NOTE-MCF-XML.html
Meta Content Framework Using XML
Submitted to W3C 6 June 97
- This document is available at:
- http://www.w3.org/TR/NOTE-MCF-XML-970606
- Editors:
- R.V. Guha (Netscape Communications) <guha@netscape.com>
Tim Bray (Textuality) <tbray@textuality.com>
Status of this Document
This document is a NOTE made available by the W3 Consortium for discussion only. This indicates no endorsement of its content, nor that the Consortium has, is, or will be allocating any resources to the issues addressed by the NOTE.
This document is a submission to W3C from Netscape Communications. Please see Acknowledged Submissions to W3C regarding its disposition.
Abstract
This document provides the specification for a data model for describing information organization structures (metadata) for collections of networked information. It also provides a syntax for the representation of instances of this data model using XML, the Extensible Markup Language.
Table of Contents
1. Introduction1.1 History and Motivation
1.2 The Basis of MCF
2. The MCF Data Model
2.1 Labels, Nodes, and Arcs
2.2 Units and Primitive Data Types
2.3 The Set of Bootstrap Nodes
3. Representation of MCF
3.1 Syntax
3.2 Special Idioms
3.3 Linking to Schemata
3.4 Processing MCF Blocks
4. Examples
4.1 The Acme Content Company Web Site
4.2 Schema Extensions for Acme
4.3 A Simple DTD
Appendices
A. Standard VocabularyA.1 Categories
A.2 Property Types
A.2.1 Properties used to describe Agents
A.2.2 Properties used to describe Content
A.2.2.1 Authorship Related Properties
A.2.2.2 Properties related to the size of the object
A.2.2.3 Temporal properties of the content
A.2.2.4 Properties about the content itself
A.2.2.5 Properties about content access
A.2.2.6 Other properties about content
A.2.3 Properties related to schedules.
B. Acknowledgements
1. Introduction
1.1 History and Motivation
The need for machine-usable descriptions of collections of distributed information is increasing rapidly. There have been a number of proposals in the recent past that have made significant steps toward this goal, including HotSauce MCF, CDF, PICS, and WebCollections.
The existence of multiple proposals reflects the fact that this type of information is needed for multiple purposes, and that there are many groups interested in its availability and use. This diversity of effort is reflected in a diversity of terminology; discussions have been couched in terms of "metadata", "typing", "schemas", "labels", and "collections," while all in fact dealing with the same underlying constructs and problems.
We believe the following principles to be central to making progress in this area:
- There is no useful distinction between data and metadata. Every item of information, without exception, is likely to be regarded by some applications as ancillary and never to be displayed, and by others as core content that needs to be formatted, printed, or searched.
- For interoperability and efficiency, schemata designed to serve different applications should share as much as possible in the way of data structures, syntax, and vocabulary.
The second principle is what really drives this proposal. It is inevitable that there will be a plethora of classes of information about information; note some of the examples listed above. If they share a common syntax, this is good, but it is not enough. For example, suppose a mature commercial word processor package were to offer a "save as XML" format, which exported an XML representation of its internal document data structures and attributes. While marginally more open than the processor's native format, this would not be of any substantial use, because to operate on this file would de facto require the use of the program which generated it.
To a certain extent this is inevitable - in many cases, data created for the purposes of a particular application will contain items that are only meaningful to that application. But the situation can be greatly improved. If information about information can share a common data model and vocabulary, it will be possible to query and manage metadata to some degree, even without fully understanding it.
1.2 The Basis of Meta Content Framework
In this document, we draw upon the features provided in the other proposals mentioned above, and on other work in this area, to develop a single data model and corresponding interchange format which can be used for many purposes, including for example
- describing the structure of web sites or a set of channels
- threading email
- PIM functions
- distributed annotation and authoring
- exchanging commerce-related information such as prices, inventories, and delivery dates
Meta Content Framework (referred to henceforth as MCF) is a structure description language. The field of structure description languages is well understood and it is not our desire to reinvent any of it. Our goal is to select the portions of it that are required for our task. One benefit of this approach is the ready availability of tools and algorithms for manipulating MCF.
We abstract an information organization structure as a Directed Labelled Graph (DLG). DLGs are well understood and as far as possible, we will use the terminology that is standard to the treatment of DLGs. In MCF, relationships between objects are represented in an unsurprising way by DLG arcs. DLG arc labels are themselves objects which participate in relationships.
