W3C | TAG | Previous: 16 Sep |
Next: 9 Oct
Minutes of 24-25 Sep 2002 TAG ftf meeting
Vancouver, British Columbia (CA)
Nearby: agenda | issues list | www-tag archive
All present. Back row in photo from left: Tim Berners-Lee, Norm Walsh,
Stuart Williams (co-Chair), Dan Connolly, Chris Lilley, Roy Fielding, David
Orchard. Kneeling from left: Paul Cotton, Tim Bray, Ian Jacobs (Scribe).

Accepted 16 Sep
minutes. Accepted status of completed action items in the agenda.
Contents:
Editor's Note: The archived IRC logs that we used to
compile these minutes are broken and incomplete due to connectivity outages
at the meeting. These minutes were pieced together from the scribe's local
notes as well as from information from the IRC logs.
The TAG extends hearty thanks to Tim Bray (Antarctica) and Philip
Mansfield (Schema Software) for hosting and providing logistical support for
this meeting!
- [DanC]
- PROPOSED: to thank HFN for help on deeplinking.
- [IanVanc]
- SW: I'd like to thank Henrik F. Nielsen for his help on the analysis
of the Danish linking case.thank Henrik F. Nielsen for his help on the
analysis of the Danish linking case.
- Action PC: Ask Henrik to forward email to
www-tag; thank him on behalf of TAG.(Done)
- [IanVanc]
- PC: Will we do enough work at this ftf to revise the document?
- IJ: My next priority is to get UAAG 1.0 to PR. So I need a little
time to get that done before turning back to arch doc.: But still
expect to be able to have a second draft by mid-October (read: before
the AC meeting in any case).
- [IanVanc]
- CL: Moving more slowly than I expected, but we are hitting the hard
questions all at once. But in the last few months we have picked up
speed.
TB: I'm pretty pleased by and large. I like the progress of the
architecture document. I was very pleased with our intervention on the
SOAP question. In an ideal world, we would go faster, but we're all
busy. I think that at some point our work will slow down, in fact.
- SW: I'm in a cycle of looking just one week in advance; would like to
be looking further.
- DC: I've not found any teleconf a waste of my time.
- PC: I appreciate the agenda being available on Thursday before
meeting.
- TB: The quality of the phone service is not good.
- [Discussion of voice over IP...]
- PC: One issue is cell phone quality and being on the move.
- RF: Tuesday would be better for me (to get work in my head)
- PC: We have not done much to coordinate work on arch outside of
w3c.
- DO: We don't do enough forward-looking work.
- TBL: It would be useful to look forward (e.g., think about sem web
and web services), but I find it difficult to do without a stronger
foundation.
- PC: We are supposed to report AC in Nov 2002 about formation of the
TAG. We haven't done that at all.
- SW: I will schedule time for this.
- Action IJ, SW: Compile list of process
questions AB postponed so that first TAG could answer.
- SW: So people sound relatively happy with the way we're working.
- RF: I'd prefer it if we did more collaborative authoring.: Each of us
writing what we think, connected in a single document, in a way that's
manageable. But not wiki.: I want to be able to write into the
document.
- TB: The conventional process is that the editor records hammered out
consensus.
- DC: Not in all groups.
- TBL: There are problems like my desire to s/resource/thing/g. At
times I copy the latest draft, and annotate class="tim" for what I've
done.
- DC: XHTML editing with CVS is good enough for me.
- TBL: W3C annotation service lets you thread comments; but you can't
print a harmonized version.
- TB: I like the current process of issues list, resolutions, series of
critiques, and editor incorporates. I find the current system of issues
list fairly time-efficient.
- DC: Issues for me are very tied to the document.
- TB: We have web services arch doc coming along. Is there any similar
milestone in the sem web activity, for the TAG to look at?
- DC: There's been talk about a document about how sem web work fits
together. I could tell the Semantic Web CG we want that.
- PC: I think it would be great to have a TAG town hall at XML2002
(in Baltimore)
- [DanC]
- grumble... can't copy/paste date/city from conference home page.
- [IanVanc]
- PC's
info on town hall (Member-only)
SW: Who expects to be at conf: PC, TB, CL, NW, DO
- [DanC]
- " - DC: Need to be able to carry out mundane tasks on the Web," --
yours truly, 7Jan2002, at the 1st
tag telcon
- [IanVanc]
- PC: In two weeks I'm giving a talk in Australia on the TAG.
- TB: I gave my first TAG talk last week here in Vancouver (at the Vancouver XML Developers' Association).
Nobody went to sleep (e.g., on why URIs matter).
- [IanVanc]
IJ: I have been working on TAG election schedule; terms to start 1
Feb.: Any objections to extending terms one month? [None]
- [IanVanc]
TB: Our next (one-day) ftf meeting 18 Nov.
- RF: My regrets for that meeting (Apachecon)
- Action IJ: Find out more admin details
about TAG ftf meeting in Nov.
- On reporting to the AC:
- Expect 30-min slot for the TAG. Who is reporter?
- Top three issues?
- PC: We should seed discussion with recently resolved issues, issues
that have received a lot of discussion, or unresolved issues.: We
haven't had much feedback from AC.
- IJ: I send summaries, but haven't heard back. It may be that tech v.
process may be an issue.
- PC: We may need AC reps to ping people in their company with TAG
summaries.
- TB: I fear that people won't pay more attention to our summaries
until we hit last call.
- PC: When TAG pays attention to an issue, relevant WGs react.
- TBL: My sense about "how we are working" is that we're doing pretty
well: we are reporting, getting input, and we are listening.
- SW: How are we going to prepare for AC meeting and tech plenary
2003?
- IJ: Does the TAG plan to meet ftf during all-WG meeting 3-7 March in
Boston?
- PC: I can't; other WG meetings.
- DO, NW: Same position.
- PC: What if we ask Steve Bratt for a slot at the AC meeting to go
over the arch document?
- DO: +1
- CL: How different from the reporting slot?
- PC: We could shrink the reporting segment and make the discussion
slot longer.
- TBL, CL: +1
- IJ: What's connection with TBL's Director's perspective talk? Should
that be less technical and move tech info to the TAG's slot?
- Resolved: Request a slot at AC
meeting for arch doc review, distinct from short TAG report.
- Summarizing:
- - Action IJ: Send email to SteveB
requesting slot at AC meeting for arch discussion, distinct from TAG
reporting slot.
- PC: If the AB is going to shorten its report (and have a separate
item on the process doc), that the AB and TAG report could be squeezed
in a smaller slot.
- Action IJ: Ask the AB if they agree to
following:
- One shared slot for general TAG/AB report
- One slot for AB to present on revised Process Doc
- One slot for TAG to present on Arch Doc.
.Resolved: No ftf meeting during tech plenary
week.
- Action IJ: Report to admin folks.
- SW: New TAG will be starting 1 Feb.
- NW: Good reason to have ftf mtg early in February.
- DC: I'm fine in Feb.
- SW: I suggest Boston in Feb, then Europe in the Spring.
- Proposed: 6-7 Feb in Boston.
- [TimBL]
- Feb 6 and 7 work for me
- [IanVanc]
- [Some suggestions to have weekend meeting around tech plenary.]
- PC: I suggest having joint meeting with old/new tag folks if Feb mtg
takes place.
- Action IJ: Arrange local, meeting in Feb
2003.
- [DanC]
- Resolved: to meet 6-7 Feb 2003 in BOS
(or a nicer venue nearby).
- [IanVanc]
- Action SW: Take top 3 issues for AC
meeting to the list.
- [DanC]
- hmm... we all said the tech plenary was our most important audience,
then didn't deal with it at all. 1/2 ;-)
- [IanVanc]
- IJ: I think there will be a TAG report there (or should be).: Other
questions from PC:
- Face-to-face alongside WWW2003 in Budapest?
- July 2003 on US West Coast (aligned with AB ftf meeting)?
See httpRange-14.
- [IanVanc]
- TB: What are the bounds of the issue?
- SW: I think that Tim's position on what an HTTP URI refers to is
driven by the principle that a URI should consistently identify one
thing.
- TBL: I haven't seen a way proposed by anyone that allows me to do
what I want to do in the Sem Web.
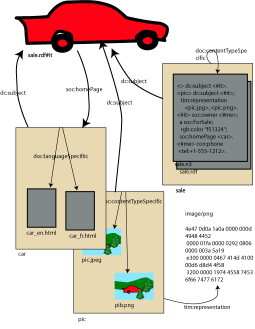
- CL: I put forward a proposal:
TimBL presents his arguments using illustration of
a car (also available as
SVG, but less up-to-date). Thumbnail version:
- [IanVanc]
- See TB
statements on contradiction between unambiguity and change.
