The
VRP V 2.5: Implementing the Updated RDF Syntax
Karsten Tolle
Johann Wolfgang Goethe-University, Frankfurt / Main, Germany
tolle@dbis.informatik.uni-frankfurt.de
Sofia Alexaki, Vassilis Christophides
Institute of Computer Science (ICS), FORTH, Heraklion, Greece
{alexaki, christop} @ics.forth.gr
1.
Introduction
The evolution of a
standard is needed to solve open problems and adopt new requirements. During
the last years the syntax specification of the Resource Description Framework
(RDF) was updated in some points. But updates sometimes also course confusion
on the side of implementers and users of this standard. Updates therefore have
do be done with care and need to be explained detailed. For existing
application it can course unexpected effort to adopt these changes. In this
report we will explain experiences with some changes of RDF and will examine
them more closely. The experiences are based on including these changes to the
Validating RDF Parser (VRP), which is a part of the RDFSuite toolset. Since VRP
not only tests the correctness of the RDF syntax but also provides a semantic
validation against the RDF Schema, related issues also included into the
report.
Before going into
detail with the changes made on the RDF standard in Section 3, we will briefly
present in Section 2 the Validating RDF Parser and highlight its new features
(version 2.5).
2.
Validating RDF
Parser (VRP v2.5)
The ICS-FORTH Validating RDF Parser (VRP v2.5) is a tool for analyzing,
validating and processing RDF schemas and resource descriptions. The Parser analyses
syntactically the statements of a given RDF/XML file according to the RDF M&S Specification (more precisely, the updated
syntax proposed by W3C Working Draft 23 January 2003 [5]). The Validator checks
whether the statements contained in both RDF schemas and resource descriptions
satisfy the semantic constraints derived by the RDF Schema Specification (RDFS) [3]. Unlike other
available RDF parsers, VRP is based on standard compiler generator tools
for Java, namely CUP (0.10j) [11] and JFlex (1.3.5) [12] similar to YACC/LEX. The stream-based
parsing support of JFlex and the quick LALR grammar parsing of CUP ensure a
good performance, when processing large volumes of RDF descriptions. For this
purpose, the VRP validation module relies on an original object representation,
separating RDF schemas from their instances.
VRP is part of the ICS-FORTH RDFSuite [13] toolset, a suite of
high-level, scalable tools for validation, storing and querying RDF schemas and
resource descriptions. RDFSuite addresses the need for effective and efficient
management of large volumes of RDF metadata as required by real-scale Semantic
Web applications.
The new version 2.5 of VRP includes syntax updates according the latest
updated syntax [5] (more on this in chapter 3), massive improvements in
performance for storing and creating the internal model of the RDF/XML files
and additional features. These new features include additional statistic
information and a visualisation of the generated RDF model by using SVG. These
improvements and features will be explained in detail in the following
subsections.
2.1.
VRP Internal Object
Model
The parser of VRP
extracts the triples from the RDF/XML file and enters them into the VRP
internal object model representing the RDF graph of the RDF/XML file. In
the following we will just call it object model. All further modules of
VRP (e.g., statistics or validator) or external programs that use VRP (e.g.,
RSSDB of the RDFSuite) will work on this object model. It is therefore
important to understand its structure.
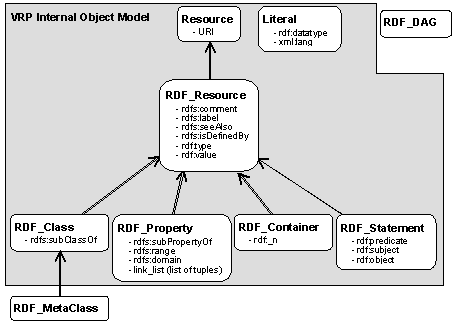
The object model of
VRP comprises a class hierarchy (see figure 1). The root of hierarchy is the
class Resource. The class RDF_Resource is a direct subclass of
it. The classes RDF_Class, RDF_Property, RDF_Statements
and RDF_Container are direct subclasses of the class RDF_Resource.
The class for literals is new since version 2.5 of VRP. The object model represents all the
information of the input RDF/XML file. More precisely, an object, which belongs
to one of the above Java classes, is created for every resource that exists in
the analyzed descriptions. The rest information is stored as attribute values
of the created objects. Note that
in VRP model the separation between schema and data is explicit. In addition we
will explain the class RDF_DAG and RDF_MetaClass for better understanding how
to work with VRP.
