Collected notes from discussion sessions and breakout groups
[Notes by Stephane Boyera]
T. Lemlouna: are all pieces of variants authored or transcoded ?
Rhys: you can do both. You may aithor what you want, and let adaptations
technics to transcode when nothing authored available
Fabio Gianetti: how do you control at the authoring time the layout
associated with devices ?
Rhys: we have a hierarchy of devices in our repository, and then you
position a specific layout at the node you want and all the subtree
inherits it.
Roland Merrick: can you nest layout ?
Rhys: yes you can
Guido Menkhaus: when you have dynamic content, you may have a size
problem, not knowing the final result size.
Rhys: we are coping with this problem. You can define what to do with
one record or a set of records. That's just implementation
Carlos Velasquez: you said that you didn't go for xslt because it's
unmaintainable. But isn't your layout the same with the same problem ?
Rhys: no, xslt is like doing manually. You cannot have output fitting
for a large class of devices with one xslt. Thus you would need to have
one xslt for each node of devices hierarchy.
[Notes by Stephane Boyera]
Tayeb Lemlouna: is there any publication on your work ?
Guido: no not yet, next year we plan to do that.
Andreas Schade: how are you doing device detection ?
Guido: not one mechanism, probably multiple, uaprof, http header, ...
Stephane Boyera: how are you planning to manage fragments
Guido: don't know yet. We probably need a kind of session like in Xforms
[Notes by Roger Gimson]
Al (Gilman): Rhys described some aspects of his system as a 'matter of implementation'. The success of abstractions is to be flexible enough to give authors a target. What you are talking about is block structure that will get reflowed. What about continuous narrative, and preserving logical reading order? Otherwise you just have bagas of user interface elements. Semantic subtasks must be kept together (c.f. Volantis layout units).
Rhys (Lewis): We rely on authors knowing about units of content.
Al: 85% of the solution is in getting authors to recognise the different needs of devices. But voice should be included in the game.
Rhys: We do support voice output.
Al: Need to model the content so that it can be adapted to meet the delivery context.
Stephane (Boyera): What if a device cannot display anything for a specific application.
Guido (Grassel): Should always have a default rendering of high-level interaction, elements, images etc. Address groups of devices and ensure at least a functional solution.
Al: Can guess a gif is inappropriate for a blind person. The content model must allow the default to change in this case.
Rhys: We require there is always an alternative e.g. video -> image -> audio -> text. We don't yet have the sophistication to capture user preferences.
Guido: Metadata can be supplied with content to specify in which circumstances it should be used. This also makes the content deployable on different servers and support re-use.
Martin (Gaedke): Authoring text for DI implies some semantic relationship between components. How much does navigation guide this?
Rhys: Linking techniques are common for any web content (DI or non-DI). You specify the URI in the link then deliver the appropriate content for the delivery context. In the DIWG we haven't looked at navigation in detail. Authoring units could be linked in such a way as to support navigation adaptation.
Martin: Do you have any experience of using different names (URIs) for content?
Rhys: We use URLs, though could be URNs.
Guido: Persistence of URLs is important.
Tayeb (Lemlouma): I have tried accessing the Volantis site from my iPAQ - it worked! Why have you not adopted SMIL control content techniques?
Rhys: We are commercially driven, and haven't got around to it yet.
Tayeb: How do you store the metadata? Do you use RDF?
Rhys: You could say this is an implementation detail (laughter). Everythin is based on XML, but may be stored in a database. RDF could be used in the future.
Tayeb: How do you handle two different users who happen to use the same device?
Rhys: Personalisation or customisation is usually handled separately in our systems.
Andreas (Schade): What is the format of the device information?
Rhys: It is proprietary, and gleaned from different sources.
Andreas: Do you use device information provided in a request?
Rhys: Currently we only use HTTP headers. We will support UAProf in the future.
Srinivas (Mandyam): ?
Rhys: Our approach is not annotation based.
Guido: You need to separate the business logic from the adaptation.
Stephane: Why create a new form of device profile?
Rhys: We have created new languages for layout and for encapsulating CSS. The device data in the repository does not use a 'new' format, it is just stored in a database.
Andreas: There may be devices that can extend their function, by downloading new software for example.
Guido: In that case would need to get a diff as in UAProf.
Stephane: There are three new languages from Volantis, but only one from Nokia/IBM/SAP.
Michael (Wasmund): Our work (IBM) is not yet complete.
Rhys: The approaches seem very close to me. The key thing is that the DI and the non-DI aspects are kept separate.
Guido: The difference between one rich and three simpler languages are not significant. We focus on business applications, with little multimedia content, and mainly text-centric and input-centric content.
Al: Rhys said the key is to separate the DI from the non-DI. There is no stable line between these. It is the model of the content independent of its delivery that is important.
Al: You don't need the concept of a session if you have one model (e.g. in XML) that captures the full application. The REST (Web) model is not applicable to V2 because sessions are not allowed. You need sessions in some situations. Read the article on peer-to-peer Grids.
