Appendix A Ruby Extension Specification
This appendix looks at various possible models for marking up ruby, with a view to informing discussion about the models found in the HTML5 draft of 25 October 2012 and the proposed Ruby Extension Spec as of 27 February 2013.
The most up-to-date version of this information is maintained at http://www.w3.org/International/notes/ruby-extension/.
This also provides a foundation for the development of future guidelines for authors on how to mark up ruby, and for development of basic ruby tests.
Each bullet point in the examples represents the boundary of an element: red represents text in an rb element; orange represents text in rt elements. All other elements are shown as markup.
I highlighted where one approach does not conform to either the HTML5 current spec, or the proposed new extension spec, so you can quickly see where the differences are.
A-1 Compound nouns
This section just looks at the order of rb elements (coloured red) and rt elements (coloured orange) without the tags themselves. Bullet points show the element boundaries. The next section looks at details about how to use rb and rt tags.
Expected outcome: either  (mono-ruby), or
(mono-ruby), or  (juguko-styled)
(juguko-styled)
1.1 One ruby element per base character.
<ruby>法•ほ</ruby><ruby>華•け</ruby><ruby>経•きょう</ruby>です
法華経です
HTML5 conformant. Ruby Annotation conformant. Ruby extension conformant.
Currently renders mono ruby as expected in: IE, Chrome, Safari
Fallback: On an ignorant browser, puts rt between base characters. Adding rp elements would be time consuming, but possible. Automatically moving rt elements to the end of the ruby element would not buy you anything.
Note: This is a pain to author, because of all the ruby tags. It also precludes the possibility of jukugo styling for a compound noun.
1.2 One ruby element per 'word', interleaved rb and rt
<ruby>法•ほ•華•け•経•きょう</ruby>です
法華経です
HTML5 conformant. Not Ruby Annotation conformant. Ruby extension conformant.
Currently renders mono ruby as expected in: IE, Chrome, Safari
Fallback: On an ignorant browser, puts rt between base characters. You can add rp elements round each rt but it would be a chore to do it manually. You could easily add parens with styling, if styles available. A browser or JavaScript routine could display all rt text after the ruby element.
Note: This would allow for jukugo styling to be applied across the compound noun. This approach would be useful if you wanted inline ruby to associate ruby text with each base character – which may be the case for educational usage, or for bopomofo.
1.3 One ruby element per 'word', grouped rb tags.
<ruby>法•華•経•ほ•け•きょう</ruby>です
法華経です
Not HTML5 conformant. Not Ruby Annotation conformant. Ruby extension conformant.
Currently renders as expected in: NO browser
Fallback: On an ignorant browser, puts rt together after all base characters. You can add a set of rp elements which would surround all the rt text - this provides some editing relief for those who put in rp elements manually. You could add parens with styling, if styles available, but you'd need a slightly more complicated selector, since it would have to find the first and last rt element.
Notes: This is pretty easy to author as long as the ruby element isn't too long. As the length increases, the chance of misalignment by the author also increases. It also allows for jukugo styling of a compound noun. If you want inline ruby to put ruby text at the end of each compound word, rather than after each ruby base, then this would be the way to mark things up.
A-2 Compound nouns - internal markup
This section looks at the use of tags, rather than the order of those tags (which is the focus of the other sections on this page).
Expected outcome: 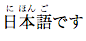
2.1 rb and rt tags, with end tags
<ruby><rb>法</rb><rt>ほ</rt><rb>華</rb><rt>け</rt><rb>経</rb><rt>きょう</rt></ruby>です
日本語です
Not HTML5 conformant. Not Ruby Annotation conformant. Ruby extension conformant.
Currently renders mono ruby as expected in: IE, Chrome, Safari
Notes: This uses all possible ruby tags (excluding the rp element). It is a pain to author and to read due to all the tags, and is unlikely to be recommended.
2.2 No rb tags, start and end tags for rt.
<ruby>日<rt>に</rt>本<rt>ほん</rt>語<rt>ご</rt></ruby>です
日本語です
HTML5 conformant. Not Ruby Annotation conformant. Ruby extension conformant.
Currently renders mono ruby as expected in: IE, Chrome, Safari
Notes: This is somewhat easier to author, and because it uses no rb tags is the only approach that is HTML5 conformant. The use of closing rt tags, however, detracts from ease of use and readability. A significant disadvantage of this approach, however, is that the lack of rb tags makes it difficult to style ruby bases for things like accessibility rendering.
2.3 rb and rt start tags, but no end tags.
