Abstract
Content creators wishing to publish multiple versions of a given
resource on the Web face a number of questions with respect to
how such URIs are created, published and discovered. Questions
include:
Given a resource
http://example.com/ubiquity/
that can be delivered in a multiplicity of representations,
how should one publish the relevant URIs to enable automatic
discovery of these representations (AKA specific resources)?
How does one ensure that the
alternative relationship amongst these
various representations is available in a machine
readable form, and
consequently discoverable?
Here, multiple representations might include:
Representations appropriate for different delivery
contexts
Alternative formats of the resource
distinguished by Content-type
Different versions of the resource e.g., either by
language or date
Representations in different languages
This document explores the issues that arise in this context,
and attempts to define best practices that help:
Preserve the One Web while enabling content
publishing to a multiplicity of delivery contexts.
Enable the creation of RESTful URIs that
remain representation agnostic while delivering the correct
end-user experience.
Enable automatic discovery of the available
representations.
Enable web crawlers discover the relationship between a
given generic resource and the specific resources that correspond to
its various alternatives.
This will help search engines build better Web indices and avoid
the need to index all available alternatives of a given resource.
Status of this Document
This document has been developed for discussion by the
W3C Technical
Architecture Group. This version, dated November 1, 2006
was
approved by the TAG on its teleconference October 31, 2006;
this approval hereby closes the TAG
issue Generic-resources-53.
Publication of this finding does not imply endorsement
by the W3C Membership. This is a draft document and may be
updated, replaced or obsoleted by other documents at any
time.
Additional
TAG findings, both approved and in draft state, may
also be available.
Please send comments on this finding to the publicly
archived TAG mailing list www-tag@w3.org (archive).
1 Introduction
There has always been a need to serve user-agent
specific content for a given URI — thus highlighting the
distinction between Resource and
Representation on the Web. The increasing
importance of the mobile, multilingual Web makes this
requirement even stronger. At the same time, published
content (and its various representations) needs to be
discoverable on the Web; as an example,
crawlers and web-bots need to be able to discover the
availability of alternative forms of a given
resource. Documents published on the Web become
discoverable via the hyperlinked structure of
the Web; to enable discovery of alternative
representations, the relation between these multiple
representations needs to be captured by the hyperlink
structure of the Web. This finding enumerates some of the
issues faced by content creators on the Web today and
proposes a sequence of best practices to foster the
following long-term goals:
Preserve a Single Web
i.e., a Web where content is universally accessible from a
variety of end-user devices.
Ensure that the One Web
enables the easy exchange of resources (and pointers to resources)
across its different facets, i.e.,
mobile and desktop users should be able to share references to Web Resources (URIs)
with the accessing user being able to retrieve an
appropriate representation (specific resource).
Ensure that contents published to a given
facet of the Web are linkable,
discoverable, crawlable,
searchable and
browsable from any of its
other facets.
Enable content providers clearly advertise the
relationship between a given generic resource and the
various specific resources that correspond to the
available alternatives for that generic resource.
2 Use Case Scenarios
This section enumerates the candidate use case scenarios
along with accompanying issues and suggested solutions.
See the next section for
recommended best practices that are a generalization of
these solutions.
The owners of http://example.com/ubiquity
would like to publish their content to a wide variety of end-user
devices ranging from desktop Web browsers to mobile devices such
as cell-phones and PDAs.
They also serve multiple geographies using different languages.
They know about the different markup language variants that are
currently in vogue on these devices, and are capable of
generating the representation that is most appropriate for the
accessing user-agent. In publishing their content and associated
URIs, they face the following issues.
2.1 Publishing Desktop And Mobile Versions
Given generic resource http://example.com/ubiquity/resource
with corresponding alternatives for a desktop browser, a PDA
and a cell-phone:
Should the different alternatives have distinct URIs?
Should the generic resource have a single URI that delivers the appropriate
representation?
If publishing distinct URIs for the resource and its
various representations, how should the relationship
between these URIs be expressed in a discoverable,
machine-readable form? How should this relationship
be reflected in the hyperlink structure of the Web?
2.1.1 Suggested Solution
We suggest the following approach for this situation:
Create representation-specific URIs
(specific resources) for each available
alternative (representation_i), e.g.,
http://example.com/ubiquity/resource/representation_i.
