ericP's notes on: Constraints of the Provenance Data Model
notes on 11 September 2012 LC
- annotated version:
- http://www.w3.org/TR/2012/WD-prov-constraints-20120911/
Provenance is information about entities, activities, and people involved in producing a piece of data or thing, which can be used to form assessments about its quality, reliability or trustworthiness. PROV-DM is the conceptual data model that forms a basis for the W3C provenance (PROV) family of specifications.
This document defines a subset of PROV instances called valid PROV instances. The intent of validation is ensure that a PROV instance represents a history of objects and their interactions which is consistent, and thus safe to use for the purpose of logical reasoning and other kinds of analysis. Valid PROV instances satisfy certain definitions, inferences, and constraints. These definitions, inferences, and constraints provide a measure of consistency checking for provenance and reasoning over provenance. They can also be used to normalize PROV instances to forms that can easily be compared in order to determine whether two PROV instances are equivalent. Validity and equivalence are also defined for PROV bundles (that is, named instances) and documents (that is, a toplevel instance together with zero or more bundles).
elided
This specification identifies features at risk related to the at-risk Mention feature of [PROV-DM]: Inference 22 (mention-specialization-inference) and Constraint 31 (unique-mention). These might be removed from PROV-CONSTRAINTS.
This document was published by the Provenance Working Group as a Last Call Working Draft. This document is intended to become a W3C Recommendation. If you wish to make comments regarding this document, please send them to public-prov-comments@w3.org (subscribe, archives). The Last Call period ends 10 October 2012. All feedback is welcome.
Publication as a Working Draft does not imply endorsement by the W3C Membership. This is a draft document and may be updated, replaced or obsoleted by other documents at any time. It is inappropriate to cite this document as other than work in progress.
This is a Last Call Working Draft and thus the Working Group has determined that this document has satisfied the relevant technical requirements and is sufficiently stable to advance through the Technical Recommendation process.
This document was produced by a group operating under the 5 February 2004 W3C Patent Policy. W3C maintains a public list of any patent disclosures made in connection with the deliverables of the group; that page also includes instructions for disclosing a patent. An individual who has actual knowledge of a patent which the individual believes contains Essential Claim(s) must disclose the information in accordance with section 6 of the W3C Patent Policy.
Provenance is a record that describes the people, institutions, entities, and activities involved in producing, influencing, or delivering a piece of data or a thing. This document complements the PROV-DM specification [PROV-DM] that defines a data model for provenance on the Web.
The key words "must", "must not", "required", "shall", "shall not", "should", "should not", "recommended", "may", and "optional" in this document are to be interpreted as described in [RFC2119].
In this document, logical formulas contain variables written as lower-case identifiers. Some of these variables are written beginning with the underscore character _, by convention, to indicate that they appear only once in the formula. Such variables are provided merely as an aid to the reader.
The PROV Data Model, PROV-DM, is a conceptual data model for provenance, which is realizable using different representations such as PROV-N and PROV-O. A PROV document is a set of PROV statements, together with zero or more bundles, or named sets of statements. For example, a PROV document could be a .provn document, the result of a query, a triple store containing PROV statements in RDF, etc. A PROV instance is a set of PROV statements. The PROV-DM specification [PROV-DM] imposes minimal requirements upon PROV instances. A valid PROV instance corresponds to a consistent history of objects and interactions to which logical reasoning can be safely applied. By default, PROV instances need not be valid.
This document specifies definitions of some provenance statements in terms of others, inferences over PROV instances that applications may employ, and also defines a class of valid PROV instances by specifying constraints that valid PROV instances must satisfy. There are four kinds of constraints: uniqueness constraints, event ordering constraints, impossibility constraints, and type constraints. Further discussion of the semantics of PROV statements, which justifies the definitions, inferences and constraints, can be found in the formal semantics [PROV-SEM].
We define validity and equivalence in terms of a concept called normalization. Definitions, inferences, and uniqueness constraints can be applied to normalize PROV instances, and event ordering, typing, and impossibility constraints can be checked on the normal form to determine validity. Equivalence of two PROV instances can be determined by comparing their normal forms. For PROV documents, validity and equivalence amount to checking the validity or pairwise equivalence of their respective documents.
This document outlines an algorithm for validity checking based on normalization. Applications may implement validity and equivalence checking using normalization, as suggested here, or in any other way as long as the same instances or documents are considered valid or equivalent, respectively.
Checking validity or equivalence are recommended, but not required, for applications compliant with PROV. This specification defines how validity and equivalence are to be checked, if an application elects to support them at all. Applications producing provenance should ensure that it is valid, and similarly applications consuming provenance may reject provenance that is not valid. Applications which are determining whether PROV instances or documents convey the same information should check equivalence as specified here, and should treat equivalent instances or documents in the same way.
Section 2 gives a brief rationale for the definitions, inferences and constraints.
Section 3 summarizes the requirements for compliance with this document, which are specified in detail in the rest of the document.
Section 4 presents definitions and inferences. Definitions allow replacing shorthand notation in [PROV-N] with more explicit and complete statements; inferences allow adding new facts representing implicit knowledge about the structure of provenance.
Section 5 presents four kinds of constraints, uniqueness constraints that prescribe that certain statements must be unique within PROV instances, event ordering constraints that require that the records in a PROV instance are consistent with a sensible ordering of events relating the activities, entities and agents involved, impossibility constraints that forbid certain patterns of statements in valid PROV instances, and type constraints that classify the types of identifiers in valid PROV instances.
Section 6 defines the notions of validity, equivalence and normalization.
The audience for this document is the same as for [PROV-DM]: developers and users who wish to create, process, share or integrate provenance records on the (Semantic) Web. Not all PROV-compliant applications need to perform inferences or check validity when processing provenance. However, applications that create or transform provenance should attempt to produce valid provenance, to make it more useful to other applications by ruling out nonsensical or inconsistent information.
This document assumes familiarity with [PROV-DM] and employs the [PROV-N] notation.
This section is non-normative.
This section gives a high-level rationale that provides some further background for the constraints, but does not affect the technical content of the rest of the specification.
One of the central challenges in representing provenance information is how to deal with change. Real-world objects, information objects and Web resources change over time, and the characteristics that make them identifiable in a given situation are sometimes subject to change as well. PROV allows for things to be described in different ways, with different descriptions of their state.
An entity is a thing one wants to provide provenance for and whose situation in the world is described by some fixed attributes. An entity has a lifetime, defined as the period between its generation event and its invalidation event. An entity's attributes are established when the entity is created and (partially) describe the entity's situation and state during the entirety of the entity's lifetime. Does this atomicity make it impractical to describe a continuously evolving entity like a SPARQL graph store?
A different entity (perhaps representing a different user or system perspective) may fix other aspects of the same thing, and its provenance may be different. Different entities that fix aspects of the same thing are called alternates, and the PROV relations of specializationOf and alternateOf can be used to link such entities. Must alternates agree on the lifetime of an entity?
Besides entities, a variety of other PROV objects have attributes, including activity, generation, usage, invalidation, start, end, communication, attribution, association, delegation, and derivation. Each object has an associated duration interval (which may be a single time point), and attribute-value pairs for a given object are expected to be descriptions that hold for the object's duration.
However, the attributes of entities have special meaning because they are considered to be fixed aspects of underlying, changing things. This motivates constraints on alternateOf and specializationOf relating the attribute values of different entities.
In order to describe the provenance of something during an interval over which relevant attributes of the thing are not fixed, a PROV instance would describe multiple entities, each with its own identifier, lifetime, and fixed attributes, and express dependencies between the various entities using events. For example, in order to describe the provenance of several versions of a document, involving attributes such as authorship that change over time, one can use different entities for the versions linked by appropriate generation, usage, revision, and invalidation events.
There is no assumption that the set of attributes listed in an entity statement is complete, nor that the attributes are independent or orthogonal of s/of/to/ each other. Similarly, there is no assumption that the attributes of an entity uniquely identify it. Two different entities that present the same aspects of possibly different things can have the same attributes; this leads to potential ambiguity, which is mitigated through the use of identifiers.
An activity's lifetime is delimited by its start and its end events. It occurs over an interval delimited by two instantaneous events. However, an activity statement need not mention start or end time information, because they may not be known. An activity's attribute-value pairs are expected to describe the activity's situation during its lifetime.
An activity is not an entity. Indeed, an entity exists in full at any point in its lifetime, persists during this interval, and preserves the characteristics provided. In contrast, an activity is something that occurs, happens, unfolds, or develops through time. This distinction is similar to the distinction between 'continuant' and 'occurrent' in logic [Logic].
