Copyright © 1997,1998 W3C (MIT, INRIA, Keio ), All Rights Reserved. W3C liability, trademark, document use and software licensing rules apply.
This document is a complete revision of the working draft dated 1998-02-16. In addition to a major rewrite and reorganization, it incorporates some technical changes to the names of certain attributes ('about' and 'resource' and adds a mechanism for making statements about the members of a collection ('aboutEach').
This draft specification is a work in progress representing the current consensus of the W3C RDF Model and Syntax Working Group. This is a W3C Working Draft for review by W3C members and other interested parties. Publication as a working draft does not imply endorsement by the W3C membership. While the design has stabilized quite a bit since the previous version and we do not anticipate substantial changes, we still caution that further changes are possible and therefore we recommend that only experimental software or software that can be easily field-upgraded be implemented to this specification at this time. The RDF Model and Syntax Working Group will not allow early implementation to constrain their ability to make changes to this specification prior to final release. This is a draft document and may be updated, replaced or obsoleted by other documents at any time. It is inappropriate to cite W3C Working Drafts as other than "work in progress".
Note: As working drafts are subject to frequent change, you are advised to reference the above address for "Latest version" rather than the addresses for specific working draft versions themselves. The latest version address is the better one to bookmark as it should point to newer revisions as they are published.
Comments on this specification may be sent to www-rdf-comments@w3.org. The archive of public comments is available at http://www.w3.org/Archives/Public/www-rdf-comments.
The World Wide Web suffers from substantial growing pains. It was built for human consumption, and although everything on it is machine-readable, this data is not machine-understandable. It is very hard to automate anything on the web, and because of the volume of information the web contains, it is not possible to manage it manually. The solution proposed here is to use metadata to describe the data contained on the web. Metadata is "data about data" (for example, a library catalog is metadata, since it describes publications) or specifically in the context of this specification "data describing web resources". The distinction between "data" and "metadata" is not an absolute one; it is a distinction created primarily by a particular application, and many times the same resource will be interpreted in both ways simultaneously.
Resource Description Framework (RDF) is a foundation for processing metadata; it provides interoperability between applications that exchange machine-understandable information on the Web. RDF emphasizes facilities to enable automated processing of Web resources. RDF can be used in a variety of application areas; for example: in resource discovery to provide better search engine capabilities, in cataloging for describing the content and content relationships available at a particular Web site, page, or digital library, by intelligent software agents to facilitate knowledge sharing and exchange, in content rating, in describing collections of pages that represent a single logical "document", for describing intellectual property rights of Web pages, and for expressing the privacy preferences of a user as well as the privacy policies of a web site. RDF with digital signatures will be key to building the "Web of Trust" for electronic commerce, collaboration, and other applications.
This document introduces a model for representing RDF metadata as well as a syntax for encoding and transporting this metadata in a manner that maximizes the interoperability of independently developed web servers and clients. The syntax presented here uses the Extensible Markup Language [XML]: one of the goals of RDF is to make it possible to specify semantics for data based on XML in a standardized, interoperable manner. RDF and XML are complementary: RDF is a model of metadata, and only superficially addresses many of the encoding issues that transportation and file storage require (such as internationalization, character sets, etc.). For these issues, RDF relies on the support of XML. It is also important to understand that XML is only one possible syntax for RDF, and that alternate ways to represent the same RDF data model may emerge.
The broad goal of RDF is to define a mechanism for describing resources that makes no assumptions about a particular application domain, nor defines (a priori) the semantics of any application domain. The definition of the mechanism should be domain neutral, yet the mechanism should be suitable for describing information about any domain.
This specification will be followed by other documents which will complete the framework. Most importantly, to facilitate the definition of metadata, RDF will have a class system, not unlike many object-oriented programming and modeling systems. A collection of classes (typically authored for a specific purpose or domain) is called a schema. Classes are organized in a hierarchy, and offer extensibility through subclass refinement. This way, in order to create a schema slightly different from an existing one, it is not necessary to "reinvent the wheel", but one can just provide incremental modifications to the base schema. Through the sharability of schemas RDF will support the reusability of metadata definitions. Due to RDF's incremental extensibility, agents processing metadata will be able to trace the origins of schemata they are unfamiliar with back to known schemata, and perform meaningful actions on metadata they weren't originally designed to process. The sharability and extensibility of RDF also allows metadata authors to use multiple inheritance to "mix" definitions, to provide multiple views to their data, leveraging work done by others. In addition, it is possible to create RDF instance data based on multiple schemata from multiple sources (i.e., "interleaving" different types of metadata).
As a result of many communities coming together and agreeing on basic principles of metadata representation and transport, RDF has drawn influence from several different sources. The main influences have come from the web standardization community itself in the form of HTML metadata and PICS, the library community, the structured document community in the form of SGML and more importantly XML, and also the knowledge representation community. There are also other areas of technology which contributed to the design; these include object-oriented programming and modeling languages, as well as databases.
The foundation of RDF is a model for representing named properties and property values. The RDF model draws on well-established principles from various data representation communities. RDF properties may be thought of as attributes of resources and in this sense correspond to traditional attribute-value pairs. RDF properties also represent relationships between resources and an RDF model can therefore resemble an entity-relationship diagram. In object-oriented design terminology, resources correspond to objects and properties correspond to instance variables.
The RDF data model is a syntax-neutral way of representing RDF expressions. The data model representation is used to evaluate equivalence in meaning. Two RDF expressions are equivalent if and only if their data model representations are the same. This definition of equivalence permits some syntactic variation in expression without altering the meaning.
The basic data model consists of three object types:
| Resources | All Web objects being described by RDF expressions are termed resources. A resource may be an entire web page; an HTML document, for example. A resource may be a part of a web page; e.g. a specific HTML or XML element within the document source. A resource may also be a whole collection of pages; e.g. an entire web site. Resources are always named by URI. Anything can have a URI; the extensibility of URIs allows the introduction of identifiers for any entity imaginable. |
| Property Types | The names of the properties (or attributes, or relations) in an RDF expression are termed property types. The property type defines the specific meaning of the property, the permitted values for the property, the types of objects that can be described with the property, and the relationship(s) between properties of one type and properties of other types. Property types are also resources. This document does not address how characteristics of property types are expressed; for such information, refer to the RDF Schema document). |
| Statements | A specific resource together with a named property plus the value of that property for that resource is an RDF statement. Property values can be other resources or they can be atomic; that is, simple strings or other primitive datatypes defined by XML. |
Resources are referred to by a URI. For the purposes of this document, property types will be referred to by a simple name. A common case of a property value being a resource occurs when the property type defines a relationship between two resources.
