
WebID Definition/hash
Note that this page has been forked, and edits have been made to both since that forking... For full context, it may be best to review both.
WebID Definition
Given that WebID's must refer to Agents, and that they must have an associated profile document, (that returns a default representation) the question here is which of the following restrictions one should have for WebIDs.
A URI is defined by RFC3986 and is constructed as follows:
foo://example.com:8042/over/there?name=ferret#nose
\_/ \______________/\_________/ \_________/ \__/
| | | | |
scheme authority path query fragment
- 1. a WebID MUST be a an http(s) hash uri
- that is scheme MUST be http or https and it must have a fragment identifier
- 2. a WebID MUST be an http(s) URI and SHOULD be an http(s) hash uri
- that is scheme MUST be http or https and it SHOULD have a fragment identifier
- 3. a WebID MUST be an http(s) uri
- that is scheme MUST be http or https
This is in the context of the current WebID definition editors draft.
Use Cases
- a user must be able to move his WebID
- Distinguish WebID and WebID profile
- client efficiency
- the system MUST work with LDP as this will be a major deployment platform for Profile create, editing and publishing
Proposal 1. "A WebID MUST be an HTTP(S) hash (#) URI"
Arguments For Proposal 1
Hash URIs make for easier explanations of WebID Protocols in action
Hash URIs make it easy to explain the difference between the Profile document ( a Information Resource from WebArch ) where the description of the agent resides and the user identifier as in the picture in the spec.
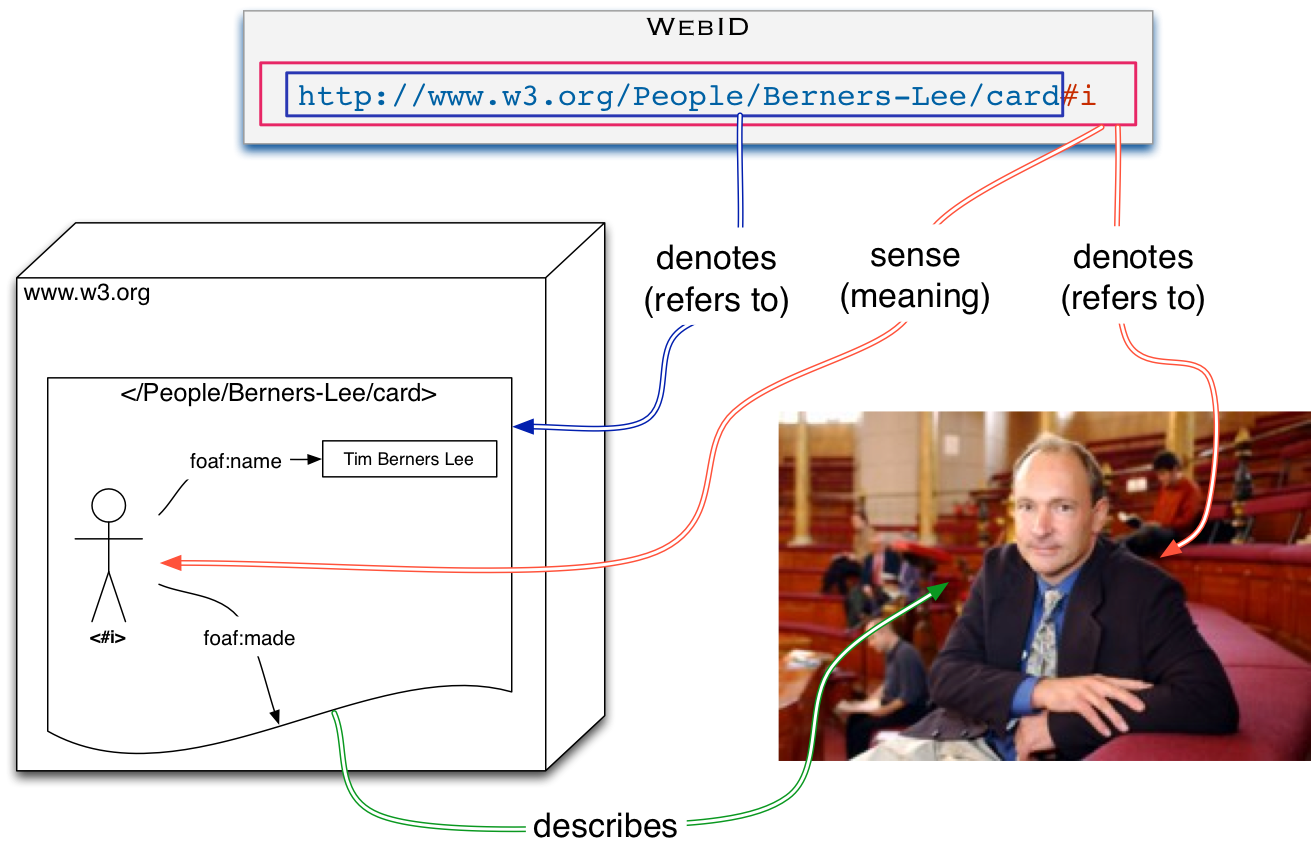{kind=link}
With 303's the job is more difficult, as one has to teach HTTP redirect codes which are not obvious to most users.
