See also: IRC log
JeniT: first session about templating
... jenit talking about thw work during the day
ivan_: talking about the simple mapping
datatype mapping is complicated
ivan_: datatype mapping is complicated
<danbri> see also https://github.com/w3c/csvw/issues https://github.com/w3c/csvw/labels/CSV%20to%20RDF/JSON%20mapping and nearby
<ivan_> http://www.w3.org/2014/Talks/1028-CSVW-IH/Overview.html
gkellogg: picture strings for validation
ivan_: we shoud nor have rdf or xml in the syntax
... row level templates and table templates
... talking about the simplest template...
... ...talking about teh table level and the row level...
<JeniT> compare to http://liquidmarkup.org/
ivan_: explainig flters line unix piping
... recursion is complicated
... typical filters: upper, lower, row_number, replace etc.
... the arguments itself are strings
... presenting some examples
... I have implemented a jquery extension...
<AxelPolleres> http://iherman.github.io/CSVPlus/test-templateonly.html
ivan_: listing possible additions as for
example escape characters in templates
... another example: inclusion of URI template
gkellogg: asking about using promises
<AxelPolleres> ivan, one possible other issue/conflict I see is when (slide 6) global keys have the same name as column names.
danbri: looking more to rdf mappings
... moustache needs javascript objects
ivan_: my first implementation uses moustache; I had to extract the data in the metadata
... you have to extract the data and transform to a format that moustache understands
JeniT: if you do a implementation in moustache and uses the json object, it is possible to use in moustache?
ivan_: moustache ask for a simple name:value pairs
<danbri> [according to http://stackoverflow.com/questions/8912540/how-to-access-nested-objects-with-mustache-js-templating-engine you can go deeper into js(on) structures with mustache]
ivan_: the way I used is a replace to a
simple mapping
... mapping
jtandy: the metadata needs to reference the template
JeniT: has a template media-type
... templates have to media_type:
... targetType: application/json
... templateType: application/mustache
ivan_: what does the template apply
<JeniT> http://www.w3.org/ns/formats/
danbri: Is there a spec for URIs for media types?
<ivan_> http://www.w3.org/ns/formats/
<JeniT> http://www.iana.org/assignments/media-types/application/cdmi-queue
<phila> See also the European Union publications office that is defining URIs for file formats that goes beyond media types http://publications.europa.eu/mdr/authority/file-type/index.html
<danbri> JSON-LD -> http://www.iana.org/assignments/media-types/application/ld+json
JeniT: use URI for targetType and templateType
<danbri> 1 . https://github.com/w3c/csvw/blob/gh-pages/examples/tests/scenarios/events/source/events-listing.csv
<danbri> 2. https://github.com/w3c/csvw/blob/gh-pages/examples/tests/scenarios/events/output/expected-triples.txt
<ericP> OWL 2 Primer gives readers a serialization choice
danbri: explaining a r2rml example
ivan_: fits nice to the cross references
laufer: You're saying that this is an RDB and you're using R2RML
... but these things are in CSV files or RDB?
danbri: Actually, I had to create the CSVs as the Chinook DB only gives you the RDB
laufer: There are lots of tools to do that
... you have the relational database, you have a lot of tools available
<danbri> (see https://github.com/w3c/csvw/blob/gh-pages/examples/tests/scenarios/chinook/chinook_tocsv.sh for the sqlite to CSV script)
ivan_: templates applies to the output or directed in the data
JeniT: if you have a csv generated from and excel file so you nedd one more type: a sourceType
ivan_: the simple mapping of rdf does not defines the serialization
ivan_: The templateType is now a URL that identifies a processor ID
<danbri> me: targetType is overloaded — a media type is in a different kind of thing
ivan_: that works on the data
... and the processor tells you what else should be included, but we cannot really define that
jtandy: We need a name to be able to say I want to use this template, so each template needs to have an ID
... that might only be a textual description of what it does
JeniT: In other places, you might want a title
jtandy: Yesterday we talked about the need
to pre-process a CSV before you parse it. That's a different kettle of
fish
... we could say that if you need to do that then it's out of scope for
this
... my example was a CSV that had separate columns for months and days
that need to be merged which is hard for templating
... I'd like to be able to do that but ...
JeniT: So you;re asking whether we should have a similar mechanism for processing the input as we're talking about for the output
<danbri> (i'm not going to over-argue for it now, but overloading targetType media type to say "Dublin Core" etc seems absolutely the wrong place for that detail, and a URI is needed alongside name/title/blurb etc.)
ivan_: That's doable with your URL templates
jtandy: But I want a triple derived from values in two cells but in the simple mapping we're talking about 2 triples
JeniT: By the template on the output should give you control over that?
jtandy: It may be an edge case to require pre-processing, but I'd still like simple mapping ro deal with that seemingly simple case
JeniT: So I've heard reqs: 1create to more than one object from each row; 2 to create one output from two cells
ivan_: The second is covered by the URI template
gkellogg: To create a URI, yes, but not, say, a date
JeniT: I think we need to make a scoping decision on this
ivan_: I'm afraid of opening the gates of hell...
AxelPolleres: These 2 reqs are doable with
R2RML or the templating
... is that something we can scope with a fragment of R2RML?
danbri: The turtle I showed had a lot of
complication & redundancy there was
... what I'd like to be able to do is take that as a JSON format and
generate the R2RML from it
ivan_: As soon as we begin to go into
specifying this and that feature - that's what we did all spring
... we keep re-doing this
... I think we should take what's there as simply as possible
... defining a proper subset of R2RML is a lot of work
<danbri> I propose to strike from the charter, "The output of the mapping mechanism for RDF MUST be consistent with either the http://www.w3.org/TR/rdb-direct-mapping/ or http://www.w3.org/TR/r2rml/ so that if a table from a relational database is exported as CSV and then mapped it produces semantically identical data."
ivan_: If we want to go into more complex
templates then we need to go through the exercise I did and I showed
that there is still more to do.
... we don't have the capacity to do that
... that's my frustration
... 6 months haggling around the conversion side
gkellogg: I'm also wary of something ugly.
We've more or less decided to using the URI template.
... I've looked at extending that to cover strings, not just URIs
... I couldn't find an implementation in Ruby - it wasn't too
challenging to do it
ivan_: We're running ahead into the next
session here
... but I'd say we take the Template RFC as is and leave it as is
... what it gives us is where we stop
... I put up an answer to something Jeremy sent round. I included a
reference to a list of implementations of that RFC in many languages
<AxelPolleres> Can we do the same with R2RML (i.e. just refer to it via providing a “hook”)? Do we have that hook already?
ivan_: we do a disservice if we fiddle around with it
<Zakim> danbri, you wanted to read from charter, "The output of the mapping mechanism for RDF MUST be consistent with either the http://www.w3.org/TR/rdb-direct-mapping/ or
danbri: I wanted to make a tech point and a
process point
... I triggered a rant from you on what I thought was uncontentious. A
paragraph could describe what it would look like in R2RML
... Quotes the charter on relationship with RDB and R2RML
ivan_: In the back of my mind - if you want to do RDF then we should be compatible with the simple mapping
AxelPolleres: Do we have a hook for referring just to an R2RML mapping?
danbri: Nearly, yes - it's on the whiteboard
jtandy: Having listened, I understand the
nervousness... but I am thinking about how I could help deliver
... I don't think it's going to be uncommon to flag a column as a do not
process
<AxelPolleres> hook to R2RML is enough to fullfill the charter, right? a shortcut notation/nicer syntax for some restricted fragment of R2RML is something somebody else could do later on…
Reference to UK Gov time periods
<danbri> see also http://en.wikipedia.org/wiki/Data_URI_scheme
jtandy: If what you wanted to do was to create a string then wouldn't the templating stuff be helpful
<danbri> data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAUAAAAFCAYAAACNbyblAAAAHElEQVQI12P4//8/w38GIAXDIBKE0DHxgljNBAAO9TXL0Y4OHwAAAABJRU5ErkJggg==
ivan_: I guess the implementations are string to string mapping with a few tricks to make them URIs
jtandy: It does have a few issues - escaping special characters tec/
JeniT: I would like a decision on...
