This document is a NOTE made available by the World Wide Web Consortium for discussion only. This indicates no endorsement of its content, nor that the Consortium has, is, or will be allocating any resources to the issues addressed by the NOTE. A list of current NOTEs can be found at: http://www.w3.org/TR/.
This document is a submission to the W3C. Please see Acknowledged W3C Submissions regarding its disposition.
Contents:
We thank Paul Grosso(ArborText), Sharon Adler (Inso Corporation), Anders Berglund (Inso Corporation), François Chahuneau (AIS/Berger-Levrault)for their help and contributions to this proposal.
Schemas define the characteristics of classes of objects. This paper describes an XML vocabulary for schemas, that is, for defining and documenting object classes. It can be used for classes which as strictly syntactic (for example, XML) or those which indicate concepts and relations among concepts (as used in relational databases, KR graphs and RDF). The former are called "syntactic schemas;" the latter "conceptual schemas."
For example, an XML document might contain a "book" element which lexically contains an "author" element and a "title" element. An XML-Data schema can describe such syntax. However, in another context, we may simply want to represent more abstractly that books have titles and authors, irrespective of any syntax. XML-Data schemas can describe such conceptual relationships. Further, the information about books, titles and authors might be stored in a relational database, in which XML-Data schemas describe row types and key relationships.
One immediate implication of the ideas in this paper is that XML document types can now be described using XML itself, rather than DTD systax. Another is that XML-Data schemas provide a common vocabulary for ideas which overlap between syntactic, database and conceptual schemas. All features can be used together as appropriate.
Schemas are composed principally of declarations for:
All schema declarations are contained within a schema element, like this:
<?XML version='1.0' ?> <?xml:namespace name="urn:uuid:BDC6E3F0-6DA3-11d1-A2A3-00AA00C14882/" as="s"/?> <s:schema id='ExampleSchema'> <!-- schema goes here. --> </s:schema>
The namespace of the vocabulary described in this document is named "urn:uuid:BDC6E3F0-6DA3-11d1-A2A3-00AA00C14882/".
The heart of an XML-Data schema is the elementType declaration, which defines a class of objects (or "type of element" in XML terminology). The id attribute serves a dual role of identifying the definition, and also naming the specific class.
<elementType id="author"/>
Within an elementType, the description subelement may be used to provide a human-readable description of the element's purpose.
<elementType id="author"> <description>The person, natural or otherwise, who wrote the book.</description> </elementType >
Subelements within elementType define characteristics of the class's members. An XML "content model" is a description of the contents that may validly appear within a particular element type in a document instance.
<elementType id="author">
<string/>
</elementType>
<elementType id="Book">
<element type="#author" occurs="ONEORMORE"/>
</elementType>
The example above defines two elements, author and book, and says that a book has one or more authors. The author element may contain a string of character data (but no other elements). For example, the following is valid:
<Book>
<author>Henry Ford</author>
<author>Samuel Crowther</author>
</Book>
Within an elementType, various specialized subelements (element, group, any, empty, string etc.) indicate which subelements (properties) are allowed/required. Ordinarily, these imply not only the cardinality of the subelements but also their sequence. (We discuss a means to relax sequence later.)
Element indicates the containment of a single element type (property). Each element contains an href attribute referencing another elementType, thereby including it in the content model syntacticly, or declaring it to be a property of the object class conceptually. The element may be required or optional, and may occur multiple times, as indicated by its occurs attribute having one of the four values "REQUIRED", "OPTIONAL", "ZEROORMORE" or "ONEORMORE". It has a default of "REQUIRED".
<elementType id="Book">
<element type="#title" occurs="OPTIONAL"/>
<element type="#author" occurs="ONEORMORE"/>
</elementType>
The example above describes a book element type. Here, each instance of a book may contain a title, and must contain one or more authors.
<Book>
<author>Henry Ford</author>
<author>Samuel Crowther</author>
<title>My Life and Work</title>
</Book>
When we discuss type hierarchies, later, we will see that an element type may have subtypes. If so, inclusion of an element type in a content model permits elements of that type directly and all its subtypes.
Empty and any content are expressed using predefined elements empty and any. (Empty may be omitted.) String means any character string not containing elements, known as "PCDATA" in XML. Any signals that any mixture of subelements is legal, but no free characters. Mixed content (a mixture of parsed character data and one or more elements) is identified by a mixed element, whose content identifies the element types allowed in addition to parsed character data. When the content model is mixed, any number of the listed elements are allowed, in any order.
<?XML version='1.0' ?>
<?xml:namespace name="urn:uuid:BDC6E3F0-6DA3-11d1-A2A3-00AA00C14882/" as="s"/?>
<s:schema>
<elementType id="name">
<string/>
</elementType>
<elementType id="Person">
<any/>
</elementType>
<elementType id="author">
<string/>
</elementType>
<elementType id="titlePart">
<string/>
</elementType>
<elementType id="title">
<mixed><element type="#titlePart"/></mixed>
</elementType>
<elementType id="Book">
<element type="#title" occurs="OPTIONAL"/>
<element type="#author" occurs="ONEORMORE"/>
</elementType>
</s:schema>
...
<Book>
<author>Henry Ford</author>
<author>Samuel Crowther</author>
<title>My Life and<titlePart>Work</titlePart></title>
</Book>
Here, book is defined to have an optional title and one or more authors. The name element has content model of any, meaning that free text is not allowed, but any arrangement of subelements is valid. The content model of title is mixed, allowing a free intermixture of characters and any number of titleParts. The author, name and titleParts elements have a content model of string.
Group indicates a set or sequence of elements, allowing alternatives or ordering among the elements by use of the groupOrder attribute. The group as a whole is treated similarly to an element.
<elementType id="Book">
<element type="#title"/>
<element type="#author" occurs="ONEORMORE"/>
<group occurs="OPTIONAL">
<element type="#preface"/>
<element type="#introduction"/>
</group>
</elementType>
In the above example, if a preface or introduction appears, both must, with the preface preceding the introduction. Each of the following is valid:
<Book>
<author>Henry Ford</author>
</Book>
<Book>
<author>Henry Ford</author>
<preface>Prefatory text</preface>
<introduction>This is a swell book.</introduction>
</Book>
Sometimes a schema designer wants to relax the ordering restrictions among elements, allowing them to appear in any order. This is indicated by setting the groupOrder attribute to "AND":
<elementType id="Book">
<element type="#title"/>
<element type="#author" occurs="ONEORMORE"/>
<group groupOrder="AND" occurs="OPTIONAL">
<element type="#preface"/>
<element type="#introduction"/>
</group>
</elementType>
Now the following is also valid:
<Book>
<author>Henry Ford</author>
<introduction>This is a swell book.</introduction>
<preface>Prefatory text</preface>
</Book>
Finally, a schema can indicate that any one of a list of elements (or groups) is needed. For example, either a preface or an introduction. The groupOrder attribute value "OR" signals this.
