See also: IRC log
<JeniT> trackbot, start telcon
<trackbot> Date: 02 April 2012
<noah> http://www.w3.org/2001/tag/2012/04/02-agenda
Noah: agenda review
... couple of logistical announcements
DanA will be joining us after lunch
<scribe> scribe: Larry
scribenic: Larry
noah: (reviewing agenda, visitor schedules)
ht: I'll have a go at chairing,
see how that goes
... plan: 45 minutes, trying to get a state of play review,
want to hear what jar thinks we need to know. then spend 11-12
slot seeing if we can identify a way forward
... my inclination is to not try to get to the resolution right
away
jar: Jeni and I spent two hours
yesterday talking about the plan for this session, and came up
with an outline for a sequence of events
... roughly 5 parts (maybe 6)
... part 1: use cases, of which there are 2-3
... part 2: two architectures
... part 3: categorization of approaches
... part 4: visualizing the two roads to go down.... "what
would it be like to go in that direction"
part 5: criteria for making decision
part 6: actually making a decision
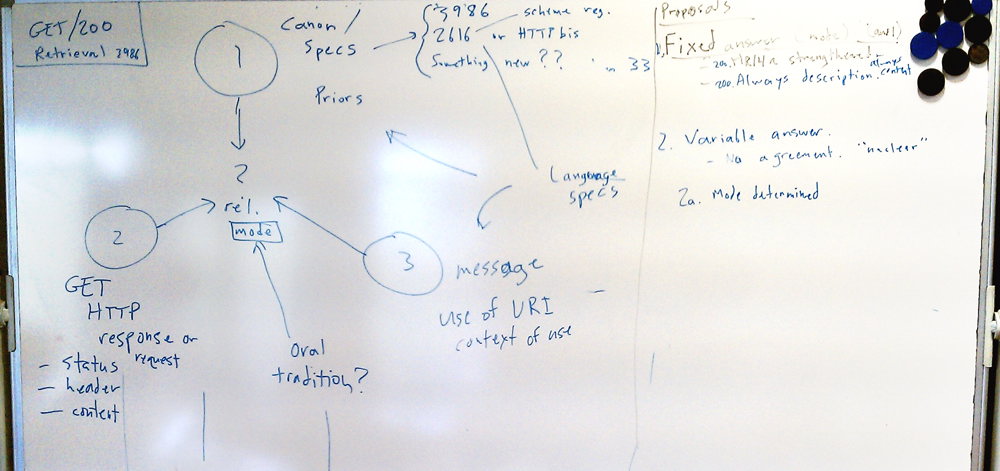
jar: RDF spec from 1997, section 5, Examples
http:/www.w3.org/TR/WD-rdf-syntax-971002/
"RDF is a foundation for processing metadadta"
jar: this is the first of 2.5 use
cases. What's going on here is you're making a database about
bibliographic information, using sparkle or some other
results
... RDF was motivated by PICS whichc was about rating, before
powder
ht: (want a sense of how jonathan is using the terminology)
jar: this is the way i see this
use case, as formulated, which i translated into a form that
makes sense now
... "If I do a get, I will get something which has the
properties)
... second use case:
http://www.w3.org/TR/WD-rdf-syntax-971002/
<noah> I'm very surprised the assertion in the example is claimed to be about the representation. I had assumed the assertions were about the resource. e.g. If the assertion is "created-on-date", then I assume that's the resource, not the representation that was created. If I really need to talk about representations, then I should find a way to get URI for the (various) representation(s)
jar points to
<?namespace href="http://docs.r.us.com/bibliography-info" as="bib"?> <?namespace href="http://www.w3.org/schemas/rdf-schema" as="RDF"?> <RDF:serialization> <RDF:assertions href="http://www.bar.com/some.doc"> <bib:author href="#John_Smith"/> </RDF:assertions> </RDF:serialization> <RDF:resource id="John_Smith"> <bib:name>John Smith</bib:name> <bib:email>john@smith.com</bib:email> <bib:phone>+1 (555) 123-4567</bib:phone> </RDF:resource>
jar: the RDF:resource
id="John_Smith" in the second use, is really about the
person
... "URI-based structured data"
... expand on this: netflix use case, we have actors, films,
separate files in some format, in each entity, there might be
some application
... 3rd case is one i will talk about an demand, the use of a
URL from Amazon to talk about a book
ht: press on ...
jar: I've been trying not to make
this RDF specific
... About "two architectures": where we are now, for whatever
we are, people are wanting to use hashless URIs for both use
cases
... the relationship between the retrieval results
... that's my analysis ...? "the other one is description. The
content you get back is different ..."
... I'm saying a fact about the two ways these fragments are
meant to be used
... in the one case, the URIs are being used as forming a
document web. In the other case, the content you get back is
more of a "REST"...
... Tim's vision and Roy's vision are different
ht: please be more specific
jar: Roy's latest formulation is "the representation is a record of the state of the resource"
<JeniT> definition in httpBis: http://tools.ietf.org/html/draft-ietf-httpbis-p2-semantics-19#section-5
noah: if a "hashless http refers to me" ?
jar: in Tim's version, people don't have hashless URIs?
<ht> "Relationship between the representation and the resource is arbitrary and application-dependent" Roy Fielding, as channelled by Jonathan Rees
jar: "If we need to"
... i think it might be useful to go over the three definitions
of the word 'representation'
<ht> "The way I interpret Roy, a server could validly return a JPG image of [Noah] with a 200 in return for a GET of a URI alleged to identify Noah"
<ht> [Above quote from JAR, I think]
larry: *munch* (eating another
spoon)
... I think "alleged" is a problem
jar: I've found 15-20 definitions of 'representation', 3 of which are interesting
rep: TBL, 2616? email, the word representation, comes from content negotiation,
"Encoding-format-desensitized methods and means for interchanging electronic document appearances." Patent no., 5,210,824, 1993 May 11 (filed Mar., 1989).
((JAR reviews matrix on board)
Rep #2: REST, by Roy fielding, in thesis, 3 publications, and in HTTPbis
the type of indentified resource is unconstrainted
jar: this is similar to ordinary
language use of the word 'representation', "is a picture of
noah a representation of noah, yes". Is a picture of jonathan a
representation of jonathan
... "Definition of Reputation #3" by 'fiat' -- if the URI
identifies something and you do a GET and you get some bits,
then by definition, the represenation of the resource
<Ashok> +
Jeni put link to 'representation' from HTTP spec
jar: Yves is correct that Roy is working to correct the terminology to be consistent with Rep #2
<JeniT> Definition in HTTPbis: http://tools.ietf.org/html/draft-ietf-httpbis-p3-payload-19#section-4
<JeniT> "A resource representation is information that reflects the state of that resource, as observed at some point in the past (e.g., in a response to GET) or to be desired at some point in the future (e.g., in a PUT request)."
jar: does "Information Resource" belong here. I don't understand, in roy's view, ways that we should not use the term "Information Resource" in this discussion
<Zakim> noah, you wanted to ask about assertions about resources vs. assertions about representations
noah: let's say the triple says "was created on"
and it's my thesis, does the assertion apply to the representation or the resource
jar: my theory of resources in
sense 1
... if you say "if you do a get, you'll come up with something
that satisfies the metadata"
... it is my belief that there is an operational behavior
... the operational behavior is predictive
<Zakim> Larry, you wanted to note that I think representation vs. resource is irrlevant
<noah> LM: I am interested in a view where the distinction between representation is not interesting, therefore the definitions of the terms are unimportant. We don't need the words.