Although time is important for provenance, provenance can be used in many different contexts within individual systems and across the Web. Different systems may use different clocks which may not be precisely synchronized, so when provenance statements are combined by different systems, an application may not be able to align the times involved to a single global timeline. Hence, PROV is designed to minimize assumptions about time. Instead, PROV talks about (identified) events.
The PROV data model is implicitly based on a notion of instantaneous events (or just events), that mark transitions in the world. Events include generation, usage, or invalidation of entities, as well as start or end of activities. This notion of event is not first-class in the data model, but it is useful for explaining its other concepts and its semantics [PROV-SEM]. Thus, events help justify inferences on provenance as well as validity constraints indicating when provenance is self-consistent.
Five kinds of instantaneous events are used in PROV. The activity start and activity end events delimit the beginning and the end of activities, respectively. The entity generation, entity usage, and entity invalidation events apply to entities, and the generation and invalidation events delimit the lifetime of an entity. More precisely:
An activity start event is the instantaneous event that marks the instant an activity starts.
An activity end event is the instantaneous event that marks the instant an activity ends.
An entity generation event is the instantaneous event that marks the final instant of an entity's creation timespan, after which it is available for use. The entity did not exist before this event.
An entity usage event is the instantaneous event that marks the first instant of an entity's consumption timespan by an activity. The described usage had not started before this instant, although the activity could potentially have used the same entity at a different time.
An entity invalidation event is the instantaneous event that marks the initial instant of the destruction, invalidation, or cessation of an entity, after which the entity is no longer available for use. The entity no longer exists after this event.
As set out in other specifications, the identifiers used in PROV documents have associated type information. An identifier can have more than one type, reflecting subtyping or allowed overlap between types, and so we define a set of types of each identifier, typeOf(id). Some types are, however, required not to overlap (for example, no identifier can describe both an entity and an activity). In addition, an identifier cannot be used to identify both an object (that is, an entity, activity or agent) and a property (that is, a named event such as usage, generation, or a relationship such as attribution.) This specification includes disjointness and typing constraints that check these requirements. Here, we summarize the type constraints in Table 1.
| In relation... | identifier | has type(s)... |
|---|---|---|
| entity(e,attrs) | e | 'entity' |
| activity(a,t1,t2,attrs) | a | 'activity' |
| agent(ag,attrs) | ag | 'agent' |
| used(id; a,e,t,attrs) | e | 'entity' |
| a | 'activity' | |
| wasGeneratedBy(id; e,a,t,attrs) | e | 'entity' |
| a | 'activity' | |
| wasInformedBy(id; a2,a1,attrs) | a2 | 'activity' |
| a1 | 'activity' | |
| wasStartedBy(id; a2,e,a1,t,attrs) | a2 | 'activity' |
| e | 'entity' | |
| a1 | 'activity' | |
| wasEndedBy(id; a2,e,a1,t,attrs) | a2 | 'activity' |
| e | 'entity' | |
| a1 | 'activity' | |
| wasInvalidatedBy(id; e,a,t,attrs) | e | 'entity' |
| a | 'activity' | |
| wasDerivedFrom(id; e2,e1,a,g,u,attrs) | e2 | 'entity' |
| e1 | 'entity' | |
| a | 'activity' | |
| wasAttributedTo(id; e,ag,attr) | e | 'entity' |
| ag | 'agent' | |
| wasAssociatedWith(id; a,ag,pl,attrs) | a | 'activity' |
| ag | 'agent' | |
| pl | 'entity' | |
| actedOnBehalfOf(id; ag2,ag1,a,attrs) | ag2 | 'agent' |
| ag1 | 'agent' | |
| a | 'activity' | |
| alternateOf(e1,e2) | e1 | 'entity' |
| e2 | 'entity' | |
| specializationOf(e1,e2) | e1 | 'entity' |
| e2 | 'entity' | |
| mentionOf(e1,e2,b) | e1 | 'entity' |
| e2 | 'entity' | |
| b | 'entity' | |
| hadMember(c,e) | c | 'entity' 'prov:Collection' |
| e | 'entity' | |
| entity(c,[prov:type='prov:EmptyCollection,...]) | c | 'entity' 'prov:Collection' 'prov:EmptyCollection' |
This section collects common concepts and operations that are used
throughout the specification, and relates them to background
terminology and ideas from logic [Logic], constraint programming
[CHR], and database constraints [DBCONSTRAINTS]. This section
does not attempt to provide a complete introduction to these topics,
but it is provided in order to aid readers familiar with one or more
of these topics in understanding the specification, and, for all readers, to clarify
some of the motivations for choices in the specification to all readers.
PROV statements involve identifiers, literals, placeholders, and attribute lists. Identifiers are, according to PROV-N, expressed as qualified names which can be mapped to URIs [IRI]. However, in order to specify constraints over PROV instances, we also need variables that represent unknown identifiers, literals, or placeholders. These variables are similar to those in first-order logic [Logic]. A variable is a symbol that can be replaced by other symbols, including either other variables or constant identifiers, literals, or placeholders. In a few special cases, we also use variables for unknown attribute lists. To help distinguish identifiers and variables, we also term the former 'constant identifiers' to highlight their non-variable nature.
Several definitions and inferences conclude by saying that some objects exist such that some other formulas hold. Such an inference introduces fresh existential variables into the instance. An existential variable denotes a fixed object that exists, but its exact identity is unknown. Existential variables can stand for unknown identifiers or literal values only; we do not allow existential variables that stand for unknown attribute lists.
In particular, many occurrences of the placeholder symbol "-" stand for unknown objects; these are handled by expanding them to existential variables. Some placeholders, however, indicate the absence of an object, rather than an unknown object. In other words, the placeholder is overloaded, with different meanings in different places.
An expression is called a term if it is either a constant identifier, literal, placeholder, or variable. We write t to denote an arbitrary term.
A substitution is a function that maps variables to terms. Concretely, since we only need to consider substitutions of finite sets of variables, we can write substitutions as [x1 = t1,...,xn=tn]. A substitution S = [x1 = t1,...,xn=tn] can be applied to a term as follows.
In addition, a substitution can be applied to an atomic formula (PROV statement) p(t1,...,tn) by applying it to each term, that is, S(p(t1,...,tn)) = p(S(t1),...,S(tn)). Likewise, a substitution S can be applied to an instance I by applying it to each atomic formula (PROV statement) in I, that is, S(I) = {S(A) | A ∈ I}.
For the purpose of constraint checking, we view PROV statements (possibly involving existential variables) as formulas. An instance is analogous to a "theory" in logic, that is, a set of formulas all thought to describe the same situation. The set can also be thought of a single, large formula: the conjunction of all of the atomic formulas.
The atomic constraints considered in this specification can be viewed as atomic formulas:
Similarly, the definitions, inferences, and constraint rules in this specification can also be viewed as logical formulas, built up out of atomic formulas, logical connectives "and" (∧), "implies" (⇒), and quantifiers "for all" (∀) and "there exists" (∃). For more background on logical formulas, see a logic textbook such as [Logic].
In logic, a formula's meaning is defined by saying when it is satisfied. We can view definitions, inferences, and constraints as being satisfied or not satisfied in a PROV instance, augmented with information about the constraints.
Merging is an operation that takes two terms and compares them to see if they are equal, or can be made equal by substituting an existential variable with another term. This operation is a special case of unification, a common operation in logical reasoning, including logic programming and automated reasoning. Merging two terms t,t' results in either substitution S such that S(t) = S(t'), or failure indicating that there is no substitution that can be applied to both t and t' to make them equal.
Formulas can also be interpreted as having computational content. That is, if an instance does not satisfy a formula, we can often apply the formula to the instance to produce another instance that does satisfy the formula. Definitions, inferences, and uniqueness constraints can be applied to instances:
As noted above, uniqueness or key constraint application can fail, if a required merging step fails. Failure of constraint application means that there is no way to add information to the instance to satisfy the constraint, which in turn implies that the instance is invalid.
The process of applying definitions, inferences, and constraints to a PROV instance until all of them are satisfied is similar to what is sometimes called chasing [DBCONSTRAINTS] or saturation [CHR]. We call this process normalization.
In general, applying sets of logical formulas of the above definition, inference, and constraint forms is not guaranteed to terminate. A simple example is the inference R(x,y) ⇒ ∃z. R(x,z) ∧R(z,y), which can be applied to {R(a,b)} to generate an infinite sequence of larger and larger instances. To ensure that normalization, validity, and equivalence are decidable, we require that normalization terminates. There is a great deal of work on termination of the chase in databases, or of sets of constraint handling rules. The termination of the notion of normalization defined in this specification is guaranteed because the definitions, inferences and uniqueness/key constraints correspond to a weakly acyclic set of tuple-generating and equality-generating dependencies, in the terminology of [DBCONSTRAINTS]. The termination of the remaining ordering, typing, and impossibility constraints is easy to show. Appendix C gives a proof that the definitions, inferences, and uniqueness and key constraints are weakly acyclic and therefore terminating.