PROPOSED: For now, and without limiting our future work, that we scope to the simplest possible thing that might work and therefore do not have multi-object per line or multiple columns per line
ivan_: If I put the CSV into Oracle and I run the direct mapping, and I take the CSV and run the simple mapping, then the two outputs must be equivalent graphs
<AxelPolleres> IMHO, s/equivalent/entailed/ …
<AxelPolleres> … because of some extra triples we might have.
danbri: If our templating said here's how to generate DC, we should perhaps have a paragraph that says these are similar but not the same as R2RML
AxelPolleres: The question is whether more complex things are in the spec or just say that it can be done
ivan_: Writing a Note on how these things can be done in R2RML is fine - but we have to do it
<danbri> Axel, let's look at that in coffee break. see https://github.com/mmlab/RMLProcessor/blob/master/src/main/java/be/ugent/mmlab/rml/core/RMLMappingFactory.java#L94
<JeniT> PROPOSED: For now, and without limiting our future work, that we scope to the simplest possible thing that might work and therefore do not have multi-object per line or multiple columns per line
<JeniT> +1
<ivan_> +1
<gkellogg> +1
<ericstephan> +1
<danbri> 0
<JeniT> PROPOSED: For now, and without limiting our future work, that we scope to the simplest possible thing that might work and therefore do not have multi-object per line or multiple columns per value
<AxelPolleres> +0 (as I find the proposal quite abstract)
<bill-ingram> +1
<jtandy> 0 ... accepting the need to drive for simplicity
<ivan_> +1
<danbri> +0.9
<jtandy> +1 ... "without limiting our future work"
<ivan_> RESOLUTION: For now, and without limiting our future work, that we scope to the simplest possible thing that might work and therefore do not have multi-object per line or multiple columns per value
<danbri> phila: let's get these possible work items into SOTD of the relevant spec(s)
<danbri> phila: I'd like to use this to help attract more effort towards adding these features - "this is limited because" … with an URL for that, so I can send it around to potential contributors
<JeniT> ACTION: jtandy and ivan to add some text in the mapping spec(s) to indicate the limit in scope and the other features that could be added given more capacity [recorded in http://www.w3.org/2014/10/28-csvw-minutes.html#action02]
<trackbot> Created ACTION-43 - And ivan to add some text in the mapping spec(s) to indicate the limit in scope and the other features that could be added given more capacity [on Jeremy Tandy - due 2014-11-04].
ivan_: A certain time has to pass between FPWD and going to CR - and we don't even have a FPWD
JeniT: So we need to get to FPWD ASAP to allow that period to pass
<jtandy> some of that future work might include being able to use SPARQL Property Paths [http://www.w3.org/TR/sparql11-query/#propertypaths] instead just a simple RDF predicate when defining the semantics relating to a particular column ... and some magic to conflate intermediate blank nodes
gkellogg: It strikes me that if someone has thoughts on how a simple mapping can cover these case then it would be good to know about it
<danbri> suggestion for ivan: add to simple RDF mapping SOTD a sentence saying something like "The WG solicits input on the value of providing a mapping from single CSV rows into multiple inter-related typed entities, rather than all fields becoming properties of a single entity in the output graph."
gkellogg: the alternative is the template mechanism - that can create more complex outputs. Simple things simple, complex things possible
ivan_: For now it's on GiHub, the description is in MarkDown...
JeniT: There's an extension mechanism that we can point to
ivan_: We have less than a year to complete the work
<Zakim> JeniT, you wanted to ask about templates interacting with schemas
gkellogg: If we can't get out of here
because we have not met the use cases... we might have to have a very
slight complication to the simple mapping or a template mech
... and if we can't even specify a template mech than it seems we won't
complete our charter
<AxelPolleres> still don’t understand why we need more than a hook to R2RML where we say that other languages can be plugged in, do we?
jenit: One of the big requirements that we have for creating mappings to RDF, also other formats, is creating URLs/URIs from data within CSV files. A syntax that exists is the URI Templates RFC.
jtandy: [presents slides based on the RFC]
http://lists.w3.org/Archives/Public/public-csv-wg/2014Oct/att-0080/RFC6570-uri-template-overview.pdf
jtandy: … you can run it reverse, harvest
variables (but we're not doing that)
... there are 4 levels. Simple String expansion. "hello World!" ->
Hello%20%21 etc.
percent encoding of chars not in ...
… if I have reserved string expansion, that is a list of chars that dont get converted.
use of +, # etc for special kinds of expansion
<hadleybeeman> https://tools.ietf.org/html/rfc6570
see also http://en.wikipedia.org/wiki/URL_Template
… undefined variables
level 3: simple expansion with multiple variables
comma separated lists
also reserved string expansion with several variables
label expansion: X{.x,Y} => X.1024.768
(discussion of other chars in place of ., e.g. /
{/var,x}/here => /value/124/here
(it has some treatment of ampersands)
{?x,y} => ?x=1024&y=768
jtandy: You can see that they're all for dealing with common URI structures
… it gets more complex. 9/10 of the things you want to do are probably level 1 templates
level 4: you can aske for 3 chars, or 1st 30 chars, {var:3}
true for all combinations, plus signs etc.
level 4 explode modifier
list as an array of values
list: = ("red","green","blue")
jtandy: you can build up some pretty complex things, … can get confusing.
… more details see slides.
hadley: are you proposing adopting the entire thing for identifiers?
jtandy: a q for the group.
… we said didn't want to partly adopt it, as some people have implemented whole thing, … better to say we support the whole thing as-is rather than profiling it
the level 1-4 terminology comes from the spec, i.e. RFC 6570
jtandy: I imagine all 4 will be useful at some stage
… there are a healthy number of implementations
jtandy: nothing I read in RFC said "you can't use this for dealing with string transformations"
danbri: any risk re i18n if we used it beyond its intended scope?
…apparently it supports IRIs at least
gregg: so this might appear in the metadata document?
jenit: this is point of the discussion now: there are 2 obv places where we might want to generate URLs
(I'll always say URL name… but mean URI/IRI etc)
jenit: if simple mapping rdf, creating identifier for a row, we might want that to be composed from different fields. Other is actual values, esp for RDF but also JSON
… we might want to create urls there
ivan: let's take the 2 separately
… for the rows, what would be the relationship of a template there, and a … [key column value thingy]
… in the metadata today, you have the possibility of … certain columns to be key columns
primary keys
ivan: at moment, the way the mapping is
defined, ..
... see example in document
... if there isn't a primary key its an empty object
if is, uri created with a base, … using dash concatenation
… exact same as in the direct mapping
… if we have additionally possibility to add a row level … [missed]
… which mechanism do i use to define a uri template for a row?
ivan: I can have that, … if doesn't exist and there are primary keys, … otherwise a blank node/empty object
gregg: purpose of primary key is to spec the subject of the result
… why not just a uri templ?
suggestion to make primaryKey a URI template
jenit: primaryKey was copied from JSON Table schema, a column or array
… it is in json table schema, not really defined
… spec doesn't get into validation
ivan: what this tells me: nobody would shout at us if this is what we do
jenit: worth trying that. It might be that rufus objects … worth proposing
ivan: another Q, probably valid for columns, … Do we have one template, or templates per target media types
e.g. into JSON, and only for JSON users, why would I put the example.org, entire URI?
jenit: if you were generating json from this, what does it look like?
ivan: it has the @id, … with the cell value not whole expanded thing
jtandy: logically there is no difference
ivan: yes & no
… the way it works if I produce a JSON, … that there is a base that I put into the @context, and then I use only the expanded part in the object itself
… if ppl don't care about URIs they don't get it (whereas json-ld view will get a URI)
if I use http://example.org/{GID} everyone has to deal with URIs
jenit: my inclination is to say that … if a primary key (or whatever we call it) is specified in this way, or "row ID", … then putting @id on each of the objects within json output is absolutely fine
… if not specified, don't have @id
… equiv of a blank node
ivan: that would be for the rows. For each column(s), rows or cells, i would add a template to generate the value
jenit: e.g. you could have:
<JeniT> "urlTemplate": "http://example.org/species/{species}"
… inside columns
ivan: if for a cell, that key exists, then the expanded one for rdf will be turned into a URI resource.