Markus (Lauff): Rhys uses device information from the delivery context. Consensus will use all kinds of delivery context information. The 'pane' is an element for Rhys. We use more flexible layout units.
Al: Have you looked at the Universal Remote Controller?
Rhys: Must have repository because devices do not provide their own data.
[Notes by Roger Gimson]
Al Gilman: What content model should be used to enable adaptation?
Candy Wong: What is the trade-off between cost and quality in adaptation?
Gottfried Zimmermann: How can third parties contribute to customised adaptation?
Rhys Lewis: How do other techniques contrast with single authoring?
Candy Wong: What are the core parts hat must be device independent?
Bert Bos: It might be possible to extend existing techniques (e.g. XHTML) rather than invent new notations.
David Shrimpton: Extensions to languages could be done as extra modules.
Shrinivas Mandyam: We use extensions as custom tags.
[Notes by Rhys Lewis]
Motivation - heterogeneity of hardware and software
Notion of Device special purpose
Not all devices may be appropriate for all content - not possible
Author constructs task model and presentation model (display only)
Task model: logical tasks(enter information), physical tasks(e.g.selecting button)
Build task/subtask model for the overall task. (intent based authoring?) Helps to design the UI - closely related items placed closely on the display.
Mapping Technique
Use DI markup to create the models and then its mapped to the target markup at run time (adaptation)
Some tasks only appropriate for some devices e.g. big forms on phones.
Single Layout Specification (at the moment)
Use a gridbag layout style - constraint based. Defined for the largest screen
Can automatically transform layouts because they know a lot about the UI intent . So the rearrangement is based on the task model wherever possible.
Control transformation
Automatically transform a control to equivalent control
Very interesting possible extensions for the interaction markup. However, it is trying to map the SAME content to all presentations. Don't have a mechanism for platform-specific content or support for dynamic content yet.
Raised the following questions for the DI workgroup
- issue about how to help authors make a smooth transition from concrete to abstract authoring
Consistency and customisation
- issue about different presentations on different devices implies that users need to learn the interfaces on different devices
Heuristics for generating high quality presentations
- what do these need to be to generate good customised presentations?
How to preserve device-specific customisations?
Maybe different types of web page and applications benefit from different approaches.
Roland: - Do you have an event model?
Candy: yes
Luu: Is your implementation client or server side?
Candy: client and server side adaptation for the prototype
Luu: I can see the benefit of client side adaptation, but how do you overcome the limitations of devices that are too small?
Candy: We can do server side adaptation if can't do at device
Gottfried: What is the task model?
Candy: Pretty much dependes on how the author views the task.
Gottfried: Is that based on a hierarchy?
Candy: Yes. The task model tends to be based on the presentation. That's how the authors tend to think about it but there may be sequential tasks.
Carmen: Have you considered the relationships between tasks and subtasks.
Candy - Our model is not that complete. We have sequential tasks and subtasks but we don't have many relationships right now.
Carmen: - Do you use a particular notation for specifying the task mode.
Candy We use heuristics
David: Does the authoring model have to be the superset of all devices?
Candy: Yes, for practical applications all features appear on the PC version.
T. Lemlouma: What markup language do you use?
Candy: Yes we have a device independent language and map to the device's particular markup.
Roland - What about the customisation you referred to. Maybe that should go to a style definition. They want predictability about features as they go from device to device. Have you measured what happens when the same user uses the interfaces on different devices.
Candy - no
Roland are there rules about going from device to device. Can the authors customise the rules that are applied?
Candy - Yes and also they often rework the task model
Al - Disagree that the big screen always has all the presentation of all the other devices. Confirmation steps in a multi step operation would only appear on small devices where only part of the presentation is given at any one time.
Also in voice you may need more verbose information to make up for the fact that the user can't see. You need to reinforce the context.
Candy - The feature is still the same, but the presentation can be different.
[Notes by Rhys Lewis]
Two step adaptation - First to device class, then to device instance
Device classes correspond to the interaction between user and device - printer, PC, phone PDA etc.
Content has two levels of indirection from the layout - hence layout adaptation is possible
Layout is grid which is a set of references to areas in the layout. There can be a nested hierarchy.
Elements are defined within these areas. Content bound to the areas through a binding. So can have selection of alternative content through the binding. Both content and style can be modified this way. Can do alternative content this way through a binding. "Alternatives" binding.
Adaptation.
Content selection based on priorities
Layout adaptation based on device capabilities
Alternatives selection based on fulfilment and authors preferred choices. Alternatives selection should select content and style at the same time
prioritisation of semantic elements. Only things with appropriately high priority will be delivered to devices witaule that is not satisfied. Hence, less important content is dropped from small devices. Once the decision has been made that the content should be delivered, then the alternatives processing occurs and the content selection occurs.
Layout adaptation occurs by including the areas in a different arrangement. Basically, the system can do an automatic layout, rather like gridbag, but authors can override this for particular device classes.
If keep solution simple with separation of layout, and content via bindings and alternatives a sophisticated system can be created as long as there is appropriate decoupling between content and layout.
Navigation markup is needed.