There is an important subtlety that is essential to guarantee termination. This specification draws a distinction between knowing that an identifier has type 'entity', 'activity', or 'agent', and having an explicit entity(id), activity(id), or agent(id) statement in the instance. For example, focusing on entity statements, we can infer 'entity' ∈ typeOf(id) if entity(id) holds in the instance. In contrast, if we only know that 'entity' ∈ typeOf(id), this does not imply that entity(id) holds.
This distinction (for both entities and activities) is essential to ensure termination of the inferences, because we allow inferring that a declared entity(id,attrs) has a generation and invalidation event, using Inference 7 (entity-generation-invalidation-inference). Likewise, for activities, we allow inferring that a declared activity(id,t1,t2,attrs) has a generation and invalidation event, using Inference 8 (activity-start-end-inference). These inferences do not apply to identifiers whose types are known, but for which there is not an explicit entity or activity statement. If we strengthened the type inference constraints to add new entity or activity statements for the entities and activities involved in generating or starting other declared entities or activities, then we could keep generating new entities and activities in an unbounded chain into the past (as in the "chicken and egg" paradox). The design adopted here requires that instances explicitly declare the entities and activities that are relevant for validity checking, and only these can be inferred to have invalidation/generation and start/end events. This inference is not supported for identifiers that are indirectly referenced in other relations and therefore have type 'entity' or 'activity'.

The ordering, typing, and impossibility constraints are checked rather than applied. This means that they do not generate new formulas expressible in PROV, but they do generate basic constraints that might or might not be consistent with each other. Checking such constraints follows a saturation strategy similar to that for normalization:
For ordering constraints, we check by generating all of the precedes and strictly-precedes relationships specified by the rules. These can be thought of as a directed graph whose nodes are terms, and whose edges are precedes or strictly-precedes relationships. An ordering constraint of the form ∀ x1...xn. A1 ∧ ... ∧ Ap ⇒ precedes(t,t') can be applied by searching for occurrences of A1 ∧ ... ∧ Ap and for each such match adding the atomic formula precedes(t,t') to the instance, and similarly for strictly-precedes constraints. After all such constraints have been checked, and the resulting edges added to the graph, the ordering constraints are violated if there is a cycle in the graph that includes a strictly-precedes edge, and satisfied otherwise.
For typing constraints, we check by constructing a function typeOf(id) mapping identifiers to sets of possible types. We start with a function mapping each identifier to the empty set, reflecting no constraints on the identifiers' types. A typing constraint of the form ∀ x1...xn. A1 ∧ ... ∧ Ap ⇒ 'type' ∈ typeOf(id) is checked by adjusting the function by adding 'type' to typeOf(id) for each conclusion 'type' ∈ typeOf(id) of the rule. Typing constraints with multiple conclusions are handled analogously. Once all constraints have been checked in all possible ways, we check that the disjointness constraints hold of the resulting typeOf function. (These are essentially impossibility constraints).
For impossibility constraints, we check by searching for the forbidden pattern that the impossibility constraint describes. Any match of this pattern leads to failure of the constraint checking process. An impossibility constraint of the form ∀ x1...xn. A1 ∧ ... ∧ Ap ⇒ False can be applied by searching for occurrences of A1 ∧ ... ∧ Ap in the instance, and if any such occurrence is found, signaling failure.
A normalized instance that satisfies all of the checked constraints is called valid. Validity can be, but is not required to be, checked by normalizing and then checking constraints. Any other algorithm that provides equivalent behavior (that is, accepts the same valid instances and rejects the same invalid instances) is allowed. In particular, the checked constraints and the applied definitions, inferences and uniqueness constraints do not interfere with one another, so it is also possible to mix checking and application. This may be desirable in order to detect invalidity more quickly.
Given two normal forms, a natural question is whether they contain the same information, that is, whether they are equivalent (if so, then the original instances are also equivalent.) By analogy with logic, if we consider normalized PROV instances with existential variables to represent sets of possible situations, then two normal forms may describe the same situation but differ in inessential details such as the order of statements or of elements of attribute-value lists. To remedy this, we can easily consider instances to be equivalent up to reordering of attributes. However, instances can also be equivalent if they differ only in choice of names of existential variables. Because of this, the appropriate notion of equivalence of normal forms is isomorphism. Two instances I1 and I2 are isomorphic if there is an invertible substitution S mapping existential variables to existential variables such that S(I1) = I2. This is similar to the notion of equivalence used in [RDF], where blank nodes play an analogous role to existential variables.
Equivalence can be checked by normalizing instances, checking that both instances are valid, then testing whether the two normal forms are isomorphic. (It is technically possible for two invalid normal forms to be isomorphic, but to be considered equivalent, the two instances must also be valid.) As with validity, the algorithm suggested by this specification is just one of many possible ways to implement equivalence checking; it is not required that implementations compute normal forms explicitly, only that their determinations of equivalence match those obtained by the algorithm in this specification.
PROV documents can contain multiple instances: a toplevel instance consisting of the set of statements not appearing within a bundle, and zero or more named instances called bundles. For the purpose of inference and constraint checking, these instances are treated independently. That is, a PROV document is valid provided that each instance in it is valid and the names of its bundles are distinct. Similarly, a PROV document is equivalent to another if their toplevel instances are equivalent, they have the same number of bundles with the same names, and the instances of their corresponding bundles are equivalent. Analogously to blank nodes in [RDF], the scope of an existential variable in PROV is the instance level, so existential variables with the same name occurring in different instances do not necessarily denote the same term. This is a consequence of the fact that the instances of two equivalent documents only need to be pairwise isomorphic; this is a weaker property than requiring that there be a single isomorphism that works for all of the corresponding instances.
Table 2 summarizes the inferences, and constraints specified in this document, broken down by component and type or relation involved.
For the purpose of compliance, the normative sections of this document are section 3. Compliance with this document, section 4. Definitions and Inferences, section 5. Constraints, and section 6. Normalization, Validity, and Equivalence. To be compliant:
Compliant applications are not required to explicitly compute normal forms; however, if checking validity or equivalence, the results should be the same as would be obtained by computing normal forms as defined in this specification.
All figures are for illustration purposes only. Information in tables is normative if it appears in a normative section; specifically, Table 3 is normative. Text in appendices and in boxes labeled "Remark" is informative. Where there is any apparent ambiguity between the descriptive text and the formal text in a "definition", "inference" or "constraint" box, the formal text takes priority.
This section describes definitions and inferences that may be used on provenance data, and preserve equivalence on valid PROV instances (as detailed in section 6. Normalization, Validity, and Equivalence). A definition is a rule that can be applied to PROV instances to replace defined expressions with definitions. An inference is a rule that can be applied to PROV instances to add new PROV statements. A definition states that a provenance statement is equivalent to some other statements, whereas an inference only states one direction of an implication; thus, defined provenance statements can be replaced by their definitions.
Definitions have the following general form:
defined_stmt IF AND ONLY IF there exists a1,..., am such that defining_stmt1 and ... and defining_stmtn.
A definition can be applied to a PROV instance, since its defined_stmt is defined in terms of other statements. Applying a definition to an instance means that if an occurrence of a defined provenance statement defined_stmt can be found in a PROV instance, then we can remove it and add all of the statements defining_stmt1 ... defining_stmtn to the instance, possibly after generating fresh identifiers a1,...,am for existential variables. In other words, it is safe to replace a defined statement with its definition.
Inferences have the following general form:
IF hyp1 and ... and hypk THEN there exists a1 and ... and am such that concl1 and ... and concln.
Inferences can be applied to PROV instances. Applying an inference to an instance means that if all of the provenance statements matching hyp1... hypk can be found in the instance, then we check whether the conclusion concl1 ... concln is satisfied for some values of existential variables. If so, application of the inference has no effect on the instance. If not, then a copy the conclusion should be added to the instance, after generating fresh identifiers a1,...,am for the existential variables. These fresh identifiers might later be found to be equal to known identifiers; they play a similar role in PROV constraints to existential variables in logic, to "labeled nulls" in database theory [DBCONSTRAINTS], or to blank nodes in [RDF]. In general, omitted optional parameters to [PROV-N] statements, or explicit - markers, are placeholders for existentially quantified variables; that is, they denote unknown values. There are a few exceptions to this general rule, which are specified in Definition 4 (optional-placeholders).