… and that means if we want to be consistent with the json-ld view, then the json output would be an object with an @id being the URI
jenit: or just the URL
… with possibly a @context
ivan: who puts the context there?
jenit: my inclination is to not generate a @context
jtandy: like "homepage" example yesterday
gregg: i'll always argue that we should output a context to make it json-ld
… so you don't have to concoct a context and manually expand it
jenit: if you really really care about getting some RDF out, use the simple rdf mapping
ivan: is there a JSON-LD "tidy" program?
gregg: by compacting a document it effectively tidies it
ivan: i am perfectly fine then to say that
what we produce as json-ld, we say you'll have to compact it with a
json-ld prociessor
... simplest case, an object with that @id with a URI, and i don't
generate a @context
jenit: I was arguing that we generate something that looks like: "species": "http://example.org/species/ash"
… this would require a context to understand that the value was an URL
… wheres you (ivan) are asking for
"species": { "@id": "http://example.org/species/ash" }
ivan: it's important to represent when something is a URI
… if you want to make it more aesthetic run it through a json-ld compactor
gregg: would it not be unreasonable to add the predicates within each of these things
[missing detail]
ivan: the fact of having a predicate is a diff issue
… what I am concerned about is … what will be the value?
jtandy: if you understand what predicate you are using, you can build the context as you go
… to say that the object of this predicate has to be an @id
gregg: you have "datatype" there; if you said "id" there, it gives you enough to say that "species" takes identifiers not strings
… I don't think that really complicates things
jenit: if you want to stay in an rdf ecosystem, use the rdf mapping
… not make the json mapping all RDFy
if you really want to make some nice json-ld … go via rdf
laufer: … [didn't hear]
(laufer, can you retype your q here?)
… this isn't for linking to other tables?
<hadleybeeman> laufer: Why do you need to map to a URL?
ivan: this is all within one table
danbri: let's let the json bit be json
jenit: if you are creating RDF, you'll get that URL as needed
gregg: am fine with that
… you might use turtle or whatever and generate prefix markup there. So JSON-LD would be handled there.
jtandy: to summarise that, … the JSON mapping is a blunt mapping that web devs who have never seen json-ld could use
… and if you want to get json-ld you have to go via the rdf mapping
(my version: it's not a requirement that the simple json mapping be half-hearted json-ld or full-glory json-ld; we have RDF output for that)
jenit: if you know you're going to be doing prefixes etc as useful in json-ld and turtle, there may need to be specifci metadata properties in the file
e.g. base
<JeniT> PROPOSAL: The simple JSON mapping is a mapping for web developers who don’t care about RDF; to generate JSON-LD, use the RDF mapping and serialise as JSON-LD informed by the metadata file to make a more asthetic result
… whether base for metadata and mappings/output are different
<ivan_> +1
<bill-ingram> +1
<JeniT> +1
suggest "need not care" about
<gkellogg> +1
<jtandy> +1
<ericstephan> +0
+1
<JeniT> PROPOSAL: The simple JSON mapping is a mapping for web developers who need not care about RDF; to generate an RDF serialisation such as JSON-LD, use the RDF mapping and serialise as JSON-LD informed by the metadata file to make a more asthetic result
<jtandy> ... assuming that the implementation supports JSON-LD serialisation for RDF ... or any other RDF serialisation
<ivan_> RESOLUTION: The simple JSON mapping is a mapping for web developers who need not care about RDF; to generate an RDF serialisation such as JSON-LD, use the RDF mapping and serialise as JSON-LD informed by the metadata file to make a more asthetic result
ivan: q: predicate url, … you put it there for a column, can I also put it in a row and a cell?
jtandy: wouldn't make sense as a row, as a row is an array of metadata for the various cells
oops mixed jtandy/ivan comment
jenit: i was going to suggest, going up a separate level, … dropping ability to talk about rows and cells
<JeniT> PROPOSAL: We drop the ability in the schema to specify metadata at the row or cell level: schemas are only used to define columns
<ivan_> +1
<gkellogg> +1
<ericstephan> +1
<bill-ingram> +1
+1
<ivan_> RESOLUTION: We drop the ability in the schema to specify metadata at the row or cell level: schemas are only used to define columns
<jtandy> +1 ... we're talking about the schema definition not a specific instance of a CSV
<JeniT> note: annotations on individual cells within a particular dataset are still enabled through the ‘annotation’ facility we talked about yesterday
<hadleybeeman> +1 as observer, with footnotes/annotations for dealing with deviations from the schema in a specific dataset
jenit: that being the case, predicateURL would be only on column
ivan: in the templates the name means, in the sense of the RFC, … it is turned into a name/value as in your examples, where the name is the col name and the val is the cell value
should i/we extend that to other key value pairs in the metadata
example:
<JeniT> 1,ADDISON AV,Celtis australis,Large Tree Routine Prune,10/18/2010
from metadata/ spec
jenit: if when we use url templates, we have to create vars of the form
(key value pairs from level 4 templates)
(disussion of exact representation asa URI Template)
GID=1
on-street= "Addison AV"
species = "Celtis australis"
trim-cycle = "Large Tree Routine Prune"
inventory-date = "2010-10-18"
jenit: I assume we'll use the normalized form of the data
… ivan's q is whether there are other variables that get set, that can be used in a template
e.g. dc:license
…row number
e.g. _row = "1"
_col = "5"
ivan: tempting to say, any key which has a string value, could be used
… why would we restrain ourselves in a template
ivan: any string valued property
jenit: … using _ to separate metadata on the column vs on the table
… since you could have a 'description' at the table and the column
jenit: there are certain properties that go down to the cell
… datatypes, language, ...
ivan: and these are all relevant things that we want in the uri
jenit: really??
ivan: language you might have diff URIs, e.g. .fr, .de etc., - you want that information
gregg: the issue i thought i was hearing: if there was a description in the col, and at the top level, should you be able to get to either of them in the template?
ivan: I can also imagine that I can construct a URI based on what's u pthere, the id value or something like that, … i.e. the global ID value for the table
… I think that there is no reason to say that we cannot use a specific key that is available for a cell for a uri template
ivan: under what criteria do we say which keys are usable in a URI template and which not?
jenit: just looking at what you might want to refer to, …
ivan: row number can't
… we yesterday said we had a cascading set of metadata
… part of this can be in one file, part in another, for a specific csv file, they are combined
… when I write that file as a human, …
… i know it's all at hand (somewhere)
jtandy: a macro level q here, … what properties are inherited down to the cell level
… which description is available?
… for a cell/column
ivan: next disagreeable conseq of all i said: that the column level URI is also a template
jenit: what's that?
ivan: predicate url
… i might have it distributed
… how it is generated might depend on stuff from another file
… i might want to build up exact path of that URI based on some URI from elsewhere
jenit: I doubt that
ivan: in the metadata json i may have
something which is http://example.org/{@id}/blah
... combining metadata from diff places to give me enough info to build
up the uri
jenit: it would be good to have an example in the mapping document
ivan: reason the metadata.json is sepated in the datamodel
… publisher in same place publishes 10 diff csv files
each csv has its own metadata
one which is common
jenit: full example please!
gregg: if we ever see a uri maybe we should parse it as a template, for consistency?
laufer: a kind of global variables
ivan: origin of those variables is merged into one
<JeniT> ACTION: ivan to create a worked through example for why predicate URLs need to be URL templates, for the simple mapping spec [recorded in http://www.w3.org/2014/10/28-csvw-minutes.html#action03]
<trackbot> Created ACTION-44 - Create a worked through example for why predicate urls need to be url templates, for the simple mapping spec [on Ivan Herman - due 2014-11-04].
gregg: communities using json-ld for activiy streams
[ivan: is this for tables where schema stuff is pushed down into the data?]
