The history of the Semantic Web goes back to several years now
It is worth looking at what has been achieved, where we are, and where we might be going…
Let us look at some results first!
The basics: RDF(S)
We have a solid specification since 2004: well defined (formal) semantics, clear RDF/XML syntax
Lots of tools are available. Are listed on W3C’s wiki:
RDF programming environment for 14+ languages, including C, C++, Python, Java,
Javascript, Ruby, PHP,… (no Cobol or Ada yet !)
13+ Triple Stores, ie, database systems to store (sometimes huge!) datasets
converters to and from RDF
etc
Some of the tools are Open Source, some are not; some are very mature, some
are not :
it is the usual picture of software tools, nothing special any more!
Anybody can start developing RDF-based applications today
The basics: RDF(S) (cont.)
There are lots of tutorials, overviews, and books around
again, some of them good, some of them bad, just as with any other areas…
Active developers’ communities
Large datasets are accumulating. E.g.:
IngentaConnect bibliographic metadata storage: over 200 million triplets
New issues may pop up at the last moment via reviews
a query language needs very precise semantics and that is not that easy
Some features are missing
control and/or description on the entailment regimes of the triple store (RDFS? OWL-DL? OWL-Lite?…)
modify the triple store
…
postponed to a next version…
Of course, not everything is so rosy…
There are a number of issues, problems
how to get RDF data
missing functionalities: rules, “light” ontologies, fuzzy reasoning, necessity to review RDF and OWL,…
misconceptions, messaging problems
need for more applications, deployment, acceptance
etc
How to get RDF data?
Of course, one could create RDF data manually…
… but that is unrealistic on a large scale
Goal is to generate RDF data automatically when possible and “fill in” by hand only when necessary
Data may be around already…
Part of the (meta)data information is present in tools … but thrown away at output
e.g., a business chart can be generated by a tool: it “knows” the structure, the
classification, etc. of the chart, but, usually, this information is lost
storing it in web data would be easy!
“SW-aware” tools are around (even if you do not know it…), though more would be good:
Photoshop CS stores metadata in RDF in, say, jpg files (using
XMP)
RSS1.0 feeds are
generated by (almost) all blogging systems (a huge amount of RDF data!)
…
Data may be extracted (a.k.a. “scraped”)
Different tools, services, etc, come around every day:
Although tools exist, it is not feasible to convert that data into RDF
Instead: SQL ⇋ RDF “bridges” are being developed:
a query to RDF data is transformed into SQL on-the-fly
the modalities are governed by small, local ontologies or rules
An active area of development, on the radar screen of W3C!
SPARQL as a unifying point?
Missing features, functionalities…
Everybody has a favorite item, ie, the list tends to infinite…
W3C is a standardization body, and has to look at where a consensus can be found
Rules
OWL-DL and OWL-Lite are based on Description Logic; there are things that DL cannot express
a well known examples is Horn rules (eg, the “uncle” relationship):
(P1 ∧ P2 ∧ …) → C
e.g.: for any «X», «Y» and «Z»: “if «Y» is a
parent of «X», and «Z» is a brother of «Y» then «Z» is the
uncle of «X»”
there are a number of attempts to combined these: RuleML,
SWRL,
cwm, …
There is also an increasing number of rule-based system that want to interchange rules
a new type of data (potentially) on the Web to be interchanged…
Some typical use cases
Negotiate eBusiness contracts across platforms: supply vendor-neutral representation of your business rules so that others may find you
Describe privacy requirements and policies, and let clients “merge” those (e.g., when paying with a credit card)
Medical decision support, combining rules on diagnoses, drug prescription conditions, etc,
Extend RDFS (or OWL) with rule-based statements (e.g., the uncle example)
In an ideal World…
In the real World…
Rule based systems can be very different
different rule semantics (based on various type of model theories, on proof systems, etc)
production rule systems, with procedural references, state transitions, etc
RIF “core”: only partial interchange
Specification of the “core” is the first step
It also forms a logic language to be used, eg, with OWL, RDF, XML data, …
RIF “variants”
Possible variants: F-logic, production rules, fuzzy logic systems, …; none of these have been finalized yet
Role of variants
“Light” ontologies
For a number of applications RDFS is not enough, but even OWL Lite is too much
There may be a need for a “light” version of OWL, just a few extra possibilities v.a.v. RDFS
There are a number of proposals, papers, prototypes around: RDFS++, OWL Feather, pD*,…
pD*, for example, has property characterization (symmetric, transitive, inverse),
class and property equivalence, and property restrictions with some or all values
This might consolidate in the coming years
Revisions of RDF and OWL?
Such specifications have their own life
Missing features come up, errors show up
There will probably be a next version at some point
Revision of the RDF model?
Some restrictions in RDF may be unnecessary (bNodes as predicates, literals as subject,…)
Issue of “named graph”: possibility to give a URI to a set of triplets and make statements on those
Syntax issues in RDF/XML (eg, QNames in properties)
Alternative XML serializations?
