
of the [type definition]
property if [validity] is
"valid", or to xs:anyType (xs:anySimpleType) otherwise.
Notice that the only information that can be inferred from an
invalid or not known validity value is that the information
item is well-formed, therefore, we must associate some general
type information with the element or attribute node.
The precise definition of the type of an element or attribute
information item is slightly more complex due to the following
factors.
First, XML Schema only guarantees the existence of either the
[type definition] property,
or the
[type definition namespace],
[type definition name] and
[type definition anonymous]
properties.
Second, if the type definition refers to a union type, there
are further properties defined, that refer to the type definition
which actually validated the element item's normalized value.
These properties are either the
[member type definition],
or the
[member type definition namespace],
[member type definition name] and
[member type definition anonymous]
properties.
If these are available the type of an element or attribute will
refer to the member type that actually validated the schema
normalized value.
Having identified all the relevant properties we can now define
how to compute a type.
The type of an element information item is
represented by an xs:QName whose namespace and local name corresponds
to the first applicable item in the following list:
-
xs:anyType if the [validity]
property is "invalid" or "notKnown", or
-
the {target namespace} and {name} properties of the
[member type definition]
schema component if that exists, or
-
the {target namespace} and {name} properties of the
[type definition]
schema component if that exists, or
-
the [member type definition namespace]
and the [member type definition name]
if [member type definition anonymous]
exists and is false, or
-
the [type definition namespace]
and the [type definition name]
if [type definition anonymous]
exists and is false, or
-
it corresponds to xs:anyType.
The type of an attribute information item is
represented by an xs:QName. Its definition is the same as for
element information items except for using xs:anySimpleType
instead of xs:anyType above.
We will find it convenient to define the following function
that will be used later in various sections.
The infoitem-to-type function takes an element or
an attribute information item and returns an xs:QName that
corresponds to the type of its argument.
function infoitem-to-type((ElementItem|AttributeItem) $ii) returns xs:QName
define function infoitem-to-type(ElementItem $ii)
{
if (psvi-element-validity($ii) ne "valid") then
return xf:QName-from-string("xs:anyType")
else if (psvi-element-member-type-definition($ii) ne ()) then
let $typedef:= psvi-element-member-type-definition($ii)
let $name:= psvi-typedefinition-name($typedef)
let $namespace:= psvi-typedefinition-namespace($typedef)
return xf:QName-from-uri($namespace,$name)
else if (psvi-element-type-definition($ii) ne ()) then
let $typedef:= psvi-element-type-definition($ii)
let $name:= psvi-typedefinition-name($typedef)
let $namespace:= psvi-typedefinition-namespace($typedef)
return xf:QName-from-uri($namespace,$name)
else if (psvi-element-member-type-definition-anonymous($ii) eq false) then
let $name:= psvi-element-member-type-definition-name($ii)
let $namespace:= psvi-element-member-type-definition-namespace($ii)
return xf:QName-from-uri($namespace,$name)
else if (psvi-element-type-definition-anonymous($ii) eq false) then
let $name:= psvi-element-type-definition-name($ii)
let $namespace:= psvi-element-type-definition-namespace($ii)
return xf:QName-from-uri($namespace,$name)
else
return xf:QName-from-string("xs:anyType")
}
function infoitem-to-type(AttributeItem $ii)
{
if (psvi-attribute-validity($ii) ne "valid") then
return xf:QName-from-string("xs:anySimpleType")
else if (psvi-attribute-member-type-definition($ii) ne ()) then
let $typedef:= psvi-attribute-member-type-definition($ii)
let $name:= psvi-typedefinition-name($typedef)
let $namespace:= psvi-typedefinition-namespace($typedef)
return xf:QName-from-uri($namespace,$name)
else if (psvi-attribute-type-definition(a) ne ()) then
let $typedef:= psvi-attribute-type-definition($ii)
let $name:= psvi-typedefinition-name($typedef)
let $namespace:= psvi-typedefinition-namespace($typedef)
return xf:QName-from-uri($namespace,$name)
else if (psvi-attribute-member-type-definition-anonymous($ii) eq false) then
let $name:= psvi-attribute-member-type-definition-name($ii)
let $namespace:= psvi-attribute-member-type-definition-namespace($ii)
return xf:QName-from-uri($namespace,$name)
else if (psvi-attribute-type-definition-anonymous($ii) eq false) then
let $name:= psvi-attribute-type-definition-name($ii)
let $namespace:= psvi-attribute-type-definition-namespace($ii)
return xf:QName-from-uri($namespace,$name)
else
return xf:QName-from-string("xs:anySimpleType")
}
Editorial Note: MF:
Following two cases need to be completed:
Given information items that validate with respect to a DTD, ...
Given information items from a document
a well-formed document, with no corresponding DTD or Schema...
