The Resource Description Framework (RDF) is a language for representing information about resources in the World Wide Web. This Primer is designed to provide the reader with the basic knowledge required to effectively use RDF. It describes how to define RDF vocabularies using the RDF Vocabulary Description Language. It introduces the basic concepts of RDF and describes its Turtle serialization syntax.
1. Introduction
The Resource Description Framework (RDF) is a language for representing
information about resources in the World Wide Web. It is particularly
intended for representing metadata about Web resources, such as the title,
author, and modification date of a Web page, copyright and licensing
information about a Web document, or the availability schedule for some
shared resource. However, by generalizing the concept of a "Web resource",
RDF can also be used to represent information about things that can be
identified on the Web, even when they cannot be directly
retrieved on the Web. Examples include information about items
available from on-line shopping facilities (e.g., information about
specifications, prices, and availability), or the description of a Web user's
preferences for information delivery.
RDF is intended for situations in which this information needs to be
processed by applications, rather than being only displayed to people. RDF
provides a common framework for expressing this information so it can be
exchanged between applications without loss of meaning. Since it is a common
framework, application designers can leverage the availability of common RDF
parsers and processing tools. The ability to exchange information between
different applications means that the information may be made available to
applications other than those for which it was originally created.
RDF is based on the idea of identifying things using Web identifiers
(called Uniform Resource Identifiers, or URIs), and
describing resources in terms of simple properties and property values. This
enables RDF to represent simple statements about resources as a
graph of nodes and arcs representing the resources, and their
properties and values. To make this discussion somewhat more concrete as soon
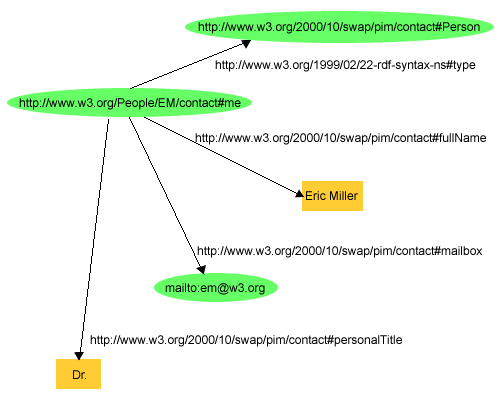
as possible, the group of statements "there is a Person identified by
http://www.w3.org/People/EM/contact#me , whose name
is Eric Miller, whose email address is em@w3.org, and whose title is Dr."
could be represented as the RDF graph in Figure 1:
Figure 1 illustrates that RDF uses URIs to
identify:
- individuals, e.g., Eric Miller, identified by
http://www.w3.org/People/EM/contact#me
- kinds of things, e.g., Person, identified by
http://www.w3.org/2000/10/swap/pim/contact#Person
- properties of those things, e.g., mailbox, identified by
http://www.w3.org/2000/10/swap/pim/contact#mailbox
- values of those properties, e.g.
mailto:em@w3.org as the
value of the mailbox property (RDF also uses character strings such as
"Eric Miller", and values from other datatypes such as integers and
dates, as the values of properties)
RDF also provides a text-based syntax (called
Turtle) for recording and exchanging these graphs. Example 1 is a small chunk of RDF in Turtle syntax corresponding to the graph in Figure 1:
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>.
@prefix contact: <http://www.w3.org/2000/10/swap/pim/contact#>.
<http://www.w3.org/People/EM/contact#me>
rdf:type contact:Person;
contact:fullName "Eric Miller";
contact:mailbox <mailto:em@w3.org>;
contact:personalTitle "Dr.".
Note that this example also contains URIs, as
well as properties like mailbox and fullName (in an
abbreviated form), and their respective values em@w3.org, and
Eric Miller.
Like HTML, this Turtle syntax is machine
processable and, using URIs, can link pieces of information across the Web.
However, unlike conventional hypertext, RDF URIs can refer to any
identifiable thing, including things that may not be directly retrievable on
the Web (such as the person Eric Miller). The result is that in addition to
describing such things as Web pages, RDF can also describe cars, businesses,
people, news events, etc. In addition, RDF properties themselves have URIs,
to precisely identify the relationships that exist between the linked items.
The following documents contribute to the specification of RDF:
This Primer is intended to provide an introduction to RDF and describe
some existing RDF applications, to help information system designers and
application developers understand the features of RDF and how to use them. In
particular, the Primer is intended to answer such questions as:
- What does RDF look like?
- What information can RDF represent?
- How is RDF information created, accessed, and processed?
- How can existing information be combined with RDF?
This Primer is a non-normative document, which means that it does
not provide a definitive specification of RDF. The examples and other
explanatory material in the Primer are provided to help readers understand
RDF, but they may not always provide definitive or fully-complete answers. In
such cases, the relevant normative parts of the RDF specification should be
consulted. To help in doing this, the Primer describes the roles these other
documents play in the complete specification of RDF, and provides links
pointing to the relevant parts of the normative specifications, at
appropriate places in the discussion.
This Primer follows as closely as possible the RDF/XML Version of the Primer [RDF-PRIMER]. RDF/XML provides a serialization
based on XML, whereas the Turtle syntax used in this document is different.
Both serializations are equivalent in the sense that they can express the
same RDF information, and the choice among the two is solely based
on personal taste, availability of parser, etc. Tools also exist that convert
the two serialization format to one another without any loss of
expressivity.
2. Making Statements
About Resources
RDF is intended to provide a simple way to make statements about Web
resources, e.g., Web pages. This section describes the basic ideas behind the
way RDF provides these capabilities (the normative specification describing
these concepts is RDF Concepts
and Abstract Syntax [RDF-CONCEPTS]).
2.1 Basic
Concepts
Imagine trying to state that someone named John Smith created a particular
Web page. A straightforward way to state this in a natural language such as
English would be in the form of a simple statement such as:
http://www.example.org/index.html
has a creator whose value is John Smith
Parts of this statement are emphasized to illustrate that, in order to
describe the properties of something, there need to be ways to name, or
identify, a number of things:
- the thing the statement describes (the Web page, in this case)
- a specific property (creator, in this case) of the thing the statement
describes
- the thing the statement says is the value of this property (who the
creator is), for the thing the statement describes
In this statement, the Web page's URL (Uniform Resource Locator) is used
to identify it. In addition, the word "creator" is used to identify the
property, and the two words "John Smith" to identify the thing (a person)
that is the value of this property.
Other properties of this Web page could be described by writing additional
English statements of the same general form, using the URL to identify the
page, and words (or other expressions) to identify the properties and their
values. For example, the date the page was created, and the language in which
the page is written, could be described using the additional statements:
http://www.example.org/index.html
has a creation-date whose value is August 16,
1999
http://www.example.org/index.html has a
language whose value is English
RDF is based on the idea that the things being described have properties which
have values, and that resources can be described by making statements,
similar to those above, that specify those properties and values. RDF uses a
particular terminology for talking about the various parts of statements.
Specifically, the part that identifies the thing the statement is about (the
Web page in this example) is called the subject. The part
that identifies the property or characteristic of the subject that the
statement specifies (creator, creation-date, or language in these examples)
is called the predicate, and
the part that identifies the value of that property is called the object. So, taking
the English statement
http://www.example.org/index.html
has a creator whose value is John Smith
the RDF terms for the various parts of the statement are:
- the subject is the URL
http://www.example.org/index.html
- the predicate is the word "creator"
- the object is the phrase "John Smith"
However, while English is good for communicating between
(English-speaking) humans, RDF is about making machine-processable
statements. To make these kinds of statements suitable for processing by
machines, two things are needed:
- a system of machine-processable identifiers for identifying a subject,
predicate, or object in a statement without any possibility of confusion
with a similar-looking identifier that might be used by someone else on
the Web.
- a machine-processable language for representing these statements and
exchanging them between machines.
Fortunately, the existing Web architecture provides both these necessary
facilities.
As illustrated earlier, the Web already provides one form of identifier,
the Uniform Resource Locator (URL). A URL was used in the original
example to identify the Web page that John Smith created. A URL is a
character string that identifies a Web resource by representing its primary
access mechanism (essentially, its network "location"). However, it is also
important to be able to record information about many things that, unlike Web
pages, do not have network locations or URLs.
The Web provides a more general form of identifier for these purposes,
called the Uniform Resource
Identifier (URI). URLs are a particular kind of URI. All URIs share the
property that different persons or organizations can independently create
them, and use them to identify things. However, URIs are not limited to
identifying things that have network locations, or use other computer access
mechanisms. In fact, a URI can be created to refer to anything that needs to
be referred to in a statement, including
- network-accessible things, such as an electronic document, an image, a
service (e.g., "today's weather report for Los Angeles"), or a group of
other resources.
- things that are not network-accessible, such as human beings,
corporations, and bound books in a library.
- abstract concepts that do not physically exist, such as the concept of
a "creator".
Because of this generality, RDF uses URIs as the basis of its mechanism
for identifying the subjects, predicates, and objects in statements. To be
more precise, RDF uses URI
references [URIS]. A URI reference (or
URIref) is a URI, together with an optional fragment
identifier at the end. For example, the URI reference
http://www.example.org/index.html#section2 consists of the URI
http://www.example.org/index.html and (separated by the "#"
character) the fragment identifier Section2. RDF URIrefs can
contain Unicode [UNICODE] characters (see [RDF-CONCEPTS]), allowing many languages to be
reflected in URIrefs. RDF defines a resource as anything that is
identifiable by a URI reference, so using URIrefs allows RDF to describe
practically anything, and to state relationships between such things as well.
URIrefs and fragment identifiers are discussed further in Appendix A, and in [RDF-CONCEPTS].
To represent RDF statements in a machine-processable way,
RDF normatively uses the Extensible Markup
Language [XML], but other syntaxes are also
possible. The XML serialization syntax (referrred to as RDF/XML) is
described in a separate
document [RDF-SYNTAX]. This document uses the Turtle syntax [TURTLE]. An
example of Turtle was given in Section 1. Turtle content
can contain Unicode [UNICODE] characters, allowing
information from many languages to be directly represented. The specific
Turtle syntax is defined in [TURTLE]
2.2 The RDF Model
Section 2.1 has introduced RDF's basic
statement concepts, the idea of using URI references to identify the things
referred to in RDF statements, and Turtle as a
machine-processable way to represent RDF statements. With that background,
this section describes how RDF uses URIs to make statements about resources.
The introduction said that RDF was based on the idea of expressing simple
statements about resources, where each statement consists of a subject, a
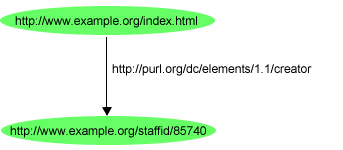
predicate, and an object. In RDF, the English statement:
http://www.example.org/index.html
has a creator whose value is John Smith
could be represented by an RDF statement having:
- a subject
http://www.example.org/index.html
- a predicate
http://purl.org/dc/elements/1.1/creator
- and an object
http://www.example.org/staffid/85740
Note how URIrefs are used to identify not only the subject of the original
statement, but also the predicate and object, instead of using the words
"creator" and "John Smith", respectively (some of the effects of using
URIrefs in this way will be discussed later in this section).
RDF models statements as nodes and arcs in a graph. RDF's graph model
is defined in [RDF-CONCEPTS]. In this
notation, a statement is represented by:
- a node for the subject
- a node for the object
- an arc for the predicate, directed from the subject node to the object
node.
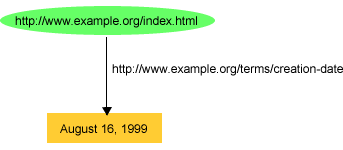
So the RDF statement above would be represented by the graph shown in Figure 2:
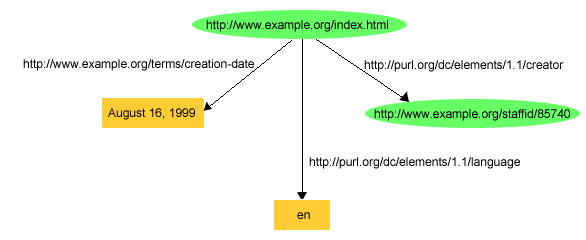
Groups of statements are represented by corresponding groups of nodes and
arcs. So, to reflect the additional English statements
http://www.example.org/index.html
has a creation-date whose value is August 16,
1999
http://www.example.org/index.html has a
language whose value is English
in the RDF graph, the graph shown in Figure 3 could
be used (using suitable URIrefs to name the properties "creation-date" and
"language"):
Figure 3 illustrates that objects in RDF statements
may be either URIrefs, or constant values (called literals)
represented by character strings, in order to represent certain kinds of
property values. (In the case of the predicate
http://purl.org/dc/elements/1.1/language the literal is an
international standard two-letter code for English.) Literals may not be used
as subjects or predicates in RDF statements. In drawing RDF graphs, nodes
that are URIrefs are shown as ellipses, while nodes that are literals are
shown as boxes. (The simple character string literals used in these examples
are called plain
literals, to distinguish them from the typed
literals to be introduced in Section 2.4.
The various kinds of literals that can be used in RDF statements are defined
in [RDF-CONCEPTS]. Both plain and typed
literals can contain Unicode [UNICODE] characters,
allowing information from many languages to be directly represented.)
Sometimes it is not convenient to draw graphs when discussing them, so an
alternative way of writing down the statements, called triples, is also
used. In the triples notation, each statement in the graph is written as a
simple triple of subject, predicate, and object, in that order. For example,
the three statements shown in Figure 3 would be
written in the triples notation as:
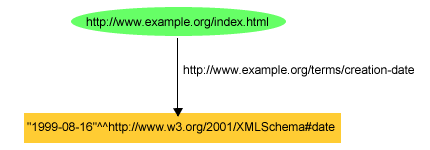
<http://www.example.org/index.html> <http://purl.org/dc/elements/1.1/creator> <http://www.example.org/staffid/85740> .
<http://www.example.org/index.html> <http://www.example.org/terms/creation-date> "August 16, 1999" .
<http://www.example.org/index.html> <http://purl.org/dc/elements/1.1/language> "en" .
Each triple corresponds to a single arc in the graph, complete with the
arc's beginning and ending nodes (the subject and object of the statement).
Unlike the drawn graph (but like the original statements), the triples
notation requires that a node be separately identified for each statement it
appears in. So, for example, http://www.example.org/index.html
appears three times (once in each triple) in the triples representation of
the graph, but only once in the drawn graph. However, the triples represent
exactly the same information as the drawn graph, and this is a key point:
what is fundamental to RDF is the graph model of the statements. The
notation used to represent or depict the graph is secondary.
The full triples notation requires that URI references be written out
completely, in angle brackets, which, as the example above illustrates, can
result in very long lines on a page. For convenience, the Primer uses a
shorthand way of writing triples (the same shorthand is also used in other
RDF specifications). This shorthand substitutes a
qualified name (or QName) without angle brackets as an
abbreviation for a full URI reference . A QName contains a prefix
that has been assigned to a namespace URI, followed by a colon, and then a
local name. The full URIref is formed from the QName by appending
the local name to the namespace URI assigned to the prefix. So, for example,
if the QName prefix foo is assigned to the namespace URI
http://example.org/somewhere/, then the QName
foo:bar is shorthand for the URIref
http://example.org/somewhere/bar. Primer examples will also use
several "well-known" QName prefixes (without explicitly specifying them each
time), defined as follows:
prefix rdf:, namespace URI:
http://www.w3.org/1999/02/22-rdf-syntax-ns#
prefix rdfs:, namespace URI:
http://www.w3.org/2000/01/rdf-schema#
prefix dc:, namespace URI:
http://purl.org/dc/elements/1.1/
prefix owl:, namespace URI:
http://www.w3.org/2002/07/owl#
prefix ex:, namespace URI: http://www.example.org/
(or http://www.example.com/)
prefix xsd:, namespace URI:
http://www.w3.org/2001/XMLSchema#
Obvious variations on the "example" prefix ex: will also be
used as needed in the examples, for instance,
prefix exterms:, namespace URI:
http://www.example.org/terms/ (for terms used by an example
organization),
prefix exstaff:, namespace URI:
http://www.example.org/staffid/ (for the example organization's
staff identifiers),
prefix ex2:, namespace URI:
http://www.domain2.example.org/ (for a second example
organization), and so on.
