Detaljer
Att använda en kodning på ditt innehåll
Innehållsförfattare bör deklarera sina webbsidors teckenkodning genom att använda en av de metoder som beskrivs i Declaring character encodings in HTML.
Det är dock viktigt att förstå att deklaration av kodningen inne i ett dokument eller på en server inte medför att dokumentets bytes ändras; du måste spara texten i den kodningen för att få kodningen att ta effekt. (Deklarationen är bara till för att hjälpa webbläsaren att tolka den sekvens av bytes som utgör den lagrade texten.)
Om möjligt bör du ange att UTF-8 är normalkodning för nya dokument i ditt redigeringsverktyg. Bilden nedan visar hur du kan ange detta som del i inställningarna (eng: preferences) för ett redigeringsverktyg som Dreamweaver.
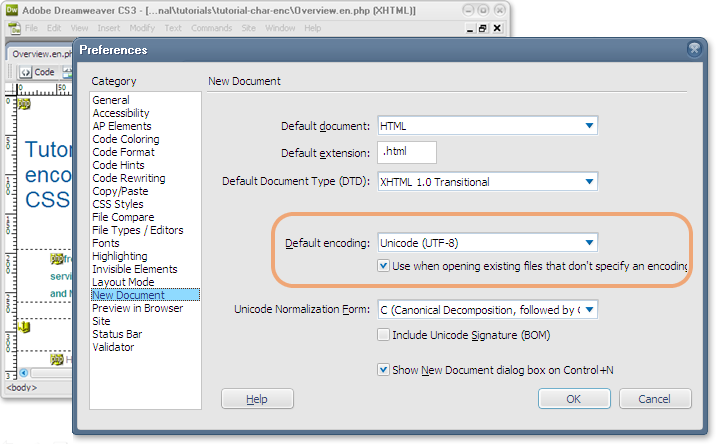
Du kan även behöva kontrollera att din server levererar dokument med korrekta HTTP-deklarationer, eftersom dessa annars kommer att ersätta det som angivits i dokumentet (se nedan).
Utvecklare måste också säkerställa att olika delar av systemet kan kommunicera med varandra. Webbsidor måste kunna kommunicera sömlöst med skripts, databaser etc som finns på servern. Dessa fungerar naturligtvis också bäst med UTF-8. Utvecklare kan hitta en detaljerad beskrivning av vad som behöver göras i artikeln Migrating to Unicode.
Varför använda UTF-8?
En HTML-sida kan bara ha en kodning. Du kan inte koda olika delar av dokumentet i olika kodningar.
En kodning baserad på Unicode, t.ex. UTF-8, kan stödja många språk och kan användas för sidor och formulär i godtycklig blandning av dessa språk. Genom att använda en sådan kodning behöver man inte ha speciell hantering på servern som, för alla levererade sidor eller all formulärinmatning, försöker avgöra vilken teckenkodning detta innehåll har. Detta ger en avsevärd minskning av komplexiteten i att hantera en flerspråkig webbplats eller tillämpning.
Med en Unicode-kodning kan man även ha text i många flera olika språk på samma webbsida än är möjligt med andra val för teckenkodning.
Numera finns det inte mycket som försvårar användning av Unicode. I januari 2012 rapporterade Google att mer än 60% av webben i ett undersökt stort urval (många miljarder sidor) var representerat i UTF-8. Till det bör man lägga den mängd sidor som är kodade i ren ASCII (eftersom ASCII är en delmängd av UTF-8), och då når man upp till närmare 80%.
Det finns tre olika teckenkodningar i Unicode; UTF-8, UTF-16 och UTF-32. Av dessa tre bör endast UTF-8 användas för webbinnehåll. Specifikationen för HTML5 säger att ”Innehållsförfattare uppmanas att använda UTF-8. Konformitetsgranskare kan avråda författare från att använda gamla kodningar. Författarverktyg bör ha UTF-8 som normalvärde för nyskapat innehåll”.
Kom ihåg att alla ASCII-tecken i UTF-8 använder exakt samma numeriska värden (bytes) som traditionell ASCII-kodning, ett faktum som ofta underlättar interoperabilitet och bakåtkompatibilitet.
Att ta hänsyn till HTTP-huvuden
Om en teckenkodning deklareras i HTTP-huvudet, så kommer detta värde att gälla, oavsett vad som anges i webbsidan. Om HTTP-huvudet deklarerar en kodning som inte är likvärdig med den du valt för ditt innehåll, så kommer detta att skapa problem, såvida du inte ser till att ändra inställningarna för servern.
Du kanske inte har möjlighet att själv påverka deklarationerna som finns i HTTP-huvudet, och då måste du begära hjälp av de som ansvarar för servern. Men det kan finnas sätt att få saker och ting att fungera bra, om du åtminstone har viss tillgång till serverns inställningsfiler, eller om du genererar sidor med hjälp av något skriptspråk. Se t.ex. i Setting the HTTP charset parameter, där det finns mer information om hur man kan ändra information om kodning, antingen lokalt för en viss uppsättning filer på servern, eller för innehåll genererat med skriptspråk.
Men innan du gör det så ska du undersöka om HTTP-huvudet faktiskt deklarerar teckenkodningen. Du kan använda W3C Internationalization Checker för att få information om någon teckenkodning angivits i HTTP-huvudet, och i så fall vilken teckenkodning. Du kan även titta i artikeln Checking HTTP Headers, som pekar ut andra verktyg vilka kan användas för att undersöka vilken information servern levererar om kodning.