Overview
- W3C's Technical Architecture Group (TAG)
- Overview of Architecture of the World Wide Web
- Architecture Review of US Patent Office Web Site
W3C's Technical Architecture Group
W3C's Technical Architecture
Group was chartered in 2001:
"to document and build consensus around principles of Web
architecture and to interpret and clarify these principles when
necessary."
Roles: write, coordinate, mediate
TAG Participants
TAG participants elected and appointed at our September 2002
meeting in Vancouver:
- Norman Walsh, Sun Microsystems. Docbook guy
- Paul Cotton, Microsoft. fulltext industry
- Chris Lilley, W3C. SVG lead
- David Orchard, BEA. Web Services.
- Roy Fielding. HTTP spec editor. REST thesis
- Tim Berners-Lee, W3C Director
- Stuart Williams, HP
- Dan Connolly, W3C
- Tim Bray, Sun. XML 1.0 co-editor
- Ian Jacobs, W3C. Tech writer
TAG Participants, all dressed up
- Henry Thompson, W3C and U. Edinburgh. XML Schema editor
- Norman Walsh
- David Orchard
- Vincent Quint, INRIA
- Tim Berners-Lee
- Dan Connolly
- Roy Fielding
- Noah Mendelsohn, IBM
Why an Architecture Document?
- To distill ten years of experience with the hypertext Web
- To help developers of Web technologies avoid pitfalls
- To provide guidance to users, site managers, software designers
on promoting a robust Web
- To build consensus around concepts and terms
- To learn humility...
Community Brings Issues to TAG
Teleconference and mailing list discussions ensue.
TAG Explores Problem Space
What makes HTTP GET important?
- HTTP GET designed so that URI alone encodes interaction; allows linking
- Safe/unsafe distinction in protocol enables user agent
support
- Requests with no side-effects enable caching of results:
- At global networking scale, require fast data exchange
- Use caching to improve performance (see HTTP/1.1
study)
- Design protocols that support caching
8 Apr 2002: Dan Connolly receives
assignment to write strawman proposal. This evolves into
a draft finding.
TAG Coordinates to Build Consensus
Groups Document Consensus
Ongoing: Marking safe operations in WSDL
Negotiation tactics
- March 2004: TAG struggling to get webarch document done
- Dan was more optimistic than Paul Cotton:
Let the record show that PC and DC have bet a dinner that at this rate we won't (PC) or we will (DC) get to Recommendation by 2005.
W3C Tag meeting notes March 2004
It's a REC! Party!

- December 15: with a week or two to spare, W3C issued webarch as a Recommendation. (with press release and all)
- Paul graciously conceded the bet
- Connolly family dines on Paul's nickel
What type of information is in the Architecture Document,
Findings?
- Properties we desire of the Web, and
- Design choices to achieve them.
Example related to previous issue:
- Principles, Constraints, Good Practice Notes
-
- Agents do not incur obligations by retrieving a representation
("GET is safe").
- Rationale
-
- Benefits of URI addressability: linking, bookmarking,
caching
- Benefits of distinction in protocols of safe/unsafe: user
agent alerts, caching
- Stories and examples
-
- Examples of safe (lookup) and unsafe (credit card purchase) interactions
- Considerations for sensitive data
- Practical considerations, ephemeral limitations
Architecture Tripod
- Identification
- Interaction
- Representation
Identification I: Why URIs?
Value of common syntax for global identifiers:
"Great multiplicative power of reuse derives from the fact that all
languages use URIs as identifiers: This allows things written in one
language to refer to things defined in another language. The use of
URIs allows a language to leverage the many forms of persistence,
identity, and various forms of equivalence."
-- URIs, Addressability, and the use of HTTP GET and POST
- Power in the network effect.
- Extension through URI schemes
Identification II: URI Usage
- Comparison. Key to Semantic Web, caches
- Dereference. Discussed below in Interactions
Due to global scope, URIs also used outside of Web protocols (e.g.,
as database keys).
Interaction I: Dereferencing a URI
- Communication between agents involves URIs, messages, data
- Dereference a URI, get back a representation of resource state
- Representation consists of representation data
and metadata (e.g., Internet Media Type).