3.6 Text Nodes and Sequences of Atomic Values
The data model supports two representations of the character data
that appears as element content: text nodes or a sequence of atomic values.
Similarly, character data of attributes can also be represented in two
ways: as a string or a sequence of atomic values.
A text node represents a string of consecutive character information
items and never has another text node as its immediately following sibling.
An element node, for example, has child nodes
that may include text nodes, comment nodes, processing instruction nodes,
and other element nodes. In addition, the text content of an element may be
interpreted as a sequence of atomic values, such as an integer, a date, or a
sequence of prices. To illustrate, consider an element node whose type is a
sequence of double-precision numbers. The element's children are three nodes:
a text node with string contents " 12.00 ", followed by a comment node,
followed by a text node with contents " 13.0", whereas its atomic value
is a sequence containing the double-precision numbers 12.0 and 13.0.
It is noted that the two representations of character data are not
equivalent. A sequence of atomic values contains more type information
then a text-node or string representation when the atomic values are
of different types (e.g. a sequence containing an integer, a date and a
string). Since the text node child does not contain enough type
information to reconstruct this typed value, an implementation must
store the element's typed value separately from the text node.
This precludes a "text node only" implementation.
3.7 Ignoring Comments, Processing Instructions, and Whitespace
Although the data model is able to represent comments, processing
instructions, and insignificant whitespace, preservation of this information
may be unnecessary and onerous for some applications.
Construction of a document from an XML information set is
parameterized by three flags, ignore-comments,
ignore-processing-instructions, and ignore-whitespace.
If the ignore-comments flag is true, comment nodes are not
preserved in the data model. If the ignore-processing-instructions
flag is true, processing-instruction nodes are not preserved in the
data model. If the ignore-whitespace flag is true,
insignificant whitespace is not preserved.
ignore-comments : xs:boolean
ignore-processing-instructions : xs:boolean
ignore-whitespace : xs:boolean
Expressions which rely upon the presence or absence of comments,
processing instructions, or insignificant whitespace may produce different
results for two data models created from the same infoset (XML document),
when each data model is constructed with different settings of these flags.
Insignificant whitespace is defined as a text node that:
-
contains no characters other than whitespace characters
(as defined in XML 1.0), and
-
has a parent element with a [validity]
property with the value "valid", and a
[type definition] property yielding
a complex type with content-type of element-only.
4 Nodes
The category of Node values contains seven distinct
kinds of nodes: document,
element, attribute,
text, namespace,
processing instruction, and
comment. The seven kinds of nodes are
defined in the following subsections.
Each kind of node has its own constructor. The effect of a node
constructor is to create a new node with a unique identity, distinct
from all other nodes.
A set of accessors is defined on all seven kinds of Nodes. Some
accessors return a constant empty sequence on certain node kinds.
-
The dm:node-kind accessor returns a string value
representing the node's kind: either "document",
"element", "attribute", "text",
"namespace", "processing-instruction", or
"comment".
-
The dm:name accessor returns a sequence containing
one expanded QName for node kinds that can have names.
For other node kinds, it always returns an empty sequence.
An expanded QName is in the value space of xs:QName,
and consists of a namespace URI and a local name. See
[Issue-0063: Is prefix preserved?], [Issue-0070: Should the name accessor return "" or ()?].
-
The dm:base-uri accessor returns a sequence containing
zero or one uri references for node kinds that can have a base-uri
(document nodes and element nodes). For other
node kinds, it always returns the empty sequence.
-
The dm:string-value accessor returns the node's
string representation. For some kinds of nodes, this is part of
the node; for other kinds of nodes, it is computed from the
dm:string-value of its descendant nodes.
-
The dm:typed-value accessor returns a sequence of
atomic values corresponding to the node. This may be a
non-empty sequence for element and attribute nodes, but it is always
the empty sequence for other node kinds.
-
The dm:parent accessor returns a sequence containing
zero or one nodes for node kinds that can have parents. For other
node kinds, it always returns the empty sequence.
Every node has at most one parent, which is either
an element node or the document node. A node that has no parent is
regarded as the root of a tree. The one exception is a namespace node,
which never has a parent.
Note: In XPath 1.0, Namespace nodes have parents.
-
The dm:children accessor returns a sequence containing
zero or more nodes for node kinds that can have children (document
nodes and element nodes). For other node kinds, it always returns
the empty sequence.
A document node or an element node is the parent of each of
its child nodes. Nodes never share children: if two nodes have
distinct identities, then no child of one node will be a child of
the other node.
-
The dm:attributes accessor returns a sequence containing
zero or more attribute nodes for element nodes. For other node kinds,
it always returns the empty sequence.
-
The dm:namespaces accessor returns a sequence containing
zero or more namespace nodes corresponding to the in-scope namespaces
for element nodes.
For other node kinds, it always returns the empty sequence.