Figure
1. Java
Classes of VRP Object Model
Resource: The instances of this class represent
resources that have not been assigned any of the predefined RDF/S properties
(i.e., rdf:type, rdfs:comment, rdfs:label, rdfs:seeAlso, rdfs:isDefinedBy). On
the contrary the instances of RDF_Resource represent resources that have
been assigned any of the previous RDF/S properties.
RDF_Class: The instances of this class represent RDF
classes.
RDF_Property: The instances of this class represent RDF
properties. Within the properties, except of the predefined RDF/S properties,
we save the resources it links in the RDF graph. For validation this class
therefore consists of an extra method, namely range_domain_check, for
testing the correctness of the domain and range definitions within these links.
RDF_Container: The instances of this class represent RDF
containers.
RDF_Statement: The instances of this class represent reified
statements. For validation this class consists of an extra method, namely valid,
that tests for the existence of each needed part of the reified triple. The
uniqueness of the single parts is tested during entering them.
Literal: With the support of xml:lang for language
settings for literals and the possibility of denoting literals with datatypes
by the property rdf:datatype, we now introduced the new class Literal to the
object model of VRP to satisfy these changes. By overwriting the toString
method the string representation of it as defined in [5] will be returned.
RDF_DAG: For different purposes, e.g., for loop
testing or the statistics, we need the hierarchy of the classes and properties
defined in the object model by the properties rdfs:subClassOf and
rdfs:subPropertyOf. For performance reasons this hierarchies will be created
once during the final validation phase and will be saved in a directed acyclic
graph represented by an object of this class. This class does not directly
belong to the object model itself, since the information is redundant, but we
think it is worth for understanding to introduce it here.
RDF_MetaClass: The instances of the classes rdfs:Class and
rdf:Property are special since they represent classes respectively properties.
This is also true for instances of subclasses of rdfs:Class and rdf:Property.
We therefore introduced RDF_MetaClass as a sub class of RDF_Class to represent
the classes rdfs:Class, rdf:Property and their subclasses. These meta classes
will be used for calculating in the statistic module and for visualization.
Note: Also this class does not directly belong to the object model itself. It
will only be used after creating and validating the object model.
Within the boxes of
the classes in figure 1 you also see the predefined RDF/S properties
corresponding to their rdfs:domain definition. When assigning such a property
VRP will cast the object to the corresponding rdfs:range class of the property,
e.g., the value for rdf:type will be entered into the object model as a
RDF_Class. The casting itself here is a problem, since we normally need to cast
from the super class to its subclass, e.g., from the class Resource to the
class RDF_Class. This down casting is not supported by Java. We therefore need
to generate a new element of the corresponding class and shift the information
we have so fare to it. By generating a new object we would loose the already
made links, e.g., in the property link_list. The link_list therefore do
not contain the links of the Java objects. In the old version of VRP we
therefore used the URIs as a unique reference within the object model and used
a hash map having the URIs as the key value to point to the corresponding Java
object. In cases of needed down casting we just replaced the Java object in
this hash map structure.
With the new version
2.5 of VRP we restructured this way referencing to the Java object. The URIs
normally containing 20 or more characters. Saving each reference inside the
object model using the URI is very storage consuming and comparing them reduces
the performance. We therefore added a second hash map that maps the URIs to a
unique integer. Inside the object model now these integers are used to refer to
the corresponding Java object. Additional we introduced two phases. In the
first phase, the model generation, all triples are entered. After entering all triples to the
object model there is no more need for down casting any more. All the integers
used for referring to the Java objects can be replaced by the Java object links
themselves. We call this second phase link resolving. In figure 2 you
can see an example for the to phases. Note: In some cases we already know
during the model generation that there will be no further down casting, e.g.,
for the predefined property rdf:type, we know the object must of type
rdfs:Class. Since RDF_Class is a leaf in our object model, there is no further
down casting possible. We therefore already use the Java object link instead of
the integer. This is also true for literals as shown in figure 2.
 Figure 2. The two phases of the VRP Model.
Figure 2. The two phases of the VRP Model.
