This document introduces the W3C Multimodal Interaction
Framework, and identifies the major components for multimodal
systems. Each component represents a set of related functions. The
framework identifies the markup languages used to describe
information required by components and for data flowing among
components. The W3C Multimodal Interaction Framework describes
input and output modes widely used today and can be extended to
include additional modes of user input and output as they become
available.
Status of this Document
This section describes the status of this document at the
time of its publication. Other documents may supersede this
document. The latest status of this document series is maintained
at the W3C.
W3C's Multimodal
Interaction Activity is developing specifications for extending
the Web to support multiple modes of interaction. This document
introduces a functional framework for multimodal interaction and is
intended to provide a context for the specifications that comprise
the W3C Multimodal Interaction Framework.
This document has been produced as part of the W3C Multimodal Interaction
Activity,
following the procedures set out for the W3C Process . The
authors of this document are members of the Multimodal Interaction
Working Group (W3C Members
only). This is a Royalty Free Working Group, as described in
W3C's Current
Patent Practice NOTE. Working Group participants are required
to provide patent
disclosures.
Please send comments about this document to the public mailing
list: www-multimodal@w3.org (public
archives). To subscribe, send an email to <www-multimodal-request@w3.
org> with the word subscribe in the subject line
(include the word unsubscribe if you want to
unsubscribe).
A list of current W3C Recommendations and other technical
documents including Working Drafts and Notes can be found at http://www.w3.org/TR/.
1. Introduction
The purpose of the W3C multimodal interaction framework is to
identify and relate markup languages for multimodal interaction
systems. The framework identifies the major components for every
multimodal system. Each component represents a set of related
functions. The framework identifies the markup languages used to
describe information required by components and for data flowing
among components.
The W3C Multimodal Interaction Framework describes input and
output modes widely used today and can be extended to include
additional modes of user input and output as they become
available.
The multimodal interaction framework is not an
architecture. The multimodal interaction framework is a level
of abstraction above an architecture. An architecture indicates how
components are allocated to hardware devices and the communication
system enabling the hardware devices to communicate with each
other. The W3C Multimodal Interaction Framework does not describe
either how components are allocated to hardware devices or how the
communication system enables the hardware devices to communicate.
See Section 6 for descriptions of several example architectures
consistent with the W3C multimodal interaction framework.
This document does not discuss two important multimodal system
architecture variations: distributed multimodal systems and
multi-user multimodal systems. These topics are under discussion by
the working group,
2. Basic Components of the W3C Multimodal Interaction
Framework
Figure 1 illustrates the basic components of the W3C multimodal
interaction framework.
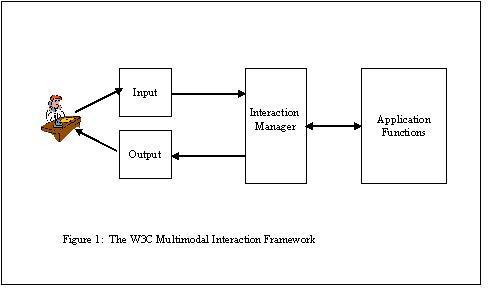
Human user--A user who enters input into the system and
observes and hears information presented by the system. In this
document, we will use the term "user" to refer to a human user.
However, an automated user may replace the human user for testing
purposes. For example, an automated "testing harness" may replace
human users for regression testing to verify that changes to one
component do not affect the user interface negatively.
Input — An interactive multimodal implementation
will use multiple input modes such as audio, speech, handwriting,
and keyboarding, and other input modes. The various modes of input
will be described in Section 3.
Output — An interactive multimodal implementation
will use one or more modes of output, such as speech, text,
graphics, audio files, and animation. The various modes of output
will be described in Section 4.
Interaction manager — The interaction manager
controls the sequence of exchange for information between the human
user and the application functions. It may support a variety of
interaction styles including:
- System-directed dialog — The system prompts the
user by asking a question, and the user responds by answering the
question.
- User-directed dialog — The user directs the
computer to perform an action, and the computer responds by
presenting the results of the action to the user.
- Mixed initiative dialog — This is a mixture of
system-directed and user-directed dialogs in which the human user
and the system take turns "driving" the dialog.