<noah> JAR: Right, we just need to talk about the relationship between the two.
<noah> LM: No, we don't want to use the words at all, therefore there's no issue of the relationship.
<noah> LM: I think it's possible to not talk about resources, representations, HTTP status codes, or what happens when you do a GET. I like that story.
<noah> JAR: Everything I'm talking about is empirical. I'm talking about these two framings, and related them to the use cases.
<noah> LM: I don't think the use cases are different.
<noah> JAR: Consider the Flickr use case: you have two things... a description, and what it describes...and they have different properties. Thus, you NEED to say which one you're talking about.
<noah> LM: No you don't.
<noah> TBL: Why not.
<noah> LM: We're having a conversation. In the old days, using English or French. You had languages you both understood, with dictionaries like OED to refer to.
<noah> LM: We communicate because we use the same language, not the same dictionary.
<noah> LM: Then we invented the Web, on which we can not only exchange text, we can annotate text, and hyperlink it. We can now say this Moby Dick was written by Melville, and can hyperlink, and can give representaitons e.g. in different natural languages.
<ht> "This book I read, it's called 'Moby Dick', it was written by Hermann Melville, it has a green cover" LM
<noah> LM: Then we can reference things like Wikipedia we kind of understand how to share and retrieve.
<noah> LM: But then we wanted more...to make it more formal with triples... e.g. to formally say things about a book, using URIs to make formal the objects being discussed, who wrote it, etc.
<noah> LM: That is more precise, yet ambiguity remains. Maybe you can't tell if I'm talking about the book or the Web page about the book.
<noah> LM: Maybe the triples weren't good enough, in not allowing us to distinguish things we care about.
<noah> JAR: In 1998, it was very clear in the RDF draft (some mumbling in the room as to whether everyone agrees)
<noah> LM: We invented RDF, rev'd it, and still have ambiguities, some of which make us uncomfortable. That's just the way it is. We can't, in my view, retrofit now. We have to live with the ambiguities. Specifically, we can't do it by now more precisely stating what a URI means.
<noah> HT: Jumping in...Jonathan has said repeatedly that 1998 draft was clear, but I don't think it addresses Larry's concern. I think the example in the spec is clear.
we can't retrofit the definition of what a URI means in order to fix this possible ambiguity in RDF.
<noah> HT: It's unclear whether the example in the 1998 draft is about Moby Dick or the Web page about MD
<noah> LM: Even if you think RDF has got metadata...the library of congress has Abraham Lincoln's glasses, the glasses themselves, in the catalog.
<noah> JAR: The description is in the catalog.
<noah> LM: Right, but the catalog entry is for the actual glasses.
jar: the RDF draft itself does
not resolve this question, in that sense that Larry is right.
It is my belief that certain people had this view #1 in mind,
that if you do a GET you will get something that has the
property
... one example is "automatic mashups", you do a query of
documents... and you produce something that has one paragraph
from each document
... second example: text mining, what do you point your
database on?
ht: i think you're right, they wanted (Guha and Tim Bray) to give web docs metadata
<Zakim> timbl, you wanted to say that JAR's way of defining 'content of' is very good and to
tim: You (LM) said RDF had an
ambiguity; there is no ambiguity, the triples aren't
ambiguous
... RDF constrained the ways in which ....
<JeniT> TimBL: RDF was completely clear: under my view, it's clear what the URIs refer to
<JeniT> TimBL: which is documents
<JeniT> TimBL: This constrained how you could use URIs, but it is not ambiguous
<timbl> The RDF system had no inhereent ambiguity om the trips. It did decide to use URIs and HTTP, and in designing them into the system, it constrained them, so URIs adn HTTP were interpreted in a more cconstrined manner which produced a very nice very clean system, whcih was very useful. But it involved imiteing the way one talks about URIs and HTTP
<timbl> compared to what was in REST.
<JeniT> jar: there are applications where you need to know whether the bits are content rather than description
<JeniT> ... for example, showing the first paragraph of all the documents that can be found
<JeniT> ... and it needs to make sure that the paragraphs are content from the documents, not from descriptions of the documents
<JeniT> ht: if I want the train schedule, to display the numbers, you have to pay attention to the response code...
<JeniT> ... if it comes back as 404 then you know you don't want to display those numbers
<JeniT> ... you need to know whether the bits are the document or about the document
<JeniT> jar: you need to know whether the bits are the content
<JeniT> timbl: the concept of a document is crucial
<JeniT> ... it's like the content of a string
<ht> jar: It's like 'quote' in LISP
<JeniT> larry: this is a distinction that I think is impossible to make
<JeniT> timbl: the URI of the content of Moby Dick and the URI of a review of Moby Dick are different
<JeniT> larry: can we describe this in terms of communication, asserting things in English, then in markup, then in triples
<JeniT> noah: maybe we are tripping over what may be distinguished and what's worth distinguishing
<JeniT> ... a document rendered with different backgrounds on different ways
<JeniT> ... these are two artefacts, roughly different representations
<JeniT> larry: I'm not happy with "I have a document and I give it a URI"
<JeniT> noah: I minted a URI by leasing a domain name etc etc
<JeniT> larry: I'm not happy about 'minting' and 'owner'
<JeniT> noah: two operations were done, two sets of bits came back
<JeniT> ... there were two artefacts, and we can't say they're the same
<JeniT> ... one had a blue background, one not
<JeniT> ... whether we care about that is something else
<JeniT> ... perhaps you're saying we don't care about that
<JeniT> larry: RDF doesn't let me express things that I want to express
<JeniT> timbl: I think originally said that the difference between description and content was not one we could make
not one we could make reliably
<JeniT> ht: clarification of relationship between resource and representation under Roy's view
<JeniT> jar: it cannot be predicted what the relationship is
<JeniT> jar: there are applications where the content/description relationship is essential for the application to work
<JeniT> ... you need to be able to identify whether something is content or description
<JeniT> larry: there may be applications that you want to build, that depend on that distinction, but I do not think you can make that distinction reliably
<JeniT> ht: there are people who are building these applications, because they assume a uniform answer to the question
<JeniT> ... if they own both ends, they can satisfy the uniform definition
so the applications are unreliable. maybe they're reliable enough for the applications to be useful anyway
<JeniT> ... own the server and the client
<JeniT> ... so there's no possibility of disagreement
the web is unreliable -- we get 404 not found all the time, but the web is sitll useful
<JeniT> timbl: the RDF folks have built systems where they own both ends, but they include things outside that space, and that's the problem
i think this really leads into persistence, that we want <A> <R> <B> to be mean the same thing for all time, but it's unreliable
<JeniT> jar: we should be able to ground this in a discussion where there's an application that do want to be able to make that distinction
<JeniT> larry: we have a system where all URIs are not cool, in 10,000 years they will stop working
<JeniT> jar: we can scope to something within the next 5 minutes
<JeniT> ... so you're right, but we're willing to make bets
<JeniT> larry: there are applications that want to make distinctions reliably, and can't, but that doesn't mean they can't be useful
<JeniT> ... the web is not completely reliable, but it's still useful
<JeniT> ... getting the first paragraph of the review of Moby Dick is still useful
<JeniT> ht: let's move on to 'proposal's
ht: let's spend 15 minutes on the third item of the agenda
jar: supposing that we want to
make distinctions, let's look at the proposals
... what are the possible sources
... in this case, let's suppose you can determine one bit of
information, "content" vs. "description", where can this come
from?