With this new
structure we where able to reduce the needed space. Using a 5.8 MB RDF/XML file
running VRP 2.5 we measured about 20% less memory usage than before. Since
during the object model creation there are lots of key comparisons needed is
also speed up the system. With the same 5.8 MB file we needed about 50% less
time for the model generation, compared to the old version of VRP. This speed
up not only effects the model generation itself. All following modules using
the model will profit from this performance improvement.
2.2.
Additional VRP
Statistics
In this subsection we
will present the statistics module are added in the new version of VRP (v2.5)
for RDF/S Schemas. These statistics are calculated for each of the class and the property
hierarchy. The property hierarchy
contains all the properties defined by a user in a RDF/S schema. For the class
hierarchy, we consider three disjoint hierarchies, i.e, the schema class
hierarchy which contains the classes whose members are data resources, the metaclass
hierarchy containing the classes that are subclasses of the rdfs:Class
(thus their members are classes) and the metaproperty hierarchy which
contains the classes that are subclasses of the rdf:Property (thus their
members are properties). The different hierarchies are stored in elements of
the class RDF_DAG as described in the previous section.
The additional
statistics include:
·
Average and Maximum number of direct
supernodes/ancestors that a node either in a class or property hierarchy has. Note that this
statistics is based on only the (super/sub)nodes that are directly accessed
from a node through the subclassOf/subPropertyOf hierarchy. For example the
node G has 3 direct ancestors (see figure 1). In
order to compute the average, we add the direct ancestors of each hierarchy
node and we divide the total with the number of hierarchy nodes.
·
Distinct[1]
Recursive Ancestors/Descendants distribution both for class and property
hierarchies. We calculate the distinct number of recursive ancestors/descendants of
the hierarchy nodes, i.e., the number of the nodes found above/below this node
in the hierarchy. Afterwards, we
compute the distribution i.e., we count how many nodes (classes or properties)
have x ancestors/descendants. In figure 3 you can see the number of ancestors/descendants of
hierarchy nodes. Note that the class B is connected to the class H both through
the class G and the class D, the class H will be added just once. Thus the
number of the /descendants of the B is 4 and NOT 5

Figure 3. Distinct Recursive
Ancestors/Descendants Distribution
2.3.
SVG
Representation of RDF/S Triples
The new version of VRP
(v2.5) supports the representation in Scalable Vector Graphics [10] (SVG 1.0)
format of the RDF Model produced by VRP - which consists of RDF (meta)classes,
properties, resources, containers, statements and literals and their
descriptions. Specifically, by checking the option SVG that is provided in the
interface of the VRP, an SVG file is created with the representation of the
output RDF Model of the VRP internal object model.
SVG is a W3C
recommendation. It is a new two-dimensional graphics file format. SVG allows
for three types of graphic objects: vector graphic shapes images and text.
Graphical objects can be grouped, styled, transformed and composed into
previously rendered objects. The feature set includes nested transformations,
clipping paths, alpha masks, filter effects and template objects. SVG drawings
can be interactive and dynamic. Animations can be defined and triggered either
declaratively (i.e., by embedding SVG animation elements in SVG content) or via
scripting.
The browsing
functionality provided by the SVG representation of the RDF/S triple is:
·
Navigate to class
and property subsumption hierarchies
·
Lookup declared
or inferred class and property descriptions
·
Discover related
resource description graphs

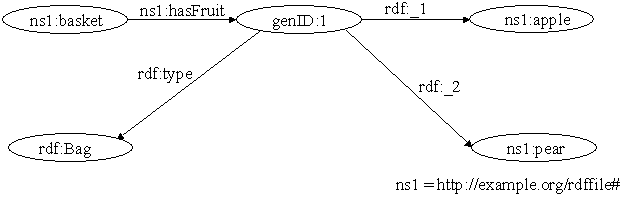
Figure 4. RDF Graph Example
Below we present some
screen dumps produced when the Internet Explorer opens the SVG file that was
generated by VRP taking as input the RDF graph of the figure 4. In the sequel, we illustrate how one can explore
the RDF schema or recourse description graph using the generated SVG graphical
representation. Every class, property or resource displayed either in the left
or the right part of the SVG window is clickable. In the left menu there
exist two buttons, namely Classes and Properties, which can be
clicked in order to display the class or property hierarchy and start
navigation to their subclasses/subproperties. The subclasses are placed exactly
below the parent class and by clicking the symbol that is displayed next to the
class one can select to display its subclasses. By default only root classes
are displayed. When one clicks a class/property he/she can see on the right part
of the SVG window its complete RDF/S description.