Using this new shorthand, the previous set of triples can be written as:
ex:index.html dc:creator exstaff:85740 .
ex:index.html exterms:creation-date "August 16, 1999" .
ex:index.html dc:language "en" .
Since RDF uses URIrefs instead of
words to name things in statements, RDF refers to a set of URIrefs
(particularly a set intended for a specific purpose) as a
vocabulary. Often, the URIrefs in such vocabularies are organized so
that they can be represented as a set of QNames using a common prefix. That
is, a common namespace URIref will be chosen for all terms in a vocabulary,
typically a URIref under the control of whoever is defining the vocabulary.
URIrefs that are contained in the vocabulary are formed by appending
individual local names to the end of the common URIref. This forms a set of
URIrefs with a common prefix. For instance, as illustrated by the previous
examples, an organization such as example.org might define a vocabulary
consisting of URIrefs starting with the prefix
http://www.example.org/terms/ for terms it uses in its business,
such as "creation-date" or "product", and another vocabulary of URIrefs
starting with http://www.example.org/staffid/ to identify its
employees. RDF uses this same approach to define its own vocabulary of terms
with special meanings in RDF. The URIrefs in this RDF vocabulary all begin
with http://www.w3.org/1999/02/22-rdf-syntax-ns#, conventionally
associated with the QName prefix rdf:. The RDF Vocabulary
Description Language (described in Section 5)
defines an additional set of terms having URIrefs that begin with
http://www.w3.org/2000/01/rdf-schema#, conventionally associated
with the QName prefix rdfs:. (Where a specific QName prefix is
commonly used in connection with a given set of terms in this way, the QName
prefix itself is sometimes used as the name of the vocabulary. For example,
someone might refer to "the rdfs: vocabulary".)
Using common URI prefixes provides a convenient way to organize the
URIrefs for a related set of terms. However, this is just a convention. The
RDF model only recognizes full URIrefs; it does not "look inside" URIrefs or
use any knowledge about their structure. In particular, RDF does not assume
there is any relationship between URIrefs just because they have a common
leading prefix (see Appendix A for further
discussion). Moreover, there is nothing that says that URIrefs with different
leading prefixes cannot be considered part of the same vocabulary. A
particular organization, process, tool, etc. can define a vocabulary that is
significant for it, using URIrefs from any number of other vocabularies as
part of its vocabulary.
In addition, sometimes an organization will use a vocabulary's namespace
URIref as the URL of a Web resource that provides further information about
that vocabulary. For example, as noted earlier, the QName prefix
dc: will be used in Primer examples, associated with the
namespace URIref http://purl.org/dc/elements/1.1/. In fact, this
refers to the Dublin Core vocabulary described in Section 6.1. Accessing this namespace URIref in a Web
browser will retrieve additional information about the Dublin Core vocabulary
(specifically, an RDF schema).
In the rest of the Primer, the term vocabulary will be used when
referring to a set of URIrefs defined for some specific purpose, such as the
set of URIrefs defined by RDF for its own use, or the set of URIrefs defined
by example.org to identify its employees.
URIrefs from different vocabularies can be freely mixed in RDF graphs. For
example, the graph in Figure 3 uses URIrefs from the
exterms:, exstaff:, and dc:
vocabularies. Also, RDF imposes no restrictions on how many statements using a given URIref as predicate can
appear in a graph to describe the same resource. For example, if the resource
ex:index.html had been created by the cooperative efforts of
several staff members in addition to John Smith, example.org might have
written the statements:
ex:index.html dc:creator exstaff:85740 .
ex:index.html dc:creator exstaff:27354 .
ex:index.html dc:creator exstaff:00816 .
These examples of RDF statements begin to illustrate some of the
advantages of using URIrefs as RDF's basic way of identifying things. For
instance, in the first statement, instead of identifying the creator of the
Web page by the character string "John Smith", he has been assigned a URIref,
in this case (using a URIref based on his employee number)
http://www.example.org/staffid/85740 . An advantage of using a
URIref in this case is that the identification of the statement's subject can
be more precise. That is, the creator of the page is not the character string
"John Smith", or any one of the thousands of people named John Smith, but the
particular John Smith associated with that URIref (whoever created the URIref
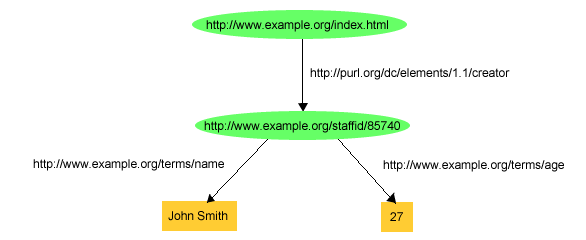
defines the association). Moreover, since there is a URIref to refer to John
Smith, he is a full-fledged resource, and additional information can be
recorded about him, simply by adding additional RDF statements with John's
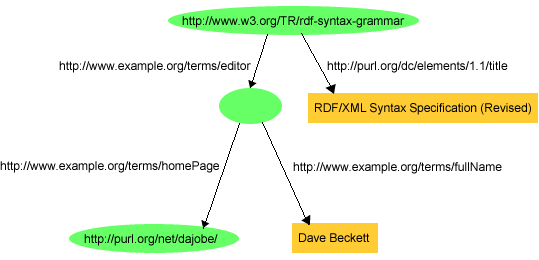
URIref as the subject. For example, Figure 4 shows
some additional statements giving John's name and age.
These examples also illustrate that RDF uses URIrefs as
predicates in RDF statements. That is, rather than using character
strings (or words) such as "creator" or "name" to identify properties, RDF
uses URIrefs. Using URIrefs to identify properties is important for a number
of reasons. First, it distinguishes the properties one person may use from
different properties someone else may use that would otherwise be identified
by the same character string. For instance, in the example in Figure 4, example.org uses "name" to mean someone's full
name written out as a character string literal (e.g., "John Smith"), but
someone else may intend "name" to mean something different (e.g., the name of
a variable in a piece of program text). A program encountering "name" as a
property identifier on the Web (or merging data from multiple sources) would
not necessarily be able to distinguish these uses. However, if example.org
writes http://www.example.org/terms/name for its "name"
property, and the other person writes
http://www.domain2.example.org/genealogy/terms/name for hers, it
is clear that there are distinct properties involved (even if a program
cannot automatically determine the distinct meanings). Also, using URIrefs to
identify properties enables the properties to be treated as resources
themselves. Since properties are resources, additional information can be
recorded about them (e.g., the English description of what example.org means
by "name"), simply by adding additional RDF statements with the property's
URIref as the subject.
Using URIrefs as subjects, predicates, and objects in RDF statements
supports the development and use of shared vocabularies on the Web, since
people can discover and begin using vocabularies already used by others to
describe things, reflecting a shared understanding of those concepts. For
example, in the triple
ex:index.html dc:creator exstaff:85740 .
the predicate dc:creator, when fully expanded as a URIref, is
an unambiguous reference to the "creator" attribute in the Dublin Core
metadata attribute set (discussed further in Section
6.1), a widely-used set of attributes (properties) for describing
information of all kinds. The writer of this triple is effectively saying
that the relationship between the Web page (identified by
http://www.example.org/index.html ) and the creator of the page
(a distinct person, identified by
http://www.example.org/staffid/85740 ) is exactly the concept
identified by http://purl.org/dc/elements/1.1/creator. Another person familiar
with the Dublin Core vocabulary, or who finds out what
dc:creator means (say by looking up its definition on the Web)
will know what is meant by this relationship. In addition, based on this
understanding, people can write programs to behave in accordance with that
meaning when processing triples containing the predicate
dc:creator.
Of course, this
depends on increasing the general use of URIrefs to refer to things instead
of using literals; e.g., using URIrefs like exstaff:85740 and
dc:creator instead of character string literals like John
Smith and creator. Even then, RDF's use of URIrefs
does not solve all identification problems because, for example, people can
still use different URIrefs to refer to the same thing. For this reason, it
is a good idea to try to use terms from existing vocabularies (such as the
Dublin Core) where possible, rather than making up new terms that might
overlap with those of some other vocabulary. Appropriate vocabularies for use
in specific application areas are being developed all the time, as
illustrated by the applications described in Section
6. However, even when synonyms are created, the fact that these different
URIrefs are used in the commonly-accessible "Web space" provides the
opportunity both to identify equivalences among these different references,
and to migrate toward the use of common references.
In addition, it is important to distinguish between any meaning that
RDF itself associates with terms (such as dc:creator in
the previous example) used in RDF statements and additional,
externally-defined meaning that people (or programs written by those
people) might associate with those terms. As a language, RDF directly defines
only the graph syntax of subject, predicate, and object triples, certain
meanings associated with URIrefs in the rdf: vocabulary, and
certain other concepts to be described later. These things are normatively
defined in [RDF-CONCEPTS] and [RDF-SEMANTICS]. However, RDF does not define
the meanings of terms from other vocabularies, such as
dc:creator, that might be used in RDF statements. Specific
vocabularies will be created, with specific meanings assigned to the URIrefs
defined in them, externally to RDF. RDF statements using URIrefs from these
vocabularies may convey the specific meanings associated with those terms to
people familiar with these vocabularies, or to RDF applications written to
process these vocabularies, without conveying any of these meanings to an
arbitrary RDF application not specifically written to process these
vocabularies.
For example, people can associate meaning with a triple such as
ex:index.html dc:creator exstaff:85740 .
based on the meaning they associate with the appearance of the word
"creator" as part of the URIref dc:creator, or based on their
understanding of the specific definition of dc:creator in the
Dublin Core vocabulary. However, as far as an arbitrary RDF application is
concerned the triple might as well be something like
fy:joefy.iunm ed:dsfbups fytubgg:85740 .
as far as any built-in meaning is concerned. Similarly, any natural
language text describing the meaning of dc:creator that might be
found on the Web provides no additional meaning that an arbitrary RDF
application can directly use.
Of course, URIrefs from a particular vocabulary can be used in RDF
statements even though a given application may not be able to associate any
special meanings with them. For example, generic RDF software would recognize
that the above expression is an RDF statement, that ed:dsfbups
is the predicate, and so on. It will simply not associate with the triple any
special meaning that the vocabulary developer might have associated with a
URIref like ed:dsfbups. Moreover, based on their understanding
of a given vocabulary, people can write RDF applications to behave in
accordance with the special meanings assigned to URIrefs from that
vocabulary, even though that meaning will not be accessible to RDF
applications not written in that way.
The result of all this is that RDF provides a way to make statements that
applications can more easily process. An application cannot actually
"understand" such statements, as noted already, any
more than a database system "understands" terms like "employee" or "salary"
in processing a query like SELECT NAME FROM EMPLOYEE WHERE SALARY >
35000. However, if an application is appropriately written, it
can deal with RDF statements in a way that makes it seem like it does
understand them, just as a database system and its
applications can do useful work in processing employee and payroll
information without understanding "employee" and "payroll". For
example, a user could search the Web for all book reviews and create an
average rating for each book. Then, the user could put that information back
on the Web. Another Web site could take that list of book rating averages and
create a "Top Ten Highest Rated Books" page. Here, the availability and use
of a shared vocabulary about ratings, and a shared group of URIrefs
identifying the books they apply to, allows individuals to build a
mutually-understood and increasingly-powerful (as additional contributions
are made) "information base" about books on the Web. The same principle
applies to the vast amounts of information that people create about thousands
of subjects every day on the Web.
RDF statements are similar to a number of other formats for recording
information, such as:
- entries in a simple record or catalog listing describing the resource
in a data processing system.
- rows in a simple relational database.
- simple assertions in formal logic
and information in these formats can be treated as RDF statements,
allowing RDF to be used to integrate data from many sources.
2.3 Structured Property Values and Blank
Nodes
Things would be very simple if the only types of information to be
recorded about things were obviously in the form of the simple RDF statements
illustrated so far. However, most real-world data involves structures that
are more complicated than that, at least on the surface. For instance, in the
original example, the date the Web page was created is recorded as a single
exterms:creation-date property, with a plain literal as its
value. However, suppose the value of the exterms:creation-date
property needed to record the month, day, and year as separate pieces of
information? Or, in the case of John Smith's personal information, suppose
John's address was being described. The whole address could be written out as
a plain literal, as in the triple
exstaff:85740 exterms:address "1501 Grant Avenue, Bedford, Massachusetts 01730" .
However, suppose John's address needed to be recorded as a
structure consisting of separate street, city, state, and postal
code values? How would this be done in RDF?
Structured information like this is represented in RDF by considering the
aggregate thing to be described (like John Smith's address) as a resource,
and then making statements about that new resource. So, in the RDF graph, in
order to break up John Smith's address into its component parts, a new node
is created to represent the concept of John Smith's address, with a new
URIref to identify it, say
http://www.example.org/addressid/85740 (abbreviated as
exaddressid:85740). RDF statements (additional arcs and nodes)
can then be written with that node as the subject, to represent the
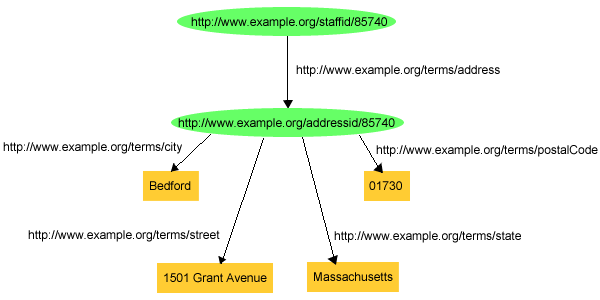
additional information, producing the graph shown in Figure 5:
or the triples:
exstaff:85740 exterms:address exaddressid:85740 .
exaddressid:85740 exterms:street "1501 Grant Avenue" .
exaddressid:85740 exterms:city "Bedford" .
exaddressid:85740 exterms:state "Massachusetts" .
exaddressid:85740 exterms:postalCode "01730" .
This way of representing structured information in RDF can involve
generating numerous "intermediate" URIrefs such as
exaddressid:85740 to represent aggregate concepts such as John's
address. Such concepts may never need to be referred to directly from outside
a particular graph, and hence may not require "universal" identifiers. In
addition, in the drawing of the graph representing the group of
statements shown in Figure 5, the URIref assigned to
identify "John Smith's address" is not really needed, since the graph could
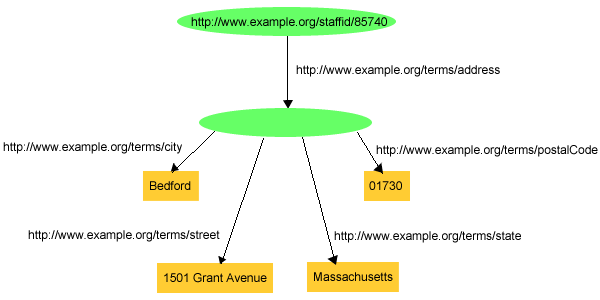
just as easily have been drawn as in Figure 6:
Figure 6, which is a perfectly good RDF graph, uses
a node without a URIref to stand for the concept of "John Smith's address".
This blank
node serves its purpose in the drawing without needing a URIref, since
the node itself provides the necessary connectivity between the various other
parts of the graph. (Blank nodes were called anonymous resources in
[RDF-MS].) However, some form of explicit identifier
for that node is needed in order to represent this graph as triples. To see
this, trying to write the triples corresponding to what is shown in Figure 6 would produce something like:
exstaff:85740 exterms:address ??? .