-
The dm:type accessor returns a sequence containing one
expanded-QName corresponding to the type of the element node or
attribute node, provided that the type is globally declared. It
returns xs:anyType or xs:anySimpleType if it is locally declared
or if no type information exists. For other node kinds, it always
returns the empty sequence.
-
The dm:unique-ID accessor returns a sequence containing
zero or one ID for element nodes. For other node kinds,
it always returns the empty sequence.
The return types of the Node accessors are given below. Some kinds of nodes
further restrict the return types; notably, many node kinds return a
constant empty sequence for some of the accessors.
A tree contains a root plus all nodes that are reachable
directly or indirectly from the root via the dm:children,
dm:attributes, and dm:namespace accessors. Every
node belongs to exactly one tree, and every tree has exactly one root
node. A tree whose root node is a document node is referred to as a
document. A tree whose root node is some other kind of
node is referred to as a fragment.
4.1 Documents
| Document Node accessors |
possible values |
| dm:node-kind |
"document" |
| dm:name |
empty sequence |
| dm:base-uri |
xs:anyURI |
| dm:string-value |
xs:string |
| dm:typed-value |
empty sequence |
| dm:parent |
empty sequence |
| dm:children |
arbitrary sequence of one or more
element nodes, zero or more processing
instruction nodes, and zero or more
comment nodes |
| dm:attributes |
empty sequence |
| dm:namespaces |
empty sequence |
| dm:type |
empty sequence |
| dm:unique-ID |
empty sequence |
A document is represented by a document node, which corresponds
to a document information item.
Note: Document nodes and XPath 1.0 root nodes are essentially
identical.
A document node does not have an expanded-QName.
The dm:base-uri of the document corresponds to the
[base URI] property.
The dm:string-value of the document node is the
concatenation of the string-values of all text-node descendants of
the document node in document order.
The dm:parent of the document node is always the empty
sequence. A document node always represents the root of a tree.
The dm:children of the document node are nodes corresponding
to the information items found in the
[children] property, omitting
any document type declaration information
items.
In a well-formed document, the children of the document node consist
exclusively of element nodes, processing-instruction nodes, and comment
nodes, and exactly one of these children is an element node. A document
node in the data model is more permissive: it permits more than one
element node as a child and also permits text nodes as children.
A document node has the constructor dm:document-node,
which takes a base URI value and a non-empty sequence of its children nodes.
Like all other node constructors, the document-node constructor has the
effect of creating a new node with a unique identity, distinct from all
other nodes.
The accessors dm:base-uri and dm:children return a
document node's constituent parts:
The accessors dm:node-kind and dm:string-value
also apply to document nodes and return results other than the empty sequence.
The accessors dm:name, dm:typed-value,
dm:parent, dm:attributes, dm:namespaces,
dm:type and dm:unique-ID
applied to a document node always return the empty sequence.
A document node is constructed from a Document Information
Item by the infoitem-to-document-node function:
The collapse-text-nodes
function synthesizes a single text node from multiple text nodes. The
sequence-map function
applies its first function argument to each member of its second
sequence argument and returns a new sequence containing the result
of applying the function to each member of the sequence. In the pseudo-code
above, infoitem-to-node is applied to each child of the
document information item$ii and a new sequence of children nodes is constructed,
each of which is a Node. The constructor
dm:document-node constructs the document node in the data
model.
function sequence-map(function $map, Item* $seq) returns Item*
The infoitem-to-node function maps an information item
to a sequence of zero or one node.
4.2 Elements
| Element Node accessors |
possible values |
| dm:node-kind |
"element" |
| dm:name |
xs:QName |
| dm:base-uri |
xs:anyURI |
| dm:string-value |
xs:string |
| dm:typed-value |
sequence of zero or more atomic values |
| dm:parent |
sequence of zero or one element or document node |
| dm:children |
sequence of zero or more element nodes,
zero or more processing instruction nodes,
zero or more comment nodes, and zero or more
text nodes |
| dm:attributes |
sequence of zero or more attribute nodes |
| dm:namespaces |
sequence of zero or more namespace nodes |
| dm:type |
xs:QName |
| dm:unique-ID |
zero or one xs:ID |
Each element node corresponds to an element
information item.
An element node has an expanded-QName. The local part
of the expanded-QName corresponds to the
[local name] property.
The namespace URI of the expanded-QName of the element node
corresponds to the [namespace name]
property.
The dm:parent of the element node corresponds to the node
corresponding to the [parent] property.
An element node has an associated dm:typed-value,
which is a sequence of zero or more atomic values. Examples of such
values would be a sequence containing an integer, or an atomic value
of some user-defined type or several dates, etc.
For a document with a schema, the element's typed-value corresponds
to the [schema normalized value]
PSVI property if that exists, or the empty sequence otherwise.