[looking at URI templates 2.3. Variables, in RFC]
jenit: we need to be careful about the naming of the cols
<JeniT> naming of columns needs to be constrained as per URL template
jenit: we talked about uri tempaltes for 3 things
url for identifying particular rows (or the objects from those)
… for values particulate cells
… and for predicates
… we talked about the initialization
but didn't go into depth of how we manage things like @id
… where @ is not an allowable char here
or dash
since
varchar = ALPHA / DIGIT / "_" / pct-encoded
… so there is some working through to do about that
ivan: that is a restriction for the end user, not only on us
(discussion re yesterday re unprefixed terms)
jenit: it would be possible for people to refer to it via a percent-encoded colon
… it's quite rare to want to refer to such things, likely
… same goes for @id
… rare to need that
ivan: we should aim for a general decision that we want to use this mechanism
<JeniT> PROPOSAL: We will use URI templates for generating URLs for objects created from rows, for mapping of cell values, and for predicate URIs
+1
<bill-ingram> +1
<ivan_> +1
<JeniT> +1
<hadleybeeman> +1 as observer. I'm all for reusing existing work.
<ericstephan> +1
<Zakim> gkellogg, you wanted to comment on result of templates
<gkellogg> +1
<ivan_> RESOLUTION: We will use URI templates for generating URLs for objects created from rows, for mapping of cell values, and for predicate URIs
<jtandy> +1
gregg; since we have datatyping info, and we know type of col is not iri, we could ...
… i.e. one issue is that result is url that needs percent encoding. If we know type of col e.g. is a string, then part of our processing could be reversing that by unencoding
jenit: is that mixing up the type of the value in the CSV with the type of the value in the target format
gregg: maybe/probably
… but there may be some way to get more use out of the URI templates
jenit: we could have a target datatype
danbri: it's v powerful mechanism, good to use it as much as can
jenit: for you guys to work through in the mapping
ivan: no! it's the metadata doc that has to say, clearly, what metadata applies for a cell. What is inherited, what is not inherited.
jenit: description isn't inherited currently
<jtandy> irrespective of this decision, we still need to determine how one refers to particular metadata value for, say, a given cell - taking into account inheritance from column, table, or import from other metadata docs
ivan: at least we know where we go now, improvement over last 6 months
hadleybeeman: how much of this discussion is referenceable in a way i can point my WG at?
jenit: see metadata spec
also csv2rdf draft of simple mapping
<JeniT> http://w3c.github.io/csvw/csv2rdf/
<JeniT> http://w3c.github.io/csvw/csv2json/
laufer: do you have a doc for templates?
ivan: we don't
... the templates that I did, won't make it as REC from this WG so we
won't have such a doc
https://tools.ietf.org/html/rfc6570
<JeniT> http://lists.w3.org/Archives/Public/public-csv-wg/2014Oct/att-0080/RFC6570-uri-template-overview.pdf
hadleybeeman: in data on the web, struggling to frame discussion around URI construction
gregg: if we added to col metadata, that perhaps references another column to act as the subject for data from that column, … that might be a fairly straight way to get multiple objects
e.g. subject column, or subject url, …
(gregg, can we look at that over lunch with my event example?)
JeniT: introduces the session
... multiple CSV files and multiple related CSV files
... and how we manage them
... should we do this?
... what are the issues here?
two particular examples:
JeniT: 1) chinook example
... 2) use case 4
danbri: is thrown a little here ...
<danbri> https://github.com/w3c/csvw/tree/gh-pages/examples/tests/scenarios/chinook/csv
danbri: chinook is a standard demo database
... packaged as binary database files; Oracle, MySQL etc
... it exists for exactly this discussion; providing an example database
<JeniT> https://github.com/w3c/csvw/tree/gh-pages/examples/tests/scenarios/chinook
<danbri> https://github.com/w3c/csvw/tree/gh-pages/examples/tests/scenarios/chinook/attempts/attempt-1
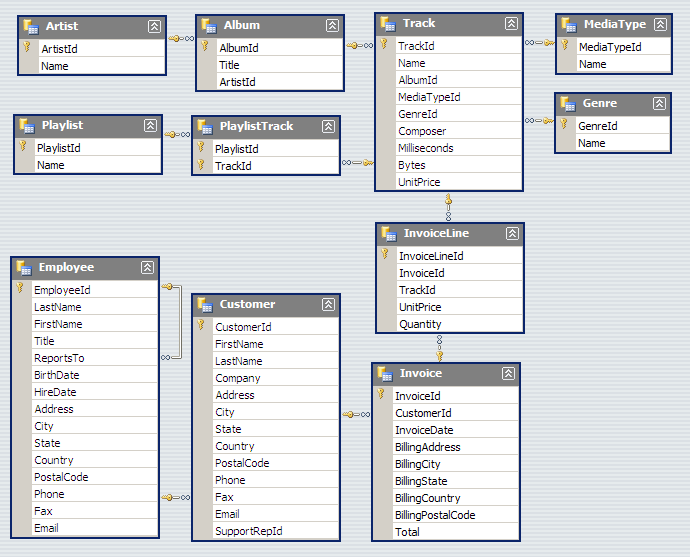
danbri: describes the entity relationship diagram (in link above)
danbri: the only difference here between the
chinook example and the events example (discussed this morning) is
complexity
... the RML works!
... but I don't know how; Anastacia did this one
... the RML doc includes lots of semantic web gibberish, but the output
is simple
... it works!
<danbri> output: https://github.com/w3c/csvw/blob/gh-pages/examples/tests/scenarios/chinook/output/chinook.rml.nt
JeniT: the point here is that each one of
these tables maps to a separate CSV file; and there are links between
the tables
... each CSV file is a dump of the table, and includes links to rows in
other tables; e.g. the "Trackid"
Bernadette: asks a question about packaging CSV files
JeniT: notes that CSVs are typically published as normalised tables - because there is no way to refer between tables
<JeniT> https://developers.google.com/public-data/docs/tutorial
JeniT: another thing to look at is the
(Google) Data Set Publishing Language
... providing another way to link CSV files published as a package
... particularly useful, say, to reference codelists used in one table
whose terms are published in other tables
danbri: the product "Public Data Explorer"
is not being actively developed
... the DSPL is not being actively developed either; their hope is that
the Recommendations from this working group will replace DSPL
JeniT: in which case we need to make sure that our work covers these usecases!
danbri: Google's interest is largely about mapping these datasets into Graphs
JeniT: talks about use case 4
<danbri> re DSPL see also http://lists.w3.org/Archives/Public/public-vocabs/2013Aug/0059.html from Omar Benjelloun, a proposal for a new format in this area
JeniT: this is about public sector salary
information
... two CSV files
... first describes senior roles & provides salary information
... second describes the junior roles that report to the associated
senior role
<JeniT> https://github.com/w3c/csvw/tree/gh-pages/examples/tests/scenarios/uc-4/attempts/attempt-1
JeniT: cross references between them
... The metadata.json includes information about the package of CSV
files
... and talks about each CSV file in turn
... each schema points to a separate schema description - because we
want to reuse these
... each gov department should validate against the same schema!
... what we really want is some way to assert that the "reporting-to"
column in the junior file refers to the senior post in the senior file
gkellogg: can you not just use URIs for this?
JeniT: yes - but is more interested in validation
gkellogg: the URI template used in each file would need to construct the same URIs
jtandy: checks that for validation purposes, we want to assert that a particular senior role used in the junior file _actually_ exists
JeniT: yes
... scribes an example for us to look at
... showing how the URI Template might work
... this doesn't show that the files are related
gkellogg: perhaps you need to create an RDF graph for the senior file and then run a pass through the junior file to see that all the references actually exist
danbri: I think we should have something that doesn't require people to use RDF and create a graph
JeniT: in Attempt 2 (of uc-4) I've tried to
do stuff that might work - as opposed to staying close to the draft spec
... I've normalised out a lot of the data
... example: the organisation stays the same throughout the entire CSV
file
... so I've pulled this out into a separate file
... Also there are separate governance arrangements about each of those
denormalised files ...