- TB: I think DC and I agreed that ambiguity is harmful and should be
avoided. Some people will write assertions in RDF that conflict. This
will happen though. It should be avoided.
- IJ: I hear discussion (rift) between what humans do and what machines
do.
- RF: People link to things based on information they get, not
location.
- TBL: Concerns about human vagueness are absolutely right. But for me
the sem web needs to have different identifiers for Roy and for Roy's
home page.
- [General agreement]
- CL: The arch should cope with the occasional 404.
- CL: Today we have lots of experience with URIs to Roy's home page,
but not to Roy.
- CL: I don't want the mere "#" to totally change what the URI points
to.
- RF: I agree.
- CL: I don't want meaning to hang on the "#".
- [TimBL]
- Chris: I don't want foo and foo#bar to be quite different things
- [IanVanc]
- CL: You know identity in some cases by inspection. But you don't know
the meaning of resource by looking at the URI.
- TBL: Identify sometimes a (unwritten) contract, sometimes a set of
representations.
- TBL shows model where two image formats (PNG, JPEG) are
representations of a resource, but are also resources in their own
right.
- [DanC]
- agenda + Can two different URIs identify the same resource? [CL seems
to think not. I think so]
- [IanVanc]
- (TBL: Most people don't do content negotiation, or other
negotiations. )
- TBL: Now take the case of the car. In RDF, I talk about the car,
pictures of the car, owner of the car.
- [The real car and the real owner.]
- TBL: Semantic Web needs to allow people to distinguish between "the
real car" and a home page about the car.
- DC: If you choose to use the same identifier for both car and web
page, you've said the car is a web page.
- TBL: DC says that you don't know that it's not a web page until
someone gives you more information.
- DC: You can choose different identifiers for car and page, you can.
You can also choose the same, but that's ill-advised.
- CL: The URI doesn't make the subject a car. It's the assertion that
"This URI designates a car."
- TBL: Whatever the abstract thing is, it's the Subject of the document
(the resource "car")
- CL: How is the car a resource? Can I get variants of it?
- TBL: It's not a "network information object". If you read the RDF
spec (or related), in many cases you don't have a representation
available (example of Pantone colors not on the Web, but identifiable).
In some cases, it will be interesting to dereference the URI, but in
some cases you won't have to or want to dereference a URI.
- CL: Do I have to dereference the URI to get back RDF and interpret
the frag id in a particular way.
- TBL: I may send you RDF in an email message saying that
</foo/sale#it> a w:car. If I send you this, you'll know that it's
a car (provided you believe me).
- RF: You can replace every identifier in that email with another HTTP
URI. You are assuming that because you have an identifier, you are
doing a GET on the resource. If I give you a resource and you can't GET
it, why do you interpret that it's not a document?
- TBL: We don't have a way in HTTP of distinguishing car from document.
When I deref something, how can I know whether I am talking about a car
or a document? We could extend HTTP...
- DC: What breaks if you take the "#" out?
- TBL: I deref the URI and I get a representation back (a Web page). I
need to be able to talk about the car, pages about the car, and
relationships among representations. The concept of a Web page in its
own right is very important (and has age, creator, author) that are
independent of ....
- DC: No. It falls apart in the Moby
Dick example (who wrote the book? who wrote the page?)
- SW: What if you replace http: with http://vin.org/ ?
- TB: You get a representation of the resource.
- [TBL goes through another example...]
- RF: Dublin Core dc:create is specifically for
documents. Don't make metadata assertions about both the car and the
web page. I hear mixing of methods and resource. You can identify pages
and other concepts with different URIs.
- PC: I hear underlying problem is that TBL wants to refer to something
that's not on the Web. And he has a particular (recognizable) syntax
for doing so.
- [ChrisL]
- now://example.org/car
- Where 'now' is defined to be a non-dereferencable protocol
- [IanVanc]
- PC: Seems like TBL wants a separate syntax for identifying a class of
objects or their physical instantiation that has nothing to do with the
Web. Tim thinks HTTP URIs are already used to represent something
else.
- NW: Earlier we said that people could make conflicting assertions
(and that errors arise). It seems to me that TBL has a particular
system where documents do not equal cars. Fine. Your system will
produce an error when this (silly) thing is done. I could have a system
with a different set of axioms. Where is the problem? My system will or
will not contain contradictions. They may be different contradictions
than in your system. I think TBL's constraint is not a Web arch
principle.
- [TB presents]
- xml:base="http://example.org/"
- "/car" represents the real car.
- dc:type "car"
- TB: By the way, some descriptive text of car available at /car.html.
That document is also a representation of the resource that is a car. I
can build a functional system that doesn't get me caught in loops. You
can have URIs for different entities; if there's confusion that's bad
(so we shouldn't do that. TB: I would propose that in the arch doc we
say (conflating principles 2 and 7):
- Ambiguity in the relationship between URIs and resources is
damaging (both in conventional Web usage and the semantic Web).
- TB: I think we don't need consensus around what http URIs refer to.
But I think we can skate around.
- TBL: What should response code be when GET on "/car"
- TB: Should be 200. I can send back a representation of the resource.
I could also choose not to send a representation.
- DC: Today, Web servers send back resource location and a
representation of car.html
- TB: It's reasonable to say "/car is red" but not "/car.html is red".
The representation of the car can be a resource in its own right if you
want to make assertions about it.
There is general support for TB's proposed conflation of
principles 2 and 7.
- TBL: I'm trying to decide whether that's good enough.
- TB: Next issue - what, if anything, do we say about the range of
particular URI schemes. Maybe it's the role of the sem web activity to
say that "the premise of the sem web is that HTTP URIs identify
documents (even though there are counter examples)".
- DC: I'm mostly supportive of TB. I have some lingering concerns. I
think there are confusions around terms:
- Resource
- "Resource representation" / "Digital artifact" / "Entity" (in
HTTP sense) / "Instance"
[RF doesn't like "instance" here since not really an instance
(in the sense of instance of a class)]
- cyc:conceptualWork is something "in-between".
- DC: To me, a resource is anything you can talk about.
- [TB: "anything with identity"]
- DC: Let's use "conceptualWork" (or something else) to refer to things
that you can get bits for.
- IJ: Can you give me a better sense of the fidelity expected for a
conceptual work?
- DC: It's fuzzy. Some resources are directly observable. We are
advocating that IETF use HTTP URIs for media type names. What URI
should be used for "text/plain"?.
- TBL: What should the return code be? I think that HTTP may be a way
out of this.
- [CL presents]
- CL Axiom: You can never get a resource, just a representation. In
some cases (e.g., only one representation), they are pretty close.
- [CL talks about different meanings of "creationDate" in car scenario
- you need to say exactly what you mean among several possible creation
dates.]
- DC: Somebody owns pic. Are you disputing that the guy who owns it can
provide a creation date? If I own the resource, I can say when the
resource was created.
- CL Summarizing:
- I assert that you cannot GET resources, only representations.
- Therefore creation dates only refer to representations.
- Conflating the two parts of the model will create a bad
model.
- Put the efficiency in the implementation, not the model.
- TBL: If I get back same-looking representation for both "car" and
"car.html"... In most of the Web, I am talking about pictures, not
cars. People understand that I'm talking about the picture. Need to
distinguish between whether the picture is black and white, or the
airplane is black in white.
- TB: I suggest procedurally that we:
- For next arch doc: Change principles 2 and 7 to be "Ambiguity in
the relationship between URIs and resources is harmful for humans
and machines." Two instances of ambiguity are (1) lack of resources
and (2) confusion about what is identified. Such ambiguity easily
arises; should be avoided. This can be done in practice. Add some
examples.
- We don't need to say what range of HTTP URIs is for arch doc.
- TBL: I think that's reasonable, but doesn't address issue 14.
- [IanVanc]
- Resolved: Accept TB's proposal for
revised principle.
- TB: I propose that httpRange-14 be de-prioritized. Two reasons (1) no
consensus (2) I don't think it affects the arch doc. I would be
amenable to close this issue with no action.
- DC: I agree with TB that httpRange-14 can be closed with no impact on
the arch doc.
- RF: When you access a resource for today's weather in Vancouver, and
you get back info that says "it's sunny", how do you know that it
doesn't mean "it's sunny everyday in Vancouver." When you access a
resource, you need to be able to make assertions about the resource and
also representations of the resource.