If no content negotiation is in place,
serve a canonical representation (generic resource) of the content at
http://example.com/ubiquity/resource
With that same URI,
use HTTP content-negotiation, along with the correct
HTTP VARY headers to serve up the appropriate representation
at access time. Ensure that the VARY headers capture the right
parameters that were used to choose the representation that is
being served — this is important for correct behavior when
using cacheing proxies.
As an alternative to the previous step,
arrange for the server to generate an HTTP
302 (Found)
redirect to automatically serve up
http://example.com/ubiquity/representation_i
when http://example.com/ubiquity is accessed by
user-agent_i.
This form of redirect involves an extra client/server
round-trip,
and may therefore be suboptimal for mobile devices.
This is a temporary redirect;
the accessing user-agent should continue to use the canonical URI
when creating bookmarks, or emailing URI.
Finally, note that to optimize link traversal out of the resulting
document, the content provider might wish to rewrite relative
links to point at the specific resource.
This will ensure that later uses of the URI results in
expected end-user results; e.g., In the following scenario:
Cell-phone user emails link
Recipiant opens message on a desktop
Clicks on the link
The user following the link from inside the email message on a
desktop browser should receive the desktop version, and not the
mobile version. Notice that passing around the canonical URI is
critical in achieving this behavior.
Additionally, contrast this solution with using HTTP
content-negotiation with VARY headers; using a redirect to the
URI as a specific resource has the advantage of freezing
all parameters that were used to choose that representation into
the URI.
Use linking mechanisms provided by the
representation being served to create
links to the other available
representations. As an example, when using HTML, one
might use a and link
elements to advertize the availability of alternate
representations. In this context, note that there are
two distinct types of such links:
Links for human consumption that are to be
presented to the user
And links for machine consumption, that are
used by the user agent to provide additional functionality.
As an example, links to available alternatives meant
for human consumption might use the HTML
a element since these are rendered by
user-agents. In contrast, links meant for use by bots
might use the HTML link element —
as an example, this reflects present practice when
publishing pointers to
Atom/RSS feeds.
In either case, notice that following these steps
creates a
mini-graph comprising of the canonical URI and URIs
for its various representations.
2.2 Publishing In Multiple Languages
The owners of http://example.com/global
publish their content in a multiplicity of languages.
They wish to publish any given announcement at a
canonical URI,
while retaining the ability to serve up a version in a language
that is most appropriate for the user.
Further, they wish to create URIs for
each available language to facilitate hyperlinking and
discovery. At the same time, they do not wish to hard-wire the
language in which a given announcement is accessed when such URIs
are passed around by end-users.
2.2.1 Suggested Solution
For a design pattern that has worked well over the years, see
the W3C practice of publishing press releases in multiple
languages. Here are its salient characteristics:
Press releases announced with a canonical URI.
Accessing this canonical URI with the appropriate
Language header results in an automatic redirect
that delivers the document in the desired language.
Each language version
contains links to URI's that in turn serve
a representation in one of the other available languages.
Since these translations are typically for
human consumption, these links
are encoded as HTML
a elements so that they get displayed in
browsers.
2.3 Publishing Continuously Updating Content
The owners of http://example.com/blogosphere/current
publish up-to-date content. Once published, they would like users
to be able to reliably bookmark the published content.
At the same time, they would like end-users to be able to always
access a canonical URL when looking for the most
recently published content.
2.3.1 Suggested Solution
The issue identified here has been faced by and solved
successfully during the last few years by the blogging community.
Accessing a blog's canonical URI retrieves recent
posts.
Posted items have a bookmark or
permalink pointer that can be used to reliably
access postings from the past.
Pointers to alternative content are encoded
as link elements. This enables agents
such as blog-readers, content-aggregators and Web
crawlers to discover the availability of alternative
versions. Note that this design pattern is widely
deployed on the Web in the context of RSS/ATOM feeds
to advertize permalinks and other pointers to make
them discoverable. In the case of RSS/Atom feeds,
this has enabled Web sites to embed such links within
the head element of HTML pages, and have
them revealed to the user by Web browsers
that are capable of consuming such feeds.