T. Lemlouha: Is it just a final selection approach
Fabio: No, because there is the automatic layout adaptation in addition. Layout selection occurs when the author is not happy with the automatic layout generation.
T. Lemlouha: Can you support dynamic creation of media according to the client properties e.g. transformation of images
Fabio: Yes, you could reduce the size of the picture. If you reduce it too much for example, it may not be worthwhile. The system through alternatives allows you to express an alternative, either another picture or text etc.
T. Lemlouha:Do you use a new language?
Fabio: Yes, but that is just to capture the content better. However, you could use any markup. The key thing is that the layout is not embedded in the content.
Axel: You assign priorities, but how do you choose these and wouldn't it be better to assign them to device classes?
Fabio: You assign priorities to pieces of content that will be placed in areas. If you have low priority content, you may find that an entire area of the layout can be discarded. The author specifies the priority of the content and the device. Its another way of specifying the task model. The author must have feedback to see the way that the priority affects the presentation.
Axel: I feel that maybe there needs to be some specification of these priorities for the device
Fabio:You need some heuristics for setting these priorities but then the author can fine tune how the priorities are used. You can use very long priority representations to get fine granularity.
Gottfriede Is there a way to express dependencies between elements that might conflict with the priorities?
Fabio: Its an authors responsibility to set the appropriate priorities to ensure that the presentation is consiste he smaller device.
Johannes: Do you define only blocks in the layout, or do you define semantic elements like headings etc.
Fabio: The layout is just represented in terms of blocks. The semantic elements are referenced by the blocks in the layout.
[Notes by Rhys Lewis]
Concrete example. I found a hotel page on the web in the office, now I have only my phone.
I have the bookmark, but the author had only a PC with Front Page!
Trust W3C - shows the standards
The ideal..
Starting point is HTML and that contains pointers to other media and information.
Authors - don't lie! Don't use HTML for layout. Don't store text as .png!
Optionally can provide alternative bitmaps, optional styles so that the client can adapt as appropriate.
The user agent should be the user's agent, not the author's agent in disguise!
The reality ...
Formats not yet powerful enough. CSS needs additional features, for example pagination and 'cards' metaphor.
Authors are not perfect
Books and tools misrepresent HTML as a page layout language
People are bad at making metadata explicit
XHTML 2 will have a lot more of what is really needed for device independent authoring
Lots of the things already presented would make good candidates for extensions in the W3C standards
Specific challenges for CSS
- better paged display
- Interaction, navigation
- Multimodal
visual, background audio, sound fx
visual and speech
- dynamic rendering
page at a time, line at a time(c.f.powerpoint)
overlays and pop-ups
- continue to avoid semantics
good CSS is CSS that is dispensable
Axel: You said that authors are not perfect, particularly in usability. Could it be an option to force authors to follow basic rules that are known to be usable.
Bert: Its a discussion we have all the time. It turns out that there are useful applications of technologies. People misuse technology all the time, but you can't limit it because there are valid uses. In most cases it has turned out better to educate the author than to restrict the function.
Gottfried: Maybe if all usability experts agree on a set of rules, we'll use it
David: The best approach may be to cause tools to guide authors to do the appropriate thing. Simple example is to ask for alt Text automatically with each image, for example.
Roland: We've seen that people want to be able to author fragments and to assemble them in various ways. We don't see that being promoted in books, and we don't yet have the standards yet for this.
Bert: Agrees
Roland: For where we are now, there are still some fundamental things that are missing and the standards weak.
[Notes by Michael Wasmund]
Markus Lauff: Why do you start with the most complex layout of the application ?
Candy Wong: No, we start with the whole design, then define pagination. How I solve the conflicts of priorities: I have one priority for each level of task to prevent conflicts.
Q from .... : Do you describe dependencies between tasks ?
Candy Wong: Yes, we have a hierarchical structure of taks.
Roger: where should adaptation take place ?
Bert Bos: CSS assumes adaptation happens very close to the renderer. Reason is to make the resources stable. If you adapt the content then give it a new URL. Don't offer adapted content with the same URL.
Luu: assigning new URL is in coflict with DI principles. Reason for DI principle is to avoid device-specific URLs.
Bert Bos: When I see a URL I want to see the same bit stream.
Roland Merrick: Don't agree. I want to know the place of my information without consideration of the device.
Bert Bos: 10 years from now I don't have the PDA anymore, but still want to see the same content. The display on the screen can be made up of several URLs, some of which survive, others not.
David: Not sure why is it so important to have one URL per device context.
Bert Bos: when using Pearl scripts, I need to be able to retrieve exactly the same information to support automated content retireval.
Roland Merrick: Disagree.
Bert Bos: Don't want the URL give different answers each time.
Roland Merrick: It's just a transformation of the same content. CSS on the client can do as nasty things as adaptions on the server side. The user is not always in control of CSS.
Roger: There is potentially a principle: You should be able to go back to some previous content. More than just the notion of "URI" may be required to achieve this. Example: MIME type helps to retieve suitable presentation for a certain device.