<elementType id="Book">
<element type="#title"/>
<element type="#author" occurs="ONEORMORE"/>
<group groupOrder="OR">
<element type="#preface"/>
<element type="#introduction"/>
</group>
</elementType>
Now each of the following is valid:
<Book>
<author>Henry Ford</author>
<preface>Prefatory text</preface>
</Book>
<Book>
<author>Henry Ford</author>
<introduction>This is a swell book.</introduction>
</Book>
XML typically does not allow an element to contain content unless that content was listed in the model. This is useful in some cases, but overly in others in which we would like the listed content model to govern the cardinality and other aspects of whichever subelements are explicitly named, while allowing that other subelements can appear in instances as well.
The distinction is effected by the content attribute taking the values "OPEN" and "CLOSED." The default is "OPEN" meaning that all element types not explicitly listed are valid, without order restrictions. (This idea has a close relation to the Java concept of a final class.)
For example, the following instance data for a book, including the unmentioned element copyrightDate would be valid given the content models declared so far, because they have all been open.
<Book>
<author>Henry Ford</author>
<author>Samuel Crowther</author>
<title>My Life and Work</title>
<copyrightDate>1922</copyrightDate>
</Book>
However, had the content model been declared closed, as follows, the copyrightDate element would be invalid.
<elementType id="Book" content="CLOSED">
<element type="#title"/>
<element type="#author" occurs="ONEORMORE"/>
<group groupOrder="SEQ" occurs="OPTIONAL">
<element type="#preface"/>
<element type="#introduction" occurs="REQUIRED"/>
</group>
</elementType>
A closed content model does not allow instances to contain any elements or attributes beyond those explicitly listed in the elementType declaration.
An element with occurs of REQUIRED or OPTIONAL (but not ONEORMORE or ZEROORMORE) can have a default value specified.
<elementType id="Book">
<element type="#title"/>
<element type="#author" occurs="ONEORMORE"/>
<element type="#ageGrp" occurs="OPTIONAL">
<default>adult</default>
</element>
</elementType>
The default value is implied for all element instances in which it is syntactically omitted.
To indicate that the default value is the only allowed value, the presence attribute is set to "FIXED".
<elementType id="Book">
<element type="#title"/>
<element type="#author" occurs="ONEORMORE"/>
<element type="#ageGrp" occurs="OPTIONAL" presence="FIXED">
<default>ADULT</default>
</element>
</elementType>
Presence has values of "IMPLIED," "SPECIFIED," "REQUIRED," and "FIXED" with the same meanings as defined in XML DTD.
ElementTypes can be know be different names in different languages or domains. The equivalence of several names is effected by the sameAs attribute, as in
<elementTypeEquivalent id="livre" type="#Book"/> <elementTypeEquivalent id="auteur" type="#author"/>
Elements are used to represent both primary object types (nouns) and also properties, relations and so forth. Relations are often known by two names, each reflecting one direction of the relationship. For example, husband and wife, above and below, earlier and later, etc. The correlative element identifies such a pairing.
<elementType id= "author">
<string/>
</elementType>
<elementType id= "wrote">
<correlative type="#author" />
<string/>
</elementType>
This indicates that "wrote" is another name for the "author" relation, but from the perspective of the person, not the book. That is, the two fragments below express the same fact:
<Person>
<name>Henry Ford</name>
</Person>
<Book>
<title>My Life and Work</title>
<author>Henry Ford</author>
</Book>
...
<Person>
<name>Henry Ford</name>
<wrote>My Life and Work</wrote>
</Person>
<Book>
<title>My Life and Work</title>
</Book>
A correlative may be defined simply to document the alternative name for the relation. However, it may also be used within a content model where it permits instances to use the alternative name. Further it may to establish constraints on the relation, indicate key relationships, etc.
ElementTypes can be organized into categories using the superType attribute, as in
<elementType id="price">
<string/>
</elementType>
<elementType id="ThingsI'veBoughtRecently">
<element type="#price"/>
</elementType>
<elementType id="PencilsI'veBoughtRecently">
<superType type="#ThingsI'veBoughtRecently"/>
<element type="#price"/>
</elementType>
<elementType id="BooksI'veBoughtRecently">
<superType type="#ThingsI'veBoughtRecently"/>
<element type="#price"/>
</elementType>
This simply indicates that, in some fashion, PencilsI'veBoughtRecently and BooksI'veBoughtRecently are subsets of ThingsI'veBoughtRecently. It implies that every valid instance of the subset is a valid instance of the superset. The superset type must have an open content model.
There are restrictions that should be followed, based on the principle that all instances of the species (subtype) must be instances of the genus (supertype):
To indicate that the content model of the subset should inherit the content model of a superset, we use a particular kind of superType called "genus" of which only one is allowed per ElementType. This copies the content model of the referenced element type and permits addition of new elements to it. Further, sub-elements occurring in the superset type, if declared again, are replaced by the newer declarations.
<elementType id="Book">
<element type="#title"/>
<element type="#author" occurs="ONEORMORE"/>
</elementType>
<elementType id="BooksI'veBoughtRecently">
<genus type="#Book"/>
<superType type="#ThingsI'veBoughtRecently"/>
<element type="#price"/>
</elementType>
The above has the same effect as
<elementType id="Book">
<element type="#title"/>
<element type="#author" occurs="ONEORMORE"/>
</elementType>
<elementType id="BooksI'veBoughtRecently">
<superType type="#Book"/>
<superType type="#ThingsI'veBoughtRecently"/>
<element type="#title"/>
<element type="#author" occurs="ONEORMORE"/>
<element type="#price"/>
</elementType>
ElementTypes and the content model elements defined so far are sufficient to declare a tree structure of elements. However, some elements such as "author" are not only usable on their own, they also act as references to other elements. For example, "Henry Ford" is the value of the author subelement of a book element. "Henry Ford" is also the value of the name element in a person element, and it can be used to connect these two.
