Abstract
The W3C Voice Browser working group aims to develop
specifications to enable access to the Web using spoken
interaction. This document is part of a set of requirements
studies for voice browsers, and provides an introduction and
glossary of terms.
Status of this document
This document introduces the requirements for voice browsing
as a precursor to starting work on specifications. The
requirements are being released as working drafts but are not
intended to become proposed recommendations.
This specification is a Working Draft of the Voice Browser working
group for review by W3C members and other interested parties. This is
the first public version of this document. It is a draft document and
may be updated, replaced, or obsoleted by other documents at any
time. It is inappropriate to use W3C Working Drafts as reference
material or to cite them as other than "work in progress".
Publication as a Working Draft does not imply endorsement by
the W3C membership, nor of members of the Voice Browser working
groups. This is still a draft document and may be updated,
replaced or obsoleted by other documents at any time. It is
inappropriate to cite W3C Working Drafts as other than "work in
progress."
This document has been produced as part of the W3C Voice Browser Activity,
following the procedures set out for the W3C Process. The
authors of this document are members of the Voice Browser Working Group.
This document is for public review. Comments should be sent to
the public mailing list <www-voice@w3.org> (archive) by
14th January 2000.
A list of current W3C Recommendations and other technical
documents can be found at
http://www.w3.org/TR.
Introduction
The goal of this document is to provide an introduction to the
goals and deliverables of the Voice Browser Working Group. In
addition to new summary and introductory material, this document
contains excerpts from various other documents (all cited) and
edited content from the W3C Voice Browser web site.
Working Group Mission Statement
Far more people today have access to a telephone than have
access to a computer with an Internet connection. In addition,
sales of cell-phones are booming, so that many of us have already
or soon will have a phone within reach wherever we go. In
addition, a new class of portable and device-embedded platforms
is being introduced that will enable mixed voice, graphical and
tactile interactions. Voice browsers offer the promise of
allowing everyone to access Internet-based services from any
device, making it practical to access services any time and any
where, whether at home, on the move, or at work.
It is common for companies to offer services over the phone
via menus traversed using the phone's keypad. Voice Browsers
offer a great fit for the next generation of call-centers, which
will become portals to the company's services and related web
sites, whether accessed via the telephone network or via the
Internet. Users will able to choose whether to respond by a key
press or a spoken command.
Voice browsers allow people to access the Web using speech
synthesis, pre-recorded audio, and speech recognition. This can
be supplemented by keypads and small displays. Voice may also be
offered as an adjunct to conventional desktop browsers with high
resolution graphical displays, providing an accessible
alternative to using the keyboard or screen, for instance in
automobiles where hands/eyes free operation is essential. Voice
interaction can escape the physical limitations on keypads and
displays as mobile devices become ever smaller.
Until recently, speech recognition and spoken language
technologies have had for the most part to be handcrafted into
applications. The Web offers the potential to vastly expand the
opportunities for voice-based applications. The Web page provides
the means to scope the dialog with the user, limiting interaction
to navigating the page, traversing links and filling in forms. In
some cases, this may involve the transformation of Web content
into formats better suited to the needs of voice browsing. In
others, it may prove effective to author content directly for
voice browsers.
Information supplied by authors can increase the robustness of
speech recognition and the quality of speech synthesis. Text to
speech can be combined with pre-recorded audio material in an
analogous manner to the use of images in visual media, drawing
upon experience with radio broadcasting. The lessons learned in
designing for accessibility can be applied to the broader voice
browsing marketplace, making it practical to author content that
is accessible on a wide range of platforms, covering voice,
visual displays and Braille.
W3C held a workshop on "Voice Browsers" in
October 1998. The workshop brought together people involved in
developing voice browsers for accessing Web based services. The
workshop concluded that the time was ripe for W3C to bring
together interested parties to collaborate on the development of
joint specifications for voice browsers, particularly since these
efforts concern subsetting or extending some of the core W3C
technologies, for example HTML and CSS.