... (1) it could be in the specification
ht: that's the state we could have been in, if Dan & Tim could have enforced the hash convention
(2) it could be in the status code, headers, content ... it could be in the response
or the information could come from the exchange in http
jar: (3) 3rd source: "the message", the use of the URI, the document in which the URI occurs
(we're not talking about the merits of these)
information could come from any of these places, or a combination of them
ht: this story is situated in a context where you sent me a message that contains a URI
noah: there are other contexts?
ht: we're trying to reduce the uncertanty of a message
noah: "There are situations where
i might just find a URI" ?
... there might "I just saw a URI?"
jar: categorization of approaches
(1), (2) and (3), the architecture i attributed to tim that is
very heavy on (1) that does also involve (3) in the language
spec ....
... ... in the GET + 200 case of (2), 'retrieval', the way that
i make this distinction, i'll look at "httpRange-14a" and then
I've answered the question
... we could have another answer, "httpRange-14b"
... Roy believes HTTPbis can't answer this question
... "He cares not to discuss this"
... New taxonomy of change proposals
"Fixed mode" proposals: 'the answer comes from source (1)"
proposal httpRange-14Strengthened
AlwaysDescription
these are the two fixed answer ones
"Variable Answer" proposal:
<JeniT> jar: 1. 'no agreement' / 'nuclear' option -- no statement about relationship between resource and representation
<JeniT> ... 2. Mode determined from server response
<JeniT> ... 2a. new header that always answer the question, which has to always be present in order to tell
<JeniT> ... 2b. Mode sometimes implicit
<JeniT> ... 2bi. by default content, header means that it's not content but description (TimBL proposal for Document: header)
<JeniT> ... 2bii. by default not content, header/message says it's content
<JeniT> ... 2c. Mode determined at point of use
<JeniT> ... you can't tell from the HTTP exchange at all
<JeniT> ... only from the use of the URI
<JeniT> ht: these could fall into two categories in the same way as 2b, different defaults
<JeniT> 2d. Mode determined from the request (eg MGET, Want-Other)
<JeniT> timbl: I don't see how 2c works
<JeniT> ... how does the server know what to give back?
<JeniT> jar: the application will interpret whatever response the server provides back in the way indicated by the context in which it got the URI
<JeniT> ht: handing chair back to noah
<JeniT> noah: we have some unscheduled time
<ht> [My 'want-other' proposal about a request header is here: http://www.ltg.ed.ac.uk/~ht/wantOther.html]
<JeniT> ht: I would like 1-1.5 hours
larry: would like to minimize the amount of time on this subject
<ht> The want-other document has a potentially useful input to the role-playing discussion
timbl: this has taken up a huge amount of mailing list... would like to make progress in f2f
jeni: I think we can make some progress at this F2F
ht: I think the "role-playing", the next step wants to be "What life would be like in the major categories" ?
henry put a pointer that has an analysis by cases
<ht> I.e. an analysis by cases of what happens wrt server vs. client uptake
noah: we'll spend a significant amount of time on this... jeni made the case... we pay a lot to swap in and out
my criteria: (1) persistence... meaning should persist independent of what happens in DNS
(2) URI equivalence ... how to decide on whether URIs are the same
(3) reading on registries, registered values, vs. using URIs in protocols
(4) play without using 'owner', 'mint',...
(5) read on MIME, ...
<JeniT> larry: A story without talking about owners
<JeniT> ... it should work for all URIs, not just HTTP
<JeniT> ... without a distinction between information resource or non-information resource
<JeniT> ... RDF has to be taken as a context, and there are other languages that might have different answers
(6) doesn't rely on 'resource/representation', 'defining what a resource is or whether two resources are the same',
<JeniT> ... like to talk about persistence, which is part of not talking about HTTP
<JeniT> ... something where there's no timeout
<JeniT> ... something that someone can put in a book
<JeniT> jar: a story in which timeout is not implicit
<JeniT> timbl: I suggest that's out of scope
<JeniT> larry: I'm saying what's important to me
<JeniT> ... it's important that it works in archives
<JeniT> ... I'd like it to talk about equivalence of URIs, but not equivalence of resource
<JeniT> ... we don't have a language for naming resources aside from URIs
<JeniT> ... we can compare code points in URIs
<JeniT> ... but not resources
<JeniT> ... We had some other related findings around URIs and registeries
<JeniT> jar: what's the criterion that comes from registeries?
<JeniT> larry: the discussion about URIs is more appropriate around URNs
<JeniT> ... where there is an owner
<JeniT> ... URNs have a story where there are naming things, and documentation and owners
<JeniT> ... but that's the only naming scheme that has that property
<JeniT> ... no one gets to say what HTTP URIs mean other than the implicit meaning
<JeniT> jar: so the criterion is that it should touch on the relationship to registeries?
<JeniT> larry: touch on the relationship between these things
<JeniT> ... I laid out a story around talking in English, then markup languages, then triples
<noah> Whiteboard photos for inclusion in agenda:
<noah> http://www.w3.org/2001/tag/2012/04/httpRange14Board2_1000px.jpg
<JeniT> ... whatever proposal we accept should be cast into why we care about this as a way of enhancing communication
<noah> Closeup of small print on upper right: http://www.w3.org/2001/tag/2012/04/httpRange14Board2Closeup.jpg
<JeniT> ... with the communication being enhanced, so that it's not just talking about philosophy
<JeniT> ... I'm looking for a use case where adopting a solution helps
<JeniT> ... persistence is the one that's hardest, because no one is talking about it and I think it's important
<JeniT> noah: I have a couple of evaluation criteria too
<JeniT> ... there are constraints and good practices in Architecture of the WWW and in our findings
<JeniT> ... eg don't use one URI to identify two different things
<JeniT> ... that interactions in HTTP should be self-describing
<JeniT> ... if we have a solution that involves HTTP interactions, we should make sure they are consistent
"should work for all URIs, not just HTTP ones, should work for mailto:, data:, ftp:, file:, ..."
<JeniT> jar: the criteria for the story is different from criteria for the solution
<JeniT> noah: apply the criteria at the appropriate point
<JeniT> ashok: I'm nervous about adding lots of equations
<JeniT> ... work on some criteria and then worry about the others
<JeniT> ht: I want a solution that we think is going to change behaviour
<JeniT> ... there are two outcomes that are plausible
<JeniT> ... one is that we figure out that the current state of play is OK
<JeniT> ... the other is that we adopt a new position
<JeniT> ... if we're going to do that, we had better have a vision about how we get behaviour to change to go there
<JeniT> ... we can't just say what the Right Answer is and then say we're done
<JeniT> timbl: my criteria is that the specific cases that got us into this discussion should be addressed
<JeniT> ... eg 303s, OGP, Flickr should be addressed specifically
<JeniT> ... add Dublin Core as a use case
<JeniT> ... and an answer where we're confident that if they need to change, we can get them to change
<JeniT> ... it must work for Dublin Core and FOAF and RDFS
<JeniT> ... ie hash-oriented vocabularies must continue to work
<JeniT> noah: at what point is it worth identifying one or two solutions might be promising, based on intuition
<JeniT> ... we can ask about whether those hold up
<JeniT> ... then at the end we can look at the other proposals
<JeniT> http://www.w3.org/2001/tag/2012/04/02-agenda#IETFParis
<JeniT> Yves: about HTTP/2.0
http://www.mnot.net/blog/2012/03/31/whats_next_for_http
<JeniT> ... we had representations about 1. SPDY
http://tools.ietf.org/agenda/83/slides/slides-83-httpbis-4.pdf
<JeniT> ... 2. from Willy Tarreau, whose view came from an intermediary point of view, so included info from Squid
<JeniT> ... 3. Waka from Roy Fielding
<JeniT> ... 4. Microsoft S+M
<JeniT> s/S&M/S+M/
<JeniT> ... the goal now is to get more concrete proposals on the mailing list for evaluation before the next IETF meeting in July in Vancouver
pointers are in mnot's blog
<JeniT> ... either one document to use as a basis, or two to be compared, one which will fail
<JeniT> ... most of the proposals are for multiplexing at the application level
<JeniT> noah: SPDY is like that?
