The Web Rule Language WRL is a rule-based ontology language
for the Semantic Web. The language is located in the Semantic Web
stack next to the Description Logic based Ontology language OWL.
WRL defines three
variants, namely Core, Flight and Full. The Core variant marks
the common fragment between WRL and OWL. WRL-Flight is a Datalog-based
rule language. WRL-Full is a full-fledged rule language with
function symbols and negation under the Well-Founded
Semantics.
This document is a part of the WRL Submission.
By publishing this document, W3C acknowledges that DERI Innsbruck at the
Leopold-Franzens-Universität Innsbruck, Austria, DERI Galway at the
National University of Ireland, Galway, Ireland, The Open University,
Software AG, Forschungszentrum Informatik (FZI), BT, and National Research Council Canada have made a formal
submission to W3C for discussion. Publication of this document by W3C
indicates no endorsement of its content by W3C, nor that W3C has, is, or
will be allocating any resources to the issues addressed by it. This
document is not the product of a chartered W3C group, but is published as
potential input to the W3C
Process. Publication of acknowledged Member Submissions at the W3C site
is one of the benefits of W3C Membership.
Please consult the requirements associated with Member Submissions of section
3.3 of the W3C Patent Policy. Please consult the complete list of acknowledged W3C Member
Submissions.
1. Introduction
2. WRL Syntax
3. WRL Semantics
4. XML Syntax for WRL
5. RDF Syntax for WRL
6. Mapping to OWL
7. Conclusions
Acknowledgments
References
Appendix A. Built-ins in WRL
Appendix B. Human-Readable Syntax
The Web Rule Language WRL is derived from the ontology
component of the Web Service Modeling Language WSML [WSML].
WRL is a rule-based [Lloyd, 1987] ontology language, whereas OWL [OWL] is a Description Logic based ontology
language. WRL adheres to a conceptual model for ontologies, developed in the WSMO effort, which is independent of any
logical language paradigm. The basic ontology meta-model of WRL consists of
concepts, relations, instances, and axioms.
WRL has an XML exchange syntax which is based on RuleML [Boley et al., 2001]. It is expected that WRL, WSML, SWSL and RuleML will
converge on the XML syntax.
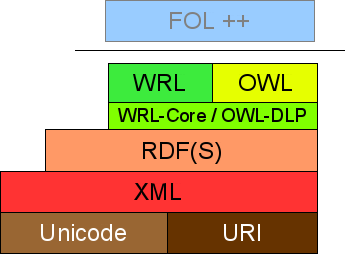
Figure 1: WRL positioned in the Semantic Web Layer
Cake
Figure 1 depicts the location of the Web Rule Language WRL in
the Semantic Web language layer cake.[1] This layer cake differs
slightly from the Semantic Web layer cake originally
presented at XML2000. Namely, we refine the "Ontology
vocabulary" layer. The Ontology vocabulary can be specified using
WRL or OWL, or using their common semantic subset, denoted by the
WRL-Core subset of WRL and the OWL-DLP subset
of OWL [Grosof et al.,
2003]. With common semantic subset we mean in this context that
every WRL-Core has a corresponding OWL-DLP ontology (and
vice versa), where both ontologies entail exactly the same set of
ground facts. In this new layer cake, WRL is a rules-based ontology
language, where OWL is a Description Logic based ontology
language. The common superset of WRL and OWL, here called "FOL++",
might be a First-Order Logic with particular extensions to
incorporate the nonmonotonic features. This language, going
beyond FOL RuleML [Boley et al., 2005] is a
possible development and is not addressed in this document. We
feel that it would be overambitious at this point in time to
try to specify FOL++; it is too early to standardize such an
expressive language, which is in fact an open research topic.
WRL itself consists of three variants, namely Core, Flight and
Full. WRL-Core marks the common core between OWL and WRL and is
thus the basic interoperability layer with OWL. WRL-Flight is
based on the Datalog subset of F-Logic [Kifer et al.,
1995], with negation-as-failure
under the Perfect Model Semantics [Przymusinski, 1989]. WRL-Full is based on full Horn with
negation-as-failure under the Well-Founded Semantics [van Gelder et al., 1991].
This document is further structured as follows. Chapter 2 defines the WRL
language along with the (normative) surface syntax. Chapter 3
specifies the WRL semantics through a mapping to existing
logical formalisms. Chapters 4 and 5 defined the XML and RDF
syntaxes of WRL, respectively. Chapter 6 specified the
mapping between WRL-Core and OWL for interoperability with OWL
ontologies. Finally, Chapter 7 presents conclusions.
In this chapter we introduce the WRL syntax. The WRL syntax
consists of two major parts: the conceptual syntax and the
logical expression syntax. The conceptual syntax is used for the
modeling of ontologies. Logical
expressions are used to refine these definitions using arbitrary
rules.
We use fragments of the WRL grammar in order to show the
syntax of the WRL elements. The grammar is specified using a
dialect of Extended BNF which can be used directly in the SableCC
compiler compiler [SableCC]. Terminals are
delimited with single quotes, non-terminals are underlined and
refer to the corresponding productions. Alternatives are
separated using vertical bars '|'; optional elements are appended
with a question mark '?'; elements that may occur zero or more
times are appended with an asterisk '*'; elements that may occur
one or more times are appended with a plus '+'. In the case of
multiple references to the same non-terminal in a production, the
non-terminals are disambiguated by using labels of the form
'[label]:'. In order to keep the descriptions in this chapter
concise, we do not fully describe all non-terminals.
Throughout the WRL examples in the following sections, we use
boldfaced text to distinguish WRL keywords.
This chapter is structured as follows. The WRL syntax basics,
such as the use of namespaces, identifiers, etc., are described
in Section 2.1. The elements in
common between all WRL specifications are described in Section
2.2. WRL ontologies are described
in Section 2.3.
Finally, the WRL logical expression syntax is specified in
Section 2.4.
The conceptual syntax for WRL has a frame-like style. The
information about a class and its attributes, a relation and its
parameters and an instance and its attribute values is specified
in one large syntactic construct, instead of being divided into a
number of atomic chunks. It is possible to spread the information
about a particular class, relation, instance or axiom over
several constructs, but we do not recommend this. In fact, in
this respect, WRL is similar to OIL [Fensel
et al., 2001], which also offers the possibility of either
grouping descriptions together in frames or spreading the
descriptions throughout the document. One important difference
with OIL (and OWL) is that attributes in WRL are only defined in the
context of the class to which the attribute
belongs. Attributes are part of a concept definition.
Nonetheless, attribute names are global and it is possible to
specify global behavior of attributes through logical
expressions. However, we do not expect this to be necessary in
the general case and we strongly advise against it. In case
one needs to model a property which is independent of the
concept definition, this property is most likely a relation
rather than an attribute and thus should be modeled as a relation.
It is often possible to specify a list of arguments, for
example for attributes. Such argument lists in WRL are
comma-separated and delimited by curly brackets. Statements in
WRL start with a keyword and can be spread over multiple
lines.
A WRL ontology is separated into two parts. The first part
provides meta-information about the ontology, which consists of
such things as WRL variant identification, namespace references,
non-functional properties (annotations), import of ontologies,
and the type of the specification.
This meta-information block is strictly ordered. The second part
of the specification, consisting of elements such as concepts,
attributes, relations, etc., is not ordered.
The remainder of this section explains the WRL MIME type and
the use of namespaces, identifiers and datatypes in WRL.
When accessing resources over the Web, the MIME type indicates
the type of the resource. For example, plain text documents have
the MIME type text/plain and XML documents have the MIME type
application/xml.
When exchanging WRL documents written in the normative syntax,
it is necessary to use the appropriate MIME type so that
automated agents can detect the type of content. The MIME type to
be used for WRL documents is:
application/x-wrl
WRL/XML documents should have the MIME type:
application/x-wrl+xml
WRL/RDF documents in the XML serialization of RDF should have the
usual MIME type: application/rdf+xml
Namespaces were first introduced in XML [XMLNamespaces] for the purpose of
qualifying names which originate from different XML documents. In
XML, each qualified name consists of a tuple <namespace,
localname>. RDF adopts the mechanism of namespaces from XML
with the difference that qualified names are not treated as
tuples, but rather as abbreviations for full URIs.
WRL adopts the namespace mechanism of RDF. A namespace can be
seen as part of an IRI (see the next Section). The WRL keywords
themselves belong to the the namespace
http://www.wsml.org/wsml/wrl-syntax# (commonly abbreviated as
'wrl').
Namespaces can be used to syntactically distinguish elements
of multiple WRL specifications and, more generally, resources on
the Web. A namespace denotes a syntactical domain for naming
resources.
Whenever a WRL specification has a specific identifier which
corresponds to a Web address, it is good practice to have a
relevant document on the location pointed to by the identifier.
This can either be the WRL document itself or a natural language
document related to the WRL document. Note that the identifier of
an ontology does not have to coincide with the location of the
ontology. It is good practice, however, to include a related
document, possibly pointing to the WRL specification itself, at
the location pointed to by the identifier.
An identifier in WRL is either a data value, an IRI [IRI], or an anonymous
ID.
WRL has direct support for different types of concrete data,
namely, strings, integers and decimals, which correspond to the
XML Schema [XMLSchemaDatatypes]
primitive datatypes string, integer and
decimal. These concrete values can then be used to
construct more complex datatypes, corresponding to other XML
Schema primitive and derived datatypes, using datatype
constructor functions. See also Appendix
C.
WRL uses datatype wrappers to construct data values based on
XML Schema datatypes. The use of datatype wrappers gives more
control over the structure of the data values than the lexical
representation of XML. For example, the date: 3rd of February,
2005, which can be written in XML as: '2005-02-03', is written in
WRL as: _date(2005,2,3). The arguments of such a term can be
either strings, decimals, integers or variables. No other
arguments are allowed for such data terms. Each conforming WRL
implementation is required to support at least the
string, integer and decimal
datatypes.
Datatype identifiers manifest themselves in WRL in two
distinct ways, namely, as concept identifiers and as datatype
wrappers. A datatype wrapper is used as a data structure for
capturing the different components of data values. Datatype
identifiers can also be used directly as concept identifiers.
Note however that the domain of interpretation of any datatype is
finite and that asserting membership of a datatype for a value
which does not in fact belong to this datatype, leads to an
inconsistency in the knowledge base.
Examples of data values:
_date(2005,3,12)
_sqname("http://www.wsml.org/wsml/wrl-syntax#", "ontology")
_boolean("true")
The following are example attribute definitions which restrict
the range of the attribute to a particular datatype:
age ofType _integer
location ofType _iri
hasChildren ofType _boolean
WRL allows the following syntactical shortcuts for particular
datatypes:
- Data values of type string can be written between
double quotes ‘"’. Double quotes inside a string
should be escaped using the backslash (‘\’)
character: \".
- Integer values can simply be written as such. Thus an
integer of the form
integer is a shortcut
for _integer("integer"). For example,
4 is a shortcut for
_integer("4")
- Decimal values can simply be written as such, using the '.'
as decimal symbols. Thus a literal of the form
decimal is a shortcut for
_decimal("decimal"). For example,
4.2 is a shortcut for
_decimal("4.2").
Appendix A lists the built-in
predicates which any conforming WRL application must be able to
support, as well as the infix notation which serves as a shortcut
for the built-ins.
Furthermore, WRL also allows shortcut syntax for IRI and
sQName data values, as described below.
The IRI (Internationalized Resource Identifier)
[IRI] mechanism
provides a way to identify resources. IRIs may point to resources
on the Web (in which case the IRI can start with 'http://'), but
this is not necessary (e.g., books can be identified through IRIs
starting with 'urn:isbn:'). The IRI proposed standard is a
successor to the popular URI standard. In fact, every URI is an
IRI.
An IRI can be abbreviated to an sQName. Note that the term
'QName' has been used, after its introduction in XML [XMLNamespaces], with different meanings. The
meaning of the term 'QName' as defined in XML got blurred after
the adoption of the term in RDF. In XML, QNames are simply used
to qualify local names and thus every name is a tuple
<namespace, localname>. In RDF, QNames have become
abbreviations for URIs, which is different from the meaning in
XML. WRL adopts a view similar to the RDF-like version of QNames,
but due to its deviation from the original definition in XML we
call them sQNames which is short for 'serialized QName'.
An sQName consists of two parts, namely, the namespace prefix
and the local part. WRL allows two distinct ways to write
sQNames. sQName can be seen as a datatype and thus it has an
associated datatype wrapper, namely, _sqname (see
also Appendix A), which has two
arguments: namespace and localname. Because sQNames are very
common in WRL specifications, WRL allows a short syntax for
sQNames. An sQName can simply be written using a namespace prefix
and a localname, separated by a hash ('#'):
namespace_prefix#localname. It is also
possible to omit the namespace prefix and the hash symbol. In
this case, the name is defined in the default namespace.
An sQName is equivalent to the IRI which is obtained by
concatenating the namespace IRI (to which the prefix refers) with
the local part of the sQName. Therefore, an sQName can be seen as
an abbreviation for an IRI which enhances the legibility of the
specification. If an sQName has no prefix, the namespace of the
sQName is the default namespace of the document.
IRI is a datatype in WRL and has the associated datatype
wrapper _iri with one argument (the IRI). For
convenience, WRL also allows a short form with the delimiters '
_" ' and ' " '. For convenience, an sQName does not require
special delimiters. However, sQNames may not coincide with any
WRL keywords. The characters '.' and '-' in an sQName need to be
escaped using the backslash (‘\’) character.
Examples of full IRIs in WRL:
_"http://example.org/PersonOntology#Human"
_"http://www.uibk.ac.at/"
Examples of sQNames in WRL (with corresponding full IRIs; dc
stands for http://purl.org/dc/elements/1.1#, foaf stands for
http://xmlns.com/foaf/0.1/ and xsd stands for
http://www.w3.org/2001/XMLSchema#; we assume the default
namespace http://example.org/#):
- dc#title (http://purl.org/dc/elements/1.1#title)
- foaf#name (http://xmlns.com/foaf/0.1/name)
- xsd#string (http://www.w3.org/2001/XMLSchema#string)
- Person (http://example.org/#Person)
- hasChild (http://example.org/#hasChild)
WRL defines the following two IRIs:
http://www.wsmo.org/wsml/wrl-syntax#true and
http://www.wsmo.org/wsml/wrl-syntax#false, which
stand for universal truth and universal falsehood, respectively.
Note that for convenience we typically use the abbreviated sQName
form (where wrl stands for the default WRL namespace
http://www.wsmo.org/wsml/wrl-syntax#): wrl#true, wrl#false.
Additionally, WRL allows the keywords 'true' and 'false' in the
human-readable syntax.
Please note that the IRI of a resource does not necessarily
correspond to a document on the Web. Therefore, we distinguish
between the identifier and the locator of a
resource. The locator of a resource is an IRI which can be mapped
to a location from which the (information about the) resource can
be retrieved.
An anonymous identifier represents an IRI which is meant to be
globally unique. Global uniqueness is to be ensured by the system
interpreting the WRL description (instead of the author of the
specification). It can be used whenever the concrete identifier
to be used to denote an object is not relevant, but when we
require the identifier to be new (i.e., not used anywhere else in
the WRL description).
Anonymous identifiers in WRL follow the naming convention for
anonymous IDs presented in [Yang & Kifer,
2003]. Unnumbered anonymous IDs are denoted with
‘_#’. Each occurrence of ‘_#’ denotes a
new anonymous ID and different occurrences of ‘_#’
are unrelated. Thus each occurrence of an unnumbered anonymous ID
can be seen as a new unique identifier.
Numbered anonymous IDs are denoted with
‘_#n’ where n stands for an integer
denoting the number of the anonymous ID. The use of numbered
anonymous IDs is limited to logical expressions and can therefore
not be used to denote entities in the conceptual syntax. Multiple
occurrences of the same numbered anonymous ID within the same
logical expression are interpreted as denoting the same
object.
Take as an example the following logical expressions:
_#[a hasValue _#1] and _#1 memberOf b.
_#1[a hasValue _#] and _# memberOf _#.
There are in total three occurrences of the unnumbered
anonymous ID. All occurrences are unrelated. Thus, the second
logical expression does not state that an object is a
member of itself, but rather that some anonymous object is a
member of some other anonymous object. The two occurrences of _#1
in the first logical expression denote the same object. Thus the
value of attribute a is a member of b.
The occurrence of _#1 in the second logical expression is,
however, not related to the occurrence of _#1 in the first
logical expression.
The use of an identifier in the specification of WRL elements
is optional. If no identifier is specified, the following default
rules apply:
- In case the identifier of an ontology is omitted or denoted by an anonymous ID, the
identifier is assumed to be the same as the locator of the
specification, i.e., the location where the specification was
found.
- In case the identifier of a WRL element (e.g., concept,
relation, postcondition) has been omitted, the unnumbered
anonymous identifier '_#' is used to identify the element.
If the same identifier is used for different definitions, it
is interpreted differently, depending on the context. In a
concept definition, an identifier is interpreted as a concept; in
a relation definition this same identifier is interpreted as a
relation. If, however, the same identifier is used in separate
definitions, but with the same context, then the interpretation
of the identifier has to conform to both definitions and thus the
definitions are interpreted conjunctively. For example, if there
are two concept definitions which are concerned with the same
concept identifier, the resulting concept definition includes all
attributes of the original definitions and if the same attribute
is defined in both definitions, the range of the resulting
attribute will be equivalent to the conjunction of the original
attributes.
A WRL file may at any place contain a comment. A single line
comment starts with comment or
// and ends with a line break.
Comments can also range over multiple lines, in which they need
to be delimited by /* and
*/.
It is recommended to use non-functional properties for any
information related to the actual WRL descriptions; comments
should be only used for meta-data about the WRL file itself.
Comments are disregarded when parsing the WRL document and when
converting to different syntaxes (e.g., XML, RDF).
Examples:
/* Illustrating a multi line
* comment
*/
// a one-line comment
comment another one-line comment
This section describes the elements of a WRL document. A WRL
document has the following structure:
Every WRL specification document may start with the
wrlVariant keyword, followed by an
identifier for the WRL variant which is used in the document.