Necessary relation between URI and definition
WebID Auth relies on the special relation that exists between a WebID and its Profile document. The document defines the meaning of the WebID. Definitions are known as analytic truths - they are necessarily true by virtue of the document ( they may identify nothing actual, but the document is where the initial meaning is built ). This is why publishing a public key in that document has completely different significance than publishing it elsewhere. This comes out very nicely from the URI spec:
The fragment identifier component of a URI allows indirect identification of a secondary resource by reference to a primary resource and additional identifying information. The identified secondary resource may be some portion or subset of the primary resource, some view on representations of the primary resource, or some other resource defined or described by those representations.
Compare this to Understanding URI Hosting Practice as Support for URI Documentation DiscoveryFor reference, the critical part of [issue-14-resolved] is reproduced below:
- If an "http" resource responds to a GET request with a 2xx response, then the resource identified by that URI is an information resource;
- If an "http" resource responds to a GET request with a 303 (See Other) response, then the resource identified by that URI could be any resource;
- If an "http" resource responds to a GET request with a 4xx (error) response, then the nature of the resource is unknown.
The 303 see Other is not at all as strong a relationship as the definition from the URI spec.
Counterpoint
[kidehen: your comments don't correlate with the conclusions of the TAG findings, as echoed here by TimBL in this excerpt from his post about the history of "R" (for Resource) in URI]:
The spec wasn't changed. The spec editors were not brought on board to the new model. The spec was interpreted. The TAG negotiated in a way a truce between the existing HTTP spec, RDF systems, and people who wanted to use HTTP URIs without "#" to identify people. That truce was HTTPRange-14, which said that you don't a priori know that a hashless HTTP URI denotes a document, but if the server responds with a 200 then you do, and you have a representation of the document. If you did a
GETon one of these new URIs which identified things that were not documents (people, RDF properties, classes, etc) then the server must not return 200, it can return 303 pointing to a document which explains more.
Counterpoint: 200-OK *may* be returned *with* Location: header and representation of *that* document (which is *NOT* the original Request URI), based on Server's best guess of desired result
a hash URI *cannot* be mistaken with an Information resource ( you cannot do a HTTP GET on it )
[ cite rfc http ]
[kidehen: the statement above continues to use flawed conflation to obscure the fact the a #fragment URI is actually about implicit (rather than explicit) indirection (via redirection) re. disambiguation of the Name and Address duality of HTTP URIs. The HTTP approach (irrespective of costs and inconvenience) is about the use of explicit indirection via HTTP itself.]
[kidehen: You can denote anything with a URI. It so happens that you can denote a Web Document using its Web Address/Location -- since URLs are a kind of URI that denote a location of content that also incorporate data access. Likewise, there's no rule that states that an HTTP URI must resolve to anything -- hence its powerful utility as a Naming (denotation) mechanism.]
Issues mentioned by by TAG issue 57
Cachability problem of URI redirections.
TimBL mentions this being a problem for Tabulator, but of course this is a problem for any javascript application, and indeed more generally for any application, since it is part of the HTTP1.1 spec
The 303 response MUST NOT be cached, but the response to the second (redirected) request might be cacheable.
Counterpoint
[kidehen: neither Linked Data, WebID nor the AWWW are about Tabulator or any other product for that matter. There's no news about the challenges posed to the Tabulator extension and Firefox combo. That's too solution specific to be used as an argument against staying with AWWW and TAG findings re., standards that affect other Web-scale Linked Data endeavors.]
Bookmarkability issues
Counterpoint
[kidehen: you don't bookmark the description of a document and the topic of document. You want to bookmark an HTML based DBpedia entity description document? You bookmark THIS. You want to refer to the concept 'Linked Data' by HTTP URI based name, you use THIS. You want to bookmark a DBpedia entity description document in TURTLE format you bookmark THIS. ]
Deployment complexity =
Counterpoint
[kidehen: that has nothing to do with the basis for defining something that serves the purpose defining an HTTP URI that denotes an entity. ]
extra connection required in fetching the resource for 303 redirects
Counterpoint
[kidehen: the definition of WebID has nothing to do with engineering choices. ]
HashlessURI are problematic for LDP
What would it mean to:
- to PATCH such a resource?