<JeniT> yves: yes
<JeniT> ... layer 7
<JeniT> ... the main discussion about SPDY is about the use of TLS or not
<JeniT> ... on the mailing list, though that wasn't so evident in the meeting
<noah> noah: right, so not e.g. the Google Maps application, but rather the Application layer of the network stack
<JeniT> ... there was one comment about authentication methods
<JeniT> ... the goal would be to completely cover HTTP/1.1 but be able to do extra things
<JeniT> jar: is there an example of something you would be able to do in the new protocol?
<JeniT> yves: eg a new method of authentication
<JeniT> larry: eg Waka includes examples of a single request naming several targets (MGET)
<JeniT> ... that would be a new feature or an optimisation
<JeniT> ... what I was interested in is that SPDY is slower for some sites
<JeniT> ... it requires some optimisation/prioritisation in the client to be used effectively
<JeniT> ... eg high priority for the first part of the document, low for the rest, so you get image headers quickly
<JeniT> ... it's about performance/reliability/security
<JeniT> ... and latency
<JeniT> ... so the features are oriented around that
<JeniT> ... earlier, I sent out a list of IETF meetings of interest, so I can go through that list
APPSAWG – “Applications Area Working Group WG”, and APPAREA (Applications area) Most things of interest to W3C are in the “applications” area The meeting reviews topics of interest, new BOFs, as well as ongoing documents http://tools.ietf.org/wg/appsawg/
<JeniT> ... I talked with Thomas and Mark about IETF/W3C dependencies and how to reduce them
<JeniT> ... normative references in W3C specs to IETF specs in progress
<JeniT> ... Apps Area WG meeting
<JeniT> ... Ned Freed's document on updating MIME registration guidelines
<JeniT> ... new draft just out, soon to be last call
<JeniT> ... if we want anything to change about MIME type registration, we need to get it into this document
<JeniT> yves: we already said something about fragments
<JeniT> larry: yes, but we should make sure that it's saying what we want it to say
<JeniT> noah: what are the timing limits?
<JeniT> larry: I don't know, but soon
<JeniT> yves: I looked at a recent version, and it looked ok
<JeniT> noah: it seems like this is something the TAG should look at
<JeniT> ... does anyone else want to sign up to double check?
<JeniT> ht: I will try to find the time, to see if the mime type to URI conversion is universal and reliable
<JeniT> ... it's IANA that manage the registry
<JeniT> ... you can get something back for some of them but not all of them
<JeniT> larry: I suggest we schedule a phone conference to review this document
<JeniT> noah: I need the URI to the document
http://tools.ietf.org/wg/appsawg/
<ht> http://tools.ietf.org/html/draft-ietf-appsawg-media-type-regs-04
<JeniT> larry: the media type reg document is the one we need to review
<JeniT> ... there is another one we need to talk about which is deprecating X-
<JeniT> timbl: is it good?
<JeniT> ht: yes
<JeniT> ... it does say that using prefixes generally is a mistake, for reasons noah will love
<noah> ACTION: Noah to schedule (soon) TAG telcon review of http://tools.ietf.org/html/draft-ietf-appsawg-media-type-regs-04 - Due 2012-04-17 [recorded in http://www.w3.org/2012/04/02-tagmem-minutes.html#action01]
<trackbot> Created ACTION-680 - schedule (soon) TAG telcon review of http://tools.ietf.org/html/draft-ietf-appsawg-media-type-regs-04 [on Noah Mendelsohn - due 2012-04-17].
<JeniT> larry: it's an interesting document that's worth reading
http://tools.ietf.org/wg/appsawg/draft-ietf-appsawg-xdash/
<JeniT> ... I like this document, but I think TAG members should read it
<ht> ACTION: Henry S to prepare TAG discussion of http://tools.ietf.org/html/draft-ietf-appsawg-media-type-regs-04 - Due 2012-04-17 [recorded in http://www.w3.org/2012/04/02-tagmem-minutes.html#action02]
<trackbot> Created ACTION-681 - S to prepare TAG discussion of http://tools.ietf.org/html/draft-ietf-appsawg-media-type-regs-04 [on Henry Thompson - due 2012-04-17].
<JeniT> noah: should these be reviewed together?
<timbl> "Deprecating the X- Prefix and Similar Constructs in Application Protocols"
<JeniT> larry: they are independent, and the X- document may not require TAG discussion, though I recommend reading it
<timbl> and Similar Constructs
<noah> LM: Not convinced we need telcon discussion of x-prefix, but TAG should review.
<JeniT> robin: should this be brought to general attention within W3C?
<noah> NM: OK, I'll only schedule x-dash if asked.
<JeniT> ... should it be sent to the Chairs list for broader review?
<JeniT> larry: yes, that would be good
<JeniT> larry: there's another document which was discussed
http://tools.ietf.org/html/draft-nottingham-appsawg-happiana-00
<noah> Who's going to send it to chairs' list? I suggest Larry as he has most context, but could do it if that helps for some reason.
<JeniT> ... being prepared to be accepted by the Apps Area WG
<JeniT> ... talking about the process around getting things into registeries
<JeniT> ... based on the happiana effort
<JeniT> ... that document is even more important for Chairs at W3C
<JeniT> ... that's it for the AppAreaWG meeting
<JeniT> ... on to WebSecWG
<JeniT> ... mainly working on strict transport security & TLS
<JeniT> ... also an issue around the mime sniffing document, which has expired
<JeniT> ... the security problem could be addressed by giving sniff content a different origin
<JeniT> ... if you have overridden the mime type, then you have given it a different origin
<JeniT> ... this would address the cross-origin problems that arise from sniffing
<JeniT> ... and I have not seen counter examples
<JeniT> ... it was discussed and dismissed beconstitute "browsers won't do it"
<JeniT> ... but browsers don't do what's being said anyway
<JeniT> ... why not have a different fantasy
<JeniT> ... email clients do sniffing all the time
<JeniT> ... the Web Security Handbook talks about sniffing
<JeniT> ... just like we have URIs in different contexts, does sniffing happen differently in different contexts
<JeniT> ... meant to go to URNbis
<JeniT> ... WG revising URN document
<JeniT> ... the TAG has expressed opinions about URNs, and I wish I had gone
<JeniT> ... we should review their documents
<JeniT> jar: I think Julian has been paying attention to what they're doing
<JeniT> larry: my opinion has changed about them
<JeniT> ... it may have been a design goal to have something persistent
<JeniT> ... in fact it is not about persistent, but about ownership
<JeniT> ... there's no owner of an HTTP URI, but there is one about URNs
<JeniT> ... Technical Plenary on browser security
<JeniT> ... HTTP 1.1 is reaching closure
<JeniT> yves: there's currently discussion about folding back documents together, adding a Part 0 so it's easier to find stuff
<JeniT> ... merging Part 1 & Part 3
<JeniT> ... not sure about Part 0
<JeniT> ... currently Part 4-7 are in IETF last call
<JeniT> ... everything else should be in last call from the last draft
<JeniT> larry: these are core documents, and the TAG should review them
<JeniT> yves: most particularly Part 1 & Part 3, the others are extensions
<JeniT> jar: Part 2 is pretty important
<JeniT> s/Part 1 & Part 3/Part 1 to Part 3/
<JeniT> yves: wait for next draft for review
<JeniT> noah: we often say we should review things, but we don't get people's attention to review them
<JeniT> ... perhaps an email that points to particular things
<JeniT> jar: I could point to the parts I've been paying attention to
<noah> ACTION: Jonathan to suggest to TAG sections of HTTPbis specification that TAG should review - Due 2012-04-17 [recorded in http://www.w3.org/2012/04/02-tagmem-minutes.html#action03]
<trackbot> Created ACTION-682 - suggest to TAG sections of HTTPbis specification that TAG should review [on Jonathan Rees - due 2012-04-17].