WRL-Core is identified with
http://www.wsmo.org/wsml/wrl-syntax/wrl-core and
WRL-Flight is identified with
http://www.wsmo.org/wsml/wrl-syntax/wrl-flight and
WRL-Full is identified with
http://www.wsmo.org/wsml/wrl-syntax/wrl-full.
The specification of the wrlVariant is optional. In case the variant is
omitted, no guarantee can be given as to which WRL variant is
used.
The following illustrates the WRL variant reference for a
WRL-Flight specification:
wrlVariant _"http://www.wsml.org/wsml/wrl-syntax/wrl-flight"
When the intended WRL variant is explicitly stated, tools can
immediately recognize the intention of the author and return an
exception if the specification does not conform to the
syntactical restrictions imposed by the intended variant. This
kind of sublanguage variation, pioneered by RuleML [Boley,
2001], generally helps developers of WRL specifications to stay within
desired limits of complexity and to communicate their desires to
others.
At the top of a WRL document, below the identification of the
WRL variant, there is an optional block of namespace references,
which is preceded by the namespace
keyword. The namespace keyword is
followed by a number of namespace references. Each namespace
reference, except for the default namespace, consists of the
chosen prefix and the IRI which identifies the namespace. Note
that, like any argument list in WRL, the list of namespace
references is delimited with curly brackets ‘{’
‘}’. In case only a default namespace is declared,
the curly brackets are not required.
Two examples are given below, one with a number of namespace
declarations and one with only a default namespace:
namespace {_"http://www.example.org/ontologies/example#",
dc _"http://purl.org/dc/elements/1.1#",
foaf _"http://xmlns.com/foaf/0.1/",
wrl _"http://www.wsmo.org/wsml/wrl-syntax#",
loc _"http://www.wsmo.org/ontologies/location#" }
namespace _"http://www.example.org/ontologies/example#"
A WRL ontology specification is identified by the ontology keyword optionally followed by an IRI
which serves as the identifier of the ontology. If no identifier
is specified for the ontology, the locator of the ontology serves
as identifier.
Example:
ontology family
An ontology specification document in WRL consists of:
In this section we explain the ontology modeling elements in
the WRL language. The modeling elements are based on the WSMO
conceptual model of ontologies [Roman et
al., 2005].
Any WRL specification may have non-functional properties and
may import ontologies:
Non-functional properties may be used for the WRL document as
a whole but also for each element in the specification.
Non-functional property blocks are delimited with the keywords
nonFunctionalProperties and
endNonFunctionalProperties or the
short forms nfp and endnfp. Following the keyword is a list of
attribute values, which consists of the attribute identifier, the
keyword hasValue and the value for the attribute, which
may be any identifier and can thus be an IRI, a data value, an
anonymous identifier or a comma-separated list of the former,
delimited with curly brackets. The recommended properties are the
properties of the Dublin Core [DublinCore], but the list of properties is extensible and thus
the user can choose to use properties coming from different
sources. Following the WRL convention, if a property has multiple
values, these are separated by commas and the list of values is
delimited by curly brackets.
Example:
nonFunctionalProperties
dc#title hasValue "WRL example ontology"
dc#subject hasValue "family"
dc#description hasValue "fragments of a family ontology to provide WRL examples"
dc#contributor hasValue { _"http://homepage.uibk.ac.at/~c703240/foaf.rdf",
_"http://homepage.uibk.ac.at/~csaa5569/",
_"http://homepage.uibk.ac.at/~c703239/foaf.rdf",
_"http://homepage.uibk.ac.at/homepage/~c703319/foaf.rdf" }
dc#date hasValue _date("2004-11-22")
dc#format hasValue "text/html"
dc#language hasValue "en-US"
dc#rights hasValue _"http://www.deri.org/privacy.html"
wrl#version hasValue "$Revision: 1.4 $"
endNonFunctionalProperties
Non-functional properties in WRL are not part of the logical
language; programmatic access to these properties can be provided
through an API.
Ontologies may be imported in any WRL specification through
the import ontologies block, identified by the keyword
importsOntology. Following the
keyword is a list of IRIs identifying the ontologies being
imported. An importsOntology
definition serves to merge ontologies, similar to the
owl:import annotation property in
OWL. This means the resulting ontology is the union of all axioms
and definitions in the importing and imported ontologies. Please
note that recursive import of ontologies is also supported. This
means that if an imported ontology has any imported ontologies of
its own, these ontologies are also imported.
Example:
importsOntology {_"http://www.wsmo.org/ontologies/location",
_"http://xmlns.com/foaf/0.1"}
If the imported ontology is of a different WRL variant than
the importing specification, the resulting ontology is of the
most expressive of the two variants. For example, if a WRL-Core
ontology imports a WRL-Full ontology, the result of the import
will be a WRL-Full ontology.
A concept definition starts with the concept keyword, which is optionally followed by
the identifier of the concept. This is optionally followed by a
superconcept definition which consists of the keyword
subConceptOf followed by one or more concept
identifiers (as usual, if there is more than one, the list is
comma-separated and delimited by curly brackets). This is
followed by an optional nonFunctionalProperties block and zero or more
attribute definitions.
Note that WRL allows inheritance of attribute definitions,
which means that a concept inherits all attribute definitions of
its superconcepts. If two superconcepts have a definition for the
same attribute a, but with a different range, these
attribute definitions are interpreted conjunctively. This means
that the resulting range of the attribute a in the
subconcept is the conjunction (intersection) of the ranges of the
attribute definitions in the superconcepts.
Example:
concept Human subConceptOf {Primate, LegalAgent}
nonFunctionalProperties
dc#description hasValue "concept of a human being"
dc#relation hasValue humanDefinition
endNonFunctionalProperties
hasName ofType foaf#name
hasParent impliesType Human
hasChild impliesType Human
hasAncestor impliesType Human
hasWeight ofType _float
hasWeightInKG ofType _float
hasBirthdate ofType _date
hasObit ofType _date
hasBirthplace ofType loc#location
isMarriedTo impliesType Human
hasCitizenship ofType oo#country
WRL allows creation of axioms in order to refine the
definition already given in the conceptual syntax, i.e., the
subconcept and attribute definitions. It is advised in the WRL
specification to include the relation between the concept and the
axioms related to the concept in the non-functional properties
through the property dc#relation. In the example
above we refer to an axiom with the identifier
humanDefinition (see Section 2.3.5 for the
axiom).
Different knowledge representation languages, such as
Description Logics, allow for the specification of defined
concepts (called "complete classes" in OWL). The definition of a
defined concept is not only necessary, but also sufficient. A
necessary definition, such as the concept specification in the
example above, specifies implications of membership of the
concept for all instances of this concept. The concept
description above specifies that each instance of
Human is also an instance of Primate
and LegalAgent. Furthermore, all values for the
attributes hasName, hasParent,
hasWeight etc. must be of specific types. A necessary and
sufficient definition also works the other way around, which
means that if certain properties hold for the instance, the
instance is inferred to be a member of this concept.
WRL supports defined concepts through the use of axioms (see
Section 2.3.5). The logical expression contained in the axiom
should reflect an equivalence relation between a class membership
expression on one side and a conjunction of class membership
expressions on the other side, each with the same variable. Thus,
such a definition should be of the form:
?x memberOf A equivalent ?x memberOf B1 and ... and ?x memberOf Bn
With A and
B1,...,Bn concept
identifiers.
For example, in order to define the class Human
as the intersection of the classes Primate and
LegalAgent, the following definition is used:
axiom humanDefinition
definedBy
?x memberOf Human equivalent ?x memberOf Primate and ?x memberOf LegalAgent.
Two important features of attribute modeling which set WRL apart
from OWL are cardinality
constraints and attribute range constraints.
OWL offers cardinality and range restrictions on attributes which
serve to create additional (monotonic) inferences
such as existence or equality of objects or membership in a certain
class. For many users these restrictions
show unintuitive behavior from the viewpoint of classical rule
languages and databases [de Bruijn et al.,
2005]: Means to actually
check the data in your knowledge base with respect to
integrity constraints are missing in OWL. WRL allows the
specification of cardinality and range
constraints which are defined like integrity constraints in databases,
i.e., in the case of violation of a constraint, a given ontology
is inconsistent. This additional feature allows to check the integrity
of a closed set of data, implicitly the modeler to express
a local a closed world view on her/his published data.
WRL allows two kinds of attribute definitions, namely,
constraining definitions with the keyword ofType and
inferring definitions with the keyword impliesType. We
expect that inferring attribute definitions will not be used very
often if constraining definitions are allowed. However, WRL-Core
does not allow constraining attribute definitions. In order to
facilitate conceptual modeling in these language variants, we
allow the use of impliesType in WRL.
An attribute definition of the form A
ofType D, where A is
an attribute identifier and D is a concept
identifier, is a constraint on the values for attribute
A. If the value for the attribute A is not
known to be of type D, the constraint is violated and
the attribute value is inconsistent with respect to the ontology.
This notion of constraints corresponds to the usual
database-style constraints.
The keyword impliesType can be used for inferring the
type of a particular attribute value. An attribute definition of
the form A impliesType D,
where A is an attribute identifier and
D is a concept identifier, implies
membership of the concept D for all values
of the attribute A. Please note that if the range of the
attribute is a datatype, the semantics of ofType and
impliesType coincide, because datatypes have a known
domain and thus values need not be inferred to be of a certain
datatype.
Attributes which have a datatype as a range can be
distinguished from regular attributes through the meta-concept
_datatype. Each datatype used in WRL is a member of this
meta-concept.
Attributes which do not have a datatype range can be specified
as being reflexive, transitive, symmetric, or being the inverse
of another attribute, using the reflexive,
transitive, symmetric and inverseOf
keywords, respectively. Notice that these keywords do not enforce
a constraint on the attribute, but are used to infer additional
information about the attribute. The keyword inverseOf
must be followed by an identifier of the attribute, enclosed in
parentheses, of which this attribute is the inverse.
The cardinality constraints for a single attribute are
specified by including two numbers between parentheses '(' ')',
indicating the minimal and maximal cardinality, after the
ofType (or impliesType) keyword. The first number
indicates the minimal cardinality. The second number indicates
the maximal cardinality, where '*' stands for unlimited maximal
cardinality (and is not allowed for minimal cardinality). It is
possible to write down just one number instead of two, which is
interpreted as both a minimal and a maximal cardinality
constraint. When the cardinality is omitted, then it is assumed
that there are no constraints on the cardinality, which is
equivalent to (0 *). Note that a maximal cardinality
of 1 makes an attribute functional.
When an attribute is specified as being transitive, this means
that if three individuals a, b and c are
related via a transitive attribute att in such a way:
a att b att c then c is
also a value for the attribute att at a: a
att c.
When an attribute is specified as being symmetric, this means
that if an individual a has a symmetric attribute
att with value b, then b also has attribute
att with value a.
When an attribute is specified as being the inverse of another
attribute, this means that if an individual a has an
attribute att1 with value b and att1 is the
inverse of a certain attribute att2, then it is inferred
that b has an attribute att2 with value
a.
Below is an example of a concept definition with attribute
definitions:
concept Human
nonFunctionalProperties
dc#description hasValue "concept of a human being"
endNonFunctionalProperties
hasName ofType foaf#name
hasParent inverseOf(hasChild) impliesType Human
hasChild impliesType Human
hasAncestor transitive impliesType Human
hasWeight ofType (1) _float
hasWeightInKG ofType (1) _float
hasBirthdate ofType (1) _date
hasObit ofType (0 1) _date
hasBirthplace ofType (1) loc#location
isMarriedTo symmetric impliesType (0 1) Human
hasCitizenship ofType oo#country
WRL-Core poses a number of restrictions on attribute
definitions. Most of these restrictions stem from the fact that
it is not possible to express constraints in WRL-Core, other
than for datatypes.
- WRL-Core does not allow for the specification of the
attribute features reflexive, transitive,
symmetric and inverseOf. This restriction stems
from the fact that reflexivity, transitivity, symmetry and
inverse of attributes are defined locally to a concept in WRL as
opposed to Description Logics or OWL. You can however define
global transitivity, symmetry and inverse of attributes
just like in DLs or OWL by defining respective axioms (cf.
Definition 3.3
below).
- Cardinality constraints are not allowed and thus it is not
possible to specify functional properties.
- One may not specify constraining attribute definitions, other
than for datatype ranges. In other words, attribute definitions
of the form:
A ofType D are
not allowed, unless D is a datatype
identifier.
A relation definition starts with the relation keyword, which is optionally followed
by the identifier of the relation. WRL allows the specification
of relations with arbitrary arity. The domain of the parameters
can be optionally specified using the keyword impliesType or ofType. Note that parameters of a relation are
strictly ordered. A relation definition is optionally completed
by the keyword subRelationOf
followed by one or more identifiers of super-relations. Finally an
optional nonFunctionalProperties
block can be specified.
Relations in WRL can have an arbitrary arity and values for
the parameters can be constrained using parameter type
definitions of the form ( ofType type-name ) and (
impliesType type-name). In case a parameter type
definition is present, the arity is not required, because
it can be derived from the parameter type specification;
otherwise, the arity is required. The usage of ofType and impliesType
correspond with the usage in attribute definitions. Namely,
parameter definitions with the ofType keyword are used to
constrain the allowed parameter values, whereas parameter
definitions with the impliesType keyword are used to infer
concept membership of parameter values.
Below are two examples, one with parameter definitions and one
with an arity definition:
relation distance (ofType City, ofType City, impliesType _decimal) subRelationOf measurement
relation distance/3
As for concepts, the exact meaning of a relation can be
defined using axioms. For example one could axiomatize the
transitive closure for a property or further restrict the domain
of one of the parameters. As with concepts, it is recommended
that related axioms are indicated using the non-functional
property dc#relation.
In WRL-Core, the arity of relations is restricted to two. The
domain of the two parameters may be given using the keyword
impliesType or ofType. However, the ofType keyword is
only allowed in combination with a datatype and only the second
parameter may have a datatype as its range.
An instance definition starts with the instance keyword, (optionally) followed by the
identifier of the instance, the memberOf keyword and the name of the concept to
which the instance belongs. The memberOf keyword identifies the concept to which
the instance belongs. This definition is followed by the
attribute values associated with the instance. Each property
filler consists of the property identifier, the keyword
hasValue and the value(s) for the
attribute.
Example:
instance Mary memberOf {Parent, Woman}
hasName hasValue "Maria Smith"
hasBirthdate hasValue _date(1949,9,12)
hasChild hasValue {Paul, Susan}
Instances explicitly specified in an ontology are those which
are shared together as part of the ontology. However, most
instance data exists outside the ontology in private data stores.
Access to these instances, as described in [Roman et al., 2005], is achieved by providing a
link to an instance store. Instance stores contain large numbers
of instances and they are linked to the ontology. We do not
restrict the user in the way an instance store is linked to a WRL
ontology. This would be done outside the ontology definition,
since an ontology is shared and can thus be used in combination
with different instance stores.
Besides specifying instances of concepts, it is also possible
to specify instances of relations. Such a relation instance
definition starts with the relationInstance keyword, (optionally) followed
by the identifier of the relationInstance, the memberOf keyword and the name of the relation to
which the instance belongs. This is followed by an optional
nonFunctionalProperties block,
followed by the values of the parameters associated with the
instance.
Below is an example of an instance of a ternary relation
(remember that the identifier is optional, see also Section 2.1.2):
relationInstance distance(Innsbruck, Munich, 234)
WRL-Core does not impose restrictions on the specification of
instances for concepts. Relation instances are only allowed for
binary relations. Both values of the relation have to be
specified and have to correspond to its signature. This includes
the restriction that the first value may not be a data
value.
An axiom definition starts with the axiom keyword, followed by the name (identifier)
of the axiom. This is followed by an optional nonFunctionalProperties block and a logical
expression preceded by the definedBy
keyword. The logical expression must be followed by either a
blank or a new line. The language allowed for the logical
expression is explained in Section 2.4.
Example of a defining axiom:
axiom humanDefinition
definedBy
?x memberOf Human equivalent
?x memberOf Animal and
?x memberOf LegalAgent.
WRL allows the specification of database-style integrity
constraints. Below is an example of a constraining axiom:
axiom humanBMIConstraint
definedBy
!- naf bodyMassIndex(bmi hasValue ?b, length hasValue ?l, weight hasValue ?w)
and ?x memberOf Human and
?x[length hasValue ?l,
weight hasValue ?w,
bmi hasValue ?b].
Logical expressions occur within axioms of ontologies. In the
following, we give a syntax specification for general logical
expressions in WRL.
In order to specify the WRL logical expressions, we introduce
a new kind of identifier: variables.
Variable names start with an initial question mark, "?".
Variables may occur in place of concepts, attributes, instances,
relation arguments or attribute values. A variable may not,
however, replace a WRL keyword. Furthermore, variables may only
be used inside logical expressions.
The scope of a variable is always defined by its
quantification. If a variable is not quantified inside a formula,
the variable is implicitly universally quantified outside the
formula.
Examples of variables are: ?x, ?y1, ?myVariable
The syntax specified in the following is inspired by
First-Order Logic [Enderton, 2002]
and F-Logic [Kifer et al., 1995]. We
define first the notation of a WRL vocabulary in Definition
2.1.
Definition
2.1. A WRL vocabulary V of a language L(V)
consists of the following:
- A set of identifiers VID.
- A set of object constructors VO ⊆
VID.
- A set of function symbols VF ⊆
VO.
- A set of datatype wrappers VD ⊆
VO.
- A set of data values VDV ⊆
VO which encompasses all string, integer
and decimal values.
- A set of anonymous identifiers VA ⊆
VO of the form _#, _#1, _#2, etc....
- A set of relation identifiers VR ⊆
VID.
- A set of variable identifiers VV ⊆
VID of the form ?alpanum*.
In the following subsections we define the logical expression
syntax for the different WRL variants.