The interaction manager may use (1) inputs form the user, (2)
the session context, (3) external knowledge sources, and (4)
disambiguation, correction, and configuration subdialogs to
determine the user's focus and intent. Based on the user's focus
and intent, the interaction manager also (1) maintains the context
and state of the application, (2) manages the composition of inputs
and synchronization across modes, (3) interfaces with business
logic, and (4) produces output for presentation to the user. One
way to implement a strategy for determining the user's focus and
intent is a interaction script. A interaction script may be
expressed in languages such as Tsuneo Nitta's XISL ,
or languages used for the control of user interfaces such as XHTML+Voice
Profile or SALT . The
interaction manager may make use of context and history to
interpret the inputs. In some architectures, the interaction
manager may be distributed across multiple components, utilizing an
event based mechanism for coordination.
Application functions — Several
application-specific functions provide database access, transaction
processing, and application-specific calculations. The exact format
of the interface to application functions is dependent upon the
application and is outside the scope of this document.
3. Input Components
Figure 2 illustrates the various types of components within the
input component.
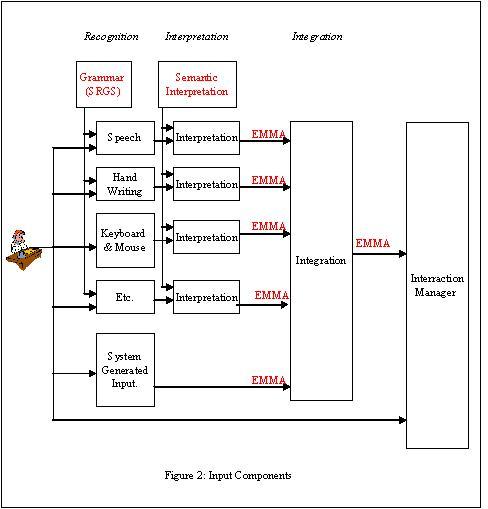
-
Recognition component — Captures natural input
from the user and translates the input into a form useful for later
processing. The recognition component may use a grammar described
by a grammar markup language. Example recognition components
include:
- Speech — Converts spoken speech into text. The
automatic speech recognition component uses an acoustic model, a
language model, and a grammar specified using the W3C Speech
Recognition Grammar or the Stochastic Language Model (N-Gram)
Specification to convert human speech into words specified by the
grammar.
- Handwriting — Converts handwritten symbols and
messages into text. The handwriting recognition component may use a
handwritten gesture model, a language model, and a grammar to
convert handwriting into words specified in a grammar.
- Keyboarding — Converts key presses into textual
characters
- Pointing device — Converts button presses into
x-y positions on a two-dimensional surface
Other input recognition components may include vision, sign
language, DTMF, biometrics, tactile input, speaker verification,
handwritten identification, and other input modes yet to be
invented.
-
Interpretation component — May further process
the results of recognition components. Each interpretation
component identifies the "meaning" or "semantics" intended by the
user. For example, many words that users utter such as "yes,"
"affirmative," "sure," and "I agree," could be represented as
"yes."
-
Integration component — Combines the output from
several interpretation components
Some or all of the functionality of this component could be
implemented as part of the recognition, interpretation, or
interaction components. For example, audio-visual speech
recognition may integrate lip movement recognition and speech
recognition as part of a lip reading component, as part of the
speech recognition component, or integrated within a separate
integration component. As another example, the two input modes
of speaking and pointing are used in
"put that," (point to an object), "there,"
(point to a location)
and may be integrated within a separate integration component or
may be integrated within the interaction manager component.
Either the user or the system may create information that may be
routed directly to the interaction manager without being encoded in
EMMA. For example, audio is recorded for later replay or a sequence
of keystrokes is captured during the creation of a macro.
Information generated by other system components may be
integrated with user input by the integration component. For
example, a GPS system generates the current location of the user,
or a banking application generates an overdraft to prohibit the
user from making additional purchases.
The output for each interpretation component may be expressed
using EMMA, a language for representing the semantics or meaning of
data.
4. Output Components
Figure 3 illustrates the components within the output
component.
