W3C | Semantic Web | SWAP
This is a collection of examples to accompany the Primer. (The files have URIs starting http://www.w3.org/2000/10/swap/test/ if you are reading this on paper.) These are designed as examples, to show how something can be done, not as working products.
Remember, to convert an RDF document from n3 syntax into xml syntax,
cwm xxx.n3 -rdf should do it among other things. I haven't
exhaustively tested all combinations of n3 and RDF in all cases.
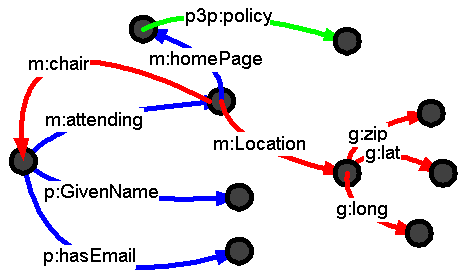
When explaining why the semantic web needs to be a web not a tree, I used
slides showing information in blue from one source (blue links) with that
from another sources (red and green links).
The key point, of course, is that URIs are used to identify the overlap concepts such as the person, meeting and its home page. This allows the graphs to be merged. It is a simple RDF example, let's see what it looks like:
cwm -rdf
blue.n3)
cwm red.n3 blue.n3 green.n3 > white.n3, in XML)Here is an ontology for geneology, (where from?). Thanks to Jos De Roo for putting this into N3.
The owners of the next two ontologies retain all rights, so you should not copy them for the purposes of making your own ontology.
These examples do not contain rules, just ontology information in DAML. DAML allows you to describe the properties and class you create and the relationships between them. Here are two fairly large examples from biochemistry. They seem to have been generated using the OILED software. They are just here as examples.
The tambis ontology was provided as an example by Ian Horrocks. Files in
test/tambis
Eric Neumann kindly provided a sketch ontology from the biopathways consortium.
In the semantic web, there are many different forms of document validity. One useful form is to check that the document doesn't violate any rules associated with the vocabularies it uses, and that for each namespace it uses, every term it uses is actually mentioned in the schema for that namespace.
The command line I used with the closed world machine was
cwm daml-ex.n3 invalid-ex.n3 schema-rules.n3 -think -filter=schema-filter.n3
This combines the schema, the document and the rules, and draws all possible conclusions, then filters out any conclusions of invalidity.
The rules are by no means complete, and this is by no means the only way to do validation. A special-purpose program would be more efficient of course. However, this demonstrates how easy it is when data is a semantic form to process it using a general purpose engine.
(update Mar 2002: see validate.n3 discussed below)
The a transitive property, like ancestor, is one such that if Fred is Joe's ancenstor, and Joe is Bill's ancenstor, then Fred is Bill's ancenstor. That (for all Fred, Joe and Bill) is a rule for "ancenstor", and the fact that that is true for any transitive property in place of "ancenstor" is the definition of transitivity.
There were some axioms for RDF and RDFS and DAML prodcued by Deborah McGuiness and Fikes for the DAML work, in KIF. KIF list syntax is pretty like N3 list syntax so a sed file converts the KIF to N3 list syntax. Then, a bunch of rules decorate the lists with their equivalent in N3. The result is quite a mess, but all the intermediate results are labelled as "log:Chaff". This magic class has the feature in cwm that -purge removes any statements from the store which mention (as subject, verb or object) anything which is in class Chaff.
The process is very recursive, and so uses the -think option on cwm, which iterates over all rules. It takes (2001/02) a long time, partly beccause it is not directed in its simple-minded approach, and partly because it is not optimised. The rules are by no means complete, so the axoim set is not translated in its entirity. This example is unfinished but still may be instructive.
Many see the semantic web's impact on the industry as a tool for Enterprise Application Integration. That is, just as the web integrates human-oriented information systems, so the Semantic Web integrates applications in which data has well-defined meaning. Here are some files which represent data which deal with technical architecture and the organizational structure around W3C. Imagine that these had been produced from specific applications for technical design and organizational management. Now it happens that there is a need bit of free softrware called GRphviz which is a tool for drawing diagrams. Putting all three together we can draw digrams of relationships between technical architecure and consortium organization. We can also make rule files to extract subsets of this data when focussing on a specific problem or area.
The schema validation above looked for inconsistencies with a schema. The
example worked by the file and the schemas being given to cwm on the command
line. However, it would be more useful to find the schemas automatically. By
using notation3's formulae, it is possible to extract all the predicates used
in an RDF document. If the namespace's URI scheme is dereferencable (such as
http:), or if the user has a local schema catalog, then one should be able to
look up the schema in real time. The is done with cwm's builtin
log:semantics which gives the N3 formula corresponding to the
parsing of the semantic content of a resource.
Note how, when validate.n3 follows a URI to a schema, it doesn't just believe it - it looks objectively at what it says. People early on with the Semantic Web were always afraid that inconsistencies could be sown which would trip up browsing agents. It is fundamental that you don't beleive everying on the Web. The log:semantics and log:includes built-ins allow rules to look objectively at other documents to see what they say.
As well as checking that the prediccates used are indeed declared as
Properties in the schema, this file also checks consistency as the example above. This involves, for each schema, finding the set of
facts which the schema implies. In other words, you don't have to state
explicitly in the schema that something is (say) a class, if you have already
said that it is a subclass of something. The validate.n3 rules takes each
schema, merges it with the schema rules, and finds all the conclusions. This
gives an augmented schema -- the schema plus the things implied by
it according to the defined meanings of the terms (like subclass) used. This
uses the built-ins log:merge (for merging formulae) and
log:conclusion (for doing, in effect, a cwm
--think internally on a specfic formula).
Try using the crypto module (thanks to Sean Palmer) for making rules which only accept information from resources on the web if they have the right cryptographic hash, or the right digital signature.
Adding cryptographic functions to an semantic web engine makes it into a trust engine. This is important for the
Suppose we want to give access to the W3C "member lounge" web site to the emplyees of member organizations. We trust any organization's appointed representative to say who is an employee. This can be done very simply using public key cryprography. The bare bones of the system are mapped out in part of the cwm cryptography test suite.
There is a regresion test for cwm which uses many files.
These are simple semantic web examples in N3 and RDF syntaxes made typically in order to test the software, but you can use them to test your understanding.
Tim BL, with his director hat off
$Id: Examples.html,v 1.20 2002/05/15 19:49:25 timbl Exp $
{kind=link}
{kind=link}
{kind=link}