Consider as a simple example the sentence:
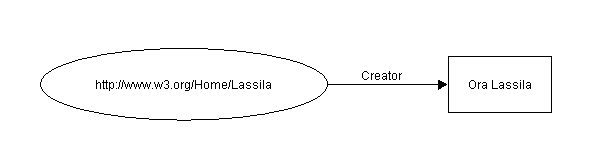
Ora Lassila is the creator of the resource http://www.w3.org/Home/Lassila
This sentence has the following objects:
Resource http://www.w3.org/Home/Lassila Property type Creator Value "Ora Lassila"
In this document we will diagram an RDF statement pictorially using directed labelled graphs (also called "nodes and arcs diagrams"). In these diagrams, the nodes (drawn as ovals) represent resources and arcs represent named properties. Nodes that represent atomic string values will be drawn as rectangles. The sentence above would thus be diagrammed as:
Figure 1: Simple node and arc
Note: The direction of the arrow is important. The arc always starts at the resource and points to the value. The simple diagram above may also be read "http://www.w3.org/Home/Lassila has creator Ora Lassila", or in general "<resource> HAS <property type> <value>".
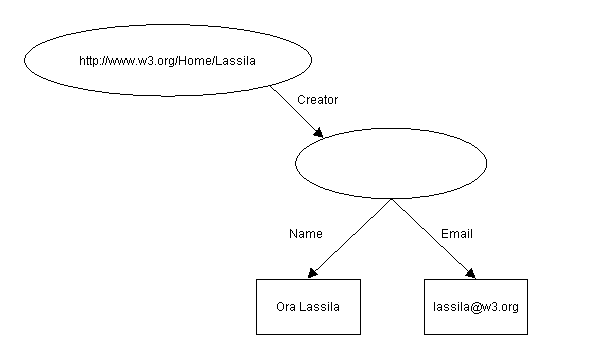
Now, consider the case that we want to say something more about the characteristics of the creator of this resource. In prose, such a sentence would be:
The individual whose name is Ora Lassila, email <lassila@w3.org>, is the creator of http://www.w3.org/Home/Lassila
The intention of this sentence is to make the value of the Creator property a structured entity. In RDF such an entity is represented as another resource. The sentence above does not give a name to that resource; it is anonymous, so in the diagram below we represent it with an empty oval:
Figure 2: Property with structured value
Note: corresponding to the reading in the previous note, this diagram could be read "http://www.w3.org/Home/Lassila has creator something and something has name Ora Lassila and email lassila@w3.org".
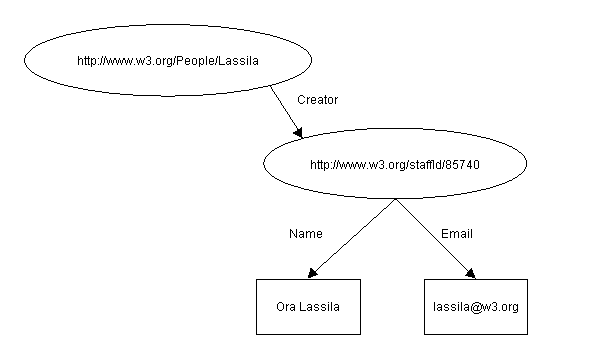
The structured entity of the previous example can also be assigned a unique identifier. The choice of identifier is made by the application database designer. To continue the example, imagine that an employee id is used as the unique identifier for a "person" resource. The URI defined by the organization that serves as the unique key for each employee might then be something like http://www.w3.org/staffId/85740. Now we can write the two sentences:
The individual referred to by employee id 85740 is named Ora Lassila and has the email address lassila@w3.org. The resource http://www.w3.org/Home/Lassila was created by this individual.
The RDF model for these sentences is:
Figure 3: Structured value with identifier
Note that this diagram is identical to the previous one with the addition of the URI for the previously anonymous resource. From the point of view of a second application querying this model, there is no distinction between the statements made in a single sentence and the statements made in separate sentences. Some applications will need to be able to make such a distinction however, and RDF supports this; see Section 4, Statements about Statements, for further details.
The RDF data model provides an abstract, conceptual framework for defining and using metadata. A concrete syntax is also needed for the purposes of creating and exchanging this metadata. This specification of RDF uses the Extensible Markup Language [XML] encoding as its interchange syntax. RDF also requires the XML namespace facility to precisely associate each property type with the schema that defines the property type.
The syntax descriptions in this document use the Extended Backus-Naur Form notation as defined in Section 6, Notation, of [XML] to describe the essential RDF syntax elements. The EBNF here is condensed for human readability; in particular, the italicized "rdf" is used to represent a variable namespace name rather than the more precise BNF notation "'<' NSname ':...'". The requirement that the property and type names in end-tags exactly match the names in the corresponding start-tags is implied by the XML rules. All syntactic flexibilities of XML are also implicitly included; e.g. whitespace rules, quoting using either single quote (') or double quote ("), character escaping, case sensitivity, and language tagging.
This specification defines two XML syntaxes for encoding an RDF data model instance. The serialization syntax expresses the full capabilities of the data model in a very regular fashion. The abbreviated syntax includes additional constructs that provide a more compact form to represent a subset of the data model. RDF interpreters are expected to implement both the full serialization syntax and the abbreviated syntax. Consequently, metadata authors are free to mix the two.
A single RDF statement seldom appears in isolation; most commonly several properties of a resource will be given together. The RDF XML syntax has been designed to accomodate this easily by grouping multiple statements for the same resource into a Description element. The Description element names, in an about attribute, the resource to which each of the property statements apply. If the resource does not yet exist (i.e. does not yet have a URI) then a Description element can create the identifer for the resource using an ID attribute.
Basic RDF serialization syntax takes the form:
[1] RDF ::= ['<rdf:RDF>'] description* ['</rdf:RDF>']
[2] description ::= '<rdf:Description' idAboutAttr? '>' property*
'</rdf:Description>'
[3] idAboutAttr ::= idAttr | aboutAttr
[4] aboutAttr ::= 'about="' URI '"'
[5] idAttr ::= 'ID="' IDsymbol '"'
[6] property ::= '<' propName '>' value '</' propName '>'
| '<' propName resourceAttr '/>'
[7] propName ::= Qname
[8] value ::= description | string
[9] resourceAttr ::= 'resource="' URI '"'
[10] Qname ::= [ NSname ':' ] name
[11] URI ::= (see RFC1738, RFC1808)
[12] IDsymbol ::= (any legal XML name symbol)
[13] name ::= (any legal XML name symbol)
[14] NSname ::= (any legal XML namespace prefix)
[15] string ::= (any XML text, with "<", ">", and "&" escaped)
The RDF element is a simple wrapper that marks the boundaries in an XML document between which the content is explicitly intended to be mappable into an RDF data model instance. The RDF element is optional if the content can be known to be RDF from the application context.