... example: there is an authoritative list of gov departments
... centrally there is a defined list of codes
... these are defined once (by central government)
... and are referred to many times
... this is part of getting CSV into the web of data!
... then there are files published by the departments
... things like the organisational units and pay-scales evolve at a
different speed to the _actual_ data
... these have been normalised out too
... so the result is a bunch of denormalised tables
... and the question is: how to build the links between those files?
... it's central government that defines the schema for the junior and
senior role information
... this includes a kind of "abstract schema" for the set of files that
need to be supplied by the gov departments - e.g. the 'units' file
any schema can say that a column references a column in another file
JeniT: property is "reference", example is "units#unit"
ivan: this is what RDBMS people term foreign
keys
... in a database, you can rely on the RDBMS to check integrity against
the foreign key to make sure that the target actually exists
... who will do this consistency checking CSV?
... aren't we reproducing an SQL engine?
JeniT: yes - but only in part ... this kind of validation is very useful
ivan: this ind of validation / checking is problematic because it's so complex
<ericstephan> +q
ivan: the mapping can be done without too much effort - the validation could be done post transformation
<Zakim> danbri, you wanted to ask about array values foo,bar,SCS2, "[OF9, OF-7]", 2014, etc.
JeniT: I would say that it's the job of the validator to do this kind of integrity checking
danbri: I think we have arrays of values in cells? how would this work?
JeniT: this is a question to be resolved - possible mechanisms include checking just the first one, or checking all items
ericstephan: this seems like you wouldn't
want to arbitrarily connect CSVs - it's more like a structured database
where you're interested in the structure
... so the publisher needs to think about these linkages ahead of time -
before publication
JeniT: yes - in the future, you might see gov depts publishing their organogram data and referencing the centrally governed code lists
ericstephan: you'd need to think about the rules [for interrelationships] ahead of publication time
<danbri> fwiw http://w3c.github.io/csvw/use-cases-and-requirements/#UC-ExpressingHierarchyWithinOccupationalListings is also quite related, also code lists for employment
ericstephan: the publication would be distributed, but they will all conform to these governance rules
gkellogg: we also need to think about
sequencing
... some files might be updated out of order and thus create a broken
link
... overly strict validation here would be bad
danbri: non-judgemental validation ...
JeniT: there shouldn't be anything to stop a
mapping just because there's a broken link
... it would be good to run a link checker over CSV data like you can
with HTML
gkellogg: can you replace "reference" with a URL Template?
JeniT: in this example we have a link
explicitly specified
... need to work through some examples to bottom this out
ivan: in SQL you make a clear declaration on
both sides
... for one table you say "this is the column that is a foreign key" and
"that this the target that this column points to"
<ivan> IN sql: FOREIGN KEY("addr") REFERENCES "Addresses"("ID")
ivan: the role of primary key is to act as a
target for a foreign key
... this allows me to say that I can only use column declared as a
primary key
gkellogg: no - a foreign key can point to any arbitrary column with a unique key ... doesn't have to be a primary key
<danbri> Consider: ListTableKeyStructure.c http://www.easysoft.com/developer/languages/c/examples/ListTableKeyStructure.html
<danbri> * For a given src table,
<danbri> * it shows the primary key field details
<danbri> * it shows foreign keys in other tables that reference primary
<danbri> * key of the src table
<danbri> * it shows foreign keys in the src table that refer to the primary
<danbri> * keys of other tables
JeniT: JSON table schema does have primary
key and foreign key
... example: http://dataprotocols.org/json-table-schema/#foreign-keys
ivan: so in this RDB direct mapping, we have foreign keys, when you generate a triple, the URI must be the same as is constructed for the corresponding row
<Zakim> danbri, you wanted to suggest ODBC have been all over this territory, e.g. http://www.easysoft.com/developer/languages/c/examples/ListTableKeyStructure.html
ivan: I should be executing the URI template expressed for the remote table and use this for the local value
JeniT: would like to see some more worked examples here
danbri: the other people who have thought
about this are the RDBMS community
... let's talk to these folks
... I will talk to Kingsley to see if there's anything obvious we're
tripping over
gkellogg: there's also "tall ted"
ivan: the existing direct mapping provides
one scheme - this is probably hairy to implement \
... especially with (very) large tables
JeniT: let's try to do some worked examples
... we also talked about "loose linking"; so we only need to get the URI
template from the remote table
<JeniT> FOREIGN KEY("addr") REFERENCES "Addresses"("ID")
<JeniT> template: “http://example.org/{ID}”
<JeniT> substitute ‘ID’ for ‘addr’
ivan: so ... rufus' specification for foreign key plus this substitution mechanism works - but does it satisfy the requirement?
JeniT: in the uc-4 example, I don't want to
say that "this specific file links to that specific csv file"; I want to
say this at the schema level in an abstract form
... this case is not satisfied
<danbri> [ok I talked to Kingsley at OpenLink. He says what I sketched sounds sensible and will review any detailed spec I email. Also suggests the original ODBC specs from Microsoft are the best b/g reading], "the GetInfo (Metadata) calls handle everything there is in regards to Tables". ]
JeniT: but I could rework the example
... to see if it will work
ivan: do we have then concept of simple mapping for the entire collection of csv files?
<danbri> [re ODBC, http://msdn.microsoft.com/en-us/library/ms711681(v=vs.85).aspx was the ref from Kingsley]
ivan: each table would be processed as discussed earlier, but the result would be expressed as one graph or one array of json objects for the entire collection
ericstephan: scientists do this all the time
when working with spreadsheets - they put keys on each sheet and
manually do the linkage
... this method would really help move people away from publishing
spreadsheets as blobs on the web
JeniT: the organogram data is based on spreadsheets
[JeniT shows the spreadsheet example]
JeniT: various fields only allow one to choose values from specific tables ... this would be really useful functionality to have with CSV
danbri: knows people who have web applications that look a lot like this
JeniT: is there any thing else?
... Tabular Data Package uses "resources" array to refer to the set of
csv files
Bernadette: each CSV file is a resource?
JeniT: yes ...
Bernadette: and the whole set is the dataset?
JeniT: we don't use the term dataset because
it's overloaded - we have the Grouped Tabular model
... DCAT's use of the term dataset is ambiguous ...
... there's lots of different usages
gkellogg: does every row in a CSV file have an explicit identifer?
ivan: yes ... and let's say that any thing
that is referenced as a foreign key must provide a URI Template [and not
be a blank node]
... it's a very understandable requirement that targets of a foreign key
must have a URI Template
gkellogg: how should the mapping work for JSON where foreign keys are used? should the referenced object be embedded?
JeniT: it might be a good idea to explore
how this will work
... in converting to JSON, we could have one object per row in the CSV,
each with an identifier
... and publish that as an array of objects
... alternatively, we could create an object that contains an indexed
list of the identifiers for each row
<JeniT> [{
<JeniT> "@id": "foo"
<JeniT> },{
<JeniT> "@id": "bar"
<JeniT> "ref": "foo"
<JeniT> }]
<JeniT> {
<JeniT> "foo": {
<JeniT> "@id": "foo"
<JeniT> },
<JeniT> "bar": {
<JeniT> "@id": "bar",
<JeniT> "ref": "foo"
<JeniT> }
<JeniT> }
gkellogg: including the subject index list is one of the more demanded upgrade features for JSON-LD
ivan: what this tells me is that we may have
to have a separate set of metadata for the entire collection; global
data for everything
... could we just use DCAT for this?
JeniT: we would need to expand what we have
already to deal with global packages
... and stick with yesterday's decision to keep our metadata minimal and
push the choice of descriptive metadata out of our scope
<danbri> [aside for minutes: Rob from Annotations group reported back at lunch to say that their group agrees to the suggestions we made yesterday w.r.t. 'body' taking literal values]
<JeniT> ACTION: JeniT to amend uc-4 example to use the foreignKey pattern from json table schema [recorded in http://www.w3.org/2014/10/28-csvw-minutes.html#action04]
<trackbot> Created ACTION-45 - Amend uc-4 example to use the foreignkey pattern from json table schema [on Jeni Tennison - due 2014-11-04].