- Resolved: "Defer" httpRange-14 with
no action. Objection: TBL.
- [DanC]
- It's essential to me that, in the summary of the issues, this version
of 'closed' is distinguishable from things like issue 7, which we
actually addressed in substance.
- [IanVanc]
- I didn't propose saying this issue was "closed" but rather "decided",
with disposition "deferred". We always have decisions in the end. In
this case, the decision is to do nothing.
Lunch.
See namespaceDocument-8.
- [IanVanc]
- TB: Namespaces are just names. There is angst in the community about
dereferencing these URIs. It's arguable that it's an architectural
issue or that it's not.
- RF: All HTTP collections ("directories") are namespaces...
- TB: I published theses
regarding namespaceDocument-8.Two use cases at least (1)
schema-like info (2) assertions in sem web that can be used for
inferences. Some pushback about RDDL. We reformulated in RDF. Some
options:
- We could say that this is not an architectural issue. Maybe XML
Core could take this up.
- We could stop with a principle or finding that it's good practice
to put something at the end of a namespace URI, with use case
scenarios.
- We could go so far as to recommend what should be found
there.
- TB: If you don't do anything, some bad things can happen - either
human-readable or machine-readable; and I don't think coneg helps you
out. Media type is not sufficient granularity. HTML has three
DTDs...
- [ChrisL]
- but all have the same media type
- [IanVanc]
- DC: I think content negotiation solves the problem in TB's case.
- TBL proposal: Establish the convention of putting an xhtml doc with
embedded RDF having (1) made a statement that when RDF is embedded in
HTML, it's valid for processors [and change schema accordingly].
- DO: Who would take the spec to Recommendation?
- TBL: The piece about putting RDF anywhere in HTML is a generically
useful action. We'd also need to say that RDF parsers can ignore HTML
parts. The question who says about who ignores what is interesting; not
quite html wg or rdf core.
- PC: I don't think the TAG should do this work.
- TB: Notion of embedding RDF is easy. RDDL comes with a pre-cooked
vocabulary (nature and purpose, which some predefined purposes). The
task would involve (1) statement of embedding policy (2) documenting
precooked vocabulary.
- TB: I think you can't get around writing a specification.
- PC: I think the TAG needs to ask the Membership whether they want
this done.
- TB: I would be willing to change RDDL.
- PC: Delegating this to someone (e.g., XML Core) may be the way to go.
I'd personally prefer that this work be done by a technical WG.
- RF: This doesn't change the arch doc (since "SHOULD"). Let someone go
off and design the format.
- PC: I want to be sure that I'm not FORCED to dereference.
- RF: There are two separate questions: can be dereferenced v. must be
dereferenced.
- DO: We should ask TB and Jonathan Borden to update the spec, and give
that work to the XML Core WG; if they don't want to work on this we
should find some other group. I would like to do this as a more
forward-looking step.
- DC: Is it ok to delete "Issue 8" from its placeholder location in the
arch document with no harm? The RDF Model and Syntax Recommendation in
1998 has an appendix
for including RDF in html docs.
- TBL: The proposed solution to this issue, touches on the issue of
language mixing (mixedNamespaceMeaning-13).
Content negotiation would work, but I would have a problem with coneg
when the documents you get back talk about different things.
- [DanC]
- [I don't think it's a "problem" that WGs aren't dealing with
namespace mixing; if the solution were apparent and being ignored, that
would be a problem. But I don't think a solution is apparent.]
- [IanVanc]
- RF: If we are making specific principles of w3c groups, or others
(e.g., dereferencing namespaces), these should be called out separate
from web architecture.
- TBL: I propose finding that documents should be self-describing using
the Web. Should we have a separate sem web arch group?
- RF: I think you should have a separate sem web description.
- [RF on multiple architectures...depending on tasks.]
- CL: On mixed namespace issue - if rdf is root element, does that mean
something different than if html element is root?
- TB proposal:
- TB could take an action to recast RDDL in RDF and turn it into a
W3C Note, for review by the TAG.
- SW Summarizing where we have gotten:
- TB volunteers to recast RDDL in RDF and publish at Note.
- Proposal from DC to strike line in arch doc pointing to issue
8
- DC: The HTML WG needs to be party to this agreement.
- TB: Right, xhtml modularization designed to accommodate this.
- DC: When technologies first deployed, original WG usually consulted
to see if done the right way. Please consider charter (or portion) for
what a WG would have to do.
- RF: If we have lots of RDDL docs at ends of namespace URIs, what's
the problem?
- DC: They don't validate.
- DO: I will write up the charter bits for what a WG should do.
- Action TB: Revise the RDDL document to
use RDF rather than XLink. Goal of publication as W3C Note.
- DO: Should the namespaces spec change?
- DC: Yes, it should.
- PC: I think that DO has a good point. We could get the Core WG's
attention by making a last call comment; namespaces 1.1 is currently in
last call.
- CL: Namespaces 1.1 only applies to xml 1.1 (not xml 1.0).
- [DanC]
- From XML
Namespaces 1.1: "this revision is being tied to the 1.1 revision of
XML itself"
- [IanVanc]
- DO: We'd like to see a change to namespaces 1.1 along the lines of
(1) add "should" be able to dereference for this type of document and
(2) the TAG will work on what type of document that is.
- NW: Won't this delay Core WG indefinitely?
- DC: I'd be willing to ask for a delay of 2 months.
- [DanC]
- (namespaces WD went out 3 Apr 2002)
- [IanVanc]
- TB: XML Core WG is not going to be happy with our request to make
this change.
- [DanC]
- DO: "It is not a goal that it be directly usable for retrieval of a
schema (if any exists)." -- http://www.w3.org/TR/2002/WD-xml-names11-20020905/
- [IanVanc]
- SW: What is the positive goal?
- PC: I have concerns that this proposed change is out of the scope of
what they agreed to do.
- CL: I think that a last call comment for namespaces 1.1 will not
achieve what we want.
- TB: I disagree. People will start doing it.
- NW: I agree, the MUST in the last call doc won't be a problem.
- [DanC]
- [the positive goal from the Arch Doc is: "Owners of
important resources (for example, Internet protocol parameters) SHOULD
make available representations that describe the nature and purpose of
those resources."]
- [IanVanc]
- PC Proposal:
- We do what TB says - we solicit creation of a (RDDL) Note.
- We actively figure out how to put into the w3c work plan.
- NW, TBL: Let's ask core wg to do this for namespaces 1.2
- DC: We should get this on the public record, and indicate we realize
not quite right for 1.1.
- [DanC]
- [this = relationship between Namespace revisions and TAG issues, e.g.
#8]
- [IanVanc]
- DO: So should this be in 1.1 or later?
- TBL: I think it's legitimate to leave core wg to leave 1.1 as is.
- Resolved: Draft a letter to the core
wg as part of the last call process saying: (1) this has been a TAG
issue, (2) there is substantial sentiment towards providing some best
practice about what a namespaces URI should point to, that (3) that the
intention of the TAG is to publish a W3C Note with info about what to
find at end of namespace URI and that (4) while that it may not be
appropriate for namespaces 1.1, it's important to get discussion going
in the public space.
- TB: I think for us to let last call go without a stake in the ground
is a mistake. But make clear that it's not a directive from on
high.
- Action TB: send a draft email to
tag@w3.org.
- See issue contentPresentation-26
- [IanVanc]
- TB Proposal: In chapter 3, make a best practice statement saying that
there are significant benefits to the separation of content from
presentation in the Web spec, to the extent possible.
- [DanC]
- [does the WAI spec already say this somewhere?]
[IJ: Yes, in XAG 1.0:
2.2 Separate presentation properties using stylesheet
technology/styling mechanisms.]
- [IanVanc]
- CL: I think this should be a principle, not a best practice note.
- TB: I have encountered many applications where you can't make the
separation (though I think it's a good idea generally to do this). It's
clearly not a MUST to me; but clearly a SHOULD.
- NW: I agree with TB.
- Action CL: Draft text on this principle
of separation of content and presentation.
- [DanC]
- [I'm hoping for specific examples. XSL-FO, "multimodal publishing",
mobile, ...]
See issue xlinkScope-23.
- [IanVanc]
- [DC goes through various groups that used xlink and those that did
not.]
- DC: NW said that "Whatever the poison, I can swallow the pill; just
give me ONE pill." In the end, we felt that this may just be a
marketing issue.