- to DELETE it?
- how would one create such a resource in an LDP Collection?
[kidehen: LDP references are irrelevant unless this is WebID-for-LDP or LDP-WebID etc.. ]
the relationship between hashless and hash URIs is known/intuitive to all Web devs I know, not true for HTTP Redirects
Counterpoint
[kidehen: as per my comments above, because (as per usual) via conflation, we are hiding the real issue of dereference and indirection. ]
avoid relying on HTTP Redirects
Counterpoint
[kidehen: redirects are irrelevant. All that matters is the retrieved profile content (an entity description graph) and the ability to use a variety of protocols to verify the subject of said graph. That's what some of us actually thought this was about re. clever exploitation of existing standards.]
Arguments Against Proposal 1
Restrictions on 303s
[Stéphane Corlosquet] Given the current spec, hash URIs come with a restriction on basic 303 redirects, that means that when people change the location of their WebID profile (be it hash or hashless), they cannot rely on redirect to keep their existing WebID, and will have to regenerate a certificate for all their browsers and all their devices. The restriction on 303s in section 5:
HTTP 303 redirects should be avoided (needs further discussion). Since WebIDs contain a URI fragment identifier, it is not necessary to use HTTP 303 redirects in order to make the difference between the identifier and the document it points to; the relationship becomes obvious.
[Kingsley Idehen] a +1 for the above point
Hashed URI confuses description data with the document containing it
A hash based HTTP URI provides the simplicity of implicit Name (URI) ->Address (URL) indirection, but adds the cost of description data conflation with regards to what's returned. For instance, a hash based HTTP URI resolves to a description of two distinct entities (a document and the entity described by the document) whereas a hash-less URI can resolve directly to a specific entity description.
discussion
- bblfish: that seems wrong to me. A 303 redirect gives you 2 HTTP requests, the second of which returns a document - so you don't have anything direct.
- kidehen: it seems correct to me. I have the ability to dereference an HTTP URI that returns an RDF graph that only describes the referent of the hashless URI. I don't have the additional RDF data that serves to describe a document. The subject of a document is one entity. The document describing the subject is another entity.
- bblfish: so the problem with larger vocabularies like foaf is that you if you want to know for each foaf vocab element (eg foaf:knows, foaf:Person, foaf:mbox...) where it is defined you have to do an HTTP GET on it
- bblfish: also you could have done the same with #uris. You could have a redirect for each defining document to one big document if you really need that indirection. So say you have abstract entities such as <http://ont.eg/knows#k> and <http://ont.eg/Person#k>, you could have <http://ont.eg/knows> and <http://ont.eg/Person> redirect to <http://ont.eg/ont>
By defining a WebID to be a hash-based we put a lot of semantics into a single character where the most important parts are that an entity is described in a standardized way.
[Jürgen Jakobitsch] Two identical => descriptions <= of a real world entity are treated differently if webid.toString().indexOf("#") is -1 or > 0. That what's interesting for the verifier is not the uri-string, but the description of an entity. In other words a verifier must judge the graph not (only) by the triples it contains, but also by a certain character in the subject's uri.
Widely deployed certificate evaluators mis-handle SANs including #, breaking otherwise trivially documented demonstration usage patterns
[Ted Thibodeau] The Keychain Access.app in Mac OS X takes any SAN that includes a #, and visually presents it correctly ( see picture). But when you click on that URI (the textual string of which you cannot select and copy), your browser loads the URI with %23 in place of the # -- e.g., Keychain Access.app displays http://twitter.com/TallTed#this locally, but when I click it, my browser (observed with both Firefox and Safari; no reason to think any other would behave differently) tries to load http://twitter.com/TallTed%23this -- which correctly 404s. Now, this is clearly a bug in Mac OS X and/or Keychain Access.app -- but this is a very widely deployed tool which demonstrates the folly of forcing a particular URI pattern for WebID. (This is an argument against both MUST for hash-URI.)
{kind=link}
Counterpoint
- [bblfish] Please report this bug to Apple ( if you have an Apple Dev Account do it here. If you believe in the meaning of MUST then clearly they have a problem with a well known specs' MUST.
- [bblfish] This is easily solved by using redirects: if someone clicks on the http://twitter.com/TallTed%23this redirect them to http://twitter.com/TallTed
Proposal 2. MUST be an HTTP(S) URI and SHOULD be an HTTP(s) hash (#) URI
- Quoting from RFC2119
SHOULD This word, or the adjective "RECOMMENDED", mean that there may exist valid reasons in particular circumstances to ignore a particular item, but the full implications must be understood and carefully weighed before choosing a different course.