<Book>
<author>Henry Ford</author>
<author>Samuel Crowther</author>
<title>My Life and Work</title>
</Book>
<Person><name>Henry Ford</name></Person>
<Person><name>Samuel Crowther</name></Person>
In this capacity, such subelement are often referred to as relations when using "knowledge representation" terminology or "keys" when using database terms. (The meaning of "relation" and "key" are slightly different, but the fact which the terms recognize is the same.)
To make such references explicit in the schema, we add declarations for keys and foreign keys.
<elementType id="name">
<string/>
</elementType>
<elementType id="Person">
<element id="p1" type="#name"/>
<key id="k1"><keyPart href="#p1"/></key>
</elementType>
<elementType id="author">
<string/>
<foreignKey range="#Person" key="#k1"/>
</elementType>
<elementType id="title">
<string/>
</elementType>
<elementType id="Book">
<element type="#title"/>
<element type="#author" occurs="ONEORMORE"/>
</elementType>
The key element within person tells us that a person can be uniquely identified by his name. The foreignKey element within the author element definition says that the contents of an author element are a foreign key indentifying a person by name.
An uninformed user agent can still display the string "Henry Ford" even if it cannot determine that is supposed to be a person. A savvy agent that reads the schema can do more. It can locate the actual person.
This is the information needed for a join in database terminology.
This mechanism not only handles the typical way in which properties are expressed in databases, it also handles all cases in which the contents of an element are to be interpreted as strings from a restricted vocabulary, such as enumerations, XML nmtokens, etc.
<Book>
<author>Henry Ford</author>
<author>Samuel Crowther</author>
<title>My Life and Work</title>
<lccn>HD9710.U54 F58 1973</lccn>
<dewey>629.2/092/4 B</dewey >
<isbn>0405050887</isbn>
<series>Business<series>
</Book>
Although not shown here, presumably lccn, dewey and isbn are declared in the schema to be foreign keys to corrresponding fields of catalog records. Series is a foreign key to a categorization of books, of which "Business" is one category.
Keys can contain URIs, as in
<Book>
<author>http://SSA.gov/blab/people/Henry+Ford</author>
<author>http://SSA.gov/blab/people/Samuel+Crowther</author>
<title>My Life and Work</title>
</Book>
This is indicated in the schema by a datatype of "URI".
<elementType id="author">
<string/>
<datatype dt="uri"/>
</elementType>
Element relations are binary. That is, we never express an n-to-1 relationship directly. We do not, for example, list within books a single relation that somehow resolves to all the authors. Instead, we always write the relationship on the 1-to-n side, but allow multiple occurrances of the subelement, for example, allowing books to have multiple occurrences of author.
<Person><name>Henry Ford</name></Person>
<Person><name>Samuel Crowther</name></Person>
<Person><name>Harvey S. Firestone</name></Person>
<Book>
<author>Henry Ford</author>
<author>Samuel Crowther</author>
<title>My Life and Work</title>
</Book>
<Book>
<author>Harvey S. Firestone</author>
<author>Samuel Crowther</author>
<title>Men and Rubber</title>
</Book>
This example shows a book with several persons as author, and also a person who is author of several books. We discussed such many-to-many relations more under the topic of correlations.
When the foreignKey element does not have foreignKeyPart sub-elements (as it does not above) then the entirety of the element's contents (e.g. "Henry Ford") should be used as the key value. However, for multipart foreign keys, or cases where the element has several sub-elements, foreignKeyPart is used, as shown below.
<elementType id="firstName">
<string/>
</elementType>
<elementType id="lastName">
<string/>
</elementType>
<elementType id="Person">
<element id="pp1" type="#firstName"/>
<element id="pp2" type="#lastName"/>
<key id="k1">
<keyPart href="#pp1"/>
<keyPart href="#pp2"/>
</key>
</elementType>
<elementType id="author">
<element id="ap1" type="#firstName"/>
<element id="ap2" type="#lastName"/>
<domain type="#Book"/>
<range type="#Person"/>
<foreignKey range="#Person" key="#k1">
<foreignKeyPart href="#ap1"/>
<foreignKeyPart href="#ap2"/>
</foreignKey>
</elementType>
...
<Book>
<title>My Life and Work</title>
<author>
<firstName>Henry</firstName>
<lastName>Ford</lastName>
</author>
</Book>
An alternative way to express a reference is with an attribute.
<person id="person1"><name>Henry Ford</name></Person>
<person id="person2"><name>Samuel Crowther</name></Person>
<Book>
<author name="Henry Ford"/>
<author name="Samuel Crowther"/>
<title>My Life and Work</title>
</Book>
This allows us to link a book to a person, through the author relation, using an attribute of the relation. This exactly parallels the construction we saw above under "multipart keys," where a subelement of author contained the author's name. Here, an attribute of author contains the name. We can express this in our schema as
<elementType id="author">
<attribute name="name" id="authorname"/>
<foreignKey range="#Person" key="#k1">
<foreignKeyPart href="#authorname"/>
</foreignKey>
</elementType>
A widely-used variant of this is to use a URI as a foreign key:
<Book>
<author href="http://SSA.gov/blab/people/Henry+Ford"/>
<author href="http://SSA.gov/blab/people/Samuel+Crowther"/>
<title>My Life and Work</title>
</Book>
In this case, we are using the href attribute to contain a URI. This is a particular kind of foreign key, where the range is any possible resource, and where that resource is not identified by some combination of its properties but instead by a name-resolution service. We indicate this by using an attribute element, with dt= "URI".
<elementType id="author">
<attribute name="href" id="authorhref" dt="uri"/>
</elementType>
Elements can be limited to restricted ranges of values. The min and max elements define the lower and upper bounds.
<elementType id="age">
<string/>
</elementType>
<elementType id="Person">
<element hef="#age"><min>0</min><max>131</max></element>
</elementType>
Such intervals are half-open (that is, the min value is in the interval, and the max value is the smallest value not in the interval).
This rule leads to the simplest calculation in most cases, and is unambiguous with respect to precision. In the above example, it is clear by these rules the 130.9999 is in the interval and 131 is not. However, had we said "all numbers from 0 to 130.99," in practice we would have some ambiguity regarding the status of 130.9999. Or interpretation would depend on the precision that we inferred for the original statement. The issue is particularly ambiguous for dates. (What exactly does "From December 5 to December 8" mean? The use of half-open intervals for representation does not, however, put any requirements on how processors must display intervals. For example, dates in some contexts display differently than their storage. That is, the interval <min>1997-12-05</min><max>1997-12-09</max> might be displayed as "December 5 through December 8".
