![]()
![]()
A presentation in the Mobile track of the WWW'9 Developer's Day, held in Amsterdam on 19th May 2000.
Access via any telephone
Hands and eyes free operation
Devices too small for displays and keyboards
WAP-phones
Palm-top organizers
Universal messaging
Mature algorithms
Speech recognition using HMM
Dictation grammars (N-gram)
Context-Free grammars
Speech synthesis – formant and concatenative models
How Moore’s law is helping
Working Group formed in March 1999, following workshop in October 1998
Public working drafts on requirements for:
Spoken dialogs
Reusable dialog components
Speech synthesis
Speech grammars
Natural language semantics
Multi-modal dialogs (coming soon!)
Now working on drafting specifications
Further info: http://www.w3.org/Voice
Application and user take turns to speak
Form filling metaphor
Prompt user for each field in turn using synthetic speech and prerecorded audio
Use speech grammars to interpret what user says
Offer help as needed
Submit completed form to back-end server
Links to other “pages”
Break out to scripting as needed
Context free grammars describe what user says, each rule associated with a semantic effect

| “I want to fly to London” | Destination= “London” |
[I want to fly to] $City { destination = $City
}
$City = London | Paris | Amsterdam | Milan
Speech Synthesis engines are smart
Basic properties: volume, rate, pitch
Speech font selection by name, gender, age
Control over how things are pronounced
Prerecorded audio effects
W3C Speech synthesis markup language
We plan to revise ACSS
C (computer): Welcome to the weather information service. What state? H (human): Help C: Please speak the state for which you want the weather. H: Georgia C: What city? H: Tblisi C: I did not understand what you said. What city? H: Macon C: The conditions in Macon Georgia are sunny and clear at 11 AM …
<form id="weather_info">
<block>Welcome to the weather information service.</block>
<field name="state">
<prompt>What state?</prompt>
<grammar src="state.gram" type="application/x-jsgf"/>
<catch event="help">
Please speak the state for which you
want the weather.
</catch>
</field>
<field name="city">
<prompt>What city?</prompt>
<grammar src="city.gram" type="application/x-jsgf"/>
<catch event="help">
Please speak the city for which you
want the weather.
</catch>
</field>
<block>
<submit next="/servlet/weather" namelist="city state"/>
</block>
</form>
In the short term, it’s best to leave the initiative with the system
Mixed initiative dialog allows you to answer a question with a question
Further work is needed to understand how to make it simple to author such systems
W3C is working on ways to represent natural language semantics
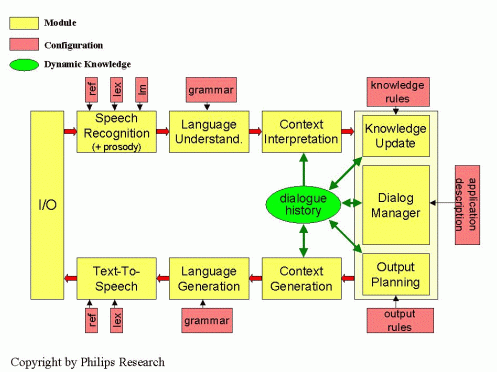
Richer dialogs become possible with the addition of mechanisms for handling dialog history, thereby allowing statements to be made in reference to what was spoken a few turns back. Some indication of the kinds of architecture needed to support this can be seen in the following diagram provided by Philips Research:
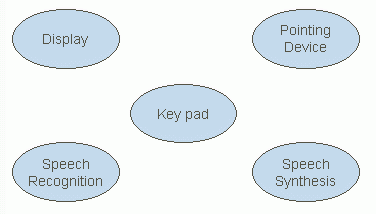
Pure interactive voice response systems are restricted to voice input and output. The simplest extension allows users to make choices via pressing keys on a telephone key pad. Moving beyond this, the addition of a display, pointing device and richer keyboards, opens up the possibilities of multi-modal interaction.
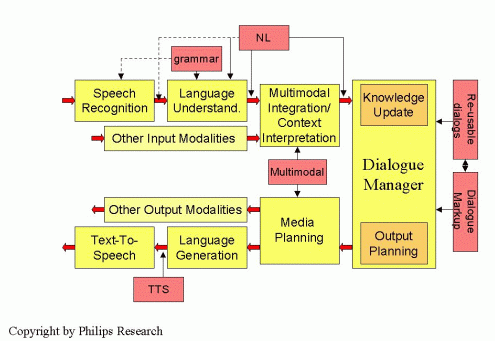
Multi-modal systems combine modalities such as display, keypad, pointing device, speech recognition, and speech synthesis. The following diagram from Philips Research gives an indication of how this can effect the architecture:
Tight and loose coupling between modalities
VoiceXML includes support for key pads using DTMF grammars
W3C is looking at different approaches
Marianne will demo one approach
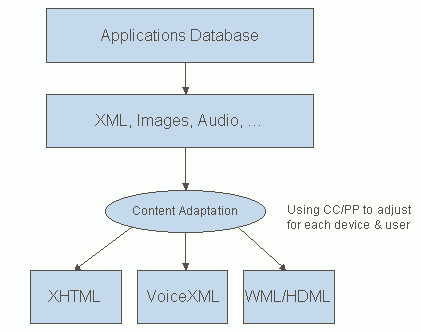
The key thing to implement is a separation of presentation from your content. This allows you to reuse the content for each channel. The starting point is the applications database. This dynamically generates XML, images, audio and other data. This is then poured into templates to match the device capabilities and user preferences. This exploits CC/PP. The end result is XHTML for desktop browsers, VoiceXML for telephony-based IVR systems, and WML for cell phones.
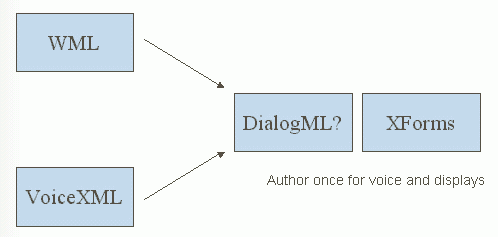
A number of current specifications have significant overlaps. There is an opportunity to "renormalize" into a suite of modular parts. Can we learn from VoiceXML and WML? Can we combine these into a new dialog markup language so that you can target small displays and voice interaction with a single document? W3C's work on XForms also has a part to play as a means to define a way to separate the presentation from the application data and logic.