<JeniT> yves: Dom should be able to report on RTC web
<jrees_> Note to minutes editor: Please add link http://lists.w3.org/Archives/Public/www-archive/2012Apr/0003.html at end of previous topic (that's the emacs buffer that was projected)
<JeniT> ... it was also about security
<JeniT> larry: security is what makes most protocol design hard
<JeniT> ... because you can't just optimise for performance and reliability
<JeniT> ... you have to design against hostile players
<JeniT> ht: what's HyBi doing?
<JeniT> yves: it's WebSockets
<JeniT> ... not the API, the protocol
<JeniT> larry: the relationship between IETF and W3C work in many of these areas is that W3C focuses on API in JS on how you invoke it, and IETF on what goes on the wire
<JeniT> noah: I had missed these were the two sides of the same coin
<JeniT> larry: I don't know what the status is
<JeniT> ... the TAG should have a review or invite someone to come and talk to us about it
<JeniT> ... where we don't have the impetus to review it ourselves, we should get someone in
<JeniT> ht: this is close to home because it's getting integrated into HTML
<JeniT> ... we have to be sure this isn't going to change the architecture of browsing over the next 5 years
<JeniT> larry: I think we should look for someone to come and present to us
<JeniT> noah: any suggestions about who?
<JeniT> yves: Thomas is watching this
<JeniT> larry: we might ask Thomas to recommend someone
<JeniT> ... there was a BOF, where I gave a presentation, to consider the document format of RFCs
<noah> ACTION: Yves to figure out who might be a good choice to present Hybi (and as appropriate WebSocket protocols) to the TAG [recorded in http://www.w3.org/2012/04/02-tagmem-minutes.html#action04]
<trackbot> Created ACTION-683 - Figure out who might be a good choice to present Hybi (and as appropriate WebSocket protocols) to the TAG [on Yves Lafon - due 2012-04-09].
<JeniT> ... the driving use case is documents that need non-ASCII characters
<JeniT> ... to show encoding
<JeniT> ... IETF does allow alternative presentations in PostScript and PDF
<JeniT> ... Martin Durst submitted a document on internationalisation of mailto URIs
<JeniT> ... where the PDF version has examples that are in Unicode
<JeniT> ... running a pre-processor on the XML so that you can have an HTML version with Unicode, and a text version in ASCII
<JeniT> ... the IRI WG
<JeniT> ... again, planning on last calling IRI documents before next IETF meeting
<JeniT> ht: please could you tell me when the XML Core WG should look at those
<JeniT> larry: there are four documents:
<JeniT> ... guidelines & process for registering schemes
<JeniT> ... takes 3987 which used to be one document, and split out section on comparison and bi-directional IRIs
<JeniT> ... the comparison document needs work, because it's a security document to avoid spoofing
<JeniT> ... it can't be a ladder
<JeniT> ... my take is IRI everywhere is not the right answer
<JeniT> ... that there are some contexts where you will want URIs
<JeniT> Adjourn for lunch
<robin> ScribeNick: robin
<ht> http://www.guardian.co.uk/world/2012/apr/02/email-web-monitoring-powers-privacy
NM: worth reviewing the goals of this work
<JeniT> http://www.w3.org/2001/tag/products/PublishingLinking-2011-12-27.html
[NM reads from the product page]
JAR: who wrote that, it's really good?
NM: we did it together
... we can always change these goals, but we should do so
consciously
<JeniT> http://www.w3.org/2001/tag/products/PublishingLinking.html
NM: we claimed PR in 2012-06, that seems tight
<JeniT> dated version: http://www.w3.org/2001/tag/products/PublishingLinking-2012-01-08.html
NM: DKA, are you avaialble for more work on this?
DKA: not in an official capacity, but I will help
AM: how do we make sure it is valuable to policymakers
NM: I don't know, trying to get
us in a mindset where we try to make it useful to them
... we can try, and if it fails learn from our errors
AM: how about asking them earlier if it helps
NM: not sure we want to debate this now
LM: I think it would be useful
after reviewing the draft to look into administrative next
steps
... e.g. forming a CG around this
<JeniT> http://www.w3.org/2001/tag/doc/publishingAndLinkingOnTheWeb-2012-01-04.html
NM: review the draft
... aiming for FPWD
JT: my aim for this session is to
get agreement on publication
... what I'd really like to do is focus on points that people
feel strongly should prevent it from FPWD
... rather than editorials
<Zakim> timbl, you wanted to say that JAR's way of defining 'content of' is very good and to
JT: editorials should be sent by
email
... is there anything that people want to say fisrt off?
LM: this is a marvellous piece of hard work, my only concerns are about positioning and how we move forward with this
AM: me too
LM: no matter how much we polish it, we will get feedback and divergent comments
JT: but the only way to get those is to put this out there
LM: yes, but I would like to
encourage their participation actively
... (in SotD)
[JT goes through section by section]
JT: Abstract
TBL: this isn't an abstract at all
JAR: matching with goals, does
more than set definitions for terms
... try to match the abstract with the goals from the product
page which were really good
LM: the product page could be the abstract
NM: extract some of it at least
LM: not an academic abstract, treat it like an ad for why people should read it
AM: it mentions issues that were raised to the TAG — were they really raised to the TAG?
LM: I'd get rid of that
JT: OK
... we'll rephrase that last §
DKA: pull it out, highlight that in introduction
<Larry> s/get rid of that/get rid of the bit about legal issues/
NM: can be very picky, but don't
want to drag the group down
... but since we're writing for a community of lawyers we
should be ruthless about drawing clear distinctions
... do people agree that that level of care is required?
<Larry> I think we should indicate that we need to be ruthless, but not before we publish FPWD
NM: concerned that this could be used in court
JAR: there's a tension between explaining words used in our community versus words defined by this document
<Larry> explain words used in the community, as well as defining specific terms which could be used more precisely
JAR: if the goal is former, then
entries need citations (though probably good as a FPWD)
... different goals: being clear, and explaining usage
NM: users versus user agent, not clear
<Larry> I think we have to do both
JAR: careful definition of UA in document, different from usage in some places
JT: different places that define these things are conflicting
JAR: agree, but hard to resolve to tension
LM: the document may have to do
both
... explain how terms are used in the community, and where
there are contradictions come up with a new definition and
recommend caution in future
<Zakim> Larry, you wanted to argue for doing both
NM: usually in the community UA
== browser
... but here the definition is different because it's anything
that accesses web content
JT: what I'm taking away is to go through that set of terms, find citations/existing uses, and discuss the multiple existing/confliction terms then make sure the document is consistent
NM: be precise where we can be,
and if it's inappropriate signal it
... UA is an example of this
TBL: for the TAG in general, the
idea of UA is really important
... for me, a UA is a piece of software that represents
me
... when you put User-Agent, you're representing someone
else
<Larry> unfortunately, "User Agent" is also used for identification of the HTTP client, even when it isn't working on behalf of any particular user.... a spider or web crawler has a "User-Agent" string. It was an error to name this "User Agent" in HTTP
LM: the problem is that User-Agent header is used to identify the web client rather than a UA
NM: explain the different uses in technical community, and say which one is used here
LM: in most cases there isn't a problem, but for legal cases it may matter
JT: arguably spiders are acting on behalf of someone
LM: but there's no identifiable user
<timbl> Many subsystems with thin the web, like proxies and archives, are automated and incapable of exercising moral judgement, and requiring them to would be impossibly onerous.
