Answer
What is a byte-order mark?
A Byte Order Mark, sometimes abbreviated "BOM", is a special Unicode character intended to appear at the very beginning of a text file. Its original purpose was to indicate the endianness
of text that used the UTF-16 or UTF-32 character encodings of Unicode. The Byte Order Mark is U+FEFF ZERO WIDTH NON-BREAKING SPACE: the character name refers to a separate, deprecated, use of the character.
Some systems use the BOM code point at the start of a file to indicate that text files are using the UTF-8 character encoding, even though UTF-8 does not need a marker to indicate endianness.
While often invisible and intended to aid in correctly interpreting text, the presence of the BOM can sometimes cause unexpected display issues or problems with software if not handled correctly.
The name BYTE ORDER MARK is an alias for the original character name ZERO WIDTH NO-BREAK SPACE (ZWNBSP). With the introduction of U+2060 WORD JOINER, there's no longer a need to ever use U+FEFF for its ZWNSP effect, so from that point on, and with the availability of a formal alias, the name ZERO WIDTH NO-BREAK SPACE is no longer helpful, and we will use the alias here.
Before UTF-8 was introduced in early 1993, the expected way for transferring Unicode text was using 16-bit code units using an encoding called UCS-2 which was later extended to UTF-16. 16-bit code units can be expressed as bytes in two ways: the most significant byte first (big-endian) or the least significant byte first (little-endian). To communicate which byte order was in use, U+FEFF (the byte-order mark) was used at the start of the stream as a magic number that is not logically part of the text the stream represents.
The picture below shows the bytes used in a sequence of two-byte characters. Each 2-digit hexadecimal number represents a byte in the stream of text. You can see that the order of the two bytes that represent a single character is reversed for big endian vs. little endian storage. The byte-order mark indicates which order is used, so that applications can immediately decode the content.
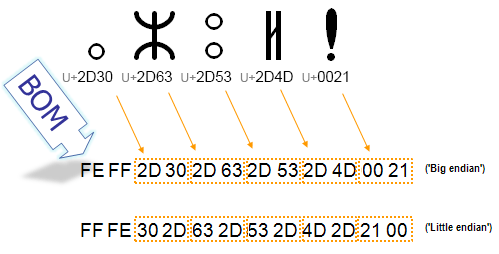
In the UTF-8 encoding, the presence of the BOM is not essential because, unlike the UTF-16 encodings, there is no alternative sequence of bytes in a character. However, the BOM may still occur in UTF-8 encoded text, either as a by-product of an encoding conversion or because it was added by an editor to flag the content as UTF-8. In this situation, the BOM is often called a UTF-8 signature.
What do I need to know about the BOM?
Most of the time you will not have to worry about the byte-order mark in UTF-8. You will find that some editors (such as Notepad on Windows) will always add a BOM when you save a file with the UTF-8 encoding, others will offer you a choice.
In HTML5 browsers are required to recognize the UTF-8 BOM and use it to detect the encoding of the page, and recent versions of major browsers handle the BOM as expected when used for UTF-8 encoded pages.
The UTF-8 BOM offers reliable encoding detection, since it is extremely short and stable, works in XML and HTML, and works whether your page is read over the network or not (unlike HTTP declarations). However, bear in mind that it is always a good idea to declare the encoding of your page using the meta element, in addition to the BOM, so that the encoding is apparent to people looking at the source text.
Also there are a number of situations where the BOM, particularly because it is invisible, may cause a problem. See the section Potential issues with the UTF-8 BOM below for more information about those.
If you use a UTF-16 encoding for your page (and we strongly recommend that you don't), there are some additional considerations.
When to Use (and Not Use) the BOM
The necessity and recommendation for using a BOM varies significantly depending on the Unicode encoding scheme being used.
UTF-8
For UTF-8, the BOM is the byte sequence EF BB BF. Unlike UTF-16 and UTF-32, UTF-8 does not have byte order (endianness) issues, so a BOM is not needed for this purpose. Its only function in UTF-8 is to act as a "signature" to indicate that the file is UTF-8 encoded. The Unicode Standard permits the BOM in UTF-8 but does not recommend its use.
Recommendation: Generally, it's best to avoid using a BOM with UTF-8 files unless you have a specific reason or compatibility requirement. Always prefer UTF-8 without a BOM if possible.
UTF-16 (UTF-16BE & UTF-16LE)
For UTF-16, the BOM is crucial for indicating endianness if the specific endianness is not already defined by the character set label (e.g., if labeled just as "UTF-16").
FE FF: Indicates Big Endian (UTF-16BE).FF FE: Indicates Little Endian (UTF-16LE).- If a UTF-16 stream is read with the wrong endianness, the BOM character
U+FEFFwill appear asU+FFFE, which is a noncharacter. - If the character set is explicitly stated as "UTF-16BE" or "UTF-16LE", a BOM should not be used as the byte order is already known.
- Recommendation: Use a BOM if your UTF-16 data might be interpreted by systems with different native endianness and the specific endianness (BE or LE) is not declared by a higher-level protocol. If the specific UTF-16 encoding (LE or BE) is known and declared, omit the BOM. (However, for HTML, UTF-8 is strongly preferred over UTF-16).
UTF-32 (UTF-32BE & UTF-32LE)
Similar to UTF-16, the BOM in UTF-32 indicates endianness but UTF-32 is rarely used for transmission or web content.
00 00 FE FF: Indicates Big Endian (UTF-32BE).FF FE 00 00: Indicates Little Endian (UTF-32LE).- Recommendation: Similar to UTF-16, use a BOM if endianness is not otherwise specified. (Again, UTF-8 is preferred for HTML).