<ruby><rb>日<rt>に<rb>本<rt>ほん<rb>語<rt>ご</ruby>です
日です
Not HTML5 conformant. Not Ruby Annotation conformant. Ruby extension conformant.
Currently renders as expected in: NO browser
Notes: This is the easiest so far to author and read. You can also omit the first <rb> if you want the markup to be even shorter, but this may lead to problems if you want to style the ruby bases later, especially when you want to do a blanket conversion for, say, accessibility reasons.
2.4 One ruby element per 'word', grouped rb tags, no end tags.
<ruby><rb>日<rb>本<rb>語<rt>に<rt>ほん<rt>ご</ruby>です
日本語です
Not HTML5 conformant. Not Ruby Annotation conformant. Ruby extension conformant.
Currently renders as expected in: NO browser
Notes: This is the equivalent of the previous markup approach but applied to the rb.rb.rt.rt model. You can also omit the first <rb> if you want the markup to be even shorter, but this may lead to problems if you want to style the ruby bases later, especially when you want to do a blanket conversion for, say, accessibility reasons.
A-3 Compound phrases
Multiple kanji compound words can form one compound phrase. In this case, there are two ways to attach ruby, i.e. attaching ruby to the compound phrase as a whole, or to each word which forms the compound. Similarly, a Japanese personal name consists of a given name and a family name, which together form a compound of a full name, and it is an editorial decision whether to attach two runs of ruby, one each for given name and family name, or to attach the full ruby text to the compound which represents the reading of the full name.
Expected outcome: either  (mono-ruby), or
(mono-ruby), or  (jukugo-styled across phrase), or
(jukugo-styled across phrase), or  (jukugo-styled by word)
(jukugo-styled by word)
3.1 One ruby element per compound word.
<ruby>常•じょう•用•よう</ruby><ruby>漢•かん•字•じ</ruby><ruby>表•ひょう</ruby>は
常用漢字表は
HTML5 conformant. Not Ruby Annotation conformant. Ruby extension conformant.
Currently renders mono ruby as expected in: IE, Chrome, Safari
Fallback: On an ignorant browser, just puts rt between base characters. A browser or JavaScript routine could display all rt text after the ruby element, but would not gather all to the end of the compound phrase.
Notes: This prevents you from applying jukugo styling across the compound phrase. It could only be applied to each compound noun.
3.2 One ruby element per compound phrase, with interleaved rb/rt.
<ruby>常•じょう•用•よう•漢•かん•字•じ•表•ひょう</ruby>は
常用漢字表は
HTML5 conformant. Not Ruby Annotation conformant. Ruby extension conformant.
Currently renders mono ruby as expected in: IE, Chrome, Safari
Fallback: On an ignorant browser, just puts rt between base characters. A browser or JavaScript routine could display all rt text after the ruby element, and that would gather all to the end of the compound phrase.
Notes: This allows the application of jukugo styling across the compound phrase, but rules out compound word specific jukugo styling.
3.3 Compound word specific tags.
<ruby>常•用•漢•字•表•じょう•よう•かん•じ•ひょう</ruby>は
常用漢字表
Not HTML5 conformant. Not Ruby Annotation conformant. Ruby extension conformant.
Currently renders mono ruby as expected in: NO browser
Fallback: On an ignorant browser, puts rt text together at the end of the compound phrase. You can't display ruby text after each compound noun. You could use multiple pairs of rp tags, but it's not clear that that would produce anything useful.
Notes: Although it would be possible to achieve jukugo across the compound phrase, it would be impossible to switch to style jukugo on a compound word by compound word basis.
3.4 Compound word specific tags.
<ruby>常•用•じょう•よう•漢•字•かん•じ•表•ひょう</ruby>は
常用漢字表
Not HTML5 conformant. Not Ruby Annotation conformant. Ruby extension conformant.
Currently renders mono ruby as expected in: NO browser
Fallback: On an ignorant browser, puts rt text together at the end of each compound noun.
Notes: This is probably the most useful approach if you are concerned about sensible fallback. It is also the only approach that allows jukugo in the phrase to be separated by each compound noun boundary. The browser would need to know how to combine ruby text across the whole ruby element if you want to apply jukugo across the whole compound phrase.
Expected outcome: 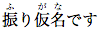
3.5 ruby only around kanji.
<ruby>振•ふ</ruby>り<ruby>仮•が•名•な</ruby>です
振り仮名です
HTML5 conformant. Not Ruby Annotation conformant. Ruby extension conformant.