New kinds of data appear on the web routinely. It should be possible to extend MCF dynamically to accommodate them. Furthermore, the list of potential applications for MCF is open-ended and each application might wish to add and use its own kinds of metadata. Though an application might associate arbitrary semantics with the new labels, it would be highly desirable if some significant portion of these semantics could itself be expressed with MCF. In light of these requirements, using DLGs, we include a simple, extensible type system as part of MCF.
2. The MCF Data Model
2.1 Labels, Nodes, and Arcs
An MCF database is a set of Directed Labelled Graphs, comprising:
- a set of labels (often referred to as properties)
- a set of nodes
- a set of arcs where each arc is a triple consisting of two nodes (the origin and destination) and a label.
In MCF, nodes can represent things like web pages, images, subject categories, channels, and sites. They can also represent "real-world" objects such as people, places, and events. The labels are nodes that correspond to properties such as size or lastRevisionDate used to describe web pages, subject categories, etc., and also to relations (such as hyperlinks, authorship or parenthood) between these things.
Each label/property is a node (but not all nodes are properties). So, if we had a label pageSize that is used to specify the basic size of documents, we would also have a pageSize node. This node could itself participate in relationships that help constrain and therefore specify the semantics of pageSize. We would for example specify that the domain of pageSize is Document and its range is SizeInBytes and that a document has exactly one pageSize. We would also use a Property to provide human readable documentation of the intended semantics of pageSize.
The figure below illustrates some simple nodes and properties, illustrating that how properties can be attached to properties.
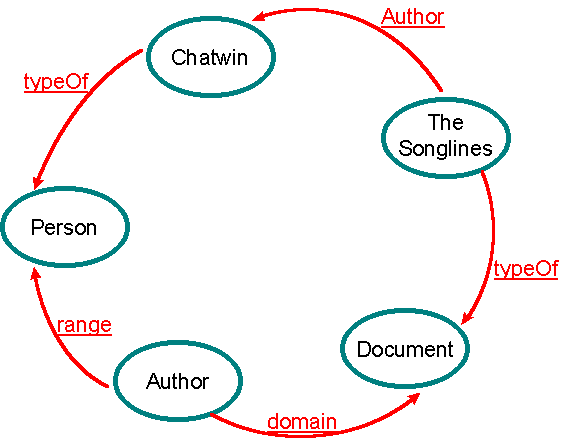
This self-description allows MCF to be its own schema definition language. This in turn allows MCF to be dynamically extended by an author or application.
2.2 Units and Primitive Data Types
A node can either be a primitive data type or a "Unit". The primitive data types are the same as the Java primitive data types. In addition, a DATE type should be supported by the low-level MCF machinery, because it is tricky to implement (beyond the reach of regexps, for example) and yet commonly available in operating system and compiler libraries, e.g. java.util.
The concept of "Unit" corresponds loosely to the Java concept of "Object".
Every unit has a unique identifying string, called its unique identifier. To simplify syntactic expression of MCF, the unique identifiers of Category and Property units (defined below) are constrained to be valid XML Names. For objects addressable on the Web and which have a canonical URI, it is expected to be common practice to use the URI as the unique identifier.
2.3 The Set of Bootstrap Nodes
A small set of units with predefined semantics are assumed to exist in order to bootstrap the type system. Specifically, these are,
typeOf- this is the Property used to specify that the given object is of a certain type. A node can be the origin of multiple typeOf arcs; for example, the node for a person can simultaneously be typeOf Person, typeOf Golfer, and typeOf Doctor. Every unit has (at least implicitly) a typeOf Property, since Unit is a type.
Category- This corresponds to the concept of Class. The destination of typeOf arc has a typeOf arc which ends at Category (with the single exception of the node for "Category" itself).
Unit- This is the most general Category. It is implicitly or explicitly the super class of all Categories (with the single exception of the node for "Unit" itself).
domain- this Property is used to specify the type constraints on the use of a Property, in particular of its origin node; the range of domain is Category.
range- this Property is used to specify the type constraints on the use of a Property, in particular of its destination node. The range of range is Category.
superType- this Property is used to indicate the superset relation between Categories.
Property- this is the typeOf all properties/arcs/relations.