Figure 5. Display a Class using SVG
The SVG representation
of RDF/S class hierarchies is depicted in figure 5. The
presented snapshot is produced after clicking on Classes
in the left upper menu and then clicking on Cubist.
In the right part of the figure we can see the description of the class Cubist,
i.e., the classes under where is classified, the direct superclasses/subclasses
of it, the properties that have as a domain or as a range the Cubist and the
instances that are classified in this class. Note that not only the properties
that are defined in the class but also the properties that are defined on its
superclasses are presented. Finally, the resources that are classified both
under this class and its subclasses are displayed.
The SVG representation
of RDF/S property hierarchy is depicted in figure 6. The
presented snapshop is produced after clicking on Properties
on the left upper menu and then clicking on creates.
In the right part of the figure we can see the full description of the property
(see also the schema in figure 4) i.e., the metaclasses
under where the property is classified, its direct
superproperties/subproperties, as well as its domain and range. Note that in
the description of the properties are displayed not only the proper domain and
range classes but also their respective subclasses.
The SVG presentation
of a resource description is depicted in the figure 7.
When one clicks on the resource www.culture.net/picasso132
you see the classes where the resource is classified (Cubist), the properties
that are defined on the resource and their values and the properties that have
as value the specific resource.

Figure 6. Display a Property using SVG

Figure 7. Display a Resource using SVG
3.
RDF Syntax
updates
In the following
subsections we will discuss five changes to the RDF syntax specification and
will explain some of our experiences with trying to include them to VRP. We
start with the handling of datatypes in RDF and the new construct of
collections, which raises some open questions. You can find something about the
support of XML Base, the handling of XMLLiterals and a little comment on
non-namespaced local-names.
3.1.
Datatypes in RDF
When talking about
datatypes in RDF we first need to clear out what is their precise meaning. One
can specify datatypes for Properties by setting the rdfs:range to the
corresponding datatype. We will call this the schema datatypes. On the
other hand one can specify the datatype for the single instances by the new
introduced rdf:datatype attribute. We will call this the instance datatype.
Below you can find a valid example of using Schema and Instance datatypes.
Example 1: Using schema and instance datatypes.
<?xml version="1.0"?><!DOCTYPE rdf:RDF [ <!ENTITY xsd "http://www.w3.org/2001/XMLSchema#"> <!ENTITY rdf "http://www.w3.org/1999/02/22-rdf-syntax-ns#"> <!ENTITY rdfs "http://www.w3.org/2000/01/rdf-schema#"> ]> <rdf:RDF xmlns:rdf="&rdf;" xmlns:rdfs="&rdfs;"><rdf:Property rdf:ID="stringProperty"> <!— Defining the schema datatype with rdfs:range --> <rdfs:range rdf:resource="&xsd;string"/> <rdfs:domain rdf:resource="&rdfs;Class"/></rdf:Property><rdf:Property rdf:ID="booleanProperty"> <rdfs:range rdf:resource="&xsd;boolean"/> <rdfs:domain rdf:resource="&rdfs;Class"/></rdf:Property><rdfs:Class rdf:ID="TYPETESTCLASS"> <!— Defining the instance datatype with rdf:datatype --> <stringProperty rdf:datatype="&xsd;string"> this is a string </stringProperty> <booleanProperty rdf:datatype="&xsd;boolean">true</booleanProperty> <booleanProperty rdf:datatype="&xsd;boolean">false</booleanProperty></rdfs:Class></rdf:RDF>
With the schema datatype one can specify what kind of data will make sense in
the context of a particular property. With the new attribute rdf:datatype for
specifying the instance datatype we can distinguee between, e.g., a string
“123” and the integer 123. In the case that everybody would use it in the
correct way this would increase the quality of data. But especially when new
datatype definitions will arise there are some open issues. How we can compare
different datatype definitions in order to validate? Is it easy enough that
people will understand it and will use it in the right way?
Since there are so many
open questions, VRP only validates against the schema datatypes and so fare
only supports the XML datatypes contained in the namespace http://www.w3.org/2001/XMLSchema
(we will use the prefix xsd
to refer to this namespace in the following text), as shown in the example 1.
During validation VRP takes the string value used with a property having a
defined schema datatype and tries to transform it using the Sun™ XML Datatypes
Library [7] to the corresponding datatype. Further datatypes might be supported
in future. The validation for the instance datatypes using XML datatypes will
come soon in VRP and in this case comparing the datatypes of the schema and the
instance can be solved, since we know the hierarchies of these datatypes. E.g.,
a xsd:positivInteger on the instance side would valid to be used with a
property having the schema datatype xsd:integer. More information on datatypes in RDF
can be found in [6].
3.2.
Collections in
RDF
In the syntax
specification form 8th November 2002 [1] collections where
introduced into the RDF syntax. To create a collection the following new terms
are included to the RDF namespace: rdf:parseType=”Collection”, rdf:nil,
rdf:rest, rdf:first and rdf:List. The collection itself, when generated with
the rdf:parseType=”Collection” attribute-value pair, is constructed with blank
nodes of the type rdf:List, which is a rdfs:Class. The blank nodes always have
a link to the current element of the list connected by the property rdf:first,
and a link to the rest of the list connected by the property rdf:rest. The end
of the list is denoted by rdf:nil which is an instance of the class rdf:List,
so, rdf:nil itself is a list.
In the following
example a collection is used to identify the fruits (apple and pear) contained
in a basket. To distinguee blank nodes we entered named them genID:n. In
the following we can see this example in all possible representation forms
(graph, RDF/XML, triples).

Figure 8. Graph representation for a basket
containing apple and pear using the collection construct
Example 2: A basket containing apple and pear using the collection construct.
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:ex="http://example.org/stuff/1.0/"> <rdf:Description rdf:about="http://example.org/basket"> <ex:hasFruit rdf:parseType="Collection"> <rdf:Description rdf:about="http://example.org/apple"/> <rdf:Description rdf:about="http://example.org/pear"/> </ex:hasFruit> </rdf:Description></rdf:RDF>
This example should generate the following triples:
http://example.org/basket,
ex:hasFruit, genID:1 .
genID:1
rdf:type rdf:List .
genID:1
rdf:first http://example.org/apple .
genID:1
rdf:rest genID:2 .
genID:2
rdf:type rdf:List .
genID:2
rdf:first http://example.org/pear .
genID:2
rdf:rest rdf:nil .
As stated in the grammar productions in 7.2.19 of [1] the collection can
be an empty list. In this case there would be just a pointer to rdf:nil and no
rdf:rest.
The default way of generating a collection in RDF is to use the
attribute-value pair rdf:parseType=”Collection” as shown in the example. But
someone could write his own constructs. As you can read in [2] (chapter 3.2.3)
there are currently no constraints on collections. Multiple or none rdf:rest or
rdf:first definitions are allowed, which means the following set of triples
would also be valid:
genID:1
rdf:type rdf:List .
genID:1 rdf:first ex:aaa .
genID:1 rdf:first ex:bbb .
genID:1 rdf:rest ex:ccc .
genID:1 rdf:rest genID:2 .
genID:2 rdf:type rdf:List .
genID:1 rdf:rest rdf:nil .
The question that
arises, does it make any sense? What would it mean to have a collection element
with different values? Would it not make more sense to enter a rdf:Bag instead?
But there is also another question: Do we need the collection construct at all?
Before there are three kinds of containers, rdf:Bag, rdf:Seq and rdf:Alt. The
following table gives an overview about these constructs:
|
Construct |
Description copied from [3] |
Comments and examples |
|
rdf:Bag |
The rdf:Bag class represents RDF's 'Bag'
container construct, and is a subclass of rdfs:Container. |
Representing the mathematical set. |
|
rdf:Seq |
The rdf:Seq class represents RDF's 'Sequence'
container construct, and is a subclass of rdfs:Container. |
Representing a mathematical ordered list.
Hence, [1, 2, 2] and [2, 2, 1] would not be the same. |
|
rdf:Alt |
The rdf:Alt class represents RDF's 'Alt'
container construct, and is a subclass of rdfs:Container. |
Representing an alternative, e.g., “female”
or “male”. |
There are some
differences between containers and a collection. A container in RDF is one
resource containing all its members. The collection is different, there are
many resources linked with each other. These resources are linked with their
value(s) and the end of the collection is denoted by the empty list as the
object for the rdf:rest property. Now here comes the main aim of this new
construct. It defines a fixed finite list of items with a given length and
terminated by rdf:nil, at least this is what we can read in [4] section 4.2.
Reaching the goal? There is no restriction on the structure of
lists in RDF. As shown there can be more than one rdf:rest, more than one
rdf:first and even the existence of rdf:nil as the terminating object is
nowhere forced. By default the collection is constructed with blank nodes but
even this can be changed.
Example 3: A collection with non-blank node.
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:ex="http://example.org/stuff/1.0/"> <rdf:Description rdf:about="http://example.org/basket"> <ex:hasFruit rdf:resource="myCollection"> <rdf:Description rdf:about="http://example.org/apple"/> <rdf:Description rdf:about="http://example.org/pear"/> </ex:hasFruit> <rdf:List rdf:ID="myCollection"> <rdf:first rdf:about="http://example.org/apple"/> <rdf:rest rdf:parseType="Collection"> <rdf:Description rdf:about="http://example.org/pear"/> </rdf:rest> </rdf:List> </rdf:Description></rdf:RDF>This example should generate the following
triples:
http://example.org/basket ex:hasFruit ns1:myCollection .
ns1:myCollection rdf:type
rdf:List .
ns1:myCollection rdf:first http://example.org/apple .
ns1:myCollection rdf:rest
genID:1 .
genID:1
rdf:type rdf:List .
genID:1
rdf:first http://example.org/pear .
genID:1
rdf:rest rdf:nil .
The effect is that by
entering a non-blank node someone could enter also to the collection construct
elements from outside. This means without any restrictions this construct is
not fixed!
What about other
relevant RDF constructs? In
[4] the following is stated: A limitation of the containers is that
there is no way to close them,
i.e., to say, "these are all the members of the container". This is
because, while one graph may describe some of the members, there is no way to
exclude the possibility that there is another graph somewhere that describes
additional members.
But we can also use
blank nodes to identify the rdf:Bag itself. Blank nodes can not be referred
from outside and therefore no further member can be added. ess triples are It
even needs less triples and the graph is more easy to read. The example of the
fruit basket could be written as:
Example 4: The fruit basket using the bag construct.
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:ex="http://example.org/stuff/1.0/"> <rdf:Description rdf:about="http://example.org/basket"> <ex:hasFruit> <rdf:Bag> <rdf:li rdf:resource="http://example.org/apple"/> <rdf:li rdf:resource="http://example.org/pear"/> </rdf:Bag> </ex:hasFruit> </rdf:Description></rdf:RDF>
http://example.org/basket ex:hasFruit genID:1 .
genID:1
rdf:type rdf:Bag .
genID:1
rdf:_1 http://example.org/apple .
genID:1 rdf:_2 http://example.org/pear
.
Without restrictions
on the collection construct it is just a more complex way of expressing things
we already could express before using containers. Possible restrictions can be:
·
Each collection
in RDF must have exactly one terminating rdf:nil element.
·
Each collection
element must have exactly one connection with the rdf:first property.
·
Each collection element
must have exactly one connection with the rdf:rest property.
·
Collection
elements in RDF have to be blank nodes.
It might be too
restrictive to have all these restrictions and there also might be further
reasons for introducing the collection construct. The main difference at the
moment is that a container is one resource containing all values, while the
collection contains different linked resources containing the values. In [1] we
can find in the appendix A.3 that the collection construct was also introduced
to support recursive processing in languages such as Prolog. I hope that the
RDF WG will think about this subject and will clear it.
3.3.
Support for XML
Base
Since March 2002 the
support for XML Base is included into the RDF/XML Specification. XML Base is a
W3C Recommendation specified in [8]. This has no effect on RDF itself, it
rather effects the transformation from the RDF/XML serialization to the other
representation forms. In particular it affects the generation of identifiers
and URI references and can be used to write abbreviated RDF/XML files.
Example 5: Usage of xml:base.
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:ex=http://example.org/rdffile# xml:base="http://mybase/rdffile#"> <rdf:Description rdf:about="basket"> <ex:hasFruit rdf:resource="Apple"/> </rdf:Description></rdf:RDF>
The example would generate the triple:
ex:hasFruit http://mybase/rdffile#basket http://mybase/rdffile#Apple .
This means it replaces the base URL of the file itself that otherwise
would have been used to generate the URI references for the resources “basket”
and “Apple”. This is very usefull, complete URIs are normally very long, for
big RDF files it can result in an enormous reduction for space needed to save
them.
But same effect can also be achieved by using XML entity references like done in example 1 with the RDF, RDFS and XML Schema Datatype namespaces. For human readability the XML entity references should be preferred, since all used entity references can be introduced at the beginning and when they are used the reader notice by the prefix which entity reference was used. Changing the base URL can be overseen and therefore it might be hard to be realized by the user.
There are some
advanced ways of using the base URL. As shown in the test cases in [14] the
base URL can also be used to point to upper nodes in its path. This might be
useful in some cases.
For RDF parsers that
are build on top of an XML parser that supports XML Base it should not be a
problem to include it, since the XML parser does all the work. For VRP it was
quite a bit of effort to include the support for it.
3.4.
External
references in parseType=”Literal”
When using the
attribute-value pair rdf:parseType=”Literal”, the child part of this element
should be a literal with the datatype rdf:XMLLiteral. The latest RDF syntax
specification [5] (see section 7.2.17) says: This specification allows some
freedom to choose exactly what string is used as the lexical form of an XML
Literal. Whatever string is used, MUST correspond to an XML document when
enclosed within a start and end element tag, and its canonicalization (without
comments, as defined in Exclusive XML Canonicalization [9]) MUST be the same as the same
canonicalization of the literal text l. It is often acceptable to use l without
any changes but this is incorrect if, for example, l uses entity references or
namespace prefixes defined in the outer XML document.
Note: Beside the
entity references and namespace prefixes there is also the base URI that is
important for the canonicalization.
How can this task
be solved? Entering all
current valid prefix, base and reference definitions would not be a great
solution. Therefore we first need to find out what is used and then include
this information to the XML Literal. Even for RDF parsers relying on an
existing XML parser it is an extra cost to implement this.
3.5.
Non-namespaced
local-names
Non-namespaced
local-names coursed many problems. The RDF WG therefore decided in 25th May
2001 that all local-names must be namespace qualified. In the latest syntax
specification [1] we can now read that to keep old RDF/XML files valid this
restriction should not be valid. Sure,
it is always great to be compatible with old versions of the standard. The
problem is that there is so fare no version number or creation date given with
the RDF/XML files. This gives the chance that also new RDF/XML files might use
non-namespaced local-names and we will have the problems again.
References
[1] RDF/XML
Syntax Specification (Revises) Nov. 8th 2002, online at:
http://www.w3.org/TR/2002/WD-rdf-syntax-grammar-20021108
[2] RDF Semantics, W3C
Working Draft 23 January 2003, online at: http://www.w3.org/TR/2003/WD-rdf-mt-20030123/
[3] RDF Vocabulary
Description Language 1.0: RDF Schema, W3C Working Draft 12 November 2002, online at: http://www.w3.org/TR/2002/WD-rdf-schema-20021112/
[4] RDF Primer, W3C Working Draft 23 January 2003, online at: http://www.w3.org/TR/2003/WD-rdf-primer-20030123/
[5] RDF/XML
Syntax Specification (Revised), W3C Working Draft 23 January 2003, online at: http://www.w3.org/TR/2003/WD-rdf-syntax-grammar-20030123
[6] RDF Datatyping online
at: http://www-db.stanfort.edu/~melnik/rdf/datatyping/
[7] Sun™ XML Datatypes Library, online at: http://wwws.sun.com/software/xml/developers/xsdlib/
[8] XML Base, W3C Recommendation 27 June 2001, online at: http://www.w3.org/TR/2001/REC-xmlbase-20010627/
[9] Exclusive XML Canonicalization Version 1.0, W3C Recommendation 18 July 2002, online at: http://www.w3.org/TR/2002/REC-xml-exc-c14n-20020718/
[10] Scalable Vector Graphics (SVG) 1.0 Specification, W3C Recommendation 04 September 2001, online at: http://www.w3.org/TR/2001/REC-SVG-20010904/
[11] CUP homepage, online at: http://www.cs.princeton.edu/~appel/modern/java/CUP/
[12] JFlex homepage, online at: http://
[13] RDFSuite homepage, online at: http://139.91.183.30:9090/RDF/
[14] RDF Test Cases, W3C Working Draft 23 January 2003, online at: http://www.w3.org/TR/2003/WD-rdf-testcases-20030123/