Bert Bos: Today, data is identified by a single URL, no metadata comes with it.
Stephane Boyera: ......
Roger: W3C allows bookmarking documents in two different formats.
Rotan: If we understand URI as "resource", we have many different representations. "Today's URI" has a different meaning with time.
Bert: .......
Rotan: There's a difference between "save (content)" and "bookmark".
Roland Merrick: "Save" may require a different URI then "bookmark".
Bert Bos: Today there's no standard metadata associated with a page.
Al Gilman: (refers to transactional context, which may have to be reconstructed to retrieve the same content at a later stage).
Bert: The ideal in saving things would be that the original can be reconstructed even if the original meanwhile moved or changed.
Rotan: How do you label ?
Markus Lauff: Other topics ?
Gottfried Zimmermann: Candy mentioned ability to transform controls. This is an important feature. Could you imagine transforming into different modality, or mixing modalities ?
Rotan: ...
Gottfried Zimmermann: We could have adaptation beyond simple scaling / resizing.
Roland Merrick: Evidence from XForms shoiws: The UI behaviour depends on type of the data it is bound to. Typing helps.
????: A combo box in XForms allows splitting or complete change of representation.
Candy Wong: My approach is also to refer to the type. We expect authors to make several widgets for different platforms and to define the rules when to choose what widget.
Bert Bos: Example: In a map made by SVG, each element can have style information associated, which controls association. Today, we cannot do this with CSS, but with SMILE.
Markus ?: Addressing "smooth transition from conrete authoring to abstract authoring...": Who do you consider as "authors" ?
Candy Wong: Transition from concrete to abstract is difficult. Layout author is concerned first. How can a layout author define layout in an "abstract way" ?
AlGilman: (You are talking about authoring techniques. I expect the techniques to ease the work of the author, not the author to be forced to adapt himself to the system.)
Roger: I see different areas: author can explicitly create variants, or system automatically creates variants.
AlGilman: (...the authoring process must assist author in design by exposing the structure to him/her...)
Roland Merrick: We have to recognize there are lots of different authors. Some authors do the overall framework, others do the fine-grained layouting, all using different tools, barely connected to each other. We have to consider this and their different tools.
Shlomit: Authors are practically "artists". Does our attempt give rise to the evolvement of a new profession or team wich combines skills which were separated before ?
Markus ?: There are emerging "interaction designers", but there are always overlaps, e.g., layout designer would like to change interaction sequenece. Results in re-ordering issues. How to address that ?
Markus Lauff: That's a topic for an extra session.
[Notes by Rotan Hanrahan]
Commenting on the diagram containing the three models
Q: (Roger Gimson) To what extent do you think app provider is same as interface provider? In case of ATM, manufacturer is also the interface provider. Which defines the core model?
A: It can be any combination of these.
Q: (RG) So if a bank defines the interface, then the manufacturer has to design a device to suit the application? What of devices that are designed to present any interface?
A: We have a Universal Remote Console (URC) concept, which is a generic access device.
Q: (RG) But in the case of the web, there is a need for an intermediary to map the interface to the generic access mechanism. I don't see the intermediary in your model, which only has two parts, the app provider and the interface designer.
A: The models are still in flux, but we are happy to get input from you to evolve these models.
End of presentation
Further Questions
Q: (Roland Merrick) I understand the creation of the core model. Do I create one or more dictionaries for each model? I can see how I do either. Do skins bind to a dictionary, or to a model and a dictionary?
A: The bind to both. They are intertwined.
Q: (RM) I was surprised that it was in the skins that you defined a special version of an application with a skin, such as a banking interface that restricted withdrawals to 100 dollars. I would have done this in a dictionary.
A: The line between skin and dictionary is blurring. You could do this in a skin or in a dictionary.
Q: (Rotan Hanrahan) How far should you go with WYSIWYG? With so many devices to support, this could be too much for a tool to offer, and possibly too much for a human designer to preview.
A: I would not require WYSIWYG for all devices. You can get good abstract information from a tool that uses a WYSIWYG approach. The tool would help the user construct skins, dictionaries and core models.
Q: (RH) Would it be sufficient to offer previews of a few classes of generic access device instead of all possible devices?
A: This would be sufficient. What is important is that we can reflect the model and skins visually. It is not necessary to include every device.
[Notes by Rotan Hanrahan]
Q: (Stephane Boyera) You say we need a flexible XML representation. Does this mean that XHTML is insufficient?
A: The new XHTML is a lot better. You can get more semantics from the elements.
Q: (Roland Merrick) When you look at languages that are domain specific, such as newsML, do you think that such languages are good for your content authoring?
A: Yes. It has a lot of semantic information, which is good for content authoring and subsequent content adaptation.
Q: (SB) About user profiles: you say that you were planning to use CC/PP structures for this, but it was insufficient. Did you develop your own?
A: Yes, but it's not RDF. We have a draft which we can send you, but we are not very happy with it. The aim is that the UP overrides the Device Profile when necessary.
A+ (SB) Definitely, user preferences can be mixed with the fixed device characteristics.