This Working Group has the mission:
- To prepare and review documents related to Voice Browsers,
for instance, relating to dialog management, extensions to
existing Web standards, speech grammar formats and authoring
guidelines.
- To serve as a coordination body with existing industry groups
working on related specifications.
- To serve as a pool of experts on Voice Browsers, some of
which will participate in the other W3C working groups relevant
to Voice Browsers.
Commenting on draft documents
An associated public mailing list (www-voice@w3.org) is
availabale for public review of proposals prepared by the Working
Group. A public web page is provided (http://www.w3.org/Voice)
describing the status of the activity, with a link to an archive
of the public e-mail list.
Please e-mail comments and suggestions to the public mailing
list, <www-voice@w3.org> (archive) by
14th January 2000. All comments and suggestions will be reviewed
by selected members of the working group, who may recommend
changes to the documents. We regret that we may not able to
respond individually to each and every comment. Revised documents
approved by the full membership of the working group will be
posted at this web site by the end of January.
What is a "Voice Browser" ?
"A device which interprets a (voice) markup
language and is capable of generating voice output and/or
interpreting voice input, and possibly other input/output
modalities."
The definition of a voice browser, above, is a broad one. The
fact that the system deals with speech is obvious given the first
word of the name, but what makes a software system that interacts
with the user via speech a "browser"? The answer lies mostly in
the context of the discussion, and the venue of this research
(the W3C), and that, loosely stated, the information that the
system uses (for either domain data or dialog flow) is dynamic
and comes somewhere from the Internet. >From an end-user's
perspective, the impetus is to provide a service similar to what
graphical browsers of HTML and related technologies do today, but
on devices that are not equipped with full-browsers or even the
screens to support them. This situation is only exacerbated by
the fact that much of today's content depends on the ability to
run scripting languages and 3rd-party plug-ins to work
correctly.
Much of the effort of the Working Group concentrates on using
the telephone as the first voice browsing device. This is not to
say that it is the preferred embodiment for a voice browser, only
that the number of access devices is huge, and because it is at
the opposite end of the graphical-browser continuum, which high
lights the requirements that make a speech interface viable. By
the first meeting it was clear that this scope-limiting was also
needed in order to make progress, given that there are
significant challenges in designing a system that uses or
integrates with existing content, or that automatically scales to
the features of various access devices.
If a voice browser is to converse with the user, then a
description, either explicit or derived and implicit, must exist
for the the underlying system to "render" into a dialog.
Ultimately, it will be up to solution-providers to take an
inventory of the existing content (if any), development tools,
data-access requirements, deployment platforms, and application
goals such as cost, security, richness and robustness, before
they can decide what technology to use. More likely than not, for
the time-being, multiple content types will be required to
deliver the most natural experience on each type of browsing
device -- this is both a technical limitation, and driven by the
user's who expect the latest-and-greatest attributes of each
modality to be featured in their applications.
Voice Browser Documents
"A prioritized list of requirements for spoken
dialog interaction which any proposed markup language (or
extension thereof) should address."
The Dialog Requirements document describes properties of a
voice browser dialog, including a discussion of modalities (input
and output mechanisms combined with various dialog interaction
capabilities), functionality (system behavior) and the format of
a dialog language. A definition of the latter is not specified,
but a list of criteria is given that any proposed language should
adhere to.
An important requirement of any proposed dialog language is
ease-of-creation. Dialogs can be created with a tool as simple as
a text-editor, with more specific tools, such as an (XML)
structure editor, to tools that are special-purposed to deal with
the semantics of the language at hand.
Examples of existing and proposed (non-sanctioned) dialog
languages can be found in the Further Reading
section, below.
"...defines a speech recognition grammar
specification language that will be generally useful across a
variety of speech platforms used in the context of a dialog and
synthesis markup environment."
When the system or application needs to describe to the
speech-recognizer what to listen for, one way it can do so is via
a format that is both human and machine-readable. This document
describes the requirements for two forms of character-set grammar
— as a matter of preference or implementation, one is more
easily read by (most) humans, while the other is geared toward
machine generation.