Description contains the remaining elements that cause the creation of properties in the model instance. The Description element may be thought of (for purposes of the basic RDF syntax) as smiply a place to hold the identification of the resource being described. Typically there will be more than one property listed for the resource; Description provides a way to give the resource name just once for several properties.
When the about attribute is specified with Description, the properties in the Description refer to the resource whose URI is given in the about. A Description element without an about attribute creates a new resource. Typically such a resource will be a surrogate, or proxy, for some other real resource that does not have a recognizable URI. This "in-line" resource has a URI formed using the value of the ID attribute of the Description element, if present.
If another Description or property value needs to refer to the in-line resource it will use the value of the ID of that resource in its own about attribute. The ID attribute signals the creation of a new resource and the about attribute refers to an existing resource; therefore either ID or about may be specified on Description but not both together in the same element. The values for each ID attribute must not appear more than once within a document; that is, ID is of type XML AttType ID.
A single Description may contain more than one property element of the same property type. Each such property element adds one arc to the graph. The interpretation of this graph is defined by the schema designer.
Within a property element, the URI used in a resource attribute identifies some other resource that is the value of this property. Strings must be well-formed XML; the usual XML content quoting and escaping mechanisms may be used if the string contains character sequences (e.g. "<" and "&") that violate the well-formedness rules or that otherwise might look like markup.
Property names must always be associated with a schema. This can be done by qualifying the element names with a namespace prefix to unambiguously connect the property definition with the corresponding RDF schema. XML namespaces [NAMESPACES] may define other association mechanisms.
The example sentence from Section 2.1.1
Ora Lassila is the creator of the resource http://www.w3.org/Home/Lassila
is represented in RDF/XML as:
<rdf:RDF>
<rdf:Description about="http://www.w3.org/Home/Lassila">
<s:Creator>Ora Lassila</s:Creator>
</rdf:Description>
</rdf:RDF>
Here the namespace prefix 's' refers to a specific namespace prefix chosen by the creator of this RDF expression and defined in an XML namespace processing instruction such as:
<?xml:namespace ns="http://description.org/schema" prefix="s"?>
The URI in the ns attribute of the namespace declaration is a globally unique name for the particular schema this metadata creator is using to define her use of the Creator property type. Other schemas may also define a property type named Creator and the two property types will be distinguished via their schema URIs.
While the serialization syntax shows the structure of an RDF model most clearly, often it is desirable to use a more compact XML form. The RDF abbreviated syntax accomplishes this. As a further benefit, the abbreviated syntax allows certain well-structured XML DTDs to be directly interpreted as an RDF model.
Three forms of abbreviation are defined for the basic serialization syntax. The first is useable for property types that are not repeated within a Description and where the values of those properties are strings. In this case, the properties may be written as XML attributes of the Description element. The previous example then becomes:
<rdf:RDF>
<rdf:Description about="http://www.w3.org/Home/Lassila"
s:Creator="Ora Lassila" />
</rdf:RDF>
Note that since the Description element has no other content once the Creator property is written in XML attribute form, the XML empty element syntax is employed to elide the Description end-tag.
Here is another example of the use of this same abbreviation form:
<rdf:RDF>
<rdf:Description about="http://www.w3.org">
<s:Publisher>World Wide Web Consortium</s:Publisher>
<s:Title>W3C Home Page</s:Title>
<s:Date>1998-07-20T14:36</s:Date>
</rdf:Description>
</rdf:RDF>
is equivalent for RDF purposes to
<rdf:RDF>
<rdf:Description about="http://www.w3.org"
s:Publisher="World Wide Web Consortium"
s:Title="W3C Home Page"
s:Date="1998-07-20T14:36"/>
</rdf:RDF>
Note that while these two RDF expressions are equivalent, they may be treated differently by other processing engines. In particular, if these two expressions were embedded into an HTML document then the default behavior of a non-RDF-aware browser would be to display the values of the properties in the first case while in the second case there should be no text displayed (or at most a whitespace character).
The second RDF abbreviation form works on nested Description elements. This abbreviation form can be employed for specific property statements when the property value is another resource and the values of any properties given in-line for this second resource are strings. In this case, a similar transformation of XML element names into XML attributes is used; the properties of the resource in the nested Description may be written as XML attributes of the property element in which that Description was contained.
The second example sentence from Section 2.1.1
The individual referred to by employee id 85740 is named Ora Lassila and has the email address lassila@w3.org. The resource http://www.w3.org/Home/Lassila was created by this individual.
is written in RDF/XML using explicit serialization form as
<rdf:RDF>
<rdf:Description about="http://www.w3.org/Home/Lassila">
<s:Creator resource="http://www.w3.org/staffId/85740"/>
</rdf:Description>
<rdf:Description about="http://www.w3.org/staffId/85740">
<v:Name>Ora Lassila</v:Name>
<v:Email>lassila@w3.org</v:Email>
</rdf:Description>
</rdf:RDF>
This form makes it clear to a reader that two separate resources are being described but it is less clear that the second resource is used within the first description. This same expression could be written in the following way to make this relationship more obvious to the human reader. Note that to the machine, there is no difference:
<rdf:RDF>
<rdf:Description about="http://www.w3.org/Home/Lassila">
<s:Creator>
<rdf:Description about="http://www.w3.org/staffId/85740">
<v:Name>Ora Lassila</v:Name>
<v:Email>lassila@w3.org</v:Email>
</rdf:Description>
</s:Creator>
</rdf:Description>
</rdf:RDF>
Using the second basic abbreviation syntax, the inner Description element and its contained property statements can be written as attributes of the Creator element:
<rdf:RDF>
<rdf:Description about="http://www.w3.org/Home/Lassila">
<s:Creator resource="http://www.w3.org/staffId/85740"
v:Name="Ora Lassila"
v:Email="lassila@w3.org" />
</rdf:Description>
</rdf:RDF>
When using this abbreviation form the about attribute of the nested Description element becomes a resource attribute on the property element, as the resource named by the URI is in both cases the value of the Creator property. It is entirely a matter of writer's preference which of the three forms above are used in the RDF source. They all produce the same internal RDF models.
Note: The observant reader who has studied the remainder of this document will see that there are some additional relationships created by a Description element to preserve the specific syntactic grouping of statements. Consequently the three forms above are slightly different in ways not important to the discussion in this section. These differences become important only when making higher-order statements as described in Section 4.