Definitions and inferences can be viewed as logical formulas; similar formalisms are often used in rule-based reasoning [CHR] and in databases [DBCONSTRAINTS]. In particular, the identifiers a1 ... an should be viewed as existentially quantified variables, meaning that through subsequent reasoning steps they may turn out to be equal to other identifiers that are already known, or to other existentially quantified variables. Their treatment is analogous to that of blank nodes in RDF. In contrast, distinct URIs or literal values in PROV are assumed to be distinct for the purpose of checking validity or inferences. This issue is discussed in more detail under Uniqueness Constraints.
In a [definition|inference], term symbols such as id, start, end, e, a, attrs, are assumed to be variables unless otherwise specified. These variables are scoped at the [definition|inference|constraint] level, so the rule is equivalent to any one-for-one renaming of the variable names. When several rules are collected within a [definition|inference] as an ordered list, the scope of the variables in each rule is at the level of list elements, and so reuse of variable names in different rules does not affect the meaning.
Many PROV relation statements have an identifier, identifying a link between two or more related objects. Identifiers can sometimes be omitted in [PROV-O] notation. For the purpose of inference and validity checking, we generate special identifiers called existential variables denoting the unknown values.
Existential variables can be substituted with other terms. Specifically, a substitution is a function from a set of existential variables to identifiers, literals, the placeholder -, or other existential variables. A substitution S can be applied to an instance I by replacing all occurrences of existential variables x in the instance with S(x).
Definition 1 (optional-identifiers), Definition 2 (optional-attributes), and Definition 3 (definition-short-forms), explain how to expand the compact forms of PROV-N notation into a normal form. Definition 4 (optional-placeholders) indicates when other optional parameters can be replaced by existential variables.
For each r in { used, wasGeneratedBy, wasInvalidatedBy, wasInfluencedBy, wasStartedBy, wasEndedBy, wasInformedBy, wasDerivedFrom, wasAttributedTo, wasAssociatedWith, actedOnBehalfOf}, the following definitional rules hold:
Likewise, many PROV-N statements allow for an optional attribute list. If it is omitted, this is the same as specifying an empty attribute list:
p(a1,...,an) IF AND ONLY IF p(a1,...,an,[]).
r(id; a1,...,an) IF AND ONLY IF r(id; a1,...,an,[]).
Definitions Definition 1 (optional-identifiers) and Definition 2 (optional-attributes). do not apply to alternateOf, specializationOf, and mentionOf, which do not have identifiers and attributes.
Finally, many PROV statements have other optional arguments or short forms that can be used if none of the optional arguments is present. These are handled by specific rules listed below.
There are no expansion rules for entity, agent, communication, attribution, influence, alternate, specialization, or mention relations, because these have no optional parameters aside from the identifier and attributes, which are expanded by the rules in Definition 1 (optional-identifiers) and Definition 2 (optional-attributes).
Finally, most optional parameters (written -) are, for the purpose of this document, considered to be distinct, fresh existential variables. Optional parameters are defined in [PROV-DM] and in [PROV-N] for each type of PROV statement. Thus, before proceeding to apply other definitions or inferences, most occurrences of - are to be replaced by fresh existential variables, distinct from any others occurring in the instance. The only exceptions to this general rule, where - are to be left in place, are the activity, generation, and usage parameters in wasDerivedFrom and the plan parameter in wasAssociatedWith. This is further explained in remarks below.
The treatment of optional parameters is specified formally using the auxiliary concept of expandable parameter. An expandable parameter is one that can be omitted using the placeholder -, and if so, it is to be replaced by a fresh existential identifier. Table 3 defines the expandable parameters of the properties of PROV, needed in Definition 4 (optional-placeholders). For emphasis, the four optional parameters that are not expandable are also listed. Parameters that cannot have value -, and identifiers that are expanded by Definition 1 (optional-identifiers), are not listed.
| Relation | Expandable | Non-expandable |
|---|---|---|
| used(id; a,e,t,attrs) | e,t | |
| wasGeneratedBy(id; e,a,t,attrs) | a,t | |
| wasStartedBy(id; a2,e,a1,t,attrs) | e,a1,t | |
| wasEndedBy(id; a2,e,a1,t,attrs) | e,a1,t | |
| wasInvalidatedBy(id; e,a,t,attrs) | a,t | |
| wasDerivedFrom(id; e2,e1,-,g,u,attrs) | g,u | |
| wasDerivedFrom(id; e2,e1,a,g,u,attrs) (where a is not placeholder -) |
g,u | a |
| wasAssociatedWith(id; a,ag,pl,attrs) | ag | pl |
| actedOnBehalfOf(id; ag2,ag1,a,attrs) | a |
Definition 4 (optional-placeholders) states how parameters are to be expanded, using the expandable parameters defined in Table 3. The last two parts, 4 and 5, indicate how to handle expansion of parameters for wasDerivedFrom expansion, which is only allowed for the generation and use parameters when the activity is specified. Essentially, the definitions state that parameters g,u are expandable only if the activity is specified, i.e., if parameter a is provided. The rationale for this is that when a is provided, then there have to be two events, namely u and g, which account for the usage of e1 and the generation of e2, respectively, by a. Conversely, if a is not provided, then one cannot tell whether one or more activities are involved in the derivation, and the explicit introduction of such events, which correspond to a single acitivity, would therefore not be justified.
A later constraint, Constraint 53 (impossible-unspecified-derivation-generation-use), forbids specifying generation and use parameters when the activity is unspecified.
r(a0;...,ai-1, -, ai+1, ...,an) IF AND ONLY IF there exists a' such that r(a0;...,ai-1,a',ai+1,...,an).
wasDerivedFrom(id;e2,e1,a,-,u,attrs) IF AND ONLY IF there exists g such that wasDerivedFrom(id; e2,e1,a,g,u,attrs).
wasDerivedFrom(id;e2,e1,a,g,-,attrs) IF AND ONLY IF there exists u such that wasDerivedFrom(id; e2,e1,a,g,u,attrs).
In an association of the form wasAssociatedWith(id; a,ag,-,attr), the absence of a plan means: either no plan exists, or a plan exists but it is not identified. Thus, it is not equivalent to wasAssociatedWith(id; a,ag,p,attr) where a plan p is given.
A derivation wasDerivedFrom(id; e2,e1,a,gen,use,attrs) that specifies an activity explicitly indicates that this activity achieved the derivation, with a usage use of entity e1, and a generation gen of entity e2. It differs from a derivation of the form wasDerivedFrom(id; e2,e1,-,-,-,attrs) with missing activity, generation, and usage. In the latter form, it is not specified if one or more activities are involved in the derivation.
Let us consider a system, in which a derivation is underpinned by multiple activities. Conceptually, one could also model such a system with a new activity that encompasses the two original activities and underpins the derivation. The inferences defined in this specification do not allow the latter modelling to be inferred from the former. Hence, the two modellings of the same system are regarded as different in the context of this specification.
Communication between activities implies the existence of an underlying entity generated by one activity and used by the other, and vice versa.
IF wasInformedBy(_id; a2,a1,_attrs) THEN there exist e, _gen, _t1, _use, and _t2, such that wasGeneratedBy(_gen; e,a1,_t1,[]) and used(_use; a2,e,_t2,[]) hold.
IF wasGeneratedBy(_gen; e,a1,_t1,_attrs1) and used(_id2; a2,e,_t2,_attrs2) hold THEN there exists _id such that wasInformedBy(_id; a2,a1,[])
The relationship wasInformedBy is not transitive. Indeed, consider the following statements.
wasInformedBy(a2,a1) wasInformedBy(a3,a2)
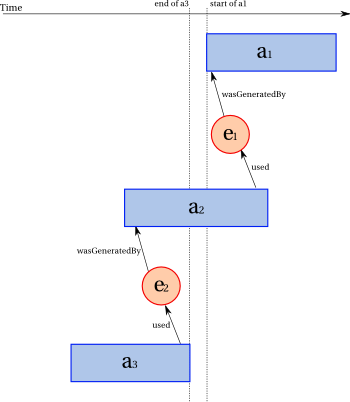
We cannot infer wasInformedBy(a3,a1) from these statements alone. Indeed, from wasInformedBy(a2,a1), we know that there exists e1 such that e1 was generated by a1 and used by a2. Likewise, from wasInformedBy(a3,a2), we know that there exists e2 such that e2 was generated by a2 and used by a3. The following illustration shows a counterexample to transitivity. The horizontal axis represents the event line. We see that e1 was generated after e2 was used. Furthermore, the illustration also shows that a3 completes before a1 started. So in this example (with no other information) it is impossible for a3 to have used an entity generated by a1. This is illustrated in Figure 2.
From an entity statement, we can infer the existence of generation and invalidation events.