- IJ: I think there is agreement that there is benefit to reuse, but we
don't perceive today buy-in. That was part of our discussion
yesterday.
- [CL on HTML WG history of use of xlink]
- Seebackground
from Mimasa(Member-only).
- CL: The SVG WG thought there would be support for xlink, but support
is waning. I see that HLink is entirely specific to xhtml. We should
either deprecate Xlink or do whatever, but I agree with NW that we need
one solution. Not sure what technology is the right one, but I would
like to see one solution.
- [General agreement that in any case HLink needs fixing.]
- TB: Given that xlink is designed for user interface application of
hypertext, if browser vendors had implemented xlink, people would have
picked it up. The fact that the HTML WG has decided not to go towards
xlink is a bad sign. HLink as posited is bogus. Not sure why it needs
to exist. Not sure of benefit to retroactively design something that
pretty much works. I think HLink has pieces that don't work (e.g.,
longdesc in three languages. Given my druthers, at the moment, for UI
applications of hypertext, xlink is a substantially superior design
base. Why has nobody proposed user-definable multi-ended links to html?
If they had done that, what alternative would they have suggested for
doing it?
- TB summarizing: For UI-oriented applications of xml, xlink
is basically a sound design. If it's not to be used, a sound technical
reason must be given why. In any case, HLink needs a lot of work.
- RF: XLink is not backwards compatible.
- TB: The XLink WG had this in their charter and didn't deliver on
this.But the xlink wg wasn't convinced of the benefits.
- DC: But it was in the xlink wg charter.
- TB: We didn't deliver on it, but not through oversight. We didn't
want to recreate architectural forms. You had attributes on
attributes....
- CL: I note that Mozilla supports simple xlinks (but not extended).
See Mozilla claim
and doczilla xlink
demos (and other demos).
[DC: hmmm... demo doesn't work in the use case I'm interested in:
http://www.w3.org/2000/08/w3c-synd/home.rss]
[DC: Demo works in Galeon, which is build from Gecko.]
- TBL: Can HLink be phrased as a constraint on xlink? Different ways:
namespace or app info. [Scribe uncertain about this
statement.]
- TBL: We could ask HTML WG to reformulate HLink in terms of XLink.
- PC: We should ensure when our issues are tied to documents (and their
schedules). The xlink wg was originally asked to map its work back onto
html. I think we need to make a strong statement about whether we think
these two technologies should evolve in parallel, to see which one
wins.
- DO: Design goal of xlink was 'link detection at run-time'. Another
way to do this is at schema evaluation time. "Design time v. run time".
Maybe both needs exist (HLink requirements might be addressed with
design-time solution). Maybe this is a case where "only one solution"
is not applicable.
- NW: With xlink, the only difference from html was that you had to say
xlink:href instead of href. I have been waiting for years to get a
linking solution for DocBook. I don't want to reinvent things. I want
just one solution. XLink gives you both design time and run-time
solution.
- DC: Two points:
- I was disappointed when xlink came out that they didn't bother to
make the html syntax workable. But that time has mostly passed.
- Since yesterday, this has appeared to me as a marketing issue.
XLink seems to be a solution to 80% of user issues. Should the TAG
do some marketing here?
- DC: I'm leaning towards encouraging re-use at this point.
- TB: If we think that the HLink approach has validity and should be
pursued further, I think we should look at ISO
Architectural Forms work ("This attribute is one of those...").
Given that HLink does kind of the same thing, someone should take an
action to talk to the HTML WG to find out if this has been
researched.
- [IanVanc]
- TB, improvising some proposals:
- Declare this issue closed. XLink is available and can be used.
And that's all.
- We could assert that the TAG thinks there are substantial
benefits to having one place that explains how to do hypertext
markup for doing user interface-oriented applications. But not say
which one.
- We could ask W3C to deprecate XLink since not catching on.
- We could say that we feel that HLink as it stands is not a
productive direction for a W3C WG and needs to be substantially
revised or something ....
- CL: Summarizes as (1) everyone use Xlink (2) everyone use HLink (3)
do what you want.
- RF: Another option: Fix XLink. If XLInk is going to be the one
solution, it needs to accept requirements from others.
- TBL: Do you mean in feature requirements?
- CL: Syntax requirements not backwards compatibility.
- [DanC]
- "XLink must support HTML 4.0 linking constructs." -- http://www.w3.org/TR/1999/NOTE-xlink-req-19990224/
- [IanVanc]
- TB: Writing a change to xlink to add some more markup to the xlink
namespace to do the hlink-style attribute remapping; with a statement
that this should only be used for backwards compatibility. But I think
the HTML WG would not want xlink namespaces in their html.
- TBL: There's a larger battle here about whether people believe in
namespaces at all.
- CL: Tantek Celik thinks there should be one W3C namespace. [That
makes his job easier when he has to implement W3C specs] There are a
number of html link features that would break xlink if tried to be
incorporated (e.g., hreflang).
- [DanC]
- [Marshall rose's DTD for Internet drafts puts human text in attrs.
bummer, that.]
- [IanVanc]
- CL: What would drive xlink if there were implementations of the more
interesting things.
- TB: Maybe the world doesn't care about multi-end hyperlinks.
- TBL: Are we trying to clean up specs so that implementing them will
require less code (or less application-specific code)?
- CL: Is the market for these components only W3C specs or other xml
vocabularies?
- TB: XBRL is an example that uses components.
- [TimBL_]
- <wg:requirement wg:for="XML 2.0 " wg:needed=>XML content in
<s>attributes</s></ wg:introduced="tag">
- [IanVanc]
- NW: HLink doesn't require you to type the colon.
- SW summarizing:
- XLink exists, is being used, has been implemented in at least
Mozilla
- Covers most of what people want it to cover...........[SW cut
off...]
- TB: The HTML WG will come back for the 100th time and say "XLink
fails the backwards compatibility requirement." What do we say to this
"Go home? We will recommend that this be fixed this if you agree to use
it?"
- TBL: I am not sure how many of the multi-end features have been
implemented. Alternative proposal:
- Some parts of XLink have been implemented.
- XLink is a bit more powerful, gives linking a namespace.
- A possible stance would be to abandon (through lack of interest)
the multi-end links, even though defined.
- We suggest that xlink simple links be used for simple links.
- [ChrisL]
- Reviewing article "XLink: Who
Cares?", 13 March 2002 by Bob DuCharme:
"The only project with more than three "yes" entries in the
table's eight columns is Fujitsu's XLiP, the "XLink Processor." Its
XLink engine advertises support for XLink simple and extended links,
including support for locator, resource, and arc elements. The engine
itself isn't available, but..."
- [IanVanc]
- DO: Generic linking doesn't solve any particular problem really well.
No killer app to make it take off.
- NW: Not sure that removing multi-end parts of xlink would help us
solve the current problem.
- RF: There's still a missing bit of xlink that doesn't adapt to
existing grammars.The missing bit: if you have an existing grammar with
defined attributes that refer to hypertext link relationships, there's
no way to say in xlink "By the way, this attribute is a link".
- NW: Even if xlink provided that feature, you'd still have to revise
the DTD/schema.
- TBL: But you wouldn't have to change the instances. You would
retroactively change the schema. Yes, I would change the schema without
changing the instance.
- TB: Point of information "eXtensible
Business Reporting Language" (xbrl) uses extended links (see
section 5.3.2)
- [[[Extensible Business Reporting Language (XBRL) 2.0
Specification]]]-- XBRL Draft Specification -
2001-11-14http://www.xbrl.org/TR/2001/XBRL-2001-12-14.htmWed, 27 Feb
2002 22:33:33 GMT
- TB proposal: XLink is designed for precooked xml markup for
describing hyperlinks in user interface-oriented applications.
- TBL: I note that there's a dependency here on xml namespaces.
- RF: And this is for "new" doc formats.
- TB: I would like to say that if html wg adds multi-end links later,
to use the baked part of xlink.
- DC: If what TB and TBL said is true, our response to HLink spec
should be "no".
- TB: So HTML WG SHOULD use XLink for XHTML 2.0 unless there is
substantial technical reason why not.
- [Some support for that]
- Action NW: Draft an email (for TAG
review) suggesting to the HTML WG that XHTML 2.0 should use XLink for
hyperlink constructs, or provide a technical explanation why that's not
a good design decision.
- DC: We are not asking for explanation at this point. TAG simply
suggests that the HTML WG SHOULD use XLink. On the basis that fewer
technologies is better for the world.
- No dissent to suggesting to HTML WG to use XLink in XHTML
2.0.