FunctionalProperty- Certain properties behave like functions, i.e., there can be at most one arc of that type originating from a given node and every object in their domain has one. e.g., lastRevisionDate. Such properties are typeOf FunctionalProperty.
superProperty- a relation between two properties. If s1 is a superProperty of s2, then the existence of an s2 arc between nodes A and B implies that there is also an s1 arc between A and B. E.g., biologicalParent is a superProperty of biologicalFather.
mutuallyDisjoint- a reflexive relation between two categories which implies that nothing can be an element of both these categories simultaneously. For example, the categories for the built-in types (int, float, etc) are all mutuallyDisjoint.
name- this can be used to provide a string which names the object. An object may or may not have a name, though for convenience, it is assumed that properties and categories will be given names.
description- a descriptive string used for human consumption.
parent- is is the most generic relation. The domain and range are Units.
Sequence- This category is a special convenience used to express sequences. It is normally expected to source a number of arcs whose labels are natural numbers sequentially increasing from 1; the targets of these arcs are the nodes which are to be considered sequenced.
ord- (short for ordinal) is a property not actually used in MCF, but which is reserved because the label is needed for the syntactic expression of MCF in XML.
As a convention, the identifying strings and names of the commonly used terms (including those listed above) are the same. Also, properties are named beginning with a lower-case letter and non-properties with an upper-case letter.
Though it is possible for a source of MCF to only assume the basic bootstrapping vocabulary and define everything else it needs dynamically (i.e., as part of the MCF database), for purposes of interoperability, it would be good to standardize the vocabulary for commonly used terms. This will also reduce the amount of information that needs to be transmitted. An appendix to this document proposes some items for this vocabulary (largely derived from existing standards such as the Dublin Core) for describing web content.
3. Representation of MCF
3.1 Syntax
Our goal is to provide an XML based syntax for representing MCF. XML aims to serve as a general purpose data representation language. One of the components of any adequate data representation language is a type system; MCF attempts to provide such a type system for XML.
MCF is expressed using XML syntax with a few conventions provided by this specification. The entire MCF (which may occur as a separate file or be embedded within HTML) is wrapped inside a block. All MCF blocks are well-formed XML.
Given XML's flexibility, a number of strategies could serve for expressing MCF structures in terms of elements and attributes; all would be essentially isomorphic. However, it seems likely that it will be common practice to use MCF to express a series of facts about some object, framed as arcs with that object as the source. Thus, the source is expressed as a container element, with a series of child elements each representing a Property, or arc with that source. The destination of the arc is represented using one of the attributes VALUE or UNIT attached to the "Property" element. The use of UNIT indicates that the destination is another unit, and, the UNIT is its unique identifier. The use of VALUE indicates that the node represents a datum of a primitive type; for example, a date would be given with VALUE=, but a more sophisticated type such as MONTHLY would be a Unit.
The unit description element uses the typeOf the unit as the element name. The unit description element must have an attribute ID which specifies the unique identifier. If the unit is an element of more than one category, the additional categories can be specified using typeOf elements.
3.2 Special Idioms
Beyond the above, there are several special XML idioms available for convenience in representing certain Properties.
parent- The simple parent relationship may be expressed simply by inclusion. That is to say, a source container element may contain not only Property elements but also other source container elements; the effect is exactly the same as as if the contained source container were standing alone and contained a parent property pointing at the containing element.
description- The range of a description is expected to be a potentially lengthy piece of free text, which might even include markup. For this reason, the value of the description property is provided in the content of the description Property element.
Sequence- A Sequence node may have Properties whose labels are just numbers, sequentially increasing from 1, whose range is the sequenced nodes. These are expressed in XML simply by replacing the numbers with the reserved property ord; the order in which these Property nodes appear in the XML entity corresponds to the numeric labels.
3.3 Linking to Schemata
The sharing and re-use of schemata is uncontroversially good. In order to avoid duplication, we propose use of the XML Hyperlink machinery to refer to externally-stored MCF blocks. While details of this syntax will have to wait for that specification to stabilize, the following examples contain references which should be at least suggestive.
Of course, when multiple schemata are in use, a namespace problem occurs. In the following examples, we use the syntax of the recent Layman/Bray proposal; but the namespace resolution mechanism is an orthogonal problem.
For HTML pages, presumably the HTML LINK element would be used to associate MCF files.