IF entity(e,_attrs) THEN there exist _gen, _a1, _t1, _inv, _a2, and _t2 such that wasGeneratedBy(_gen; e,_a1,_t1,[]) and wasInvalidatedBy(_inv; e,_a2,_t2,[]).
From an activity statement, we can infer start and end events whose times match the start and end times of the activity, respectively.
IF activity(a,t1,t2,_attrs) THEN there exist _start, _e1, _a1, _end, _a2, and _e2 such that wasStartedBy(_start; a,_e1,_a1,t1,[]) and wasEndedBy(_end; a,_e2,_a2,t2,[]).
The start of an activity a triggered by entity e1 implies that e1 was generated by the starting activity a1.
IF wasStartedBy(_id; a,e1,a1,_t,_attrs), THEN there exist _gen and _t1 such that wasGeneratedBy(_gen; e1,a1,_t1,[]).
Likewise, the ending of activity a by triggering entity e1 implies that e1 was generated by the ending activity a1.
IF wasEndedBy(_id; a,e1,a1,_t,_attrs), THEN there exist _gen and _t1 such that wasGeneratedBy(_gen; e1,a1,_t1,[]).
Derivations with explicit activity, generation, and usage admit the following inference:
In this inference, none of a, gen2 or use1 can be placeholders -.
IF wasDerivedFrom(_id; e2,e1,a,gen2,use1,_attrs), THEN there exists _t1 and _t2 such that used(use1; a,e1,_t1,[]) and wasGeneratedBy(gen2; e2,a,_t2,[]).
A revision admits the following inference, stating that the two entities linked by a revision are also alternates.
In this inference, any of _a, _g or _u may be placeholders.
IF wasDerivedFrom(_id; e2,e1,_a,_g,_u,[prov:type='prov:Revision']), THEN alternateOf(e2,e1).
Attribution is the ascribing of an entity to an agent. An entity can only be ascribed to an agent if the agent was associated with an activity that generated the entity. If the activity, generation and association events are not explicit in the instance, they can be inferred.
IF wasAttributedTo(_att; e,ag,_attrs) THEN there exist a, _t, _gen, _assoc, _pl, such that wasGeneratedBy(_gen; e,a,_t,[]) and wasAssociatedWith(_assoc; a,ag,_pl,[]).
Delegation relates agents where one agent acts on behalf of another, in the context of some activity. The supervising agent delegates some responsibility for part of the activity to the subordinate agent, while retaining some responsibility for the overall activity. Both agents are associated with this activity.
IF actedOnBehalfOf(_id; ag1, ag2, a, _attrs) THEN there exist _id1, _pl1, _id2, and _pl2 such that wasAssociatedWith(_id1; a, ag1, _pl1, []) and wasAssociatedWith(_id2; a, ag2, _pl2, []).
The wasInfluencedBy relation is implied by other relations, including usage, start, end, generation, invalidation, communication, derivation, attribution, association, and delegation. To capture this explicitly, we allow the following inferences:
The relation alternateOf is an equivalence relation: that is, it is reflexive, transitive and symmetric. As a consequence, the following inferences can be applied:
IF entity(e) THEN alternateOf(e,e).
IF alternateOf(e1,e2) and alternateOf(e2,e3) THEN alternateOf(e1,e3).
IF alternateOf(e1,e2) THEN alternateOf(e2,e1).
Similarly, specialization is a strict partial order: it is irreflexive and transitive. Irreflexivity is handled later as Constraint 54 (impossible-specialization-reflexive)
IF specializationOf(e1,e2) and specializationOf(e2,e3) THEN specializationOf(e1,e3).
If one entity specializes another, then they are also alternates:
IF specializationOf(e1,e2) THEN alternateOf(e1,e2).
If one entity specializes another then all attributes of the more general entity are also attributes of the more specific one.
IF entity(e1, attrs) and specializationOf(e2,e1), THEN entity(e2, attrs).
Note: The following inference is associated with a feature "at risk" and may be removed from this specification based on feedback. Please send feedback to public-prov-comments@w3.org.
If one entity is a mention of another in a bundle, then the former is also a specialization of the latter:
IF mentionOf(e2,e1,b) THEN specializationOf(e2,e1).
This section defines a collection of constraints on PROV instances. There are three kinds of constraints:
As in a [definition|inference], term symbols such as id, start, end, e, a, attrs in a constraint, are assumed to be variables unless otherwise specified. These variables are scoped at the constraint level, so the rule is equivalent to any one-for-one renaming of the variable names. When several rules are collected within a constraint as an ordered list, the scope of the variables in each rule is at the level of list elements, and so reuse of variable names in different rules does not affect the meaning.
In the absence of existential variables, uniqueness constraints could be checked directly by checking that no identifier appears more than once for a given statement. However, in the presence of existential variables, we need to be more careful to combine partial information that might be present in multiple compatible statements, due to inferences. Uniqueness constraints are enforced through merging pairs of statements subject to equalities. For example, suppose we have two activity statements activity(a,2011-11-16T16:00:00,_t1,[a=1]) and activity(a,_t2,2011-11-16T18:00:00,[b=2]), with existential variables _t1 and _t2. The merge of these two statements (describing the same activity a) is activity(a,2011-11-16T16:00:00,2011-11-16T18:00:00,[a=1,b=2]).
Merging is an operation that can be applied to a pair of terms, or a pair of attribute lists. The result of merging is either a substitution (mapping existentially quantified variables to terms) or failure, indicating that the merge cannot be performed. Merging of pairs of terms, attribute lists, or statements is defined as follows.
A typical uniqueness constraint is as follows:
IF hyp1 and ... and hypn THEN t1 = u1 and ... and tn = un.
Such a constraint is enforced as follows:
Key constraints are uniqueness constraints that specify that a particular key field of a relation uniquely determines the other parameters. Key constraints are written as follows:
The ak field is a KEY for relation r(a0; a1,...,an).
Because of the presence of attributes, key constraints do not reduce directly to uniqueness constraints. Instead, we enforce key constraints as follows.
Thus, if a PROV instance contains an apparent violation of a uniqueness constraint or key constraint, merging can be used to determine whether the constraint can be satisfied by instantiating some existential variables with other terms. For key constraints, this is the same as merging pairs of statements whose keys are equal and whose corresponding arguments are compatible, because after merging respective arguments and attribute lists, the two statements become equal and one can be omitted.
The various identified objects of PROV must have unique statements describing them within a valid PROV instance. This is enforced through the following key constraints:
Likewise, the statements in a valid PROV instance must provide consistent information about each identified object or relationship. The following key constraints require that all of the information about each identified statement can be merged into a single, consistent statement:
Entities may have multiple generation or invalidation events (either or both may, however, be left implicit). An entity can be generated by more than one activity, with one generation event per each entity-activity pair. These events must be simultaneous, as required by Constraint 41 (generation-generation-ordering) and Constraint 42 (invalidation-invalidation-ordering).
IF wasGeneratedBy(gen1; e,a,_t1,_attrs1) and wasGeneratedBy(gen2; e,a,_t2,_attrs2), THEN gen1 = gen2.
IF wasInvalidatedBy(inv1; e,a,_t1,_attrs1) and wasInvalidatedBy(inv2; e,a,_t2,_attrs2), THEN inv1 = inv2.
It follows from the above uniqueness and key constraints that the generation and invalidation events linking an entity and activity are unique, if specified. However, because we apply the constraints by merging, it is possible for a valid PROV instance to contain multiple statements about the same generation or invalidation event, for example:
wasGeneratedBy(id1; e,a,-,[prov:location="Paris"]) wasGeneratedBy(-; e,a,-,[color="Red"])
When the uniqueness and key constraints are applied, the instance is normalized to the following form:
wasGeneratedBy(id1; e,a,_t,[prov:location="Paris",color="Red"])
where _t is a new existential variable.
An activity may have more than one start and end event, each having a different activity (either or both may, however, be left implicit). However, the triggering entity linking any two activities in a start or end event is unique. That is, an activity may be started by several other activities, with shared or separate triggering entities. If an activity is started or ended by multiple events, they must all be simultaneous, as specified in Constraint 33 (start-start-ordering) and Constraint 34 (end-end-ordering).
IF wasStartedBy(start1; a,_e1,a0,_t1,_attrs1) and wasStartedBy(start2; a,_e2,a0,_t2,_attrs2), THEN start1 = start2.
IF wasEndedBy(end1; a,_e1,a0,_t1,_attrs1) and wasEndedBy(end2; a,_e2,a0,_t2,_attrs2), THEN end1 = end2.
An activity start event is the instantaneous event that marks the instant an activity starts. It allows for an optional time attribute. Activities also allow for an optional start time attribute. If both are specified, they must be the same, as expressed by the following constraint.