But if the element node has a complex type with complex
content then dm:typed-value returns the error value.
Furthermore, if the type of the element node is xs:anyType or
xs:anySimpleType then dm:typed-value returns its string
value with unknown simple type.
In particular this implies the following:
If an element was created with an xsi:nil attribute set to true,
then its dm:typed-value is the empty sequence.
For an element in a well-formed document with no associated schema,
the element's dm:typed-value is its string value with
unknown simple type. See [Issue-0071: Magic Attributes].
The dm:children of the element node
correspond to the element, comment, processing instruction, and
character information items appearing in the
[children] property.
This correspondence is not one-to-one, as consecutive
character information item children
are coalesced into a single text node. Because the data model requires
that all general entities be expanded, there will never be
unexpanded entity reference information item
children.
The dm:attributes of the element node are nodes
corresponding to attribute information
items appearing in the
[attributes] property. The
attributes of an element always have distinct names.
The dm:namespaces of the element node are nodes
corresponding to namespace information items
appearing in the [in-scope namespaces]
property. The namespaces of an element always have distinct prefixes.
See [Issue-0062: Namespace fixups required].
The dm:type of an element is an xs:QName and
its namespace and local name correspond to the following:
-
xs:anyType if the [validity]
property is "invalid" or "notKnown", or
-
the {target namespace} and {name} properties of the
[member type definition]
schema component if that exists, or
-
the {target namespace} and {name} properties of the
[type definition]
schema component if that exists, or
-
the [member type definition namespace]
and the [member type definition name]
if [member type definition anonymous]
exists and is false, or
-
the [type definition namespace]
and the [type definition name]
if [type definition anonymous]
exists and is false, or
-
it corresponds to xs:anyType.
It is noted that if the type referenced would be a union type then
type refers to the member type that actually validated the
schema normalized value.
See [Issue-0064: Including type definition in element constructors].
The unique ID of the element node is an identifier
optionally assigned by the user. It corresponds to the
[normalized value] property
of the attribute information item
in the [attributes]
property that has a type ID, if one exists.
An element node can be constructed in one of two
ways: dm:element-node is useful for constructing an element
from the PSVI, dm:element-node-atomic is useful when
constructing an element via embedded expressions. The difference in
the constructors is whether the children of the node are specified
as a sequence of nodes or as a sequence of atomic values.
The constructor
dm:element-node takes an expanded-QName,
a sequence of namespace nodes, a sequence of attribute nodes, a
sequence of child nodes, and the node's type.
The constructor dm:element-node-atomic
takes an expanded-QName,
a sequence of namespace nodes, a sequence of attribute nodes, a
sequence of atomic values, and the node's type.
Like all other node constructors, the element node
constructors has the effect of creating a new node with a unique
identity, distinct from all other nodes.
To guarantee that the parent-child relationship is
invertible, the element constructors logically create a copy of all of their
namespace, attribute, and children arguments and set the parent property
of these nodes to the newly created element node. As long as the parent-child
constraint is satisfied, an implementation of the data model may choose to
use specialized techniques to avoid creating physical copies of the
arguments to an element constructor. See [Issue-0052: Element constructor copies nodes?].
Neither constructor allows specifying the children of the node
as a heterogeneous sequence, i.e. a sequence mixing nodes and atomic
values. It is still possible to construct an element (with
mixed content) from such a sequence in two steps:
First the heterogeneous sequence will need to be turned into a
homogeneous one by converting the atomic values to text nodes,
then the now homogeneous sequence can be passed to the
element-node constructor.
Note that the precise type information of the atomic values is
lost in the process, which is inline with XML Schema, that cannot
represent the type of such mixed content.
The accessors dm:name, dm:namespaces,
dm:attributes and dm:type return an
element node's constituent parts.
The dm:children accessor returns the sequence of children
nodes for an element node if it was created with dm:element-node
and it returns a singleton sequence containing a text node corresponding
to the sequence of atomic values if it was created with
dm:element-node-atomic.
The string value of the text node in the latter case is the string
value of the sequence of atomic values, which is obtained by inserting
a #x20 (space) separator between the dm:string-values of the individual
atomic values and concatenating the result (as defined in
6 Sequences).
See [Issue-0068: Retaining the type of a sequence of heterogeneous simple typed values.].
The accessor function dm:typed-value returns a sequence
of zero or more atomic values. If the element was created with
dm:element-node, dm:typed-value corresponds
to the [schema normalized value]
PSVI property if that exists, or the empty sequence otherwise.
But if the element node has a complex type with complex
content then dm:typed-value returns the error value.
Furthermore, if the type of the element node is xs:anyType or
xs:anySimpleType then dm:typed-value returns its string
value with unknown simple type.
If the element was created with dm:element-node-atomic,
dm:typed-value returns the sequence of atomic values
that were used to construct the element.