Q: (Roger Gimson) In DIWG we have separated UP for presentation purposes from UP for application purposes. For example, if you have preferences for accessing the weather forecast for your location, that's only an application preference to determine what information is sent to you.
A: We have a similar concept.
Q: (Johannes K) With respect to CMS there are issues with having in-line markup in the content. This occurs when the input system to a CMS is a web browser and the author wants to include inline markup, even something as simple as making a piece of text bold. It forces the author to know the markup, and can complicate the web interface, especially if it cannot be enhanced via a plug-in or applet.
A: We have similar issues with web-based CMS.
[Notes by Gottfried Zimmermann]
How to organize content?
* Nature of authoring fragments
* Authoring style - page by page, max to min,...
* Managing available choices
Fragment could be applied to:
* Presentation (components, styles)
* Interaction (user events, communication)
* Content ("real content", metadata such as data type specs)
* Metadata (... applied to presentation, interaction, content)
Selecting content:
* XSLT as a model for priority driven selection? Use of modes, priorities, and templates...
* Priorities and modes as part of metadata
* Structure of fragments should be extensible (e.g. user can modify)
Authoring style:
* Flexible for both: Specify generic solution and specify custom solution
* Start with generic solution; then device class specific; then device specific. At the end the user may override it all??
Questions:
* How can 3rd parties modify presentation and interaction?
* What fragments could be reused?
* Solution should allow for flexible processing (e.g. employing Web services)
* Should the user be allowed to modify everything (e.g. ban ads and logos)?
* License agreement: Model (constraints) not to be overridden!
[Transcript of flipchart]
How to organize content?
* define metadata
* tools should generate the metadata
* XForm - good start
* semantics of context/content
Nature of authoring fragments?
* navigation - XPointer; XLink - Hypermedia design patterns
* context-based content
* interaction (interface elements)
* process & communication
* presentation
[Notes by David Shrimpton]
Discussion to consider:
How to organise content?
Nature of authoring fragments.
Authoring style - page-by-page, max to min.
Managing available choices.
How to organise content?
The authoring scenarios document describes authoring roles but does not fully consider the relationships between the various roles. It is questionable whether a strict set of relationships can be defined as these may well depend on particular organisations needs. In some cases a single person or team may be responsible for several of the defined roles. One solution might be to attempt to define the possible interfaces between the roles rather than specifying relationships.
The increasing complexity of markup that includes DI aspects will inevitably make authoring a more complex task. There is likely to be more need to give feedback to the author. This may lead to WYSIWYG authoring systems that can provide feedback on how the final rendered document will appear on either specific devices or maybe on a range of classes of device. Such tools might provide indications to the author where alternative forms of content may be required (AMAYA was given as an example of a system where authors are required to at least consider alternate content). Where possible such tools should attempt to capture the required semantic information as transparently as possible and might also provide sensible defaults.
The way DI authoring is undertaken may depend on whether the author is starting from scratch or whether they are retrofitting the additional semantic information into an existing document structure.
We concluded that DI has a cost associated with it and that an organisation may have to make strategic decisions as to the level of resources that might be applied on a case-by-case basis. Some DI, relating to accessibility for example, may be considered to be essential whereas the range of devices supported may be limited according to specific requirements. The initial cost of DI may be recouped by making the site more easily maintainable and the ability to easily incorporate new devices as they become available.
Nature of Authoring Fragments
The group preferred to use the term ‘Authoring Units’ to discuss the units of information that might be manipulated by a DI system.
Much of the discussion was based on the possible relationships that might exist between authoring units and we concluded that although there is a tendency to think in terms of the spatial relationships between units, there is also a need to consider other relationships such as temporal, semantic and functional relationships. For example, an alternate form for a piece of text might be an audio representation of the content and it then does not make sense to simply consider the spatial placement of the relative to other visible units. An authoring unit might contain more than one type of media content and could conceivably include some user interaction. Some prioritisation of authoring units may be necessary in order to select which should be rendered on a device with limited capabilities.
Authoring Style
We concluded that the notion of ‘page by page’ authoring is redundant if authoring units are being considered as pages often associated with particular device capabilities whereas authoring units provide a more flexible abstraction for DI authoring.
At the two extremes it appeared that an author might either start with the most inclusive feature rich form of a document and subsequently break it down into authoring units or conversely start by defining individual authoring units and then build up the document. This is analogous to top-down vs. bottom-up approaches in programming.
It seemed as though both these approaches might be viable and ultimately might depend on an individual organisations policy. Identifying different approaches might be more useful than attempting to specify a single authoring style.
[Transcript of flipchart]
Nature of authoring fragments?
- Device Dependent Chunking. +1
- Hard
- Authoring must address [Ap stuff] through views employing varying aggregations.
- Multiple aspects to consider
Content Interdependencies,
Scale of device capabilities,
User cognitive maint. of exo-structural concept
Authoring style - page by page, max 2 min
Managing available Choices
Properties of each selectable choice:
- Device may leave you 0-1 option.