WRL-Core allows only a restricted form of logical
expressions. There are two sources for these restrictions [Grosof et al.,
2003].
Namely, the restriction of the language to a subset of
Description Logics restricts the kind of formulas which can be
written in the two-variable fragment of first-order logic.
Furthermore, it disallows the use of function symbols,
restricts the arity of predicates to binary and
chaining variables over predicates. The restriction of the
language to a subset of Datalog (without equality) disallows the
use of the equality symbol, disjunction in the head of a rule and
existentially quantified variables in the head of the rule.
Definition 2.2. A WRL-Core
vocabulary V is a WRL vocabulary with the following
restrictions:
- VC, VD,
VR, VI and
VNFP are the sets of concept, datatype,
relation, instance and non-functional property identifiers.
These sets are all subsets of the set of IRIs and are pairwise
disjoint.
- The set of attribute names is equivalent to
VR
- The set of relation identifiers VR is
split into two disjoint sets, VRA and
VRC, which correspond to relations with an
abstract and relations with a concrete range,
respectively.
Let V be a WRL-Core vocabulary. Let further γ
∈ VC, Γ be either an identifier in
VC or a list of identifiers in VC, Δ
be either an identifier in VD or a list of identifiers
in VD, φ ∈ VI, ψ be either an
identifier in VI or a list of identifiers in
VI, p,q ∈ VRA, s,t
∈ VRC, and Val be either a data value or a
list of data values.
Definition 2.3. The set of
atomic formulae (also called molecules) in L(V) is defined as follows:
- γ subConceptOf Γ is an atomic formula in
L(V)
- φ memberOf Γ is an atomic formula in
L(V)
- φ[ p ofType Δ ] is an atomic
formula in L(V)
- φ[ s impliesType Δ ] is an atomic
formula in L(V)
- φ[ s impliesType Γ ] is an atomic
formula in L(V)
- φ[ p hasValue ψ ] is an atomic
formula in L(V)
- φ[ s hasValue Val ] is an atomic
formula in L(V)
These are the only atomic formulae allowed in WRL Core, i.e.,
compared with general logical expressions, WRL core only allows
ground facts.
Let Var1, Var2, ... be
arbitrary WRL variables. We call molecules of the form
Vari memberOf Γ
a-molecules, and molecules of the forms ,
Vari[ p hasValue
Vark ] and Vari[ p
hasValue {Vark1,
Varkl} ] b-molecules, respectively.
In the following, F stands for an lhs-formula, with the
set of lhs-formulae defined as follows:
- Any b-molecule is an lhs-formula
- if F1 and F2 are
lhs-formulae, then F1 and
F2 is an lhs-formula
- if F1 and F2 are
lhs-formulae, then F1 or
F2 is an lhs-formula
In the following, G,H stand for rhs-formulae, with the
set of rhs-formulae defined as follows:
- Any a-molecule is an rhs-formula
- if G and H are rhs-formulae, then G
and H is an rhs-formula
Definition 2.4. The set
of WRL-Core formulae is defined as follows:
- Any atomic formula is a formula in L(V).
- If F1,...Fn are atomic
formulae, then F1 and ... and
Fn is a formula in L(V).
- Var1[ p hasValue
Var2 ] impliedBy
Var1[ p hasValue
Var3 ] and Var3[
p hasValue Var2 ] (globally
transitive attribute/relation) is a formula in
L(V).
- Var1[ p hasValue
Var2 ] impliedBy
Var2[ p hasValue
Var1 ] (globally symmetric
attribute/relation) is a formula in L(V).
- Var1[ p hasValue
Var2 ] impliedBy
Var1[ q hasValue
Var2 ] (globally
sub-attribute/relation)) is a formula in
L(V).
- Var1[ p hasValue
Var2 ] impliedBy
Var2[ q hasValue
Var1 ] (globally inverse
attribute/relation)) is a formula in L(V).
- G equivalent H is a formula in
L(V) if it contains only one WRL variable.
- H impliedBy F is a formula in
L(V) if all the WRL variables occurring in H occur in F
as well and the variable graph of F is connected
and acyclic.
- If, for WRL-Core formulae D and E,
D impliedBy E is a formula in
L(V), then Body implies
Head is a
formula in L(V) .
- Any occurrence of a molecule of the form
Var1[ p hasValue
Var2 ] in a WRL-Core clause can be
interchanged with
p(Var1,Var2) (i.e.,
these two forms can be used interchangeably in WRL
Core).
Any WRL-Core formula together with a period '.' is
a logical expression in WRL-Core.
Here, the variable graph of a formula E,
defined as the undirected graph having all variables in E as
nodes and an edge between Var2 and
Var2 for every molecule
Var1[p hasValue
Var2], or
p(Var1,Var2),
respectively, then E is an admissible WRL-Core
formula.
Note that wherever an a-molecule (or b-molecule) is allowed in
a WRL-Core clause, compound molecules abbreviating conjunctions
of a-molecules (or b-molecules, respectively), as mentioned at
the end of this section.
The following are examples of WRL-Core logical expressions:
The attribute 'hasAncestor' is transitive:
?x[hasAncestor hasValue ?z] impliedBy ?x[hasAncestor hasValue ?y] and ?y[hasAncestor hasValue ?z].
A female person is a woman:
?x memberOf Woman impliedBy ?x memberOf
Person and ?x memberOf Female
A student is a person:
Student subConceptOf Person.
WRL-Flight is a rule language based on the Datalog subset of
F-Logic, extended with locally stratified default negation, the
inequality symbol '!=' and the unification operator '='.
Furthermore, WRL-Flight allows monotonic Lloyd-Topor [Lloyd and Topor, 1984], which means that we
allow classical implication and conjunction in the head of a rule
and we allow disjunction in the body of a rule.
The head and the body of a rule are separated using the Logic
Programming implication symbol ':-'. This additional
symbol is required because negation-as-failure (naf) is
not defined for classical implication (implies,
impliedBy). WRL-Flight allows classical implication in the
head of the rule. Consequently, every WRL-Core logical
expression is a WRL-Flight rule with an empty body.
We define the notion of
a WRL-Flight vocabulary in Definition 2.5.
Definition 2.5.
Any WRL vocabulary (see Definition
2.1) is a WRL-Flight vocabulary.
Definition 2.6
defines the set of WRL-Flight terms
TermFlight(V) for a given vocabulary
V.
Definition 2.6. Given
a vocabulary V, the set of terms
TermFlight(V) in WRL-Flight is defined as
follows:
- Any f ∈ VO is a term.
- Any v ∈ VV is a term
- If d ∈ VD and
dv1, ..., dvn are in
VDV ∪ VV, then
d(dv1, ..., dvn) is a
term.
As usual, the set of ground terms
GroundTermFlight(V) is the greatest subset of
TermFlight(V) in which no variables occur.
Definition 2.7. Given a
set of WRL-Flight terms TermFlight(V), an
atomic formula in L(V) is defined by:
- If r ∈ VR and
t1, ..., tn are terms, then
r(t1, ..., tn) is an atomic
formula in L(V).
- If α, β ∈
TermFlight(V) then α =
β, and α != β are
atomic formulae in L(V).
- If α, β ∈
TermFlight(V) and γ ∈
Term(V) or γ is of the form {
γ1,...,γn }
with γ1,...,γn
∈ TermFlight(V), then:
- α subConceptOf γ is an atomic
formula in L(V)
- α memberOf γ is an
atomic formula in L(V)
- α[β ofType
γ] is an atomic formula in
L(V)
- α[β impliesType
γ] is an atomic formula in
L(V)
- α[β hasValue
γ] is an atomic formula in
L(V)
A ground atomic formula is an atomic formula with no
variables.
Definition 2.8.
Given a WRL-Flight vocabulary V, the set of formulae in
L(V) is recursively defined as follows:
- We define the set of admissible head formulae
Head(V) as follows:
- Any atomic formula α which does not contain the
inequality symbol (!=) or the unification operator (=) is
in Head(V).
- Let α,β ∈ Head(V),
then α and β is in
Head(V).
- α implies β is in
Head(V) .
- α impliedBy β is in
Head(V).
- α equivalent β is in
Head(V).
- Any variable-free admissible head formula in Head(V) is a formula
in L(V).
- We define the set of admissible body formulae
Body(V) as follows:
- Any atomic formula α is in
Body(V)
- For α ∈ Body(V), naf
α is in Body(V).
- For α,β ∈ Body(V),
α and β is in
Body(V).
- For α,β ∈ Body(V),
α or β is in
Body(V).
- Given a head-formula β ∈ Head(V)
and a body-formula α ∈ Body(V),
β :- α is a formula. Here we
call α the body and β the
head of the formula. The formula is admissible if (1)
α is an admissible body formula, (2) β
is an admissible head formula, and (3) the safety
condition holds.
- Any formula of the form !- α with
α ∈ Body(V) is an admissible formula
and is called a constraint.
Any WRL-Flight admissible formula together with a period '.' is
a logical expression in WRL-Core.
In order to check the safety condition for a
WRL-Flight rule, the following transformations should be applied
until no transformation rule is applicable:
- Rules of the form A1 and ...
and An :- B are split
into n different rules:
- Rules of the form A1 equivalent
A2 :- B are split into 2 rules:
- A1 implies
A2 :- B
- A1 impliedBy
A2 :- B
- Rules of the form A1 impliedBy
A2 :- B are transformed to:
- Rules of the form A1 implies
A2 :- B are transformed to:
- Rules of the form A :- B1
or ... or Bn are split into
n different rules:
Application of these transformation rules yields a set of
WRL-Flight rules with only one atomic formula in the head and a
conjunction of literals in the body.
The safety condition holds for a WRL-Flight rule if every
variable which occurs in the rule occurs in a positive body
literal which does not correspond to a built-in predicate. For
example, the following rules are not safe and thus not allowed in
WRL-Flight:
p(?x) :- q(?y).
a[b hasValue ?x] :- ?x > 25.
?x[gender hasValue male] :- naf ?x[gender hasValue female].
We require each WRL-Flight knowledge base to be locally
stratified. Appendix A of [Kifer et
al., 1995] explains local stratification for a frame-based
logical language.
The following are examples of WRL-Flight logical expressions
(note that variables are implicitly universally quantified):
No human can be both male and female:
!- ?x[gender hasValue {?y, ?z}] memberOf Human and ?y = Male and ?z = Female.
The brother of a parent is an uncle:
?x[uncle hasValue ?z] impliedBy ?x[parent hasValue ?y] and ?y[brother hasValue ?z].
Do not trust strangers:
?x[distrust hasValue ?y] :- naf ?x[knows hasValue ?y].
The WRL-Full logical expression syntax extends WRL-Flight by
allowing unsafe rules, full Lloyd-Topor (i.e., arbitrary
first-order formulas in the body of a rule), and unstratified
negation (under the Well-Founded Semantics).
We start with the definition of the basic vocabulary for
building logical expressions. Then, we define how the elements of
the basic vocabulary can be composed in order to obtain
admissible logical expressions. Definition 2.1 defines
the notion of a vocabulary V of a WRL language
L.
WRL allows the following connectives: and,
or, implies, impliedBy, equivalent,
naf, forall and exists and the following
auxiliary symbols: '(', ')', '[', ']', ',', '=',
'!=', memberOf, hasValue,
subConceptOf, ofType, and impliesType.
Furthermore, WRL allows use of the symbol ':-' for Logic
Programming rules and the use of the symbol '!-' for
database-style constraints.
Definition 2.9
defines the set of terms Term(V) for a given vocabulary
V.
Definition 2.9. Given
a vocabulary V, the set of terms Term(V) in
WRL-Full is defined as follows:
- Any f ∈ VO is a term.
- Any v ∈ VV is a term
- If f ∈ VF and
t1, ..., tn are terms, then
f(t1, ..., tn) is a
term.
- If f ∈ VD and
dv1, ..., dvn are in
VDV ∪ VV, then
f(dv1, ..., dvn) is a
term.
As usual, the set of ground terms
GroundTerm(V) is the greatest subset of
Term(V) in which no variables occur.
Based on the basic constructs of logical expressions, the
terms, we can now define formulae. In WRL, we have atomic
formulae and complex formulae. A logical expression consists of a
formula terminated by a period.
Definition 2.10. Given a
set of WRL-Full terms Term(V), an atomic formula in
L(V) is defined by:
- If r ∈ VR and
t1, ..., tn are terms, then
r(t1, ..., tn) is an atomic
formula in L(V).
- If α, β ∈
TermRule(V) then α =
β, and α != β are
atomic formulae in L(V).
- If α, β ∈
TermRule(V) and γ ∈
Term(V) or γ is of the form {
γ1,...,γn }
with γ1,...,γn
∈ TermRule(V), then:
- α subConceptOf γ is an atomic
formula in L(V)
- α memberOf γ is an
atomic formula in L(V)
- α[β ofType
γ] is an atomic formula in
L(V)
- α[β impliesType
γ] is an atomic formula in
L(V)
- α[β hasValue
γ] is an atomic formula in
L(V)
A ground atomic formula is an atomic formula with no
variables.
Definition 2.11.
Given a WRL-Full vocabulary V, the set of formulae in
L(V) is recursively defined as follows:
- We define the set of admissible head formulae
Head(V) as follows:
- Any atomic formula α which does not contain the
inequality symbol (!=) or the unification operator (=) is
in Head(V).
- Let α,β ∈ Head(V),
then α and β is in
Head(V).
- α implies β is in
Head(V) .
- α impliedBy β is in
Head(V).
- α equivalent β is in
Head(V).
- Any admissible head formula in Head(V) is a formula
in L(V).
- We define the set of admissible body formulae
Body(V) as follows:
- Any atomic formula α is in
Body(V)
- For α ∈ Body(V), naf
α is in Body(V).
- For α,β ∈ Body(V),
α and β is in
Body(V).
- For α,β ∈ Body(V),
α or β is in
Body(V).
- For α,β ∈ Body(V),
α implies β is in
Body(V).
- For α,β ∈ Body(V),
α impliedBy β is in
Body(V).
- For α,β ∈ Body(V),
α equivalent β is in
Body(V).
- For variables ?x1,...,?xn and
α ∈ Body(V),
forall ?x1,...,?xn
(α) is in
Body(V).
- For variables ?x1,...,?xn and
α ∈ Body(V),
exists ?x1,...,?xn
(α) is in
Body(V).
- Given a head-formula β ∈ Head(V)
and a body-formula α ∈ Body(V),
β :- α is a formula. Here we
call α the body and β the
head of the formula. The formula is admissible if (1)
α is an admissible body formula, (2) β
is an admissible head formula.
- Any formula of the form !- α with
α ∈ Body(V) is an admissible formula
and is called a constraint.
Any WRL-Full admissible formula followed by a dot '.' is a WRL logical
expression.
The precedence of the operators is as follows: implies,
equivalent, impliedBy < or, and < naf. Here,
op1 < op2 means that
operator op2 binds stronger than operator
op1. The precedence prevents extensive use of
parentheses and thus helps to achieve a better readability of
logical expressions.
To enhance the readability of logical expressions it is
possible to abbreviate a conjunction of several molecules with the
same subject as one compound molecule. E.g., the three
molecules
Human subConceptOf Mammal
and Human[hasName ofType foaf#name] and Human[hasChild impliesType Human]
can be written as
Human[hasName ofType foaf#name, hasChild impliesType Human] subConceptOf Mammal
The following are examples of WRL-Full logical expressions:
Both the father and the mother are parents:
?x[parent hasValue ?y] :- ?x[father hasValue ?y] or ?x[mother hasValue ?y].
Every person has a father:
?x[father hasValue f(?x)] :- ?x memberOf Person.
There may only be one distance between two locations, and
the distance between locations A and B is
the same as the distance between B and A:
!- distance(?location1,?location2,?distance1) and
distance(?location1,?location2,?distance2) and ?distance1 != distance2.
distance(?B,?A,?distance) :-
distance(?A,?B,?distance).
In the previous chapter we have defined the conceptual and
logical expression syntax for different WRL variants. We have
mentioned several characteristics of the semantics of different
variants, but we have not defined the semantics itself. This
chapter specifies the formal semantics for the WRL variants.
In the following we provide first a mapping between the
conceptual syntax for ontologies and the logical expression
syntax for that part of the conceptual syntax which has a meaning
in the logical language. We then provide a semantics for
WRL-Core, WRL-Flight and WRL-Full through mappings to existing
logical formalisms.
In order to be able to specify the WRL semantics in a concise
and understandable way, we first translate the conceptual syntax
to the logical expression syntax.
Before we translate the conceptual syntax to the logical
expression syntax, we perform the following pre-processing
steps:
- Introduce unnumbered anonymous identifiers (see
Section 2.1.3) for missing
identifiers.
- Remove all non-functional properties from the conceptual
model.
- Replace idlists with single ids for
subRelationOf.
E.g., "P subRelationOf {Q, R}" is
substituted by "P subRelationOf Q" and
"P subRelationOf R".
- Expand all sQNames to full IRIs using the namespace
declarations.
Table 3.1 contains the mapping between the WRL conceptual
syntax for ontologies and the logical expression syntax through
the mapping function τ (X and Y are
meta-variables and are replaced by actual identifiers or
variables during the translation itself; pnew
is a newly introduced predicate). In the table, italic keywords
refer to productions in the WRL grammar (as explained in the
previous chapter) and boldfaced keywords refer to keywords in the
WRL language.
Table 3.1: Mapping WRL conceptual syntax to logical
expression syntax.
| WRL Conceptual Syntax |
WRL Logical Expression Syntax |
| τ(ontology) |
τ(ontology_element1)
... τ(ontology_elementn) |
| τ(concept id superconcept attribute1 ...
attributen) |
τ(superconcept, id) τ(attribute1,
id) ... τ(attributen,
id) |
| τ(subConceptOf idlist, X) |
X subConceptOf idlist. |
| τ(attribute_id
attributefeature
impliesType cardinality range_idlist, X) |
?x memberOf X and ?x[attribute_id hasValue ?y] implies ?y
memberOf range_idlist.
