The libwww core is the central part of libwww. By itself it doesn't do much - it is not capable of accessing any local files, HTTP servers, or any other Internet service. Also, it does not know about authentication, redirection, caching or any other often used feature. The reason for this is that not all applications need the same amount of functionality and also they do not need it to be done in the same order. Therefore, in order to accommodate the various needs of different types of applications, libwww has a set of application profiles which initialize the libwww core with a standard set of features provided as a part of the libwww distribution-file.
If you have not already installed and compiled libwww then have a look at our installation guide before you continue.
Libwww comes with a large set of default functions, for example for accessing HTTP and FTP servers, parsing RFC 822 headers etc. but it must all be registered by the application before the core knows about it. You can either register the parts directly through the many initialization functions in the Initialization Interface or you can use these "precompiled" profiles which are set up to contain the features often used by the a specific type of application, for example a client and a robot.
The Client profile initializes a large set of features often used in client applications. These include features like:
The Robot profile initializes a large set of features often used in robot applications. These include features like:
When you want to load a URL, or perform some other method, for example sending a document to a remote server, you must create a Request object -fill it out with your preferences, and pass it to libwww. In the application interface, there is already a large set of functions that help you set up the request in order to perform the operation you want. For example, there are functions that download a document into a memory buffer, save a document to local file, or to POST form data to a remote HTTP server.
When a request is passed to libwww, libwww calls a set of filters that can modify the request in various ways before it is passed on to the network layers of libwww. Also, after a request has terminated, libwww calls a set of AFTER filters that interpret the result and can perform variousoperations based on this result. If the request succeeds and we start receiving data from the other end of the connection, libwww creates a stream pipe which feeds data from the network layers back to the application. In the request object you can specify the final destination for your data, for example presenting it to a user, save it to a file, or to send it over the network.
Libwww has a concept of filters that can be called when a request object has been passed to libwww and when the request has terminated.These filters handle a lot of the functionality enabled by the application profiles. For example, access authentication, redirection, logging,cache validation, proxy support and much more are implemented as filters.Filters can be registered either locally to a single request of globally for all requests. Global filters is useful if the filter is to be performed very often and local filters can either add to or override the global set of filters.
All filters are registered at run-time, and filters can be cascaded so that one filter can call other filters and so on. Filters can also start new requests or terminate existing requests, so the set of possibilities is very big. Normally, filters do only handle metainformation about a resource.For example, the authentication filters looks to see if we have been asked to provide some credentials in order to access a URL. If so then it adds a protocol defined header to the request, and if not then the request just proceeds.
One thing filters can not do is to add a document to the request- for example if you are using a PUT method in order to send a document to a remote HTTP server. Instead, libwww uses streams to transport data objects from the application over the network, or the other way. Streams are advantageous as they handle data as soon as it arrives and they can be cascaded into stream pipes. Each stream element in a stream pipe can do some operation on the data object. Streams can be used for many things: they can convert data object from one data type to another, or they can apply a compression algorithm or a transport encoding, for example base 64. However,streams can also be used for calculating the content length, or to generate an MD5 hash of the data object.
Stream pipes are generated by looking at the content-type, the content-encoding, and the transport-encoding of a data object.That is, if libwww receives a document encoded using chunked transfer-encoding, then it looks to see if it has a stream object which can decode this encoding and pass it to the next stream in the stream pipe.
Another feature of streams is that they can be forked into multiple streams and then do different operations on each branch of the stream. This is for example how we cache a document while we are presenting it to the user, or you can also preserve the original HTML text in one branch while parsing the document in another.
The application interface provides many helper functions that make libwww core easier to use. This is particular the case for accessing URLs where you can find a large set of functions in the HTAccess module. If these functions for some reason are not what you are looking for then you can of course go ahead and write your own additions but you should find what is needed at least to get started!
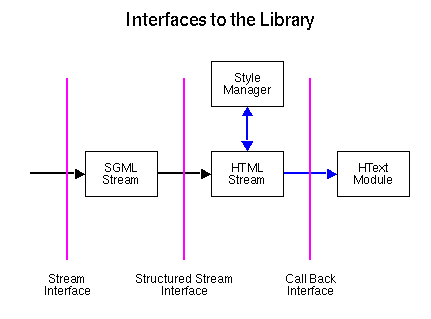
Libwww contains code for parsing an HTML document but not to present it to the user. The reason for that is that libwww is platform independent and doesn't know about the UI interface at all. The libwww HTML parser is quite crude as it has not been updated for a long time. Instead we refer you to the Amaya browser/edirtor for a full HTML parser. However, if you prefer using the default libwww HTML parser (like for example the Line Mode Browser) then you must provide a set of functions that meet the HText Interface definition.
The HTML parser calls the HText interface each time it has identified an HTML element, but doesn't put any restrictions on what the HText function actually do with the data. Two different examples are the Line Mode Browser which renders the information and presents it to the user; and the Mini Robot which uses the anchor information to start new requests in order to traverse the Web space. The illustration below shows how the libwww HTML parser is organized with a description of the model below.