- See rdfmsQnameUriMapping-6
Original question from Jonathan Borden:
It seems to me that the RDFCore and XMLSchema WGs (at the very least)
ought to develop a common, reasonably acceptable convention as to the
mapping between QNames and URIs. Perhaps this is an issue that the TAG
ought to consider (because it is a really basic architectural issue)."
- [IanVanc]
- TB: RDF names things using QNames, and specifies a way to turn qnames
to URI (refs). Other places use QNames to identify things, and in those
places, no agreed way to turn QName into URI ref. This is a perceived
problem.
- TB: We could say:
- That's ok. In some cases it's ok to name things with two-part
names (local part + URI ref)
- No, if you are to name things with QNames, you'd better provide a
rule for building URI refs.
- Not only do you have to do this, here's how to do this. (And I
think concatenation is the only reasonable way).
- DC: Specific case that came up, something like
~~~~~~~XMLSchema#decimal. When you write XML Schemas, it shows up
something like xsi:type="decimal", and I think you can say something
like "dt:decimal" where dt is xmlns:dt="~~~~~~~XMLSchema" [no
hash].
- DC: Meanwhile, in RDF-land, people see the URI ref
"XMLSChema#decimal" and are happy. In RDF you can write
<dts:decimal>10</>, binding :dts="~~~~~~~~~~XMLSchema#"
[with hash]
- DC: People unhappy to see hash in RDF context, and no hash in schema
context. XML Schema spec introduces machinery for other data types,
with a mechanism for qnames but not URI refs.
- RF:
- The relevant principle is that all important resources should
have URI refs. That answers the question about whether there should
be URI refs: yes, they should not be tuples.
- Possible solution to this is: here's the algorithm for
constructing the URI ref from the namespace URI: If it ends in an
alphanumeric character , then add # before concatenating the name,
otherwise just concatenate the name to the namespace URI.
- CL: There's a problem with that if the character is escaped.
- DC: I agree with RF that it's nearly what RF said.
- NW: I think that the schema wg is actively working on this issue.
- PC: Right. The difficult problem is that some schema types are local;
not visible outside schema.
- DC: Those don't need URIs.
- NW: I think the schema wg should have a chance to get the first wd
out.
- DC: All the ideas I've seen so far would make the RDF WG happy.
- TBL: There's a problem of same qname used as both element and
attribute name in same context. Is there a problem that the RDF WG has
with mere concatenation?
- SW: RDF labels nodes with URI refs, and uses a Qnames as a means to encode
URI Refs. ie RDF is more concerned with the URIref->Qname->URIRef mapping
and less concerned with a Qname->URIRef->Qname mapping.
- DC: If you process RDF with xslt, the xslt only cares about the
qname. There are RDF users who care that the QName mapping works both
ways. So, even for some RDF cases, it qnames matter.
- RF: Element/attributes are not in same namespace; it's hierarchical
(element.attribute).
- DC: The schema wg is chartered to do this. We could send the Schema
WG a note saying "We have this issue; you are chartered to so this;
please notify us when done."
- TB: At the moment, the only observed place where this is biting is in
XML Schema. Is there a larger problem that's lurking here (where qnames
are being thrown around)? I'm not aware of other examples.
- Action DC: Write to Schema WG to say that
TAG is interested in progress on this issue.
- SW: Please copy Jonathan Borden and Brian McBride to ensure they are
aware.
- Adjourned.
All present except Paul Cotton.
Reference draft is 30 Aug 2002
draft.
- [Tim-TAG]
- RF: Looking at the arch doc, I had to figure out what people meant by
architectural principles. Do we mean general principles like
simplicity, or do we mean constraints that we had imposed?
- DanC: It is in fact discussed in section
1.3:
-
"This document focuses on architectural principles specific to or
fundamental to the Web. It does not address general principles of
design, which are also important to the success of the Web. Indeed,
behind many of the principles of Web Architecture lie these and other
principles such as minimal constraint (fewer rules makes the system
more flexible), modularity, minimum redundancy, extensibility,
simplicity, and robustness."
- [DanC: Also in section 1.4.]
- TB: People bandy the word "architecture" around all the time and what
they usually mean is the major design decisions. A general decision
across the board.
- RF: There is no physical dividing line. My idea of software
architecture is to focus on one aspect of the system. You don't focus
on more than one at once. So I wanted to discuss the principle, not the
constraints. Principles are things that guide our decisions.
Constraints are particular decisions based on those principles.
- [IanVanc]
- TBL: I think there has been confusion on the list about what
architecture is. Our job is to list the constraints.
- RF: Constraints without motivation is a recipe for argument.
- [Tim-TAG]
- RF: Our job is to list the constraints and the argument behind it. We
can negotiate with WGs too.
- DO: My interpretation is broader. You talk about it applying to "a
particular phase". I look at it as looking at all the phases.
- RF: Phases form a time scale. You can look at one level at a time. To
look at all at once is possible but complicated.
- [IanVanc]
- RF: Think in 10-year time scale. I don't know how to contribute to
the document as we are proceeding.
- [TimBL-TAG]
- RF: I have a problem that we are addressing everything at once
- [IanVanc]
- TB: Yes, I agree that what's in the boxes are constraints.
- [TimBL-TAG]
- TB: I agree we can look at different views.
- DO: Is that what you mean?
- RF: All the constraints are always applicable.
- DO: Yes ... 4+1 views of architecture from Rational.
- TB: Our current constraints (see section 1.4) are long-term.
- [IanVanc]
- TBL, CL: This is too abstract for me.
- CL: There's a marketing issue here if you call them "constraints" or
"restrictions".
- [Ian will scribe]
- [TimBL-TAG]
- I found what RF was saying too abstract to understand... too
vague.
- [IanVanc]
- RF: The principles that TBL has about "unambiguous URIs" is not a
constraint (we can't force it). But we can say that there's a principle
that if you don't do this, bad things will happen.
- TBL: The TAG is not defining components. The TAG is documenting
global constraints. We may need to fill gaps, but our job is not to
plan for the next 20 years.
- DO: Chartering of WGs is not architecture.
- TBL: I think that we should accept that there are different forms of
architecture. The Web Services Architecture WG can't define general
constraints. They don't glob into domains.
- RF: I think these are just different abstraction levels. But it's
still one architecture, and still one definition of architecture.
- DC: There was a block-diagram with clients in servers when I got
involved in the Web... The document doesn't have a definition of
architecture and I don't see any pain in that.
- IJ: Functionally, it would be good to have more motivation in the
document.
- RF: Describe the global requirements on the system, such as
- Independent deployment of components.
- System scales across multiple organizations.
- We have to anticipate versioning, change, and we have to do other
things in the protocol design to incrementally adopt changes.
- DO: Yes, functional requirements of the system. And some
non-functional requirements (e.g., scalability, robust error handling,
minimal interactions)
- CL: Some of what we have today is issue-driven. I think there would
be little disagreement about areas that RF is describing. We've focused
on what people disagree on.
- DC: Yes, I'd like to see more motivation; principles should be
conclusions not starts of arguments.
- TBL: Perhaps we do talk about modularity.....when we've said xhtml
ought to use xlink. On the topic of functional requirements: that makes
sense in a project that has an end (e.g., building a coffee machine).
However, with the Web, new pieces come along (e.g., voice browsing). We
don't have the requirement of defining the Web in a manner that will
terminate. I like the constraint approach (backed with principles) is
that we can make the fewest number of constraints so that the Web
continues to work. When the next wacky thing comes along, still we will
want to preserve the existing Web.
- RF: No need to start again. Just give direction. If I could feed Ian
text on how to describe these as constraints and principles, I would be
able to contribute more.
- TB: Sounds like we've all bought into the notion that we are writing
constraints.
- DC: Some of those we want to keep are not constraints. E.g.,
"Representation retrieval is safe" is not a constraint.
- TBL: There is a balance: there are things like "persistence" at that
level, but we only put "persistence" there since it's been a problem. I
agree that this document is not the "complete" Web architecture book.
The list is a mix of high-level and low-level bits.
- RF: By confusing principles and constraints, we are creating
arguments where we don't need them. We don't need to constrain the
architecture, but we need to motivate the principle. It's a principle
that persistence is necessary since if you don't do it it's damaging.
An example -
- Principle: The more things on a network, the more useful the
overall system.
- Constraint: All important resources should have a URI.
- IJ: What's the difference between the agent-less principles and those
that include SHOULD/MUST/MAY? How do agent-less statements fit into
RF's model? Are most of the constraints agent-less?