??? exterms:street "1501 Grant Avenue" .
??? exterms:city "Bedford" .
??? exterms:state "Massachusetts" .
??? exterms:postalCode "01730" .
where ??? stands for something that indicates the presence of the blank
node. Since a complex graph might contain more than one blank node, there
also needs to be a way to differentiate between these different blank nodes
in a triples representation of the graph. As a result, triples use blank node
identifiers, having the form _:name, to indicate the
presence of blank nodes. For instance, in this example a blank node
identifier _:johnaddress might be used to refer to the blank
node, in which case the resulting triples might be:
exstaff:85740 exterms:address _:johnaddress .
_:johnaddress exterms:street "1501 Grant Avenue" .
_:johnaddress exterms:city "Bedford" .
_:johnaddress exterms:state "Massachusetts" .
_:johnaddress exterms:postalCode "01730" .
In a triples representation of a graph, each distinct blank node in the
graph is given a different blank node identifier. Unlike URIrefs and
literals, blank node identifiers are not considered to be actual parts of the
RDF graph (this can be seen by looking at the drawn graph in Figure 6 and noting that the blank node has no blank node
identifier). Blank node identifiers are just a way of representing the blank
nodes in a graph (and distinguishing one blank node from another) when the
graph is written in triple form. Blank node identifiers also have
significance only within the triples representing a single graph
(two different graphs with the same number of blank nodes might independently
use the same blank node identifiers to distinguish them, and it would be
incorrect to assume that blank nodes from different graphs having the same
blank node identifiers are the same). If it is expected that a node in a
graph will need to be referenced from outside the graph, a URIref should be
assigned to identify it. Finally, because blank node identifiers represent
(blank) nodes, rather than arcs, in the triple form of an RDF graph,
blank node identifiers may only appear as subjects or objects in triples;
blank node identifiers may not be used as predicates in triples.
The beginning of this section noted that aggregate structures, like John
Smith's address, can be represented by considering the aggregate thing to be
described as a separate resource, and then making statements about that new
resource. This example illustrates an important aspect of RDF: RDF directly
represents only binary relationships, e.g. the relationship between
John Smith and the literal representing his address. Representing the
relationship between John and the group of separate components of
this address involves dealing with an n-ary (n-way) relationship (in
this case, n=5) between John and the street, city, state, and postal code
components. In order to represent such structures directly in RDF (e.g.,
considering the address as a group of street, city, state, and postal code
components), this n-way relationship must be broken up into a group of
separate binary relationships. Blank nodes provide one way to do this. For
each n-ary relationship, one of the participants is chosen as the subject of
the relationship (John in this case), and a blank node is created to
represent the rest of the relationship (John's address in this case). The
remaining participants in the relationship (such as the city in this example)
are then represented as separate properties of the new resource represented
by the blank node.
Blank nodes also provide a way to more accurately make statements about
resources that may not have URIs, but that are described in terms of
relationships with other resources that do have URIs. For example,
when making statements about a person, say Jane Smith, it may seem natural to
use a URI based on that person's email address as her URI, e.g.,
mailto:jane@example.org. However, this approach can cause
problems. For example, it may be necessary to record information both about
Jane's mailbox (e.g., the server it is on) as well as about Jane
herself (e.g., her current physical address), and using a URIref for
Jane based on her email address makes it difficult to know whether it is Jane
or her mailbox that is being described. The same problem exists when a
company's Web page URL, say http://www.example.com/, is used as
the URI of the company itself. Once again, it may be necessary to record
information about the Web page itself (e.g., who created it and when) as well
as about the company, and using http://www.example.com/ as an
identifier for both makes it difficult to know which of these is the actual
subject.
The fundamental problem is that using Jane's mailbox as a
stand-in for Jane is not really accurate: Jane and her mailbox are
not the same thing, and hence they should be identified differently. When
Jane herself does not have a URI, a blank node provides a more accurate way
of modeling this situation. Jane can be represented by a blank node, and that
blank node used as the subject of a statement with
exterms:mailbox as the property and the URIref
mailto:jane@example.org as its value. The blank node could also
be described with an rdf:type property having a value of
exterms:Person (types are discussed in more detail in the
following sections), an exterms:name property having a value of
"Jane Smith", and any other descriptive information that might
be useful, as shown in the following triples:
_:jane exterms:mailbox <mailto:jane@example.org> .
_:jane rdf:type exterms:Person .
_:jane exterms:name "Jane Smith" .
_:jane exterms:empID "23748" .
_:jane exterms:age "26" .
(Note that mailto:jane@example.org is written within angle
brackets in the first triple. This is because
mailto:jane@example.org is a full URIref in the
mailto URI scheme, rather than a QName abbreviation, and full
URIrefs must be enclosed in angle brackets in the triples notation.)
This says, accurately, that "there is a resource of type
exterms:Person, whose electronic mailbox is identified by
mailto:jane@example.org, whose name is Jane Smith,
etc." That is, the blank node can be read as "there is a resource".
Statements with that blank node as subject then provide information about the
characteristics of that resource.
In practice, using blank nodes instead of URIrefs in these cases does not
change the way this kind of information is handled very much. For example, if
it is known that an email address uniquely identifies someone at example.org
(particularly if the address is unlikely to be reused), that fact can still
be used to associate information about that person from multiple sources,
even though the email address is not the person's URI. In this case, if some
RDF is found on the Web that describes a book, and gives the author's contact
information as mailto:jane@example.org, it might be reasonable,
combining this new information with the previous set of triples, to conclude
that the author's name is Jane Smith. The point is that saying something like
"the author of the book is mailto:jane@example.org" is typically
a shorthand for "the author of the book is someone whose mailbox is
mailto:jane@example.org". Using a blank node to represent this
"someone" is just a more accurate way to represent the real world situation.
(Incidentally, some RDF-based schema languages allow specifying that certain
properties are unique identifiers of the resources they describe.
This is discussed further in Section 5.5.)
Using blank nodes in this way can also help avoid the use of literals in
what might be inappropriate situations. For example, in describing Jane's
book, lacking a URIref to identify the author, the publisher might have
written (using the publisher's own ex2terms: vocabulary):
ex2terms:book78354 rdf:type ex2terms:Book .
ex2terms:book78354 ex2terms:author "Jane Smith" .
However, the author of the book is not really the character string "Jane
Smith", but a person whose name is Jane Smith. The same information
might be more accurately given by the publisher using a blank node, as:
ex2terms:book78354 rdf:type ex2terms:Book .
ex2terms:book78354 ex2terms:author _:author78354 .
_:author78354 rdf:type ex2terms:Person .
_:author78354 ex2terms:name "Jane Smith" .
This essentially says "resource ex2terms:book78354 is of type
ex2terms:Book, and its author is a resource of type
ex2terms:Person, whose name is Jane Smith." Of
course, in this particular case the publisher might instead have assigned its
own URIrefs to its authors instead of using blank nodes to identify them, in
order to encourage external references to its authors.
Finally, the example above giving Jane's age as 26 illustrates the fact
that sometimes the value of a property may appear to be simple, but actually
may be more complex. In this case, Jane's age is actually 26 years,
but the units information (years) is not explicitly given. Such information
is often omitted in contexts where it can be safely assumed that anyone
accessing the property value will understand the units being used. However,
in the wider context of the Web, it is generally not safe to make
this assumption. For example, a U.S. site might give a weight value in
pounds, but someone accessing that data from outside the U.S. might assume
that weights are given in kilograms. In general, careful consideration should
be given to explicitly representing units and similar information. This issue
is discussed further in Section 4.4, which describes
an RDF feature for representing such information as structured values, as
well as some other techniques for representing such information.
2.4 Typed
Literals
The last section described how to handle situations in which property
values represented by plain literals had to be broken up into structured
values to represent the individual parts of those literals. Using this
approach, instead of, say, recording the date a Web page was created as a
single exterms:creation-date property, with a single plain
literal as its value, the value would be represented as a structure
consisting of the month, day, and year as separate pieces of information,
using separate plain literals to represent the corresponding values. However,
so far, all constant values that serve as objects in RDF statements have been
represented by these plain (untyped) literals, even when the intent is
probably for the value of the property to be a number (e.g., the value of a
year or age property) or some other kind of more
specialized value.
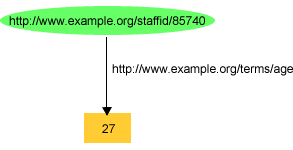
For example, Figure 4 illustrated an RDF graph
recording information about John Smith. That graph recorded the value of John
Smith's exterms:age property as the plain literal "27", as shown
in Figure 7:
In this case, the hypothetical organization example.org probably intends
for "27" to be interpreted as a number, rather than as the string consisting
of the character "2" followed by the character "7" (since the literal represents the value of an "age"
property). However, there is no information in Figure 7's graph that
explicitly indicates that "27" should be interpreted as a number. Similarly,
example.org also probably intends for "27" to be interpreted as a
decimal number, i.e., the value twenty seven, rather than,
say, as an octal number, i.e., the value twenty three.
However, once again there is no information in Figure 7's graph that
explicitly indicates this. Specific applications might be written with the
understanding that they should interpret values of the
exterms:age property as decimal numbers, but this would mean
that proper interpretation of this RDF would depend on information not
explicitly provided in the RDF graph, and hence on information that would not
necessarily be available to other applications that might need to interpret
this RDF.
The common practice in programming languages or database systems is to
provide this additional information about how to interpret a literal by
associating a datatype with the literal, in this case, a datatype
like decimal or integer. An application that
understands the datatype then knows, for example, whether the literal "10" is
intended to represent the number ten, the number two, or
the string consisting of the character "1" followed by the character "0",
depending on whether the specified datatype is integer,
binary, or string. (More specialized datatypes
could also be used to include the units information mentioned at the end of
Section 2.3, e.g., a datatype
integerYears, although the Primer will not elaborate on this
idea.) In RDF, typed
literals are used to provide this kind of information.
An RDF typed literal is formed by pairing a string
with a URIref that identifies a particular datatype. This results in a single
literal node in the RDF graph with the pair as the literal. The value
represented by the typed literal is the value that the specified datatype
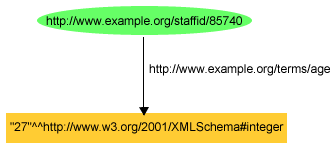
associates with the specified string. For example, using a typed
literal, John Smith's age could be described as being the integer number
27 using the triple:
<http://www.example.org/staffid/85740> <http://www.example.org/terms/age> "27"^^<http://www.w3.org/2001/XMLSchema#integer> .
or, using the QName simplification for writing long URIs:
exstaff:85740 exterms:age "27"^^xsd:integer .
or as shown in Figure 8:
Similarly, in the graph shown in Figure 3
describing information about a Web page, the value of the page's
exterms:creation-date property was written as the plain literal
"August 16, 1999". However, using a typed literal, the creation date of the
Web page could be explicitly described as being the date August 16,
1999, using the triple:
ex:index.html exterms:creation-date "1999-08-16"^^xsd:date .
or as shown in Figure 9:
Unlike typical programming languages and database systems, RDF has no
built-in set of datatypes of its own, such as datatypes for integers, reals,
strings, or dates. Instead, RDF typed literals simply
provide a way to explicitly indicate, for a given literal, what datatype
should be used to interpret it. The datatypes used in typed literals are
defined externally to RDF, and identified by their datatype URIs.
(There is one exception: RDF defines a built-in datatype with the URIref
rdf:XMLLiteral to represent XML content as a literal value. This
datatype is defined in [RDF-CONCEPTS], and
its use is described in Section 4.5.) For
instance, the examples in Figure 8 and Figure 9 use the datatypes integer and
date from the XML Schema datatypes defined in XML Schema Part 2: Datatypes [XML-SCHEMA2]. An advantage of this approach is
that it gives RDF the flexibility to directly represent information coming
from different sources without the need to perform type conversions between
these sources and a native set of RDF datatypes. (Type conversions would
still be required when moving information between systems having different
sets of datatypes, but RDF would impose no extra conversions into and out of
a native set of RDF datatypes.)
RDF datatype concepts are based on a
conceptual framework from XML Schema datatypes [XML-SCHEMA2], as described in RDF Concepts and Abstract
Syntax [RDF-CONCEPTS]. This conceptual
framework defines a datatype as consisting of:
- A set of values, called the value space, that literals of the
datatype are intended to represent. For example, for the XML Schema
datatype
xsd:date, this set of values is a set of dates.
- A set of character strings, called the lexical space, that the
datatype uses to represent its values. This set determines which
character strings can legally be used to represent literals of this
datatype. For example, the datatype
xsd:date defines
1999-08-16 as being a legal way to write a literal of this
type (as opposed, say, to August 16, 1999). As defined in [RDF-CONCEPTS], the lexical space of a
datatype is a set of Unicode [UNICODE]
strings, allowing information from many languages to be directly
represented.
- A lexical-to-value mapping from the lexical space to the value
space. This determines the value that a given character string from the
lexical space represents for this particular datatype. For example, the
lexical-to-value mapping for datatype
xsd:date determines
that, for this datatype, the string 1999-08-16 represents
the date August 16, 1999. The lexical-to-value mapping is a
factor because the same character string may represent different values
for different datatypes.
Not all datatypes are suitable for use in RDF. For a datatype to be
suitable for use in RDF, it must conform to the conceptual framework just
described. This basically means that, given a character string, the datatype
must unambiguously define whether or not the string is in its lexical space,
and what value in its value space the string represents. For example, the
basic XML Schema datatypes such as xsd:string,
xsd:boolean, xsd:date, etc. are suitable for use in
RDF. However, some of the built-in XML Schema datatypes are not suitable for
use in RDF. For example, xsd:duration does not have a
well-defined value space, and xsd:QName requires an enclosing
XML document context. Lists of the XML Schema datatypes that are currently
considered suitable and unsuitable for use in RDF are given in [RDF-SEMANTICS].
Since the value that a given typed literal denotes
is defined by the typed literal's datatype, and, with the exception of
rdf:XMLLiteral, RDF does not define any datatypes, the actual
interpretation of a typed literal appearing in an RDF graph (e.g.,
determining the value it denotes) must be performed by software that is
written to correctly process not only RDF, but the typed literal's datatype
as well. Effectively, this software must be written to process an extended
language that includes not only RDF, but also the datatype, as part of its
built-in vocabulary. This raises the issue of which datatypes will be
generally available in RDF software. Generally, the XML Schema datatypes that
are listed as suitable for use in RDF in [RDF-SEMANTICS] have a "first among
equals" status in RDF. As noted already, the examples in Figure 8 and Figure 9 used some of
these XML Schema datatypes, and the Primer will be using these datatypes in
most of its other examples of typed literals as well (for one thing, XML
Schema datatypes already have assigned URIrefs that can be used to refer to
them, specified in [XML-SCHEMA2]). These XML
Schema datatypes are treated no differently than any other datatype, but they
are expected to be the most widely used, and therefore the most likely to be
interoperable among different software. As a result, it is expected that much
RDF software will also be written to process these datatypes. However, RDF
software could be written to process other sets of datatypes as well,
assuming they were determined to be suitable for use with RDF, as described
already.
In general, RDF software may be called on to process RDF data that
contains references to datatypes that the software has not been written to
process, in which case there are some things the software will not be able to
do. For one thing, with the exception of
rdf:XMLLiteral, RDF itself does not define the URIrefs that
identify datatypes. As a result, RDF software, unless it has been written to
recognize specific URIrefs, will not be able to determine whether or not a
URIref written in a typed literal actually identifies a datatype. Moreover,
even when a URIref does identify a datatype, RDF itself does not define the
validity of pairing that datatype with a particular literal. This
validity can only be determined by software written to correctly process that
particular datatype.