The dm:string-value of an element node returns the concatenation
of the string-values of all text-node descendants of the element node in
document order if it was created with dm:element-node
and it returns the string representation of the sequence of atomic values
if it was created with dm:element-node-atomic. See [Issue-0073: Whitespace normalization of the string-value of elements with simple content].
If an element has a unique ID, the accessor function dm:unique-ID
returns a sequence containing the unique ID of the node; otherwise, it
returns the empty sequence.
The node accessors dm:base-uri, dm:node-kind,
dm:parent, and dm:string-value also apply to
element nodes.
An element node is constructed from an Element Information
Item by the infoitem-to-element-node function:
define function infoitem-to-element-node(ElementItem $ii) returns ElementNode
{
let $qname:= xf:QName-from-uri(infoset-element-namespace-name($ii),
infoset-element-local-name($ii)),
$nsnodes:= sequence-map(infoitem-to-namespace-node,
infoset-element-in-scope-namespaces($ii)),
$attrnodes:= sequence-map(infoitem-to-attribute-node,
infoset-element-attributes($ii)),
$kids:= collapse-text-nodes(sequence-map(
infoitem-to-node, infoset-element-children($ii))),
$type:= infoitem-to-type($ii)
return dm:element-node($qname, $nsnodes, $attrnodes, $kids, $type)
}
4.3 Attributes
| Attribute Node accessors |
possible values |
| dm:node-kind |
"attribute" |
| dm:name |
xs:QName |
| dm:base-uri |
empty sequence |
| dm:string-value |
xs:string |
| dm:typed-value |
sequence of zero or more atomic values |
| dm:parent |
sequence of zero or one element nodes |
| dm:children |
empty sequence |
| dm:attributes |
empty sequence |
| dm:namespaces |
empty sequence |
| dm:type |
xs:QName |
| dm:unique-ID |
empty sequence |
Each element node has an associated set of attribute nodes, each
corresponding to an attribute
information item.
An attribute node has an expanded-QName. The local part
of the expanded-QName corresponds to the
[local name] property. The namespace
name of the expanded-QName corresponds to the
[namespace name] property.
An attribute node has an associated dm:string-value,
which corresponds to the
[normalized value] property.
An attribute node also has a dm:typed-value. For a
document with a schema, the attribute's typed-value corresponds to
the [schema normalized value]
PSVI property.
But if the type of the attribute node is xs:anySimpleType then
dm:typed-value returns its string value with unknown
simple type.
For convenience, the element node is called the "parent" of each of
these attribute nodes even though an attribute node is not a "child" of
its parent element. The dm:parent of the attribute node
corresponds to the [owner element]
property.
The dm:type of an attribute is an xs:QName and
its namespace and local name correspond to the following:
-
xs:anySimpleType if the [validity]
property is "invalid" or "notKnown", or
-
the {target namespace} and {name} properties of the
[member type definition]
schema component if that exists, or
-
the {target namespace} and {name} properties of the
[type definition]
schema component if that exists, or
-
the [member type definition namespace]
and the [member type definition name]
if [member type definition anonymous]
exists and is false, or
-
the [type definition namespace]
and the [type definition name]
if [type definition anonymous]
exists and is false, or
-
it corresponds to xs:anySimpleType.
It is noted that if the type referenced would be a union type then
type refers to the member type that actually validated the
schema normalized value.
An attribute node can be constructed in one of two ways:
dm:attribute-node is useful for constructing an attribute
from the PSVI, dm:attribute-node-atomic is useful when
constructing an attribute with embedded expressions.
The constructor
dm:attribute-node
takes the attribute's name, a string value and the attribute's type.
The constructor
dm:attribute-node-atomic takes the attribute's name, a
list of atomic values and the attribute's type.
Like all other node constructors, the attribute node
constructors have the effect of creating a new node with a unique
identity, distinct from all other nodes.
The accessors dm:name and dm:type return an
attribute's constituent parts.
The accessor dm:string-value returns an attribute's
constituent part if it was created with dm:attribute-node
and it returns the string representation of the sequence of atomic values
if it was created with dm:attribute-node-atomic.
The accessor function dm:typed-value returns
a sequence of the atomic values of an attribute.
In particular if the type of the attribute node is xs:anySimpleType
then dm:typed-value returns its string value with unknown
simple type.
The node accessors dm:node-kind and dm:parent
also apply to attribute nodes and may return results other than the
empty sequence.
The accessors dm:base-uri, dm:children,
dm:attributes, dm:namespaces and dm:unique-ID
applied to an attribute node always return the empty sequence.