In certain cases this rule for a half-open interval is impractical (for example, what letter follows "z" in the latin alphabet?) If so, use maxInclusive:
<elementType id="student">
<element type="#grade"><min>A</min><maxInclusive>Z</maxInclusive></element>
</elementType>
We can use the domain and range elements to add constraints to an element's use or value. The domain element, if present, indicates that the element may only be used as a property of certain other elements. That is, syntactically it may appear only in the content model of those other element types. It constrains the sorts of schemas that can be written with the element.
<elementType id="author">
<string/>
<domain type="#Book"/>
<attribute name="href" dt="uri"/>
</elementType>
The domain property above permits author elements to be used only within elements which are either books or subsets of books. Use of domain is optional. If omitted, there is simply no restriction.
The range element is used with elements which are references and declares a restriction on the types of elements to which the relation may refer. Graphically, it describes the target end of a directed edge. Each range element references one elementType, any of which are valid. In this case, below, we have said that an author element must have an href attribute which is a URI reference to a Person or to an element type which is Person or a subset of Person.
<elementType id="author">
<string/>
<domain type="#Book"/>
<attribute name="href" dt="uri" range="#Person" />
</elementType>
Element and attribute types can have an unlimited amount of further information added to them in the schema due to the open nature of XML with namespaces.
A schema may use elements and attributes from other schemas in content models. For example, a subelement named "http://books.org/date" could be used within a book element as follows:
<?XML version='1.0' ?>
<?xml:namespace name="urn:uuid:BDC6E3F0-6DA3-11d1-A2A3-00AA00C14882/" as="s"/?>
<s:schema>
<elementType id="author">
<string/>
</elementType>
<elementType id="title">
<string/>
</elementType>
<elementType id="Book">
<element type="#title" occurs="OPTIONAL"/>
<element type="#author" occurs="ONEORMORE"/>
<element href="http://books.org/date" />
</elementType>
</s:schema>
This can be abbreviated by adopting the rule that namespace-qualified names may be used within the href attribute value of an element or attribute element.
<?XML version='1.0' ?>
<?xml:namespace name="urn:uuid:BDC6E3F0-6DA3-11d1-A2A3-00AA00C14882/" as="s"/?>
<?xml:namespace name=" http://books.org/" as="bk"/?>
<s:schema>
<elementType id="author">
<string/>
</elementType>
<elementType id="title">
<string/>
</elementType>
<elementType id="Book">
<element type="#title" occurs="OPTIONAL"/>
<element type="#author" occurs="ONEORMORE"/>
<element href="bk:date" />
</elementType>
</s:schema>
XML-Data schemas contain a number of facilities to match features of XML DTDs or to support certain characteristics of XML. The XML syntax allows that certain properties can be expressed in a form called "attributes." To support this, an elementType can contain attribute declarations, which are divided into attributes with enumerated or notation values, and all other kinds.
An attribute may be given a default value. Whether it is required or optional is signaled by presence. (Presence ordinarily defaults to IMPLIED, but if omitted and there is an explicit default, presence is set to the SPECIFIED.) See the DTD at the end of this document for syntactic details.
Attributes with enumerated (and notation) values permit a values attribute, a space-separated list of legal values. The values attribute is required when the atttype is ENUMERATION or NOTATION, else it is forbidden. In these cases, if a default is specified, it must be one of the specified values.
<elementType id="Book">
<element type="#title"/>
<element type="#author" occurs="ONEORMORE"/>
<attribute name="copyright" />
<attribute name="ageGrp" atttype="ENUMERATION" values="child adult" default="adult" />
</elementType>
describes an instance such as
<book copyright="1922" ageGrp="adult">
<title>My Life and Work</title>
<author>
<firstName>Henry</firstName>
<lastName>Ford</lastName>
</author>
</Book>
Attributes may also reference elementTypes, meaning that one may use the element type but with attribute syntax. This allows an attribute to explicitly have the same name and semantics even when used on different element types. There are of course some limits: The attribute can still occur only once in an instance, and it cannot contain other elements. However, this allows the semantics of the element type to be employed in attribute syntax.
<elementType id="Book">
<attribute href="bk:title"/>
<attribute href="bk:author"/>
<attribute name="copyright" />
<attribute name="ageGrp" type="ENUMERATION" values="children adult" default="adult" />
</elementType>
describes an instance such as
<book bk:author="Henry Ford" bk:title="My Life and Work" ageGrp="adult"/>
This and the next two declarations cover entities. Entities are a shorthand mechanism, similar to macros in a programming language.
<intEntityDcl name="LTG">
Language Technology Group
</intEntityDcl>
<extEntityDcl name="dilbert" notation="#gif"
systemId="http://www.ltg.ed.ac.uk/~ht/dilb.gif"/>
Here as elsewhere, following XML, systemId must be a URI, absolute or relative, and publicId, if present, must be a Public Identifier (as defined in ISO/IEC 9070:1991, Information technology -- SGML support facilities -- Registration procedures for public text owner identifiers). If a notation is given, it must be declared (see below) and the entity will be treated as binary, i.e., not substituted directly in place of references.
<notationDcl name="gif" systemId='http://who.knows.where/'/>
Although we allow an external entity with declarations to be included, we recommend a different declaration for schema modularization. The extDcls declaration gives a clean mechanism for importing (fragments of) other schemas. It replaces the common SGML idiom of declaring an external parameter entity and then immediately referring to it, and has the same import, namely, that the text referred to by the combination of systemId and publicId is included in the schema in place of the extDcls element, and that replacement text is then subject to the same validity constraints and interpretation as the rest of the schema.
Note that in many cases the desired effect may be better represented by referencing elements (and attributes) from the other schema or subclassing from them.
A dataype indicates that the contents of an element can be interpreted as both a string and also, more specifically, as an object that can be interpreteted more specifically as a number, date, etc. The datatype indicates that the element's contents can be parsed or interpreted to yeild an object more specific than a string.
That is, we distinguish the "type" of an element from its "datatype." The former gives the semantic meaning of an element, such as "birthday" indicating the date on which someone was born. The "datatype" represents the parser class needed to decode the element's contents into an object type more specific than "string." For example, "19541022" is the 22nd of October, 1954 in ISO 8601 date format. (That is, ISO 8601 parsing rules will decode "19541022" into a date, which can then be stored as a date rather than a string.