Add a time tag to statements? A probability value? A measure of “fuzzyness”?
Internationalization issues with literals (how do I set “bidi” writing?)
These are just ideas floating around…
Revision of OWL? (OWL 1.1)
There is a group working on this (outside W3C for now)
“qualified cardinality restrictions” (i.e., “class instance must have two black cats”)
disjoint properties
reflexive, irreflexive properties
property composition
own datatype constructs instead of complex XML Schema datatypes
“light” ontologies (called “tracable fragments”)
some syntactic sugar (eg, disjoint union)
…
At this moment not yet decided how, if, and when this would become a W3C document
Other items…
Fuzzy logic
look at alternatives of Description Logic based on fuzzy logic
alternatively, extend RDF(S) with fuzzy notions
Probabilistic statements
have an OWL class membership with a specific probability
combine reasoners with Bayesian networks
Security, trust, provenance
combining cryptographic techniques with the RDF model, sign a portion of the graph, etc
Ontology merging, alignment, term equivalences, versioning, development, …
etc
(Need a new PhD topic?)
A major problem: messaging
Some of the messaging on Semantic Web has
gone terribly wrong . See these statements:
“the Semantic Web is a reincarnation of Artificial Intelligence on the Web”
“it relies on giant, centrally controlled ontologies for "meaning" (as opposed to
a democratic, bottom–up control of terms)”
“one has to add metadata to all Web pages, convert all relational databases, and XML data to
use the Semantic Web”
“it is just an ugly application of XML”
“one has to learn formal logic, knowledge representation techniques, description logic, etc,
to use it”
“it is, essentially, an academic project, of no interest for industry”
…
Some simple messages should come to the fore!
RDF ≠ RDF/XML!
RDF is a model, and RDF/XML is only one possible serialization thereof
lots of people prefer, for example, Turtle
a good percentage of the tools have Turtle parsers, too!
The model is, after all, simple: interchange format for Web resources.
That is it !
RDF ≠ RDF/XML! (cont.)
RDF/XML is indeed a very complex serialization format
Certainly not the nicest possible XML application
good to know that it was created when XML was not yet final…
Again: it is only syntactic sugar!
One has to emphasize: RDF is not an XML application!
RDF is not that complex…
Of course, the formal semantics of RDF is complex
But the average user should not care, it is all “under the hood”
how many users of SQL have ever read its formal semantics?
it is not much simpler than RDF…
People should “think” in terms of graphs, the rest is syntactic sugar!
Semantic Web ≠ Ontologies on the Web!
Formal ontologies (like OWL) are important, but use them only when necessary
you can be a perfectly decent citizen of the Semantic Web if you do not use Ontologies, not even RDFS…
remember the “light ontologies” issue?
SW Ontologies ≠ some central, big ontology!
The “ethos” of the Semantic Web is on sharing, ie, sharing ontologies (small or large)
A huge, central ontology would be unmanageable
OWL includes statements for versioning, for equivalence and disjointness of terms
a revision of those may be necessary, but the goal is clear
The practice:
SW applications using ontologies always mix large number of ontologies and vocabularies (FOAF, DC, and others)
the real advantage comes from this mix: that is also how new relationships may be discovered
Remember?
Semantic Web ≠ an academic research only!
SW has indeed a strong foundation in research results
But remember:
(1) the Web was born at CERN…
(2) …was first picked up by high energy physicists…
(3) …then by academia at large…
(4) …then by small businesses and start-ups…
(5) “big business” came only later!
network effect kicked in early…
Semantic Web is now at #4, and moving to #5!
May start with small communities
The needs of a deployment application area:
have serious problem or opportunity
have the intellectual interest to pick up new things
have motivation to fix the problem
its data connects to other application areas
have an influence as a showcase for others
The high energy physics community played this role for the Web in the 90’s
Some RDF deployment areas
Library metadata
Defense
Life sciences
Problem to solve?
single-domain integration
yes, serious data integration needs
yes, connections among genetics, proteomics, clinical trials,
regulatory,…
Willingness to adopt?
yes: OCLC push and Dublin Core initiative
yes: funded early DAML (OWL) work
yes: intellectual level high, much modeling done already.
Motivation
light
strong
very strong
Links to
other library data
phone calls records, etc
chemistry, regulatory, medical, etc
Some RDF deployment areas (cont)
These are just examples
Others are coming to the fore: eGovernment, energy sector (oil industry), financial services,…
Health care and life science sector is now very active
also at W3C, in the form of an Interest Group
The “corporate” landscape is moving
Major companies offer (or will offer) Semantic Web tools or systems using Semantic
Web: Adobe, Oracle, IBM, HP, Software AG, webMethods, Northrop Gruman, Altova,…
Some of the names of active participants in W3C SW related groups: ILOG, HP, Agfa, SRI International, Fair Isaac Corp., Oracle, Boeing, IBM, Chevron, Siemens, Nokia, Merck, Pfizer, AstraZeneca, Sun, Citigroup,…
“Corporate Semantic Web” listed as major technology by
Gartner in 2006
speakers in 2006: from IBM, Cisco, BellSouth, GE, Walt Disney, Nokia, Oracle, …
not all referring to Semantic Web (eg, RDF, OWL,…) but semantics in general
but they might come around!