An attribute node is constructed from an Attribute Information
Item by the infoitem-to-attribute-node function:
define function infoitem-to-attribute-node(AttributeItem $ii) returns AttributeNode
{
let $qname:= xf:QName-from-uri(infoset-attribute-namespace-name($ii),
infoset-attribute-local-name($ii)),
$type:= infoitem-to-type($ii)
return dm:attribute-node($qname, infoset-attribute-normalized-value($ii), $type)
}
Editorial Note: JM: Update the above to accommodate the possibility of
schema-less and DTD validation.
4.4 Namespaces
| Namespace Node accessors |
possible values |
| dm:node-kind |
"namespace" |
| dm:name |
sequence of zero or one xs:QName |
| dm:base-uri |
empty sequence |
| dm:string-value |
xs:string |
| dm:typed-value |
empty sequence |
| dm:parent |
empty sequence |
| dm:children |
empty sequence |
| dm:attributes |
empty sequence |
| dm:namespaces |
empty sequence |
| dm:type |
empty sequence |
| dm:unique-ID |
empty sequence |
Each element node has an associated set of namespace nodes, each
corresponding to a namespace information item.
A namespace node has an expanded-QName. The local part of the
QName corresponds to the [prefix]
property. The namespace URI of the QName is the empty
sequence.
The dm:string-value of the namespace node corresponds to
the [namespace name] property.
A namespace node has no dm:parent.
A namespace node has the constructor
dm:namespace-node, which takes a namespace prefix and
the absolute URI of the namespace being declared. The namespace prefix may
be the empty sequence. If the URI is the zero-length string, the prefix must
be the empty sequence.
Like all other node constructors, the namespace node
constructor has the effect of creating a new node with a unique identity,
distinct from all other nodes.
A namespace node's constituent parts may be obtained by applying
the accessors dm:name (with the function
xf:get-local-name) and
dm:string-value.
The node accessor dm:node-kind also applies to namespace nodes
and returns a result other than the empty sequence.
The accessors dm:base-uri, dm:typed-value,
dm:parent, dm:children, dm:attributes,
dm:namespaces, dm:type and
dm:unique-ID applied to a namespace node always return the empty
sequence.
A namespace node is constructed from a Namespace Information
Item by the infoitem-to-namespace-node function:
4.5 Processing Instructions
| Processing Instruction Node accessors |
possible values |
| dm:node-kind |
"processing-instruction" |
| dm:name |
xs:QName |
| dm:base-uri |
empty-sequence |
| dm:string-value |
xs:string |
| dm:typed-value |
empty sequence |
| dm:parent |
sequence of zero or one element or document nodes |
| dm:children |
empty sequence |
| dm:attributes |
empty sequence |
| dm:namespaces |
empty sequence |
| dm:type |
empty sequence |
| dm:unique-ID |
empty sequence |
A processing instruction node corresponds to a processing
instruction information item. There are no processing instruction
nodes for processing instructions that are children of a
document type declaration information item.
A processing instruction node has an expanded-QName. The local part of the
expanded-QName corresponds to the [target]
property. The namespace URI of the expanded-QName is
the empty sequence. The local part is a string value that must be an NCName.
The string '?>' may not occur within a processing instruction's
target value ([XML Recommendation]).
The dm:string-value of the processing instruction node
corresponds to the [content]
property.
The dm:parent of the processing instruction node
corresponds to the [parent]
property.
A processing-instruction node has the constructor
dm:processing-instruction-node, which takes an NCName
representing the target and a string representing the content. Like
all other node constructors, the processing node constructor has the
effect of creating a new node with a unique identity, distinct from
all other nodes.
A processing instruction's constituent parts may be obtained by applying
the accessors dm:name (with the function
xf:get-local-name) and
dm:string-value.
The node accessors dm:node-kind and dm:parent
also apply to processing-instruction nodes and may return results other
than the empty sequence.
The accessors dm:base-uri, dm:typed-value,
dm:children, dm:attributes, dm:namespaces,
dm:type and dm:unique-ID
applied to a processing-instruction node always return the empty sequence.
A processing-instruction node is constructed from an Processing
Instruction Information Item by the infoitem-to-processing-instruction-node function:
4.6 Comments
| Comment Node accessors |
possible values |
| dm:node-kind |
"comment" |
| dm:name |
empty sequence |
| dm:base-uri |
empty-sequence |
| dm:string-value |
xs:string |
| dm:typed-value |
empty sequence |
| dm:parent |
sequence of zero or one element or document nodes |
| dm:children |
empty sequence |
| dm:attributes |
empty sequence |
| dm:namespaces |
empty sequence |
| dm:type |
empty sequence |
| dm:unique-ID |
empty sequence |
A comment node corresponds to a comment
information item. There are no comment nodes for comments
that are children of a document type declaration
information item.
A comment node does not have an expanded-QName.
The dm:string-value of the comment node corresponds to
the [content] property.
The dm:parent of the comment node
corresponds to the [parent]
property.
The string "--" (double-hyphen) must not occur within a comment's
string value ([XML Recommendation]).