- User: distinguish constraints (go / no-go) from preferences (better / worse)
Devices contribute both of these too
[Notes by Abbie Barbir]
We tried to tackle the question of how to organize content in a different way. We thought about fragments and how they can be applied to presentation. Could be in different formats and styles. There could be real content or meta-data. We struggled with the definition of meta-data. It can apply to presentation, interaction, and content. Regarding how to select content, XSLT with it´s priority selection could be a model. Also, the use of modes, priorities and templates in XSLT. The structure of how to tie content together should be extensible so the user interface can be extended. The authoring style is the question, min/max, where to start. We need the flexibility for both. The author should be able to specify generic and specific solution. If the generic is good enough for all devices, then we´re done, but also need to allow user to override everything. Everything should be treated carefully because there are some things we don´t want to let the user modify. The question is: how can 3rd parties modify presentation and interaction. If we have a good model of the content, then this should not be modified by 3rd parties. What fragments could be reused and modified? We don´t want to talk about processing, but how different languages come together to specify interfaces, we can use web services as a step in describing interfaces. Should the user be allowed to replace everything? E.g.you can´t skip ads on T.V. The user should give explicit agreement, e.g. license, before downloading code for example. The model has a constraint that the user must agree to something. This is still an open question.
We asked what the difference between interaction and navigation. This generated a lot of conversion. We identified that as a group, we´ve been speaking about authoring techniques and about authors. We need a more precise mapping of the various tasks involved in creating a site and the humans involved in it. E.g. the role of information author, if we require them to do meta-data tagging, it´s not going to happen. As much as we want to be DI, when it comes to optimal presentation, there is the desire to leave room for the author to touch-up the final optimal presentation.
I think in the future this will not be required, because of the maintenance nightmare. More and more people want to see the transformation and processing happen on the client side since that´s where all the information is. Of course, we have some hardware limitations to achieve this, we should think as though there aren´t since we´ll soon remove those limitations. As humans, the responsibility of information delivery is shared. When we talked about how to organize content, let´s say that I´m delivering with voice something over the radio. The same information I´m delivering with voice over the T.V. The voice content will be different. In optimized presentation it´s going to affect the presentation. Al: suitability for use, a super-concept of methods. In managing systems, the concept has been there. Shlomit: semantics applies to context and to content. Xforms is a good start, if not yet complete. We must define meta-data, not expect the creative person to supply meta-data, let tools do it.
We had an interesting conversation without addressing the individual points. We discussed what is a fragment, and what is the relationship between fragments. We thought of a fragment as the basic unit of authoring. People should understand fragments and the relationship between them. Fragments need an identifier. You can then establish the relationship between fragments. You might have the relationship that you´re part of another. You might have a sequential relationship, or alternatives. These are all kinds of relationships that we´ll have to explore.
The variants we talked about are types of fragments. The choice type of nature, you have two fragments and you have to select one. Those are the basic units we have to deal with. It might be a chunk of markup, that may not correspond to any vocabulary we have today, e.g. a paragraph. This is the logical structure. We think that the fragments are great for tasks and groups. If I have the transaction/task I want to perform, all of these fragments have a root and you can identify a path through these fragments. The adaptation process could go through these fragments, prune, select, etc.
Michael: When we have the ability to choose between alternatives, some means to ensure consistency between the fragments is needed.
Roland: Within this document, this instance, you always make the same decision. E.g. selecting logos, I´d always get the same one.
Al: over-arching, the breadth of applicability.
Srinivas: Did anyone talk about device clusters/classes?
Roland: The superset of fragments, adaptation would apply to fragments taking into account device clusters. The runtime adapation process only applies to one device.
Roger: The key thing is what information needs to be supplied by the author in the first place in order to allow adaptation further down the line. There may be some adapatation that can be applied automatically without the author´s involvement, e.g. image transcoding, but others that require further semantic information from the author. We haven´t enumerated all of those, but the principle that authors need to supply some semantics on some content in order to facilitate adapation is important.
Roland: We didn´t talk about how you´d do this.
Srinivas: We interviewed quite a few designers and they wanted to design at a high level of quality, and what´s the most efficient way of doing that.
Roland: Different people will be worried about different things. No single author can create a very sophisticated website. The fragment boundaries would be where you´d consider changing authoring roles.
We talked in terms of organization of content. The AS document defined some authoring roles. What´s missing is the relationship between those roles, and that´s critical. Is there some sort of workflow between these roles. You may need to define the interfaces to these roles and leave it up to the organization to define the relationship. You need to be able to give some sort of feedback to the author for DI. It´s going to get more difficult for an author to know what´s going to show up on a particular device. You would need to get some feedback on classes of devices. You can´t view 420 devices simultaneously. Authoring documents, there may be a need to force the author to think about alternative forms. We all agree that building in semantic information is needed, but how much do authors need to think about it. You either start from scratch in which case you´d need an environment to provide this information. You might also need to retrofit an existing site. There´s a cost to DI, and organizations need to make decisions. Accessibility issues might be considered very important. And an organization may decide that they don´t care for their content to be viewed on multiple devices. But the cost can be saved if it makes the site easier to maintain, and leads to easier extensibility. On fragments, are they spatial, temporal, functional, task-oriented? E.g. a caption might be an audio clip. We tend to think visually, but there are other alternatives. Is there a distinction between an authoring unit and the relationship? E.g. an authoring unit may include some interaction. Authoring style, page by page is redundant, a page is an authoring unit. Do you start with the big picture and work down, or the other way. It depends on how you like to do it, or how your organization dicates. Authoring approaches need to address both.