3 Recommended Best Practices
As can be seen from the use-cases and suggested solutions
enumerated in the previous section,
pointers to Web Resources (URIs) can either:
Be canonical URIs, i.e., have no context
hard-wired. Such canonical URIs identify a generic resource.
Encapsulate partial context, e.g.,
language. Such URIs identify a specific resource that is
one possible alternative of a generic resource.
Encapsulate multiple context bits, e.g., language and
device profile.
Capture all context, i.e.,
the creator of the URI guarantees that all state is
completely captured by the URI.
Our primary take-aways from the these observations are:
URIs are cheap, we suggest creating as many distinctive
URIs as is meaningful.
The hyperlink structure of the Web is crucial
for content discovery; when creating a multiplicity of
URIs for a given canonical resource, ensure that the
relationship amongst these multiple URIs is captured by
the hyperlink structure of the content. This will ensure
that Web user-agents (both human-facing as well as web
crawlers) are able to discover the various available
alternatives and even more importantly, discover the
inter-relationship amongst these specific resources,
and their mutual relationship to the generic resource.
Encourage users and user-agents to work with
canonical URIs; leave it to the underlying
infrastructure to generate appropriate redirects in
order to serve users the appropriate representation
(specific resource). For each such available
representation that is generated as a function of user
context, ensure that there is a URI that can reproduce
that representation (specific resource) in the absence
of user context; or equivalently: for every
representation, ensure that there is a URI that
hard-wires all user context e.g., language, device
preference etc., required to generate that
specific resource.
4 Conclusions
Principal conclusions:
URIs are cheap.Create them as needed, publish them to
the Web, and ensure that they are appropriately linked in to the
rest of the Web.
Thus,
each representation of interest should
get it's own URI (become a specific resource)
and there should be one additional URI representing the
generic resource.
Enable discoverability of alternative representations by
leveraging the hyperlink structure of the Web.
Thus,
given one of the alternatives for a resource, ensure that one can reach the corresponding generic
resource
by traversing a contained hyperlink.
When creating a generic resource
with multiple alternatives, encode hyperlinks to the available
alternatives with the generic resource. This will enable crawlers
and other web agents discover the availability of these
alternatives,
and to establish the correct semantic linkage amongst the various
alternatives.
Hyperlinks can be designed either for human consumption
(HTML a element), purely for machine consumption
(HTML link element), or both.
To maintain a single Web,
ensure that the hyperlink structure of the Web is leveraged to
create a graph structure whose transitive closure includes all
available representations of a given generic resource.
5 Open Issues
This finding has highlighted the need to capture the
relationship between a generic resource and its specific
alternatives. We have illustrated such linking using the present
practice of using link elements with an appropriate
rel attribute.
It would be useful for groups defining various hypertext formats
to arrive at a common set of values for the rel
attribute
that appropriately capture the various types of relationships
that are envisioned amongst a generic resources and its specific
alternatives --- for some initial ideas, see W3C Architecture: Generic
Resources
which sketches an ontology;
also, see TAG
Issue 51 (Standardized Field Values).
6 Figures
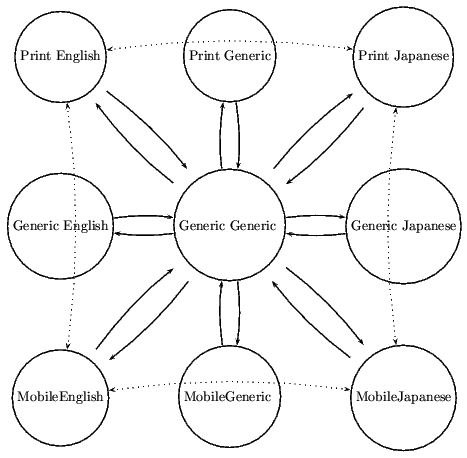
This figure shows a Generic Resource along with
its multiple representations. In addition to its generic
representation, the resource is available in print and mobile
versions in both English and Japanese. URIs are assigned to each
of these possible representations, and the illustration shows
that these individual representations (specific resources) have
links to/from the Generic Resource. Additional
dotted arcs indicate that the content provider may create
additional links that connect specific resources.