3.4 Processing MCF Blocks
If a program reading an MCF block encounters a semantic contradiction, the entire MCF block is to be considered as unreliable and information from it is not to be used. An example of such a contradiction would be two arcs originating from the same node, labelled with a Property that has been declared a FunctionalProperty, or for example, assertions that some node is both typeOf float and typeOf character.
Note, however, that different MCF blocks, obtained from different sources, describing same object, may be inconsistent. The decision as to how this should be handled is highly application-dependent.
4. Examples
4.1 The Acme Content Company Web Site
The following example uses MCF to describe a range of information about the website of the Acme Content Company.
The following segment contains information that can be used for diverse purposes. For example,
- a robot could use it to determine which portions of the site to index.
- a browser could use it to present a site map.
- a channel client could use it to periodically download portions of the site.
- the rich information here could be used by a search engine to provide better search (filters, concept based searches, etc.)
|
4.2 Schema Extensions for Acme
The following describes the schema extensions made by the Acme Content Company that are available from http://www.acme.com/AcmeVocab.mc This is a very small extension, but it illustrates the concept of how MCF can be used to extend itself:
<xml-mcf> |
4.3 A Simple DTD
Consider the following DTD:
<!ELEMENT EMAIL (HEAD, BODY)> |
The XML expression of the MCF version makes heavy use of the Sequence construct:
<XML-MCF> |
Appendices
A. Standard Vocabulary
In addition to the basic bootstrapping terms (typeOf, Category, etc.) specified earlier, in order to promote interoperability, we also propose some standard vocabulary that can be used for purposes of describing the kinds of content typically found on the web.
Such standard schemata are very important, but are separate from the data model and the transfer syntax. The purpose of this section of the proposal is to initiate a discussion. There is significant work to do in this area, but it should be started now.
Though the following can easily be specified in MCF itself, for purposes of readability, we provide the following description in English. The MCF specification will however be made available for authors.
An author can use this vocabulary as the schema for their MCF (by using XML-transclusion) and make further modifications and additions to it as they need.
A.1 Categories
As a convention, Categories (are in the singular. So, the category of all people is called Person and of all organizations is called Organization.
Also, even though MCF is case insensitive, for purposes of human readability, as a convention, categories start with a capital letter and properties start with a lower case letter.
The name and identifier for all of the following are the same.
Content- Includes everything from websites and web pages to legacy databases and file folders. Its superType is Unit.
ContentContainer- A collection of information. Includes subject categories, file folders, channels, etc. Its superType is Content. There are no constraints on the items belonging to a container. The items in a container could themselves be containers. The relation between an item belonging to a container and the container is just parent (though we might want to eventually introduce a more specialized relation.) The distinction between a container and non-container is one of convenience. There will be cases where we want to consider a single page as a container and in other cases, we might want to consider the same page as an atomic entity. The flexibility of MCF allows us this freedom.
Subject- The category of subjects. An example is the Arts category in Yahoo! or the portion of the Developer portion of the Netscape Website. Its superType is ContentContainer.
WebSite- A web site. Its superType is ContentContainer.
Page- A document. Could be a WordPerfect document on a PC or a web page or even a FileMaker database. Its superType is Content.
Agent- The concept of an Agent is a general one intended to cover people, robots, organizations, etc. Its superType is Unit.
Organization- Examples include Apple Computer, United States and the Peace Corps. Organizations are mutually disjoint with people. Its superType is Agent.
Person- The category of people. Its superType is Agent.
TableOfContents- The table of contents for any Content (could be for a web site, page, ...) Its superType is Content.
NaturalLanguage- Examples include English, French, etc. Its superType (for now) is Unit.
Schedule- This category is used to specify information like the periodicity with which content is updated, when it should be pulled down, etc. The range includes both simple instances like Hourly or Daily to instances with intermediate complexity like daily at eight am to more complex instances (such as that proposed by CDF) like hourly between eight am and six pm on weekdays...
A.2 Property Types
A.2.1 Properties used to describe Agents
There has been much work in standardizing vocabularies for describing agents, most notably vcard, and we hope to adopt those standards as applicable. In addition, we should also provide standard properties for describing the location, hobbies, etc. of agents.
emailAddress- A string representing the email address of an agent.
homePage- The url of the home page(s) of an agent.
contactInformation- A string representing how the person can be contacted.