The third basic abbreviation applies to the common case of a Description element containing an instanceOf property (see Section 4.1 for the meaning of instanceOf). In this case, the object type defined in the schema corresponding to the value of the instanceOf property can be used directly as an element name. For example, using the previous RDF fragment if we wanted to add the fact that the resource http://www.w3.org/staffId/85740 represents an instance of a Person, we would write this in full serialization syntax as:
<rdf:RDF>
<rdf:Description about="http://www.w3.org/Home/Lassila">
<s:Creator>
<rdf:Description about="http://www.w3.org/staffId/85740">
<rdf:instanceOf resource="s:Person"/>
<v:Name>Ora Lassila</v:Name>
<v:Email>lassila@w3.org</v:Email>
</rdf:Description>
</s:Creator>
</rdf:Description>
</rdf:RDF>
and using this third abbreviated form as:
<rdf:RDF>
<rdf:Description about="http://www.w3.org/Home/Lassila">
<s:Creator>
<s:Person about="http://www.w3.org/staffId/85740">
<v:Name>Ora Lassila</v:Name>
<v:Email>lassila@w3.org</v:Email>
</rdf:Description>
</s:Creator>
</rdf:Description>
</rdf:RDF>
The EBNF for the basic abbreviated syntax replaces productions [2] and [6] of the grammar for the basic serialization syntax in the following manner:
[2a] description ::= '<rdf:Description' idAboutAttr? propAttr* '/>'
| '<rdf:Description' idAboutAttr? propAttr* '>'
property* '</rdf:Description>'
| typedNode
[6a] property ::= '<' propName '>' value '</' propName '>'
| '<' propName resourceAttr? propAttr* '/>'
[16] propAttr ::= propName '="' string '"'
(with embedded quotes escaped)
[17] typedNode ::= '<' typeName idAboutAttr? propAttr* '/>'
| '<' typeName idAboutAttr? propAttr* '>'
property* '</' typeName '>'
When we write a sentence in natural language we use words that are meant to convey a certain meaning. That meaning is crucial to understanding the statements and, in the case of applications of RDF, is crucial to establishing that the correct processing occurs as intended. It is crucial that both the writer and the reader of a statement understand the same meaning for the terms used, such as Creator, approvedBy, Copyright, etc. or confusion will result. In a medium of global scale such as the World Wide Web it is not sufficient to rely on shared cultural understanding of concepts such as "creatorship"; it pays to be as precise as possible.
Meaning in RDF is expressed through reference to a schema. You can think of a schema as a kind of dictionary. A schema defines the terms that will be used in RDF statements and gives specific meanings to them. A variety of schema forms can be used with RDF, including as a specific form defined in a separate document [RDFSchema] that has some specific characteristics to help with automating tasks using RDF.
A schema is the place where definitions and restrictions of usage for property types are documented. In order to avoid confusion between independent -- and possibly conflicting -- definitions of the same term, RDF uses the XML namespace facility. Namespaces are simply a way to tie a specific use of a word in context to the dictionary (schema) where the intended definition is to be found. In RDF, each property type used in a statement must be identified with exactly one namespace, or schema. However, a Description element may contain property statements from many schemas. Examples of RDF Descriptions that use more than one schema appear in Section 7.
Frequently it is necessary to refer to a collection of resources; for example, to say that a work was created by more than one person, or to list the students in a course, or the software modules in a package. RDF containers are used to hold such lists of resources or atomic values.
RDF defines three types of container objects:
| Bag | An unordered list of resources or atomic values. Bags are used to declare that a property has multiple values and that there is no significance to the order in which the values are given. Bag might be used to give a list of part numbers where the order of processing the parts does not matter. Duplicate values are permitted. |
| Sequence | An ordered list of resources or atomic values. Sequence is used to declare that a property has multiple values and that the order of the values is significant. Sequence might be used, for example, to preseve an alphabetical ordering of values. Duplicate values are permitted. |
| Alternative | A list of resources or values that represent alternatives for the (single) value of a property. Alternative might be used to provide alternative language translations for the title of a work, or to provide a list of Internet mirror sites at which a resource might be found. An application using a property whose value is an Alternative collection is aware that it can choose any one of the items in the list as appropriate. |
Note: The definitions of Bag and Sequence explicitly permit duplicate values. RDF does not define a core concept of Set, which would be a Bag with no duplicates because the RDF core does not mandate an enforcement mechanism in the event of violations of such constraints. Future work layered on the RDF core may define such facilities.
To create a collection of resources, RDF uses an additional resource that represents the specific collection (an instance of a collection, in object modeling terminology). This resource must be declared to be an instance of one of the container object types defined above. The instanceOf property type, defined below, is used to make this declaration. The membership relation between this container resource and the resources that belong in the collection is defined by a set of property types defined expressly for this purpose. These membership property types are named simply "1", "2", "3", etc.
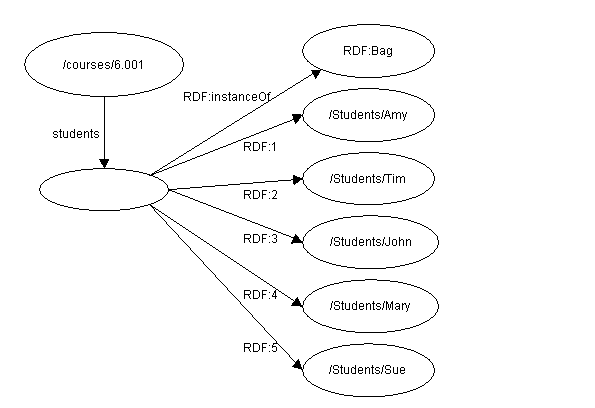
For example, to represent the sentence
The students in course 6.001 are Amy, Tim, John, Mary, and Sue
the RDF model is
Figure 4: Simple Bag container
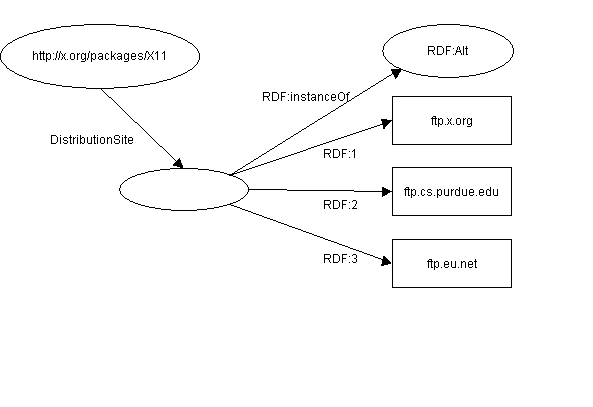
The sentence
The source code for X11 may be found at ftp.x.org, ftp.cs.purdue.edu, or ftp.eu.net
is modeled in RDF as
Figure 5: Simple Alternative container
Alternative containers are frequently used in conjunction with language tagging. A work whose title has been translated into several languages might have its Title property pointing to an Alternative container holding each of the language variants.