τ(cardinality, X,
attribute_id)
τ(attributefeature,
X, attribute_id) |
| τ(attribute_id
attributefeature
ofType cardinality range_idlist, X) |
!- ?x memberOf X and
?x[attribute_id
hasValue ?y] and naf ?y memberOf range_idlist.
τ(cardinality, X,
attribute_id)
τ(attributefeature,
X, attribute_id) |
| τ(transitive, X, Y) |
?x memberOf X and ?y memberOf
X and ?x[Y hasValue ?y] and
?y[Y hasValue ?z] implies ?x[Y
hasValue ?z]. |
| τ(symmetric, X, Y) |
?x memberOf X and ?y memberOf
X and ?x[Y hasValue ?y] implies
?y[Y hasValue ?x]. |
| τ(reflexive, X, Y) |
?x memberOf X implies ?x[Y
hasValue ?x]. |
| τ(inverseOf(att_id), X, Y) |
?x memberOf X and ?x[Y
hasValue ?y] implies ?y[att_id hasValue ?x].
?y memberOf X and ?x[att_id hasValue ?y] implies
?y[Y hasValue ?x]. |
| τ((n), X,
Y) |
τ((n n), X,
Y) |
| τ((n m), X,
Y) |
τ((n *), X,
Y)
τ((0 m), X, Y) |
| τ((n *), X,
Y) |
pnew(?x) :- ?x memberOf
X and ?x[Y hasValue
?y1, ...,Y hasValue
?yn] and ?y1 != ?y2 and
?y1 != ?y3 and ... and
?yn-1 != ?yn.
!- ?x memberOf x and naf
pnew(?x). |
| τ((0 m), X,
Y) |
!- ?x memberOf X and ?x[Y
hasValue ?y1, ...,Y hasValue
?ym+1] and ?y1 != ?y2 and
?y1 != ?y3 and ... and ?ym
!= ?ym+1. |
| τ(relation id/arity superrelation) |
τ(superrelation, id, arity) |
| τ(subRelationOf id, X, Y) |
X(?x1,...,?xY)
implies id(?x1,...,?xY). |
| τ(instance id memberof attributevalue1
... attributevaluen) |
τ(memberof,
id) τ(attributevalue1,
id) τ(attributevaluen,
id) |
| τ(memberOf idlist, X) |
X memberOf idlist. |
| τ(att_id
hasValue valuelist, X) |
X[att_id
hasValue valuelist]. |
| τ(axiom id
log_expr) |
log_expr |
As an example, we translate the following WRL ontology:
namespace {_"http://www.example.org/ontologies/example#",
dc _"http://purl.org/dc/elements/1.1#",
foaf _"http://xmlns.com/foaf/0.1/",
xsd _"http://www.w3.org/2001/XMLSchema#",
wrl _"http://www.wsml.org/wsml/wrl-syntax#",
loc _"http://www.wsmo.org/ontologies/location#"}
ontology Family
nfp
dc#title hasValue "WRL example ontology"
endnfp
concept Human subConceptOf { Primate, LegalAgent }
nonFunctionalProperties
dc#description hasValue "concept of a human being"
endNonFunctionalProperties
hasName ofType foaf#name
relation ageOfHuman/2 (ofType Human, ofType _integer)
nonFunctionalProperties
dc#relation hasValue FunctionalDependencyAge
endNonFunctionalProperties
axiom FunctionalDependencyAge
definedBy
!- ageOfHuman(?x,?y1) and
ageOfHuman(?x,?y2) and wrl#numericInequal(?y1,?y2).
To the following logical expressions:
_"http://www.example.org/ontologies/example#Human"[_"http://www.example.org/ontologies/example#hasName" ofType
_"http://xmlns.com/foaf/0.1/name"].
_"http://www.example.org/ontologies/example#Human" subConceptOf
{ _"http://www.example.org/ontologies/example#Primate",
_"http://www.example.org/ontologies/example#LegalAgent" }.
!- naf ?x memberOf_"http://www.example.org/ontologies/example#Human" and
_"http://www.example.org/ontologies/example#ageOfHuman"(?x,?y).
!- naf ?y memberOf _integer and _"http://www.example.org/ontologies/example#ageOfHuman"(?x,?y).
!- _"http://www.example.org/ontologies/example#ageOfHuman"(?x,?y1) and
_"http://www.example.org/ontologies/example#ageOfHuman"(?x,?y2) and _"http://www.wsml.org/wsml/wrl-syntax#numericInequal"(?y1,?y2).
In order to make the definition of the WRL semantics more
straightforward, we define a number of preprocessing steps to be
applied to the WRL logical expressions. We identify the following
preprocessing steps in order to obtain a suitable set of logical
expressions which can be readily mapped to a logical
formalism:
- Replacing idlists with multiple statements
- Statements involving argument lists of the form
A op
{v1,...,vn}, with op
∈ {hasValue, ofType, impliesType},
are replaced by multiple statements in the following way:
A op v1, ...,
A op vn.
Statements involving argument lists of the form A
is-a {c1,...,cn},
with is-a ∈ {memberOf, subConceptOf},
are replaced by a conjunction of statements in the following
way: A op c1
and ... and A op
cn.
- Reducing composed molecules to single molecules
-
Composed molecules are split into singular molecules in two
steps:
- Molecules of the form a is-a
b[c1 op1
d1,..., cn
opn dn], with
is-a ∈ {memberOf, subConceptOf}
and opi ∈ {hasValue,
ofType, impliesType} are transformed to:
a is-a b and
a[c1 opn
d1,..., cn
opn dn]
- Then, attributes of the form
a[c1 op1
d1,..., cn
opn dn], with
opi ∈ {hasValue,
ofType, impliesType}, are translated to:
a[c1 op1
d1] and ... and
a[cn opn
dn]
- Rewriting data term shortcuts
- The shortcuts for writing strings, integers and decimals
are rewritten to their full form:
"string" := _string("string") (unless
"string" already occurs in the _string datatype
wrapper)
integer := _integer("integer")
decimal := _decimal("decimal")
- Rewrite data terms to predicates
- Data terms occur as functions in WRL. However, Datalog does
not allow the use of function symbols. Thus, we rewrite the
datatype wrappers to built-in predicates as follows:
Each datatype wrapper with arity n has a corresponding
built-in predicate with the same name as the datatype wrapper
(cf. Appendix A). This built-in
predicate always has an arity n+1. Each occurrence of
a datatype wrapper δ in a statement φ is replaced
with a new variable ?x and the datatype predicate
corresponding to the wrapper δ is conjoined with the
resulting statement φ': (φ' and
δ(X1,...,X1,?x)).
- Rewrite built-in functions to predicates
- Built-in functions are replaced with predicates similar to
datatype wrappers. Each of the built-in predicates
corresponding to built-in functions mentioned in Appendix A contains one argument which is
the result. The occurrence of the function is replaced with a
variable and the statement is replaced with the conjunction of
that statement and the built-in predicate.
- Unfolding sQNames to full IRIs
- Finally, all sQNames in the syntax are replaced with full
IRIs, according to the rules defined in Section 2.2.
The resulting set of logical expressions does not contain any
syntactical shortcuts and can be used directly for the definition
of the semantics of the respective WRL variants.
In order to define the semantics of WRL-Core, we first define
the notion of a WRL-Core knowledge base in Definition 3.1.
Definition 3.1. We define a WRL-Core knowledge base
KB as a collection of formulas written in the WRL
logical expression language which are the result of application
of the translation function τ of Table 3.1 and the
preprocessing steps defined in Section 3.2 to a WRL-Core
ontology.
We define the semantics of WRL-Core through a mapping to
Datalog (under minimal Herbrand model semantics; 'not' stands
for stratified default negation) using the mapping function π.
Table 3.2 presents the WRL-Core semantics through a direct
mapping to Datalog. In the table, id#
can be any identifier, dt# is a datatype identifier,
X# can be either a variable or an identifier. Each
occurrence of x and each occurrence of y represents a newly
introduced variable.
Table 3.2: WRL-Core Semantics
| WRL |
Datalog |
| π(head impliedBy body.) |
π(head) ← π(body) |
| π(head implies body.) |
π(body) ← π(head) |
| π(head equivalent body.) |
π(head) ← π(body)
π(body) ← π(head) |
| π(lexpr or rexpr) |
π(lexpr) ∨ π(rexpr) |
| π(lexpr and rexpr) |
π(lexpr) ∧ π(rexpr) |
| π(X1 memberOf id2) |
id2(X1) |
| π(id1 subConceptOf id2) |
id2(x) ← id1(x) |
| π(X1[id2 hasValue
X2]) |
id2(X1,X2) |
| π(id1[id2 impliesType
id3]) |
id3(y) ← id1(x) ∧
id2(x,y) |
| π(id1[id2 ofType
dt]) |
← id1(x) ∧
id2(x,y) ∧ not dt(y) |
|
π(p(X1,...,Xn)) |
p(X1,...,Xn) |
Each occurrence of an unnumbered anonymous ID is replaced with
a new globally unique identifier. All occurrences of the same
numbered anonymous ID in one formula are replaced with the same
new globally unique identifier.
Application of the usual Lloyd-Topor transformations [Lloyd and Topor, 1984] yields actual Datalog
rules. In particular, the following transformations are
iteratively applied until no transformation is applicable:
- Rules of the form A1 ∧ ... ∧
An ← B are split in n different
rules:
- Rules of the form (A1 ← A2)
← B are transformed to:
- Rules of the form A ← B1 ∨ ... ∨
Bn are split into n different rules:
Definition 3.2 (Satisfiability in WRL-Core) We say a
WRL-Core knowledge base KB is satisfiable iff
π(KBA) has a minimal Herbrand
model.
Note that the only case in which a WRL-Core is not
satisfiable is when a value constraint corresponding to a
datatype is violated.
Definition 3.3 (Entailment in WRL-Core) We say a
satisfiable WRL-Core knowledge base KB entails a
WRL-Core ground formula F iff MKB
|= π(F), where MKB is the
minimal Herbrand
model of KB.
In order to define the semantics of WRL-Flight, we first
define the notion of a WRL-Flight knowledge base in Definition
3.4.
Definition 3.4. We define a WRL-Flight knowledge base
KB as a collection of formulae written in the WRL
logical expression language which are the result of application
of the translation function τ of Table 3.1 and the
preprocessing steps defined in Section 3.2 to a WRL-Flight
ontology.
We define the semantics of WRL-Flight through a mapping to the
Datalog fragment of F-Logic [Kifer et al.,
1995] (extended with inequality and locally stratified default
negation in the body of the rule) using the mapping function
π.
In our translation to F-Logic we use four kinds of
molecule (A,B,C denote terms), which we can define
intuitively as:
- A:B denotes that A is a member of
class B.
- A::B denotes that A is a subclass of
B.
- A[B ->> C] denotes that object
A has the value C for attribute B.
- A[B =>> C] denotes that class
A has an attribute B with range C.
Concepts, instances and attributes are interpreted as objects
in F-Logic. We need a number of auxiliary rules in order to
ensure the correct interpretation of the translated F-Logic
statements (with not denoting default negation under
the Perfect Model Semantics [Przymusinski, 1989] and a rule
with an empty head denoting an integrity constraint):
The semantics of method signatures is captured through an
integrity constraint on method signatures:
← x[y =>> z] ∧ w:x ∧ w[y ->> v] ∧ not
v:z
The semantics of 'impliesType' is captured through an
auxiliary predicate:
v:z ← _impliestype(x,y,z) ∧ w:x ∧ w[y ->>
v]
Now follows the semantics of WRL-Flight in Table 3.3. In the
table, X# stands for either a variable or an identifier;
'=' is the unification operator and '!=' is the built-in
inequality symbol. The symbol '←LT' stands for
Lloyd-Topor implication, which is eliminated from the formulae
as indicated below Table 3.3.
Table 3.3: Semantics of WRL-Flight
| WRL |
F-Logic |
| π(!- body.) |
← π(body) |
| π(head :- body.) |
π(head) ← π(body) |
| π(lexpr impliedBy rexpr.) |
π(lexpr) ←LT π(rexpr) |
| π(lexpr implies rexpr.) |
π(rexpr) ←LT π(lexpr) |
| π(lexpr equivalent rexpr.) |
(π(rexpr) ←LT
π(lexpr)) ∧ (π(lexpr)
←LT π(rexpr)) |
| π(lexpr or rexpr) |
π(lexpr) ∨ π(rexpr) |
| π(lexpr and rexpr) |
π(lexpr) ∧ π(rexpr) |
| π(naf expr) |
not π(expr) |
| π(X1 memberOf X2) |
X1:X2 |
| π(X1 subConceptOf X2) |
X1::X2 |
| π(X1[X2 hasValue
X3]) |
X1[X2 ->> X3] |
| π(X1[X2 ofType X3]) |
X1[X2 =>> X3] |
| π(X1[X2 impliesType
X3]) |
_impliestype(X1,X2,X3) |
|
π(p(X1,...,Xn)) |
p(X1,...,Xn) |
| π(X1 = X2) |
X1 = X2 |
| π(X1 !=
X2) |
X1 != X2 |
Rules with empty heads are integrity constraints. The first
row in the table produces integrity constraints from some WRL
logical expressions. Furthermore, there exists the integrity
constraint which axiomatizes the semantics of
ofType, which was mentioned above the table. We define C as the set of all
integrity constraints.
Each occurrence of an unnumbered anonymous ID is replaced with
a new globally unique identifier. All occurrences of the same
numbered anonymous ID in one formula are replaced with the same
new globally unique identifier.
Application of the usual Lloyd-Topor transformations [Lloyd and Topor, 1984] rules in the
function-free Horn fragment of F-Logic. In particular, the
following transformations are
iteratively applied until no transformation is applicable:
- Rules of the form A1 ∧ ... ∧
An ← B are split into n different
rules:
- Rules of the form A1 ←LT A2
← B are transformed to:
- Rules of the form A ← B1 ∧ (F ∨ G) ∧
Bn are split into two different rules:
- A ← B1 ∧ F ∧ B2
- A ← B1 ∧ G ∧ B2
- Rules of the form A ← B1 ∧ not (F ∧ G) ∧
Bn are split into two different rules:
- A ← B1 ∧ not F ∧ B2
- A ← B1 ∧ not G ∧ B2
- Rules of the form A ← B1 ∧ not (F ∨ G) ∧
Bn are transformed to:
- A ← B1 ∧ not F ∧ not G ∧ B2
We base the semantics of WRL-Flight on the perfect model
semantics ([Przymusinski, 1989]) of F-Logic ([Kifer et al.,
1995, Appendix A]), which
defines the
semantics for locally stratified logic programs. Przymusinski
shows that every stratified program has a unique perfect model.
WRL-Flight only allows locally stratified negation.
Definition 3.5 (Satisfiability in WRL-Flight) Let
KB be a WRL-Flight knowledge base which includes a
set of integrity constraints C. KB is satisfiable iff
π(KB\{C}) has a perfect model MKB
which does not violate any of the constraints in C. We
say an integrity constraint is violated if some ground
instantiation of the body of the constraint is true in the model
MKB.
We define the semantics of WRL-Flight with respect to the
entailment of ground formulae. We say a formula is ground if it
does not contain any variables.
Definition 3.6 (Entailment in WRL-Flight) We say a
satisfiable WRL-Flight knowledge base KB entails a
WRL-Flight ground formula F iff MKB
|= π(F), where MKB is the perfect
model of KB.
The semantics of WRL-Full is defined in the same way as
WRL-Flight. The only difference is that the semantics of WRL-Full
is not defined through a mapping to Datalog, but through a
mapping to full Logic Programming (i.e., with function symbols
and allowing unsafe rules) with inequality and unstratified
negation.
The only difference is that the meta-variables
X# can also stand for a constructed term.
In order to define the semantics of WRL-Full, we first define
the notion of a WRL-Full knowledge base in Definition 3.7.
Definition 3.7. We define a WRL-Full knowledge base
KB as a collection of formulae written in the WRL
logical expression language which are the result of application
of the translation function τ of Table 3.1 and the
preprocessing steps defined in Section 3.2 to a WRL-Full
ontology.
We define the semantics of WRL-Full through a mapping to the
Horn fragment of F-Logic [Kifer et al.,
1995] (extended with inequality and Well-Founded
default negation [van Gelder et al., 1991] in the body of the rule) using the mapping
function π.
Concepts, instances and attributes are interpreted as objects
in F-Logic. We need a number of auxiliary rules in order to
ensure the correct interpretation of the translated F-Logic
statements (with not denoting Well-Founded default negation and a rule
with an empty head denoting an integrity constraint):
The semantics of method signatures is captured through an
integrity constraint on method signatures:
← x[y =>> z] ∧ w:x ∧ w[y ->> v] ∧ not
v:z
The semantics of 'impliesType' is captured through an
auxiliary predicate:
v:z ← _impliestype(x,y,z) ∧ w:x ∧ w[y ->>
v]
Now follows the semantics of WRL-Full in Table 3.4. In the
table, X# stands for either a variable, an identifier,
or a constructed term; '=' is the unification operator and '!='
is the built-in inequality symbol.
Table 3.4: Semantics of WRL-Full
| WRL |
F-Logic |
| π(!- body.) |
← π(body) |
| π(head :- body.) |
π(head) ← π(body) |
| π(lexpr impliedBy rexpr.) |
π(lexpr) ←LT π(rexpr) |
| π(lexpr implies rexpr.) |
π(rexpr) ←LT π(lexpr) |
| π(lexpr equivalent rexpr.) |
(π(rexpr) ←LT
π(lexpr)) ∧ (π(lexpr)
←LT π(rexpr)) |
| π(lexpr or rexpr) |
π(lexpr) ∨ π(rexpr) |
| π(lexpr and rexpr) |
π(lexpr) ∧ π(rexpr) |
| π(exists X1,...,Xn (expr)) |
∃ X1,...,Xn (π(expr)) |
| π(forall X1,...,Xn (expr)) |
∀ X1,...,Xn (π(expr)) |
| π(naf expr) |
not π(expr) |
| π(X1 memberOf X2) |
X1:X2 |
| π(X1 subConceptOf X2) |
X1::X2 |
| π(X1[X2 hasValue
X3]) |
X1[X2 ->> X3] |
| π(X1[X2 ofType X3]) |
X1[X2 =>> X3] |
| π(X1[X2 impliesType
X3]) |
_impliestype(X1,X2,X3) |
|
π(p(X1,...,Xn)) |
p(X1,...,Xn) |
| π(X1 = X2) |
X1 = X2 |
| π(X1 !=
X2) |
X1 != X2 |
Rules with empty heads are integrity constraints (in the
database sense). The first row in the table produces integrity
constraints from the WRL logical expressions. Furthermore, there
exists the integrity constraint which axiomatizes the semantics
of ofType. We define C as the set of all
integrity constraints.