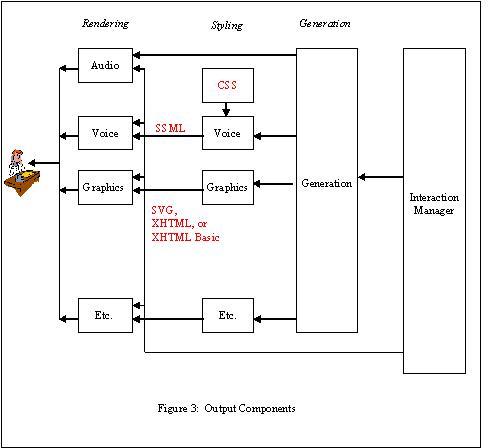
Information from the interaction manager may be routed directly
to the appropriate rendering device without being encoded in an
internal representation. For example, recorded audio is send
directly to the audio system.
-
Styling component — This component adds
information about how the information is "layed out." For example,
the styling component for a display specifies how graphical objects
are positioned on a canvas, while the styling component for audio
may insert pauses and voice inflections into text which will be
rendered by a speech synthesizer. Cascading Style Sheets (CSS)
could be used to modify voice output.
-
Rendering component — The rendering component
converts the information from the styling component into a format
that is easily understood by the user. For example, a graphics
rendering component rectangle displays a vector of points as a
curved line, and a speech synthesis system converts text into
synthesized voice.
Each of the output modes has both a styling and rendering
component.
The voice styling component constructs text strings containing
Speech Synthesis Markup Language tags describing how the words
should be pronounced. This is converted to voice by the voice
rendering component. The voice styling component may also select
prerecorded audio files for replay by the voice rendering
component.
The graphics styling component creates XHTML, XHTML Basic, or SVG markup tags describing how
the graphics should be rendered. The graphics rendering component
converts the output from the graphics styling component into
graphics displayed to the user.
Other pairs of styling and rendering components are possible for
other output modes. SMIL
may be used for coordinated multimedia output.
5. Illustrative Use Case
To illustrate the component markup languages of the W3C
Multimodal Interaction Framework, consider this simple use case.
The human user points to a position on a displayed map and speaks:
"What is the name of this place?" The multimodal interaction system
responds by speaking "Lake Wobegon, Minnesota" and displays the
text "Lake Wobegon, Minnesota" on the map. The following summarizes
the actions of the relevant components of the W3C Multimodal
Interaction Framework:
Human user — Points to a position on a map and
says, "What is the name of this place?"
Speech recognition component — Recognizes the
words "What is the name of this place?"
Pointer recognition component — Recognizes the
x-y coordinates of the position to which the user pointed on a
map.
Speech understanding component — Converts the
words "What is the name of this place?" into an internal
notation.
Pointing understanding component — Converts the
x-y coordinates of the position to which the user pointed into an
internal notation.
Integration component — Integrates the internal
notation for the words "What is the name of this place?" with the
internal notation for the x-y coordinates.
Interaction manager component — Converts the
request to a database request, submits the request to a database
management system which returns the value of "Lake Wobegon,
Minnesota". The interaction manager converts the response into
an internal notation and sends the response to the generation
component.
Generation component — Decides to present the
result as two complementary modes, voice and graphics. The
generation component sends internal notation representing "Lake
Wobegon, Minnesota" to the voice styling component, and sends
internal notation representing the location of Lake Wobegon,
Minnesota on a map to the graphics styling component.
Voice styling component — Converts the internal
notation representing "Lake Wobegon, Minnesota" into SSML.
Graphics styling component — Converts the
internal notation representing the "Lake Wobegon, Minnesota"
location on a map into HTML notation.
Voice rendering component: Converts the SSML notation
into acoustic voice for the user to hear.
Graphics styling component: Converts the HTML notation
into visual graphics for the user to see.
6. Examples of Architectures Consistent with the W3C
Multimodal Interaction Framework.
There are many possible multimodal architectures that are
consistent with the W3C multimodal interaction framework. These
multimodal architectures have the following properties:
Property 1. THE MULTIMODAL ARCHITECTURE CONTAINS A SUBSET OF THE
COMPONENTS OF THE W3C MULTIMODAL INTERACTION FRAMEWORK. A
multimedia architecture contains two or more output modes.
A multimodal architecture contains two or more input
modes.
Property 2. COMPONENTS MAY BE PARTITIONED AND COMBINED. The
functions within a component may be partitioned into several
modules within the architecture, and the functions within two or
more components may be combined into a single module within the
architecture.
Property 3. THE COMPONENTS ARE ALLOCATED TO HARDWARE DEVICES. If
all components are allocated to the same hardware device, the
architecture is said to be centralized architecture . For
example, a PC containing all of the selected components has a
centralized architecture. A client-server architecture
consists of two types of devices, several client devices containing
many of the input and output components, and the server which
contains the remaining components. A distributed
architecture consists of multiple types of devices connected
by a communication system.