A.2.2 Properties used to describe Content
Existing standards that these draw from (and will rely upon even more in the future) include the Dublin Core, Z39.50 and of course, the rich body of work in Library Science.
A.2.2.1 Authorship Related Properties
authorIndividual- The individual person(s) who is(are) the authors of the content object. The entries are not names of the authors but references to objects corresponding to the authors. The name, email address, etc. of the author can be specified on that object.
authorOrganization- The organization which is the author of the content object.
author- The generalization of the previous 2 propertiess. The is a superProperty of both of them.
editor- The agent that is the editor of the content object.
publisher- The agent that is the publisher of the content object.
contactAgent- The agent who is the "contact" for that piece of content. Typically the person behind "webmaster@xyz.com".
copyright- The copyright declarations. The range is a string.
A.2.2.2 Properties related to the size of the object
size- The size of a content object in bytes. Represented using an integer. This is the size of the object alone and does not represent the size of its inclusions (like in-line images).
loadSize- The total number of bytes, including inline images, plugins, etc. of a content object.
A.2.2.3 Temporal properties of the content
Some more temporal properties appear under Schedules.
publicationDate- The date on which a content object was first published.
lastRevisionDate- The date on which the content object was last modified.
expires- The date until the information in this content object is valid.
contentUpdateSchedule- The frequency with which this is typically updated. The range is a Schedule (which includes Hourly, Daily, etc. and also more complex Schedules.)
versionNumber- The version number of this content object or subject category. A string.
contentDownloadSchedule- This is to be used if the content is to be proactively downloaded to the users computer. It specifies the download schedule and the entry is a Schedule.
nextUpdateTime- The next time that this piece of content is scheduled to be updated.
nextDownloadTime- This is also to be used if the content is to be proactively downloaded to the users computer. It specifies the next time this piece of content should redownloaded. More often than not, this will suffice in lieu of a full blown schedule and will default to the nextUpdateTime.
A.2.2.4 Properties about the content itself
subject- The subject categories that this content object falls under. parent is a superProperty of subject. Using this, an author could for example suggest that his/her page belongs to a certain Yahoo! subject category.
language- The language(s) (typically a natural language such as English or French) in which the content is primarily encoded.
toc- One or more tables of contents of which this content object is a part.
siteHomePage- The home page for the site of which this content object is a part.
helpPage- The page at which help can be found regarding this content object.
linksTo- The content objects that a content object has hyperlinks to. parent is a superProperty of linksTo.
includesContent- To be used when one content object includes another (such as an HTML page including an image or a poem). This is useful when we want to distinctly identify a certain piece of a page, such as a table, as a first class unit and specify the relation between the enclosing page and table.
contentMimeType- The MIME type of the content.
contentPartMimeTypes- A convenience predicate for specifying the mime types of all the included content.
superTopic- A relational between two subject categories such as Yahoo Arts and Yahoo Arts Museums which states that the later is a more specific subject category of the former. parent is a superProperty of superTopic.
objectIcon- An icon that can be used to represent the object. The value is typically the object corresponding to a GIF or JPEG, but could also be a platform specific encoding. Preferably, it will be one object with several different encodings being available.
A.2.2.5 Properties about content access
location- One or more URIs at from which object content may be obtained.
contentMirror- Mirror uris for this content object. Mirrors are assumed to be secondary sources of the content, which might potentially be stale. The distinction between mirrors and location is subtle at best.
contentAvailabilityStatus- This Property can be used to specify information like whether the server is down, the last time the content was accessible, etc. This meta-content is typically furnished not by the content provider himself, but by indexers like Yahoo!
A.2.2.6 Other properties about content
accessMode- This is used to specify whether the content is to be accessed via the traditional Web pull mechism, via email (e.g., InBox Direct), via channels, etc.
contentRating- The intent of this Property is to contain the information that would be contained in a PICs-like rating. The range is Rating.
contentCost- The cost of this content. The range is a Cost, which could be as simple as "5 US Dollars" or something much more complex. The more complex specification is beyond the scope of this proposal.
A.2.3 Properties related to schedules.
scheduleStartDate- This is the day upon which the schedule will start to apply.
scheduleEndDate- This is the day upon which the schedule expires and no longer applies.
scheduleIntervalTime- The interval of time that the schedule should repeat over.
scheduleEarliestTime- Earliest time during the schedule interval that the schedule applies to.