IF activity(a2,t1,_t2,_attrs) and wasStartedBy(_start; a2,_e,_a1,t,_attrs), THEN t1=t.
An activity end event is the instantaneous event that marks the instant an activity ends. It allows for an optional time attribute. Activities also allow for an optional end time attribute. If both are specified, they must be the same, as expressed by the following constraint.
IF activity(a2,_t1,t2,_attrs) and wasEndedBy(_end; a2,_e,_a1,t,_attrs1), THEN t2 = t.
Note: The following constraint is associated with a feature "at risk" and may be removed from this specification based on feedback. Please send feedback to public-prov-comments@w3.org.
An entity can be the subject of at most one mention relation.
IF mentionOf(e, e1, b1) and mentionOf(e, e2, b2), THEN e1=e2 and b1=b2.
Given that provenance consists of a description of past entities and activities, valid provenance instances must satisfy ordering constraints between instantaneous events, which are introduced in this section. For instance, an entity can only be used after it was generated; in other words, an entity's generation event precedes any of this entity's usage events. Should this ordering constraint be violated, the associated generation and usage would not be credible. The rest of this section defines the temporal interpretation of provenance instances as a set of instantaneous event ordering constraints.
To allow for minimalistic clock assumptions, like Lamport [CLOCK], PROV relies on a notion of relative ordering of instantaneous events, without using physical clocks. This specification assumes that a preorder exists between instantaneous events.
Specifically, precedes is a preorder between instantaneous events. A constraint of the form e1 precedes e2 means that e1 happened at the same time as or before e2. For symmetry, follows is defined as the inverse of precedes; that is, a constraint of the form e1 follows e2 means that e1 happened at the same time as or after e2. Both relations are preorders, meaning that they are reflexive and transitive. Moreover, we sometimes consider strict forms of these orders: we say e1 strictly precedes e2 to indicate that e1 happened before e2, but not at the same time. This is a transitive relation.
PROV also allows for time observations to be inserted in specific provenance statements, for each of the five kinds of instantaneous events introduced in this specification. Times in provenance records arising from different sources might be with respect to different timelines (e.g. different time zones) leading to apparent inconsistencies. For the purpose of checking ordering constraints, the times associated with events are irrelevant; thus, there is no inference that time ordering implies event ordering, or vice versa. However, an application may flag time values that appear inconsistent with the event ordering as possible inconsistencies. When generating provenance, an application should use a consistent imeline for related PROV statements within an instance.
A typical ordering constraint is as follows.
IF hyp1 and ... and hypn THEN evt1 precedes/strictly precedes evt2.
The conclusion of an ordering constraint is either precedes or strictly precedes. One way to check ordering constraints is to generate all precedes and strictly precedes relationships arising from the ordering constraints to form a directed graph, with edges marked precedes or strictly precedes, and check that there is no cycle containing a strictly precedes edge.
This section specifies ordering constraints from the perspective of the lifetime of an activity. An activity starts, then during its lifetime can use, generate or invalidate entities, communicate with, start, or end other activities, or be associated with agents, and finally it ends. The following constraints amount to checking that all of the events associated with an activity take place within the activity's lifetime, and the start and end events mark the start and endpoints of its lifetime.
Figure 3 summarizes the ordering constraints on activities in a graphical manner. For this and subsequent figures, an event time line points to the right. Activities are represented by rectangles, whereas entities are represented by circles. Usage, generation and invalidation are represented by the corresponding edges between entities and activities. The five kinds of instantaneous events are represented by vertical dotted lines (adjacent to the vertical sides of an activity's rectangle, or intersecting usage and generation edges). The ordering constraints are represented by triangles: an occurrence of a triangle between two instantaneous event vertical dotted lines represents that the event denoted by the left line precedes the event denoted by the right line.
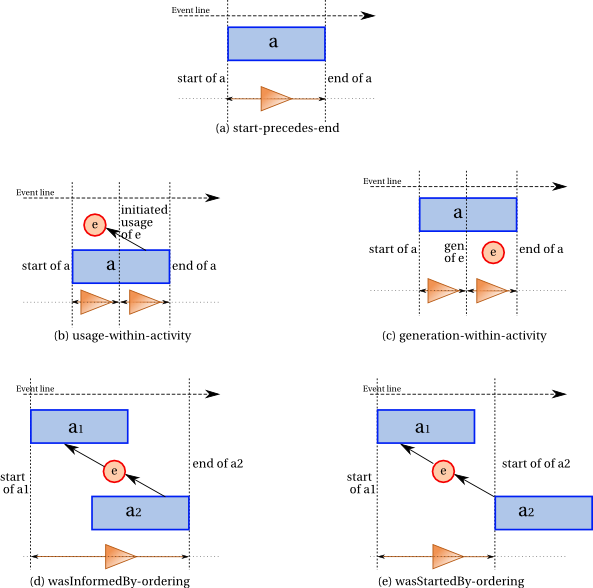
The existence of an activity implies that the activity start event always precedes the corresponding activity end event. This is illustrated by Figure 3 (a) and expressed by Constraint 32 (start-precedes-end).
IF wasStartedBy(start; a,_e1,_a1,_t1,_attrs1) and wasEndedBy(end; a,_e2,_a2,_t2,_attrs2) THEN start precedes end.
If an activity is started by more than one activity, the events must all be simultaneous. The following constraint requires that if there are two start events that start the same activity, then one precedes the other. Using this constraint in both directions means that each event precedes the other.
IF wasStartedBy(start1; a,_e1,_a1,_t1,_attrs1) and wasStartedBy(start2; a,_e2,_a2,_t2,_attrs2) THEN start1 precedes start2.
If an activity is ended by more than one activity, the events must all be simultaneous. The following constraint requires that if there are two end events that end the same activity, then one precedes the other. Using this constraint in both directions means that each event precedes the other, that is, they are simultaneous.
IF wasEndedBy(end1; a,_e1,_a1,_t1,_attrs1) and wasEndedBy(end2; a,_e2,_a2,_t2,_attrs2) THEN end1 precedes end2.
A usage implies ordering of events, since the usage event had to occur during the associated activity. This is illustrated by Figure 3 (b) and expressed by Constraint 35 (usage-within-activity).
A generation implies ordering of events, since the generation event had to occur during the associated activity. This is illustrated by Figure 3 (c) and expressed by Constraint 36 (generation-within-activity).
Communication between two activities a1 and a2 also implies ordering of events, since some entity must have been generated by the former and used by the latter, which implies that the start event of a1 cannot follow the end event of a2. This is illustrated by Figure 3 (d) and expressed by Constraint 37 (wasInformedBy-ordering).
IF wasInformedBy(_id; a2,a1,_attrs) and wasStartedBy(start; a1,_e1,_a1',_t1,_attrs1) and wasEndedBy(end; a2,_e2,_a2',_t2,_attrs2) THEN start precedes end.
As with activities, entities have lifetimes: they are generated, then can be used, other entities can be derived from them, and finally they can be invalidated. The constraints on these events are illustrated graphically in Figure 4 and Figure 5.
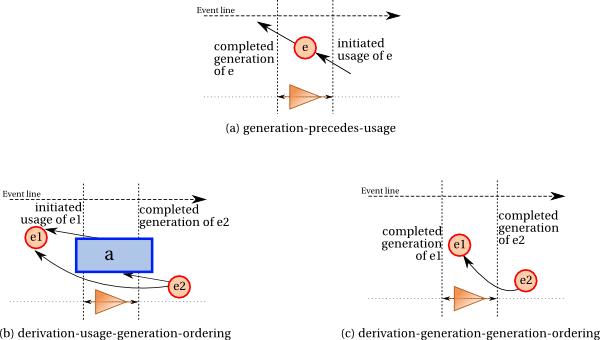
Generation of an entity precedes its invalidation. (This follows from other constraints if the entity is used, but it is stated explicitly here to cover the case of an entity that is generated and invalidated without being used.)
IF wasGeneratedBy(gen; e,_a1,_t1,_attrs1) and wasInvalidatedBy(inv; e,_a2,_t2,_attrs2) THEN gen precedes inv.
A usage and a generation for a given entity implies ordering of events, since the generation event had to precede the usage event. This is illustrated by Figure 4(a) and expressed by Constraint 39 (generation-precedes-usage).
IF wasGeneratedBy(gen; e,_a1,_t1,_attrs1) and used(use; _a2,e,_t2,_attrs2) THEN gen precedes use.
All usages of an entity precede its invalidation, which is captured by Constraint 40 (usage-precedes-invalidation) (without any explicit graphical representation).
IF used(use; _a1,e,_t1,_attrs1) and wasInvalidatedBy(inv; e,_a2,_t2,_attrs2) THEN use precedes inv.