"To assist in clarifying the scope of charters of
each of the several subgroups of the W3C Voice Browser Working
Group, a representative or model architecture for a typical voice
browser application has been developed. This architecture
illustrates one possible arrangement of the main components of a
typical system, and should not be construed as a
recommendation."
Some of this document is reproduced in System Architecture,
below.
"...establishes a prioritized list of requirements
for natural language processing in a voice browser
environment."
The data that a voice browser uses to create a dialog can vary
from a rigid set of instructions and state transitions, whether
declaratively and/or procedurally stated, to a dialog that is
created dynamically from information and constraints about the
dialog itself.
The NLP requirements document describes the requirements of a
system that takes the latter approach, using an example paradigm
of a set of tasks operating on a frame-based model. Slots in the
frame that are optionally filled guide the dialog and provide
contextual information used for task-selection. The document
describes what forms of input the NLP component is likely to
consume, and what output it is expected to generate.
"...establishes a prioritized list of requirements
for speech synthesis markup which any proposed markup language
should address."
A text-to-speech system, which is usually a stand-alone module
that does not actually "understand the meaning" of what is
spoken, must rely on hints to produce an utterance that is
natural and easy to understand, and moreover, evokes the desired
meaning in the listener. In addition to these prosodic elements,
the document also describes issues such as multi-lingual
capability, pronunciation issues for words not in the lexicon,
time-syncronization, and textual items that require special
preprocessing before they can be spoken properly.
Other Requirements documents
Requirement documents are being constructed for reusable
components and multimodal dialogs. They will be posted here when
ready for review
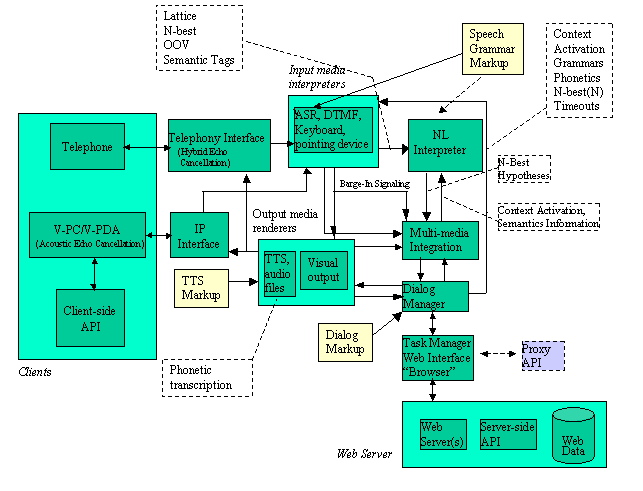
System Architecture
"The architecture diagram was created as an aid to
how we structure our work into subgroups. The diagram will help
us to pinpoint areas currently outside the scope of existing
groups."
Although individual instances of voice browser systems are apt
to vary considerably, it is reasonable to try and point out
architectural commonalties as an aid to discussion, design and
implementation. Not all segments of this diagram need be present
in any one system, and systems which implement various subsets of
this functionality may be organized differently. Systems built
entirely third-party components, with architecture imposed, may
result in unused or redundant functional blocks.
Two types of clients are illustrated: telephony and data
networking. The fundamental telephony client is, of course, the
telephone, either wireline or wireless. The handset telephone
requires PSTN (Public Switched Telephone Network) interface,
which can be either tip/ring, T1, or higher level, and may
include hybrid echo cancellation to remove line echoes for ASR
barge-in over audio output. A speakerphone will also require an
acoustic echo canceller to remove room echoes. The data network
interface will require only acoustic echo cancellation if used
with an open microphone since there is no line echo on data
networks. The IP interface is shown for illustration only. Other
data transport mechanisms can be used as well.