Interaction II: Dereferencing a URI (illustration)
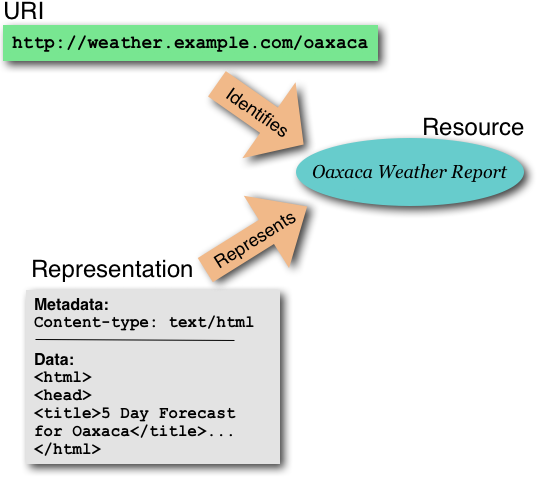
Interaction III: Managing Representations
- Internet Media Type
- Representations evolve over time as resource, technology
evolves
- Consistency in representation increases trust in URI
- Content negotiation facilitates evolution
- Fragment identifier semantics and content negotiation
Interaction IV: Issues Raised by Interaction
- Safe, unsafe interactions
- Sensitive data
- Access control independent of identification (cf. Deep
Linking Finding)
- Metadata from representation provider authoritative.
Other behavior ok, but requires transparency for user.
Representation: Data formats
- Data formats used to organize representation data
- Data format considerations: binary v. text, extensibility,
versioning, composition, modularization
- Hypertext
- XML-based data formats: links, namespaces, qnames, media types
Architecture Review of US Patent Office Web Site
Review of the United States
Patent and Trademark Office revealed:
- HTTP GET used for database lookup (good)
- HTTP GET used for unsafe interactions (not good)
- URI for patent is actually URI for search (not optimal)
- POST used to protect sensitive login data (design choice)
HTTP GET used for database lookup
HTML "GET" form used for database
lookup:
<form action="/netacgi/nph-Parser" method="GET">
Use GET for queries, searches, database lookups.
HTTP GET used for unsafe interactions (not good)
Modifying state of shopping cart is unsafe since produces
side-effect:
- Search
with keyword "hypertext"
- Select Patent 6,678,889: "Systems, methods and
computer program ...."
- Add to cart, view "Quantity" (1)
- Hit back button, add to cart, view "Quantity" (2)
"Add to Cart" an HTML link:
<a href=".../AddToShoppingCart?docNumber=6,678,889...">...
I cannot link to shopping cart from this slide; a search engine or
pre-fetching agent might increment counter (cf. SVG 1.2, section 11.8.
In HTML, use "POST" form for unsafe operations.
URI for patent is actually URI for search (not optimal)
What might a URI for a patent look like?
http://www.uspto.gov/patents/p6678889
Note that this is globally unambiguous; better than "6678889"
Search produced this URI for search on "hypertext":
http://patft.uspto.gov/...s1=hypertext&OS=hypertext...
Search produced this URI for search by patent number 6,678,899:
http://patft.uspto.gov/...s1=6,678,889.WKU....
Why are these URIs different if this is the same patent?
Cost of Arbitrarily Different URIs
At first, I thought these URIs were arbitrarily different
URIs for the same resource. If so, machines cannot
compare reliably, so:
- Interferes with caching
- Semantic Web does not work
- Site management more complex
Identify Results of Search, not Search
Resource only indirectly identified as query result.
- My expectation is not to bookmark search, but result of search
- Search might return different results another day; I want to
refer to the patent.
Related in Architecture Document:
- Avoid URI ambiguity.
- Publishers of a URI SHOULD provide representations of the
identified resource consistently and predictably.
- URI persistence
POST used to protect sensitive login data (design choice)
- GET allows URIs (bookmarking, back button), but
we don't want sensitive data in URI.
- Choices include:
- GET with HTTP Basic Authentication over SSL: Sensitive
data in HTTP headers, so allows bookmarking. User agent
manages passwords.
- POST over SSL
- However, cost to SSL as well
Think about these architecture issues, tradeoffs during design!
See URIs,
Addressability, and the use of HTTP GET and POST
Questions?
For more info:

