Only comments that are publicly visible are listed below.
Such comments sometimes contain links to other items that are not publicly visible.
| LC002 | E | A | N | Tom Milo | - | B | Re: Character Model: Two new documents and Last Call
Behdad Esfahbod suggests: لالایی - a persian word meaning 'lullaby', pronounced /laalaayee/ Najib Tounsi suggests: تتلألأ - an arabic word which means "it
shines", "it sparkles". Where the subject "it" is of female gender.
Pronounce: ta ta la' la'
Discussed: Discussed: Decision: Accepted. We used the Persian word suggested above.
|
| LC003 | S | N | N | Markus Scherer | - | Overall | charmod vs. UTF-16/32
Decision: Noted and deferred. We agree with the first part of the sentence, but we do not yet have enough consensus to talk about the BOM in this version of the document. |
| LC004 | S | N | N | Markus Scherer | - | Overall | charmod vs. UTF-16/32
Decision: Noted and deferred We agree, but we do not yet have enough consensus to talk about the BOM in this version of the document. |
| LC005 | S | N | N | Markus Scherer | - | Overall | charmod vs. UTF-16/32
Decision: Noted and deferred We agree, but we do not yet have enough consensus to talk about the BOM in this version of the document. |
| LC006 | S | R | N | Markus Scherer | - | 6.2 | charmod vs. UTF-16/32
Discussed: Decision: Rejected The 'character string'
provides a good balance between user requirements (ideally
count in terms of grapheme clusters) and implementation
requirements (count in terms of code units). Also, it takes
into account that specifications (in particular those related
to XML) are written in terms of characters, not code units. We would like to point out that we have carefully listed the
alternatives and the reasons for when to use them in C052 and
C071,..., so that readers of the Character Model (writers of
specifications) should be able to make the best decision on
their own. Although we understand performance concerns about calculating
string length, we haven't heard any complaints about this e.g.
from implementers of XSLT. Also, in cases where it should really
become a bottleneck, e.g. finding a certain character position
in an extremely long string encoded in UTF-16 (or for that
matter e.g. in UTF-8), there are techniques for optimization
(e.g. building an index of every 1000'th character position
for an 1M long string, to be used for speedup of subsequent
indexing operations). Also, strings in general are not as easy to use as they may
seem. For some interesting background, please see
http://www.joelonsoftware.com/articles/fog0000000319.html. |
| LC007 | E | A | N | fantasai | - | 3.2 | poor example of multi-letter phonemes
|
| LC008 | E | A | N | fantasai | - | 3.3 | describing 'logical' order
|
| LC009 | S | R | N | Frank Ellermann | - | 4.5 | C069
Discussed: Discussed Decision: Rejected We have decided to reject your comment, but would like to thank
you for making it, because it has helped us getting more clarity
on what exactly we should say. We agree that C069, as it was written, at least in some interpretations,
would have prohibited ASCII art and ASCII smilies, and potentially even
Unicode smilies and so on. While we do not think that ASCII art and
ASCII smilies are necessarily a good idea, and in particular there
are accessibility issues, we note that there is quite a widespread
practice, and that with respect to accessibility, it is the expertise
of a separate group, and a separate spec, that is most qualified to
decide this (WCAG 1.0 has some techniques that mention ASCII art,
but doesn't prohibit it outrightly). So we decided to defer the question
of what to say about ASCII art and so on, and decided to remove
C069, and insert a much more specific conformance requirement into
the spec, placed somewhat earlier after the Note after C073: >>>>>>>>
C076 [C] Content MUST NOT use a code point for any purpose other than
that defined by its character encoding.
This prohibits the construction of fonts that misuse e.g. iso-8859-1
to represent different scripts, characters, or symbols than what is
actually encoded in iso-8859-1.
>>>>>>>> This is the major misuse that we tried to address with C069, in a somewhat
too general a fashion. In an ASCII smiley, a ')' is still a ')' as defined
in ASCII, it's just used in a different way than usually, but neither
the character model nor Unicode say how characters can be used and how not. |
| LC010 | Na | R | N | Frank Ellermann | - | 4.6 | C048
Discussed: Decision: Rejected We have taken the assumption that your comment asks for removing
C048 to avoid problems with browsers such as Netscape 3.x and 4.x.
Under that assumption, we have rejected your comment.
We would like to note that not only do these browsers not deal with hexadecimal character references, they are also very bad at dealing with character references in general according to the reference processing model. In particular, for Netscape 4.x, one has to label a document as UTF-8 in order for arbitrary
(decimal!) character references to take effect. Given that very poor if not non-existent support for the very basics of the Character Model in those browser versions, we do not feel that it is appropriate to remove C048, which otherwise is undisputed. In addition, browser statistics (see e.g.
http://www.w3schools.com/browsers/browsers_stats.asp) show that the percentage of these browsers is declining steadily and has reached very low numbers. We would also like to note that C048 is only a SHOULD, so this still allows the use of decimal numeric character references in situations where backwards compatibility with such kinds of browsers is really important, e.g. in intranet environments with very slow upgrade cycles. Please note that the wording of C048 has changed to
"Content SHOULD use the hexadecimal form of character escapes
rather than the decimal form when there are both."
to avoid saying anything about the relative preference of named character entities vs. numeric character references.
But this should be only marginally related to your comment. |
| LC011 | E | A | S | Tim Bray | - | 1.2 | Review of WD-charmod-20040225
|
| LC012 | E | N | S | Tim Bray | - | 1.2 | Review of WD-charmod-20040225
Decision: Noted We have classified this comment as 'noted', which means
that we acknowledge the point, but don't think that a change
to the specification is necessary. APIs often require more detailled specifications than protocols
or formats:
- APIs are often used on lower-granulary units than procotols and
formats.
- APIs often work on a single machine, and trade efficiency for
(cross-architecture) interoperability.
- Protocols and formats often only move data, whereas APIs
manipulate data. For I18N, this means that more details e.g. re. Unicode may have
to be specified for APIs than for protocols and formats. This is
explained in detail a couple paragraphs later. See also clarification |
| LC013 | E | N | S | Tim Bray | - | 1.2 | Review of WD-charmod-20040225
Decision: Noted We have classified this comment as 'noted'. This means that while it raises a valid point, we have decided not to change the specification. The fact that the Web can be seen as a single, very large application (in the sense that data flows through all the pieces without any total boundaries) is indeed very important in particular for the use of Unicode as a common reference point in the Character Model. Without such a reference, binary data would be exchanged without the chance to be able to compare two text strings (e.g. if they are in incompatible encodings). This also increases the requirement for Web-wide agreements on things such as counting characters,...
So this is indeed relevant to i18n, and is to quite some extent actually explained before and after the text in question. See also clarification |
| LC014 | E | P | S | Tim Bray | - | 1.2 | Review of WD-charmod-20040225
|
| LC015 | E | P | S | Tim Bray | - | 1.3 | Review of WD-charmod-20040225
Discussed: see notes RI finds only one other use of 'producer' and 'recipient'. Discussed: see notes Decision: Partially Accepted We removed the first paragraph and note in section 3.1, since those definitions were not needed for this document. We will use your proposed text for the Normalization document, where these definitions are needed. |
| LC016 | E | A | S | Tim Bray | - | 2 | Review of WD-charmod-20040225
|
| LC017 | E | A | S | Tim Bray | - | 2 | Review of WD-charmod-20040225
|
| LC018 | E | A | S | Tim Bray | - | 2 | Review of WD-charmod-20040225
|
| LC019 | E | A | S | Tim Bray | - | 3.1 | Review of WD-charmod-20040225
|
| LC020 | E | A | S | Tim Bray | - | 3.3 | Review of WD-charmod-20040225
|
| LC021 | E | A | S | Tim Bray | - | 3.3 | Review of WD-charmod-20040225
|
| LC022 | E | A | S | Tim Bray | - | 4.1 | Review of WD-charmod-20040225
|
| LC023 | E | A | S | Tim Bray | - | 4.3 | Review of WD-charmod-20040225
|
| LC024 | S | A | S | Tim Bray | - | 4.3 | Review of WD-charmod-20040225
Discussed: Discussion: Decision: Accepted We have split the requirement into two, making it a MUST NOT for surrogates, and a SHOULD not for other stuff.
The main reason for the distinction is that surrogates are the biggest area, therefore easiest to exclude. From there on, it's a bit of a slippery slope, with a decreasing return on investement. An example would be the U+??FFFE and U+??FFFF codepoints at the end of each plane. They are clearly not allowed, but a spec might want to make their own decision of whether they want to formally disallow them or not, based on efficiency considerations. See also clarification |
| LC025 | S | R | S | Tim Bray | - | 4.3 | Review of WD-charmod-20040225
Discussed: Decision: Rejected We have decided to reject this comment. The argument about having to choose between Java/C# friendly and C/C++ friendly has been countered on www-tag: in terms of programming, an explicit decoding step has to be used anyway e.g. in Java to deal with endianness issues, and interoperability and speed is not increased by adding more encodings because in the general case, all encodings have to be addressed. Also, we note that recently, the focus on abstract representations should allow to e.g. pass data directly as characters between two Java programs or processes. In addition, we note that we don't know any technology that currently would allow exactly UTF-8 and UTF-16 but nothing else (as opposed to XML, which allows lots of other encodings).
This would mean that it would be impossible to show implementation experience for such a combination. This seems to be in accordance with a well-known (at least in the IETF) saying for spec design:
"zero, one, many". In the case of (the next version of) CSS, this wouldn't really apply, because CSS, at least currently, like XML allows a wide range of character encodings. Also, it is very ASCII-heavy, more so on average than XML, so that
UTF-16 is less important. See also clarification |
| LC026 | E | N | S | Tim Bray | - | various | Review of WD-charmod-20040225
|
| LC027 | S | P | S | Tim Bray | - | 4.4.2 | Review of WD-charmod-20040225
Discussed: see notes Decision: Partially accepted We felt that the first part of the sentence had meaning and value, but removed the second part [ " and SHOULD implement them in such a way that they are easy to use (for instance in HTTP servers)" ]. See also clarification |
| LC028 | E | A | S | Tim Bray | - | 4.4.2 | Review of WD-charmod-20040225
|
| LC029 | E | P | S | Tim Bray | - | 4.4.2 | Review of WD-charmod-20040225
|
| LC030 | E | P | S | Tim Bray | - | 4.6 | Review of WD-charmod-20040225
Discussed: see notes Decision: Partially accepted This is a formal definition of an escape, rather than a statement of purpose, so we feel that point 3 is fine. We did however, change ''character codes' to 'encoded characters'. See also clarification |
| LC031 | E | A | S | Tim Bray | - | 4.6 | Review of WD-charmod-20040225
|
| LC032 | E | R | S | Tim Bray | - | 4.6 | Review of WD-charmod-20040225
Discussed: Discussed: Decision: Rejected Charmod does
not deprecate everything but Unicode (although it shows a clear and
intentional preference) and also the earlier requirement for hex
escapes (C045) applies to specifications that define escape syntaxes,
while this one applies to content (and implementations that generate
content). See also clarification |
| LC033 | E | R | S | Tim Bray | - | 4.6 | Review of WD-charmod-20040225
Discussed: see notes Decision: Rejected Charmod does not deprecate everything but Unicode (although it shows a clear and intentional preference). C049 includes things like using iso-8859-1 or windows-1252 for western European languages, or shift_jis,... for Japanese, and so on. See also clarification |
| LC034 | E | A | S | Tim Bray | - | 6.2 | Review of WD-charmod-20040225
|
| LC035 | S | A | S | Tim Bray | - | 7 | Review of WD-charmod-20040225
Discussed: see notes Decision: Accepted We have accepted this comment. As a result of this and other comments, we have split the character model again, creating a separate part that only deals with IRIs. We plan to move that to CR, and only proceed to PR when the IRI spec has further proceeded in the IETF (e.g. is published as a Proposed Standard RFC). We would like to note that the IRI spec recently has made quite some progress, IETF last call has successfully ended, and IESG approval may be close. See also clarification |
| LC036 | E | R | S | Tim Bray | - | 4.6 | Review of WD-charmod-20040225
Discussed: Decision: Rejected Not all specs need a reference to Unicode (or to 10646, for that matter). An example would be the xml:base spec, which doesn't involve characters except indirectly through XML and URIs. However, it is difficult to clearly define when a spec does or does not depend on character definitions and semantics. If C062 changed to a MUST, it would need to have a qualifier (e.g. "if the spec depends on character definitions and semantics...") which would make the MUST clause untestable. Therefore, this should remain a SHOULD, providing an escape hatch for specs that legitimately do not require a Unicode reference. See also clarification |
| LC037 | E | A | N | Susan Lesch | W3C Communications Team | Overall | Background color of images
|
| LC038 | E | A | N | Susan Lesch | W3C Communications Team | Overall | XML Spec XSLT
Discussed: see notes Decision: Accepted: but we fixed the XSLT we are using, rather than upgrade to the current version of XMLSpec, because we have added numerous extensions and don't feel we have the time or need to redo things. |
| LC039 | E | A | N | Susan Lesch | W3C Communications Team | 4.3 | Minor editorial
|
| LC040 | T | A | N | Susan Lesch | W3C Communications Team | 4.3 | Typo
|
| LC041 | T | A | N | Susan Lesch | W3C Communications Team | 2 | Typos
|
| LC042 | E | P | N | Susan Lesch | W3C Communications Team | A | URIs in citations
Our response (sent 2004-18-03) -- Re: URIs in citations Discussed: see notes Decision: Partially-accepted We already link the title text, and we don't think
URIs should not be linked. However, there are some titles that have not been linked that we noticed thanks to this comment. We have fixed them. |
| LC043 | S | P | S | Dan Connolly | - | 3.2 | conformance to "software MUST NOT assume" measurable?
Discussed: see notes Decision: Partially accepted We have changed the wording from: C001 [S][I][C] Specifications, software and content MUST NOT
>assume that there is< a one-to-one correspondence between characters
and the sounds of a language. to C001 [S][I][C] Specifications, software and content MUST NOT
>require or depend on< a one-to-one correspondence between characters
and the sounds of a language. and have made the same change for C002 and C003. This avoids the issue that specifications, implementation, and content don't really make 'assumptions'. As for conformance, we would like to first point out that all the conformance criteria in the Character Model are predicated on whether a given criteria actually applies to a give technology. So technology that does not deal with the auditory representation of language (i.e. most W3C specifications) are not affected by this criterion.
Technology that is affected (e.g. VoiceXML and in particular SSML) can be checked. If SSML for example tried to do text-to-speach conversion by defining a format for a table that would only associate single phonemes with single characters, it would very clearly not conform to the character model. But as you can check at http://www.w3.org/TR/2004/REC-speech-synthesis-20040907/#S3.1.9,
SSML definitions of written to spoken correspondence using the <phoneme> element allows definitions on whole words or larger pieces of text, so it is conformant. With this example, I hope that we have shown that conformance of specifications can indeed be checked. To be even more concrete, one could easily collect a series of examples (starting with those mentioned in the spec, such as "thing"), where there is not a one-to-one correspondence between characters and phonemes, and check whether specs, implementations,... that deal with such correspondences can handle them. |
| LC044 | S | R | D | Dan Connolly | - | 3.7 | define 'character' once and for all
Discussed: see notes Decision: Rejected The definition for 'character'
currently available in the document ("a character can be defined informally as a small logical unit of text") is too fuzzy to be directly useful in other specifications. Having a single, very precise, definition of 'character' is not really feasible, because different kinds of specifications may need different definitions.
Also, in C067, we advise to use more specific terms if available.
The wide range of ways to look at the phenomenon of a 'character, and to define the term 'character', should become obvious to the reader after reading Section 3 of the Character Model. Discussed Decided to leave as dissatisfied. |
| LC045 | S | A | S | Martin Dürst | - | 8 | Last call comment on Charmod (Fundamentals)
|
| LC046 | S | A | S | Dan Connolly | - | 4.6 | appropriate mechanism exists... says who?
Discussed: Discussed: Decision: Accepted Changed "Specifications MUST NOT invent a new escaping mechanism if an appropriate one already exists." to "Specifications SHOULD NOT invent a new escaping mechanism if an appropriate one already exists." This can indeed only be observed by humans looking at a specification and comparing it with known pre-existing escaping mechanisms, and this will include some judgement. However, we think that it is better to have this conformance criterion to make such judgement explicit rather than to have spec writers come up with new mechanisms all the time. |
| LC047 | S | A | S | Dan Connolly | - | 7 | IRI section needs too much testing to go in Fundamentals
Discussion: Our response (sent 2004-07-22) -- [Urgent] Request for additional feedback (was: Clarification sought: CharMod LC053) Request for TAG to comment on our plans to split the document and advance this Fundamentals part straight to PR. Discussed Decision: Accepted. We split off section 7 'Character Encoding in URI References' into a separate document titled "Character Model for the World Wide Web 1.0: Resource Identifiers", and will advance the remainder of the Fundamentals document to PR. The new document will go to CR and will be advanced with the IRI Internet-Draft. |
| LC048 | S | P | N | Dominique Hazaël-Massieux | - | Overall | Support for DanC's comment re conformance
|
| LC049 | S | A | N | Frank Ellermann | - | 4.6 | C049
|
| LC050 | E | A | N | Philippe Le Hégaret | - | 7 | IRI Reference should be normative
Discussion: Discussion: question is: does the CharMod text require it to be a normative reference? Decision: Accepted We moved ID-IRI reference from non-normative to normative references. Updated document links to draft-duerst-iri-10.txt. Added following note: "[NOTE: This reference should be taken to point to the RFC once the IRI draft has progressed to that stage.]" Note that as a result of other comments, we have moved the section about IRIs to a separate document. |
| LC051 | S | A | N | Chris Lilley | TAG | 4.5 | Pi fonts and PUA
Decision: Accepted. Discussion: Discussed Decision: Accepted We have added some new text: >>>>>>>>
C076 [C] Content MUST NOT use a code point for any purpose other than
that defined by its character encoding.
This prohibits the construction of fonts that misuse e.g. iso-8859-1
to represent different scripts, characters, or symbols than what is
actually encoded in iso-8859-1.
>>>>>>>> This is just after C073, which says that content on the Web
SHOULD not use the PUA. By having C076 being a MUST and C73 a SHOULD,
it is clear that if symbols not encoded in Unicode have to be represented,
they have to go into the PUA rather than into some assigned or reserved
area. On the other hand, we have removed C069 because it was too general
and covered e.g. things like ASCII art, which is an issue of
use of characters rather than encoding of characters. |
| LC052 | E | A | N | Chris Lilley | TAG | 3.3 | C004 ambiguous
|
| LC053 | S | A | N | Chris Lilley | TAG | 7 | Please remove IRIs
|
| LC054 | E | P | S | Karl Dubost | QA | 3.2 | KD-001
Discussion:note that this is linked to LC055, LC056 and LC068 Decision: Partially accepted For 3.2, C001; 3.3, C002; 3.4, C005; 3.6, C009: replaced "MUST NOT assume" with "MUST NOT require or depend on". We have changed the wording from: "C001 [S][I][C] Specifications, software and content MUST NOT >>assume that there is<< a one-to-one correspondence between characters and the sounds of a language." to "C001 [S][I][C] Specifications, software and content MUST NOT >>require or depend on<< a one-to-one correspondence between characters and the sounds of a language." This avoids the issue that specifications, implementation, and content don't really make 'assumptions'. As for conformance, we would like to first point out that all the conformance criteria in the Character Model are predicated on whether a given criteria actually applies to a give technology. So technology that does not deal with the auditory representation of language (i.e. most W3C
specifications) are not affected by this criterion. Technology that is affected (e.g. VoiceXML and in particular SSML) can be checked. If SSML for example tried to do text-to-speach conversion by defining a format for a table that would only associate single phonemes with single characters, it would very clearly not conform to the character model. But as you can check at http://www.w3.org/TR/2004/REC-speech-synthesis-20040907/#S3.1.9, SSML definitions of written to spoken correspondence using the <phoneme> element allows definitions on whole words or larger pieces of text, so it is conformant. With this example, I hope that we have shown that conformance of specifications can indeed be checked. To be even more concrete, one could easily collect a series of examples (starting with those mentioned in the spec, such as "thing"), where there is not a one-to-one correspondence between characters and phonemes, and check whether specs, implementations,... that deal with such correspondences can handle them. As for implementability, there are a lot of text-to-speech engines, and a lot of speech detection engines, that do not require or depend on a one-to-one correspondence, so it is very clear that this can be implemented. As for your point of "If the software implements only this language because it's a specific use for only this language", yes, such a software would not conform to the character model. From the viewpoint of the character model, this would be on purpose; in the age of the World Wide Web, it is a bad idea to create software that can handle only one language, and it is a bad idea to create software that has language-related issues hard-coded when it can easily be made configurable. |
| LC055 | E | P | S | Karl Dubost | QA | 3.3 | KD-002
Discussion: Discussion: Decision: Partially acceptedOur reply is basically the same as that for LC054. We replaced "MUST NOT assume" with "MUST NOT require or depend on".
We note that this is testable with very simple examples, some of which can be found in the spec itself.
Implementations dealing with only a single language may not conform to the character model, and that is by design; it's the goal of the character model to make sure that specs and software can deal with as much languages as possible. |
| LC056 | E | P | S | Karl Dubost | QA | 3.4 | KD-003
Discussion: Discussion: Decision: Partially accepted Our reply is basically the same as that for LC054. We replaced "MUST NOT assume" with "MUST NOT require or depend on".
We note that this is testable with very simple examples, some of which can be found in the spec itself.
Implementations dealing with only a single language may not conform to the character model, and that is by design; it's the goal of the character model to make sure that specs and software can deal with as much languages as possible. |
| LC057 | E | R | S | Karl Dubost | QA | 3.5 | KD-004
Discussion: Decision: Rejected You write:
===> What's happening if you implement all western languages but not asian because the context of applications do not make it necessary. Do I still have to implement everything? If not how can I be conformant? As we have already explained in our responses to LC054-56 that the goal of the character model is to cover as many languages/scripts/ characters as possible. On the WWW, you never know what input you get.
If an implementation blows up just because it is unable to do anything with Asian characters, that would be very bad. Please note that we do not require any particular sort order for any character, simply sorting 'unknown' characters by codepoint would be okay. |
| LC058 | E | P | S | Karl Dubost | QA | 3.6 | KD-005
Discussion: Discussion: Decision: Partially accepted Our reply is basically the same as that for LC054. We replaced "MUST NOT assume" with "MUST NOT require or depend on".
We note that this is testable with very simple examples, some of which can be found in the spec itself.
Implementations dealing with only a single language may not conform to the character model, and that is by design; it's the goal of the character model to make sure that specs and software can deal with as much languages as possible. |
| LC059 | E | A | S | Karl Dubost | QA | 3.7 | KD-006
|
| LC060 | E | A | S | Karl Dubost | QA | 4.4.1 | KD-007
|
| LC061 | E | A | S | Karl Dubost | QA | 4.4.2 | KD-008
Discussion: Decision: Accepted Replaced "Specifications MAY define either UTF-8 or UTF-16 as a default encoding form (or both if they define suitable means of distinguishing them), but they MUST NOT use any other character encoding as a default." with "Specifications that mandate a default encoding MUST define either UTF-8 or UTF-16 as the default, or both if they define suitable means of distinguishing them." |
| LC062 | E | A | S | Karl Dubost | QA | 4.4.2 | KD-009
|
| LC063 | E | A | S | Karl Dubost | QA | 4.4.2 | KD-010
|
| LC064 | S | A | S | Karl Dubost | QA | 4.5 | KD-011
Discussion: Discussed Decision: Accepted We have removed C069, which was too general,
because we don't want to discuss the use of characters so much as the
encoding of characters. We have added new text, just after C073 >>>>>>>>
C076 [C] Content MUST NOT use a code point for any purpose other than
that defined by its character encoding.
This prohibits the construction of fonts that misuse e.g. iso-8859-1
to represent different scripts, characters, or symbols than what is
actually encoded in iso-8859-1.
>>>>>>>> in order to not loose the main issue for which C069 was originally
introduced. |
| LC065 | E | R | S | Karl Dubost | QA | 6.1 | KD-012
|
| LC066 | E | A | S | Karl Dubost | QA | 8 | KD-013
|
| LC067 | E | R | S | Karl Dubost | QA | 8 | KD-014
Discussion: Decision: Rejected In your comment, you mention the case that a spec depends on a particular version of Unicode. In this case, it is not a generic reference, but a specific reference.
The difference is given in http://www.w3.org/TR/charmod/#C063. If a spec follows this, then it will use a generic reference to indicate that future codepoints allocated can be used, and it will use a specific reference if it has to reference a particular version of e.g. normalization, character properties, or so. Then if that spec is updated, the generic reference can be updated to the latest version of Unicode without problems, but the specific reference is not changed, unless there is an explicit decision that a the newer version e.g.
of normalization or character properties should be used. |
| LC068 | E | P | S | Karl Dubost | QA | - | KD-015
|
| LC069 | E | N | N | Karl Dubost | QA | - | KD-016
Discussion: Decision: Noted and deferred We agree that having a glossary would be a good idea, but given our current resources, we have had to give priority to moving the spec on. We may be able to come back to create a glossary at a later stage, or it may be possible to extract (at least some of the) terms from the document, because to a large extent, terms and their usage is already marked up. |
| LC070 | E | P | S | Björn Höhrmann | - | 1.2 | Clarify "legacy encoding"
Discussed Discussed Decision: Partially accepted We removed 'legacy encoding' as a formally defined term from CharMod Fundamentals. We will revisit this for CharMod Normalization. Discussed The one remaining use of the word 'legacy' was in the introductory text, and was not used in a technical way, but we have removed that. |
| LC071 | S | R | D | Björn Höhrmann | - | 4.4 | APIs vs. physical string representations
Discussion: Decision: Rejected You raise a valid point mentioning that although the DOM specifies to use UTF-16, not all implementations follow this. When the DOM was created, we were apparently more worried about inter-language compatibility than necessary, but not only that, we were also worried about intra-language compatibility. Today, most major languages have their model for how to deal with Unicode; when
DOM1 was created, that wasn't the case. In particular, people were pointing to Corba, which does things like character encoding negotiation, which would not at all have been suited for DOM. Going back to the text of C016: "When designing a new protocol, format or API, specifications SHOULD require a unique character encoding.", we would like to point out that it doesn't require APIs across languages to use the same encoding. We would also like to point out that e.g.
the DOM1 spec is very careful to avoid using the word API for DOM itself (see e.g. http://www.w3.org/TR/1998/REC-DOM-Level-1-19981001/).
In addition, we would like to point out that C017, "When basing a protocol, format, or API on a protocol, format, or API that already has rules for character encoding, specifications SHOULD use rather than change these rules." would provide strong justification for a spec like DOM that would want to leave the question of character encoding to each language binding. So therefore, we don't think that the current wording causes any problems. |
| LC072 | E | Na | O | Björn Höhrmann | - | Overall | Editorial suggestions
-
Comment (received 2004-04-08) -- Editorial suggestions
I think the use of abbreviations like CCS, CEF, CES, etc. reduces the readability of the document. While it might be convenient to use abbreviated forms in discussions, they make the document more difficult to read, especially because these look too similar. You cannot expect that someone not familiar with the issues involved could easily understand a paragraph like
[...]
A CES is a mapping of the code units of a CEF into well-defined
sequences of bytes, taking into account the necessary specification of
byte-order for multi-byte base datatypes and including in some cases
switching schemes between the code units of multiple CESes (an example
is ISO 2022). A CES, together with the CCSes ...
[...]
It is already quite difficult to differentiate between terms like "code point" and "code unit". Please spell these out more often. It might also be helpful to include (simplified) definitions of these terms for each occurence, like
<span title='a mapping from a repertoire of characters to a set
of non-negative integers'>Coded Character Set</span>
and/or make occurences links to the definitions, for example XML Schema uses constructs like
<a href="#dt-value-space" class="termref"><span class="arrow"
>·</span>value space<span class="arrow">·</span></a>
It would also be helpful to have a summary glossary of the terms used in the document, this would help to create the title attributes suggested above and simplifies lookup for these terms.
If there is any chance you could renumber the Cxxx codes to bring them back in order, please do. While it might be convenient not to break links and references to the document, having many of them out of order is quite confusing. The document split already breaks references, for example css3-selectors CR references the normalization part which is no longer included in the latest version of the document it references, hence it appears there is only a minimal addtional cost here.
Please make sure to publish checklists containing the conformance requirements (complete and by product) along with the CR. This would
be a great help for your audience (specification and implementation reviews in particular).
Please make Cxxx identifiers links to that section, i.e., turn e.g.
<a id="C013" name="C013">
into
<a id="C013" name="C013" href="#C013">
so I can copy and paste pointers to specific guidelines more easily. That these are links could be hidden through style sheets, if you think this reduces readability.
Discussion: see notes This comment has been split into the following comments: LC086, LC087, LC088, LC089 |
| LC073 | S | A | S | Björn Höhrmann | - | 4.4.1 | Strike C019
Discussion: Discussed (First part of minutes) Discussion: Decision: Accepted We have replaced C019 with the following
sentence:
"US-ASCII is upwards-compatible with UTF-8 (an US-ASCII string is also an UTF-8 string, see [RFC 3629]), and UTF-8 is therefore appropriate if compatibility with US-ASCII is desired." |
| LC074 | E | A | S | Björn Höhrmann | - | 4.6 | Improved text for C047
Discussed Discussed Decision: Accepted We now say: "Escapes should only be used when the characters
to be expressed are not directly representable in the format or the encoding of the document, or when the visual representation of the character is unclear.", and we added a note referring to the as an example. |
| LC075 | S | P | D | Björn Höhrmann | - | 6.2 | Arguments vs. return types
Discussion: Discussion: Decision: Partially Accepted Changed C056 from
"Specifications of APIs SHOULD NOT specify single character or single
encoding-unit arguments." to "Specifications of APIs SHOULD NOT specify single characters or
single units of encoding as argument or return types." We agree that return types should also be mentioned, and
that 'encoding-unit' has to be replaced by 'units of encoding'. However, we disagree with your counterexample. The fact that an
'uppercase' function can take a single character, even an sz,
as an argument in some cases doesn't prove that there are no cases
where it will not become necessary to hand over more than one character
at a time to a function for proper uppercasing. Therefore, in general,
both the arguments and the return type should be strings. Discussed Our response (sent 2004-10-28) -- Re: Your comments on Character Model Fundamentals [LC070, LC074, LC075, LC079, LC080, LC081, LC082, LC083, LC084, LC085, LC086, LC087, LC088, LC089] See also following mails with same subject. Discussed We decided to stay with his objection. The text is the way it is for a reason and it is not a MUST in any case. |
| LC076 | S | P | D | Björn Höhrmann | - | 4.5 | Clarify "character technology misuse"
Discussed Decision: Partially-accepted You are correct that C068 and
C069 do strictly speaking not belong into the PUA section, but they
are in that section because they have a very strong connection to the
other things in that section. You are correct to raise the question about ASCII art and Unicode smilies.
Given your and others' comments, we have realized that C069 is too general.
The various factors affecting the use of ASCII art and Unicode smilies
are not questions of character encoding. In as far as they are
accessibility issues, they should be and are being addressed in the
relevant specifications. We have therefore removed C069 and instead
added new text, just after C073: >>>>>>>>
C076 [C] Content MUST NOT use a code point for any purpose other than
that defined by its character encoding.
This prohibits the construction of fonts that misuse e.g. iso-8859-1
to represent different scripts, characters, or symbols than what is
actually encoded in iso-8859-1.