RDF container syntax takes the form:
[18] container ::= sequence | bag | alternative [19] sequence ::= '<rdf:Seq' idAttr? '>' member* '</rdf:Seq>' [20] bag ::= '<rdf:Bag' idAttr? '>' member* '</rdf:Bag>' [21] alternative ::= '<rdf:Alt' idAttr? '>' member+ '</rdf:Alt>' [22] member ::= referencedItem | inlineItem [23] referencedItem ::= '<rdf:li' resourceAttr '/>' [24] inlineItem ::= '<rdf:li>' value '</rdf:li>'
Containers may be used everywhere a Description is permitted:
[1a] RDF ::= '<rdf:RDF>' obj* '</rdf:RDF>' [8a] value ::= obj | string [25] obj ::= description | container
Note that RDF/XML uses 'li' as a convenience element to avoid having to explicitly number each member. The li element assigns the property names '1', '2', and so on as necessary.
An Alt container is required to have at least one member. This member, whose property type will be "1", is the default or preferred value.
Note: The RDF Schema specification [RDFSCHEMA] also defines a mechanism to declare additional subtypes of these container types, in which case production [18] is extended to include the names of those declared subtypes.
The model for the sentence
The students in course 6.001 are Amy, Tim, John, Mary, and Sue
is written in RDF/XML as
<rdf:RDF>
<rdf:Description about="http://mycollege.edu/courses/6.001">
<s:students>
<rdf:Bag>
<rdf:li resource="http://mycollege.edu/students/Amy"/>
<rdf:li resource="http://mycollege.edu/students/Tim"/>
<rdf:li resource="http://mycollege.edu/students/John"/>
<rdf:li resource="http://mycollege.edu/students/Mary"/>
<rdf:li resource="http://mycollege.edu/students/Sue"/>
</rdf:Bag>
</s:students>
</rdf:Description>
</rdf:RDF>
In this case, since the value of the students property is expressed as a Bag there is no significance to the order given here for the URIs of each student.
The model for the sentence
The source code for X11 may be found at ftp.x.org, ftp.cs.purdue.edu, or ftp.eu.net
is written in RDF/XML as
<rdf:RDF>
<rdf:Description about="http://x.org/packages/X11">
<s:DistributionSite>
<rdf:Alt>
<rdf:li>ftp.x.org</rdf:li>
<rdf:li>ftp.cs.purdue.edu</rdf:li>
<rdf:li>ftp.eu.net</rdf:li>
</rdf:Alt>
</s:DistributionSite>
</rdf:Description>
</rdf:RDF>
Here, any one of the items listed in the container value for DistributionSite is an acceptable value without regard to the other items.
Container structures give rise to an issue about statements: when a statement is made referring to a collection, what is the "thing" a statement is made of? In other words, what is the object the statement is referring to. This object (in the XML syntax indicated by the about attribute) is in RDF called the referent.
The following example:
<rdf:Bag ID="pages">
<rdf:li resource="http://foo.org/foo.html" />
<rdf:li resource="http://bar.org/bar.html" />
</rdf:Bag>
<rdf:Description about="#pages">
<s:Creator>Ora Lassila</s:Creator>
</rdf:Description>
expresses that "Ora Lassila" is the creator of the bag "pages". It does not, however, say anything about the individual pages, the members of the bag. The referent of the Description is the container (the bag), not its members. One would sometimes like to make a statement about each of the contained objects individually, instead of the container itself. In order to express that "Ora Lassila" is the creator of each of the pages, a different kind of referent is called for, one that distributes over the members of the container. This referent in RDF is expressed using the aboutEach attribute:
[3a] idAboutAttr ::= idAttr | aboutAttr | aboutEachAttr [26] aboutEachAttr ::= 'aboutEach="' URI '"'
As an example, if we wrote
<rdf:Description aboutEach="#pages">
<s:Creator>Ora Lassila</s:Creator>
</rdf:Description>
we would get the desired meaning. We will call the new referent type a distributive referent. Distributive referents allow us to "share structure" in an RDF Description. For example, when writing several Descriptions which all have a number of common properties (property types + values), the common parts can be shared among all the Descriptions, possibly resulting in space savings and more maintainable metadata. The value of an aboutEach attribute must be a container. Using a distributive referent on a container is the same as making all the statements about each of the members separately.
No explicit graph representation of distributive referents is defined. Instead, in terms of the statements made, distributive referents are expanded into the individual statements about the individual container members (internally, implementations are free to retain information about the distributive referents - in order to save space, for example - as long as any querying functions work as if all of the statements were made individually). Thus, with respect to the resources "foo" and "bar", the above example is equivalent to
<rdf:Description about="http://foo.org/foo.html">
<s:Creator>Ora Lassila</s:Creator>
</rdf:Description>
<rdf:Description about="http://bar.org/bar.html">
<s:Creator>Ora Lassila</s:Creator>
</rdf:Description>
A resource may have multiple properties with the same property type. This is not the same as having a single property whose value is a container containing multiple members. The choice of which to use in any particular circumstance is in part made by the person who designs the schema and in part made by the person who writes the specific RDF statements.
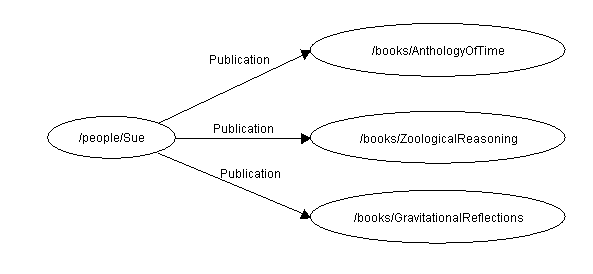
Consider as an example the relationship between a writer and her publications. We might have the sentence
Sue has written "Anthology of Time", "Zoological Reasoning", "Gravitational Reflections".
That is, there are three resources each of which was written independently by the same writer.
Figure 6: Repeated property
In this example there is no stated relationship between the publications other than that they were written by the same person.
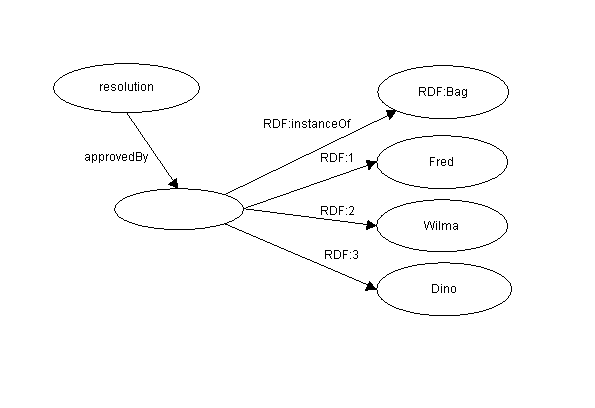
On the other hand, the sentence
The committee of Fred, Wilma, and Dino approved the resolution.
says that the three committee members as a whole voted in a certain manner; it does not necessarily state that each committee member voted in favor of the article. It would be incorrect to model this sentence as three separate approvedBy properties, one for each committee member, as this would state the vote of each individual member. Rather, it is better to model this as a single approvedBy property whose value is a Bag containing the committee members' identities:
Figure 7: Using Bag to indicate a collective opinion
In addition to making statements about web resources, RDF can be used for making statements about other RDF statements; we will refer to these as higher-order statements. In order to make a statement about another statement, we actually have to build a model of the original statement; this model is a new resource to which we can attach additional properties.