JT: moving on to Introduction
<timbl> ^ attemtp to capture the best practuces in a scentence for the abstract
<Larry> well, or at least for identification of whether there is a single responsible person for whose benefit the agent is operating
TBL: Abstract is very good compared to most abstracts out there
<nmendels> 1.0 Introduction:
<nmendels> I suggest chg/The page itself may cause/logic encoded with the page may cause/
NM: reason is, we in the
community understand what it means when we say "the page cause
a retrieval", but that notion would seem bizarre to people
outside
... hence the use of "logic", which is easier to explain
JAR: the notion of agency is central, because this is legal — who causes something to happen?
<nmendels> Well, it's really that, in the real world, pages don
AM: yes
<nmendels> don't caus things to happen.
AM: have you looked at the legal interpretation of agency, there's a whole bunch of stuff there
<nmendels> 2nd paragraph.
JAR: not sure it's relevant here,
might be useful in writing the document, but not necessary to
capture it directly
... good thing to put on the TODO list, but no need to prevent
FPWD
AM: yeah
<nmendels> Suggest chg/Proxy servers and services that combine and repackage data from other sources may also retain copies of this material, due to the user's original request for the page./Proxy servers and services that combine and repackage data from other sources may also retain copies of this material/ (I.e. delete phrase at end)
<nmendels> Reason: proxy servers wind up holding onto things for lots of reasons.
TBL: agency makes my rant stronger about UAs acting on behalf of users
<nmendels> 3rd para:
<nmendels> Still other services on the web, such as search engines and archives, make copies of content as a matter of course
JAR: "intents and conditions...." don't use passive — this is not editorial because agency matter
<nmendels> Suggest after "matter of course": in part to facilitate the indexing necessary to their operation, and in part to enable presentation of search results"
<nmendels> Suggest delete: (as it enables the content to be found more easily)
DKA: the problem is that if you load these § with contextual clarification then it starts to get quite heavy
JAR: use your judgement
NM: legal community have an extraordinary capability for this, clarity is important
JT: already talked about tightening up terminology — so we can skip over that section
<timbl> "For instance, one standard set of terms and conditions includes" -- reference?
NM: "not taking into account this complexity" — is this a bad thing?
JT: yes, this is an example of
trouble
... with "distribute", the problem is transfer of ownership
because there is no transfer
NM: would be useful to clarify this below the box
HT: the Guardian has this profile
thing where they put footnotes
... you could use little anchors to highlight or signal
problems in the text
... this is a great way to show where the problems are, to make
people realise that standard boilerplate is full of gotchas
NM: might be worth picking the problem apart
JT: would you say that throughout the entire background, it would expand it
HT: I was thinking mostly about the box examples
JAR: might be nice to have a couple sentences after each example to explain what is an example about it
LM: can you use a different style for examples?
RB: you can use class=example
NM: this is fine, we can refine style
JT: used blockquote to indicate them
TBL: when you quote gsip.com, is it possible to use a copy of their T&C since it may not be stable
<nmendels> Propose after box on scraping: "Yet, the automated agents on which the Web depends are incapable of reliably understanding such written licenses."
JAR: you can't even mention aa.com, so you couldn't cite the source properly
NM: § that says "limits placed on
use of a website"... suggest that after that, you put [pasted
above in IRC]
... you don't want to fix this, but NLP is not an option
s/but NLP/NLP/
NM: explain why deep link § is a problem
JT: similar to previous comment
NM: happy to skip if you feel
you've got that for all instances
... the SHOULD not be misleading part — something about the
different between SHOULD and MUST ought to be clarified
JAR: this is legal language
NM: right, which may be different from RFC2119
JAR: should we include reference
to 2119 in terminology?
... I don't think it's implied that everything in the box is
bad
NM: it's fine if it's clear that
these are just examples of things we need to talk about
... wonder if scope should move up, to establish
expectations?
JT: Publishing section
... 3.1 Hosting
NM: §1 too strong, trying to say
it's not a proxy
... but is confusing
TBL: what do you mean by that?
JT: it's not a copy of something
that's being hosted somewhere else
... trying to separate out the case where this is the original
content
NM: if we have a photograph,
hosted on her website
... I want to copy it (with permission); now we're both hosting
it
... but with your definition I'm not
JT: here we really want to talk about the original, not the copy
TBL: I disagree, if you set up software on your server you're serving pre-existing content, not the original but you're still hosting it
JAR: delete the notion of "original"
<nmendels> Section 3.1, suggest:
HT: the two cases I am concerned with are those in which jailed infringer is said to "just link" to content
JT: he was embedding it
<nmendels> chg/does not necessarily mean that the organisation that owns and maintains the server has an awareness of that data being present/does not necessarily mean that the organisation that owns and maintains the server has an awareness of the details or intended meaning of that data./
<nmendels> Reason: surely it's aware of the bits.
JT: but he was not hosting it
HT: "just linking" conjures up
the notion of clicking, a user action
... so we need to be clear that hosting here covers that
case
NM: my ISP knows what files I've put there
HT: no they don't
... "know" is not a helpful word
... they shouldn't be asked to find out if you have child
pornography
s/... they shouldn't be asked to find out if you have child pornography/NM: they shouldn't be asked to find out if you have child pornography/
HT: they know a whole lot less than that
TBL: two types of know 1) is are aware of it as a matter of business, and 2) could find out if they paid someone to do it
JT: has "specific" awareness?
HT: ok
<Larry> to what extent does provenance help ?
[discussion about Wendy]
NM: we should check the awareness issue with her
<jrees> a to-do (after Dijkstra): check verbs to consider appropriateness of automata or documents being active agents, replace when appropriate with people or organization (e.g. "server being aware" to "server operator being aware")
NM: would like this § to dig deeper into the difference between knowing that data is there and knowing its nature
JT: I understand the comments, will rephrase
LM: does the work on provenance
help here?
... were you to record provenance, could you push
responsibility back to originator
JAR: out of scope
<nmendels> Noah notes we're run off the end of the parts he's read :-(
LM: why is it out of scope?
JAR/RB: because the technology is not there
LM: but to what extent *could* this be useful? Ask the provenance group?
JT: maybe this could go into section 4 since it's about tecniques?
<ht> "any specific awareness of that data being present, much less of its nature." would do it for me
LM: the TAG has more influence over W3C and its groups than web page hosters
HT: there's a WG
[meta discussion]
JT: would like to come out of f2f with plan forward, not just publishing but also potential CG
HT: would anyone object to FPWD at this stage, assuming Jeni takes comments into account?
LM: so long as the abstract is clearer on next steps I would be fine
<Larry> my only concern is that the introduction makes it clear that we're open as to next steps
JT: let me try to draft something and when we come back on Wednesday we can figure that out
<Larry> clearer that 'next steps' are open
NM: so no one likely objects to FPWD, how much do we need a longer session?