Each occurrence of an unnumbered anonymous ID is replaced with
a new globally unique identifier. All occurrences of the same
numbered anonymous ID in one formula are replaced with the same
new globally unique identifier.
Application of the usual Lloyd-Topor transformations [Lloyd and Topor, 1984] yields actual
rules in the Horn fragment of F-Logic (note that the
syntactic restrictions on the WRL-Full
logical expression syntax prevent the use of disjunction in the
head of any rule). In particular, the following transformations
are iteratively applied until no transformation is
applicable:
- Rules of the form A1 ∧ ... ∧
An ← B are split into n different
rules:
- Rules of the form A1 ←LT
A2 ← B are transformed to:
- Rules of the form A ←
B1 ∧ (G
←LT F) ∧ B2 are transformed to
the two rules:
- A ← B1 ∧ not F ∧ B2
- A ← B1 ∧ G ∧ B2
- Rules of the form A ←
B1 ∧ ∃ X1,...,Xn (G) ∧ B2 are transformed to:
- Rules of the form A ←
B1 ∧ ∀ X1,...,Xn (G) ∧ B2 are transformed to:
- A ← B1 ∧ not ∃ X1,...,Xn
(not (G)) ∧ B2
- Rules of the form A ←
B1 ∧ not ∃ X1,...,Xn (G) ∧
B2 are transformed to two rules (with p a
newly introduced predicate symbol and Y1,...Yk free
variables occurring in ∃ X1,...,Xn (G)):
- A ← B1 ∧ not p(Y1,...,Yk) ∧ B2
- p(Y1,...,Yk) ← G
- Rules of the form A ←
B1 ∧ not ∀ X1,...,Xn (G) ∧
B2 are transformed to:
- A ← B1 ∧ ∃ X1,...,Xn (not (G)) ∧ B2
- Rules of the form A ←
B1 ∧ not ∃ X1,...,Xn (G) ∧
B2 are transformed to:
- A ← B1 ∧ ∀ X1,...,Xn (not (G)) ∧ B2
- Rules of the form A ← B1 ∧ (F ∨ G) ∧
Bn are split into two different rules:
- A ← B1 ∧ F ∧ B2
- A ← B1 ∧ G ∧ B2
- Rules of the form A ← B1 ∧ not (F ∧ G) ∧
Bn are split into two different rules:
- A ← B1 ∧ not F ∧ B2
- A ← B1 ∧ not G ∧ B2
- Rules of the form A ← B1 ∧ not (F ∨ G) ∧
Bn are transformed to:
- A ← B1 ∧ not F ∧ not G ∧ B2
We base the semantics of WRL-Full on the Well-Founded
Semantics [van Gelder et al., 1991],
applied to F-Logic according to [Yang & Kifer,
2002].
Definition 3.8 (Satisfiability in WRL-Full) Let
KB be a WRL-Full knowledge base which includes a set
of constraints C. KB is satisfiable iff
π(KB\C) has well-founded partial model
MKB which does
not violate any of the constraints in C. We say an
integrity constraint is violated if the body of some ground
instantiation of the constraint is true in the model
MKB.
We define the semantics of WRL-Full with respect to the
entailment of ground formulae. We say a formula is ground if it
does not contain any variables.
Definition 3.9 (Entailment in WRL-Full) We say a
satisfiable WRL-Full knowledge base KB entails a
WRL-Full ground formula F iff MKB |=
π(F), where MKB is the well-founded
model of KB.
WRL uses RuleML version
0.89 as the main XML serialization
language for the logical expression part. We specify the
correspondence between the WRL human-readable syntax and the XML
serialization below.
The XML syntax for the conceptual part of WRL is based on the
human-readable syntax for WRL presented in Chapter 2. The XML syntax for WRL
captures all WRL variants. The user can specify the variant of a
WRL/XML document through the 'variant' attribute of the
<wrl> root element. The language for logical expressions is
based on RuleML version 0.89.
Table 4.1 provides the transformations of the conceptual
syntax, Table 4.2 presents the transformation of logical
expressions, while in Table 4.3 a simple mapping example is
given. There exists an XML Schema for the WRL conceptual syntax.
The basic namespace for WRL/XML is
http://www.wsml.org/wsml/wrl-syntax#. This is the namespace for
all elements in WRL.
Before beginning the transformation process the following
pre-processing steps need to be performed:
- sQNames need to be resolved to full IRIs, i.e., there will
not be any namespace definitions in the XML syntax.
- in the conceptual syntax universal truth, universal
falsehood, unnumbered anonymous IDs, unification, and
inequality are resolved to:
http://www.wsml.org/wsml/wrl-syntax#true,
http://www.wsml.org/wsml/wrl-syntax#false,
http://www.wsml.org/wsml/wrl-syntax#anonymousID,
http://www.wsml.org/wsml/wrl-syntax#unification, and
http://www.wsml.org/wsml/wrl-syntax#inequality,
respectively. Numbered anonymous IDs are resolved as such: _#1
to http://www.wsml.org/wsml/wrl-syntax#anonymousID1, _#2
to http://www.wsml.org/wsml/wrl-syntax#anonymousID2,
..., _#n to
http://www.wsml.org/wsml/wrl-syntax#anonymousIDn.
- Built-in functions and predicates are resolved to the
corresponding full IRIs, as defined in Appendix A.
- Datatype identifiers are resolved to full IRIs by replacing
the leading underscore '_' with the WRL namespace. For example,
the datatype identifier '_date' is resolved to
http://www.wsml.org/wsml/wrl-syntax#integer.
- Inside logical expressions, compound molecules are split into
a conjunction of simple molecules.
T(...) denotes a function which is recursively called to
transform the first parameter (a fragment of WRL syntax) to the
XML syntax.
In Table 4.1, all WRL keywords are marked bold. A,B,C
stand for identifiers, D stands for a datatype identifier,
DVi stands for an integer value,
DVd stands for a decimal, and
DVs stands for a string data value.
k,m,n are integer numbers. Productions in the grammar are
underlined and linked to the production rules in Appendix B. Note
that in the table we use the familiar sQName macro mechanism (see
also Section 2.1.2) to abbreviate the IRIs of resources.
Table 4.1: Mapping the WRL conceptual syntax to the WRL/XML
syntax
| WRL syntax |
XML Tree |
Remarks |
T (
wrlVariant A
ontology1
...
ontologyn
) |
<wrl
xmlns="http://www.wsml.org/wsml/wrl-syntax#"
variant="A">
T(ontology1)
...
T(ontologyn)
</wrl> |
T (
namespace { N,
P1 N1,
...,
Pn Nn } ) |
|
Because sQNames were resolved to full IRIs during
pre-processing, there is no translation to XML necessary
for namespace definitions |
T (
ontology A
header1
...
headern
ontology_element1
...
ontology_elementn
) |
<ontology name="A">
T(header1)
...
T(headern)
T(ontology_element1)
...
T(ontology_elementn)
</ontology> |
An ontology_element represents all possible content of
an ontology definition, i.e., concepts, relations,
instances, ... |
T (
concept C
subConceptOf
{B1,...,Bn}
nfp
attribute1
...
attributen
) |
<concept name="C">
T(nfp)
<superConcept>B1</
superConcept>
...
<superConcept>Bn</
superConcept>
T(attribute1)
...
T(attributen)
</concept> |
|
T (
A attributefeature1
... attributefeaturen
ofType cardinality C
nfp
) |
<attribute name="A"
type="constraining">
<range>C</range>
T(attributefeature1)
...
T(attributefeaturen)
T(cardinality)
T(nfp)
</attribute> |
|
T (
A attributefeature1
... attributefeaturen
impliesType cardinality C
nfp
) |
<attribute name="A"
type="inferring">
<range>C</range>
T(attributefeature1)
...
T(attributefeaturen)
T(cardinality)
T(nfp)
</attribute> |
|
T (
transitive
) |
<transitive/> |
|
T (
symmetric
) |
<symmetric/> |
|
T (
reflexive
) |
<reflexive/> |
|
T (
inverseOf(A)
) |
<inverseOf>A</
inverseOf> |
|
T (
(minCard maxCard)
) |
<minCardinality>minCard</
minCardinality>
<maxCardinality>maxCard</
maxCardinality> |
|
T (
(card)
) |
<cardinality>card</
cardinality> |
|
T (
instance A
memberOf
C1,...,Cn
nfp
attributevalue1
...
attributevaluen
) |
<instance name="A">
<memberOf>C1</
memberOf>
...
<memberOf>Cn</
memberOf>
T(nfp)
T(attributevalue1)
...
T(attributevaluen)
</instance> |
|
T (
A hasValue {value1, ..., valuen}
) |
<attributeValue
name="A">
T(value1
...
T(valuen
</attributeValue> |
A value has always a datatype. There are four built-in
datatypes: IRI, string, integer, decimal. In addition any
arbitrary datatype can be defined by use of datatype
wrappers. The next four transformations show how to handle
these five cases. |
T (
A
) |
<value type="wrl#iri">
A
</value> |
|
T (
DVs
) |
<value type="wrl#string">
DVs
</value> |
|
T (
DVi
) |
<value type="wrl#integer">
DVi
</value> |
|
T (
DVd
) |
<value type="wrl#decimal">
DVd
</value> |
|
T (
DV
) |
<value
type="http://www.example.org/datatype#any">
<argument>DV.arg1</
argument>
...
<argument>DV.argn</
argument>
</value> |
A datatype wrapper is defined by the type and a number
of arguments that define the value, e.g., _date(2005,12,12)
for December 12, 2005 (and thus the value of type date has
three arguments). In case there is just on argument, the
element <argument> is optional and the value can be
given as above for IRI, string, integer, decimal. |
T (
relation A / n (paramtype1,...,
paramtypem)
subRelationOf
{C1,...,Ck}
nfp
) |
<relation name="A"
arity="n">
<parameters>
T(paramtype1>)
...
T(paramtypen)
</parameters>
<superRelation>C1</
superRelation>
...
<superRelation>Ck</
superRelation>
T(nfp)
</relation> |
Note that the parameters of a relation are ordered and
thus the order of the parameters elements in the XML
representation important. |
T (
ofType
{C1,...,Cn}
) |
<parameter
type="constraining">
<range>C1</
range>
...
<range>Cn</
range>
</parameter> |
|
T (
impliesType
{C1,...,Cn}
) |
<parameter
type="inferring">
<range>C1</
range>
...
<range>Cn</
range>
</parameter> |
|
T (
relationInstance A B
(value1,...,
valuen)
nfp
) |
<relationInstance
name="A">
<memberOf>B</memberOf>
T(value1)
...
T(valuen)
T(nfp)
</relationInstance> |
|
T (
{value1,...,
valuen} ) |
<parameterValue>
T(value1)
...
T(valuen)
</parameterValue> |
Note that the parameters of a relationInstance are
ordered and thus the order of the value elements is
important. |
T (
axiom A
axiomdefinition
) |
<axiom name="A">
T(axiomdefinition)
</axiom> |
|
T (
nfp
definedBy
log_expr
) |
T(nfp)
T(log_expr) |
The mapping of logical expressions is defined in Table
4.2. |
T (
nonFunctionalProperties
attributevalue1
...
attributevaluen
endNonFunctionalProperties
) |
<nonFunctionalProperties>
T(attributevalue1)
...
T(attributevaluen)
</nonFunctionalProperties> |
|
T (
nfp
attributevalue1
...
attributevaluen
endnfp
) |
<nonFunctionalProperties>
T(attributevalue1)
...
T(attributevaluen)
</nonFunctionalProperties> |
|
T (
importsOntology {
A1,...,An}
) |
<importsOntology>A1</
importsOntology>
...
<importsOntology>An</
importsOntology> |
|
The logical expression syntax is explained in Table 4.2. The
namespace for these elements is http://www.ruleml.org/0.89/xsd.
In the table, A stands for identifiers and
T1,...,Tn stand for terms. V
stands for a variable. We make a distinction between the mapping
function T, which maps logical expressions, and the mapping function
Tt, which maps terms. Note that all IRIs are stripped
from their delimiters.
We extend the <Implies> element in the RuleML syntax with
an attribute "kind", which indicates the kind of
implication. Allowed values are "fo", which stands for
First-Order (classical) implication and "lp", which stands for
Logic Programming implication. <Implies kind="fo">
corresponds to the WRL keyword implies;
<Implies kind="lp"> corresponds to the
symbol :-. We furthermore add the element
<Constraint>, which denotes an integrity constraint. Any
formula allowed in the body of a rule may be nested inside.
In order to axiomatize the proper behavior of impliesType
attribute signature definitions, we add the following rule to the
knowledge base before translating to RuleML:
?v memberOf ?z impliedBy
wrl#impliesType(?x,?y,?z) and ?w
memberOf ?x and ?w[?y hasValue ?v].
Table 4.2: Mapping the WRL
logical expression syntax to RuleML
| WRL syntax |
RuleML |
Remarks |
Tt (
A(term1, ...,
termn)
) |
<Cterm>
<Ctor>A</Ctor>
Tt (term1)
...
Tt (termn)
</Cterm> |
|
Tt (
A
) |
<Ind>A</Ind> |
Constant |
Tt (
?V
) |
<Var>V</Var> |
Variable |
T (
A(term1, ...,
termn)
) |
<Atom>
<Rel>A</Rel>
Tt(term1)
...
Tt(termn)
</Atom> |
|
T (
T1[T2 ofType
{T3, ..., Tn}]
) |
<Signature>
<oid>Tt(T1)</oid>
<slot>
Tt(T2)
<Set>
Tt(T3)
...
Tt(Tn)
</Set>
</slot>
</Signature> |
Attribute signature (ofType) |
T (
T1[T2 ofType
T3]
) |
<Signature>
<oid>Tt(T1)</oid>
<slot>
Tt(T2)
Tt(T3)
</slot>
</Signature> |
Attribute signature (ofType); set |
T (
T1[T2 impliesType
T3]
) |
<Atom>
<Rel>http://www.wsmo.org/wsml/wrl-syntax#impliesType</Rel>
Tt(term1)
Tt(term2)
Tt(term3)
</Atom> |
Attribute signature (impliesType) |
T (
T1[T2 impliesType
{T3, ..., Tn}]
) |
<And>
<Atom>
<Rel>http://www.wsmo.org/wsml/wrl-syntax#impliesType</Rel>
Tt(term1)
Tt(term2)
Tt(term3)
</Atom>
...
<Atom>
<Rel>http://www.wsmo.org/wsml/wrl-syntax#impliesType</Rel>
Tt(term1)
Tt(term2)
Tt(termn)
</Atom>
</And> |
Attribute signature (impliesType); set |
T (
T1[T2 hasValue
T3]
) |
<Atom>
<oid>Tt(T1)</oid>
<slot>Tt(T2) Tt(T3)</slot>
</Atom> |
Attribute value (hasValue) |
T (
T1[T2 hasValue
{T3, ..., Tn}]
) |
<Atom>
<oid>Tt(T1)</oid>
<slot>Tt(T2)
<Set>
Tt(T3)
...
Tt(Tn)
</Set>
</slot>
</Atom> |
Attribute value (hasValue), sets |
T (
T1 memberOf T2
) |
<InstanceOf>
Tt(T1)
Tt(T2)
</InstanceOf> |
Concept membership |
T (
T1 memberOf {T2,...,Tn}
) |
<InstanceOf>
Tt(T1)
<Set>
Tt(T2)
...
Tt(Tn)
</Set>
</InstanceOf> |
Concept membership (set) |
T (
T1 subConceptOf T2
) |
<SubclassOf>
Tt(T1)
Tt(T2)
</SubclassOf> |
Subconcept relationship |
T (
T1 subConceptOf {T2,...,Tn}
) |
<SubclassOf>
Tt(T1)
<Set>
Tt(T2)
...
Tt(Tn)
</Set>
</SubclassOf> |
Subconcept relationship (set) |
T (
expr1
and expr2
) |
<And>
T(expr1)
T(expr2)
</And> |
Conjunction |
T (
expr1
or expr2
) |
<Or>
T(expr1)
T(expr2)
</Or> |
Disjunction (only allowed in the
body of a rule) |
T (
naf expr
) |
<Naf>
T(expr)
</Naf> |
|
T (
expr1
implies expr2
) |
<Implies kind="fo">
<body>T(expr1)</body>
<head>T(expr2)</head>
</Implies> |
|
T (
expr1
impliedBy expr2
) |
<Implies kind="fo">
<head>T(expr1)</head>
<body>T(expr2)</body>
</Implies> |
|
T (
expr1
equivalent expr2
) |
<Equivalent>
<torso>T(expr1)</torso>
<torso>T(expr2)</torso>
</Equivalent> |
|
T (
forall ?v1, ...,
?vn ( expr
)
) |
<Forall>
<Var>v1</Var>
...
<Var>vn</Var>
T(expr)
</Forall> |
|
T (
exists ?v1, ...,
?vn ( expr
)
) |
<Exists>
<Var>v1</Var>
...
<Var>vn</Var>
T(expr)
</Exists> |
|
T (
!- expr
) |
<Constraint>
T(expr)
</Constraint> |
|
T (
expr1
:- expr2
) |
<Implies kind="lp">
<head>T(expr1)</head>
<body>T(expr2)</body>
</Implies> |
|
Table 4.3 provides a simple translation example.