Statements are made about resources. A model of a statement is the resource we need in order to be able to make new statements (higher-order statements) about the modeled statement.
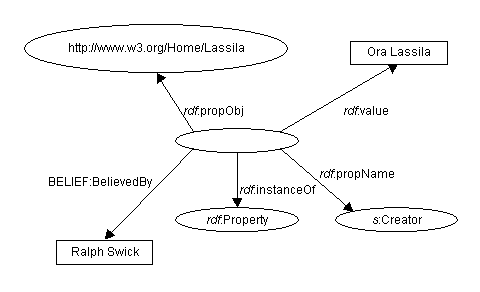
For example, let us consider the sentence
Ora Lassila is the creator of the resource http://www.w3.org/Home/Lassila
RDF would regard this sentence as a fact. If, instead, we write the sentence
Ralph Swick believes that Ora Lassila is the creator of the resource http://www.w3.org/Home/Lassila
we have said nothing about the resource http://www.w3.org/Home/Lassila; instead, we have expressed a fact about a belief Ralph has. In order to express this belief to RDF, we have to model the original statement as a resource with four properties. This process is formally called reification in the Knowledge Representation community. A model of a statement is called a reified statement.
To model statements RDF defines the following property types:
A new resource with the above four properties represents the original statement and can be used as the value of other properties and additional properties can be attached to it. Depending on how we would like to model this example, we could attach another property to the reified statement (say, "BelievedBy") with an appropriate value (in this case, "Ralph Swick"). Using base-level RDF/XML syntax, this could be written as
<rdf:RDF>
<rdf:Description>
<rdf:propObj resource="http://www.w3.org/Home/Lassila" />
<rdf:propName resource="http://description.org/schema#Creator" />
<rdf:value>Ora Lassila</rdf:value>
<rdf:instanceOf resource="http://www.w3.org/TR/WD-rdf-syntax#Property" />
<BELIEF:BelievedBy>Ralph Swick</BELIEF:BelievedBy>
</rdf:Description>
</rdf:RDF>
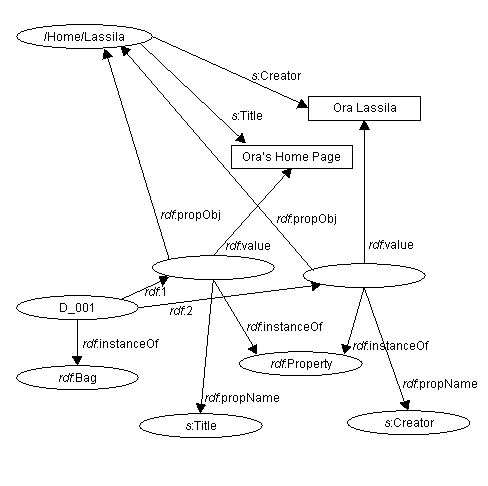
Figure 8 represents this in graph form. Syntactically this is rather verbose; later in this document we present a shorthand for making statements about statements.
Figure 8: Representation of a reified property
Reification is also needed to represent explicitly in the model the statement grouping implied by Description elements. The RDF graph model does not need a special construct for Descriptions; since Descriptions really are collections of statements, a Bag container is used to indicate that a set of statements came from the same (syntactic) Description. This bag is created by reifying each statement of a Description, and making the reified statements members of the bag. As an example, the RDF fragment
<rdf:RDF>
<rdf:Description about="http://www.w3.org/Home/Lassila" bagID="D_001">
<s:Creator>Ora Lassila</s:Creator>
<s:Title>Ora's Home Page</s:Title>
</rdf:Description>
</rdf:RDF>
would result in the graph shown in Figure 9.
Figure 9: Using Bag to represent statement grouping
Note the new attribute bagID. This attribute specifies the resource id of the container resource:
[2b] description ::= '<rdf:Description' idAboutAttr? bagIDAttr? propAttr* '/>'
| '<rdf:Description' idAboutAttr? bagIDAttr? propAttr* '>'
property* '</rdf:Description>'
[27] bagIDAttr ::= 'bagID="' IDsymbol '"'
BagID and ID should not be confused. ID specifies the identification of an in-line resource whose properties are further detailed in the Description. BagID specifies the identification of the container resource whose members are the reified statements about that in-line resource. A Description may have both an ID attribute and a bagID attribute.
Since attaching a bagID to a Description results in including in the model a bag of the reified properties of the Description, we can use this as a syntactic shorthand when making statements about statements. For example, if we wanted to say that Ralph believes that Ora is the creator of http://www.w3.org/Home/Lassila and that he also believes that the title of that resource is "Ora's Home Page" we can simply write
<RDF:Description aboutEach="#D_001">
<BELIEF:BelievedBy>Ralph Swick</BelievedBy>
</RDF:Description>
Note that this shorthand example includes an additional fact in the model not represented by the example in Figure 8. This shorthand usage expresses both a fact about Ralph's belief and two facts about Ora's home page.
The reader is referred to Section 5 ("Formal Model") of this specification for a more formal treatment of higher-order statements and reification.
This specification shows three representations of the data model; as 3-tuples (triples), as a graph, and in XML. These representations have equivalent meaning. The mapping between the representations used in this specification is not intended to constrain in any way the internal representation used by implementations.
The RDF data model is defined formally as follows:
|
In this data model, both the resources being described and the values describing them are represented as nodes in a directed labeled graph. The arcs connecting pairs of nodes are labeled by property types (the named arcs correspond to names of property types).
The triple {p, r, v} corresponds to a resource r having a property p with a value v, or
[r] --p--> v
This can be read either
v is the value of p for r
or (left to right)
r has a property p with a value v
or even
the p of r is v
For example, the statement
Ora Lassila is the creator of the resource http://www.w3.org/Home/Lassila
would be represented graphically as follows:
[http://www.w3.org/Home/Lassila] --creator--> "Ora Lassila"
and the corresponding triple (member of Triples) would be
{creator, [http://www.w3.org/Home/Lassila], "Ora Lassila"}
The notation [URI] denotes the node representing the resource identified by URI and quotation marks denote an atomic value (a string).