- RF: Generally when you specify a constraint it's targeted.
- TBL: I'm happy with the document, but it needs some philosophy. When
you use the Internet, you sign on to the Internet protocols. You sign
on to the meaning of specs. It's worth making the point that we work
with specifications.
- TB: People need to see assertion of the right thing to do; and where
to go to find more information. I'm hearing:
- There should be more progression from principle to constraint. We
may draw the box around one or the other (and the box may be the
same color even ;).
- I also hear RF suggesting that that document be organized around
different phases; I'm less confident of our ability to break down
beyond identifiers, protocols, and formats.
- RF: Can we get rid of the title of the principles? Risk of saying
inconsistent things.
- TB: Pithy identifiers that are not numbers are useful. Maybe we need
just short labels. I also suggest getting rid of the numbers.
- CL: About "This document does not address architectural design goals
covered by targeted W3C specifications". We should say instead:
"There's more detail over there." Not that we don't deal with it.
- Resolved:
- Adopt CL's proposal about intro text (i18n, wai)
- Shorten statement titles to one-word labels.
- Delete numbers from numbered list in section 1.4.
- TB: I suggest that we take one test case, and see how RF's model
would work.
- Action RF: Propose a rewrite of a
principle to see if the TAG like that.
- [Ian]
- [CL comments on text in current draft]
- [DanC]
- Timbl: the "use XLinks, not IDREFs" is corollary of "use URIs"
- [suggestion: "page" for 'presentation object']
- [Ian]
- IJ: Question - what's the scope of the formats section? Should we
limit ourselves to things that are just crucial to making the Web
work?
- CL: I think it's important to also have information about things
other W3C WGs need to know.
- TBL: I'm happy when we do this work by defining a little here and a
little there.
- [One multiple doc formats]
- TB: In both opendoc and oda, the failures, as I understand it, were
due to the fact that they tried to aim too high. SGML survived, in
part, since it doesn't address presentation.
- TBL: CSS + XML may work today since CSS is not in SGML.
- TB: The reason CSS is great is that it's strongly decoupled from the
document format.
- RF: "Independent specs for orthogonal problems."
- TB: Here's how CL's comments mesh with our
discussion on Monday(TAG only). A resource representation
(shortened to "representation") consists of metadata and a bag of bits
(or, octet sequence). We should explain how "representation" maps to
other specs (e.g., HTTP). We can already hang some findings on this
statement (e.g., "# Internet Media Type registration, consistency of
use")
- [DanC]
- note to self: remember to come back to 'how much metadata?'. I need
it to NOT be open-ended. I can live with 'exactly a mime type'.
- [Ian]
- TBL: It's an important principle that you need the metadata for the
system to work ("competition for suffixes" reflects that this is an
ongoing struggle on local systems). The metadata is still there off the
Web (in the system registry).
- DC: You can represent the content type as ".html" as long as you
don't screw up.
- TB: Section three should start off with:
- Data on web manifests itself as resource representation
- A resource representation is metadata + bits
- Web metadata...
- Web bag of bits...
- The following principles apply...
- TBL: CL's text doesn't fit into part 2 of that outline.
- TB: Once you know by reading the metadata (image/svg+xml), then there
are useful things you can say about what goes in the bag of bits.
- CL: What about self-describing data? We are saying here that if no
metadata, it all breaks.
- TBL: We are saying that the meaning of the document depends on the
mime type. The way the specs are written is that the interpretation of
the bag of bits depends on the mime type. When you use XML, you can use
less metadata since lots of the (mixed) content is
self-describing (after the initial mime type). We are not saying that
external metadata always overrides what's in the document.
- TB: Two meta issues to solve (1) how do we organize this section? I
think this outline + CL structure addresses issues I'm aware of.
Meta-question 2: What are the principles that fit in? Which of what
we've written are principles?
- Reviewing 3.3
(ideas and issues)
- TB: We should say that "When designing new languages, the following
criteria [for example] suggest that you use XML: requirement for
persistence, requirement for I18N, requirement for clean
error-handling."
- TBL: I think you should add that: when you need structure, and when
there's a MIX of structure and text content.
- [Discussion of whether MIME would work in XML]
- TB: I think we can agree that the document to say something about XML
and when it's desirable: e.g., for I18N-ized content (agreement),
supports early detection of errors (agreement), for mix of structure
and substantial amounts of text.
- DC: It will be cheaper to use XML. "If there is some chance of
persistence" since there's lots of redundancy.
- CL: Composability.
- TB: So it sounds like we have some signposts for when to use XML.
[Agreement]
- IJ: After you say "when to use xml" what are the principles for using
XML (e.g., follow the XML
Accessibility Guidelines)?
- DC: Whatever specs we endorse, let's endorse individual specs.
- TBL: I move that you shouldn't use XML without using XML Namespaces
(agreed).
- DC: We endorsed xlink with a smaller scope (for UI applications).
- TB: We have only agreed to XML + namespaces. We have separately
agreed to xlink in some cases.
- "# Format designers should use URIs without constraining content
providers to particular URI schemes. What does "use" mean? IDREF v.
linking - web-wide rather than document-wide references.'
- IJ: This is here and not in section 2 since this is about use of URis
in formats.
- RF: We already agreed to the first sentence (independence of
orthogonal specs).
- [Discussion of first sentence only.]
- DC: I can't agree to "Format designers should use URIs without
constraining content providers to particular URI schemes." There are
better ways to express this.
- TBL, CL: It's worth saying something about using Web-wide, not just
document-wide, linking.
- DC: Are we going to have a section on Web-izing formats (i.e., taking
existing ones and changing them)?
- TBL: The principle of information-hiding is contrary to global
identifiers....Shall we put in the document something about information
hiding/independent design of orthogonal specs? You should should not be
able to write an xpath to peek into http headers....
- Action TBL: Propose some text on
information hiding for the arch document.
- Action CL: Redraft section 3,
incorporating CL's existing text and TB's structural proposal.
See namespaceDocument-8
and mixedNamespaceMeaning-13.
- [IanVanc]
TB: On namespacesDocument-8, we have an action item. We have an
assertion we agreed to yesterday (1) namespaces docs should be there
(2) should be something like RDDL.
- RF: I don't know, but I think there should be a section on namespaces
in the arch doc.
- CL: I think this should be a best practice note.
- Action NW: Write some text for a section
on namespaces (docs at namespace URIs, use of RDDL-like thing).
- TB proposal regarding mixedNamespaceMeaning-13: We haven't been able
to get consensus around TBL's processing proposal. I think we can say
that "Format designers should give serious consideration to, and should
document, the effect of embedding content from other namespaces and
when embedded in other namespaces."
[Support for this proposal from DC, TBL.]
- CL: Example of a policy - if you want to include something to be
rendered, include it here. Otherwise, it will be ignored.
- TBL: To be more specific, the way you should do this: there should be
widely defined classes of things you can embed. E.g., a class of
"things that can be embedded here but will only be regarded as a
comment".
- (Different axes: presentation, semantics, ...) I see the TAG's task
of saying in principle, showing how to do it, and including enough
rallying points in specs.
- TB: XLink is a good example - embed me when you mean for action to be
taken.
- DC: xlink:href in xslt doesn't mean follow me; it means generate a
link (generally).
- Resolved: Accept TB's proposal for
mixedNamespaceMeaning-13 for formats section.
- TBL: We have two conflicting observations here; we probably should
have both:
- It's useful to say what
xml:lang means in a very
large number of cases, without too much effort
- We also need to allow other specs to use
xml:lang in
other ways (e.g., xslt outputting it).
- TBL: you can't, in xml, resolve the battling attributes problem ("I
override this other thing no matter what the other thing says."). You
can give an algorithm for interpreting documents to try to resolve this
(see the top-down
processing model).
- TB: I don't see how you can say that, given existing specs.
- TBL: You could have a small number of categories (generic) that would
work in specs. E.g., XML functions.
- TB: Some examples to back proposal (a): XLink, RDF
- DC: You can mix lots of RDF vocabularies together.
- TBL: RDF solves a lot of these problems - doesn't have the problem of
battling namespaces. RDF doesn't have the right to say "you can't write
XSLT". RDF has gone further than most specs in saying how to be
embedded.
[Lunch. Paul Cotton rejoins meeting.]
[We reviewed Norm Walsh's draft email regarding XLink, which he
revised and sent to www-tag; seeXLink
email.]