Table 4.3: A Mapping Example
| WRL syntax |
XML Tree |
wrlVariant
_"http://www.wsml.org/wsml/wrl-syntax/wrl-flight"
namespace {_"http://www.example.org/ex1#",
dc _"http://purl.org/dc/elements/1.1#",
wrl _"http://www.wsml.org/wsml/wrl-syntax#",
ex _"http://www.example.org/ex2#"}
ontology _"http://www.example.org/ex1"
nonFunctionalProperties
dc#title hasValue "WRL to RDF"
dc#date hasValue _date(2005,12,12)
endNonFunctionalProperties
importsOntology _"http://www.example.net/ex2"
concept Woman subConceptOf
{ex#Human, ex#LivingBeing}
name ofType _string
ancestorOf transitive impliesType ex#Human
age ofType (1) _integer
axiom GenderConstraint
definedBy
!- ?x memberOf ex#Man and
?x memberOf Woman.
instance Mary memberOf Woman
name hasValue "Mary Jones"
age hasValue 23
relation childOf/2
(ofType ex#Human, impliesType ex#Parent)
|
<wrl xmlns="http://www.wsml.org/wsml/wrl-syntax#"
xmlns:ruleml="http://www.ruleml.org/0.89/xsd"
variant="http://www.wsml.org/wsml/wrl-syntax/wrl-flight">
<ontology name="http://www.example.org/ex1">
<nonFunctionalProperties>
<attributeValue name="http://purl.org/dc/elements/1.1#title">
<value type="http://www.wsml.org/wsml/wrl-syntax#string">
WRL to RDF
</value>
</attributeValue>
<attributeValue name="http://purl.org/dc/elements/1.1#date">
<value type="http://www.wsml.org/wsml/wrl-syntax#date">
<argument>2005</argument>
<argument>12</argument>
<argument>12</argument>
</value>
</attributeValue>
</nonFunctionalProperties>
<importsOntology>http://www.example.org/ex2</importsOntology>
<concept name="http://www.example.org/ex1#Woman">
<superConcept>
http://www.example.org/ex2#Human
<superConcept>
<superConcept>
http://www.example.org/ex2#LivingBeing
<superConcept>
<attribute name="http://www.example.org/ex1#name"
type="constraining">
<range>http://www.wsml.org/wsml/wrl-syntax#string</range>
</attribute>
<attribute name="http://www.example.org/ex1#ancestor"
type="inferring">
<range>http://www.example.org/ex2#Human</range>
<transitive/>
</attribute>
<attribute name="http://www.example.org/ex1#age" type="inferring">
<range>http://www.wsml.org/wsml/wrl-syntax#integer</range>
<minCardinality>1</minCardinality>
<maxCardinality>1</maxCardinality>
</attribute>
</concept>
<axiom name="http://www.example.org/ex1#GenderConstraint">
<definedBy>
<ruleml:Constraint>
<ruleml:And>
<ruleml:InstanceOf>
<ruleml:Var>x</ruleml:Var>
<ruleml:Con>http://www.example.org/ex1#Woman</ruleml:Con>
</ruleml:InstanceOf>
<ruleml:InstanceOf>
<ruleml:Var>x</ruleml:Var>
<ruleml:Con>http://www.example.org/ex2#Man</ruleml:Con>
</ruleml:InstanceOf>
</ruleml:And>
</ruleml:Constraint>
</definedBy>
</axiom>
<instance name="http://www.example.org/ex1#Mary">
<memberOf>http://www.example.org/ex1#Woman</memberOf>
<attributeValue name="http://www.example.org/ex1#name">
<value type="http://www.wsml.org/wsml/wrl-syntax#string">
Mary Jones
</value>
</attributeValue>
<attributeValue name="http://www.example.org/ex1#age">
<value type="http://www.wsml.org/wsml/wrl-syntax#integer">
23
</value>
</attributeValue>
</instance>
<relation name="http://www.example.org/ex1#childOf" arity="2">
<parameters>
<parameter type="constraining">
<range>http://www.example.org/ex2#Human</range>
</parameter>
<parameter type="inferring">
<range>http://www.example.org/ex2#Parent</range>
</parameter>
</parameters>
</relation>
</ontology>
</wrl>
|
In this chapter an RDF syntax for WRL is introduced. The
vocabulary used is an extension of the RDF Schema vocabulary
defined in [RDFS]. The extension consists of WRL language components, as
given in Table 5.1.
Table 5.1: WRL vocabulary extending RDFS for WRL triple
syntax
| WRL keyword |
RDF usage |
| wrl#variant |
Used as predicate to indicate the WRL variant
applied. |
| wrl#ontology |
Used to define a WRL ontology. |
| wrl#hasConcept |
Used to type a WRL concept and to bind it to an
ontology. |
| wrl#attribute |
Used to define a WRL attribute |
| wrl#ofType |
Used as predicate to define constraining
attributes and parameters. |
| wrl#hasAttribute |
Used as predicate to bind an attribute to a
concept. |
| wrl#transitiveAttribute |
Used to indicate the transitivity of an attribute. |
| wrl#symmetricAttribute |
Used to indicate the symmetry of an attribute. |
| wrl#reflexiveAttribute |
Used to indicate the reflexivity of an attribute. |
| wrl#inverseOf |
Used to indicate the inverse relationship of two
attributes. |
| wrl#minCardinality |
Used as predicate to defined the minimal
cardinality of an attribute. |
| wrl#maxCardinality |
Used as predicate to defined the maximal
cardinality of an attribute. |
| wrl#hasInstance |
Used to type an instance and to bind it to a
concept. |
| wrl#hasRelation |
Used to type a relation and to bind it to an
ontology. |
| wrl#arity |
Used to define the arity of a WRL relation. |
| wrl#param |
Used to type parameters of WRL relations. |
| wrl#subRelationOf |
Used as predicate to define sub-relations. |
| wrl#hasRelationInstance |
Used to type a relation instance and to bind it to an
ontology. |
| wrl#hasAxiom |
Used to type an axiom and to bind it to an
ontology. |
| wrl#importsOntology |
Used to define the import of an external ontology. |
| wrl#nfp |
Used to type non-functional properties. |
The remainder of this chapter presents a mapping between the
human-readable syntax of WRL and the RDF/WRL-triple syntax for
all WRL variants, where the knowledge is encoded in
<subject><predicate><object>-triples.
The big advantage of having such a syntax and reusing the
RDFS-vocabulary as far as possible, is the fact that there are
many existing RDF(S)-based tools available. These tools are
optimized to handle triples and are thus able to understand parts
of our specification and in a more general sense we can guarantee
inter-operability with those. In RDF all triples are global,
while in the conceptual syntax of WRL it is possible to append
specific entities to higher-level entities, e.g., concepts to
ontologies or attribute values to instances.
In order to maximize the reuse of RDFS vocabulary, several
Dublin Core properties are translated to corresponding RDFS
properties. Namely, dc#title is mapped to rdfs#label,
dc#description is mapped to rdfs#comment, and dc#relation is
mapped to rdfs#seeAlso.
Table 5.2 defines the mapping function T from WRL entities to
RDF triples. Logical expressions are not completely translated to
RDF. Instead, they are translated to the WRL/XML syntax and are
specified as literals of type rdf#XMLLiteral. The transformation
creates an RDF-graph based on above introduced RDF-triples. As
definitions, i.e., the top-level entity ontology are disjoint construct, their
graphs are not inter-related. In other words the transformation
defines one graph per definition. Note that in the table we use
the familiar sQName macro mechanism (see also Section 2.1.2) to
abbreviate IRIs. The prefix 'wrl' stands for
'http://www.wsml.org/wsml/wrl-syntax#', 'rdf' stands for
'http://www.w3.org/1999/02/22-rdf-syntax-ns#', 'rdfs' stands for
'http://www.w3.org/2000/01/rdf-schema#', 'dc' stands for
'http://purl.org/dc/elements/1.1#', and 'xsd' stands for
'http://www.w3.org/2001/XMLSchema#'.
In Table 5.2, A,B,C,Z stand for identifiers, D
stands for a datatype identifier, DVi stands
for an integer value, DVd stands for a decimal,
and DVs stands for a string data value, and
k,m,n are integer numbers.
The basic namespace for WRL/RDF is
http://www.wsml.org/wsml/wrl-syntax#. This is the namespace for
all elements in WRL.
Before beginning the transformation process the following
pre-processing steps need to be performed:
- If multiple top-level specifications (i.e., ontology) occur in the same document, the document
must be split into multiple WRL documents. Each WRL document is
then translated to a separate RDF graph.
- sQNames need to be resolved to full IRIs, i.e., there will
not be any namespace definitions in the RDF syntax.
- In the conceptual syntax universal truth, universal
falsehood and unnumbered anonymous IDs are resolved to:
http://www.wsml.org/wsml/wrl-syntax#true,
http://www.wsml.org/wsml/wrl-syntax#false, and
http://www.wsml.org/wsml/wrl-syntax#anonymousID,
respectively. Numbered anonymous IDs are resolved as such: _#1
to http://www.wsml.org/wsml/wrl-syntax#anonymousID1, _#2
to http://www.wsml.org/wsml/wrl-syntax#anonymousID2,
..., _#n to
http://www.wsml.org/wsml/wrl-syntax#anonymousIDn.
- Datatype identifiers are resolved to full IRIs by replacing
the leading underscore '_' with the WRL namespace. For example,
the datatype identifier '_date' is resolved to
http://www.wsml.org/wsml/wrl-syntax#integer.
A simple example of a full translation from the human-readable
syntax to the RDF triple notation is given in Table 5.3.
Table 5.2: Mapping to the WRL/RDF syntax
| WRL syntax |
RDF Triples |
Remarks |
T (
wrlVariant A
ontology1
...
ontologyn
) |
T(ontology1,
A)
...
T(ontologyn,
A) |
namespace { N,
P1 N1
...
Pn Nn } |
|
Because sQNames were resolved to full IRIs during
pre-processing, there is no translation to RDF necessary
for namespace definitions |
T (
ontology A
header1
...
headern
ontology_element1
...
ontology_elementn
, Z ) |
A rdf#type wrl#ontology
A wrl#variant Z
T(header1,
A)
...
T(headern,
A)
T(ontology_element1,
A)
...
T(ontology_elementn,
A) |
An ontology_element represents possible content of an
ontology definition, i.e., concepts, relations, instances,
... |
T (
concept A
subConceptOf
{B1,...,Bn}
nfp
attribute1
...
attributen
, Z ) |
Z wrl#hasConcept A
T(nfp, A)
A rdfs#subClassOf B1
...
A rdfs#subClassOf Bn
T(attribute1,
A)
...
T(attributen,
A) |
|
T (
A attributefeature1
... attributefeaturen
ofType cardinality C
nfp
, Z ) |
_:X wrl#attribute A
T(attributefeature1,
_:X)
...
T(attributefeaturen,
_:X)
_:X wrl#ofType C
T(cardinality,
_:X)
T(nfp, _:X)
Z wrl#hasAttribute _:X |
The blank identifier_:X denotes a helper node to bind
the attribute A to a defined owner: attributes are
locally defined! |
T (
A attributefeature1
... attributefeaturen
impliesType cardinality C
nfp
, Z ) |
_:X wrl#attribute A
T(attributefeature1,
_:X)
...
T(attributefeaturen,
_:X)
_:X rdfs#range C
T(cardinality,
_:X)
T(nfp, _:X)
Z wrl#hasAttribute _:X |
|
T (
transitive
, Z ) |
Z rdf#type wrl#transitiveAttribute |
|
T (
symmetric
, Z ) |
Z rdf#type wrl#symmetricAttribute |
|
T (
reflexive
, Z ) |
Z rdf#type wrl#reflexiveAttribute |
|
T (
inverseOf(A)
, Z ) |
Z wrl#inverseOf A |
|
T (
(m n)
, Z ) |
Z wrl#minCardinality m
Z wrl#maxCardinality n |
|
T (
(card)
, Z ) |
Z wrl#minCardinality card
Z wrl#maxCardinality card |
|
T (
instance A
memberOf
C1,...,Cn
nfp
attributevalue1
...
attributevaluen
, Z ) |
Z wrl#hasInstance A
A rdf#type C1
...
A rdf#type Cn
T(nfp, A)
T(attributevalue1,
A)
...
T(attributevaluen,
A) |
It is not required to associate an instance with an
identifier. In that case the identifier J is
replaced by a blank node identifier, e.g _:X.
The same counts for all entities that do not require an ID:
instance, relationInstance. |
T (
dc#title hasValue value
, Z ) |
Z rdfs#label T(value) |
|
T (
dc#description hasValue value
, Z ) |
Z rdfs#comment T(value) |
|
T (
dc#relation hasValue value
, Z ) |
Z rdfs#seeAlso T(value) |
|
T (
A hasValue value
, Z ) |
Z A T(value) |
|
T (
DVs
) |
DVs^^xsd#string |
Strings are already enclosed with double quotes in WRL;
these do not have to be added for the RDF literals. |
T (
DVi
) |
"DVi"^^xsd#integer |
|
T (
DVd
) |
"DVd"^^xsd#decimal |
|
T (
D(a1,...,an)
) |
Tserializer(D(a1,...,an))^^T
datatypes(D) |
Tserializer serializes the WRL
representation of a data value to a string representation
which can be readily used in RDF literals. This function is
not yet defined.
Tdatatypes maps WRL datatypes to XML Schema
datatypes, according to Table A.1 in Appendix A. |
T (
A
) |
A |
IRIs are directly used in RDF. |
T (
relation A / n
(B1,...Bm)
subRelationOf
{C1,...,Ck}
nfp
, Z ) |
Z wrl#hasRelation A
A wrl#arity "n"^^xsd#integer
A wrl#param _:X
_:X rdf#type rdf#List
_:X rdf#first _:X1
T(B1, _:X1)
_:X rdf#rest _:1
_:1 rdf#type rdf#List
_:1 rdf#first _:X2
...
_:m rdf#type rdf#List
_:m rdf#first _:Xn
T(Bm, _:Xn)
R wrl#subRelationOf C1
...
R wrl#subRelationOf Ck
T(nfp, A) |
The parameters of a relation are unnamed and thus
ordered. The ordering in RDF is provided by use of the
rdf#List. |
T (
ofType C
, Z ) |
Z wrl#ofType C |
|
T (
impliesType C
, Z ) |
Z rdfs#range C |
|
T (
relationInstance A B
(valuelist)
nfp
, Z) |
Z wrl#hasRelationInstance A
A rdf#type B
T(valuelist, A)
T(nfp, A) |
|
T (
value1,...,valuen
, Z ) |
Z wrl#param _:X
_:X rdf#type rdf#List
_:X rdf#first T(value1)
_:X rdf#rest _:1
_:1 rdf#type rdf#List
_:1 rdf#first T(value2)
_:1 rdf#rest _:2
...
_:m rdf#type rdf#List
_:m rdf#first T(valuen) |
The arguments of a relationinstance are unnamed and
thus ordered. The ordering in RDF is provided by use of the
rdf#List. |
T (
axiom A
axiomdefinition
, Z ) |
Z wrl#hasAxiom A
T(axiomdefinition,
A) |
|
T (
nfp
definedBy
log_expr
) |
T(nfp, A)
A rdfs#isDefinedBy "TXML(log_expr)"^^rdf#XMLLiteral |
log_expr denotes a logical expression. The logical
expressions are translated to literals of type
rdf#XMLLiteral using the mapping function defined in
Table 4.2 |
T (
nonFunctionalProperties
attributevalue1
...
attributevaluen
endNonFunctionalProperties
, Z ) |
Z wrl#nfp _:P1
T(attributevalue1,
_:P1)
...
Z wrl#nfp _:Pn
T(attributevaluen,
_:Pn) |
|
T (
nfp
attributevalue1
...
attributevaluen
endnfp
, Z ) |
Z wrl#nfp _:P1
T(attributevalue1,
_:P1)
...
Z wrl#nfp _:Pn
T(attributevaluen,
_:Pn) |
|
T (
importsOntology {
A1,...,An}
, Z ) |
Z wrl#importsOntology A1
...
Z wrl#importsOntology An |
|
Table 5.3 provides a simple translation example.
Table 5.3: A Mapping Example
| WRL syntax |
RDF Triples |
wrlVariant
_"http://www.wsml.org/wsml/wrl-syntax/wrl-flight"
namespace {_"http://www.example.org/ex1#",
dc _"http://purl.org/dc/elements/1.1#",
wrl _"http://www.wsml.org/wsml/wrl-syntax#",
ex _"http://www.example.org/ex2#"}
ontology _"http://www.example.org/ex1"
nonFunctionalProperties
dc#title hasValue "WRL to RDF"
dc#date hasValue _date(2005,12,12)
endNonFunctionalProperties
importsOntology _"http://www.example.net/ex2"
concept Woman subConceptOf
{ex#Human, ex#LivingBeing}
name ofType _string
ancestorOf transitive impliesType ex#Human
age ofType (1) _integer
axiom GenderConstraint
definedBy
!- ?x memberOf ex#Man and
?x memberOf Woman.
instance Mary memberOf Woman
name hasValue "Mary Jones"
age hasValue 23
relation childOf/2
(ofType ex#Human, impliesType ex#Parent)
|
The first RDF graph for the ontology:
http://www.example.org/ex1 rdf#type wrl#ontology
http://www.example.org/ex1 wrl#variant
http://www.wsml.org/wsml/wrl-syntax/wrl-flight
http://www.example.org/ex1 wrl#nfp _:P1
_:P1 http://purl.org/dc/elements/1.1#title
"WRL to RDF"^^xsd#string
http://www.example.org/ex1 wrl#nfp _:P2
_:P2 http://purl.org/dc/elements/1.1#date
"2005-02-04"^^xsd#date
http://www.example.org/ex1
wrl#importsOntology http://www.example.org/ex2
http://www.example.org/ex1 wrl#hasConcept
http://www.example.org/ex1#Woman
http://www.example.org/ex1#Woman rdfs#subClassOf
http://www.example.org/ex2#Human
http://www.example.org/ex1#Woman rdfs#subClassOf
http://www.example.org/ex2#LivingBeing
http://www.example.org/ex1#Woman wrl#hasAttribute _:X
_:X wrl#ofType xsd#string
_:X wrl#attribute http://www.example.org/ex1#name
http://www.example.org/ex1#Woman wrl#hasAttribute _:Y
_:Y rdfs#range http://www.example.org/ex2#Human
_:Y rdf#type wrl#transitiveAttribute
_:Y wrl#attribute http://www.example.org/ex1#ancesterOf
http://www.example.org/ex1#Woman wrl#hasAttribute _:Z
_:Z wrl#ofType xsd#integer
_:Z wrl#minCardinality 1
_:Z wrl#maxCardinality 1
_:Z wrl#attribute http://www.example.org/ex1#age
http://www.example.org/ex1 wrl#hasAxiom
http://www.example.org/ex1#GenderConstraint
http://www.example.org/ex1#WomanDef rdfs#isDefinedBy
"<ruleml:Constraint>...