For example, we would like an XML author to be able to say that the contents of a "size" element is an integer, meaning that it should be parsed according to numeric parsing rules and that it can be stored in integer format. In some contexts an API can expose it as an integer rather than a string.
<item>
<name>shirt</name>
<size>8</size>
</item>
There are two main contexts for datatypes. First, when dealing with database APIs, such as ODBC, all elements with the same name typically contain the same type of contents. For example, all sizes contain integers or all birthdays contain dates. We will return to this case shortly.
Second, and by contrast, the type of the content may vary widely from instance to instance. The softer we make our software, the more often these flexible cases occur. For example, size could contain the integer 8, or the word "small" or even a formula for computing the size.
We expose the datatype of an element instance by use of a dt:dt attribute, where the value of the attribute is a URI giving the datatype. (The URI might be explicitly in URI format or might rely on the XML namespace facility for resolution.) For example, we might find a document containing something like:
<?namespace name="urn:uuid:C2F41010-65B3-11d1-A29F-00AA00C14882/" as="dt"?>
<?namespace name="http://zoosports.com/dt?" as="zoo"?>
<purchases>
<item>
<name>shirt</name>
<size dt:dt="int">8</size>
</item>
<item>
<name>shoes</name>
<size>large</size>
</item>
<item>
<name>suit</name>
<size dt:dt="zoo:script">
=(shirtsize*1.05) + 3
</size>
</item>
</purchases>
Clearly this technique works for the heterogeneous typing in the above example. It also works for the database case where all element's of the same type have the same datatype.
<item> <name>shirt</name> <size dt:dt="int">8</size> </item> <item> <name>shoes</name> <size dt:dt="int">6</size> </item> <item> <name>suit</name> <size dt:dt="int">12</size> </item>
As written above, this is inefficient. Fortunately, XML allows us in schemasto put attributes with default or fixed values, so we could say once that all size elements have a datatype with value "int". Having done so, our our instance just looks like:
<item> <name>shirt</name> <size>14</size> </item> <item> <name>shoes</name> <size>6</size> </item> <item> <name>suit</name> <size>16</size> </item>
In a DTD, we can set a fixed attribute value, so that all size elements have datatype "int" or we can set it as a default attribute value so that it is an integer except where explicitly noted otherwise.
<item> <name>shirt</name> <size>14</size> </item> <item> <name>shoes</name> <size dt:dt="string">large</size> </item> <item> <name>suit</name> <size>16</size> </item>
XML DTDs today allow such attributes. For example, a DTD can say that all shirt elements have integer datatype by the following:
<!ELEMENT size PCDATA > <!ATTLIST size dt:dt "int" #FIXED >
XML-Data schemas allow the equivalent, though with specialized syntax:
<elementType id="size" >
<datatype dt="int" />
</elementType>
Elements use datatype subelements to give the datatype so that an optional presence attribute of the datatype element can indicate whether the datatype is fixed or merely a default. Attributes can also have datatypes. Because there is no possibility of their being anything other than a fixed type, the datatype of an attribute is signalled by a dt attribute:
<attribute id="size" dt="int" />
Different APIs to typed data will use the datatype attribute differently. The basic XML parser API should expose all element contents as strings regardless of any datatype attribute. (It might also contain supplementary methods to read values as more specific types such as "integer," thereby getting more efficiency.) An ODBC interface could use the datatype attribute to expose each type of element as a column, with the column's datatype determined by the element type's datatype.
If a datatype requires a complex structure for storage, or an object-based storage, this is also handled by the dt:dt attribute, where the datatype's storage format can be a structure, Java class, COM++ class, etc. For example, if an application needed to have an element stored in a "ScheduleItem" structure and using some private format, it could note this like
<when dt:dt="zoo:ScheduleItem">M*D1W4B19971022;100</when>
The datatype does not require a private format. It could also use subelements and attributes such as
<when dt:dt="zoo:ScheduleItem2">
<month>*</month>
<day>1</day>
<week>4</week>
<begin>19971022</begin>
<recurs>100</recurs>
</when>
In the case of the graph-oriented interfaces (e.g. XML/RDF) the mapping from the XML tree to a graph should add a wrapping node for each non-string data type. The datatype property gives the type of that node. For example, the following two are graphically equivalent:
<size dt:dt="int">8</size> <size><dt:int>8</dt:int></size>
Adding an attribute to an element does not change the other attributes or pose any special versioning problems. For example, an application written to expect an instance to contain "<birthday>19541022</birthday>" is not harmed if the schema reveals that this is ISO 8601 format. Versioning within datatypes should be handled by the author's making sure that that subtypes of datatypes retain all the characteristics of the supertype.
If a down-level application is given a datatype it cannot process, it should expose the element contents as a supertype of the indicated datatype. In practice, this will usually mean that unrecognized datatypes will be the same as "dt:string". However, there are cases in which a type will be promoted, for example exposing a boolean in a byte or word rather than a bit, exposing a floating point number in a language's native format, etc.
The datatype attribute "dt" is defined in the namespace named "urn:uuid:C2F41010-65B3-11d1-A29F-00AA00C14882/". (See the XML Namespaces Note at the W3C site for details of namespaces.) The full URN of the attribute is "urn:uuid:C2F41010-65B3-11d1-A29F-00AA00C14882/dt".
You will have noticed that the value of the attribute, as used in the examples above, is not lexically a full URI. For example, it reads "int" or "string" etc. Datatype attribute values are abbreviated according to the following rule: If it does not contain a colon, it is a datatype defined in the datatypes namespace "urn:uuid:C2F41010-65B3-11d1-A29F-00AA00C14882/". If it contains a colon, it is to be expanded to a full URI according to the same rules used for other names, as defined by the XML Namespaces Note. For example
<?namespace name="urn:uuid:C2F41010-65B3-11d1-A29F-00AA00C14882/" as="dt"?>
<?namespace name="http://zoosports.com/dt?" as="zoo"?>
<item>
<size dt:dt="int">8</size>
<name dt:dt="zoo:clothing">shirt</name>
</item>
has two datatypes whose full names are "urn:uuid:C2F41010-65B3-11d1-A29F-00AA00C14882/integer" and "http://zoosports.com/dt?clothing".
Datatypes are identified by URIs. The URI as simply a reference to a section of a document that defines the appropriate parser and storage format of the element. To make this broadly useful, this document defines a set of common data types including all common forms of dates, plus all basic datatypes commonly used in SQL, C, C++, Java and COM (including strings).