[We reviewed Tim Bray's draft email regarding namespaces, which he
revised and sent to www-tag; seeNamespaces
email.]
- [IanVanc]
DO: I've been asked to be on the program committee. I'd like
substantial TAG participation in that day. Some ideas:
- TAG fishbowl. TAG on the stage or having a meeting of some
kind.
- Technical slot dedicated to a particular area of interest. E.g.,
REST v. Web services.
- [DanC]
- hmm... logistics (e.g. audio) of "TAG fishbowl" look unworkable to
me.
- [Ian]
- PC: I could see a model where the TAG runs the tech plenary (and the
planning committee would be TAG participants). Some people appreciate
the Chair-training process aspects of the day, some do not. People made
it clear last year that the day should be largely technical, with TAG
driving agenda.
- IJ: I think other group input is important.
- SW: How much work is it to organize the day?
- PC: TBL, DC, and I organized the first tech plenary over the phone.
Not much work involved in planning the day. I think the TAG should play
a heavy role in the organization of the day.
- IJ: The "fishbowl" proposal is tricky for a number of reasons. Among
others, experience from the AC meeting is that people don't like to sit
there and watch.
- DC: There are issues of people being able to hear us in an audience
of 150.
- PC: Also, we can't be unaffected by presence of 150 people.
- TBL: What we could do is re-enact. Use the Socratic method to show
people we understand views A and B.
- DC: Lightning talks on TAG issues (anybody gets 2 minutes).
- TBL: It's good to let people give input on things we haven't
discussed.
- SW: Does the TAG want to volunteer to take over some or all of that
day? What active role does the TAG want to take?
- DO: And what are good ways to get technical discussion going?
- Unlikely to attend: SW, TB, RF
- IJ: I'm happy to hear reports of progress on this.
[There was no formal resolution, but a general sense that those
already involved on the program committee should continue as they are
doing.]
- See summary
of comments.
- [DanC]
- [DanC will scribe for a bit]
- RF: REST shouldn't be in a section about protocols
- TB: how about moving "see more in [REST]" into the intro?
- PROPOSED: s/HTTP has been specially.../HTTP 1.1 has been
specially.../
- IJ: would moving this to the front synergize with your goals to have
more motivation up front?
- RF: hmm... no...
- [Ian]
- TB PROPOSED: The most important theoretical work in this area is
REST....read more here....
- (for intro)
- RF: REST is a named set of constraints. The webarch is another named
set of constraints (that the TAG finds useful).
- [DanC]
- DO: I'd be surprised if REST just sort a disappeared...
- [TimBL-tag]
- The document need *not* be modified to change "HTTP" to
"HTTP1.1".
- [Ian]
- TB: If our constraints are not a superset of REST's I'll be
worried.
- [DanC]
- PROPOSED: reduce summary of REST to something in the intro ala "the
principles in this doc are based on experience, plus there has been
theory/modeling work, the best write-up of which see [REST]".
- [discussion of REST, peer to peer, whether REST excludes some P2P
stuff...]
- RF: if you want to have a section that talks about the properties of
HTTP in particular...
- TBL: yes, let's do that...
- [... more on whether our arch doc should include all the REST
constraints, or whether REST is more constraining than what we
want...]
- RF: what I don't want is for the doc to say "REST applies (only) to
protocols"
- [PC asks about principles/constraints, which see notes from this
morning?]
- Resolved: reduce summary of REST to
something in the intro ala "the principles in this doc are based on
experience, plus there has been theory/modeling work, the best write-up
of which see [REST]".
- PROPOSED: there should be a distinct section on REST/HTTP style
stuff, part of section 4.
- Action RF: Draft a section on HTTP/REST,
showing rationale, principles, constraints.
- ==================================
- 1 Introduction
- ==================================
- Resolved: Change "RDF" to "RDF/XML"
in list of formats, per suggestion from Joseph Reagle.
- -------------------------------------------
- From Elliotte Rusty Harold: Does SMTP belong in the list of
protocols?
- [Ian]
- DC: When I mail something to someone, there's a URI. And SMTP is a
protocol I can use to get the thing. SMTP has a role in Web arch,
though different from HTTP's role.
- [DanC]
- TB Proposal: s/SMTP//
- CL: is ftp part of the web? what assumptions are being made?
- DC: SMTP has a role... mail messages have URIs... SMTP is one way you
can GET the mail message; usually it transfers the bits before you ask
for them, but ... see "Protocol - Smotocol"
-- TBL: ftp is definitely part of the web; you can get ftp thingies
just like HTTP thingies.
- DO: ftp is stateful, no?
- TBL: No, ftp isn't really stateful ... at this level [... more from
timbl, too fast].
- [Ian]
- DC: "mail data" inRFC
821 refers to RFC
822: "mail data: A sequence of ASCII characters of arbitrary
length, which conforms to the standard set in the Standard for the
Format of ARPA Internet Text Messages (RFC 822 [2]).
- [DanC]
- TBL: [... on the hand-off from SMTP to RFC822 to MIME specs, via IANA
registry...]
- [Ian]
- CL: But RFC 822 is not the MIME spec.
- TBL: But RFC 822 indirectly refers to the MIME spec.
- [DanC]
- TB: how is this discussion relevant?
- TBL: the question is: should the mail community care about what the
TAG puts in the web document? yes, since what we say here affects
email.
- [Ian]
- TBL: "Should the mail community worry about what we decide here?"
Yes!!
- PROPOSED: Add a sentence explaining why it's in the list.
- PROPOSED: Delete "SMTP"
- [DanC]
- Resolved: Add a sentence explaining
why SMTP is in the list of protocols, pointing to what TimBL writing
about spec connections. Include FTP in the list as well.
- [Ian]
- ================================
- 1.3 Limits of this document
- ================================
- From Brian
Carpenter email: Cite RFC 1958 "Architectural
Principles of the Internet".
- DC: Can we change the name of this section?
- [DanC]
- Resolved: Change title of section 1.3
to "Scope of this document."
Resolved: Cite RFC 1958 "Architectural
Principles of the Internet".
PC Editorial: The word "these" in the last paragraph of 1.3 ("Some
of THESE principles...") has an unclear antecedent. Please fix.
- ---------------
- Email
from Anthony Coates
- [Ian]
- TB: Web's correct operation doesn't rely on this
"componentization".
- DC: I want to get rid of the Editor's note, but this proposal doesn't
do it for me.
- [moving on quickly to question of term "absolute URI
reference"]
- [DanC]
- TB: ... we could say that URIs identify resources, and if the
identifier has a #, it's still a URI --
- TBL: yes, let's...
- TB: But what about staying in sync with the IETF specs?
- [we seem to have skipped down to comment from Connolly '"absolute URI
reference" considered awkward']
- CL: how about just using 'identifier'?
- SW: Roy, what do you think we could do about this in the IETF?
- RF: depends on who shows up. it's more valuable if individual TAG
members speak up than just something from the TAG
- [... possible risks involved in the IESG review...]
- TB: [... web arch doesn't rely on distinction...]
- CL: ... compound docs and such ...
- TBL: "we call all those things resources".
- ... doesn't seem necessary to change the arch doc in response to
this.
- Resolved: The TAG believes what
Coates says in his comment is true, but we don't see any changes
necessary in the doc to distinguish the classes of things; we regard
all those things, compound or otherwise, as resources.
- -----------------------
- [Ian]
- Email
from Dan Connolly: "absolute URI reference" considered awkward (and
in one case,overly constraining)"
- SW: I think it's folly to be inconsistent with IETF specs for these
terms.
- DC: My preference is to do the change (use "URI") and state that we
are not done with this spec until the IETF makes the change.
- DC: I wouldn't want to go to last call without this change in the
IETF spec.
- CL: I wouldn't want a dependency on a group that doesn't exist
yet.
- DC: But the editor is in the room!
- RF (rhetorically): Where is the BNF for "URI".
- [TimBL-tag]
- RF: The RFC does not define "URI"
- [DanC]
- (note that it's not critical path to do a WG.)
- [Ian]
- PC: I hear DC saying we have to commit to this as a group, and to
support this as individuals in the IETF forum.
- DC: I don't think there are any low-cost solutions here.
DC to RF: When do you expect a new RFC?
- RF: Six-month processing time between editor's final draft and when
number issued. Timing is not entirely under my control.
- [DanC]
- DC: how about 'till the IESG decision? that's when the risk goes to
zero, no?
- RF: right, that's when the risk goes to zero, but I don't really know
when the IESG will make their decision, though Q1/Q2 2003 isn't
unreasonable.