Detecting the BOM
You can find out whether a page contains a BOM at the start or further down in the content by using the W3C Internationalization Checker. A BOM at the start of the page will be reported in the Information panel. A BOM that is included in the page lower down (typically due to content being added to the page from an external source) will be reported in the Detailed Report section.
You can try looking for a UTF-8 signature in your content in your editor, but if your editor handles the BOM correctly you probably won't be able to see it. With a binary editor capable of displaying the hexadecimal byte values in the file, the UTF-8 signature displays as EF BB BF.
If your editor or browser applies the wrong character encoding to a UTF-8 encoded file with a BOM, you are likely to see a sequence of bytes at the start of the file. These are the bytes that compose BOM represented as the characters those bytes represent in that encoding. With the Latin 1 (ISO 8859-1) character encoding, the signature displays as characters .
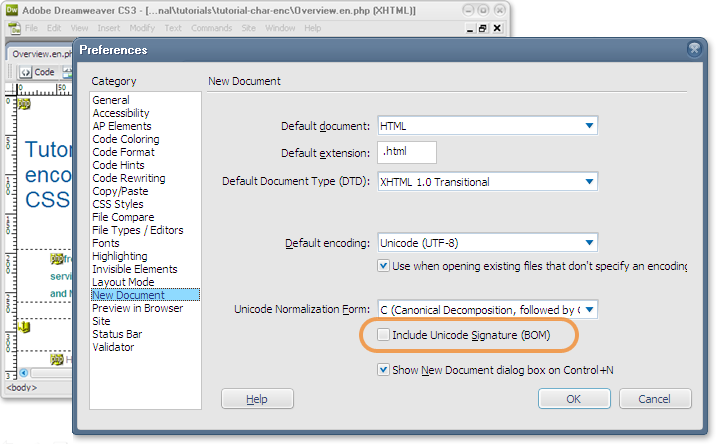
Alternatively, your editor may tell you in a status bar or a menu what encoding your file is in, including information about the presence or not of the UTF-8 signature. For example, if you use Save As in Dreamweaver and your file has a BOM at the start you will see a check mark in the box labeled 'Include Unicode Signature (BOM)'. You can also specify in your preferences (see illustration) whether new documents should use a BOM by default.
Potential issues with the UTF-8 BOM
What follows are some situations where the byte-order mark has been known to cause problems.
In general, these issues are fading away as people adopt newer versions of browsers and editing tools. It is worth knowing about them if your user base still uses older technology. However, this is not solely about legacy issues.
PHP includes
At the time this article was written, if you include some external file in a page using PHP and that file starts with a BOM, it may create blank lines.
This is because the BOM is not stripped before inclusion into the page, and acts like a character occupying a line of text. See an example. In the example, a blank line containing the BOM appears above the first item of included text.
You should ensure that the included files do not start with a BOM.
You may also find that the BOM causes problems for an ordinary PHP page. When sending custom HTTP headers the code to set the header must be called before output begins. A BOM at the start of the file causes the page to begin output before the header command is interpreted, and may lead to error messages and other problems in the displayed page.
Processing with program code
You need to be careful to take the BOM into account in scripts or program code that automatically process files that start with a BOM. For example, when pattern matching at the start of a file that begins with a BOM you need additional code to test for the presence of the BOM and ignore it if found.
The UTF-8 encoding without a BOM has the property that a document which contains only characters from the US-ASCII range is encoded byte-for-byte the same way as the same document encoded using the US-ASCII encoding. Such a document can be processed and understood when encoded either as UTF-8 or as US-ASCII. Adding a BOM inserts additional non-ASCII bytes, so this is no longer true. If you have processes or scripts that assume that the content is comprised of US-ASCII characters only, you will need to avoid the BOM.
HTTP precedence
Changes introduced with HTML5 mean that the byte-order mark overrides any encoding declaration in the HTTP header when detecting the encoding of an HTML page. This can be very useful when the author of the page cannot control the character encoding setting of the server, or is unaware of its effect, and the server is declaring pages to be in an encoding other than UTF-8. If the BOM has a higher precedence than the HTTP headers, the page should be correctly identified as UTF-8.
At the time of writing, not all browsers do this, so you should not rely on all readers of your page benefitting from this just yet.
Previous versions of Internet Explorer gave the BOM precedence over HTTP, but IE10 and IE11 gave a higher precedence to HTTP.
In browsers where the HTTP header still overrides the byte-order mark and the server is declaring pages to have a non-Unicode character encoding, you are likely to find unexpected characters at the start of the page (such as  in a page labelled in HTTP as ISO 8859-1) as well as problems displaying non-ASCII characters on the page.
Other issues
If you use applications or scripts in the back end of your site you should check that they are also able to recognize and handle the BOM.
We strongly recommend that you don't change the encoding of a UTF-8 file from a Unicode encoding to a non-Unicode encoding, but if you do (for some exceptional reason), you must ensure that the BOM is removed. If you don't, either the browser will continue to treat your content as UTF-8, or you will see strange characters at the beginning of the page.
Removing the BOM
If you need to remove the BOM, check whether your editor allows you to specify whether a UTF-8 signature is added or kept while you save the file. Such an editor provides a way of removing the signature by simply reading the file in then saving it out again. For example, in editors such as Notepad++ on Windows and BBEdit on the Mac, it is possible to select the encoding from a list while using the Save As function. The list has options to save as UTF-8 with or without the BOM. Just choose the option without the BOM and save.
One of the benefits of using a script is that you can remove the signature quickly, and from multiple files. In fact the script could be run automatically as part of your process.
Note: You should check the process impact of removing the signature. It may be that some part of your content development process relies on the use of the signature to indicate that a file is in UTF-8. Bear in mind also that pages with a high proportion of Latin characters may look correct superficially but that occasional characters outside the ASCII range (U+0000 to U+007F) may be incorrectly encoded.