The best form of such a document is that it should itself be an XML-Data schema where each datatype is an element declaration. For this purpose we define a <Syntax> subelement which can be used in lieu of a content model. We also define an <objecttype> subelement. Each has a URI as its value. This integrates data types with element types in general.
<schema:elementType id="int"> <syntax href="urn:uuid:C2F41010-65B3-11d1-A29F-00AA00C14882/num_to_int" /> <objectType href="urn:uuid:C2F41010-65B3-11d1-A29F-00AA00C14882/integer32" /> </schema:elementType> <schema:elementType id="date.iso8601"> <syntax href="urn:uuid:C2F41010-65B3-11d1-A29F-00AA00C14882/date.iso8601_to_int32" /> <objecttype href="urn:uuid:C2F41010-65B3-11d1-A29F-00AA00C14882/integer32" /> </schema:elementType>
The objecttype sub-element can reference a structure, Java class, COM++ coClass, etc. The syntax subelement identifies a parser which can decode the element's content (and/or attributes) into the object type given the storage type URI. Input to the parser is the element object exposing all its attributes and content tree (that is, the subtree of the grove beginning with the element containing the dt attribute). The objectType attribute in particular is assumed available to the parser so that a single parser can support several objecttypes.
Having said this, all basic data types should be built into the parsers for efficiency and in order to ground the process. For these, the datatype elements serve only to formally document the storage types and parsers, and to give higher-level systems (such as RDF) a more formal basis for datatypes.
I do not currently propose that we attempt to write any universal notation for parsing rules. Certain popular kinds of formats, particularly dates, are not easily expressed in anything but natural language or code, and the parsers must be custom written code. In other words, the URIs for the basic syntax and objecttype elements probably resolve only to text descriptions.
Attributes in cannot XML have structure. I will separately propose some techniques to avoid this problem, specifically that the XML API should contain a method that treats attributes and subelements indistinguishably, and also that the content which is an element's value can be syntactically separated from content which is an element's properties.
This includes all highly-popular types and all the built-in types of popular database and programming languages and systems such as SQL, Visual Basic, C, C++ and Java(tm).
| Name | Parse type | Storage type |
Examples |
string |
pcdata | string (Unicode) | Omwnuma legatai wn onoma monon koinon, o de kata tounoma logos thV ousiaV eteros, oion zuon o te anqropoV kai to gegrammenon. |
number |
A number, with no limit on digits, may potentially have a leading sign, fractional digits, and optionally an exponent. Punctuation as in US English. | string | 15, 3.14, -123.456E+10 |
int |
A number, with optional sign, no fractions, no exponent. | 32-bit signed binary | 1, 58502, -13 |
float |
Same as for "number." | 64-bit IEEE 488 | .314159265358979E+1 |
fixed.14.4 |
Same as "number" but no more than 14 dights to the left of the decimal point, and no more than 4 to the right. | 64-bit signed binary | 12.0044 |
boolean |
"1" or "0" | bit | 0, 1 (1=="true") |
dateTime.iso8601 |
A date in ISO 8601 format, with optional time and no optional zone. Fractional seconds may be as precise as nanoseconds. | Structure or object containing year, month, hour, minute, second, nanosecond. | 19941105T08:15:00301 |
dateTime.iso8601tz |
A date in ISO 8601 format, with optional time and optional zone. Fractional seconds may be as precise as nanoseconds. | Structure or object containing year, month, hour, minute, second, nanosecond, zone. | 19941105T08:15:5+03 |
date.iso8601 |
A date in ISO 8601 format. (no time) | Structure or object containing year, month, day. | 19541022 |
time.iso8601 |
A time in ISO 8601 format, with no date and no time zone. | Structure or object exposing day, hour, minute | |
time.iso8601.tz |
A time in ISO 8601 format, with no date but optional time zone. | Structure or object containing day, hour, minute, zonehours, zoneminutes. | 08:15-05:00 |
i1 |
A number, with optional sign, no fractions, no exponent. | 8-bit binary | 1, 255 |
i2 |
" | 16-bit binary | 1, 703, -32768 |
i4 |
" | 32-bit binary | |
i8 |
" | 64-bit binary | |
ui1 |
A number, unsigned, no fractions, no exponent. | 8-bit unsigned binary | 1, 255 |
ui2 |
" | 16-bit unsigned binary | 1, 703, -32768 |
ui4 |
" | 32-bit unsigned binary | |
ui8 |
" | 64-bit unsigned binary | |
r4 |
Same as "number." | IEEE 488 4-byte float | |
r8 |
" | IEEE 488 8-byte float | |
float.IEEE.754.32 |
" | IEEE 754 4-byte float | |
float.IEEE.754.64 |
" | IEEE 754 8-byte float | |
uuid |
Hexidecimal digits representing octets, optional embedded hyphens which should be ignored. | 128-bytes Unix UUID structure | F04DA480-65B9-11d1-A29F-00AA00C14882 |
uri |
Universal Resource Identifier | Per W3C spec | http://www.ics.uci.edu/pub/ietf/uri/draft-fielding-uri-syntax-00.txt |
bin.hex |
Hexidecimal digits representing octets | no specified size | |
char |
string | 1 Unicode character (16 bits) | |
string.ansi |
string containing only ascii characters <= 0xFF. | Unicode or single-byte string. | This does not look Greek to me. |
All of the dates and times above reading "iso8601.." actually use a restricted subset of the formats defined by ISO 8601. Years, if specified, must have four digits. Ordinal dates are not used. Of formats employing week numbers, only those that truncate year and month are allowed (5.2.3.3 d, e and f).
Certain uses of data emphasize syntax, others "conceptual" relations. Syntactic schemas often have fewer elements compared to explicitly conceptual ones. Further, it is usually easier to design a schema that merely covers syntax rather than designing a well-thought-out conceptual data model. An effect of this is that many practical schemas will not contain all the elements that a conceptual schema would, either for reasons of economy or because the initial schema was simply syntactic. But is it useful to make the implicit explicit over time so that more generic processors can make use of data.
For example, the following schema is essentially syntax:
<elementType id="author">
<string/>
</elementType>
<elementType id="title">
<string/>
</elementType>
<elementType id="Book">
<element type="#title"/>
<element type="#author" occurs="ONEORMORE"/>
</elementType>
with instances looking like this
<Book>
<title>Paradise Lost</title>
<author>Milton</author>
</Book>
On the other hand, a conceptual schema could look like this:
<elementType id="name">
<string/>
</elementType>
<elementType id="Person">
<element type="#name/>
</elementType>
<elementType id="creator">
<range type="#Person/>
</elementType>
<elementType id="title">
<string/>
</elementType>
<elementType id="Book">
<element type="#title"/>
<element type="#creator" occurs="ONEORMORE"/>
</elementType>
If fully explicit, its instances would look something like this:
<Person id="thing1">
<name>Milton</Person>
</Person>
<Book>
<title>Paradise Lost</title>
<creator>
<Person>
<name>Milton</name>
</Person>
</creator>
</Book>
In any case, what we want to express is a diagram such as this:

To do this, we will add mapping information into the syntactic schema which tells us how to interpolate the implied elements (and also to map author to creator) thereby creating a conceptual data model.
<?xml:namespace href="uri-to-the-conceptual-schema" as="c" ?>
<elementType id="author">
<string/>
</elementType>
<elementType id="title">
<string/>
</elementType>
<elementType id="Book">
<mapsTo type="c:book"/>
<element type="#title"> <mapsTo type="c:title"/> </element>
<element type="#author" occurs="ONEORMORE">
<mapsTo type="string">
<implies type="c:name">
<implies type="c:person">
<implies type="c:creator"/>
</implies>
</implies>
</mapsTo>
</element>
</elementType>
A more complex case could involve needing to map several properties to have a common implied node. For example, suppose we wanted that a street element and city element should both imply the same address node.
<Person>
<name>Mary Poppins</name>
<street>17 Cherry Tree Lane</street>
<city>London</city>
</Person>

That is, rather than creating two address nodes, we want to create only a single onc, and subordinate both the street and city to it. If the conceptual schema has elements livesAt, address, street and city, we could write a mapping thus:
...definitions of name, street and city...
<elementType id="Person">
<mapsTo type="c:person"/>
<element type="#name"> <string/> <mapsTo type="c:name"/> </element>
<element type="#street">
<string/>
<mapsTo type="c:street">
<implies type="c::address" id="livesAtAddress">
<implies type="c:livesAt"/>
</implies>
</mapsTo>
</element>
<element type="#city">
<string/>
<mapsTo type="c:city">
<implies type="#livesAtAddress"/>
</mapsTo>
</element>
</elementType>
Elements may be repeated, so mapping rules need to accommodate repetitions. Suppose that someone has two addresses in the grammatical syntax, this needs to map to two addresses in the graph while still keeping the structure correct.
<Person>
<name>Mary Poppins</name>
<street>17 Cherry Tree Lane</street>
<city>London</city>
<street>One Park Lane</street>
<city>London</city>
</Person>
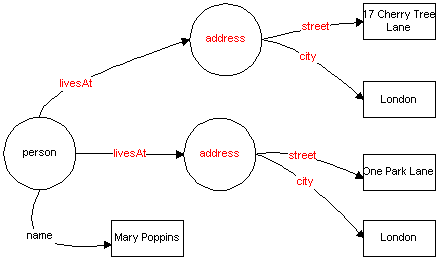
<elementType id="Person">
<mapsTo type="c:person"/>
<element type="#name"> <string/> <mapsTo type="c:name"/> </element>
<group occurs="ZEROORMORE"/>
<element type="#street">
<string/>
<mapsTo type="c:street">
<implies type="c::address" id="livesAtAddress">
<implies type="c:livesAt"/>
</implies>
</mapsTo>
</element>
<element type="#city">
<string/>
<mapsTo type="c:city">
<implies type="#livesAtAddress"/>
</mapsTo>
</element>
</group>
</elementType>
Mappings within groups are handled together. Since street and city are in a single group, each occurrence of such a group results in one address.
Text markup can also be handled by mapping. Suppose that for some reason we choose to markup the number portion of a street address:
<Person>
<name>Mary Poppins</name>
<street>< streetNumber>17</ streetNumber > Cherry Tree Lane</street>
<city>London</city>
</Person>
If this should be reflected in the graph,

We can do that with mapping such as:
<elementType id="streetNumber">
<string/>
</elementType>
<elementType id="street>
<mixed>
<element type="# streetNumber">
<mapsTo type="c: streetNumber">
<implies type="#livesAtAddress"/>
</mapsTo>
</element>
</mixed>
</elementType>
...Person defined as before...
Some data:
<?xml:namespace name="http://company.com/schemas/books/" as="bk"/>
<?xml:namespace name="http://www.ecom.org/schemas/dc/" as="ecom" ?>
<bk:booksAndAuthors>
<Person>
<name>Henry Ford</name>
<birthday>1863</birthday>
</Person>
<Person>
<name>Harvey S. Firestone</name>
</Person>
<Person>
<name>Samuel Crowther</name>
</Person>
<Book>
<author>Henry Ford</author>
<author>Samuel Crowther</author>
<title>My Life and Work</title>
</Book>
<Book>
<author>Harvey S. Firestone</author>
<author>Samuel Crowther</author>
<title>Men and Rubber</title>
<ecom:price>23.95</ecom:price>
</Book>
</bk:booksAndAuthors>
The schema for http://company.com/schemas/books:
<?xml:namespace name="urn:uuid:BDC6E3F0-6DA3-11d1-A2A3-00AA00C14882/" as="s"/?>
<?xml:namespace href="http://www.ecom.org/schemas/ecom/" as="ecom" ?>
<s:schema>
<elementType id="name">
<string/>
</elementType>
<elementType id="birthday">
<string/>
<dataType dt="date.ISO8601"/>
</elementType>
<elementType id="Person">
<element type="#name" id="p1"/>
<element type="#birthday" occurs="OPTIONAL">
<min>1700-01-01</min><max>2100-01-01</max>
</element>
<key id="k1"><keyPart href="#p1" /></key>
</elementType>
<elementType id="author">
<string/>
<domain type="#Book"/>
<foreignKey range="#Person" key="#k1"/>
</elementType>
<elementType id="writtenWork">
<element type="#author" occurs="ONEORMORE"/>
</elementType>
<elementType id="Book" >
<genus type="#writtenWork"/>
<superType href=" http://www.ecom.org/schemas/ecom/commercialItem"/>
<superType href=" http://www.ecom.org/schemas/ecom/inventoryItem"/>
<group groupOrder="SEQ" occurs="OPTIONAL">
<element type="#preface"/>
<element type="#introduction"/>
</group>
<element href="http://www.ecom.org/schemas/ecom/price"/>
<element href="ecom:quantityOnHand"/>
</elementType>
<elementTypeEquivalent id="livre" type="#Book"/>
<elementTypeEquivalent id="auteur" type="#author"/>
</s:schema>
<!ENTITY % nodeattrs 'id ID #IMPLIED'>
<!-- href is as per XML-LINK, but is not required unless there is
no content -->
<!ENTITY % linkattrs
'id ID #IMPLIED
href CDATA #IMPLIED'>
<!ENTITY % typelinkattrs
'id ID #IMPLIED
type CDATA #IMPLIED'>
<!ENTITY % exattrs
'name CDATA #IMPLIED
content (OPEN|CLOSED) "OPEN" ' >
<!ENTITY % elementTypeElements1
'genus? correlative? superType*'>
<!ENTITY % elementTypeElements2
'description,
(min|minExclusive)?,
(max | maxInclusive)?,
domain*,
key*,
foreignKey*,
(datatype | ( syntax?, objecttype+ ) )?