- Resolved:
- s/absolute URI ref/URI/ in the Arch Doc.
- Note the dependency/inconsistency between webarch and RFC2396.
Indicate that work is actively underway to harmonize usage.
- TAG participants pipe up in relevant IETF forum.
- Action RF: Spell out the "relevant IETF
fora" to TAG.
- [DanC]
- ==================================
- 2.1 Resources, URIs, and the shared information space
- ==================================
- Email
from Joseph Reagle
- [Ian]
- TB: Did we say "should' because some QNames don't have mappings to
URIs and it's ok to use them? That's not what we meant by SHOULD.
- [DanC]
- TB: no, QNames aren't why we said SHOULD.
- [Ian]
- DC: "../foo" is a perfectly good reference.
- [DanC]
- PROPOSED: no, SHOULD is not there to allow the QName exceptions, but
we don't need to change the document.
- TBL: let's get much more clear about references v.. identifiers.
References are strings that occur in documents. but every relative URI
reference is short for a URI.
- TB/TBL: let's put QName (with mapping, ala RDF [see issue 8]) in with
relative URI references just before 2.1
- Resolved: The finding on get7 already
says why it's a SHOULD, not a must. [validator example]
- [Ian]
- ================================
- 2.2.1 Comparison of identifiers
- ================================
- Email
From Dan Connolly:
- [DanC]
- Connolly's comment was just an aside.
- [Ian]
- ================================
- 2.2.2 Interactions with resources
- ================================
- Email
from Elliotte Rusty Harold
Topic: Are GETs really safe, e.g., in context of micropayments?
- TB: My initial take was that I incurred an obligation when I signed
up. Other people disagreed.
- [DanC]
- [Orchard is excused]
- [Ian]
- TB: Scenario I'm describing is that I pay a flat monthly fee, then a
penny per GET.
- [DanC]
- [... discussion of pay-per-GET service, and whether this motivates a
change to the principle 'retrieval is safe'...]
- [Ian]
- TBL: Two different layers. Some things are architecturally
underneath; not part of interaction between vendor about catalogs, for
example.
- [DanC]
- TBL: the fact that following a link might cause your cell-phone data
threshold to get crossed might cost you too.
- [Ian]
- [Discussion of ecommerce scenarios...]
- [DanC]
- DC: if I were to deploy a micropayment thingy, I'd agree with Baker:
I'd give 403 errors, and let the user POST to pay for the page, and
then continue.
- [Ian]
- Resolved: The TAG agrees with
email from Mark Baker - under no circumstances should someone incur
obligations by doing GET on a URI.
- ================================
- 2.2.4. Absolute URI references and context-sensitivity
- ================================
- [Ian]
- Email
from Joseph Reagle about section 2.2.4.
- [DanC]
- TB/DC: note we're already re-writing this principle
- [Ian]
- TBL: If you say paragraph 1 (of 2.2.4), you have to make a flag to
say that there is a security problem here. You should avoid
misrepresentation; you should ensure that people are aware of the
context-sensitivity.
- NW: That's what the principle "Be aware context-sensitivity"
says.
- TB Proposal: We nuke 2.2.4.
TBL Proposal: Add a security section.
- TBL: If you have a privacy policy on your site, and the policy is
that it changes after 10pm, that's very misleading.
- [DanC]
- [I'm interested in a pointer to where/when we discussed this text. IJ
responds with minutes of
22 July teleconf]
- TBL: separate the stuff before/after "Similarly, http://localhost/ ..."
- TB: I suggest deprecating the use of file: altogether.
- TBL: I'd like to encourage the use of file: URIs in command-line
tools; use "current URI base" rather than "current working
directory"
- [Ian]
- DC: Suppose I have a resource that I identify locally dir.ps. If I
mail you that pointer, you'll try to get something that's a different
resource. There's a public Web, and in your world, you see that plus
some other stuff. There's a public Web, and in my world, I see other
stuff. There's a lot of shared context, but ragged edges. We might
paint this point in a section on ambiguity. So, it's a myth that
there's "one Web"; there's a lot of shared stuff but lots of different
Webs depending on your view.
- TB: Web technologies are clearly useful in entirely unshared,
partially shared, or globally shared contexts. Don't kid yourself that
using "file:" is useful in the global context.
- CL: I assert that there is one Web. There are portions you can't get
to. I assert that DC's local file system is on the Web, with highly
protective access control.
- TBL: How do you distinguish the architecture considering DC's or CL's
view?
- DC: In my world, naming is unambiguous. In CL's view, naming is
ambiguous.
- CL: Not ambiguous if they have your machine's IP address.
- TBL: In DC's view, there's something broken: what you can do validly
is to make a link from anything private into anything public. But not
in the other direction. But every now and again that happens, and that
can be dangerous...
- TBL Proposal: (1) you can use file: (2) you don't have to put your
hostname in if nobody but you will use that URI (3) if you write to the
larger context, you should try to find out your Internet hostname and
include it in the URI.
- SW: Does distinguishing identifiers from references help here?
- RF: "Context-sensitive URIs should only be used to identify
context-sensitive resources". But that's pretty useless. Example of
posting information in global space about managing one's local
system.
- TBL: I note that http://localhost/ could be regarded as
shorthand meaning "before you publish me change me to global IP..."
- IJ Proposal: What if we move this to a finding and have a note
referring to it?
- TB summarizing: There is general agreement that the pizza example and
the weather example are similar. Should be merged.
- [Back to second question on file:]
- SW: I think we can move this to the discussion on "harm around
ambiguity".
- RF: There is no ambiguity.
- TB: A file: URI can be used in an ambiguous manner.
- [General agreement that there is no ambiguity.]
- TBL: I support file://lskflksdjf.com/etc/foo and "../bin/foo"
TBL: But not file://localhost/etc/host or flie://etc/host
- TBL: Rather - be careful when you use file://localhost/.
- TB: I think that this is best practice, and is sound.
- [DanC]
- DC: if anything, this "Be aware..." is a best-practice, not a
principle, yes? [nod from TB, SW]
- [Ian]
- TBL: If the specs are a mess, perhaps we should help clear this
up.
- [DanC]
- [[[
- re: drive letter in file name
- From: Larry Masinter (masinter@parc.xerox.com)
- Date: Thu, Jan 09 1997
- http://lists.w3.org/Archives/Public/www-lib/1997JanMar/0004.html
- ]]]
- ^ evidence from Masinter that the specs for file: are busted. google
search: http://www.google.com/search?q=masinter+file+URL
- [Ian]
- DC: file: URIs behave differently on different platforms.
- [DanC]
- Resolved: delete section 2.2.4
- [Ian]
- ==================================
- 2.4 URI Schemes
- ==================================
- ---------------
- Email
from Danny Ayers
- [No resolution]
- [DanC]
- Some sentiment in support, but discussion not conclusive.
- RF: Day Software is willing to host a TAG meeting in Basel
(Switzerland), whether it be the one in February or any future
meeting.
- PC: how about doing that in May, combining it with the WWW2003
trip?
- Resolved: to thank the hosts:
Antarcti.ca, Schemasoft.
- moved to adjourn...
- CL: note on my section 3 action, I'm otherwise occupied for the next
1.5 weeks
- Next meeting: 7 October.
- ADJOURN. With thanks to Stuart for chairing.
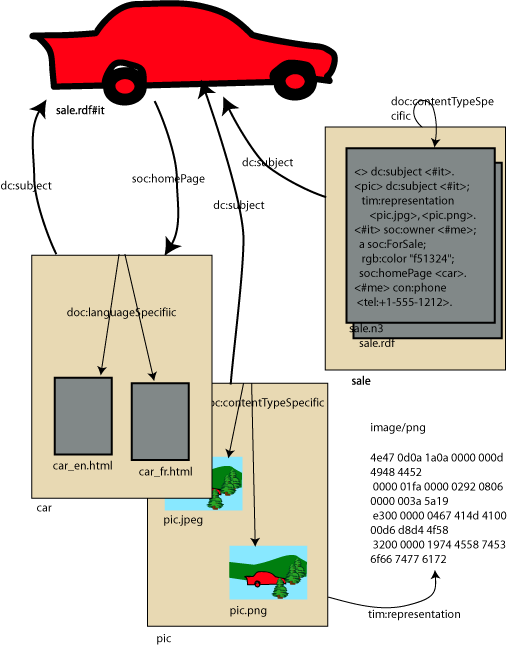{kind=link}
{kind=link}