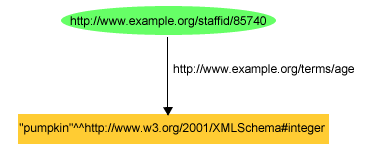
For example, the typed literal in the triple:
exstaff:85740 exterms:age "pumpkin"^^xsd:integer .
or the graph shown in Figure 10:
is valid RDF, but obviously an error as far as the
xsd:integer datatype is concerned, since "pumpkin"
is not defined as being in the lexical space of xsd:integer. RDF
software not written to process the xsd:integer datatype would
not be able to recognize this error.
However, proper use of RDF typed literals provides more
information about the intended interpretation of literal values, and hence
makes RDF statements a better means of information exchange among
applications.
Taken as a whole, RDF is basically simple: nodes-and-arcs diagrams
interpreted as statements about things identified by URIrefs. This section
has presented an introduction to these concepts. As noted earlier, the
normative (i.e., definitive) RDF specification describing these concepts is
RDF Concepts and Abstract
Syntax [RDF-CONCEPTS], which should be
consulted for further information. The formal semantics (meaning) of these
concepts is defined in the (normative) RDF Semantics [RDF-SEMANTICS] document.
However, in addition to the basic techniques for describing things using
RDF statements discussed so far, it should be clear that people or
organizations also need a way to describe the vocabularies (terms)
they intend to use in those statements, specifically, vocabularies for:
- describing types of things (like
exterms:Person)
- describing properties (like
exterms:age and
exterms:creation-date), and
- describing the types of things that can serve as the subjects or
objects of statements involving those properties (such as specifying that
the value of an
exterms:age property should always be an
xsd:integer).
The basis for describing such vocabularies in RDF is the RDF Vocabulary Description Language
1.0: RDF Schema [RDF-VOCABULARY], which
will be described in Section 5.
Additional background on the basic ideas underlying RDF, and its role in
providing a general language for describing Web information, can be found in
[WEBDATA]. RDF draws upon ideas from knowledge
representation, artificial intelligence, and data management, including
Conceptual Graphs, logic-based knowledge representation, frames, and
relational databases. Some possible sources of background information on
these subjects include [SOWA], [CG], [KIF], [HAYES], [LUGER], and [GRAY].
4.
Other RDF Capabilities
RDF provides a number of additional capabilities, such as built-in types and properties for representing
groups of resources and RDF statements, and capabilities for representing XML
fragments as property values. These additional capabilities are
described in the following sections.
There is often a need to describe groups of things: for example,
to say that a book was created by several authors, or to list the students in
a course, or the software modules in a package. RDF provides several
predefined (built-in) types and properties that can be used to describe such
groups.
First, RDF provides a container vocabulary consisting of three
predefined types (together with some associated predefined properties). A
container is a resource that contains things. The contained things
are called members. The members of a container may be resources
(including blank nodes) or literals. RDF defines three types of containers:
A Bag (a resource having type rdf:Bag) represents a group of resources or literals, possibly
including duplicate members, where there is no significance in the order of
the members. For example, a Bag might be used to describe a group of part
numbers in which the order of entry or processing of the part numbers does
not matter.
A Sequence or Seq (a resource having type
rdf:Seq) represents a group of
resources or literals, possibly including duplicate members, where the order
of the members is significant. For example, a Sequence might be used to
describe a group that must be maintained in alphabetical order.
An Alternative or Alt (a resource having type
rdf:Alt) represents a group of
resources or literals that are alternatives (typically for a single
value of a property). For example, an Alt might be used to describe
alternative language translations for the title of a book, or to describe a
list of alternative Internet sites at which a resource might be found. An
application using a property whose value is an Alt container should be aware
that it can choose any one of the members of the group as appropriate.
To describe a resource as being one of these types of containers, the
resource is given an rdf:type property whose value is one of the
predefined resources rdf:Bag, rdf:Seq, or
rdf:Alt (whichever is appropriate). The container resource
(which may either be a blank node or a resource with a URIref) denotes the
group as a whole. The members of the container can be described by
defining a container membership property for each member with the
container resource as its subject and the member as its object. These
container membership properties have names of the form rdf:_n
, where n is a decimal integer greater than zero, with no
leading zeros, e.g., rdf:_1, rdf:_2,
rdf:_3, and so on, and are used specifically for describing the
members of containers. Container resources may also have other properties
that describe the container, in addition to the container membership
properties and the rdf:type property.
It is important to understand that while these types of containers are
described using predefined RDF types and properties, any special meanings
associated with these containers, e.g., that the members of an Alt container
are alternative values, are only intended meanings. These specific
container types, and their definitions, are provided with the aim of
establishing a shared convention among those who need to describe groups of
things. All RDF does is provide the types and properties that can be used to
construct the RDF graphs to describe each type of container. RDF has no more
built-in understanding of what a resource of type rdf:Bag is
than it has of what a resource of type ex:Tent (discussed in Section 3.2) is. In each case, applications must be
written to behave according to the particular meaning involved for each type.
This point will be expanded on in the following examples.
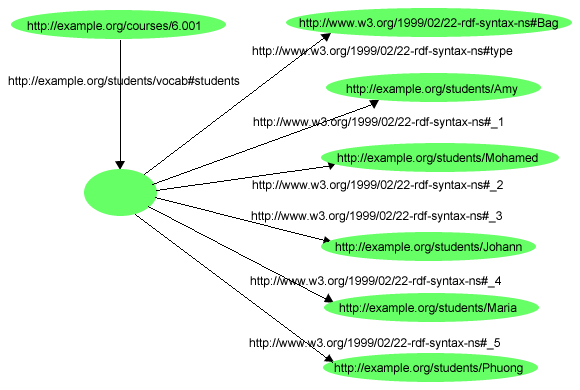
A typical use of a container is to indicate that the value of a property
is a group of things. For example, to represent the sentence "Course 6.001
has the students Amy, Mohamed, Johann, Maria, and Phuong", the course could
be described by giving it a s:students property (from an
appropriate vocabulary) whose value is a container of type
rdf:Bag (representing the group of
students). Then, using the container membership properties, individual
students could be identified as being members of that group, as in the RDF
graph shown in Figure 14:
Since the value of the s:students property in this example is
described as a Bag, there is no intended significance in the order given for
the URIrefs of the students, even though the membership properties in the
graph have integers in their names. It is up to applications creating and
processing graphs that include rdf:Bag containers to ignore any
(apparent) order in the names of the membership properties.
Example 12 describes the graph shown in Figure 14:
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>.
@prefix s: <http://example.org/students/vocab#>.
<http://example.org/courses/6.001>
s:students [
a rdf:Bag;
rdf:_1 <http://example.org/students/Amy>;
rdf:_2 <http://example.org/students/Mohamed>;
rdf:_3 <http://example.org/students/Johann>;
rdf:_4 <http://example.org/students/Maria>;
rdf:_5 <http://example.org/students/Phuong>.
].
The graph structure for an rdf:Seq container, and the
corresponding Turtle, are similar to those for an rdf:Bag (the
only difference is in the type, rdf:Seq). Once again, although
an rdf:Seq container is intended to describe a sequence, it is
up to applications creating and processing the graph to appropriately
interpret the sequence of integer-valued property names.
Note that this example also shows a Turtle abbreviation for the property http://www.w3.org/1999/02/22-rdf-syntax-ns#type in the form of the special predicate name "a". Because using rdf typing is very frequent, this abbreviation is very useful in practice.
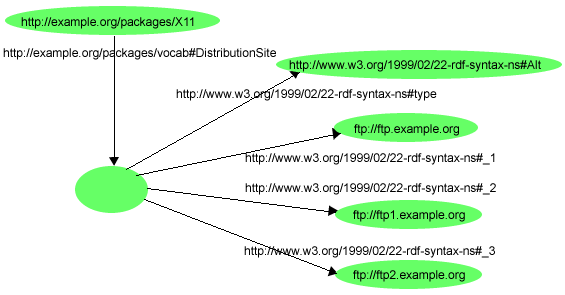
To illustrate an Alt container, the sentence "The source code for X11 may
be found at ftp.example.org, ftp1.example.org, or ftp2.example.org" could be
expressed in the RDF graph shown in Figure 15:
Example 13 shows how the graph in Figure 15 could be written in Turtle:
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>.
@prefix s: <http://example.org/packages/vocab#>.
<http://example.org/packages/X11>
s:DistributionSite [
a rdf:Alt;
rdf:_1 <ftp://ftp.example.org>;
rdf:_2 <ftp://ftp1.example.org>;
rdf:_3 <ftp://ftp2.example.org>.
].
An Alt container is intended to have at least one member, identified by
the property rdf:_1. This member is intended to be considered as
the default or preferred value. Other than the member identified as
rdf:_1, the order of the remaining elements is not significant.
The RDF in Figure 15 as written states
simply that the value of the s:DistributionSite site property is
the Alt container resource itself. Any additional meaning that is to be read
into this graph, e.g., that one of the members of the Alt container
is to be considered as the value of the s:DistributionSite site
property, or that ftp://ftp.example.org is the default or
preferred value, must be built into an application's understanding of the
intended meaning of an Alt container, and/or into the meaning defined for the
particular property (s:DistributionSite in this case), which
also must be understood by the application.
Alt containers are frequently used in conjunction with language tagging.
(Turtle permits the use of a language tag to indicate that the element
content is in a specified language. The use of this tag is described in [TURTLE], and illustrated later in Section 6.2.) For example, a work whose title has been
translated into several languages might have its title property
pointing to an Alt container holding literals representing the titles
expressed in each of the language variants.
The distinction between the intended meanings of a Bag and an Alt can be
further illustrated by considering the authorship of the book "Huckleberry
Finn". The book has exactly one author, but the author has two names (Mark
Twain and Samuel Clemens). Either name is sufficient to specify the author.
Thus using an Alt container for the author's names more accurately represents
the relationship than using a Bag (which might suggest there are two
different authors).
Users are free to choose their own ways to describe groups of resources,
rather than using the RDF container vocabulary. These RDF containers are
merely provided as common definitions that, if generally used, could help
make data involving groups of resources more interoperable.
Sometimes there are clear alternatives to using these RDF container types.
For example, a relationship between a particular resource and a group of
other resources could be indicated by making the first resource the subject
of multiple statements using the same property. This is structurally
different from the resource being the subject of a single statement whose
object is a container containing multiple members. In some cases, these two
structures may have equivalent meaning, but in other cases they may not. The
choice of which to use in a given situation should be made with this in mind.
Consider as an example the relationship between a writer and her
publications, as in the sentence:
Sue has written "Anthology of Time", "Zoological Reasoning", and
"Gravitational Reflections".
In this case, there are three resources each of which was written
independently by the same writer. This could be expressed using repeated
properties as:
exstaff:Sue exterms:publication ex:AnthologyOfTime .
exstaff:Sue exterms:publication ex:ZoologicalReasoning .
exstaff:Sue exterms:publication ex:GravitationalReflections .
In this example there is no stated relationship between the publications
other than that they were written by the same person. Each of the statements
is an independent fact, and so using repeated properties would be a
reasonable choice. However, this could just as reasonably be represented as a
statement about the group of resources written by Sue:
exstaff:Sue exterms:publication _:z
_:z rdf:type rdf:Bag .
_:z rdf:_1 ex:AnthologyOfTime .
_:z rdf:_2 ex:ZoologicalReasoning .
_:z rdf:_3 ex:GravitationalReflections .
On the other hand, the sentence:
The resolution was approved by the Rules Committee, having members Fred,
Wilma, and Dino.
says that the committee as a whole approved the resolution; it
does not necessarily state that each committee member individually
voted in favor of the resolution. In this case, it would be potentially
misleading to model this sentence as three separate
exterms:approvedBy statements, one for each committee member, as
shown below:
ex:resolution exterms:approvedBy ex:Fred .
ex:resolution exterms:approvedBy ex:Wilma .
ex:resolution exterms:approvedBy ex:Dino .
since these statements say that each member individually approved the
resolution.
In this case, it would be better to model the sentence as a single
exterms:approvedBy statement whose subject is the resolution and
whose object is the committee itself. The committee resource could then be
described as a Bag whose members are the members of the committee, as in the
following triples:
ex:resolution exterms:approvedBy ex:rulesCommittee .
ex:rulesCommittee rdf:type rdf:Bag .
ex:rulesCommittee rdf:_1 ex:Fred .
ex:rulesCommittee rdf:_2 ex:Wilma .
ex:rulesCommittee rdf:_3 ex:Dino .
When using RDF containers, it is important to understand that the
statements are not constructing containers, as in a programming
language data structure. Instead, the statements are describing
containers (groups of things) that presumably exist. For instance, in the
Rules Committee example just given, the Rules Committee is an unordered group
of people, whether it is described in RDF that way or not. Saying that the
resource ex:rulesCommittee has type rdf:Bag is not
saying that the Rules Committee is a data structure, or constructing a
particular data structure to hold the members of the group (the Rules
Committee could be described as a Bag without describing any members at all).
Instead, it is describing the Rules Committee as having characteristics
corresponding to those associated with a Bag container, namely that it has
members, and their order of description is not significant. Similarly, using
the container membership properties simply describes a container resource as
having certain things as members. This does not necessarily say that the
things described as members are the only members that exist. For
example, the triples given above to describe the Rules Committee say only
that Fred, Wilma, and Dino are members of the committee, not that they are
the only members of the committee.
Also, Example 12 and Example
13 illustrated a common "pattern" in describing containers, regardless of
the type of container involved (e.g., use of a blank node with an appropriate
rdf:type property to represent the container itself, and use of
rdf:_n to generate sequentially-numbered container membership
properties). However, it is important to understand that RDF does not
enforce this particular way of using the RDF container vocabulary,
and so it is possible to use this vocabulary in other ways. For example, in
some cases it might be appropriate to use a container resource having a
URIref rather than using a blank node. Moreover, it is possible to use the container vocabulary in
ways that may not describe graphs with the "well-formed" structures shown in
the previous examples. For example, Example 14 shows
the Turtle syntax for a graph similar to the Alt container shown in Figure 15:
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>.
@prefix s: <http://example.org/packages/vocab#>.
<http://example.org/packages/X11>
s:DistributionSite [
a rdf:Alt;
a rdf:Bag;
rdf:_2 <ftp://ftp.example.org>;
rdf:_2 <ftp://ftp1.example.org>;
rdf:_5 <ftp://ftp2.example.org>
].
As noted in [RDF-SEMANTICS], RDF imposes
no "well-formedness" conditions on the use of the container vocabulary, so Example 14 is perfectly legal, even though the
container is described as both a Bag and an Alt, it is described as
having two distinct values of the rdf:_2 property, and it does
not have rdf:_1, rdf:_3, or rdf:_4
properties.
As a result, RDF applications that require containers to be "well-formed"
should be written to check that the container vocabulary is being used
appropriately, in order to be fully robust.
A limitation of the containers described in Section
4.1 is that there is no way to close them, i.e., to say "these
are all the members of the container". As noted in Section 4.1, a container only says that certain
identified resources are members; it does not say that other members do not
exist. Also, while one graph may describe some of the members, there is no
way to exclude the possibility that there is another graph somewhere that
describes additional members. RDF provides support for describing groups
containing only the specified members, in the form of RDF
collections. An RDF collection is a group of things represented as a
list structure in the RDF graph. This list structure is constructed using a
predefined collection vocabulary consisting of the predefined type
rdf:List, the predefined properties rdf:first and
rdf:rest, and the predefined resource rdf:nil.