Property 4. THE COMMUNICATION SYSTEMS ARE SPECIFIED. Designers
specify the protocols for exchanging messages among hardware
devices.
Property 5. THE DIALOG MODEL IS SPECIFIED. Designers specify how
modules are invoked and terminated, and how they interpret input to
produce output.
The following examples illustrate architectures that conform to
the W3C multimodal interaction framework.
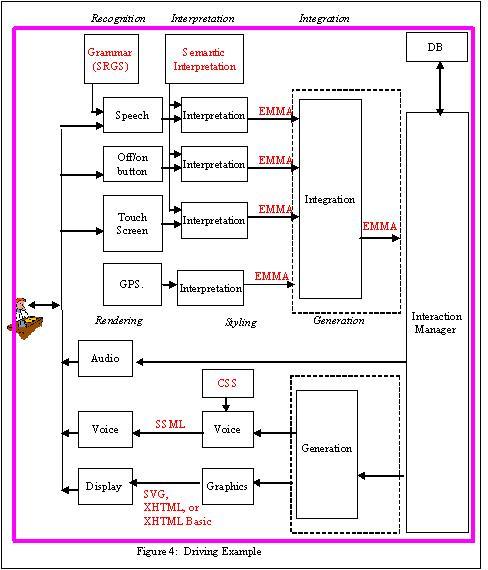
Example 1: Driving Example (Figure 4)
In this example, the user wants to go to a specific address from
his current location and while driving wants to take a detour to a
local restaurant (The user does not know the restaurant address nor
the name). The user initiates service via a button on his steering
wheel and interacts with the system via the touch screen and
speech.
Property 1. The driving architecture contains the components
illustrated in Figure 4: a graphical display, map database, voice
and touch input, speech output, local ASR, TTS Processing and
GPS.
Property 2. No components are partitioned or combined with the
possible exception of the integration and interaction manager
components, and the generation and interaction components. There
are two possible configurations, depending upon whether the
integration component is stand alone or combined with the
interaction manager component:
-
Information entered by the user may be encoded into EMMA
(Extensible MultiModal Annotation Markup Language, formerly known
as the Natural Language Semantic Markup Language) and combined by
an integration component (shown within the dotted rectangle in
Figure 4) which is separate from the interaction manager.
-
Information entered by the user may be recognized and
interpreted and then routed directly to the interaction manager,
which performs its own integration of user information
There are two possible configurations, depending upon whether
the generation component is stand alone or combined with the
interaction manager component:
-
Information from the interaction manager may be routed to the
generation component, where multiple modes of output are generated
and the appropriate synchronization control created.
-
Information may be be routed directly to the styling components
and then on to the rendering components. In this case, the
interaction manager does its own generation and
synchronization.
Property 3. All components are allocated to a single client side
hardware device onboard the car. In Figure 4, the client is
illustrated by a pink box containing all of the components.
Property 4. No communication system is required in this
centralized architecture.
Property 5. Dialog Model: The user wants to go to a specific
address from his current location and while driving wants to take a
detour to a local restaurant . (The user does not know the
restaurant name or address.) The user initiates service via a
button on his steering wheel and interacts with the system via the
touch screen and speech.
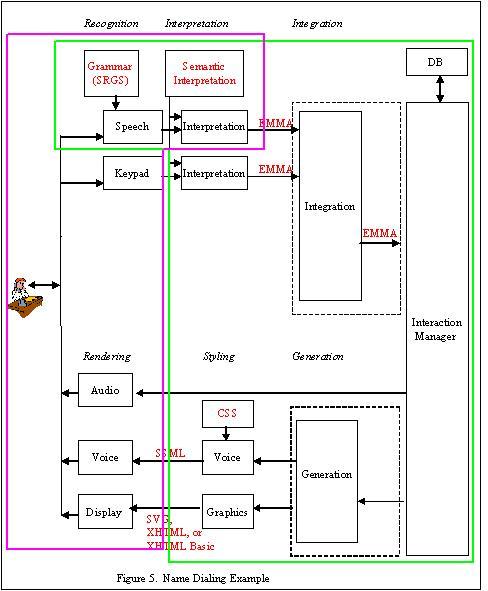
Example 2: Name dialing (Figure 5)
The Name dialing example enables a user to initiate a call by
saying the name of the person to be contacted. Visual and spoken
dialogs are used to narrow the selection, and to allow an exchange
of multimedia messages if the called person is unavailable. Call
handling is determined by a script provided by the called person.