mapsTo?'>
<!ENTITY % elementConstraints
'min? max? default?'>
<!ENTITY % elementAttrs
'occurs (REQUIRED|OPTIONAL|ONEORMORE|ZEROORMORE) "REQUIRED" '>
<!ENTITY % rangeAttribute
'range CDATA #IMPLIED' >
<!-- The top-level container -->
<!element schema ((elementType|linkType|
extendType|
intEntityDcl|extEntityDcl|
notationDcl|extDcls)*)>
<!attlist schema %nodeattrs;>
<!-- Element Type Declarations -->
<!element elementType (%elementTypeElements1;,
((element|group)*|empty|any|string|mixed)?,
attribute*
%elementTypeElements2 )>
<!attlist elementType %nodeattrs;
%exattrs >
<!-- Element types allowed in content model -->
<!-- Note this is just short for a model group with only one element in it -->
<!element element (%elementConstraints;) >
<!-- The type is required -->
<!attlist element %typelinkattrs;
%elementAttrs;
presence (FIXED) #IMPLIED >
<!-- A group in a content model: and, sequential or disjunctive -->
<!element group ((group|element)+)>
<!attlist group %nodeattrs;
%elementattrs;
presence (FIXED) #IMPLIED
groupOrder (AND|SEQ|OR) 'SEQ'>
<!element any EMPTY>
<!element empty EMPTY>
<!element string EMPTY>
<!-- mixed content is just a flat, non-empty list of elements -->
<!-- We don't need to say anything about <string/> (CDATA), it's implied -->
<!element mixed (element+)>
<!attlist mixed %nodeattrs;>
<!element superType EMPTY>
<!attlist superType %linkattrs;>
<!element genus EMPTY>
<!attlist genus %typelinkattrs;>
<!element description MIXED>
<!attlist description %nodeattrs;>
<!element domain EMPTY>
<!attlist domain %typelinkattrs;>
<!element default MIXED>
<!attlist default %nodeattrs;>
<!element min MIXED>
<!attlist min %nodeattrs; >
<!element max MIXED>
<!attlist max %nodeattrs; >
<!element maxInclusive MIXED>
<!attlist maxInclusive %nodeattrs; >
<!element minExclusive MIXED>
<!attlist minExclusive %nodeattrs; >
<!element key (keyPart+)>
<!attlist key %nodeattrs;>
<!element keyPart EMPTY>
<!attlist keyPart %linkattrs;>
<!element foreignKey foreignKeyPart* >
<!attlist foreignKey %nodeattrs;
%rangeAttribute;
key CDATA #IMPLIED >
<!element foreignKeyPart EMPTY>
<!attlist foreignKeyPart %linkattrs;>
<!-- Datatype support -->
<!element datatype (elementType?) >
<!attlist datatype %typelinkattrs;
presence (IMPLIED|SPECIFIED|REQUIRED|FIXED) #IMPLIED >
<!element syntax >
<!attlist syntax %linkattrs; >
<!element objecttype >
<!attlist objecttype %linkattrs; >
<!-- Mapping support -->
<!element mapsTo (implies?)>
<!attlist mapsTo %typelinkattrs;>
<!element implies (implies?)>
<!attlist implies %typelinkattrs;>
<!-- Alias support -->
<!element elementTypeEquivalent EMPTY>
<!attlist elementTypeEquivalent %typelinkattrs; >
<!element correlative EMPTY>
<!attlist correlative %linkattrs;>
<! Subtype of ElementType that is explicitly a relation. -->
<!element relationType (%elementTypeElements1;,
((element|group)*|empty|any|string|mixed)?,
attribute*
%elementTypeElements2)>
<!attlist relationType %nodeattrs;
%exattrs; >
<!-- Attributes -->
<!-- default value must be present if presence is specified or fixed -->
<!-- presence defaults to specified if default is present, else implied -->
<!element attribute (%PropertyElements1,
%PropertyElements2,
%elementConstraints)>
<!attlist attribute %typelinkattrs;
name CDATA #IMPLIED
%elementAttrs
dt CDATA #IMPLIED
atttype (URIREF|
ID|IDREF|IDREFS|ENTITY|ENTITIES|
NMTOKEN|NMTOKENS|
ENUMERATION|NOTATION|CDATA) CDATA
%rangeAttribute;
default CDATA #IMPLIED
values NMTOKENS #IMPLIED
presence (IMPLIED|SPECIFIED|REQUIRED|FIXED) #IMPLIED >
<!-- Notation and Entity Declarations -->
<!-- Note: as this is written, only external entities
can have structure without escaping it -->
<!-- 'par' is TRUE iff parameter entity. -->
<!-- systemID and publicId (if present) must have the required syntax -->
<!ENTITY % notationattrs '%nodeattrs
systemID CDATA #IMPLIED
publicID CDATA #IMPLIED'>
<!ENTITY % entityattrs '%notationattrs
name CDATA #IMPLIED
par (TRUE | FALSE) "FALSE">
<!-- Notation Declarations -->
<!element notationDcl EMPTY>
<!attlist notationDcl %notationattrs>
<!element intEntityDcl PCDATA>
<!attlist intEntityDcl %entityattrs; >
<!-- The entity will be treated as binary if a notation is present -->
<!element extEntityDcl EMPTY>
<!attlist extEntityDcl %entityattrs;
notation CDATA #IMPLIED>
<!-- External entity with declarations to be included -->
<!element extDcls EMPTY>
<!attlist extDcls %entityattrs;>