</ruleml:Constraint>"^^rdf#XMLLiteral
http://www.example.org/ex1
wrl#hasInstance http://www.example.org/ex1#Mary
http://www.example.org/ex1#Mary rdf#type
http://www.example.org/ex1#Woman
http://www.example.org/ex1#Mary http://www.example.org/ex1#name
"Mary Jones"^^xsd#string
http://www.example.org/ex1#Mary http://www.example.org/ex1#age
"23"^^xsd#integer
http://www.example.org/ex1 wrl#hasRelation
http://www.example.org/ex1#childOf
http://www.example.org/ex1#childOf wrl#arity "2"xsd#integer
http://www.example.org/ex1#childOf wrl#hasParameter _:A
_:A wrl#ofType http://www.example.org/ex2#Human
http://www.example.org/ex1#childOf wrl#hasParameter _:B
_:B rdfs#range http://www.example.org/ex2#Parent
|
The mapping to OWL presented here is applicable to ontologies
and logical expressions only; note that logical expressions might
occur in ontologies. For a mapping of non-ontology constructs except
logical expressions the RDF Syntax for WRL has to be used.
Furthermore this version of the deliverable contains only a
mapping of WRL-Core to OWL. Other WRL variants cannot be mapped
to OWL in a straightforward way, since their semantics are not
compatible.
In this section we define a mapping of WRL-Core to the OWL DL
abstract syntax [OWLSemantics].
In order to simplify the translation we perform the following
pre-processing steps:
- Replace missing ontology identifiers by the locator of the
file containing the specification.
- Replace missing identifiers with unnumbered anonymous
identifiers (i.e., for concepts, relations, instances, relation
instances and axioms)
- Replace all unnumbered anonymous identifiers with a new unique
identifier
- Replace idlists with single ids (in the case of
ofType, impliesType, hasValue, subConceptOf and
subRelationOf).
E.g., "hasAnchestor hasValue {Peter, Paul}"
is substituted by "hasAnchestor hasValue
Peter" and "hasAnchestor hasValue
Paul".
- All sQNames in the syntax are replaced with full IRIs,
according to the rules defined in Section 2.2
- Within logical expression the following
pre-processing steps are applied:
- Replacing right implication with left implication
(lexpr implies
rexpr. is replaced by
rexpr impliedBy lexpr).
- Rewriting data term shortcuts ( "string" is replaced by
_string("string"); integer is replaced by _integer("integer"); decimal
is replaced by _decimal("decimal")).
- Rewriting all WRL datatype constructors according to
Table A.1 to their
corresponding XML schema datatype, e.g.,
_string to http://www.w3.org/2001/XMLSchema#string
Table 6.1 contains the mapping between the WRL Core and OWL DL
abstract syntax through the mapping function τ. In the table,
underlined words refer to production rules in the WRL grammar
(see Appendix B) and boldfaced words refer to keywords in the WRL
language. X and Y are meta-variables and are
replaced with actual identifiers or variables during the
translation itself. Note that in the table we use the familiar
sQName macro mechanism (see also Section 2.1.2) to abbreviate
IRIs. The prefix 'wrl' stands for
'http://www.wsml.org/wsml/wrl-syntax#', 'rdf' stands for
'http://www.w3.org/1999/02/22-rdf-syntax-ns#', 'rdfs' stands for
'http://www.w3.org/2000/01/rdf-schema#', 'dc' stands for
'http://purl.org/dc/elements/1.1#', 'xsd' stands for
'http://www.w3.org/2001/XMLSchema#', and 'owl' stands for
'http://www.w3.org/2002/07/owl#'.
Table 6.1: Mapping between WRL-Core and OWL DL abstract
syntax
| WRL-Core conceptual syntax |
OWL DL Abstract syntax |
Remarks |
| Mapping for ontologies |
τ(
ontology A
header1
...
headern
ontology_element1
...
ontology_elementn
) |
Ontology(id
τ(header1)
...
τ(headern)
τ(ontology_element1)
...
τ(ontology_elementn)
) |
|
τ(nonFunctionalProperties
id1
hasValue value1 ...
idn
hasValue valuen
endNonFunctionalProperties ) |
annotation(id1
τ(value1))
...
annotation(idn
τ(valuen)) |
For non-functional properties on the ontology level
"Annotation" instead of "annotation" has to be
written. |
| τ(importsOntoloy idlist) |
Annotation(owl#import id1) ...
Annotation(owl#import idn)
|
An idlist can
consist of n full IRIs (this remark holds for all idlists
in this table. |
| Mapping for concepts |
τ(concept
id superconcept nfp
att_id1
att_type1
range_id1
...
att_idn
att_typen
range_idn
) |
Class(id partial τ(nfp) τ(superconcept)
restriction (att_id1
allValuesFrom (range_id1))...
restriction (att_idn
allValuesFrom (range_idn))
)
[ObjectProperty|DatatypeProperty] (att_id1)
... [ObjectProperty|DatatypeProperty] (att_idn)
|
"DatatypeProperty" is chosen in case range_idi refers to
a datatype; otherwise, "ObjectProperty" is used. |
| τ(subConceptOf idlist) |
id1
... idn |
|
| Mapping for relations |
τ(relation id arity
paramtyping
superrelation
nfp) |
[ObjectProperty|DatatypeProperty] (id τ(nfp)
τ(superrelation)
τ(paramtyping)
) |
"DatatypeProperty" is chosen in case range_id refers to a datatype
identifier; otherwise the relation is mapped to
"ObjectProperty" (range_id refers to the second
type of paramtyping). |
| τ(subRelationOf idlist) |
super(id1) ..
super(idn) |
|
| τ((att_type
domain_id,
att_type range_id)) |
domain(domain_id) range(range_id) |
|
| Mapping for instances |
τ(instance id memberof nfp
att_id1
hasValue value1 ...
att_idn
hasValue valuen
) |
Individual(id τ(nfp) τ(memberof)
value (att_id1
τ(value1)) ...
value (att_idn
τ(valuen))
) |
|
| τ(memberOf idlist) |
type(id1)...type(
idn) |
|
| τ(datatype_id(x1,...,x
n)) |
τserializer(datatype_id(x1,...,x
n))^^τdatatypes(datatype_id) |
τserializer serializes the WRL
representation of a data value to a string representation
which can be readily used in OWL. This function is not yet
defined. τdatatypes maps WRL datatypes to
XML Schema datatypes, according to Table C.1 in Appendix
C. |
| τ(id) |
id |
In WRL and IRI is enclosed by _" and ",
which are omitted in OWL abstract syntax. |
τ(relationInstance relation_id
memberof_id(value1,
value2)
nfp) |
Individual(value1
value (memberof_id
τ(value2))
) |
If the relation instance has an identifier it will be
omitted. The NFPs are disregarded as their semantics cannot
be captured by OWL. |
| Mapping for axioms |
| τ(axiom id nfp log_expr) |
τ(log_expr) |
|
| τ(conjunction) |
intersectionOf( τ(molecule1), ...,
τ(moleculen)) |
|
τ(id[att_id1 att_type1
range_id1
...
att_idn
att_typen
range_idn]
superconcept) |
Class(id partial τ(superconcept)
restriction (att_id1
allValuesFrom range_id1)...
restriction (att_idn
allValuesFrom range_idn)
) |
|
τ(id[att_id1
hasValue value1 ...
att_idn
hasValue valuen]memberof) |
Individual(id
τ(memberof)
value (att_id1
τ(value1)) ...
value (att_idn
τ(valuen))
) |
|
τ(?x[att_id hasValue
?x]
impliedBy
?x[att_id hasValue
?y]
and ?y[att_id hasValue
?z]) |
ObjectProperty(att_id Transitive) |
|
τ(?x[att_id hasValue
?y]
impliedBy
?y[att_id hasValue
?x]) |
ObjectProperty(att_id Symmetric) |
|
τ(?x[att_id hasValue
?y]
impliedBy
?y[att_id2 hasValue
?x]) |
ObjectProperty(att_id InverseOf(att_id2)) |
|
τ(?x
memberOf concept_id2
impliedBy
?x memberOf
concept_id) |
Class (concept_id partial
concept_id2) |
|
τ(?x
memberOf concept_id
equivalent
?x memberOf
concept_id1
and ... and ?x memberOf
concept_idn) |
Class (concept_id complete
concept_id1 ...
concept_idn
) |
|
| τ(att_id(?x,?y) impliedBy
att_id2(?x,?y)) |
SubProperty (att_id att_id2) |
|
τ(?x
memberOf concept_id
impliedBy
att_id(?x,?y)) |
ObjectProperty(att_id domain(concept_id) ) |
|
τ(?y memberOf concept_id
impliedBy
att_id(?x,?y)) |
ObjectProperty(att_id range(att_id2) ) |
|
| τ() |
|
If τ is applied for a non-occurring production no
translation has to be made |
Table 6.2 shows the partial mapping between OWL DL (abstract syntax)
and WRL-Core. The table shows for each construct supported by OWL
DL (and being semantically within WRL-Core) the corresponding
WRL-Core syntax in terms of logical expressions necessary to
capture the construct.
The mapping is done by a recursive translation function τ.
The symbol X denotes a meta variable that has to be substituted
with the actual variable occurring during the translation. Note
that only those ontologies which fall in the DLP subset are
translated. If for an OWL DL ontology a mapping cannot be
found by applying τ the ontology is not within the
expressiveness of WRL Core.
In order to translate class axioms, the translation function
τ takes a WRL logical expression from the translation of the
left-hand side, τlhs, of a subclass relation (or
partial/complete class descriptions, respectively) as the first
argument, the right hand side of a subclass relationship as
second argument, and a variable as third argument. This variable
is used for relating classes through properties from the
allValuesFrom and someValuesFrom restrictions. Whenever we pass
such a value restriction during the translation, a new variable
has to be introduced, i.e., xnew stands for a freshly
introduced variable in every translation step.
In the table we apply the following convention for the
Identifiers:
- A refers to named classes
- C and D refer to named class
descriptions
- R refers to a property
- V refers to a Value (either a data value or an
Individual)
- I refers to an Individual
Table 6.2: Mapping between OWL DL abstract syntax and
WRL-Core
| OWL DL Abstract syntax |
WRL-Core syntax |
Remarks |
| Class Axioms |
| Class(A partial C1 ...
Cn) |
concept A
nonFunctionalProperties
dc#relation hasValue AxiomOfA
endNonFunctionalProperties
axiom AxiomOfA
definedBy
τ(?xnew memberOf A,
C1, ?xnew).
...
τ(?xnew memberOf A,
Cn, ?xnew). |
If Ci is a named class the axiom
definition for this i can be omitted and only
conceptual syntax can be used by including
Ci in the list of super concepts of
A:
concept A subConceptOf
{Ci} |
| Class(A complete C1 ...
Cn) |
concept A
nonFunctionalProperties
dc#relation hasValue AxiomOfA
endNonFunctionalProperties
axiom AxiomOfA
definedBy
τ(?xnew memberOf A,
C1, ?xnew). ...
τ(?xnew memberOf A,
Cn, ?xnew).
τ(τlhs(C1,
?xnew), A, ?xnew).
τ(τlhs(Cn,
?xnew), A, ?xnew). |
τlhs stands for a transformation
function for left-hand side descriptions. |
| EquivalentClasses(C1 ...
Cn) |
axiom _#
definedBy
τ(τlhs(Ci,
?xnew), Cj,
?xnew). |
Conjunctively for all i ≠ j |
| SubClassOf(C1
C2) |
axiom _#
definedBy
τ(τlhs(C1,
?xnew), C2,
?xnew) |
|
| Mapping of left hand side
descriptions |
| τlhs(A,X) |
X memberOf A |
|
|
τlhs(intersectionOf(C1
... Cn), X) |
τlhs(C1, X)
and ... and
τlhs(Cn, X) |
|
| τlhs(unionOf(C1 ...
Cn), X) |
τlhs(C1, X)
or ... or
τlhs(Cn, X) |
|
τlhs(restriction(
R someValuesFrom C), X) |
X[R hasValue ?xnew]
and τlhs(C,
xnew) |
|
τlhs(restriction(
R minCardinality(1)), X) |
X[R hasValue xnew] |
|
| Mapping of right hand side
descriptions |
τ(WRLExpr,
intersectionOf(C1 ...
Cn), X) |
τ(WRLExpr, C1, X)
and ... and
τ(WRLExpr, Cn, X) |
|
| τ(X memberOf
A1, A2, X) |
A1 subConceptOf
A2 |
|
| τ(WRLExpr, A, X) |
WRLExpr implies X memberOf
A |
|
τ(WRLExpr, restriction(
R allValuesFrom C), X) |
τ(WRLExpr and X[R
hasValue ?xnew],
C, ?xnew) |
|
| Property Axioms |
ObjectProperty(R
[super(R1) ...
super(Rn)]
[domain(C1) ...
domain(Cn)]
[range(D1) ...
range(Dn)]
[inverseOf(R')]
[Symmetric]
[Transitive]
) |
relation R/2
subRelationOf {R1, ...,
Rn}
nonFunctionalProperties
dc#relation hasValue AxiomOfR
endNonFunctionalProperties
axiom AxiomOfR
definedBy
τ(?x[R hasValue ?y],
C1, ?x) and ... and
τ(?x[R hasValue ?y],
Cn, ?x).
τ(?x[R hasValue ?y],
D1, ?x) and ... and
τ(?x[R hasValue ?y],
Dn, ?x).
?x[R hasValue ?y] implies
?y[R' hasValue ?x] and
?x[R' hasValue ?y] implies
?y[R hasValue ?x].
?x[R hasValue ?y] implies
?y[R hasValue ?x].
?x[R hasValue ?y] and ?y[R
hasValue ?z].
implies ?x[R hasValue ?z]. |
All Specifications of the ObjectProperty except the
identifier are optional.
If both range and domain are given and consist only of
named classes their translation can be abbreviated in the
conceptual model:
relation R(
impliesType {C1, ...,
Cn}
impliesType {D1, ...,
Dn})
|
| SubProperty(R1
R2) |
relation R1/2
subRelationOf R2 |
|
| EquivalentProperties(R1 ...
Rn) |
?x[Ri hasValue ?y]
implies
?x[Rj hasValue ?y] |
Conjunctively for all i ≠ j |
| Individuals |
Individual (I
[type (C1) ...
type(Cn)]
[value (R1 V1)
...
value (Rn
Vn)]
) |
instance I
memberOf {C1,...,
Cn}
R1 hasValue
V1 ....
Rn hasValue
Vn
|
All Specifications of the Individual except the
identifier are optional. |
In this document we have presented the Web Rule Language WRL,
which is a rule-based ontology language for use on the Semantic
Web. OWL [OWL] is an important
language for the Semantic Web, but practice shows that many
applications need expressiveness beyond OWL. With WRL we
provide a rule language in the tradition of Logic Programming
and Deductive Databases. WRL can be
used beside the Description Logic
based ontology language OWL and inter-operation can be achieved
through a common semantic subset; a subset of WRL, namely
WRL-Core, can be
translated to a subset of OWL (and vice versa), such that both
subsets entail exactly the same set of ground
facts. Inter-operation through a common subset, rather than
layering directly on top of OWL, is necessary
in order to stay in the framework of standard (LP-based) rule
languages. We base our approach on F-Logic [Kifer et al.,
1995], because it gives a syntactic framework to specify
the structure of concepts and attributes (e.g., concept
hierarchy and attribute ranges) and to reason over this
structure. Furthermore, F-Logic allows
higher-order constructs, such as meta-modeling (e.g., classes
as instances), while staying in the standard Horn fragment.
WRL itself consists of three layers, namely, Core, Flight and
Full. WRL-Core marks a basic interoperability layer with OWL. WRL-Flight
is a rule language based on the Datalog subset of F-Logic with
Perfect Model Semantics for locally stratified negation and limited
Lloyd-Topor. WRL-Full
extends WRL-Flight to a full-fledged Logic Programming language with
function symbols, unsafe rules, unstratified negation under the
Well-Founded Semantics, and full Lloyd-Topor (i.e., arbitrary
first-order formulae are allowed in the rule body).
WRL enables non-expert users to model ontologies using an intuitive
"conceptual" syntax. Expert users can use the logical
expression syntax to leverage the full power of the rule language.
WRL is based on the principle of Web identifiers. Every
concept, instance, etc., is identified using an IRI. WRL defines an
XML serialization for exchange over the Web and for interoperability
with RuleML-enabled applications. WRL furthermore layers on top of
RDF and defines an RDF exchange syntax for inter-operation with
Semantic Web applications.
These properties make WRL a very user-friendly and
machine-friendly language for the Semantic Web and provides a good
starting point for the specification of a rules language for the
Semantic Web.
The work is funded by the European Commission under the projects DIP,
Knowledge Web, InfraWebs, SEKT, SWWS, ASG and Esperonto; by Science
Foundation Ireland under the DERI-Lion project; by the FIT-IT (Forschung,
Innovation, Technologie - Informationstechnologie) under the projects
RW² and TSC; by the German Federal Ministry of Education and Research (BMBF) under the SmartWeb project.