The model architecture is shown below. Solid (green) boxes
indicate system components, peripheral solid (yellow) boxes
indicate points of usage for markup language, and dotted
peripheral boxes indicate information flows.
Document Requirements Terminology
The various draft requirement documents use the following
nomenclature to describe the priorities that describe if
particular sections of the requirements draft document should be
present in the final, official version of the document. Note
that these modifiers do not pertain to the desired features in
any implementation, but only to the document itself.
| Must address |
The first official specification must define the feature.
|
| Should address |
The first official specification should define the feature if
feasible but may defer it until a future release.
|
| Nice to address |
The first official specification may define the feature if
time permits, however, its priority is low.
|
| Future revision |
It is not intended that the first official specification
include the feature.
|
Glossary of Terms
There is some variance in the use of terminology in the speech
synthesis community. The following definitions establish a common
understanding for this document.
| Prosody |
Features of speech such as pitch, pitch range, speaking rate
and volume.
|
| Speech Synthesis |
The process of automatic generation of speech output from data
input which may include plain text, formatted
text or binary objects.
|
| Text-To-Speech |
The process of automatic generation of speech output from text
or annotated text input.
|
Although defining a dialog is highly problematic, some basic
definition must be provided to establish a common basis of
understanding and avoid confusion. The following terminology is
based upon an event-driven model of dialog interaction.
| Voice Markup Language |
a language in which voice dialog behaviour is specified. The
language may include reference to style and scripting elements
which can also determine dialog behaviour.
|
| Voice Browser |
a software device which interprets a voice markup language and
generates a dialog with voice output and possibly other output
modalities and/or voice input and possibly other modalities.
|
| Dialog |
a model of interactive behaviour underlying the interpretation
of the markup language. The model consists of states, variables,
events, event handlers, inputs and outputs.
|
| State |
the basic interactional unit defined in the markup language;
for example, an < input > element in HTML. A state can
specify variables, event handlers, outputs and inputs. A state
may describe output content to be presented to the user, input
which the user can enter, event handlers describing, for example,
which variables to bind and which state to transition to when an
event occur.
|
| Events |
generated when a state is executed by the voice browser; for
example, when outputs or inputs in a state are rendered or
interpreted. Events are typed and may include information; for
example, an input event generated when an utterance is recognized
may include the string recognized, an interpretation, confidence
score, and so on.
|
| Event Handlers |
are specified in the voice markup language and describe how
events generated by the voice browser are to be handled.
Interpretation of events may bind variables, or map the current
state into another state (possibly itself).
|
| Output |
content specified in an element of the markup language for
presentation to the user. The content is rendered by the voice
browser; for example, audio files or text rendered by a TTS.
Output can also contain parameters for the output device; for
example, volume of audio file playback, language for TTS, etc.
Events are generated when, for example, the audio file has been
played.
|
| Input |
content (and its interpretation) specified in an element of
the markup language which can be given as input by a user; for
example, a grammar for DTMF and speech input. Events are
generated by the voice browser when, for example, the user has
spoken an utterance and variables may be bound to information
contained in the event. Input can also specify parameters for the
input device; for example, timeout parameters, etc.
|
Terminology from Grammar Representation Requirements
| BNF |
Backus-Naur Format.
|
| Context |
A context is a subset of the full domain. A
context can possess state.
|
| CFG |
Context-Free Grammar.
|
| Domain |
Domain is the scope of task semantics over which the
associated language and associated attribute-values are
meaningful.
|
| Grammar |
Grammar is the representation of constraints defining
the set of allowable sentences in the language.
|
| Language |
Language is the collection or set of sentences
associated with a particular domain. Language may
refer to natural or program language.
|
| N-Best |
Top N hypotheses; from speech recognition, in this case, but
could be from natural language processing.
|
| N-Gram |
Probabilistic grammar using conditional probabilities
P(wn | wn-1 wn-2 ...).
|
| OOV |
Out Of Vocabulary (words).
|
| State |
State is the current condition or value of variables
and attributes of a system.