Our conclusion on what is the right path, top down, or sideways, is, don´t go there. You´ll never impose one, the customers will define it. You have to be able to build up aggregations that are supplied by your customer. There is no single logical unit that characterizes authoring. Authoring must interact with the application in the large, and at different levels at different times. You need to be able to deal with different authors like you deal with different users. In the presentation, the units from which you build the interaction vary with the device. You chunk things finer in a small display, bigger in a big display. There are multiple aspects or properties, kinds of properties, that determine what you want to aggregate. A tuple-space view of how this subset of properties change. You don´t worry about all the properties, just a coarse-grained view. Managing available choices, what you need to do is characterize the content with what you can say validly about the content, that´s not dependent on what you´re assuming about the content of use. You do this on a factor by factor basis. Then you look on a composite rating and pick the one that looks good. The user will have a go/no-go constraints, e.g. a blind person no/go visual. There are both hard constraints that come from the user, and preferences. The devices have both categories that contribute to the decision process. Devices can handle things more gracefully than others, and some can´t handle some things at all. You pool all of these together and take a balanced view. There might be external constraints, e.g. license agreement. There are valid constraints that become overriding. You try to resist changing things but may be forced to.
[Notes by Guido Grassel]
Q: have you looked at WSRP and WSIA?
A: Will have a look in the future
Stephane
Q: What are you proposing to us?
A: Some Web services want generate their own UI. How to do that in a device independent way?
Q: Should a Web service be able to make a presentation?
A See WSIA and WSRP, OASIS they look at UI in connection with Web services.
Q Do use a special device profile?
A: At the moment our device profile is hand crafted for demo purposes, we need one in the future. a new one will need to be defined. Work at IETF needs to be studied.
A: Device independence could be interested in web services architecture. Mario's ideas will be presented there as well.
[Notes by Guido Grassel]
Q: Giving authors direct control of presentation - how in the case of pagination
A: * UAProf device attribute: WMLDeckSize -> compiled deck size.
* device attribute: Bandwidth
* Using grouping to protect breaking parts that should not be split into separate fragments.
automatic pagination vs. pagination defined by the author. pagination is a run-time thing.
Q: how to select the best suited variant if there is not a variant for that specific terminal
A: select by closest match. device attributes are assigned a priorities. Priorities are used to determine the most suited variant. authors should design for a broad range of terminals.
Q what is the notation for your transformation rules
A XSL-T
Q: Is the markup publicly available.
A: no clear answer.
Q: how does the processing of a request work
A: 1. detection rule for the device determines the profile, 2. device profile determines the transformation to be used, 3. transformation to apply the single source document.
Note: device classes: Clear clusters exists when grouping according to one device capability, but across capabilities there are no clear clusters.
Note: capabilities have priorities, screen size is the most important criteria in Srinivas' opinion.
Q: How do you determine device capabilities?
A: We support UAProf detection and as a fallback we identify the device by UA header. Dynamic and static device attributes get merged.
Q: Are there savings of the approach compared to multiple authoring.
A: Yes.
Note: conclusion: define the interface to adaptation
e.g. pagination needs to be defined as a concept, e.g. e.g. transformation of tables.
Q: Is your device profile repository available?
A: Our UAProf repository is available on subscription basis
[Notes by Rotan Hanrahan]
In this session, Roger Gimson commenced by presenting a draft diagram that attempted to capture the results of the workshop. It indicated a pipeline process moving from left to right representing the stages from authoring to presentation. The intermediate stages were content model and adaptation. Beneath the pipeline were indicated the technologies to support the various stages, and highlighting the possible gaps in technology/techniques identified during the workshop. Comments and suggestions were invited from the floor.
Al Gilman pointed out that "Management" should be included and should span the entire process. Furthermore, the content model could also be federal. It could be a variant model that drives the presentation. These points were accepted and the diagram altered accordingly. Al went further to indicate that web services could also be present at other stages of the process, unlike the original diagram where web services only played a role at the initial stage (as a content provider with an implied authoring role). Once again, the diagram was altered to show adaptation being provided by a web service as an alternative to a fixed component of the pipeline.
Following further discussions, Roger concluded that there needed to be functions in the authoring tool to populate the content and that therefore the content model has to include the concept of authoring. (Diagram updated.)
It was agreed that the content model needed to include all of the static properties that an author could supply. It should include anything that an author would be able to supply to the process as if the author was actually present at the time when the presentation was being constructed for delivery. This included properties that would influence the adaptation, properties we would call "adaptation hints".