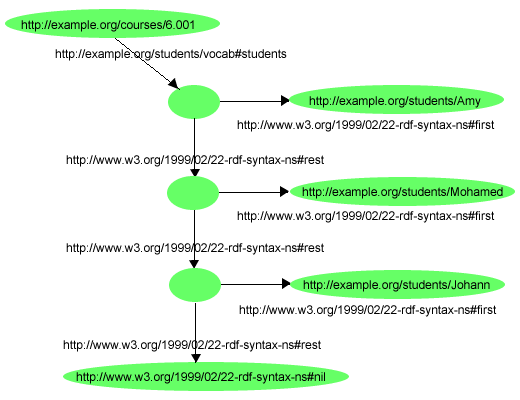
To illustrate this, the sentence "The students in course 6.001 are Amy,
Mohamed, and Johann" could be represented using the graph shown in Figure 16:
In this graph, each member of the collection, such as s:Amy,
is the object of an rdf:first property whose subject is a
resource (a blank node in this example) that represents a list. This list
resource is linked to the rest of the list by an rdf:rest
property. The end of the list is indicated by the rdf:rest
property having as its object the resource rdf:nil (the resource
rdf:nil represents the empty list, and is defined as being of
type rdf:List). This structure will be familiar to those who
know the Lisp programming language. As in Lisp, the rdf:first
and rdf:rest properties allow applications to traverse the
structure. Each of the blank nodes forming this list structure is implicitly
of type rdf:List (that is, each of these nodes implicitly has an
rdf:type property whose value is the predefined type
rdf:List), although this is not explicitly shown in the graph.
The RDF Schema language [RDF-VOCABULARY]
defines the properties rdf:first and rdf:rest as
having subjects of type rdf:List, so the information about these
nodes being lists can generally be inferred, rather than the corresponding
rdf:type triples being written out all the time.
Turtle provides a special notation to make it easy to describe collections
using graphs of this form. To illustrate how this notation works, the Turtle
from Example 15 would result in the RDF graph shown
in Figure 16:
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>.
@prefix s: <http://example.org/students/vocab#>.
<http://example.org/courses/6.001>
s:students (
<http://example.org/students/Amy>
<http://example.org/students/Mohamed>
<http://example.org/students/Johann>
).
The use of Turtle abbreviation for lists always defines a list structure
like the one shown in Figure 16, i.e., a fixed finite
list of items with a given length and terminated by rdf:nil, and
which uses "new" blank nodes that are unique to the list structure itself.
However, RDF does not enforce this particular way of using the RDF
collection vocabulary, and so it is possible to use this vocabulary in other
ways, some of which may not describe lists or closed collections. To see why,
note that the graph shown in Figure 16 could also be
written in Turtle by writing out the same triples "in longhand" (without
using the special Turtle notation) using the collection vocabulary, as in Example 16:
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>.
@prefix s: <http://example.org/students/vocab#>.
<http://example.org/courses/6.001> s:student _:sch1.
_:sch1
rdf:first <http://example.org/students/Amy>;
rdf:rest _:sch2.
_:sch2
rdf:first <http://example.org/students/Mohamed>;
rdf:rest _:sch3.
_:sch3
rdf:first <http://example.org/students/Johann>;
rdf:rest rdf:nil.
As noted in [RDF-SEMANTICS] (and as was
the case for the container vocabulary described in Section 4.1), RDF
imposes no "well-formedness" conditions on the use of the collection
vocabulary so, when writing triples in longhand, it is possible to define RDF
graphs with structures other than the well-structured graphs that would be
automatically generated by using list notation of Turtle. For example, it is
not illegal to assert that a given node has two distinct values of the
rdf:first property, to create structures that have forked or
non-list tails, or to simply omit part of the description of a collection.
Also, graphs defined by using the collection vocabulary in longhand could use
URIrefs to identify the components of the list instead of blank nodes unique
to the list structure. In this case, it would be possible to create triples
in other graphs that effectively added elements to the collection, making it
non-closed.
As a result, RDF applications that require collections to be well-formed
should be written to check that the collection vocabulary is being used
appropriately, in order to be fully robust. In addition, languages such as OWL [OWL],
which can define additional constraints on the structure of RDF graphs, can
rule out some of these cases.
RDF applications sometimes need to describe other RDF statements using
RDF, for instance, to record information about when statements were made, who
made them, or other similar information (this is sometimes referred to as
"provenance" information). For example, Example 9 in
Section 3.2 described a particular tent with
URIref exproducts:item10245, offered for sale by example.com.
One of the triples from that description, describing the weight of the tent,
was:
exproducts:item10245 exterms:weight "2.4"^^xsd:decimal .
and it might be useful for example.com to record who provided that
particular piece of information.
RDF provides a built-in vocabulary intended for describing RDF statements.
A description of a statement using this vocabulary is called a
reification of the statement. The RDF reification vocabulary
consists of the type rdf:Statement, and the properties
rdf:subject, rdf:predicate, and
rdf:object. However, while RDF provides this reification
vocabulary, care is needed in using it, because it is easy to imagine that
the vocabulary defines some things that are not actually defined. This point
will be discussed further later in this section.
Using the reification vocabulary, a reification of the statement
about the tent's weight would be given by assigning the statement a URIref
such as exproducts:triple12345 (so statements can be written
describing it), and then describing the statement using the statements:
exproducts:triple12345 rdf:type rdf:Statement .
exproducts:triple12345 rdf:subject exproducts:item10245 .
exproducts:triple12345 rdf:predicate exterms:weight .
exproducts:triple12345 rdf:object "2.4"^^xsd:decimal .
These statements say that the resource identified by the URIref
exproducts:triple12345 is an RDF statement, that the subject of
the statement refers to the resource identified by
exproducts:item10245, the predicate of the statement refers to
the resource identified by exterms:weight, and the object of the
statement refers to the decimal value identified by the typed literal
"2.4"^^xsd:decimal. Assuming that the original statement is
actually identified by exproducts:triple12345, it should be
clear by comparing the original statement with the reification that the
reification actually does describe it. The conventional use of the RDF
reification vocabulary always involves describing a statement using four
statements in this pattern; the four statements are sometimes referred to as
a "reification quad" for this reason.
Using reification according to this convention, example.com could record
the fact that John Smith made the original statement about the tent's weight
by first assigning the original statement a URIref (such as
exproducts:triple12345 as before), describing that statement
using the reification just described, and then adding an additional statement
that exproducts:triple12345 was written by John Smith (using a
URIref to identify which John Smith is being referred to). The resulting
statements would be:
exproducts:triple12345 rdf:type rdf:Statement .
exproducts:triple12345 rdf:subject exproducts:item10245 .
exproducts:triple12345 rdf:predicate exterms:weight .
exproducts:triple12345 rdf:object "2.4"^^xsd:decimal .
exproducts:triple12345 dc:creator exstaff:85740 .
The original statement, together with the reification and the attribution
of the statement to John Smith, forms the graph shown in Figure 17:
Section 3.2 introduced the use of the Turtle shorthand for URIrefs. This can also be used in
a property element to automatically produce a reification of the
triple that the property element generates. Example
17 shows how this could be used to produce the same graph :
In this case, specifying the attribute :triple12345 in the
exterms:weight element results in the original triple describing
the tent's weight:
exproducts:item10245 exterms:weight "2.4"^^xsd:decimal .
plus the reification triples:
exproducts:triple12345 rdf:type rdf:Statement .
exproducts:triple12345 rdf:subject exproducts:item10245 .
exproducts:triple12345 rdf:predicate exterms:weight .
exproducts:triple12345 rdf:object "2.4"^^xsd:decimal .
The subject of these reification triples is a URIref formed by
concatenating the base URI of the document (given in the @base
declaration), the character "#" (to indicate that what follows
is a fragment identifier), and the value of the shorthand; that is, the
triples have the same subject exproducts:triple12345 as in the
previous examples.
Note that asserting the reification is not the same as asserting the
original statement, and neither implies the other. That is, when someone says
that John said something about the weight of a tent, they are not making a
statement about the weight of a tent themselves, they are making a statement
about something John said. Conversely, when someone describes the weight of a
tent, they are not also making a statement about a statement they made (since
they may have no intention of talking about things called "statements").
The text above deliberately referred in a number of places to "the
conventional use of reification". As noted earlier, care is needed when using
the RDF reification vocabulary because it is easy to imagine that the
vocabulary defines some things that are not actually defined. While there are
applications that successfully use reification, they do so by following some
conventions, and making some assumptions, that are in addition to the actual
meaning that RDF defines for the reification vocabulary, and the actual
facilities that RDF provides to support it.
For one thing, it is important to note that in the conventional use of
reification, the subject of the reification triples is assumed to identify a
particular instance of a triple in a particular RDF document, rather
than some arbitrary triple having the same subject, predicate, and object.
This particular convention is used because reification is intended for
expressing properties such as dates of composition and source information, as
in the examples given already, and these properties need to be applied to
specific instances of triples. There could be several triples that have the
same subject, predicate, and object and, although a graph is defined as a
set of triples, several instances with the same triple structure
might occur in different documents. Thus, to fully support this convention,
there needs to be some means of associating the subject of the reification
triples with an individual triple in some document. However, RDF
provides no way to do this.
For instance, in the examples above, there is no explicit information in either the triples or the Turtle code that actually indicates that the original statement describing the tent's weight is the resource exproducts:triple12345, the resource that is the subject of the
four reification statements and the statement that John Smith created it.
This can be seen by looking at the drawn graph shown in Figure 17. The original statement is certainly part of
this graph, but as far as the information in the graph is concerned,
exproducts:triple12345 is a separate resource, rather than
identifying that part of the graph. RDF does not provide a built-in way of
indicating how a URIref like exproducts:triple12345 is
associated with a particular statement or graph, any more than it provides a
built-in way of indicating how a URIref like
exproducts:item10245 is associated with an actual tent.
Associating specific URIrefs with specific resources (statements in this
case) must be done using mechanisms outside of RDF.
Using URIrefs shorthand as shown in Example 17 generates the reification automatically, and provides a convenient way of indicating the URIref to be used as the subject of the statements in the reification. Moreover, it provides a partial "hook" relating the triples in the reification with the piece of Turtle syntax that caused them to be created, since the value triple12345 of the shorthand is used to
generate the URIref of the subject of the reification triples. However, this
relationship is once again outside RDF, since there is nothing in the
resulting triples that explicitly says that the original triple had the
URIref exproducts:triple12345 (RDF does not assume there is any relationship between a URIref and any Turtle code that it might have been used or abbreviated in).
The lack of a built-in means for assigning URIrefs to statements does not
mean that "provenance" information of this kind cannot be expressed in RDF,
just that it cannot be done using only the meaning RDF associates with the
reification vocabulary. For example, if an RDF document (say, a Web page) has
a URI, statements could be made about the resource identified by that URI
and, based on some application-dependent understanding of how those
statements should be interpreted, an application could act as if those
statements "distribute" over (apply equally to) all the statements in the
document. Also, if some mechanism exists (outside of RDF) to assign URIs to
individual RDF statements, then statements could certainly be made about
those individual statements, using their URIs to identify them. However, in
these cases, it would also not be strictly necessary to use the reification
vocabulary in the conventional way.
To see this, assuming the original statement:
exproducts:item10245 exterms:weight "2.4"^^xsd:decimal .
had a URIref of exproducts:triple12345, the statement could
be attributed to John Smith simply by the statement:
exproducts:triple12345 dc:creator exstaff:85740 .
with no use of the reification vocabulary (although the description of
exproducts:triple12345 as having rdf:type
rdf:Statement might also be helpful).
In addition, the reification vocabulary could be used directly according
to the convention described above, along with an application-dependent
understanding as to how to associate specific triples with their
reifications. However, other applications receiving this RDF would not
necessarily share this application-dependent understanding, and thus would
not necessarily interpret the graphs appropriately.
It is also important to note that the interpretation of reification
described here is not the same as "quotation", as found in some languages.
Instead, the reification describes the relationship between a particular
instance of a triple and the resources the triple refers to. The reification
can be read intuitively as saying "this RDF triple talks about these things",
rather than (as in quotation) "this RDF triple has this form." For instance,
in the reification example used in this section, the triple:
exproducts:triple12345 rdf:subject exproducts:item10245 .
describing the rdf:subject of the original statement says
that the subject of the statement is the resource (the tent) identified by
the URIref exproducts:item10245. It does not say that
the subject of the statement is the URIref itself (i.e., a string beginning
with certain characters), as quotation would do.
Section 2.3 noted that the RDF model
intrinsically supports only binary relations; that is, a statement
specifies a relation between two resources. For example, the statement:
exstaff:85740 exterms:manager exstaff:62345 .
states that the relation exterms:manager holds between two
employees (presumably one manages the other).
However, in some cases it is necessary to represent information involving
higher arity relations (relations between more than two resources) in RDF. Section 2.3 discussed one example of this,
where the problem was to represent the relationship between John Smith and
his address information, and the value of John's address was a structured
value of his street, city, state, and postal code. Writing this as a relation
shows that this address is a 5-ary relation of the form:
address(exstaff:85740, "1501 Grant Avenue",
"Bedford", "Massachusetts", "01730")
Section 2.3 noted that this kind of
structured information can be represented in RDF by considering the aggregate
thing be described (here, the group of components representing John's
address) as a separate resource, and then making separate statements about
that new resource, as in the triples:
exstaff:85740 exterms:address _:johnaddress .
_:johnaddress exterms:street "1501 Grant Avenue" .
_:johnaddress exterms:city "Bedford" .
_:johnaddress exterms:state "Massachusetts" .
_:johnaddress exterms:postalCode "01730" .
(where _:johnaddress is the blank node identifier of the
blank node representing John's address.)
This is a general way to represent any n-ary relation in RDF: select one
of the participants (John in this case) to serve as the subject of the
original relation (address in this case), then specify an
intermediate resource to represent the rest of the relation (either with or
without assigning it a URI), then give that new resource properties
representing the remaining components of the relation.
In the case of John's address, none of the individual parts of the
structured value could be considered the "main" value of the
exterms:address property; all of the parts contribute equally to
the value. However, in some cases one of the parts of the structured value is
often thought of as the "main" value, with the other parts of the relation
providing additional contextual or other information that qualifies the main
value. For instance, in Example 9 in Section 3.2, the weight of a particular tent was
given as the decimal value 2.4 using a typed
literal, i.e.,
exproduct:item10245 exterms:weight "2.4"^^xsd:decimal .
In fact, a more complete description of the weight would have been 2.4
kilograms rather than just the decimal value 2.4. To state
this, the value of the exterms:weight property would need to
have two components, the typed literal for the decimal value and an
indication of the unit of measure (kilograms). In this situation the decimal
value could be considered the "main" value of the exterms:weight
property, because frequently the value would be recorded simply as the typed
literal (as in the triple above), relying on an understanding of the context
to fill in the unstated units information.
In the RDF model a qualified property value of this kind can be considered
as simply another kind of structured value. To represent this, a separate
resource could be used to represent the structured value as a whole (the
weight, in this case), and to serve as the object of the original statement.
That resource could then be given properties representing the individual
parts of the structured value. In this case, there should be a property for
the typed literal representing the decimal value, and a property for the
unit. RDF provides a predefined rdf:value property to describe
the main value (if there is one) of a structured value. So in this case, the
typed literal could be given as the value of the rdf:value
property, and the resource exunits:kilograms as the value of an
exterms:units property (assuming the resource
exunits:kilograms is defined as part of example.org's
vocabulary). The resulting triples would be:
exproduct:item10245 exterms:weight _:weight10245 .
_:weight10245 rdf:value "2.4"^^xsd:decimal .
_:weight10245 exterms:units exunits:kilograms .
The same approach can be used to represent quantities using any units of
measure, as well as values taken from different classification schemes or
rating systems, by using the rdf:value property to give the main
value, and using additional properties to identify the classification scheme
or other information that further describes the value.
There is no need to use rdf:value for these purposes (e.g., a
user-defined property name, such as exterms:amount, could have
been used instead of rdf:value), and RDF does not associate any
special meaning with rdf:value. rdf:value is simply
provided as a convenience for use in these commonly-occurring situations.