Applications are not always very complex…
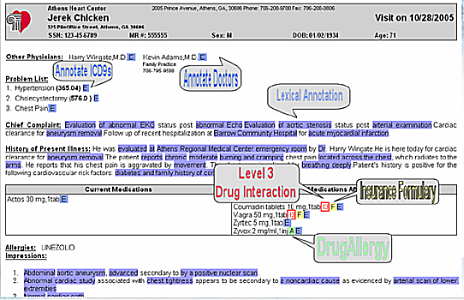
Eg: simple semantic annotations of patients’ data greatly enhances communications among doctors
What is needed: some simple ontologies, an RDFa/microformat type editing environment
Simple but powerful!
Data integration
Data integration comes to the fore as one of the SW Application areas
Very important for large application areas (life sciences, energy sector, eGovernment, financial institutions),
as well as everyday applications (eg, reconciliation of calendar data)
Life sciences example:
data in different labs…
data aimed at scientists, managers, clinical trial participants…
large scale public ontologies (genes, proteins, antibodies, …)
different formats (databases, spreadsheets, XML data, XHTML pages)
etc
Life Sciences (cont.)
General approach
Map the various data onto RDF
assign URI-s to your data
“mapping” may mean on-the-fly SPARQL to SQL conversion, “scraping”, etc
Merge the resulting RDF graphs (with a possible help of ontologies, rules, etc, to combine the terms)
Start making queries on the whole!
Remember the role of SPARQL?
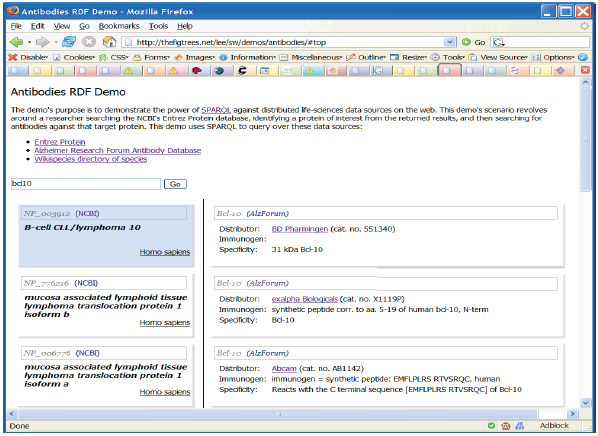
Example: antibodies demo
Scenario: find the known antibodies for a protein in a specific species
 !)
!) :
it is the usual picture of software tools, nothing special any more!
:
it is the usual picture of software tools, nothing special any more!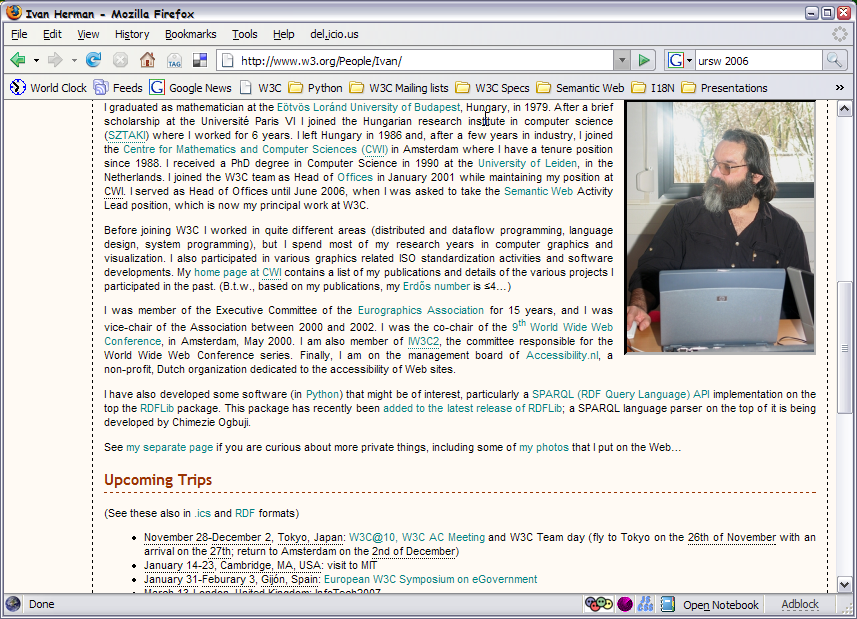


{kind=link}