If an entity is generated by more than one activity, the events must all be simultaneous. The following constraint requires that if there are two generation events that generate the same entity, then one precedes the other. Using this constraint in both directions means that each event precedes the other.
IF wasGeneratedBy(gen1; e,_a1,_t1,_attrs1) and wasGeneratedBy(gen2; e,_a2,_t2,_attrs2) THEN gen1 precedes gen2.
If an entity is invalidated by more than one activity, the events must all be simultaneous. The following constraint requires that if there are two invalidation events that invalidate the same entity, then one precedes the other. Using this constraint in both directions means that each event precedes the other, that is, they are simultaneous.
IF wasInvalidatedBy(inv1; e,_a1,_t1,_attrs1) and wasInvalidatedBy(inv2; e,_a2,_t2,_attrs2) THEN inv1 precedes inv2.
If there is a derivation relationship linking e2 and e1, then this means that the entity e1 had some influence on the entity e2; for this to be possible, some event ordering must be satisfied. First, we consider derivations, where the activity and usage are known. In that case, the usage of e1 has to precede the generation of e2. This is illustrated by Figure 4 (b) and expressed by Constraint 43 (derivation-usage-generation-ordering).
In this constraint, _a, gen2, use1 must not be placeholders.
IF wasDerivedFrom(_d; _e2,_e1,_a,gen2,use1,_attrs) THEN use1 precedes gen2.
When the activity, generation or usage is unknown, a similar constraint exists, except that the constraint refers to its generation event, as illustrated by Figure 4 (c) and expressed by Constraint 44 (derivation-generation-generation-ordering).
In this constraint, any _a, _g, _u may be placeholders.
IF wasDerivedFrom(_d; e2,e1,_a,_g,_u,attrs) and wasGeneratedBy(gen1; e1,_a1,_t1,_attrs1) and wasGeneratedBy(gen2; e2,_a2,_t2,_attrs2) THEN gen1 strictly precedes gen2.
This constraint requires the derived entity to be generated strictly following the generation of the original entity. This follows from the [PROV-DM] definition of derivation: A derivation is a transformation of an entity into another, an update of an entity resulting in a new one, or the construction of a new entity based on a pre-existing entity, thus the derived entity must be newer than the original entity.
The event ordering is between generations of e1 and e2, as opposed to derivation where usage is known, which implies ordering between the usage of e1 and generation of e2.
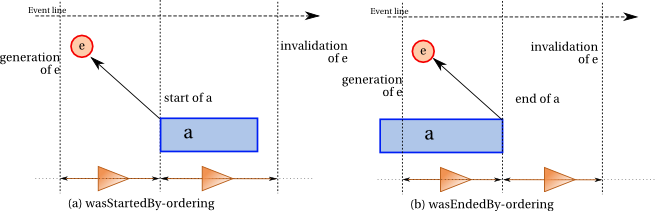
The entity that triggered the start of an activity must exist before the activity starts. This is illustrated by Figure 5(a) and expressed by Constraint 45 (wasStartedBy-ordering).
Similarly, the entity that triggered the end of an activity must exist before the activity ends, as illustrated by Figure 5(b).
If an entity is a specialization of another, then the more specific entity must have been generated after the less specific entity was generated.
IF specializationOf(e2,e1) and wasGeneratedBy(gen1; e1,_a1,_t1,_attrs1) and wasGeneratedBy(gen2; e2,_a2,_t2,_attrs2) THEN gen1 precedes gen2.
Similarly, if an entity is a specialization of another entity, and then the invalidation event of the more specific entity precedes that of the less specific entity.
IF specializationOf(e1,e2) and wasInvalidatedBy(inv1; e1,_a1,_t1,_attrs1) and wasInvalidatedBy(inv2; e2,_a2,_t2,_attrs2) THEN inv1 precedes inv2.
Like entities and activities, agents have lifetimes that follow a familiar pattern. An agent that is also an entity can be generated and invalidated; an agent that is also an activity can be started or ended. During its lifetime, an agent can participate in interactions such as starting or ending other activities, association with an activity, attribution, or delegation.
Further constraints associated with agents appear in Figure 6 and are discussed below.
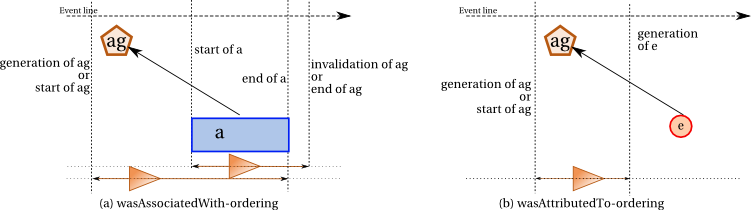
An activity that was associated with an agent must have some overlap with the agent. The agent must have been generated (or started), or must have become associated with the activity, after the activity start: so, the agent must exist before the activity end. Likewise, the agent may be destructed (or ended), or may terminate its association with the activity, before the activity end: hence, the agent invalidation (or end) is required to happen after the activity start. This is illustrated by Figure 6 (a) and expressed by Constraint 49 (wasAssociatedWith-ordering).
In the following inferences, _pl may be a placeholder -.
An agent to which an entity was attributed, must exist before this entity was generated. This is illustrated by Figure 6 (b) and expressed by Constraint 50 (wasAttributedTo-ordering).
For delegation, two agents need to have some overlap in their lifetime.
The following rule establishes types denoted by identifiers from their use within expressions. The function typeOf gives the set of types denoted by an identifier. That is, typeOf(e) returns the set of types associated with identifier e. The function typeOf is not a term of PROV, but a construct introduced to validate PROV statements.
For any identifier id, typeOf(id) is a subset of {'entity', 'activity', 'agent', 'prov:Collection', 'prov:EmptyCollection'}. For identifiers that do not have a type, typeOf gives the empty set. Identifiers can have more than one type, because of subtyping (e.g. 'prov:EmptyCollection' is a subtype of 'prov:Collection') or because certain types are not disjoint (such as 'agent' and 'entity'). The set of types does not reflect all of the distinctions among objects, only those relevant for checking validity. In particular, subtypes such as 'plan' and 'bundle' are omitted, and statements such as wasAssociatedWith and mentionOf that have plan or bundle parameters only check that these parameters are entities.
To check if a PROV instance satisfies type constraints, one obtains the types of identifiers by application of Constraint 52 (typing) and check that none of the impossibility constraints Constraint 57 (entity-activity-disjoint) and Constraint 58 (membership-empty-collection) are violated as a result.
Impossibility constraints require that certain patterns of statements never appear in valid PROV instances. Impossibility constraints have the following general form:
IF hyp1 and ... and hypn THEN INVALID.
Checking an impossibility constraint on instance I means checking whether there is any way of matching the pattern hyp1, ..., hypn. If there is, then checking the constraint on I fails (which implies that I is invalid).
A derivation with unspecified activity wasDerivedFrom(id;e1,e2,-,g,u,attrs) represents a derivation that takes one or more steps, whose activity, generation and use events are unspecified. It is forbidden to specify a generation or use event without specifying the activity.
In the following rules, g and u must not be -.
As noted previously, specialization is a strict partial order: it is irreflexive and transitive.
IF specializationOf(e,e) THEN INVALID.
Furthermore, identifiers of basic relationships are disjoint.
For each r and s in { used, wasGeneratedBy, wasInvalidatedBy, wasStartedBy, wasEndedBy, wasInformedBy, wasAttributedTo, wasAssociatedWith, actedOnBehalfOf} such that r and s are different relation names, the following constraint holds:
IF r(id; a1,...,am) and s(id; b1,...,bn) THEN INVALID.
Since wasInfluencedBy is a superproperty of many other properties, it is excluded from the set of properties whose identifiers are required to be pairwise disjoint. The following example illustrates this observation:
wasInfluencedBy(id;e2,e1) wasDerivedFrom(id;e2,e1)
This satisfies the disjointness constraint.
There is, however, no constraint requiring that every influence relationship is accompanied by a more specific relationship having the same identifier. The following valid example illustrates this observation:
wasInfluencedBy(id; e2,e1)
This is valid; there is no inferrable information about what kind of influence relates e2 and e1, other than its identity.
Identifiers of entities, agents and activities cannot also be identifiers of properties.
For each p in {entity, activity or agent} and for each r in { used, wasGeneratedBy, wasInvalidatedBy, wasInfluencedBy, wasStartedBy, wasEndedBy, wasInformedBy, wasDerivedFrom, wasAttributedTo, wasAssociatedWith, actedOnBehalfOf}, the following impossibility constraint holds:
IF p(id,a1,...,an) and r(id; b1,...,bn) THEN INVALID.