WebID definition spec with proposed changes (Stéphane Corlosquet).
Arguments For Proposal 2
It promotes the simplest solution avoiding issues described in TAG 57 , but allows us to live with legacy issues
It allows us to have a simple explanation without needing to go into the complexity of RDF Deployment
It fosters interoperability
- LDP servers - it is the only way to publish things there
- javascript clients like the tabulator, that work from within the browser and need to keep track of where data comes from, and be responsive
- Nathan has a detailed overview of the problem space that at least allows for SHOULD as an option
Arguments Against Proposal 2
SHOULD allows room for interpretation, leading to people minting a WebID in the form of http://example.com/bob/secretary
[Andrei Sambra] At this point, one needs to rely on 303 redirects to get the WebID profile, which means having to specify in the spec how many 303 redirects we are going to allow. Do we allow one or more? How many more? By using SHOULD, we can also imagine people implementing 301 as well. If all this is not specified in the spec, we will have compatibility issues in TLS authentication for example.
Counterpoint: Web architecture imposes no restriction on number of redirects, and HTTP clients must handle them. WebID should not impose such restriction.
I can't parse the argument(s) out of the remaining commentary...
Alexandre Bertails
- here is what I read with this proposal: "we rely on HTTP uris, but we know that there is this http-range-14 issue, so we invite you to fix it by using hash URIs, but if you don't want to do that, then you can use HTTP 303". This basically doesn't solve anything, just introduce confusion.
- a MUST sets the *minimal set of expectations*, and helps achieving interoperability. I'd be open for something like "MUST be a an HTTP(s) hash (#) URI, MAY be a hashless HTTP uri for legacy reasons". I would add "HTTP 303 SHOULD be avoided". But if we enter this dance, we would have to explain all these different scenarios and that would make the spec much more difficult to explain and sell.
Proposal 3. A WebID MUST be an HTTP(S) URI (saying nothing about hashed or hasless)
WebID definition spec with proposed changes (diff) (Stéphane Corlosquet).
Arguments For Proposal 3
Hash URIs or 303 redirects are implementation details that the TAG is working on.
[Stéphane Corlosquet:] I strongly encourage hash URIs because they make life easier, but I just don't see the need to mandate it in the spec. Hash URIs should be used in all examples so that people are not tempted to mint of kinds of URIs. The TAG is working on possibly standardizing Non-Information Resources URIs on hash URIs, or possibly something completely different via parallel properties. Let's strongly encourage hash URIs via examples without restricting WebID to hash URIs.
discussion
[ bblfish: does that not put you in the SHOULD camp above? ]
TimBL's Linked Data design issue did not specify hash URIs; why should WebID?
[Kingsley Idehen:] WebID is based on Linked Data principles espoused in TimBL's Web oriented Linked Data publication meme. The aforementioned meme describes how to denote entities (things) using HTTP URIs such that an Entity Name (generic HTTP URI) and its Description Document Name/Address (URI/URL) resolve to RDF model based content (entity relationship graph) that describes the HTTP URI's referent -- this enables a wide variety of sophisticated data representation, integration, and dissemination initiatives that scale to the Web e.g., verifiable identity .
Arguments Against Proposal 3
LDP has issues with 303?
[Alexandre Bertails] -- Let's say that you want to consider your WebId Profile as an LDPR. Then LDP tells you how to simply update it, without any special/new protocol. That's my biggest issue with any solution encouraging HTTP 303: it doesn't play well at all with all the Write scenarios. (By the way, whenever your WebId is not part of such a platform, then you need to define yet-another-API to do the same, while LDP will save us from that.)
Counterpoint
[Stéphane]: we're not encouraging 303 at all, in fact if you check the spec proposed above, there is a note discouraging 303s. If people care to have a WebID compatible with LDPR, they'll definitely use a hash URI WebID!
Counterpoint: [| HTTP codes 302, 303, 307, 308]
Straw Poll results
Straw poll during WebID call Friday 30 Nov with wiki at revision 504
(Responses and totals have been updated here, since...)
| Participant | 1. MUST | 2. SHOULD | 3. OPEN |
|---|---|---|---|
| bblfish | -1 | +1 | +0.2 |
| MacTed | -1 | -0.9 | +1 |
| scor | -1 | +0.5 | +1 |
| deiu | 0 | +1 | -0.5 |
| bergi | -1 | +1 | +1 |
| melvster | 0 | +1 | 0 |
| Totals (current) | -4 | +3.6 | +2.7 |