<JeniT> ACTION: JeniT to put foreignKey stuff into metadata document [recorded in http://www.w3.org/2014/10/28-csvw-minutes.html#action05]
<trackbot> Created ACTION-46 - Put foreignkey stuff into metadata document [on Jeni Tennison - due 2014-11-04].
<JeniT> ACTION: jtandy and ivan to work out how foreign keys get applied when mapping into RDF / JSON [recorded in http://www.w3.org/2014/10/28-csvw-minutes.html#action06]
<trackbot> Created ACTION-47 - And ivan to work out how foreign keys get applied when mapping into rdf / json [on Jeremy Tandy - due 2014-11-04].
<laufer> bye all... nice to meet you... cheers
JeniT: we talked yesterday about implementations; as part of w3c process where we have normative implementations
…we have to have to be able to demonstrate that we have a good set of tests and a test harness
gkellogg: found a document: w3c testing howto — good to look through
<JeniT> Gregg’s presentation: http://lists.w3.org/Archives/Public/public-csv-wg/2014Oct/att-0092/CSVW-TPAC-2014.pdf
…testing he's be involved with tend to use a similar test manifest, which seeks to provide metadata about the tests
<JeniT> W3C Testing How To: http://w3c.github.io/testing-how-to/#(1)
…test runner can determine the type of process that should be run
…we have syntax tests as well as deeper, analysis tests
…syntax test takes a single input; the output should match the expected byte-for-byte
…return type is true or false
…developers generally write their own test harnesses
gkellogg: shows tests in ruby rspec and in earl
<danbri> EARL = http://www.w3.org/2001/03/earl/
ivan: nice thing about rdf-a tests was that they generated the earl reports automatically
gkellogg: there is an online test harness we developed for rdf-a
…rdf-a is quite configurable
…user creates an endpoint that makes requests and accepts results
…implementers will need to create an endpoint that will provide the csvs
JeniT: how are errors reported?
ivan: there are two or three defined errors, and then a bunch of undefined (e.g., syntax errors)
gkellogg: people develop these thigns, they run the tests, and submit reports
…results are collated into an implementation report that shows, for each test, the expected results and the actual
gkellogg: this is an automatic process
…this is, of course, and open tool; it's not only open source — it's public domain
ivan: one addition: the rdf-a development was incredibly useful that the test harness was running *way* before we started implementations
…it was incredibly useful; we shoudl have something like this running ASAP
gkellogg: suggest running all tests in the browser
<Zakim> danbri, you wanted to mention tests as a tool for documenting consensus / closing issues; e.g. http://www.w3.org/2000/03/rdf-tracking/#rdf-ns-prefix-confusion
danbri: talk about experience of the rdf core group
…emphasis on using tests as a tool for consensus
gkellogg: agrees; very useful to have tests first
…if nothing else, you can create a placeholder for the tests to come back to
gkellogg: volunteers to work on tests
…certainly curating the test infrastructure and assist in making tests
JeniT: we all agree testing infrastructure will be beneficial; what are the steps to get us there?
gkellogg: the hurdle is hosting resources, etc, plus we need at least one example of an online implementation
JeniT: ivan is not doing a reference implementation; Andy might be; I might be
…a null implementation can be any web page
gkellogg: need to be clear about processing nodes, inputs, outputs
ivan: for those things, greg, you are in the driving seats. you should tell us what you'd like to see
<JeniT> q?
…details forthcoming
JeniT: three types of tests: validation tests, rdf tests, json test
gkellogg: and then how do we specificy an error? what is the format of an error?
…this is more about the test harness interface; people will expect that it behave in some way
JeniT: csvlink.io/validation
…csvlint provides a report in json
gkellogg: if you expect json, then the error results should also be in json
JeniT: this is a standalone validator that creates json report, html report, and a nice little badge
…tbd how much information should be returned; suspect we'd want to have proper error codes, same error codes as in the spec
<Zakim> danbri, you wanted to ask about testing the more IETF parts (bytes to tabular model)
danbri: in an ideal world, we'd test everything, vigorously; but what do we do about itf?
…how do we test the parser?
JeniT: out of our scope
<JeniT> https://github.com/maxogden/csv-spectrum
JeniT: this has a bunch of csv files that are horrible, and I'm sure that extra ones could be added
danbri: he uses json?
JeniT: so, there are csv testing, but suggest we should concentrate on what we're testing for
<danbri> e.g. https://github.com/maxogden/csv-spectrum/blob/master/csvs/quotes_and_newlines.csv -> https://github.com/maxogden/csv-spectrum/blob/master/json/quotes_and_newlines.json
JeniT: proposes some area of the github repo for tests
gkellogg: and a separate repo for the test harness itself
…it would be useful to have at least a trivial example of what a test would be
JeniT: we have 45 mins now — would it be useful to work that out?
…lots of crosstalk about types of tests
JeniT: stuff happening in tag — we're looking at test mechanisms that, when a file is requested, instead of returning just that file, return the other artifacts related to that file
…e.g., for html file would also include images, js, etc
…can use the package to populate your local cache, as if you requested all those resources in a GET
…i'd be in favor of not packaging these files — should we take out the reference to packaging?
…we don't specify a particular packaging format
jtandy_: we won't describe the packaging and unpackaging
ivan: if i want to access a file that happens to be in a package, for me as a user, this is invisible
…I don't care if the file happens to be in a package
…this is the direction, in which case we should not talk about packaging separately
<danbri> [we don't explicitly say that our stuff can be served via FTP, HTTP, gopher:, sent by email; so I'm happy equally not enumerating *.tar.gz vs *.zip etc.]
jtandy_: we're more interested in a single metadata that corresponds to a set of files
<JeniT> PROPOSAL: We remove referencing packaging (except as a note) in the Data Model WD
<danbri> +1
<ivan> +1
+1
<JeniT> +1
<jtandy_> +1
<ivan> RESOLUTION: We remove referencing packaging (except as a note) in the Data Model WD
<ericstephan_> +1
<gkellogg> +1
JeniT: going back to our list of test types: syntax, validation, locating metadata
jtandy_: locating metadata introduces complexity
ivan: suggests we use metadata location as our first set of tests
danbri: then other tests can assume the metadata has been located and aggregated?
JeniT: aggregation is separate
ivan: i think it's related
danbri: we're only testing simple mapping
<AxelPolleres> mapping via hook to r2rml could be handled by reference to the r2rml test suite?
danbri: would it work to use pos/neg sparql?
gkellogg: we're typically going to be generating relatively simple rdf
…but sparql is possible, but my experience with it is that people don't generally write good sparql
JeniT: types again are: syntax, validation, locating metadata, simple mapping to rdf, json
jtandy_: there may be a simple mapping to xml
gkellogg: doable
AxelPolleres: do we want to test r2rml?
danbri: complexity is that you could have several possible mappings, whereas with simple there would be one
jtandy_: maybe included in simple mapping, but we need to test mapping in the absence of metadata
<danbri> danbri: one issue is e.g. with 'advanced mappings' like https://github.com/w3c/csvw/blob/gh-pages/examples/tests/scenarios/chinook/attempts/attempt-1/chinook.rml.ttl whether the template file carries the paths to the CSV files directly, vs. whether they are somehow passed to the relevant interpreter as additional args from our metadata description.
ivan: thinks that animal doesn't exist — always will have at least the column names
<danbri> re testing jSON, see https://github.com/mirkokiefer/canonical-json "Canonical JSON means that the same object should always be stringified to the exact same string. JavaScripts native JSON.stringify does not guarantee any order for object keys when serializing…"
jtandy_: you can guarantee that somebody will not provide *external* metadata — so will validation include testing for minimal metadata?
<danbri> (see also https://github.com/davidchambers/CANON)
…we will have to assume the first row is the column names — we need to have a test that shows the minimal metadata, and one that does not have the minimal, which will fail
gkellogg: we will need to initialize the csv parser, so we'll need that our test data is proper csv
JeniT: csv+
…non-normative, but does define what must be in order to be a csv+
jtandy_: so all of our test files will conform to this non-normative section, and we can always build from there
<danbri> (for another time: suggest renaming 'CSV+' to 'WebCSV')
JeniT: because we're dealing with multiple csv and manifests, suggests using subdirectories
gkellogg: doesn't particularly matter for the test runner
JeniT: but it does matter for metadata location
gkellogg: agrees
…but still it isn't necessary, but is more convenient for the people managing the tests
<Zakim> danbri, you wanted to ask whether someone deploying our metadata vocab in RDFa HTML manifests could claim to be conforming to a W3C standard
danbri: if somebody chose to publish csv with rdf-a file next to it, could they say they conform to our vocabulary?
gkellogg: we want to have a vocabulary with our terms
JeniT: we're specifying the json format, implicit in it is each of those terms
gkellogg: json-ld we're using should be able to round-trip to rdf-a
ivan: need to be careful that our terms are used in the graph we are specifying
AxelPolleres: what if the metadata file is in turtle?
ivan: I'd be surprised if our metadata tools are used as an rdf graph
<Zakim> AxelPolleres, you wanted to ask about round-trippability of our JSON->RDF->JSON
…our terms are only valid n our serializatioin
gkellogg: specify that it shouldn't be roundtripped, but it could be
…it requires framing
ivan: good that it's in json-ld because can be put into a triplestore
<Zakim> danbri, you wanted to ask about MAYMUST with @vocab
<danbri> I took https://raw.githubusercontent.com/w3c/csvw/gh-pages/examples/tests/scenarios/uc-4/attempts/attempt-1/metadata.json and json-playground
danbri: will this group pick a url for the vocab? who's going to write the document for that?
JeniT: intention is to have a context json file
ivan: we don't yet have http://www.w3.org/ns/csvw; that's for the end of our process
JeniT: good progress in getting gkellogg to volunteer
…come back in 1/4 hour for administrative, wrap-up, etc
<Zakim> AxelPolleres, you wanted to volunteer to attempt RDF2CSVmetadataJSON implementation, if anybody else also finds that useful :-)
<JeniT> ACTION: AxelPolleres to follow up on round-tripping metadata.json into RDF and out again [recorded in http://www.w3.org/2014/10/28-csvw-minutes.html#action07]
<trackbot> Created ACTION-48 - Follow up on round-tripping metadata.json into rdf and out again [on Axel Polleres - due 2014-11-04].
<JeniT> some of the files from the sessions today: https://gist.github.com/JeniT/147021e4408db090326f
<JeniT> https://gist.github.com/JeniT/147021e4408db090326f
<ivan> scribenick: ericstephan
JenIt: Goal of last session wrap up of F2F and talk about participation
Ivan: If we keep to the schedule as is we
should be in August proposed recommendation end of June. Even though it
is only 4 weeks voting it is summer
... Would be good if it was second half of Apri with CR
Jen: Would be good to have two or 3 working drafts going forward
Ivan: Yes, for the conversion document,
talked with Jeremy if we have a conversion doc done before new year that
would be good
... Another one about Feb 2015
... The important thing is the CR second half of April the rec could be
published within our limits.
Jen: In order to get through our CR we need
two independent implementations
... Biggest barrier we have right now. Question to the group, who is
planning on doing the implementation
Ivan: If we don't make it by the end of
August 2015, and we say we need more time for testing, then I don't
think it would be a problem. If the spec work is done.
... However if we only have working drafts, then the management might
not be in favor of extension.
Jeni: ODI will do an implementation of validation against metadata statements.
Danbri: Google will do testing as well.
gkellogg: I will do some testing as well.
Jtandy: I cannot commit at this time.
Bill: I want to volunteer I don't know what I could do.....
Jeni: If you could write an implementation using your own software.
Ivan: It could be as simple as taking a CSV
file and producing RDF or JSON
... You can use what you'd like, preference for javascript....
bill: I could use Ruby
Ivan: I've been looking for a project to use javascript.
Scratch last comment that was from Bill
Ivan: Bill you could check out my code, perhaps as a starting point.
<danbri> me: if there is a basic js implementation i'll make time to plug it into Google Docs spreadsheets 3rd party developer addons system
JeniT would you be willing to do all three tests for validation, mapping to RDF mapping to Json
Ivan: anything on the xml stuff?
Jen: Liam said every few months they have
someone pop up on the xml channel.
... We need to mark it as a risk
Danbri: We need to relay this to management
<JeniT> PROPOSAL: We will label conversion of CSV to XML as an at risk feature
<ivan> +1
+1
<jtandy> +1
<JeniT> +1
<danbri> bill-ingram, see https://developers.google.com/apps-script/guides/sheets and nearby. Anyone can add custom js functions to spreadsheets for others to re-use.
<danbri> +1
<gkellogg> +1
jtandy: because the json and rdf mapping are different we cannot merge the documents.
<AxelPolleres> +1
<ivan> RESOLUTION: We will label conversion of CSV to XML as an at risk feature
Jen: Axel - do you want to do something?
Axel: The mapping work I think I could do.
Jen: There is the existing work around data
package implementation (relating to Ivan asking about Rufus helping)
... It is likely that Ivan will help out on data package.
<JeniT> ericstephan: we might be able to implement things that we have to do anyway
Eric: I'll do the mapping work for rdf and json
Jeni: By Christmas would be good.
<danbri> http://en.wikipedia.org/wiki/Data_Format_Description_Language
<Zakim> AxelPolleres, you wanted to ask about character encodings again.
jtandy/Jeni: there is follow up on Alf and Andy
<Zakim> danbri, you wanted to ask re MS
Jeni: Axel we'll tai to metadata re CSV parsing in about 10 minutes
danbri: He has a contact at Microsoft for
knowledge graph, do we have a broader conversion with them that would be
useful?
... Should we be asking for more?
Jeni: It would be good if they supported
import and export of UTF8 correctly
... In terms of editing of specs, the use cases and requirements we have
Jeremy and Eric and Davide working on it.
Jeremy: After the specs we go back and tidy up the doc and we should be good.
Jeni: model spec in pretty good shape, the
bits around CSV parsing was good. Will continue to work on that.
... Metadata spec that Rufus is co-editor, there is still quite a lot of
work to do. Some examples need to be included. I would like to have
another editor on that.
... Validation and mapping pieces will come out for that one.
Ivan: DO you think it is realistic, sometime mid-December we publish 4 documents.
Jeni: Yes
... this is draft documents.
Eric: I can help with the metadata spec.
Jeni: after the decisions have come out, the parts that would be helpful is bringing out the examples.
Ivan: Do we know if Andy plans any implementations?
Jeni: Yes I think so, but I don't know.
... The other two specs are the mapping to json and rdf.
Ivan: May have a draft mid-December of mapping documents.
<danbri> re Jena, the summerofcode thing was http://mvnrepository.com/artifact/org.apache.jena/jena-csv/1.0.0
Ivan: It would be really good to have some examples going forward. If there are examples you are using elsewhere we could use this in the examples.
gkellogg: We could also put this in the test manifest.
jtandy: It would be really good to have real working examples for people to try out would be great.
Jeni: We still need to cover: calls what would make them more useful? When our next f2f meeting? How do we get more people involved?
danbri: some groups don't meet every week, we aren't obliged to meet every week. some groups meet by email.
<JeniT> PROPOSAL: We reserve 1 hour at 15:00 UK time on Wednesdays
<danbri> +1
<bill-ingram> +1
<gkellogg> +1
+1
<AxelPolleres> 0 (no time until end of january, teaching)
<JeniT> +1
<ivan> +1
<chunming_> +1
<jtandy> +1
<ivan> RESOLVED: We reserve 1 hour at 15:00 UK time on Wednesdays
<ivan> RESOLUTION: We reserve 1 hour at 15:00 UK time on Wednesdays
Jeni: Back to Dan's point do we have a meeting every week?
+q
Ivan: I am happy doing work on the mailing list, I'm just not convinced we have enough practice working on the mailing list.
Jtandy: Find it helpful having meetings hearing what is going on.
gkellogg: I wonder how much we can get done just through the mailing list.
PROPOSAL: We continue on with the calls and review this in a couple of months.
<danbri> +1
<ivan> +1
+1
<bill-ingram> +1
<jtandy> +1
<gkellogg> +1
<JeniT> +1
<AxelPolleres> +1
<ivan> RESOLUTION: We continue on with the calls and review this in a couple of months
Jeni: Would be helpful that the editors come to meeting ready to ask questions
Ivan: For the time being we have a bunch of issues in the document, in the W3C tracker, and issues in github and issues in the emailing list. Pretty chaotic
<danbri> https://github.com/w3c/csvw/issues
Ivan: Lets be consistent what ever we used
<danbri> https://www.w3.org/2013/csvw/track/
gkellogg: Everyone was happy in my other work in github. You can put comments in commits, you don't get automated emails in tracker...
<AxelPolleres> +1 to ivan, for member like me who only manage to follow occasionally (for which reason I also don’t want to raise strong opinions here), this makes it hard to get an overview
gkellogg: Don't remember how judicious we were in json-ld...
Ivan: You can make document and github issues, Jeremy showed me.
PROPOSED: Create github issues for every issue in a document. That we use tracker for actions outside documents that are administrative.
<jtandy> +1
<jtandy> what about the repo for the test harness?
<gkellogg> ACTION: gkellogg to investigate GitHub/ReSpec issue linkage [recorded in http://www.w3.org/2014/10/28-csvw-minutes.html#action08]
<trackbot> Created ACTION-49 - Investigate github/respec issue linkage [on Gregg Kellogg - due 2014-11-05].
PROPOSED: Create github issues for every issue in a document. That we use tracker for actions outside documents that are administrative. We make sure we close the issues when we resolve them
<danbri> see also https://www.w3.org/wiki/Guide/GitHub
<danbri> also https://github.com/github/github-services/blob/master/lib/services/irc.rb offers some IRC integration
Ivan: attempting find ways of binding w3c issues with github issues and reported back to group mailing list.
Jeni: Would like to have a convention about where we discuss issues on github or issue tracker...
<gkellogg> +1
<danbri> +1
<ivan> +0.5
jtandy: If something comes in on the mailing list, editor will create an issue in github and drive the traffic onto the github thread
+1
<JeniT> +1
<Zakim> AxelPolleres, you wanted to ask about tracker vs. github?
<AxelPolleres> 0 (not enought information)
<jtandy> +1
axel: now are the issues not tied to the issue tracker?
<ivan> RESOLUTION: Create github issues for every issue in a document. That we use tracker for actions outside documents that are administrative
Ivan: I will send out to administration for changing the time.
Jeni: Early march 2015 F2F meeting in London?
<danbri> looking for related events, http://ec.europa.eu/research/index.cfm?pg=events&eventcode=2860176A-DF7E-0A6B-C70C2DB5F95F12ED "the future for Open Access and the move towards Open Data
<danbri> 26 March 2015, London"
<AxelPolleres> +1 to week of Feb 16th
Ivan: I might be in US around that time. Week of mid February would work.
jeni: February 12-13 might be another option?
<JeniT> ACTION: JeniT to propose 12/13th Feb for CSV F2F on mailing list [recorded in http://www.w3.org/2014/10/28-csvw-minutes.html#action09]
<trackbot> Created ACTION-50 - Propose 12/13th feb for csv f2f on mailing list [on Jeni Tennison - due 2014-11-05].
Jeni: Reachout, who do we reach out to?
Jtandy: Sheet to RDF working group looking
for standardization activities. (sheet as in spreadsheet)
... They should be able to contribute
Axel: What about other countries?
Jeni: Axel could you reach out?
<JeniT> ACTION: AxelPolleres to reach out to other open data portals to join the group [recorded in http://www.w3.org/2014/10/28-csvw-minutes.html#action10]
<trackbot> Created ACTION-51 - Reach out to other open data portals to join the group [on Axel Polleres - due 2014-11-05].
<JeniT> ACTION: jtandy to reach out to UKGovLD Group to join the group [recorded in http://www.w3.org/2014/10/28-csvw-minutes.html#action11]
<trackbot> Created ACTION-52 - Reach out to ukgovld group to join the group [on Jeremy Tandy - due 2014-11-05].
<JeniT> ACTION: ericstephan to talk to Bernadette about getting students to do some stuff [recorded in http://www.w3.org/2014/10/28-csvw-minutes.html#action12]
<trackbot> Created ACTION-53 - Talk to bernadette about getting students to do some stuff [on Eric Stephan - due 2014-11-05].
<JeniT> ACTION: danbri and JeniT to talk to members of the group about being more active [recorded in http://www.w3.org/2014/10/28-csvw-minutes.html#action13]
<trackbot> Created ACTION-54 - And jenit to talk to members of the group about being more active [on Dan Brickley - due 2014-11-05].
chunming just joined the group perhaps he would be interested in talking.
<JeniT> ACTION: Danbri to set up a community group around template mapping syntaxes [recorded in http://www.w3.org/2014/10/28-csvw-minutes.html#action14]
<trackbot> Created ACTION-55 - Set up a community group around template mapping syntaxes [on Dan Brickley - due 2014-11-05].
Jeni: We have 15 minutes left and we will
talk about metadata re CSV parsing with Axel
... We currently have a non-normative section on parsing tabular data
(section 5)
... We have in the metadata document an issue (issue 6) that we intend
to have a small set up sub properties to indicate how a CSV file should
be parsed.
... by way of contrast in the data protocols.org doc we have a CSV
dialect Description Format (CSVDDF)
<danbri> http://dataprotocols.org/csv-dialect/
Jeni: It has some of the properties from that longer list.
Axel: if we adopt this list that would resolve the issue...
Jeni: I propose we have non-normative hints about addressing this issue rather than being normative which would infer test suites etc.
Axel: I would prefer encoding requirements.
Jeni: Our charter does not cover parsing a CSV file ....
Ivan: In the informative part in the model plus the parsing algorithm, the metadata just gives you info like the encoding. You can say this is optional ....
jeni: We would not be expecting any implementation to use the encoding, you can use it.
Axel: Of course I would want that to be of an implementation....
Ivan: for the purpose of what we want to use the metadata for, the separator doesn't even come up.
Jeni: What would be really useful for the people who want to do this is for the people who want the encoding write a specification.
Axel: I am fine with it being non-normative.
<Zakim> danbri, you wanted to ask about "parsing csv" properties and Excel/GoogleDocs import wizards - can we ask those product teams what info they'd hope to see?
Jtandy: Really suggest reaching out to yakov and getting involved in his working group.
<AxelPolleres> if issue 6 and other parsing properties that optionally can override wrong header infos is adopted in an non-normative section, then I am fine.
jtandy: We use the separator later in the document for a different meaning. Can we change the name from separator to delimiter?
jeni: Should we be specifying other properties here?
jtandy: extra header rows
danbri: what about row count?
jeni: for QA there is issue 7 on the sub resource integrity.
www.w3.org/TR/SRI
Jeni: my inclination would be not to do it...
<AxelPolleres> Can we simply propose to have optional metadata-keys for each of the properties mentioned in http://w3c.github.io/csvw/syntax/#parsing?
Axel: With the intended meaning to override ...
<JeniT> PROPOSE: We mirror all the CSV parsing configuration specified in the model document as properties within an object in the metadata document
<ivan> +1
<AxelPolleres> +1
+1
<JeniT> +1
<bill-ingram> +1
<gkellogg> +1
<jtandy> +1
<ivan> RESOLUTION: We mirror all the CSV parsing configuration specified in the model document as properties within an object in the metadata document
<danbri> +1
jtandy: No one has to implement it being non-normative
Jeni: Thank you all for coming.
{kind=link}