[no objection]
NM: anything other than actions?
AM: yes. the idea here is to
influence the legal ecosystem.
... publishing it as a finding will not do that
... a Rec is not enough either
... it's not sufficient
JAR: you need publicity
AM: need to involve a broader community
JAR: won't be hard to sell, if the EFF learns about it it will be pushed
HT: we will work to push this in public outlets
NM: take an action long term on getting this on policy radar?
LM: we need to get to a position that people who have a stake in this game can voice their opinions, concerned about a TAG Rec
<Larry> i'm concerned that we establish a next step process which actually engaged in discussing the content
NM: so you're saying that some of the relevant people might not be comfortable with www-tag?
LM/AM: yes
NM: we'll talk on Wednesday about next steps
LM: want some feedback from relevant community, not sure how politically sensitive this is
JT: please email further comments
[break]
NM: there will be a short session on this on Wednesday
<masinter> http://www.adobe.com/content/dam/Adobe/en/devnet/xmp/pdfs/DynamicMediaXMPPartnerGuide.pdf#page=6
<JeniT> ScribeNick: JeniT
noah: welcome to Robin
noah: Product page is no longer a
draft:
http://www.w3.org/2001/tag/products/apiminimization-2012-02-02.html
... review of
http://www.w3.org/2001/tag/doc/privacy-by-design-in-apis-2012-03-27
robin: the feedback I've got is
that the scope should be clarified
... so I will clarify it here
... the background is: we started working on Geo API
... this had privacy impacts
... in DAP we tried to take into account privacy from day
one
... DAP started to think about how to do privacy in APIs
... one principle was API minimisation which led to DKA's
draft
... now, that is only used in one API
... and not used in any other WG
... because we've moved on to other techniques
... so API minimisation needs to be set into a broader
framework
... applicable to several groups who are defining APIs
<Zakim> DKA, you wanted to ask robin to put the good parts back in
DKA: that all sounds great
... *but* I think you've taken out bits that shouldn't have
been taken out
<DKA> http://www.cs.virginia.edu/~evans/cs551/saltzer/
DKA: for instance, the original draft referenced Saltzer & Schroeder
jar: in academia, this is the seminal classic on the subject
<DKA> http://escholarship.org/uc/item/0rp834wf
DKA: I understand why you might
not want to bring those things up
... but I think it's important to do so, to mend the fence
between the "privacy nuts" and the "script kiddies"
... there is really good information in the Dierdre Mulligan
document
... and in the Saltzer document
... these are architectural principles that could be brought
into the modern age
<jrees> Official but paywalled location of S&S's classic: http://dx.doi/org/10.1109/PROC.1975.9939
DKA: if the additional techniques
that you think could be recommended enhance these
... then point that out
... point out that it helps to minimise the data that flows
down the line
... I would like that work, which I think is good, to be
brought through
robin: I hear that the digestion process was too aggressive
DKA: you know the latest stuff
from DAP
... have the principles been tossed out?
robin: mostly the document from
which they come has not been updated in three years
... no one has read it in two years
DKA: did they need to be updated?
robin: I don't have a problem
with the meaning of the principles, but the phrasing is
probably off
... because the discussions have happened in other WGs
... and whenever the document has been cited, it's been
ignored
<DKA> http://dev.w3.org/2009/dap/privacy-reqs/#privacy-minimization
robin: so clearly it's not
expressing things in a way that people are able to use it
... I'm happy to try to revive those principles more actively,
but we need to rephrase them
... and I'm happy to do that
... I really tried to make this document a how-to manual for
people busy writing specs
... so if I'm writing a spec, what do I need to read to get it
right
... a short, checklist document
... I could re-organise the document so it serves both
ends
... there's good architectural matter in the documents you
cited
... so I will try to restructure to serve both documents, I
think that's doable
... the fast reading for the spec writers, and then there's the
background that can inform further thinking
DKA: yes, and give the reasons for why the techniques work
ashok: when we started this work,
we really wanted to do something in the privacy area
... DKA found this well-scoped, well-defined area, which he
wrote up
... and we hoped we could close on it quickly
... what I'm worried about is that the scope has been
enlarged
robin: slightly
ashok: the parts that you've
added are different
... they seem to be addressing a different problem with
different solutions
... it looks like two ideas in this space, and I'm not sure
whether we shouldn't break them up into two things
jar: or there might be more, two is a funny number
ashok: there's lots of issues in privacy, and we couldn't possibly handle them all
robin: I don't want to boil the
privacy ocean
... this document is scoped to what you can do about privacy
inside a User Agent API
... it's not everything that could possibly do in this
area
... but I think it does scope the problem in a way that is
useful and applicable by people who are working in this
space
... and it would be difficult to explain them in isolation
ashok: so these are two directions that a user agent could take to help protect privacy
<Zakim> nmendels, you wanted to talk about tradeoffs
robin: not the user agent, but the design of the API to be run within the user agent
noah: this is good work
... I think it's coherent in its scope
... I'm worried about it taking a long time, so focusing on the
most important thing is a good idea
... you were saying that you wanted to do a quick guide for
people building these things
... I think the TAG is at its best when it tries to tell
stories that have longevity
... there are tradeoffs in the designs of the APIs
... I'd expect to see those tradeoffs set out, for example how
testable the API is
... as it will have a bigger surface area
<masinter> I don't think this is the right recommendation for "privacy by design". I'm not certain privacy-by-design if only because there isn't even a clear definition of the "privacy" design goal. I think this is consistent, I was worried about API minimization. Note GEOPRIV policy document http://tools.ietf.org/html/draft-ietf-geopriv-policy-25 in 25th revision
noah: also talk about
performance
... numbers of calls on the API
... draw out the core things
... to teach people to think deeply
... handy guides are great as well
... but I'd skew it more towards longevity
<Zakim> timbl, you wanted to feel that a document of this sort should mention acceptable use tracking, and the concept of accptabl euse for a user aget and fo a community of agents of
timbl: basically, I think it's a
very useful document
... two separate things that occur to me
... talking about acceptable use
... that's what came out of a privacy workshop at MIT
... about capturing policy
... if you're a user agent, you don't want to do anything
unexpected or damaging
... if I've decided to share something (eg a calendar
entry)
... I select the two people to share it with
... my app might decide to send them emails
... it would be more reasonable for it to pop up the email so I
can edit it
... it's different to add the name & address to a mailing
list
... which leads to the idea that sometimes there's an implicit
use
... you haven't captured what you said the data could be used
for
robin: looking at data usage is a
fundamental question in privacy
... but it's hard to put that into API design
... but you'll get pushback from API designers
... and you'll get a fight, and it won't give progress
jar: can we learn from that conflict?
