Details
Applying an encoding to your content
Content authors should declare the character encoding of their pages using one of the methods described in Declaring character encodings in HTML.
However, it is important to understand that just declaring an encoding inside a document or on the server won't actually change the bytes; you need to save the text in that encoding to apply it to your content. (The declaration just helps the browser interpret the sequences of bytes in which the text is stored.)
If necessary, set up UTF-8 as the default for new documents in your editor. The picture below shows how you would do that in the preferences of an editor such as Dreamweaver.
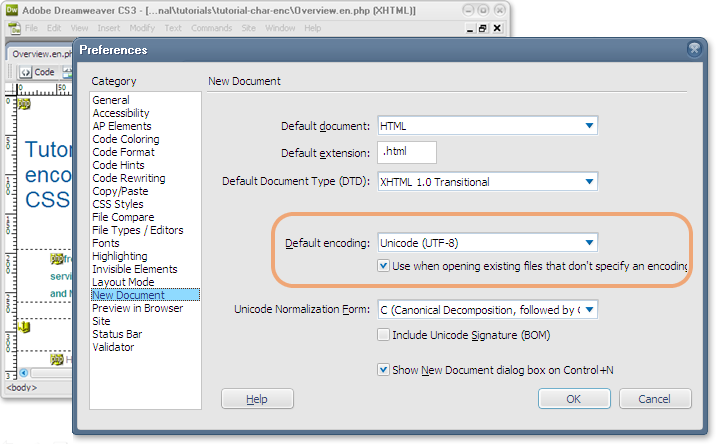
You may also need to check that your server is serving documents with the right HTTP declarations, since it will override the in-document information (see below).
Developers also need to ensure that the various parts of the system can communicate with each other. Web pages must be able to communicate seamlessly with back-end scripts, databases, and such. These, of course, all work best with UTF-8, too. Developers can find a detailed set of things to consider in the article Migrating to Unicode.
Why use UTF-8?
An HTML page can only be in one encoding. You cannot encode different parts of a document in different encodings.
A Unicode-based encoding such as UTF-8 can support many languages and can accommodate pages and forms in any mixture of those languages. Its use also eliminates the need for server-side logic to individually determine the character encoding for each page served or each incoming form submission. This significantly reduces the complexity of dealing with a multilingual site or application.
A Unicode encoding also allows many more languages to be mixed on a single page than any other choice of encoding.
Any barriers to using Unicode are very low these days. In fact, in January 2012 Google reported that over 60% of the Web in their sample of several billion pages was now using UTF-8. Add to that the figure for ASCII-only web pages (since ASCII is a subset of UTF-8), and the figure rises to around 80%.
There are three different Unicode character encodings: UTF-8, UTF-16 and UTF-32. Of these three, only UTF-8 should be used for Web content. The HTML5 specification says "Authors are encouraged to use UTF-8. Conformance checkers may advise authors against using legacy encodings. Authoring tools should default to using UTF-8 for newly-created documents."
Note, in particular, that all ASCII characters in UTF-8 use exactly the same bytes as an ASCII encoding, which often helps with interoperability and backwards compatibility.
Taking the HTTP header into account
Any character encoding declaration in the HTTP header will override declarations inside the page. If the HTTP header declares an encoding that is not the same as the one you want to use for your content this will cause a problem unless you are able to change the server settings.
You may not have control over the declarations that come with the HTTP header, and may have to contact the people who manage the server for help. On the other hand there are sometimes ways you can fix things on the server if you have limited access to server setup files or are generating pages using scripting languages. For example, see Setting the HTTP charset parameter for more information about how to change the encoding information, either locally for a set of files on a server, or for content generated using a scripting language.
Typically, before doing so, you need to check whether the HTTP header is actually declaring the character encoding. You could use the W3C Internationalization Checker to find out what character encoding, if any, is specified in the HTTP header. Alternatively, the article Checking HTTP Headers points to some other tools for checking the encoding information passed by the server.