Currently renders as expected in: IE, Chrome, Safari
Notes: Not clear whether inline ruby would be expected to display two groups of rt or one for this example. One is not possible with this approach.
3.6 One ruby element per 'word', empty rt after り.
<ruby>振•ふ•り••仮•が•名•な</ruby>です
振り仮名です
HTML5 conformant(?). Not Ruby Annotation conformant. Ruby extension conformant (?).
Currently renders as expected in: IE, Chrome, Safari
Notes: If ruby were extracted and placed at end of compound noun it would be missing the RI character. Note that two bullet points side by side indicate an empty rt element.
3.7 One ruby element per 'word', grouped rb tags, empty rt corresponding toり.
<ruby>振•り•仮•名•ふ••が•な</ruby>です
振り仮名です
Not HTML5 conformant. Not Ruby Annotation conformant. Ruby extension conformant(?).
Currently renders as expected in: NO browser
Notes: By default ruby text appears at end of compound noun when inline, but is missing the RI character. Note that two bullet points side by side indicate an empty rt element.
A-4 Double-sided ruby
Expected outcome: 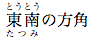
4.1 Two mono-ruby texts above, one group ruby below, embedded ruby.
<ruby><ruby>東•とう•南•なん</ruby>たつみ</ruby>の方角
東南の方角
HTML5 conformant. Not Ruby Annotation conformant. Not ruby extension conformant.
Currently renders ruby as expected in: Chrome, Safari
(except that the group ruby is above the other ruby, rather than the other side of the base - CSS is needed for this).
Fallback: puts mono-ruby between base characters, and group ruby after everything.
4.2 Two mono-ruby texts above, one group ruby below, using rtc.
<ruby>東•南•とう•なん<rtc>たつみ</rtc></ruby>の方角
東南の方角
Not HTML5 conformant. Not Ruby Annotation conformant. Ruby extension conformant.
Currently renders ruby as expected in: NO broswer
Fallback: puts all ruby text after all base characters.
Expected outcome: 
4.3 Two mono-ruby texts above, two mono-ruby texts below, using multiple rts.
<ruby>東•とう•tou•南•なん•nan</ruby>の方角
東南の方角
HTML5 conformant. Not Ruby Annotation conformant. Not ruby extension conformant.
Currently renders ruby as expected in: NO broswer
Fallback: puts both mono-ruby texts alongside each base character.
4.4 Two mono-ruby texts above, two mono-ruby texts below, using multiple rtc.
<ruby>東•とう<rtc>tou</rtc>南•なん<rtc>nan</rtc>/ruby>の方角
東
南
の方角
Not HTML5 conformant. Not Ruby Annotation conformant. Ruby extension conformant.
Currently renders ruby as expected in: NO broswer
Fallback: puts both mono-ruby texts alongside each base character.
4.5 Two mono-ruby texts above, two mono-ruby texts below, using one rtc.
<ruby>東•南•とう•なん<rtc>tou•nan</ruby>の方角
東南の方角
Not HTML5 conformant. Not Ruby Annotation conformant. Ruby extension conformant.
Currently renders ruby as expected in: NO broswer
Fallback: puts all ruby text after all base characters.
Expected outcome: 
4.6 Single mono-ruby above, group ruby below across two base characters.
<ruby><ruby>護•まも•れ</ruby>プロテゴ</ruby>!
護れ!
HTML5 conformant. Not Ruby Annotation conformant. Not ruby extension conformant.
Currently renders ruby as expected in: Chrome, Safari
(except that the group ruby is above the other ruby, rather than the other side of the base - CSS is needed for this).
Fallback: puts mono-ruby between base characters, and group ruby after everything. This actually helps in this case because the hiragana base character is in the right place.
4.7 Single mono-ruby above, group ruby below across two base characters.
<ruby>護•れ•まも<rtc>プロテゴ</ruby>!
護れ!
Not HTML5 conformant. Ruby Annotation conformant. Ruby extension conformant.
Currently renders ruby as expected in: NO broswer
Fallback: puts all ruby text after all base characters. There is a problem for fallback because the hiragana base character comes between the kanji and its ruby text.
Notes: With respect to the fallback behaviour, this seems to be a use case where the HTML5 approach actually works better than the extension spec approach.


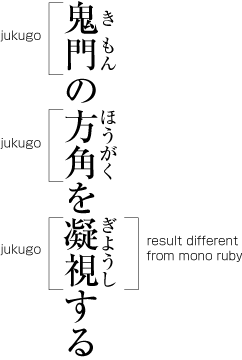

{kind=link}
{kind=link}
{kind=link}