Using the triples, we can explain how statements are reified (as introduced in Section 4). Given a statement
{creator, [http://www.w3.org/Home/Lassila], "Ora Lassila"}
we can express the reification of this as a new node X as follows:
{instanceOf, [X], [RDF:Property]}
{propName, [X], [creator]}
{propObj, [X], [http://www.w3.org/Home/Lassila]}
{value, [X], "Ora Lassila"}
From the standpoint of an RDF processor, facts (i.e. statements) are triples (which are members of Triples). Therefore, the original statement remains a fact despite it being reified since the triple representing the original statement remains in Triples. We have merely added four more triples.
The property type instanceOf is defined to provide primitive typing. The formal definition of instanceOf is:
|
Furthermore, the formal specification of reification is:
|
As described in Section 3, it is frequently necessary to create a collection of nodes; for example to state that a property has an ordered sequence of values. RDF defines three kinds of collections: ordered lists of nodes, called Sequences, unordered lists of nodes, called Bags, and lists that represent alternatives for the (single) value of a property, called Alternatives.
Formally, these three collection types are defined by:
|
To create a collection of nodes c, create a triple {RDF:instanceOf, c, t} where t is one of the three node types RDF:Seq, RDF:Bag, or RDF:Alt. The remaining triples {RDF:1, c, r1}, ..., {RDF:n, c, rn}, ... point to each of the members rn of the collection. There may be at most one arc from a single collection node labeled with each element of Ord and the elements of Ord must be used in sequence starting with RDF:1. For nodes that are instances of the RDF:Alt collection type, there must be exactly one member whose arc label is RDF:1 and that is the default value for the Alternatives node (that is, there must always be at least one alternative).
The complete BNF for RDF is reproduced here from previous sections. The precise interpretation of the grammar in terms of the formal model is also given. This section is intended for implementors who are building tools that read and interpret RDF/XML syntax.
[6.1] RDF ::= '<rdf:RDF>' obj* '</rdf:RDF>'
[6.2] obj ::= description | container
[6.3] description ::= '<rdf:Description' idAboutAttr? bagIdAttr? propAttr* '/>'
| '<rdf:Description' idAboutAttr? bagIdAttr? propAttr* '>'
property* '</rdf:Description>'
| typedNode
[6.4] container ::= sequence | bag | alternative
[6.5] idAboutAttr ::= idAttr | aboutAttr | aboutEachAttr
[6.6] idAttr ::= 'ID="' IDsymbol '"'
[6.7] aboutAttr ::= 'about="' URI '"'
[6.8] aboutEachAttr ::= 'aboutEach="' URI '"'
[6.9] bagIdAttr ::= 'bagID="' IDsymbol '"'
[6.10] propAttr ::= propName '="' string '"'
(with embedded quotes escaped)
[6.11] property ::= '<' propName idAttr? '>' value '</' propName '>'
| '<' propName idRefAttr? bagIdAttr? propAttr* '/>'
[6.12] typedNode ::= '<' typeName idAboutAttr? bagIdAttr? propAttr* '/>'
| '<' typeName idAboutAttr? bagIdAttr? propAttr* '>'
property* '</' typeName '>'
[6.13] propName ::= Qname
[6.14] typeName ::= Qname
[6.15] idRefAttr ::= idAttr | resourceAttr
[6.16] value ::= obj | string
[6.17] resourceAttr ::= 'resource="' URI '"'
[6.18] Qname ::= [ NSname ':' ] name
[6.19] URI ::= (see RFC1738, RFC1808)
[6.20] IDsymbol ::= (any legal XML name symbol)
[6.21] name ::= (any legal XML name symbol)
[6.22] NSname ::= (any legal XML namespace prefix)
[6.23] string ::= (any XML text, with "<", ">", and "&" escaped)
[6.24] sequence ::= '<rdf:Seq' idAttr? '>' member* '</rdf:Seq>'
[6.25] bag ::= '<rdf:Bag' idAttr? '>' member* '</rdf:Bag>'
[6.26] alternative ::= '<rdf:Alt' idAttr? '>' member+ '</rdf:Alt>'
[6.27] member ::= referencedItem | inlineItem
[6.28] referencedItem ::= '<rdf:li' resourceAttr '/>'
[6.29] inlineItem ::= '<rdf:li>' value </rdf:li>'
Each XML element E contained by a Description element results in the creation of a triple {p,r,v} where:
The Description element itself creates an instance of a Bag node. The members of this Bag are the nodes corresponding to the reification of each of the properties in the Description. If the bagID attribute is specified its value is the identifier of this Bag, else the Bag is anonymous.
When about is specified with Description, the properties in the Description refer to the resource named in the about. A Description element without an about attribute creates an in-line resource. This in-line resource has a URI formed using the value of the ID attribute of the Description element, if present. When another Description or property value refers to the in-line resource it will use the value of the ID in an about attribute. When the other Description refers to the bag of nodes corresponding to the reified properties it will use the value of bagID in an about attribute. Either ID or about may be specified on Description but not both together in the same element. The values for each ID and bagID attribute must not appear more than once within a document nor may the same value be used in an ID and a bagID; that is, these two attributes have XML AttType ID.
When aboutEach is specified with Description, the properties in the Description refer to each of the members of the container named by aboutEach. The triples {p,r,v} created by each contained XML element E as described above are duplicated for each r that is a member of the container.
Seq, Bag, and Alt create an instance of a Sequence, Bag, or Alternative container node type respectively. A triple {RDF:instanceOf,c,t} is created where c is the container resource and t is one of RDF:Seq, RDF:Bag, or RDF:Alt. The members of the collection are denoted by li. Each li corresponds to one member of the collection and results in the creation of a triple {p,c,v} where:
The URI identifies the target resource; i.e. the resource to which the Description applies or the resource that is included in the container. The bagID attribute on a Description element and the ID attribute on a container element permit that Description or container to be referred to by other Descriptions. The ID on a container element is the name that is used in a resource attribute on a property element to make the collection the value of that property.
Within property, the URI used in a resource attribute identifies the resource that is the value of this property. The value of the ID attribute, if specified, is the identifier for the node that represents the reification of the property. If an expression is specified as a property value the value is the node given by the about attribute of the Description or the (possibly implied) ID of the Description or container. Strings must be well-formed XML; the usual XML content quoting and escaping mechanisms may be used if the string contains character sequences (e.g. "<" and "&") that violate the well-formedness rules or that otherwise might look like markup.
It is recommended that property names always be qualified with a namespace prefix to unambiguously connect the property definition with the corresponding RDF schema.