However, even though much existing data in databases and on the Web (and
in later Primer examples) takes the form of simple values for properties such
as weights, costs, etc., the principle that such simple values are often
insufficient to adequately describe these values is an important one. In a
global environment such as the Web, it is generally not safe to make
the assumption that anyone accessing a property value will understand the
units being used (or other contextually-dependent information that may be
involved). For example, a U.S. site might give a weight value in pounds, but
someone accessing that data from outside the U.S. might assume that weights
are given in kilograms. The correct interpretation of data in the Web
environment may require that additional information (such as units
information) be explicitly recorded. This can be done in many ways, such as
using rdf:value, building units into property names (e.g.,
exterms:weightInKg), defining specialized datatypes that include
units information (e.g., extypes:kilograms), or adding
additional user-defined properties to specify this information (e.g.,
exterms:unitOfWeight), either in descriptions of individual
items or products, in descriptions of sets of data (e.g., all the data in a
catalog or on a site), or in schemas (see Section
5).
5. Defining RDF
Vocabularies: RDF Schema
RDF provides a way to express simple statements about resources, using
named properties and values. However, RDF user communities also need the
ability to define the vocabularies (terms)
they intend to use in those statements, specifically, to indicate that
they are describing specific kinds or classes of resources, and will use
specific properties in describing those resources. For example, the company
example.com from the examples in Section 3.2
would want to describe classes such as exterms:Tent, and use
properties such as exterms:model,
exterms:weightInKg, and exterms:packedSize to
describe them (QNames with various "example" namespace prefixes are used as
the names of classes and properties here as a reminder that in RDF these
names are actually URI references, as discussed in Section 2.1). Similarly, people interested in
describing bibliographic resources would want to describe classes such as
ex2:Book or ex2:MagazineArticle, and use properties
such as ex2:author, ex2:title, and
ex2:subject to describe them. Other applications might need to
describe classes such as ex3:Person and
ex3:Company, and properties such as ex3:age,
ex3:jobTitle, ex3:stockSymbol, and
ex3:numberOfEmployees. RDF itself
provides no means for defining such application-specific classes and
properties. Instead, such classes and properties are described as an RDF
vocabulary, using extensions to RDF provided by the RDF Vocabulary Description Language
1.0: RDF Schema [RDF-VOCABULARY],
referred to here as RDF Schema.
RDF Schema does not provide a vocabulary of application-specific classes
like exterms:Tent, ex2:Book, or
ex3:Person, and properties like exterms:weightInKg,
ex2:author or ex3:JobTitle. Instead, it provides
the facilities needed to describe such classes and properties, and
to indicate which classes and properties are expected to be used together
(for example, to say that the property ex3:jobTitle will be used
in describing a ex3:Person). In other words, RDF Schema provides
a type system for RDF. The RDF Schema type system is similar in some
respects to the type systems of object-oriented programming languages such as
Java. For example, RDF Schema allows resources to be defined as instances of
one or more classes. In addition, it allows classes to be organized
in a hierarchical fashion; for example a class ex:Dog might be
defined as a subclass of ex:Mammal which is a subclass of
ex:Animal, meaning that any resource which is in class
ex:Dog is also implicitly in class ex:Animal as
well. However, RDF classes and properties are in some respects very different
from programming language types. RDF class and property descriptions do not
create a straightjacket into which information must be forced, but instead
provide additional information about the RDF resources they describe. This
information can be used in a variety of ways, which will be discussed in Section 5.3.
The RDF Schema facilities are themselves provided
in the form of an RDF vocabulary; that is, as a specialized set of predefined
RDF resources with their own special meanings. The resources in the RDF
Schema vocabulary have URIrefs with the prefix
http://www.w3.org/2000/01/rdf-schema# (conventionally associated
with the QName prefix rdfs:). Vocabulary descriptions (schemas)
written in the RDF Schema language are legal RDF graphs. Hence, RDF software
that is not written to also process the additional RDF Schema vocabulary can
still interpret a schema as a legal RDF graph consisting of various resources
and properties, but will not "understand" the additional built-in meanings of
the RDF Schema terms. To understand these additional meanings, RDF software
must be written to process an extended language that includes not only the
rdf: vocabulary, but also the rdfs: vocabulary,
together with their built-in meanings. This point will be illustrated in the
next section.
The following sections will illustrate RDF Schema's basic resources and
properties.
A basic step in any kind of description process is identifying the various
kinds of things to be described. RDF Schema refers to these "kinds of things"
as classes. A class in RDF Schema corresponds to the
generic concept of a Type or Category, somewhat like the
notion of a class in object-oriented programming languages such as Java. RDF
classes can be used to represent almost any category of thing, such as Web
pages, people, document types, databases or abstract concepts. Classes are
described using the RDF Schema resources rdfs:Class and
rdfs:Resource, and the properties rdf:type and
rdfs:subClassOf.
For example, suppose an organization example.org wanted to
use RDF to provide information about different kinds of motor vehicles. In
RDF Schema, example.org would first need a class to represent
the category of things that are motor vehicles. The resources that belong to
a class are called its instances. In this case,
example.org intends for the instances of this class to be
resources that are motor vehicles.
In RDF Schema, a class is any resource having an
rdf:type property whose value is the resource
rdfs:Class. So the motor vehicle class would be described by
assigning the class a URIref, say ex:MotorVehicle (using ex: to stand for the URIref
http://www.example.org/schemas/vehicles, which is used as the
prefix for URIrefs from example.org's vocabulary) and describing that
resource with an rdf:type property whose value is the resource
rdfs:Class. That is, example.org would write the
RDF statement:
ex:MotorVehicle rdf:type rdfs:Class .
As indicated in Section 3.2, the property
rdf:type is used to indicate that a resource is an instance of a
class. So, having described ex:MotorVehicle as a class, resource
exthings:companyCar would be described as a motor vehicle by the
RDF statement:
exthings:companyCar rdf:type ex:MotorVehicle .
(This statement uses a common convention that class names are written with
an initial uppercase letter, while property and instance names are written
with an initial lowercase letter. However, this convention is not required in
RDF Schema. The statement also assumes that
example.org has decided to define separate vocabularies for
classes of things, and instances of things.)
The resource rdfs:Class itself has an rdf:type
of rdfs:Class. A resource may be an instance of more than one
class.
After describing class ex:MotorVehicle,
example.org might want to describe additional classes
representing various specialized kinds of motor vehicle, e.g., passenger
vehicles, vans, minivans, and so on. These classes can be described in the
same way as class ex:MotorVehicle, by assigning a URIref for
each new class, and writing RDF statements describing these resources as
classes, e.g., writing:
ex:Van rdf:type rdfs:Class .
ex:Truck rdf:type rdfs:Class .
and so on. However, these statements by themselves only describe the
individual classes. example.org may also want to indicate their
special relationship to class ex:MotorVehicle, i.e., that they
are specialized kinds of MotorVehicle.
This kind of specialization relationship between two classes is described
using the predefined rdfs:subClassOf property to relate the two
classes. For example, to state that ex:Van is a specialized kind
of ex:MotorVehicle, example.org would write the RDF
statement:
ex:Van rdfs:subClassOf ex:MotorVehicle .
The meaning of this rdfs:subClassOf relationship is that any
instance of class ex:Van is also an instance of class
ex:MotorVehicle. So if resource
exthings:companyVan is an instance of ex:Van then,
based on the declared rdfs:subClassOf relationship, RDF software
written to understand the RDF Schema vocabulary can infer the additional information that
exthings:companyVan is also an instance of
ex:MotorVehicle.
This example of exthings:companyVan
illustrates the point made earlier about RDF Schema defining an extended
language. RDF itself does not define the special meaning of terms from the
RDF Schema vocabulary such as rdfs:subClassOf. So if an RDF
schema defines this rdfs:subClassOf relationship between
ex:Van and ex:MotorVehicle, RDF software not
written to understand the RDF Schema terms would recognize this as a triple,
with predicate rdfs:subClassOf, but it would not understand the
special significance of rdfs:subClassOf, and not be able to draw
the additional inference that exthings:companyVan is also an
instance of ex:MotorVehicle.
The rdfs:subClassOf property is transitive. This
means, for example, that given the RDF statements:
ex:Van rdfs:subClassOf ex:MotorVehicle .
ex:MiniVan rdfs:subClassOf ex:Van .
RDF Schema defines ex:MiniVan as also being
a subclass of ex:MotorVehicle. As a result, RDF Schema defines
resources that are instances of class ex:MiniVan as also being
instances of class ex:MotorVehicle (as well as being instances
of class ex:Van). A class may be a subclass of more than one
class (for example, ex:MiniVan may be a subclass of both
ex:Van and ex:PassengerVehicle). RDF Schema defines
all classes as subclasses of class rdfs:Resource (since the
instances belonging to all classes are resources).
Figure 18 shows the full class hierarchy being
discussed in these examples.
(To simplify the figure, the rdf:type properties relating
each of the classes to rdfs:Class are omitted in Figure 18. In fact, RDF Schema defines both the subjects
and objects of statements that use the rdfs:subClassOf property
to be resources of type rdfs:Class, so this information could be
inferred. However, in actually writing schemas, it is good practice to
explicitly provide this information.)
This schema could also be described by the triples:
ex:MotorVehicle rdf:type rdfs:Class .
ex:PassengerVehicle rdf:type rdfs:Class .
ex:Van rdf:type rdfs:Class .
ex:Truck rdf:type rdfs:Class .
ex:MiniVan rdf:type rdfs:Class .
ex:PassengerVehicle rdfs:subClassOf ex:MotorVehicle .
ex:Van rdfs:subClassOf ex:MotorVehicle .
ex:Truck rdfs:subClassOf ex:MotorVehicle .
ex:MiniVan rdfs:subClassOf ex:Van .
ex:MiniVan rdfs:subClassOf ex:PassengerVehicle .
In addition to describing the specific classes of things they
want to describe, user communities also need to be able to describe specific
properties that characterize those classes of things (such as
rearSeatLegRoom to describe a passenger vehicle). In RDF Schema,
properties are described using the RDF class rdf:Property, and
the RDF Schema properties rdfs:domain, rdfs:range,
and rdfs:subPropertyOf.
All properties in RDF are described as instances of class
rdf:Property. So a new property, such as
exterms:weightInKg, is described by assigning the property a
URIref, and describing that resource with an rdf:type property
whose value is the resource rdf:Property, for example, by
writing the RDF statement:
exterms:weightInKg rdf:type rdf:Property .
RDF Schema also provides vocabulary for describing how properties and
classes are intended to be used together in RDF data. The most important
information of this kind is supplied by using the RDF Schema properties
rdfs:range and rdfs:domain to further describe
application-specific properties.
The rdfs:range property is used to indicate that the values
of a particular property are instances of a designated class. For example, if
example.org wanted to indicate that the property
ex:author had values that are instances of class
ex:Person, it would write the RDF statements:
ex:Person rdf:type rdfs:Class .
ex:author rdf:type rdf:Property .
ex:author rdfs:range ex:Person .
These statements indicate that ex:Person is a class,
ex:author is a property, and that RDF statements using the
ex:author property have instances of ex:Person as
objects.
A property, say ex:hasMother, can have zero, one, or more
than one range property. If ex:hasMother has no range property,
then nothing is said about the values of the ex:hasMother
property. If ex:hasMother has one range property, say one
specifying ex:Person as the range, this says that the values of
the ex:hasMother property are instances of class
ex:Person. If ex:hasMother has more than one range
property, say one specifying ex:Person as its range, and another
specifying ex:Female as its range, this says that the values of
the ex:hasMother property are resources that are instances of
all of the classes specified as the ranges, i.e., that any value of
ex:hasMother is both a ex:Female
and a ex:Person.
This last point may not be obvious. However, stating that the property
ex:hasMother has the two ranges ex:Female and
ex:Person involves making two separate statements:
ex:hasMother rdfs:range ex:Female .
ex:hasMother rdfs:range ex:Person .
For any given statement using this property, say:
exstaff:frank ex:hasMother exstaff:frances .
in order for both the rdfs:range statements to be
correct, it must be the case that exstaff:frances is
both an instance of ex:Female and of
ex:Person.
The rdfs:range property can also be used to indicate that the
value of a property is given by a typed literal, as discussed in Section 2.4. For example, if
example.org wanted to indicate that the property
ex:age had values from the XML Schema datatype
xsd:integer, it would write the RDF statements:
ex:age rdf:type rdf:Property .
ex:age rdfs:range xsd:integer .
The datatype xsd:integer is identified by its URIref (the
full URIref being http://www.w3.org/2001/XMLSchema#integer).
This URIref can be used without explicitly stating in the schema that it
identifies a datatype. However, it is often useful to explicitly state that a
given URIref identifies a datatype. This can be done using the RDF Schema
class rdfs:Datatype. To state that xsd:integer is a
datatype, example.org would write the RDF statement:
xsd:integer rdf:type rdfs:Datatype .
This statement says that xsd:integer is the URIref of a
datatype (which is assumed to conform to the requirements for RDF datatypes
described in [RDF-CONCEPTS]). Such a
statement does not constitute a definition of a datatype,
e.g., in the sense that example.org is defining a new datatype.
There is no way to define datatypes in RDF Schema. As noted in Section 2.4, datatypes are defined externally to
RDF (and to RDF Schema), and referred to in RDF statements by their
URIrefs. This statement simply serves to document the existence of the
datatype, and indicate explicitly that it is being used in this schema.
The rdfs:domain property is used to indicate that a
particular property applies to a designated class. For example, if
example.org wanted to indicate that the property
ex:author applies to instances of class ex:Book, it
would write the RDF statements:
ex:Book rdf:type rdfs:Class .
ex:author rdf:type rdf:Property .
ex:author rdfs:domain ex:Book .
These statements indicate that ex:Book is a class,
ex:author is a property, and that RDF statements using the
ex:author property have instances of ex:Book as
subjects.
A given property, say exterms:weight, may have zero, one, or
more than one domain property. If exterms:weight has no domain
property, then nothing is said about the resources that
exterms:weight properties may be used with (any resource could
have a exterms:weight property). If exterms:weight
has one domain property, say one specifying ex:Book as the
domain, this says that the exterms:weight property applies to
instances of class ex:Book. If exterms:weight has
more than one domain property, say one specifying ex:Book as the
domain and another one specifying ex:MotorVehicle as the domain,
this says that any resource that has a exterms:weight property
is an instance of all of the classes specified as the domains, i.e.,
that any resource that has a exterms:weight property is both a
ex:Book and a ex:MotorVehicle
(illustrating the need for care in specifying domains and ranges).
As in the case of rdfs:range, this last point may not be
obvious. However, stating that the property exterms:weight has
the two domains ex:Book and ex:MotorVehicle
involves making two separate statements:
exterms:weight rdfs:domain ex:Book .
exterms:weight rdfs:domain ex:MotorVehicle .
For any given statement using this property, say:
exthings:companyCar exterms:weight "2500"^^xsd:integer .
in order for both the rdfs:domain statements to be
correct, it must be the case that exthings:companyCar is
both an instance of ex:Book and of
ex:MotorVehicle.
The use of these range and domain descriptions can be illustrated by
extending the vehicle schema, adding two properties
ex:registeredTo and ex:rearSeatLegRoom, a new class
ex:Person, and explicitly describing the datatype
xsd:integer as a datatype. The ex:registeredTo
property applies to any ex:MotorVehicle and its value is a
ex:Person. For the sake of this example,
ex:rearSeatLegRoom applies only to instances of class
ex:PassengerVehicle. The value is an xsd:integer
giving the number of centimeters of rear seat legroom. These descriptions are
shown in Example 18 :
:registeredTo a rdf:Property;
rdfs:domain :MotorVehicle;
rdfs:range :Person.
:rearSeatLegRoom a rdf:Property;
rdfs:domain :PassengerVehicle;
rdfs:range xsd:integer.