The example supports the use of a combination of local and remote
speech recognition.
Property 1: The architecture contains a subset of the components
of the W3C Multimodal Interface Framework.
Property 2: No components have been partitioned or combined with
the possible exception of the integration component and interaction
component, and the generation component and the interaction
component (as discussed in example 2).
Property 3. The components in pink are allocated to the client
and the components in green are allocated to the server. Note that
the speech recognition and interpretation components are on both
client and server. The local ASR recognizes basic control commands
based upon the ETSI DES/HF-00021 standardized command and control
vocabulary, and the remote ASR recognizes names of individuals the
user wishes to dial. (The vocabulary of names is too large to
maintain on the client, so it is maintained on the server.)
Property 4. Communications system is SIP. SIP
is a session initiation protocol and is a means for initiating
communication sessions involving multiple devices, and for control
signaling during such sessions.
Property 5. Navigational and control commands are recognized by
the ASR on the client. When the user says "call John Smith," the
ASR on the client recognizes the command "call" and transfers the
following information ("John Smith") to the server for recognition.
The application on the server then connects the user with John
Smith's telephone.
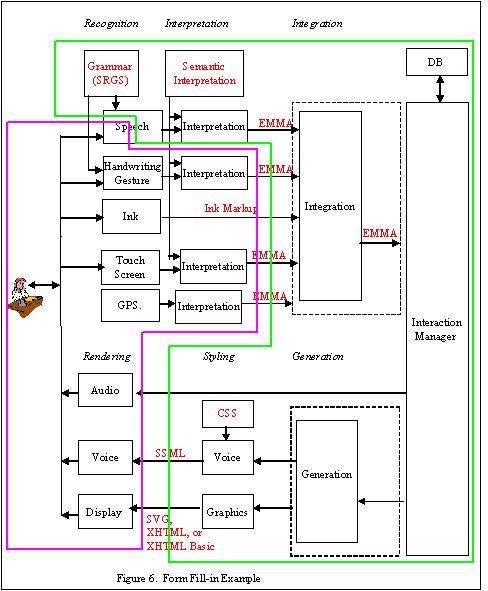
Example 3: Form fill-in (Figure 6)
In the Form fill-in example, the user wants to make a flight
reservation with his mobile device while he is on the way to work.
The user initiates the service by means of making a phone call to
a multimodal service (telephone) or by selecting an application
(portal environment metaphor). The dialogue between the user
and the application is driven by a form-filling paradigm where the
user provides input to fields such as "Travel Origin:", "Travel
Destination:", "Leaving on date", "Returning on date". As the user
selects each field in the application to enter information, the
corresponding input constraints are activated to drive the
recognition and interpretation of the user input.
Property 1: The architecture contains a subset of the components
of the W3C Multimodal Interface Framework, including GPS and
Ink.
Property 2: The speech recognition component has been
partitioned into two components, one which will be placed on the
client and the other on the server. The integration component and
interaction component, and the generation component and the
interaction component may be combined or left separate (as
discussed in example 2).
Property 3. The components in pink are allocated to the client
and the components in green are allocated to the server. Speech
recognition is distributed between the client and the server, with
the feature extraction on the client and the remaining speech
recognition functions performed on the server.
Property 4. Communications system is SIP. SIP
is a session initiation protocol and is a means for initiating
communication sessions involving multiple devices, and for control
signaling during such sessions.
Property 5. Dialog Model: The user wants to make a flight
reservation with his mobile device while he is on the way to work.
The user initiates the service via means of making a phone call to
a multimodal service (telephone metaphor) or by selecting an
application (portal environment metaphor). The dialogue between the
user and the application is driven by a form-filling paradigm where
the user provides input to fields such as "Travel Origin:", "Travel
Destination:", "Leaving on date", "Returning on date". As the user
selects each field in the application to enter information, the
corresponding input constraints are activated to drive the
recognition and interpretation of the user input. The capability of
providing composite multimodal input is also examined, where input
from multiple modalities is combined for the interpretation of the
user's intent.