>>>>>>>> in order to not loose the main issue for which C069 was originally
introduced. Discussed Our response (sent 2004-10-28) -- RE: Your comments on Character Model Fundamentals [LC076] See also following mails with same subject. Discussed Keep as dissatisfied. See notes in minutes. |
| LC077 | E | R | D | Björn Höhrmann | - | 1.3 | Use uppercase hhhh
Discussion: Decision: Rejected We have rejected this request because we feel that the uppercase string U+HHHH is inferior in appearance compared to the string U+hhhh and that the latter is more common when giving an example of Unicode Scalar Values. In particular, the Unicode standard, v4.0, on page xxxiv ("Notational Conventions") introduces the USV notation with lowercase ('x' and 'y' in this case). Discussed Leave as dissatisfied. |
| LC078 | S | R | D | Björn Höhrmann | - | 2 | Specs must require specs to conform
Discussion: Decision: Rejected We think that it is a somewhat rare edge case that doesn't warrant additional complication in the conformance section. In the general case, every specification should try to conform to the character model, whether it also conforms to some other specification or not. In many cases, conformance to the character model also will come naturally for a derived spec. Discussed Leave as dissatisfied. |
| LC079 | S | R | D | Björn Höhrmann | - | 4.4.2 | Using "charset" should be prohibed
Discussion: Decision: Rejected We have decided to reject this comment because there may for example on occasion be historic reasons to mention these terms. Also, we would like to point out that this is just an issue of wording, not of interoperability, so there is no reason to be absolutely strict. Our response (sent 2004-10-28) -- Re: Your comments on Character Model Fundamentals [LC070, LC074, LC075, LC079, LC080, LC081, LC082, LC083, LC084, LC085, LC086, LC087, LC088, LC089] See also following mails with same subject. Discussed Decided to leave as dissatisfied. |
| LC080 | S | P | N | Björn Höhrmann | - | 6.1 | A string is a sequence of characters
Discussion: Discussion: Discussion: Decision: Partially accepted We revised the explanations of byte and other strings to clarify their utility. We added this whole section (the diff.
kinds of string) in response to a comment on a previous version of Charmod. To the issue of whether or not distinguishing the different types of strings is a good idea, as we indicate in the first paragraph of section 6.1, these are existing notions. We feel it is important to formalize their definitions so we can label and describe appropriate and inappropriate practices. We added the example to the section on byte strings, to emphasize a bad practice. |
| LC081 | E | A | S | Björn Höhrmann | - | 4.4.2 | C036 and C033 are duplicates and too obvious
|
| LC082 | E | A | S | Björn Höhrmann | - | Overall | Avoid inline conformance criteria
Discussion: See also LC060. Decision: Accepted We have separated each conformance criterion into a separate paragraph, or in one case, a paragraph followed by a list. |
| LC083 | E | A | D | Björn Höhrmann | - | 2 | Define "mandate"
Discussion: Decision: Accepted We have replaced 'mandate' with 'require'
thoughout the document. 'Require' is well defined in RFC 2119. Please
note that we are not using upper-case in this case, because we are using
'require' descriptively, rather than normatively, in our spec. Discussed Our response (sent 2004-10-28) -- Re: Your comments on Character Model Fundamentals [LC070, LC074, LC075, LC079, LC080, LC081, LC082, LC083, LC084, LC085, LC086, LC087, LC088, LC089] See also following mails with same subject. |
| LC084 | Na | N | N | Björn Höhrmann | - | 4.4.2 | Clarify C034 in case of heuristics
Discussion: Decision: Noted We have decided to classify this comment as 'noted', which means that we think it raises a valid point, but does not merit changes to the current specification. With the example of XML, we have tried to make clear that rules that unambiguously lead to a determination of the character encoding to be used for decoding the document are not considered heuristics. Whether it is a good idea to make the used character encoding depend on the way the document is loaded is a different issue, not addressed by C034, but such cases already exist (e.g. loading a document from a file system vs. serving it over the Web including meta information in HTTP headers). The case you mention, loading from a link in an existing document vs. idenpendent loading, is just an extension of the above case. Discussed |
| LC085 | S | R | N | Björn Höhrmann | - | 2 | Conformance vs. non-conformance
Discussion: Decision: Rejected We have decided to reject this comment because, as you may be able to deduce from our response to your issue LC084, we do not think that CSS 2.1 violates C028. The specific example you give is therefore not applicable. Even if we accepted your point re. C028, we would like to note that it would still be possible to produce CSS that conformed to the character model, for example by always using the @charset rule. The question of what should be done with some implementations or content to try to conform to the character model even if the specification they use doesn't conform to the character model doesn't have an easy answer in general (as shown above, sometimes this may be easy; at other times, it may not be easy).
Making any general statements about such cases therefore doesn't look like it will help at all. |
| LC086 | E | A | S | Björn Höhrmann | - | Overall | Editorial suggestions
|
| LC087 | E | R | S | Björn Höhrmann | - | Overall | Editorial suggestions
Discussion: see LC072 notes Discussed Decision: Rejected There are links to conformance criteria from existing mailnotes and the like, and these links depend on the numbers used. For this reason, though we would also prefer to maintain a sequential order, we do not want to renumber the criteria. |
| LC088 | E | P | S | Björn Höhrmann | - | Overall | Editorial suggestions
Discussion: see LC072 notes Discussed Decision: Partially accepted We have produced a simple list of the conformance requirements in Appendix D. We may make this more sophisticated in future versions of the document. |
| LC089 | E | A | S | Björn Höhrmann | - | Overall | Editorial suggestions
|
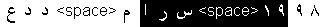{kind=link}
{kind=link}