A comment node's constituent parts may be obtained by applying
the accessor dm:string-value.
The node accessors dm:node-kind and dm:parent
also apply to comment nodes and may return results other than the empty
sequence.
The accessors dm:name, dm:base-uri,
dm:typed-value, dm:children, dm:attributes,
dm:namespaces, dm:type and
dm:unique-ID applied to a comment node always return the empty
sequence.
A comment node is constructed from a Comment Information
Item by the infoitem-to-comment-node function:
4.7 Text
| Text Node accessors |
possible values |
| dm:node-kind |
"text" |
| dm:name |
empty sequence |
| dm:base-uri |
empty-sequence |
| dm:string-value |
xs:string |
| dm:typed-value |
sequence containing one atomic value |
| dm:parent |
sequence of zero or one element or document nodes |
| dm:children |
empty sequence |
| dm:attributes |
empty sequence |
| dm:namespaces |
empty sequence |
| dm:type |
empty sequence |
| dm:unique-ID |
empty sequence |
A text node corresponds to a sequence of one or more consecutive
character information items. As much
character data as possible is grouped into each text node: a text node
never has an immediately following or preceding sibling that is a
text node.
A text node does not have an expanded-QName.
The dm:string-value of a text node is the character data,
which corresponds to the concatenated [character
code] properties of each of the character
information items.
The dm:parent of the text node corresponds to
the [parent] property of
any one of the consecutive character
information items (consecutive characters always have
the same parent).
A text node has the constructor dm:text-node
and takes a string value. Like all other node constructors, the text
constructor has the effect of creating a new node with a unique identity,
distinct from all other nodes.
The dm:string-value of a text node is simply its content.
The dm:typed-value accessor returns the string content
of the text node with unknown simple type.
The node accessors dm:node-kind and dm:parent
also apply to text nodes and may return results other than the empty
sequence.
The accessors dm:name, dm:base-uri,
dm:children, dm:attributes,
dm:namespaces, dm:type and
dm:unique-ID applied to a text node always return the empty
sequence.
The mapping from character information items to text nodes occurs
in the infoitem-to-element-node
function. The infoset-character-code accessor maps a
character information item to the ISO 10646 character code (in the
range 0 to #x10FFFF, though not every value in this range is a legal
XML character code) of the character.
The function infoitem-to-single-character-text-node takes one character
information item and maps it to a text node with a string value of
length one.
define function infoitem-to-single-character-text-node(CharacterItem $ii)
returns TextNode
{
{-- convert character code to string of length 1 --}
return dm:text-node(code2string(infoset-character-code($ii)))
}
Editorial Note: JM: need a definition or description of code2string.
The collapse-text-nodes function synthesizes a single text
node from multiple text nodes. It calls infoitem-to-text-nodes
to collapse recursively one or more consecutive text nodes in its argument
sequence. If insignificant whitespace is ignored, any text node containing
only whitespace is eliminated. All other nodes are returned unchanged.
define function collapse-text-nodes(Node* $nodes) returns Node*
{
let $newnodes:= infoitem-to-text-nodes($nodes)
return
if (ignore-whitespace) then
sequence-map(delete-whitespace-node, $newnodes)
else $newnodes
}
define function infoitem-to-text-nodes(Node* $nodes) returns Node*
{
if (xf:empty($nodes)) then return empty-sequence()
else
let $head:= op:item-at($nodes, 1),
$tail:= xf:sublist($nodes, 2)
return
if (dm:node-kind($head) = "text") then
/* Collapse two consecutive text nodes and apply
infoitem-to-text-nodes recursively */
if (xf:empty($tail)) then $head
else if (dm:node-kind(op:item-at($tail,1)) = "text") then
infoitem-to-text-nodes(
op:concatenate(
dm:text-node(xf:concat(dm:string-value($head),
dm:string-value(op:item-at($tail,1)))),
xf:sublist($tail, 2)
)
)
else op:concatenate($head,
op:concatenate(op:item-at($tail,1),
infoitem-to-text-nodes($tail)))
else op:concatenate($head, infoitem-to-text-nodes($tail))
}
Editorial Note: JM: need a definition or description of delete-whitespace-node.
5 Atomic Values
Editorial Note: MN:
Atomic values were previously called simple or simple-typed values. The
current terminology clarifies that the type of these values is an XML
Schema atomic type.
[Definition: A atomic
value encapsulates an XML Schema atomic type
and a corresponding value of that type.]
An XMLSchema atomic type [XMLSchema Part 2] may be
primitive or derived.
The primitive atomic types are named:
xs:string,
xs:boolean,
xs:decimal,
xs:float,
xs:double,
xs:duration,
xs:dateTime,
xs:time,
xs:date,
xs:gYearMonth,
xs:gYear,
xs:gMonthDay,
xs:gDay,
xs:gMonth,
xs:hexBinary,
xs:base64Binary,
xs:anyURI,
xs:QName,
xs:NOTATION.