:Person a rdfs:Class.
xsd:integer a rdfs:Datatype.
RDF Schema provides a way to specialize properties as well as
classes. This specialization relationship between two properties is described
using the predefined rdfs:subPropertyOf property. For example,
if ex:primaryDriver and ex:driver are both
properties, example.org could describe these properties, and the
fact that ex:primaryDriver is a specialization of
ex:driver, by writing the RDF statements:
ex:driver rdf:type rdf:Property .
ex:primaryDriver rdf:type rdf:Property .
ex:primaryDriver rdfs:subPropertyOf ex:driver .
The meaning of this rdfs:subPropertyOf relationship is that
if an instance exstaff:fred is an ex:primaryDriver
of the instance ex:companyVan, then RDF
Schema defines exstaff:fred as also being an
ex:driver of ex:companyVan.
A property may be a subproperty of zero, one or more properties. All RDF
Schema rdfs:range and rdfs:domain properties that
apply to an RDF property also apply to each of its subproperties. So, in the
above example, RDF Schema defines
ex:primaryDriver as also having an rdfs:domain of
ex:MotorVehicle, because of its subproperty relationship to
ex:driver.
Example 19 shows the Turtle for the
full vehicle schema, containing all the descriptions given so far:
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#>
@prefix xsd: <http://www.w3.org/2001/XMLSchema#>.
@base <http://example.org/schemas/vehicles>
:MotorVehicle a rdfs:Class.
:PassengerVehicle a rdfs:Class;
rdfs:subClassOf :MotorVehicle.
:Truck a rdfs:Class;
rdfs:subClassOf :MotorVehicle.
:Van a rdfs:Class;
rdfs:subClassOf :MotorVehicle.
:MiniVan a rdfs:Class;
rdfs:subClassOf :Van.
rdfs:subClassOf :PassengerVehicle;
:Person a rdfs:Class.
xsd:integer a rdfs:Datatype.
:registeredTo a rdf:Property;
rdfs:domain :MotorVehicle;
rdfs:range :Person.
:rearSeatLegRoom a rdf:Property;
rdfs:domain rdf:resource :MotorVehicle;
rdfs:range xsd:integer.
:driver a rdf:Property;
rdfs:domain :MotorVehicle.
:primaryDriver a rdf:Property;
rdfs:subPropertyOf :driver.
Having shown how to describe classes and properties using RDF Schema,
instances using those classes and properties can now be illustrated. For
example, Example 29 Example 20 describes an instance of the
ex:PassengerVehicle class described in Example 19, together with some hypothetical values for its
properties.
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
@prefix ex: <http://example.org/schemas/vehicles#>
@base <http://example.org/things>
:johnSmithsCar a ex:PassengerVehicle;
ex:registeredTo <http://www.example.org/staffid/85740>;
ex:rearSeatLegRoom "127"^^xsd:integer;
ex:primaryDriver <http://www.example.org/staffid/85740>.
This example assumes that the instance is described in a separate document
from the schema. Since the schema has an xml:base of
http://example.org/schemas/vehicles, the namespace declaration
@prefix ex: <http://example.org/schemas/vehicles#>
is provided to allow QNames such as ex:registeredTo in the
instance data to be properly expanded to the URIrefs of the classes and
properties described in that schema. An @base
declaration is also provided for this instance, to allow :johnSmithsCar to expand to the proper URIref
independently of the location of the actual document.
Note that an ex:registeredTo property can be used in
describing this instance of ex:PassengerVehicle, because
ex:PassengerVehicle is a subclass of
ex:MotorVehicle. Note also that a typed literal is used for the
value of the ex:rearSetLegRoom property in this instance, rather
than a plain literal (i.e., rather than stating the value as
ex:rearSeatLegRoom 127;). Because the schema describes the
range of this property as an xsd:integer, the value of the
property should be a typed literal of that datatype in order to match the
range description (i.e., the range declaration does
not automatically "assign" a datatype to a plain literal, and so a typed
literal of the appropriate datatype must be explicitly provided).
Additional information, either in the schema, or in additional instance data,
could also be provided to explicitly specify the units of the
ex:rearSetLegRoom property (centimeters), as discussed in Section 4.4.
As noted earlier, the RDF Schema type system is similar in some respects
to the type systems of object-oriented programming languages such as Java.
However, RDF differs from most programming language type systems in several
important respects.
One important difference is that instead of describing a class as having a
collection of specific properties, an RDF schema describes properties as
applying to specific classes of resources, using domain and
range properties. For example, a typical object-oriented programming
language might define a class Book with an attribute called
author having values of type Person. A
corresponding RDF schema would describe a class ex:Book, and, in
a separate description, a property ex:author having a domain of
ex:Book and a range of ex:Person.
The difference between these approaches may seem to be only syntactic, but
in fact there is an important difference. In the programming language class
description, the attribute author is part of the description of
class Book, and applies only to instances of class
Book. Another class (say, softwareModule) might
also have an attribute called author, but this would be
considered a different attribute. In other words, the scope
of an attribute description in most programming languages is restricted to
the class or type in which it is defined. In RDF, on the other hand, property
descriptions are, by default, independent of class definitions, and
have, by default, global scope (although they may optionally be
declared to apply only to certain classes using domain specifications).
As a result, an RDF schema could describe a property
exterms:weight without a domain being specified. This property
could then be used to describe instances of any class that might be
considered to have a weight. One benefit of the RDF property-based approach
is that it becomes easier to extend the use of property definitions to
situations that might not have been anticipated in the original description.
At the same time, this is a "benefit" which must be used with care, to insure
that properties are not mis-applied in inappropriate situations.
Another result of the global scope of RDF property
descriptions is that it is not possible in an RDF schema to define a specific
property as having locally-different ranges depending on the class of the
resource it is applied to. For example, in defining the property
ex:hasParent, it would be desirable to be able to say that if
the property is used to describe a resource of class ex:Human,
then the range of the property is also a resource of class
ex:Human, while if the property is used to describe a resource
of class ex:Tiger, then the range of the property is also a
resource of class ex:Tiger. This kind of definition is not
possible in RDF Schema. Instead, any range defined for an RDF property
applies to all uses of the property, and so ranges should be defined
with care. However, while such locally-different ranges cannot be defined in
RDF Schema, they can be defined in some of the richer schema languages
discussed in Section 5.5.
Another important difference is that RDF Schema descriptions are not
necessarily prescriptive in the way programming language type
declarations typically are. For example, if a programming language declares a
class Book with an author attribute having values
of type Person, this is usually interpreted as a group of
constraints. The language will not allow the creation of an instance
of Book without an author attribute, and it will
not allow an instance of Book with an author
attribute that does not have a Person as its value. Moreover, if
author is the only attribute defined for class
Book, the language will not allow an instance of
Book with some other attribute.
RDF Schema, on the other hand, provides schema information as additional
descriptions of resources, but does not prescribe how these
descriptions should be used by an application. For example, suppose an RDF
schema states that an ex:author property has an
rdfs:range of class ex:Person. This is simply an
RDF statement that RDF statements containing ex:author
properties have instances of ex:Person as objects.
This schema-supplied information might be used in different ways. One
application might interpret this statement as specifying part of a template
for RDF data it is creating, and use it to ensure that any
ex:author property has a value of the indicated
(ex:Person) class. That is, this application interprets the
schema description as a constraint in the same way that a
programming language might. However, another application might interpret this
statement as providing additional information about data it is receiving,
information which may not be provided explicitly in the original data. For
example, this second application might receive some RDF data that includes an
ex:author property whose value is a resource of unspecified
class, and use this schema-provided statement to conclude that the resource
must be an instance of class ex:Person. A third application
might receive some RDF data that includes an ex:author property
whose value is a resource of class ex:Corporation, and use this
schema information as the basis of a warning that "there may be an
inconsistency here, but on the other hand there may not be". Somewhere else
there may be a declaration that resolves the apparent inconsistency (e.g., a
declaration to the effect that "a Corporation is a (legal) Person").
Moreover, depending on how the application interprets the property
descriptions, a description of an instance might be considered valid either
without some of the schema-specified properties (e.g., there might
be an instance of ex:Book without an ex:author
property, even if ex:author is described as having a domain of
ex:Book), or with additional properties (there might be
an instance of ex:Book with an ex:technicalEditor
property, even though the schema describing class ex:Book does
not describe such a property).
In other words, statements in an RDF schema are always
descriptions. They may also be prescriptive (introduce
constraints), but only if the application interpreting those statements wants
to treat them that way. All RDF Schema does is provide a way of stating this
additional information. Whether this information conflicts with explicitly
specified instance data is up to the application to determine and act upon.
RDF Schema provides a number of other built-in properties, which can be
used to provide documentation and other information about an RDF schema or
about instances. For example the rdfs:comment property can be
used to provide a human-readable description of a resource. The
rdfs:label property can be used to provide a more human-readable
version of a resource's name. The rdfs:seeAlso property can be
used to indicate a resource that might provide additional information about
the subject resource. The rdfs:isDefinedBy property is a
subproperty of rdfs:seeAlso, and can be used to indicate a
resource that (in a sense not specified by RDF; e.g., the resource may not be
an RDF schema) "defines" the subject resource. RDF Vocabulary Description Language
1.0: RDF Schema [RDF-VOCABULARY] should
be consulted for further discussion of these properties.
As with a number of the built-in RDF properties such as
rdf:value, the uses described for these RDF Schema properties
are only their intended uses. [RDF-SEMANTICS] defines no special meanings for
these properties, and RDF Schema does not define any constraints based on
these intended uses. For example, there is no constraint specified that the
object of a rdfs:seeAlso property must provide
additional information about the subject of the statement in which it
appears.
RDF Schema provides basic capabilities for describing RDF vocabularies,
but additional capabilities are also possible, and can be useful. These
capabilities may be provided through further development of RDF Schema, or in
other languages based on RDF. Other richer schema capabilities that have been
identified as useful (but that are not provided by RDF Schema) include:
- cardinality constraints on properties, e.g., that a Person has
exactly one biological father.
- specifying that a given property (such as
ex:hasAncestor)
is transitive, e.g., that if A ex:hasAncestor B,
and B ex:hasAncestor C, then A ex:hasAncestor
C.
- specifying that a given property is a unique identifier (or
key) for instances of a particular class.
- specifying that two different classes (having different URIrefs)
actually represent the same class.
- specifying that two different instances (having different URIrefs)
actually represent the same individual.
- specifying constraints on the range or
cardinality of a property that depend on the class of resource to which a
property is applied, e.g., being able to say that for a soccer team the
ex:hasPlayers property has 11 values, while for a basketball
team the same property should have only 5 values.
- the ability to describe new classes in terms of combinations (e.g.,
unions and intersections) of other classes, or to say that two classes
are disjoint (i.e., that no resource is an instance of both classes).
The additional capabilities mentioned above, in addition to others, are
the targets of ontology languages such as DAML+OIL [DAML+OIL] and OWL [OWL].
Both these languages are based on RDF and RDF Schema (and both currently
provide all the additional capabilities mentioned above). The intent of such
languages is to provide additional machine-processable semantics for
resources, that is, to make the machine representations of resources more
closely resemble their intended real world counterparts. While such
capabilities are not necessarily needed to build useful applications using
RDF (see Section 6 for a description of a number
of existing RDF applications), the development of such languages is a very
active subject of work as part of the development of the Semantic Web.
6. Some RDF
Applications: RDF in the Field
The previous sections have described the general capabilities of RDF and
RDF Schema. While examples were used in those sections to illustrate those
capabilities, and some of those examples may have suggested potential RDF
applications, those sections did not actually discuss any real
applications. This section will describe some actual deployed RDF
applications, showing how RDF supports various real-world requirements to
represent and manipulate information about a wide variety of things.
Metadata is data about data. Specifically, the term
refers to data used to identify, describe, or locate information resources,
whether these resources are physical or electronic. While structured metadata
processed by computers is relatively new, the basic concept of metadata has
been used for many years in helping manage and use large collections of
information. Library card catalogs are a familiar example of such metadata.
The Dublin Core is a set of "elements" (properties) for describing
documents (and hence, for recording metadata). The element set was originally
developed at the March 1995 Metadata Workshop in Dublin, Ohio. The Dublin
Core has subsequently been modified on the basis of later Dublin Core
Metadata workshops, and is currently maintained by the Dublin Core Metadata Initiative. The goal
of the Dublin Core is to provide a minimal set of descriptive elements that
facilitate the description and the automated indexing of document-like
networked objects, in a manner similar to a library card catalog. The Dublin
Core metadata set is intended to be suitable for use by resource discovery
tools on the Internet, such as the "Webcrawlers" employed by popular World
Wide Web search engines. In addition, the Dublin Core is meant to be
sufficiently simple to be understood and used by the wide range of authors
and casual publishers who contribute information to the Internet. Dublin Core
elements have become widely used in documenting Internet resources (the
Dublin Core creator element has already been used in earlier
examples). The current elements of the Dublin Core are defined in the Dublin Core Metadata
Element Set, Version 1.1: Reference Description [DC], and contain definitions for the following
properties:
- Title: A name given to the resource.
- Creator: An entity primarily responsible for making
the content of the resource.
- Subject: The topic of the content of the resource.
- Description: An account of the content of the
resource.
- Publisher: An entity responsible for making the
resource available
- Contributor: An entity responsible for making
contributions to the content of the resource.
- Date: A date associated with an event in the life
cycle of the resource.
- Type: The nature or genre of the content of the
resource.
- Format: The physical or digital manifestation of the
resource.
- Identifier: An unambiguous reference to the resource
within a given context.
- Source: A reference to a resource from which the
present resource is derived.
- Language: A language of the intellectual content of
the resource.
- Relation: A reference to a related resource.
- Coverage: The extent or scope of the content of the
resource.
- Rights: Information about rights held in and over the
resource.
Information using the Dublin Core elements may be represented in any
suitable language (e.g., in HTML meta elements). However, RDF is
an ideal representation for Dublin Core information. The examples below
represent the simple description of a set of resources in RDF using the
Dublin Core vocabulary. Note that the specific Dublin Core RDF vocabulary
shown here is not intended to be authoritative. The Dublin Core Reference
Description [DC] is the authoritative
reference.
The first example, Example 21,
describes a Web site home page using Dublin Core properties:
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>.
@prefix dc: <http://purl.org/dc/elements/1.1/>.
<http://www.dlib.org>
dc:title "D-Lib Program - Research in Digital Libraries";
dc:description """The D-Lib program supports the community of people
with research interests in digital libraries and electronic
publishing.""";
dc:publisher: "Corporation For National Research Initiatives";
dc:date "1995-01-07";
dc:subject [
a rdf:Bag;
rdf:_1 "Research; statistical methods";
rdf:_2 "Education, research, related topics";
rdf:_3 "Library use Studies".
];
dc:type "World Wide Web Home Page";
dc:format "text/html";
dc:language "en".
Note that both RDF and the Dublin Core define an (XML) element called
"Description" (although the Dublin Core element name is written in
lowercase). Even if the initial letter were identically uppercase, the XML
namespace mechanism enables these two elements to be distinguished (one is
rdf:Description, and the other is dc:description).
Also, as a matter of interest, accessing http://purl.org/dc/elements/1.1/
(the namespace URI used to identify the Dublin Core vocabulary in this
example) in a Web browser (as of the current writing) will retrieve an RDF
Schema declaration for [DC].
The second example, Example 22,
describes a published magazine:
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>.
@prefix dc: <http://purl.org/dc/elements/1.1/>.
@prefix dcterms: <http://purl.org/dc/terms/>.