As defined by XML, the character repertoire of an RDF string is ISO/IEC 10646 [ISO10646]. An actual RDF string, whether in an XML document or in some other representation of the RDF data model, may be stored using a direct encoding of ISO/IEC 10646 or an encoding which can be mapped to ISO/IEC 10646. Language tagging is part of the string value; it is applied to sequences of characters within an RDF string and does not have an explicit manifestation in the data model.
Two RDF strings are deemed to be the same if their ISO/IEC 10646 representations match. Each RDF application must specify which one of the following definitions of 'match' it uses:
The xml:lang attribute may be used as defined by [XML] to associate a language with the property value. There is no specific data model representation for xml:lang (i.e. it adds no triples to the data model); the language of a string value is considered by RDF to be a part of the atomic value. An application may ignore language tagging of a string. All RDF applications must specify whether or not language tagging in string values is significant; that is, whether or not language is considered when performing string matching or other processing.
Each property type and value expressed in XML attribute form by productions [6.3] and [6.10] is equivalent to the same property type and value expressed as XML content of the corresponding Description according to production [6.11]. Specifically; each XML attribute A specified with a Description start tag other than the attributes ID, about, aboutEach or bagID results in the creation of a triple {p,r,v} where:
The typedNode form (production [6.12]) may be used to create or declare instances of nodes of specific types and to further describe those nodes. A Description expressed in typedNode form by production [6.12] is equivalent to the same Description expressed by production [6.3] with the same ID, bagID, and about attributes plus an additional instanceOf property in the Description where the value of the instanceOf property is the fully expanded URI corresponding to the typeName of the typedNode. Specifically, when a typedNode is given, a triple {RDF:instanceOf,n,t} is created where n is the resource whose URI is given by the value of the about attribute or whose identifier is given by the value of the ID attribute of the typedNode element, t is the expansion of the namespace-qualified tag name, and the remainder of the the typedNode attributes and content is handled as for Description elements above.
Property types and values expressed in XML attribute form by productions [6.10] and [6.11] are equivalent to the same property types and values expressed as XML content of a single Description element D where the referent of D is the value of the property named by the XML element according to productions [6.16], [6.2], and [6.3]. Specifically; each property start tag containing attribute specifications other than ID, resource, or bagID results in the creation of the triples {p,r1,r2}, {pa1,r2,va1}, ..., {pan,r2,van} where
The value of the bagID attribute, if specified, is the identifier for the Bag corresponding to the Description D; else the Bag is anonymous.
<<to be completed; substantially copied from the 19980216 draft.>>
This specification is the work of the W3C RDF Model and Syntax Working Group. This Working Group has been most ably chaired by Eric Miller of the Online Computer Library Center and Bob Schloss of IBM. We thank Eric and Bob for their tireless efforts in keeping the group on track and we especially thank OCLC and IBM for supporting them and us in this endeavor.
The members of the Working Group who helped design this specfication, debate proposals, provide words, proofread numerous drafts and ultimately reach consensus are: Renato Iannella (DSTC), Tsuyoshi SAKATA (DVL), Murray Maloney (Grif), Bob Schloss (IBM), Naohiko URAMOTO (IBM), Bill Roberts (KnowledgeCite), Ron Daniel (Datafusion), Arthur van Hoff (Marimba), Andrew Layman (Microsoft), Chris McConnell (Microsoft), Jean Paoli (Microsoft), R.V. Guha (Netscape), Ora Lassila (Nokia), Ralph LeVan (OCLC), Eric Miller (OCLC), Charles Wicksteed (Reuters), Misha Wolf (Reuters), Wei Song (SISU), Lauren Wood (SoftQuad), Tim Bray (Textuality), Paul Resnick (University of Michigan), Tim Berners-Lee (W3C), Dan Connolly (W3C), Jim Miller (W3C, emeritus), Ralph Swick (W3C).
This document is the collective work of all of the above. The editors are indebted to each of them for helping to create this document.
Descriptions may be associated with the resource they describe in one of four ways:
All resources will not support all association methods; in particular, many kinds of resources will not support embedding and only certain kinds of resources may be wrapped.
A human- or machine-understandable description of an RDF schema may be accessed through content negotiation by dereferencing the schema URI. If the schema is machine-understandable it may be possible for an application to learn some of the semantics of the property types named in the schema on demand. The logic and syntax of RDF schemas are described in a separate document, [RDFSchema].
The recommended technique for embedding RDF expressions in an HTML document is simply to insert the RDF in-line. This will make the resulting document non-conformant to HTML specifications up to and including HTML 4.0 but the RDF Working Group hopes that the HTML specification will evolve to support this. Two practical issues will arise when this technique is employed with respect to browsers conforming to specifications of HTML up to and including HTML 4.0. Alternatives are available to authors in these cases; see [XMLinHTML]. It is up to the author to choose the appropriate alternative in each circumstance.
In the event that none of the alternatives above provides the capabilities desired by the author, the RDF expressions may be left external to the HTML document and linked with an HTML <LINK> element. The recommended relation type for this purpose is REL="meta"; e.g.
<LINK rel="meta" href="mydocMetadata">
To Be Specified. We expect to specify a simple extension to HTTP that allows a client to request that RDF metadata be included in a header along with the document. We will deal here only with the HTTP protocol; we hope that other protocols will be similarly extended.
The RDF serialization and abbreviated syntaxes use XML as their encoding. XML elements and attributes are case sensitive, so RDF property names are therefore also case sensitive. This specification does not require any specific format for property names other than that they be legal XML names. For its own identifiers, RDF has adopted the convention that all property names use "InterCap style"; that is, the first letter of the property name and the remainder of the word is lowercase; e.g. value. When the property name is a composition of words or fragments of words, the words are concatenated with the first letter of each word (other than the first word) capitalized and no additional punctutation; e.g. propName.
RDF uses the proposed XML namespace mechanism to implement globally unique identifiers for all properties. In addition, the namespace URI serves as the URI of the corresponding RDF schema. An RDF processor can expect to use the schema URI to access the schema content. This specification places no further requirements on the content that might be supplied at that URI, nor how (if at all) the URI might be modified to obtain alternate forms or a fragment of the schema.
Revision History:
20-July-1998: More typos fixed. Third public draft
15-July-1998: Incorporate comments and fix typos. Initial letter of property names changed to lowercase
15-June-1998: Major rewrite and reorganization
16-February-1998: Editorial cleanup, prep for second public distribution
6-February-1998: Editorial cleanup, add and revise some examples
11-January-1998: Renaming and collapsing of several elements
14-November-1997: Further refinement, especially regarding assertions
3-November-1997: Edits in preparation for second public distribution
2-October-1997: First public draft
1-October-1997: Edits in preparation for first public distribution
1-August-1997: First draft to Working Group
Last updated: 1998-07-21T17:05:48Z