The set of entities and activities are disjoint, expressed by the following constraint:
IF 'entity' ∈ typeOf(id) AND 'activity' ∈ typeOf(id) THEN INVALID.
An empty collection cannot contain any member, expressed by the following constraint:
IF hasMember(c,e) and 'prov:EmptyCollection' ∈ typeOf(c) THEN INVALID.
We define the notions of normalization, validity and equivalence of PROV documents and instances. We first define these concepts for PROV instances and then extend them to PROV documents.
We define the normal form of a PROV instance as the set of provenance statements resulting from applying all definitions, inferences, and uniqueness constraints.
Because of the potential interaction among definitions, inferences, and constraints, the above algorithm is recursive. Nevertheless, all of our constraints fall into a class of tuple-generating dependencies and equality-generating dependencies that satisfy a termination condition called weak acyclicity that has been studied in the context of relational databases [DBCONSTRAINTS]. Therefore, the above algorithm terminates, independently of the order in which inferences and constraints are applied. Appendix C gives a proof that normalization terminates and produces a unique (up to isomorphism) normal form.
A PROV instance is valid if its normal form exists and satisfies all of the validity constraints; this implies that the instance satisfies all of the definitions, inferences, and constraints. The following algorithm can be used to test validity:
A normal form of a PROV instance does not exist when a uniqueness constraint fails due to merging failure.
Two PROV instances are equivalent if they have isomorphic normal forms (that is, after applying all possible inference rules, the two instances produce the same set of PROV statements, up to reordering of statements and attributes within attribute lists, and renaming of existential variables). Equivalence has the following characteristics:
An application that processes PROV data should handle equivalent instances in the same way. (Common exceptions to this rule include, for example, pretty-printers that seek to preserve the original order of statements in a file and avoid expanding inferences.)
The definitions, inferences, and constraints, and the resulting notions of normalization, validity and equivalence, assume a PROV document that consists only of a toplevel instance, containing all PROV statements in the top level of the document (that is, not enclosed in a named bundle). In this section, we describe how to deal with general PROV documents, possibly including multiple named bundles. Briefly, each bundle is handled independently; there is no interaction between bundles from the perspective of applying definitions, inferences, or constraints, computing normal forms, or checking validity or equivalence.
We model a general PROV document, containing n named bundles b1...bn, as a tuple (B0,[b1=B1,...,bn=Bn]) where B0 is the set of statements of the toplevel instance, and for each i, Bi is the set of statements of bundle bi. Names b1...bn are assumed to be distinct. This notation is shorthand for the following PROV-N syntax:
The normal form of a PROV document (B0,[b1=B1,...,[bn=Bn]) is (B'0,[b1=B'1,...,bn=B'n]) where B'i is the normal form of Bi for each i between 0 and n.
A PROV document is valid if each of the bundles B0, ..., Bn are valid and none of the bundle identifiers bi are repeated.
Two (valid) PROV documents (B0,[b1=B1,...,bn=Bn]) and (B'0,[b1'=B'1,...,b'm=B'm]) are equivalent if B0 is equivalent to B'0 and n = m and there exists a permutation P : {1..n} -> {1..n} such that for each i, bi = b'P(i) and Bi is equivalent to B'P(i).
This section is non-normative.
We will show that normalization terminates, that is, that applying definitions, inferences and uniqueness/key constraints eventually either fails (due to constraint violation) or terminates with a normal form.
First, since the inferences and constraints never introduce new defined statements, for the purpose of termination we always expand the definitions first and then consider only normalization of instances in which there are no remaining defined statements.
We will prove termination for the simple case where there are no attributes. For the general case, we will show that any nontermination arising from an instance that does involve attributes would also arise from one with no attributes.
Termination for instances without attributes. For these instances, uniqueness and key constraints can be As shown in [DBCONSTRAINTS], termination of normalization can be shown by checking that the inference rules are weakly acyclic. In addition, weak acyclicity can be checked in a modular fashion for our system, because there are only a few possible cycles among statements. The following table summarizes seven stages of the inference rules; because there are no cycles among stages, it is sufficient to check weak acyclicity of each stage independently.
| Stage # | Inference | Hypotheses | Conclusions |
|---|---|---|---|
| 1 | 19, 20, 21, 22 | specializationOf, mentionOf | specializationOf, entity |
| 2 | 7, 8, 13, 14 | entity, activity, wasAttributedTo, actedOnBehalfOf | wasInvalidatedBy, wasStartedBy, wasEndedBy |
| 3 | 9, 10 | wasStartedBy, wasEndedBy | wasGeneratedBy |
| 4 | 11, 12 | wasDerivedFrom | wasGeneratedBy, used, alternateOf |
| 5 | 16, 17, 18 | alternateOf, entity | alternateOf |
| 6 | 5, 6 | wasInformedBy, generated, used | wasInformedBy, generated, used |
| 7 | 15 | many | wasInfluencedBy |
For each stage, we show that the stage is weakly acyclic.

Termination for instances with attributes. We can translate an instance with attributes to an alternative, purely relational language by introducing a relation attribute(id,a,v) and replacing every statement of the form r(id;a1,...,an,[(k1,v1),...,(km,vm)]) with r(id;a1,...,an),attribute(id,k1,v1),...,attribute(id,km,vm), and similarly for entity, activity and agent attributes. The inference rules can also be translated so as to work on these instances, and a similar argument to the above shows that inference is terminating on instances with explicit attributes. Any infinite sequence of normalization steps on the original instance would lead to an infinite sequence of translated normalization steps on instances with explicit attributes.
This document has been produced by the PROV Working Group, and its contents reflect extensive discussion within the Working Group as a whole. The editors extend special thanks to Ivan Herman (W3C/ERCIM), Paul Groth, Tim Lebo, Simon Miles, Stian Soiland-Reyes, for their thorough reviews.
Members of the PROV Working Group at the time of publication of this document were: Ilkay Altintas (Invited expert), Reza B'Far (Oracle Corporation), Khalid Belhajjame (University of Manchester), James Cheney (University of Edinburgh, School of Informatics), Sam Coppens (IBBT), David Corsar (University of Aberdeen, Computing Science), Stephen Cresswell (The National Archives), Tom De Nies (IBBT), Helena Deus (DERI Galway at the National University of Ireland, Galway, Ireland), Simon Dobson (Invited expert), Martin Doerr (Foundation for Research and Technology - Hellas(FORTH)), Kai Eckert (Invited expert), Jean-Pierre EVAIN (European Broadcasting Union, EBU-UER), James Frew (Invited expert), Irini Fundulaki (Foundation for Research and Technology - Hellas(FORTH)), Daniel Garijo (Universidad Politécnica de Madrid), Yolanda Gil (Invited expert), Ryan Golden (Oracle Corporation), Paul Groth (Vrije Universiteit), Olaf Hartig (Invited expert), David Hau (National Cancer Institute, NCI), Sandro Hawke (W3C/MIT), Jörn Hees (German Research Center for Artificial Intelligence (DFKI) Gmbh), Ivan Herman, (W3C/ERCIM), Ralph Hodgson (TopQuadrant), Hook Hua (Invited expert), Trung Dong Huynh (University of Southampton), Graham Klyne (University of Oxford), Michael Lang (Revelytix, Inc.), Timothy Lebo (Rensselaer Polytechnic Institute), James McCusker (Rensselaer Polytechnic Institute), Deborah McGuinness (Rensselaer Polytechnic Institute), Simon Miles (Invited expert), Paolo Missier (School of Computing Science, Newcastle university), Luc Moreau (University of Southampton), James Myers (Rensselaer Polytechnic Institute), Vinh Nguyen (Wright State University), Edoardo Pignotti (University of Aberdeen, Computing Science), Paulo da Silva Pinheiro (Rensselaer Polytechnic Institute), Carl Reed (Open Geospatial Consortium), Adam Retter (Invited Expert), Christine Runnegar (Invited expert), Satya Sahoo (Invited expert), David Schaengold (Revelytix, Inc.), Daniel Schutzer (FSTC, Financial Services Technology Consortium), Yogesh Simmhan (Invited expert), Stian Soiland-Reyes (University of Manchester), Eric Stephan (Pacific Northwest National Laboratory), Linda Stewart (The National Archives), Ed Summers (Library of Congress), Maria Theodoridou (Foundation for Research and Technology - Hellas(FORTH)), Ted Thibodeau (OpenLink Software Inc.), Curt Tilmes (National Aeronautics and Space Administration), Craig Trim (IBM Corporation), Stephan Zednik (Rensselaer Polytechnic Institute), Jun Zhao (University of Oxford), Yuting Zhao (University of Aberdeen, Computing Science).