The technologies associated with the authoring stage was expanded to include XForms Data Model, though Roland Merrick observed that the model was not designed to be split. The models in the authored content may be subject to splitting and subsequent recombination (aggregation) as part of the adaptation process. Roland declared that "someone" would have to take responsibility for any such splitting.
Srinivas Mandyam indicated that CSS is another technology that needed to be included. Roger wondered if fragments could have something to do with style and Bert Bos argued that CSS should belong to the adaptation box in the diagram. However, Roger countered that CSS needed to be created by someone, presumably the author so it should be part of the authoring process not the adaptation process.
Axel Spriestersbach asked about the role of dynamic data in the pipeline. Is it an aggregation process? Guido Grassel pointed out that as a source of content it should be included in the data model, and the diagram was updated accordingly.
Gottfried Zimmermann expressed a preference for authoring tools to extend further across the pipeline. Seeking clarification, Roger outlined possible author influences at other stages such as adaptation using local rules supplied by authors other than the original authors of the content. However, this led to an objection by Stephane Boyera who noted that we were trying to combine "authoring time" with "runtime". This led to a brief debate (many participants) on the issue of the dimensions in the diagram. The temporal dimension (left to right) and the dimension of specificity (top to bottom) covered the issues of the steps from author to presentation, and the mapping from abstract notions to technologies. It was generally accepted that this made the diagram "busy". It also highlighted the fact that where one chose to place an item depended on which dimension one was considering. However, it was agreed to continue with the single diagram now that the matter of dimensions had been accepted.
Roland wanted to know what "kinds" of things were being dealt with at different parts of the process, to which Al replied that a "typing system" would be a good way to organise model knowledge, accepting that content is not merely a collection of raw data. Roland pointed out that "kinds" was just a synonym for "types", but the original question went unanswered. We were left with the impression that any kind/type could be possible.
Stephane asked if CC/PP should be included in the content, ("as in Document Profiles" clarified Roger).
Roger then asked about the protocol or mechanism that would support the management function across the entire process. Al pointed out that many systems have overarching supervisory tasks that supervise other tasks (although these are generally not standardised). He offered WSFL as a potential fit, though the flow language should only be used as an example.
As the diagram began to fill, Roger pointed out that the green boxes at the bottom of the diagram were intended to highlight technologies for standardisation. Several possibilities had been identified during the workshop and were now finding representation in the summary diagram. This was an indication of progress.
The diagram still had its two dimensional character which continued to raise concerns about the placement of items such as "the author". In this respect, Roger pointed out that annotation plays the role of the author in the process so the author only really has to be present at the start. Annotation represents author input.
With respect to the annotation (adaptation hints) it was noted that there was no technology with which to represent this kind of author input. Possibilities include changes or extensions to XHTML, XLink or new technologies. This highlighted a need (within W3C) to address the need for adaptation hints in authored input.
The role of the end-user (client) also needed consideration, and Al proposed that XML Events could represent this layer. However, Roland pointed out that there is a lot more work to be done on XML Events.
It was also agreed that any changes or enhancements should be minimised, to avoid overloading authors who already have to deal with increasingly complex markup. Al remarked that it must be possible for the author to put into the content model anything that can provide input to, or influence, the content that is delivered. This includes style and hints and any other assets that could be comprehended by the delivery system.
During the wrap-up, Roland asked why XML Fragments failed, to which Al suggested that XML Fragments was addressing reuse issues, but was not perceived as an appropriate use of the XML technology.
The meeting closed with a commitment from Roger to tidy and publish the diagram.
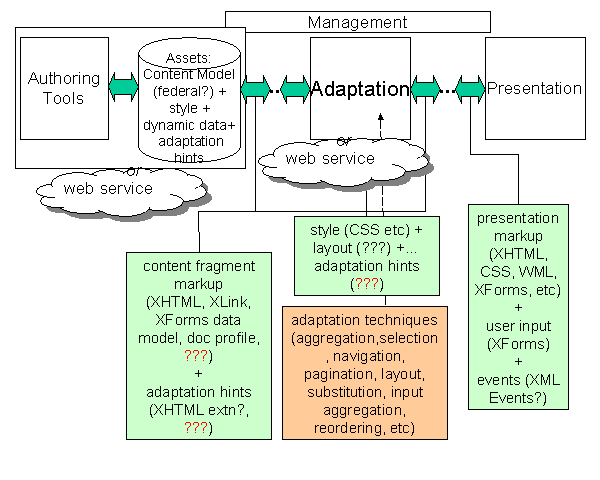
Final version of diagram at end of plenary discussion
Following the workshop, Al Gilman (via the www-di@w3.org mailing list) proposed an alternative diagram for representing the authoring, adaptation and presentation process, based on an IDEF (functional model) diagram.
Further discussion on this and other topics related to the workshop can continue on the public www-di@w3.org mailing list, which is archived at http://lists.w3.org/Archives/Public/www-di/. For further information on W3C mailing lists, including how to subscribe, see http://www.w3.org/Mail/.
Roger Gimson - 8 October 2002