timbl: the related thing is
between a trusted and an untrusted app
... web apps have to have total power, so they become trusted
apps
... with an untrusted app, it's difficult to stop them from
using the data for something different
... but then there's a trusted app talking to an untrusted
app
<masinter> note long discussion about whether SPDY's use of SSL offers a "promise of improved privacy"
timbl: at that point it might be
reasonable to have a negotiation about acceptable use
... because the trusted app gathers the data to do something
specific
robin: it would make sense, but
we don't want to reinvent P3P
... DAP started looking at rulesets, a simplified version of
P3P
... so a server could say what it wants to do with the
data
... there's only one person in the privacy community who
cares
... and no one in the browser space
... no one sees how to make that work in the broader
sense
... the solution we've come up with at the moment is user
mediation
... so web intents allow the initiation of communication
between a server you trust and another that you don't
... or vice versa
... with the user in the middle saying ok about the
transfers
<Zakim> DKA, you wanted to comment on scope
<masinter> main problem is that the design requirements for privacy, accessibility, performance, security from eavesdroppers, etc. can't be evaluated in isololation, so "X by design" in general is problematic
DKA: I want to comment on scope
and support Robin
... the original idea we had for privacy on the TAG was data
minimisation as one targetted document as a series of things we
could say
... I struggled to think about what that set should say
... your revised title and scope for this document really made
sense to me
... how do you apply the 'privacy by design' idea to API
design
... I have been thinking about this for a while, and this
brought that back to me
... so I support that idea
<masinter> http://www.ietf.org/mail-archive/web/privacydir/current/msg00053.html
DKA: and I think the scope you've
chosen is not boil the privacy ocean
... it's focusing on the API design, rather than all the
potential issues that the TAG might hit on privacy
robin: yes, and it stops where
the IAB's work on privacy starts
... the IAB works up to the protocol layer
... and I hope their work will also address data usage
larry: I'm really concerned about
the TAG taking this on as a work item
... not because it's not important, but because we're
optimising about a moving set of requirements
... we had a discussion about SPDY's use of SSL and found we
didn't really have a common understanding of what privacy
meant
... we're optimising against a goal that is not clearly
understood in the industry
... the GeoPriv policy expression language has been repeatedly
revised
... the subject is controversial enough and has a lot of
different perspectives
... it seems unlikely that the TAG will converge on a finding
that will fit with those
... especially as the IAB is moving about what it covers
... we have the area of variability around the tradeoffs
... and about the definition of privacy and the channels of
communication
... and then there's the boundary between this and other TAG
work
... the boundaries feel very fuzzy to me
robin: you're worried about us broadening the scope?
larry: we have a risk of
overlapping and saying something contradictory, or leaving a
gap between this work and others' work
... to shallow to the point it's not actionable, or too
deep
yves: what about the risk of saying nothing?
larry: what's the boundary
between the TAG and the privacy interest group etc
... there are other groups who are strongly chartered to work
on this
<masinter> wonders if we are really ready to negotiate a boundary with IAB
larry: maybe we could come up with something that's shorter and more generic to encourage further work
robin: we should talk about this
in the session with Dom tomorrow
... I did meet up with Christine who is chairing the privacy
interest group
... to discuss whether this is of interest to them, whether
they should be doing it, whether the TAG should be doing
it
... I've also been talking about it with the IAB as well
<robin> http://tools.ietf.org/html/draft-iab-privacy-considerations-02
robin: the reasonable consensus
is that the IAB are working at the protocol level
... and I have the impression that they are happy with this
noah: isn't there a lot of conceptual stuff that has to be sorted out across these
robin: yes, so we've spoken about
terminology
... which is still a moving target
noah: do they include a threat matrix?
robin: they start with an internet privacy threat model
noah: that seems important to agree on, what the problem space is
robin: yes, so their terminology
is too much of a moving target to be reused, so that will need
to be revisited at intervals
... as far as the Privacy IG goes, Christine felt that some
joint work, either joint review or a joint TF
... to look at policy and that we could contribute
technological view
larry: I talked to people at the
IETF meeting, to the IAB, to Wendy, to Thomas, and they didn't
mention any of this
... for you to have a private discussion, that the others in
the IAB and Privacy IG aren't aware of makes me worried
robin: these discussions happened Thursday and Friday
larry: we need to arrange discussions with the IAB in order to collaborate with them
noah: getting colocated with the
IAB has proven difficult
... we couldn't have a TAG meeting at the same time as the IETF
meeting
larry: my concern is about overlapping with other groups
<Zakim> jar, you wanted to urge disclaimer about sampling of techniques, it's not a comprehensive treatment
jar: there's something that feels
incomplete about the draft
... about how the scope is set
... if you just look at the title it looks like it's about all
privacy issues
... what you've said today about the scope is really important,
and should go into the introduction
... this is really just a sampling of things that have come up
through the WG process
timbl: you could have a related work section
jar: there's a lot of interesting
stuff in this space
... you should say that
noah: say why we chose these bits
now
... and what you should watch out for because we haven't
covered it here
... stuff that hasn't been touched: different threat models,
different capabilities
jar: give space for the reader to
realise that this is a sampling of what we know about right
now
... it might end up being complete, but because it's an active
area it's unlikely to be
robin: this is like a BCP more than anything else
noah: it might just be
early
... a year ago people were talking about minimisation
timbl: I like 'patterns in API
design'
... and you could mention an anti-pattern, things that you
didn't cover
... you're not saying they're best, that they could work for
some people
robin: the reason I didn't use
'pattern' was that several groups said it would tie it to
'design patterns'
... which is a little old-fashioned
... personally 'pattern' would have been something that I would
have used, but some people are scared of using that word
<Zakim> nmendels, you wanted to say we must be willing to say we don't have good answers on, e.g. policy
robin: I'm happy to try using it
<timbl> Alexander et al A Pattern Language
<timbl> 1865
noah: talking about policy, and
that we don't have good answers
... there's a risk of telling the piece of the story we
understand in isolation
... and perhaps without policy it doesn't matter
... need to explain which part of the problem these designs
will solve
noah: and what issues it doesn't
solve
... if it can do it without talking about policy, I'm happy
robin: I think that's part of explaining the scoping better
noah: let's see if we can tell
enough of the story with this
... we have another session on this tomorrow to review how this
went with Dom
... and we can go over logistics at that point
... so let's wrap this up for now and come back on it
tomorrow
Adjourned
This is scribe.perl Revision: 1.136 of Date: 2011/05/12 12:01:43 Check for newer version at http://dev.w3.org/cvsweb/~checkout~/2002/scribe/ Guessing input format: RRSAgent_Text_Format (score 1.00) Succeeded: s/ww.w3/www.w3/ Succeeded: s/to do/to give web docs metadata/ Succeeded: s/You said/You (LM) said/ Succeeded: s/quote/'quote'/ Succeeded: s/what/jar: what/ Succeeded: s/by default description/by default not content/ Succeeded: s/in our findings/in Architecture of the WWW and in our findings/ Succeeded: s/S&M/S+M/ FAILED: s/S&M/S+M/ FAILED: s/Part 1 & Part 3/Part 1 to Part 3/ Succeeded: s/cause/constitute/ FAILED: s/get rid of that/get rid of the bit about legal issues/ FAILED: s/but NLP/NLP/ FAILED: s/... they shouldn't be asked to find out if you have child pornography/NM: they shouldn't be asked to find out if you have child pornography/ Found Scribe: Larry Inferring ScribeNick: Larry Found ScribeNick: robin Found ScribeNick: JeniT ScribeNicks: Larry, robin, JeniT WARNING: No "Present: ... " found! Possibly Present: AM DKA JT JeniT LM NM RB Reason ScribeNick TBL TimBL Yves ashok different ht jar jeni jrees jrees_ larry masinter nmendels noah parties plinss rep robin scribenic tim timbl_ trackbot You can indicate people for the Present list like this: <dbooth> Present: dbooth jonathan mary <dbooth> Present+ amy Agenda: http://www.w3.org/2001/tag/2012/04/02-agenda Found Date: 02 Apr 2012 Guessing minutes URL: http://www.w3.org/2012/04/02-tagmem-minutes.html People with action items: henry jonathan noah s yves[End of scribe.perl diagnostic output]
{kind=link}
{kind=link}