|
| URI |
Universal Resource Identifier.
|
| URL |
Universal Resource Locator.
|
| XML |
Extensible Markup Language.
|
Terms from Language Processing Requirements
| Natural language interpreter |
A device which produces a representation of the meaning of a
natural language expression.
|
| Natural language expression |
An unformatted spoken or written utterance in a human language
such as English, French, Japanese, etc.
|
| Anaphoric expression |
A pronoun or other linguistic form which depends on the
(linguistic or non-linguistic) context for its
interpretation.
|
| Frame/task model |
A representation of a task which includes slots or components
of the task.
|
| Slot/attribute/variable/key |
A component of a frame or task model. For example, "lines" and
"date" in a teleconference scheduling application.
|
| Filler/value |
The value assigned to a slot.
|
The following resources are related to the efforts of the
Voice Browser working group.
- Aural
CSS
- The aural rendering of a document, already commonly used by
the blind and print-impaired communities, combines speech
synthesis and "auditory icons." Often such aural presentation
occurs by converting the document to plain text and feeding this
to a screen reader -- software or hardware that simply reads all
the characters on the screen. This results in less effective
presentation than would be the case if the document structure
were retained. Style sheet properties for aural presentation may
be used together with visual properties (mixed media) or as an
aural alternative to visual presentation.
The European Telecommunications
Standards Institute (ETSI)- The European Telecommunications Standards Institute (ETSI)
ETSI is a non-profit organization whose mission is "to determine
and produce the telecommunications standards that will be used
for decades to come". ETSI's work is complementary to W3C's. The
ETSI STQ Aurora DSR Working Group standardizes algorithms for
Distributed Speech Recognition (DSR). The idea is to preprocess
speech signals before transmission to a server connected to a
speech recognition engine. Navigate to http://www.etsi.org/stq/
for more details.
Java Speech Grammar Format- The Java™ Speech Grammar Format is used for defining
context free grammars for speech recognition. JSGF adopts the
style and conventions of the Java programming language in
addition to use of traditional grammar notations.
NOTE-voice- This note describes features needed for effective interaction
with Web browsers that are based upon voice input and output.
Some extensions are proposed to HTML 4.0 and CSS2 to support
voice browsing, and some work is proposed in the area of speech
recognition and synthesis to make voice browsers more
effective.
SABLE- SABLE is a markup language for controlling text to speech
engines. It has evolved out of work on combining three existing
text to speech languages: SSML, STML and JSML.
SpeechML- (IBM's server precludes a simple URL for this, but you can
reach the SpeechML site by following the link for Speech
Recognition in the left frame)
SpeechML plays a similar role to VoxML, defining a markup
language written in XML for IVR systems. SpeechML features close
integration with Java.
TalkML- This is an experimental markup language from HP Labs, written
in XML, and aimed at describing spoken dialogs in terms of
prompts, speech grammars and production rules for acting on
responses. It is being used to explore ideas for object-oriented
dialog structures, and for next generation aural style
sheets.
Voice Browsers
and Style Sheets- Presentation by Dave Raggett on May 13th 1999 as part of the
Style stack of Developer's Day in
WWW8. The presentation makes suggestions for extensions to ACSS.
VoiceXML site- The VoiceXML Forum formed by AT&, IBM, Lucent and
Motorola to pool their experience. The Forum has published an
early version of the VoiceXML specification. This builds on
earlier work on PML, VoxML and SpeechML.
VoxML Site, VoxML Reference Spec
(pdf file - 141K)- A markup language written in XML for interactive voice
response systems using speech recognition for simple commands.
VoxML represents dialogs as a transition network.
David Ladd writes: "The language spec for VoxML. Just to
clarify, the VXML forum is working on merging VoxML and similar
languages from AT&T and Lucent. Soon, the forum will have a
draft proposal ready for comment. In the interim, I'll offer
VoxML as an example of a "pure" dialog language that makes no
special attempt to be HTML-compatible or
graphically-renderable."