<http://www.dlib.org/dlib/may98/05contents.html>
dc:title "DLIB Magazine - The Magazine for Digital Library Research - May 1998";
dc:description """D-LIB magazine is a monthly compilation of
contributed stories, commentary, and briefings.""";
dc:contributor "Amy Friedlander";
dc:publisher "Corporation for National Research Initiatives";
dc:date "1998-01-05";
dc:type "electronic journal";
dc:subject [
a rdf:Bag;
rdf:_1 "library use studies";
rdf:_2 "magazines and newspapers".
];
dc:format "text/html";
dc:identifier <urn:issn:1082-9873>;
dcterms:isPartOf <http://www.dlib.org>.
Example 22 uses (in the last line)
the Dublin Core qualifier isPartOf (from a separate
vocabulary) to indicate that this magazine is
"part of" the previously-described Web site.
The third example, Example 23,
describes a specific article in the magazine described in Example 22.
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>.
@prefix dc: <http://purl.org/dc/elements/1.1/>.
@prefix dcterms: <http://purl.org/dc/terms/>.
<http://www.dlib.org/dlib/may98/miller/05miller.html>
dc:title "An Introduction to the Resource Description Framework";
dc:creator "Eric J. Miller";
dc:description
"""The Resource Description Framework (RDF) is an
infrastructure that enables the encoding, exchange and reuse of
structured metadata. rdf is an application of xml that imposes needed
structural constraints to provide unambiguous methods of expressing
semantics. rdf additionally provides a means for publishing both
human-readable and machine-processable vocabularies designed to
encourage the reuse and extension of metadata semantics among
disparate information communities. the structural constraints rdf
imposes to support the consistent encoding and exchange of
standardized metadata provides for the interchangeability of separate
packages of metadata defined by different resource description
communities.""";
dc:publisher "Corporation for National Research Initiatives";
dc:subject [
a rdf:Bag;
rdf:_1 "machine-readable catalog record formats";
rdf:_2 "applications of computer file organization and access methods".
];
dc:rights "Copyright © 1998 Eric Miller";
dc:type "Electronic Document";
dc:format "text/html";
dc:language "en";
dcterms:isPartOf <http://www.dlib.org/dlib/may98/05contents.html>.
Example 23 also uses the qualifier
isPartOf, this time to indicate that this article is "part of"
the previously-described magazine.
PRISM: Publishing Requirements for
Industry Standard Metadata [PRISM] is a metadata
specification developed in the publishing industry. Magazine publishers and
their vendors formed the PRISM Working Group to identify the industry's needs
for metadata and define a specification to meet them. Publishers want to use
existing content in many ways in order to get a greater return on the
investment made in creating it. Converting magazine articles to HTML for
posting on the Web is one example. Licensing it to aggregators like LexisNexis is another. All of these are
"first uses" of the content; typically they all go live at the time the
magazine hits the stands. The publishers also want their content to be
"evergreen". It might be used in new issues, such as in a retrospective
article. It could be used by other divisions in the company, such as in a
book compiled from the magazine's photos, recipes, etc. Another use is to
license it to outsiders, such as in a reprint of a product review, or in a
retrospective produced by a different publisher. This overall goal requires a
metadata approach that emphasizes discovery, rights
tracking, and end-to-end metadata.
Discovery: Discovery is a general term for finding content which
encompasses searching, browsing, content routing, and other techniques.
Discussions of discovery frequently center on a consumer searching a public
Web site. However, discovering content is much broader than that. The
audience may consist of consumers, or it may consist of internal users such
as researchers, designers, photo editors, licensing agents, etc. To assist
discovery, PRISM provides properties to describe the topics, formats, genre,
origin, and contexts of a resource. It also provides means for categorizing
resources using multiple subject description taxonomies.
Rights Tracking: Magazines frequently contain material licensed
from others. Photos from a stock photo agency are the most common type of
licensed material, but articles, sidebars, and all other types of content may
be licensed. Simply knowing if content was licensed for one-time use,
requires royalty payments, or is wholly-owned by the publisher is a struggle.
PRISM provides elements for basic tracking of such rights. A separate
vocabulary defined in the PRISM specification supports description of places,
times, and industries where content may or may not be used.
End-to-end metadata: Most published content already has metadata
created for it. Unfortunately, when content moves between systems, the
metadata is frequently discarded, only to be re-created later in the
production process at considerable expense. PRISM aims to reduce this problem
by providing a specification that can be used in multiple stages in the
content production pipeline. An important feature of the PRISM specification
is its use of other existing specifications. Rather than create an entirely
new thing, the group decided to use existing specifications as much as
possible, and only define new things where needed. For this reason, the PRISM
specification uses XML, RDF, Dublin Core, and well as various ISO formats and
vocabularies.
A PRISM description may be as simple as a few Dublin Core
properties with plain literal values. Example 24
describes a photograph, giving basic information on its title, photographer,
format, etc.
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>.
@prefix dc: <http://purl.org/dc/elements/1.1/>.
<http://travel.example.com/2000/08/Corfu.jpg>
dc:title "Walking on the Beach in Corfu";
dc:description "Photograph taken at 6:00 am on Corfu with two models";
dc:creator "John Peterson";
dc:contributor "Sally Smith, lighting";
dc:format "image/jpeg".
PRISM also augments the Dublin Core to allow more detailed descriptions.
The augmentations are defined as three new
vocabularies, generally cited using the prefixes prism:,
pcv:, and prl:.
prism: This prefix refers to the main PRISM vocabulary, whose terms use the URI prefix
http://prismstandard.org/namespaces/basic/1.0/ . Most of
the properties in this vocabulary are more specific versions of properties
from the Dublin Core. For example, more specific versions of
dc:date are provided by properties like
prism:publicationTime, prism:releaseTime,
prism:expirationTime, etc.
pcv: This prefix refers to the PRISM Controlled Vocabulary
(pcv) vocabulary, whose terms use the URI prefix
http://prismstandard.org/namespaces/pcv/1.0/ . Currently,
common practice for describing the subject(s) of an article is by supplying
descriptive keywords. Unfortunately, simple keywords do not make a great
difference in retrieval performance, due to the fact that different people
will use different keywords [BATES96]. Best
practice is to code the articles with subject terms from a "controlled
vocabulary". The vocabulary should provide as many synonyms as possible for
its terms in the vocabulary. This way the controlled terms provide a meeting
ground for the keywords supplied by the searcher and the indexer. The pcv
vocabulary provides properties for specifying terms in a vocabulary, the
relations between terms, and alternate names for the terms.
prl: This prefix refers to the PRISM Rights Language vocabulary, whose terms use the URI prefix
http://prismstandard.org/namespaces/prl/1.0/ . Digital
Rights Management is an area undergoing considerable upheaval. There are a
number of proposals for rights management languages, but none are clearly
favored throughout the industry. Because there was no clear choice to
recommend, the PRISM Rights Language (PRL) was defined as an interim measure.
It provides properties which let people say if an item can or cannot be
"used", depending on conditions of time, geography, and industry. This is
believed to be an 80/20 trade-off which will help publishers begin to save
money when tracking rights. It is not intended to be a general rights
language, or allow publishers to automatically enforce limits on consumer
uses of the content.
PRISM uses RDF because of its abilities for dealing with descriptions of
varying complexity. Currently, a great deal of metadata uses simple character
string (plain literal) values, such as:
Over time the developers of PRISM expect uses of the PRISM specification
to become more sophisticated, moving from simple literal values to more
structured values. In fact, that range of values is a situation being faced
now. Some publishers already use sophisticated controlled vocabularies,
others are barely using manually-supplied keywords. To illustrate this, some
examples of the different kinds of values that can be given for the
dc:coverage property are:
dc:coverage "Greece";
dc:coverage <http://prismstandard.org/vocabs/ISO-3166/GR>;
(i.e., using either a plain literal or a URIref to identify the country)
and
dc:coverage <http://prismstandard.org/vocabs/ISO-3166/GR>.
<http://prismstandard.org/vocabs/ISO-3166/GR> rdf:type pcv:Descriptor;
<http://prismstandard.org/vocabs/ISO-3166/GR> pcv:label "Greece"@en;
<http://prismstandard.org/vocabs/ISO-3166/GR> pcv:label "Grèce"@fr.
(using a structured value to provide both a URIref and names in various
languages).
Note also that there are properties whose meanings are similar, or subsets
of other properties. For example, the geographic subject of a resource could
be given with
prism:subject "Greece";
dc:coverage "Greece";
or
Any of those properties might use the simple literal value, or a more
complex structured value. Such a range of possibilities cannot be adequately
described by DTDs, or even by the newer XML Schemas. While there is a wide
range of syntactic variations to deal with, RDF's graph model has a simple
structure - a set of triples. Dealing with the metadata in the triples domain
makes it much easier for older software to accommodate content with new
extensions.
This section closes with two final examples. Example 25 says that the image
(.../Corfu.jpg) cannot be used (#none) in the
tobacco industry (code 21 in SIC, the Standard Industrial Classifications).
@prefix prism: <http://prismstandard.org/namespaces/basic/1.0/>.
@prefix prl: <http://prismstandard.org/namespaces/prl/1.0/>.
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>.
@prefix dc: <http://purl.org/dc/elements/1.1/>.
<http://travel.example.com/2000/08/Corfu.jpg>
dc:rights [
prl:usage <http://prismstandard.org/vocabularies/1.0/usage.xml#none>;
prl:industry <http://prismstandard.org/vocabs/SIC/21>.
].
Example 26 says that the
photographer for the Corfu image was employee 3845, better known as John
Peterson. It also says that the geographic coverage of the photo is Greece.
It does so by providing, not just a code from a controlled vocabulary, but a
cached version of the information for that term in the vocabulary.
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>.
@prefix pcv: <http://prismstandard.org/namespaces/pcv/1.0/>.
@prefix dc: <http://purl.org/dc/elements/1.1/>.
</2000/08/Corfu.jpg>
dc:identifier <http://travel.example.com/content/2357845> ;
dc:creator <http://travel.example.com/content/2357845> ;
dc:coverage <http://prismstandard.org/vocabs/ISO-3166/GR>.
</content/2357845> a pcv:Descriptor;
pcv:label "John Peterson".
<http://prismstandard.org/vocabs/ISO-3166/GR>
pcv:label "Greece"@en;
pcv:label "Grèce"@fr.
Appendix A: More
on Uniform Resource Identifiers (URIs)
Note: This section is intended to provide a brief
introduction to URIs. The definitive specification of URIs is RFC 2396 [URIS], which should be consulted for further details.
Additional discussion of URIs can also be found in Naming and Addressing: URIs, URLs,
... [NAMEADDRESS].
As discussed in Section 2.1, the Web provides
a general form of identifier, called the Uniform Resource
Identifier (URI), for identifying (naming) resources on the Web. Unlike
URLs, URIs are not limited to identifying things that have network locations,
or use other computer access mechanisms. A number of different URI
schemes (URI forms) have been already been developed, and are being
used, for various purposes. Examples include:
http: (Hypertext Transfer Protocol, for Web pages) mailto: (email addresses), e.g.,
mailto:em@w3.org ftp: (File Transfer Protocol) urn: (Uniform Resource Names, intended to be persistent
location-independent resource identifiers), e.g.,
urn:isbn:0-520-02356-0 (for a book)
A list of existing URI schemes can be found in Addressing Schemes [ADDRESS-SCHEMES], and it is a good idea to
consider adapting one of the existing schemes for any specialized
identification purposes, rather than trying to invent a new one.
No one person or organization controls who makes URIs or how they can be
used. While some URI schemes, such as URL's http:, depend on
centralized systems such as DNS, other schemes, such as
freenet:, are completely decentralized. This means that, as with
any other kind of name, no one needs special authority or permission to
create a URI for something. Also, anyone can create URIs to refer to things
they do not own, just as in ordinary language anyone can use whatever name
they like for things they do not own.
As also noted in Section 2.1, RDF uses
URI references [URIS] to name subjects,
predicates, and objects in RDF statements. A URI reference (or
URIref) is a URI, together with an optional fragment
identifier at the end. For example, the URI reference
http://www.example.org/index.html#section2 consists of the URI
http://www.example.org/index.html and (separated by the "#"
character) the fragment identifier Section2. RDF URIrefs can
contain Unicode [UNICODE] characters (see [RDF-CONCEPTS]), allowing many languages to be
reflected in URIrefs.
URIrefs may be either absolute or relative. An
absolute URIref refers to a resource independently of the context in
which the URIref appears, e.g., the URIref
http://www.example.org/index.html. A relative URIref is
a shorthand form of an absolute URIref, where some prefix of the URIref is
missing, and information from the context in which the URIref appears is
required to fill in the missing information. For example, the relative URIref
otherpage.html, when appearing in a resource
http://www.example.org/index.html, would be filled out to the
absolute URIref http://www.example.org/otherpage.html. A URIref
without a URI part is considered a reference to the current document (the
document in which it appears). So, an empty URIref within a document is
considered equivalent to the URIref of the document itself. A URIref
consisting of just a fragment identifier is considered equivalent to the
URIref of the document in which it appears, with the fragment identifier
appended to it. For example, within
http://www.example.org/index.html, if #section2
appeared as a URIref, it would be considered equivalent to the absolute
URIref http://www.example.org/index.html#section2.
[RDF-CONCEPTS] notes that RDF graphs (the
abstract models) do not use relative URIrefs, i.e., the subjects, predicates,
and objects (and datatypes in typed literals) in RDF statements must always
be identified independently of any context. However, a specific concrete RDF
syntax, such as RDF/XML or Turtle, may allow relative URIrefs to be used as a
shorthand for absolute URIrefs in certain situations. Turtle does permit such
use of relative URIrefs, and some of the Turtle examples in this Primer
illustrate such uses. [TURTLE] should be consulted
for further details.
Both RDF and Web browsers use URIrefs to identify things. However, RDF and
browsers interpret URIrefs in slightly different ways. This is because RDF
uses URIrefs only to identify things, while browsers also use
URIrefs to retrieve things. Often there is no effective difference,
but in some cases the difference can be significant. One obvious difference
is that when a URIref is used in a browser, there is the expectation that it
identifies a resource that can actually be retrieved: that something is
actually "at" the location identified by the URI. However, in RDF a URIref
may be used to identify something, such as a person, that cannot be
retrieved on the Web. People sometimes use RDF together with a convention
that, when a URIref is used to identify an RDF resource, a page containing
descriptive information about that resource will be placed on the Web "at"
that URI, so that the URIref can be used in a browser to retrieve that
information. This can be a useful convention in some circumstances, although
it creates a difficulty in distinguishing the identity of the original
resource from the identity of the Web page describing it (a subject discussed
further in Section 2.3). However, this
convention is not an explicit part of the definition of RDF, and RDF itself
does not assume that a URIref identifies something that can be retrieved.
Another difference is in the way URIrefs with fragment identifiers are
handled. Fragment identifiers are often seen in the URLs that identify HTML
documents, where they serve to identify a specific place within the document
identified by the URL. In normal HTML usage, where URI references are used to
retrieve the indicated resources, the two URIrefs:
http://www.example.org/index.html
http://www.example.org/index.html#Section2
are related (they both refer to the same document, the second one
identifying a location within the first one). However, as noted already, RDF
uses URI references purely to identify resources, not to retrieve
them, and RDF assumes no particular relationship between these two URIrefs.
As far as RDF is concerned, they are syntactically different URI references,
and hence may refer to unrelated things. This does not mean that the
HTML-defined containment relationship might not exist, just that RDF does not
assume that a relationship exists based only on the fact that the URI parts
of the URI references are the same.
Carrying this point further, RDF does not assume that there is any
relationship between URI references that share a common leading string,
whether there is a fragment identifier or not. For example, as far as RDF is
concerned, the two URIrefs:
http://www.example.org/foo.html
http://www.example.org/bar.html
have no particular relationship even though both of them start with the
string http://www.example.org/. To RDF, they are simply
different resources, because their URIrefs are different. (They may in fact
be two files located in the same directory, but RDF does not assume this or
any other relationship exists.)