The editor would like to thank to all the members of the WSML working group for their advice and
input into this document.
[Boley, 2001] Harold Boley:
The Rule
Markup Language: RDF-XML Data Model, XML Schema Hierarchy, and
XSL Transformations, Invited Talk, INAP2001, Tokyo, October 2001.
[Boley et al., 2001]
Harold Boley, Said Tabet, and Gerd Wagner: Design
Rationale of RuleML: A Markup
Language for Semantic Web Rules, Proc. SWWS'01, Stanford, July/August 2001.
[Boley et al., 2005]
Harold Boley, Mike Dean, Benjamin Grosof, Michael Sintek, Bruce
Spencer, Said Tabet, Gerd Wagner: FOL RuleML: The
First-Order Logic Web Language, W3C Member Submission 11 April
2005. http://www.w3.org/submissions/FOL-RuleML/
[de Bruijn et
al., 2005] J. de Bruijn, A. Polleres, R. Lara and D.
Fensel. OWL DL vs. OWL Flight: Conceptual Modeling and Reasoning
for the Semantic Web. In Proceedings of the Fourteenth
International World Wide Web Conference (WWW2005), 2005.
[DublinCore] S. Weibel, J. Kunze, C.
Lagoze, and M. Wolf: RFC 2413 - Dublin Core Metadata for
Resource Discovery, September 1998, available at http://www.isi.edu/in-notes/rfc2413.txt.
[Enderton,
2002] H. B. Enderton. A Mathematical
Introduction to Logic (2nd edition). Academic Press,
2002
[Fensel et al.,
2001] D. Fensel, F. van Harmelen, I. Horrocks, D.L.
McGuinness, and P.F. Patel- Schneider: OIL: An Ontology
Infrastructure for the Semantic Web. IEEE Intelligent
Systems, 16:2, May 2001.
[van Gelder et
al., 1991] A. van Gelder, K. Ross, and J. S.
Schlipf. The well-founded semantics for general logic programs.
Journal of the ACM, 38(3):620--650, 1991.
[Grosof et al.,
2003] B. N. Grosof, I. Horrocks, R. Volz, and S. Decker.
Description logic programs: Combining logic programs with description
logic. In Proc. of the Twelfth International World Wide Web
Conference (WWW 2003), pages 48-57. ACM, 2003.
[IRI] M. Duerst and M. Suignard.
Internationalized Resource Identifiers (IRIs). IETF
RFC3987. http://www.ietf.org/rfc/rfc3987.txt
[Kifer et al.,
1995] M. Kifer, G. Lausen, and J. Wu: Logical
foundations of object-oriented and frame-based languages.
Journal of the ACM, 42:741-843, July 1995.
[Lloyd, 1987]
J. W. Lloyd. Foundations of Logic Programming (2nd edition).
Springer-Verlag, 1987.
[Lloyd and Topor,
1984] John W. Lloyd and Rodney W. Topor: Making
prolog more expressive. Journal of Logic Programming,
1(3):225{240, 1984.
[OWL] M.
Dean, G. Schreiber, (Eds.). OWL Web Ontology Language
Reference, W3C Recommendation, 10 February 2004. Available
from http://www.w3.org/TR/2004/REC-owl-ref-20040210/.
[OWLSemantics] P. F. Patel-Schneider, P.
Hayes, and I. Horrocks: OWL web ontology language semantics
and abstract syntax. W3C Recommendation 10 February 2004.
Available from http://www.w3.org/TR/owl-semantics/.
[Pan & Horrocks,
2005] Jeff Z. Pan, Ian Horrocks: OWL-Eu: Adding
Customised Datatypes into OWL. Second European Semantic Web
Conference (ESWC2005), Heraklion, Greece, 2005; 153-166.
[Przymusinski, 1989]
T. C. Przymusinski. On the declarative and procedural semantics of
logic programs. Journal of Automated Reasoning, 5(2):167-205,
1989.
[RDFS] D. Brickley and R. V. Guha.
RDF vocabulary description language 1.0: RDF schema. W3C
Recommendation 10 February 2004. Available from http://www.w3.org/TR/rdf-schema/.
[Roman et al., 2005] D. Roman, H. Lausen, and U. Keller (eds.): Web Service Modeling Ontology - Standard (WSMO
- Standard), WSMO Final Draft D2 version 1.2, 2005. available from http://www.wsmo.org/TR/d2/v1.2/.
[SableCC]
The SableCC Compiler Compiler. http://sablecc.org/
[SparQL]
E. Prud'hommeaux and A. Seaborne: SPARQL
Query Language for RDF. W3C Working draft. http://www.w3.org/TR/rdf-sparql-query/
[SWRL] I. Horrocks, P.F.
Patel-Schneider, H. Boley, S. Tabet, B. Grosof and M. Dean:
SWRL: A Semantic Web Rule Language Combining OWL and
RuleML. W3C Member Submission 21 May 2004. Available from
http://www.w3.org/submissions/2004/SUBM-SWRL-20040521/.
[WSML] J. de
Bruijn, H. Lausen, R. Krummenacher, A. Polleres, L. Predoiu, M.
Kifer, and D. Fensel. The Web Service Modeling Language
WSML. WSML Final Draft 20 March D16.1v0.2, WSML, 2005.
http://www.wsmo.org/TR/d16/d16.1/v0.2/.
[XMLNamespaces] T. Bray, D. Hollander, A.
Layman (eds.): Namespaces in XML, W3C Recommendation,
available from http://www.w3.org/TR/REC-xml-names/.
[XPathFunctions] A. Malhotra, J.
Melton, N. Walsh: XQuery 1.0 and XPath 2.0 Functions and
Operators, W3C Working Draft, available at http://www.w3.org/TR/xpath-functions/.
[XMLSchemaDatatypes] P.V. Biron and A.
Malhorta. XML Schema Part 2: Datatypes Second Edition.
W3C Recommendation 28 October 2004.
[Yang & Kifer,
2002] G. Yang and M. Kifer. Well-Founded
Optimism: Inheritance in Frame-Based Knowledge Bases.
In First International Conference on
Ontologies, Databases and Applications of Semantics (ODBASE), Irvine,
California, 2002.
[Yang & Kifer,
2003] G. Yang and M. Kifer. Reasoning about
anonymous resources and meta statements on the semantic web.
Journal on Data Semantics, 1:69-97, 2003.
This appendix contains a preliminary list of built-in
functions and relations for datatypes in WRL. It also contains a
translation of syntactic shortcuts to datatype predicates.
WRL recommends the use of XML Schema datatypes as defined in
[XMLSchemaDatatypes] for the
representation of concrete values, such as strings and integers.
WRL defines a number of built-in functions for the use of XML
Schema datatypes.
WRL allows direct usage of the string, integer and decimal
data values in the language. These values have a direct
correspondence with values of the XML Schema datatypes
string, integer, and decimal,
respectively. Values of these most primitive datatypes can be
used to construct values of more complex datatypes. Table A.1
lists datatypes allowed in WRL with the name of the datatype
constructor, the name of the corresponding XML Schema datatype, a
short description of the datatype (corresponding with the value
space as defined in [XMLSchemaDatatypes]) and an example of the use of the datatype.
Table A.1: WRL Datatypes
| WRL datatype constructor |
XML Schema datatype |
Description of the Datatype |
Syntax |
| _string |
string |
A finite-length sequence of Unicode characters, where
each occurrence of the double quote ‘"’ is
escaped using the backslash symbol: ‘\"’ and
the backslash is escaped using the backslash:
‘\\’. |
_string("any-character*") |
| _decimal |
decimal |
That subset of natural numbers which can be represented
with a finite sequence of decimal numerals. |
_decimal("'-'?numeric+.numeric+") |
| _integer |
integer |
That subset of decimals which corresponds with natural
numbers. |
_integer("'-'?numeric+") |
| _float |
float |
|
_float("see XML Schema document") |
| _double |
double |
|
_double("see XML Schema document") |
| _iri |
similar to anyURI |
An IRI conforms to [IRI]. Every URI is an IRI. |
_iri("iri-according-to-rfc3987") |
| _sqname |
serialized QName |
An sQName is a pair {namespace, localname}, where the
localname us concatenated to the namespace to form an IRI.
An sQName is actually equivalent to the IRI which results
from concatenating the namespace and the localname. |
_sqname("iri-according-to-rfc3987",
"localname") |
| _boolean |
boolean |
|
_boolean("true-or-false") |
| _duration |
duration |
|
_duration(year, month, day,
hour, minute, second) |
| _dateTime |
dateTime |
|
_dateTime(year, month, day,
hour, minute, second,
timezone-hour, timezone-minute)
_dateTime(year, month, day,
hour, minute, second) |
| _time |
time |
|
_time(hour, minute, second,
timezone-hour, timezone-minute)
_time(hour, minute, second) |
| _date |
date |
|
_date(year, month, day,
timezone-hour, timezone-minute)
_date(year, month, day) |
| _gyearmonth |
gYearMonth |
|
_gyearmonth(year, month) |
| _gyear |
gYear |
|
_gyear(year) |
| _gmonthday |
gMonthDay |
|
_gmonthday(month, day) |
| _gday |
gDay |
|
_gday(day) |
| _gmonth |
gMonth |
|
_gmonth(month) |
| _hexbinary |
hexBinary |
|
_hexbinary(hexadecimal-encoding) |
| _base64binary |
base64Binary |
|
_base64binary(hexadecimal-encoding) |
Table A.2 contains the shortcut syntax for the string,
integer, decimal, IRI and sQName datatypes.
Table A.2: WRL Datatype shortcut syntax
| WRL datatype constructor |
Shortcut syntax |
Example |
| _string |
"any-character*" |
"John Smith" |
| _decimal |
'-'?numeric+.numeric+ |
4.2, 42.0 |
| _integer |
'-'?numeric+ |
42, -4 |
| _iri |
_"iri-according-to-rfc3987" |
_"http://www.wsmo.org/wsml/wrl-syntax#" |
| _sqname |
alphanumeric+'#'alphanumeric+ |
wrl#concept, xsd#integer |
This section contains a list of datatype predicates suggested
for use in WRL. These predicates correspond to functions in
XQuery/XPath [XPathFunctions].
Notice that SWRL [SWRL] built-ins are also based on XQuery/XPath.
The current list is only based on the built-in support in the
WRL language through the use of special symbols. A translation of
the built-in symbols to datatype predicates is given in the next
section. The symbol ‘range’ signifies the range of
the function. Functions in XQuery have a defined range, whereas
predicates only have a domain. Therefore, the first argument of a
WRL datatype predicate which represents a function represents the
range of the function. Comparators in XQuery are functions, which
return a boolean value. These comparators are directly translated
to predicates. If the XQuery function returns 'true', the
arguments of the predicate are in the extension of the predicate.
See Table A.3 for the complete list. In the evaluation of the
predicates, the parameters 'A' and 'B' must be bound; the
parameter 'range' does not need to be bound. A parameter is bound
if it is substituted with a value. It is not bound if it is
substituted with a variable. The variable is then used to convey
some outcome of the function.
Table A.3: WRL Datatype Predicates
| WRL datatype predicate |
XQuery function |
Datatype (A) |
Datatype (B) |
Return datatype |
| wrl#numericEqual(A,B) |
op#numeric-equal(A,B) |
numeric |
numeric |
|
|
wrl#numericGreaterThan(A,B) |
op#numeric-greater-than(A,B) |
numeric |
numeric |
|
|
wrl#numericLessThan(A,B) |
op#numeric-less-than(A,B) |
numeric |
numeric |
|
| wrl#stringEqual(A,B) |
op#numeric-equal(fn:compare(A, B), 1) |
xsd#string |
xsd#string |
|
|
wrl#numericAdd(range,A,B) |
op#numeric-add(A,B) |
numeric |
numeric |
numeric |
|
wrl#numericSubtract(range,A,B) |
op#numeric-subtract(A,B) |
numeric |
numeric |
numeric |
|
wrl#numericMultiply(range,A,B) |
op#numeric-multiply(A,B) |
numeric |
numeric |
numeric |
|
wrl#numericDivide(range,A,B) |
op#numeric-divide(A,B) |
numeric |
numeric |
numeric |
Each WRL implementation is required to either implement the
complement of each of these built-ins or to provide a negation
operator which can be used together with these predicates.
We see the need for a standardized vocabulary for built-in
predicates (functions and operators over datatypes) for the
Semantic Web. We envision this vocabulary to be based on
XQuery/XPath [XPathFunctions]. SWRL [SWRL] and SparQL [SparQL] have made steps in this direction, but
we believe that this vocabulary should be independent of the
particular language in which it is used. These built-in predicates
could be used in combination with a variety of languages
besides WRL, such
as OWL (cf. [Pan & Horrocks,
2005]) and SparQL [SparQL].
In this section, we provide the translation of the built-in
(function and predicate) symbols for datatype predicates to these
datatype predicates.
We distinguish between built-in functions and built-in
relations. Functions have a defined domain and range. Relations
only have a domain and can in fact be seen as functions, which
return a boolean, as in XPath/XQuery [XPathFunctions]. We first provide the
translation of the built-in relations and then present the
rewriting rules for the built-in functions.
The following table provides the translation of the built-in
relations:
Table A.4: WRL infix operators and corresponding datatype
predicates
| Operator |
Datatype (A) |
Datatype (B) |
Predicate |
| A = B |
string |
string |
wrl#stringEqual(A,B) |
| A != B |
xsd#string |
xsd#string |
wrl#stringInequal(A,B) |
| A = B |
numeric |
numeric |
wrl#numericEqual(A,B) |
| A != B |
numeric |
numeric |
wrl#numericInequal(A,B) |
| A < B |
numeric |
numeric |
wrl#lessThan(A,B) |
| A =< B |
numeric |
numeric |
wrl#lessEqual(A,B) |
| A > B |
numeric |
numeric |
wrl#greaterThan(A,B) |
| A >= B |
numeric |
numeric |
wrl#greaterEqual(A,B)) |
We list the built-in functions and their translation to
datatype predicates in Table A.5. In the table, ?x1 represents a
unique newly introduced variable, which stands for the range of
the function.
Table A.5: Translation of WRL infix operators to datatype
predicates
| Operator |
Datatype (A) |
Datatype (B) |
Predicate |
| A + B |
numeric |
numeric |
wrl#numericAdd(?x1,A,B) |
| A - B |
numeric |
numeric |
wrl#numericSubtract(?x1,A,B) |
| A * B |
numeric |
numeric |
wrl#numericMultiply(?x1,A,B) |
| A / B |
numeric |
numeric |
wrl#numericDivide(?x1,A,B) |
Function symbols in WRL are not as straightforward to
translate to datatype predicates as are relations. However, if we
see the predicate as a function, which has the range as its first
argument, we can introduce a new variable for the return value of
the function and replace an occurrence of the function symbol
with the newly introduced variable and append the newly
introduced predicate to the conjunction of which the top-level
predicate is part.
Formulas containing nested built-in function symbols can be
rewritten to datatype predicate conjunctions according to the
following algorithm:
- Select an atomic occurrence of a datatype function symbol.
An atomic occurrence is an occurrence of the function symbol
with only identifiers (which can be variables) as
arguments.
- Replace this occurrence with a newly introduced variable
and append to the conjunction of which the function symbol is
part the datatype predicate, which corresponds with the
function symbol where the first argument (which represents the
range) is the newly introduced variable.
- If there are still occurrences of function symbols in the
formula, go back to step (1), otherwise, return the
formula.
We present an example of the application of the algorithm to
the following expression:
?w = ?x + ?y + ?z
We first substitute the first occurrence of the function
symbol '+' with a newly introduced variable ?x1 and append the
predicate wrl#numericAdd(?x1, ?x, ?y) to the conjunction:
?w = ?x1 + ?z and wrl#numericAdd(?x1, ?x, ?y)
Then, we substitute the remaining occurrence of '+'
accordingly:
?w = ?x2 and wrl#numericAdd(?x1, ?x, ?y) and wrl#numericAdd(?x2, ?x1, ?z)
Now, we don't have any more built-in function symbols to
substitute and we merely substitute the built-in relation '=' to
obtain the final conjunction of datatype predicates:
wrl#numericEqual(?w, ?x2) and wrl#numericAdd(?x1, ?x, ?y) and wrl#numericAdd(?x2, ?x1, ?z)
This appendix presents the complete grammar for the WRL
language. The language use write this grammar is a variant of Extended
Backus Nauer Form which can be interpreted by the SableCC compiler
compiler [SableCC].
We present one WRL grammar for all WRL variants. The restrictions
that each variants poses on the use of the syntax are described in
Chapter 2.
In this section we show the entire WSML grammar.
The grammar is specified using a dialect of Extended BNF
which can be used directly in the SableCC compiler compiler [SableCC]. Terminals are quoted, non-terminals are
underlined and refer to the tokens and productions. Alternatives are
separated using vertical bars '|', and are labeled, where the label is
enclosed in curly brackets '{' '}'; optional elements are appended with a
question mark '?'; elements that may occur zero or more times are appended
with an asterisk '*'; elements that may occur one or more times are appended
with a plus '+'.
The first part of the grammar file provides HELPERS which
are used to write TOKENS. Broadly, a language has a collection
of tokens (words, or the vocabulary) and rules, or PRODUCTIONS,
for generating sentences using these tokens (grammar). A grammar
describes an entire language using a finite set of productions of
tokens or other productions; however this finite set of rules can
easily allow an infinite range of valid sentences of the language they
describe. Note, helpers cannot directly be used in productions. A last
word concerning the IGNORED TOKENS: ignored tokens are ignored
during the parsing process and are not taken into consideration when
building the abstract syntax tree.
Note that the
depicted layer cake is somewhat
simplified. WRL-Core/OWL-DLP does not completely semantically layer on
top of RDF and neither do OWL Lite/DL and WRL
Flight/Full. Additionally, under WRL semantics the WRL-Core/OWL-DLP
layer allows only ground entailment.