A derived atomic type is derived by restriction and has a primitive
base type and a set of constraining facets.
It is noted that the value space of the atomic values is the
union of the value spaces of the nineteen primitive XML Schema types.
This value space clearly includes those atomic values whose type is
primitive, but it also includes those whose type is derived, as
derivation by restriction always limits the value space.
An XMLSchema simple type [XMLSchema Part 2] may be also
primitive or derived with the method of
derivation being restriction, list or
union.
The atomic types are exactly those types where the derivation method
is restriction only and not list or union. Values corresponding
to such types are represented by atomic values.
XML Schema simple types can be derived by list. Values corresponding
to such types are represented by a sequence of atomic values
whose type is the base type.
XML Schema simple types can be derived by union. Values corresponding
to such types lose the union type information and store one of
the individual types.
An atomic value can be constructed from its lexical representation.
The constructor dm:atomic-value takes a string
and a corresponding atomic type.
This constructor corresponds very closely to the atomic
value constructors specified in [XQuery 1.0 and XPath 2.0 Functions and Operators].
Each of those constructors takes a string in the lexical space of the
given primitive type and returns the corresponding atomic value.
For example, the constructor
xf:decimal(xf:string)
constructs an atomic value of type xs:decimal from a string.
Analogous constructors exist for the other XML Schema primitive types.
The accessor dm:type returns an atomic value's type.
The accessor dm:string-value can be used to recover a
lexical representation of the atomic value:
If the atomic value's type is primitive, it returns the
atomic value's canonical lexical representation for that primitive
type as specified in XML Schema Part 2 : Datatypes
[XMLSchema Part 2].
If the atomic value's type is derived, it returns the
atomic value's canonical lexical representation for the base type
(which is a primitive type). See [Issue-0072: Lexical representation of Schema primitive types].
Note: Using the canonical lexical representation for atomic values
as described above may not always be compatible with XPath 1.0.
Note that the data model does not currently represent
key values and key reference values as described in XML Schema Part 1 :
Structures [XMLSchema Part 1]. In a future draft of this
document, keys and key references may be represented in the data
model (see [Issue-0032: Keys and key references not represented]).
6 Sequences
A sequence is an ordered collection of zero or more
items. An item may be a node or an atomic value, i.e.
a sequence may contain nodes, atomic values, or any mixture of
nodes and atomic values (see [Issue-0035: Eliminate heterogeneous sequences]).
When a node is added to a sequence its identity remains the same.
Consequently one node may be contained in more than one sequence
and a sequence may contain duplicate items.
Unlike conventional lists, sequences are "flat", i.e., sequences may not
contain other sequences.
An important characteristic of the data model is that there is no
distinction between an item (i.e., a node or an atomic value) and a
singleton sequence containing that item, i.e., an item is
equivalent to a singleton sequence containing that item and vice
versa.
Note: Sequences replace node-sets from XPath 1.0. In XPath 1.0,
node-sets do not contain duplicates. In generalizing node-sets to
sequences in XPath 2.0, duplicate removal is provided by functions
on node sequences.
A collection of documents is represented in the data model as a
sequence of document nodes (see [Issue-0023: Support for document repositories]).
A sequence has no identity. Equality comparison of sequences is
performed only by comparing the items of the sequences.
The dm:string-value of a sequence containing atomic
values only is obtained by inserting a #x20 (space)
separator between the dm:string-values of the individual
members of the sequence and concatenating the result.
The dm:string-value of a sequence containing any item
other than an atomic value is the concatenation of the
dm:string-values of the individual members of the sequence.
In particular the string value of an empty sequence is an empty string.
The constructor empty-sequence constructs the empty
sequence. The n-ary op:concatenate constructor creates a
new sequence containing the values in its first argument followed by
the concatenated values of its second through final arguments.
In the function signatures below Item refers to a
nodes or an atomic value.
Since an item is equivalent to a singleton sequence containing the
item, op:concatenate may be applied to items.
function empty-sequence() returns Item*
function op:concatenate(Item*, ..., Item*) returns Item*
A sequence has several accessors. They are defined in [XQuery 1.0 and XPath 2.0 Functions and Operators].
In this document the following four accessors are used.
The empty accessor returns a boolean indicating whether or
not the specified sequence is empty.
The item-at accessor returns the item in the sequence that
is located at the specified index.
The sublist accessor returns the contiguous sequence of items
beginning at the specified position and continuing to the end of the
sequence.
The count function returns the number of items in the sequence.
function empty(Item*) returns xs:boolean
function item-at(Item*,xs:decimal) returns Item
function sublist(Item*,xs:decimal) returns Item*
function count(Item*) returns xs:unsignedInt