Detalhes
Usando codificação para seu conteúdo
Autores de conteúdos devem declarar codificação de caracteres em suas páginas usando um dos métodos descritos em Declarando codicação de caracteres em HTML.
É importante saber e levar em conta que simplesmente declarar a codificação de caracteres no documento ou no servidor não é suficiente; faz-se necessário e indispensável que se salve o texto na mesma codificação que foi declarada para que ela seja aplicada ao conteúdo. (A declaração no documento destina-se a fornecer ao navegador uma indicação de como interpretar a sequência de bytes adotada na armazenagem do texto).
Configure UTF-8 como a codificação padrão para novos documento no seu editor. A figura a seguir mostra como definir a codificação padrão para novos documentos no Dreamweaver.
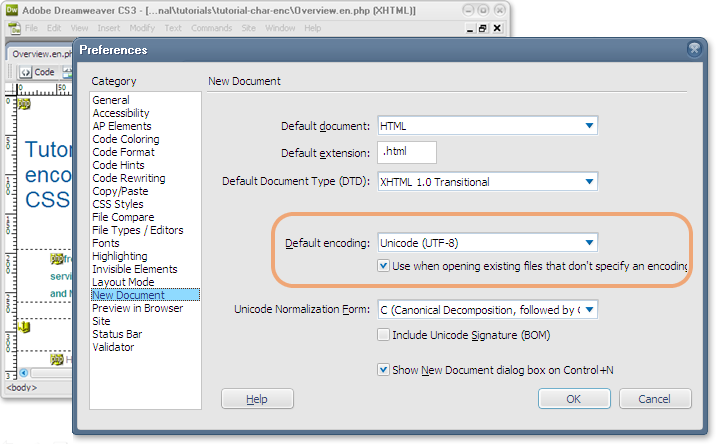
Pode ainda haver a necessidade de se verificar se o servidor está servindo os documentos com a declaração HTTP apropriada, pois ela sobrescreve a declaração definida no documento (ver adiante).
É importante certificar-se de que os vários componentes de um sistema são capazes de se comunicar entre si. Páginas web devem ser capazes de se comunicar com scripts de back-end, banco de dados, etc. Todos estes componentes funcionam de forma apropriada, também, com a codificação UTF-8. Para uma descrição detalhada de uma série de itens a considerar neste assunto consulte o artigo Migrando para Unicode.
Por que usar UTF-8?
Uma página HTML pode ter apenas uma codificação de caracteres. Não é possível codificar diferentes partes de uma página em diferentes codificações.
A codificação baseada em Unicode, tal como UTF-8, oferece suporte para vários idiomas e assim sendo admite páginas e formulários em qualquer combinação de idiomas. Isso dispensa a necessidade de se criar uma lógica no servidor capaz de determinar a codificação para cada página servida ou para cada conjunto de dados recebidos de um formulário. Fica significantemente reduzida a complexidade própria do gerenciamento de um site ou aplicação multi-idiomas.
A codificação Unicode, mais do que qualquer outra codificação, permite que muito mais idiomas sejam usados em uma única página.
Nos dias atuais praticamente não existem barreiras para o uso de Unicode. Em janeiro de 2012 o Google informou que mais de 60% da Web está usando UTF-8. Se forem consideradas as páginas codificadas em ASCII (lembrando que ASCII é um subconjunto de UTF-8) aquele percentual sobe para 80%.
Em Unicode existem três diferentes codificações de caracteres: UTF-8, UTF-16 e UTF-32. Destas três somente UTF-8 deve ser usada para conteúdo Web. A especificação para a HTML5 diz "Recomenda-se que os autores usem UTF-8. Validadores deverão desaconselhar os autores a usar codificações legadas. Ferramentas de autoria devem ser configuradas por padrão para uso de UTF-8 para novos documentos."
Notar, particularmente, que todo caractere ASCII em UTF-8 usa exatamente os mesmos bytes da codificação em ASCII, fato que em muitos casos viabiliza a interoperabilidade e a retro-compatibilidade.
Considerando o HTTP header
Qualquer declaração de caracteres constante do HTTP header sobrescreve a declaração constante na página. Se o HTTP header declara uma codificação diferente daquela que você escolheu para seu conteúdo isso irá lhe causar problemas a não ser que você seja capaz de alterar as configurações do servidor.
É provável que você não tenha controle sobre as declarações vindas no HTTP header. Neste caso entre em contato com o responsável pelo servidor e peça ajuda. Por outro lado existem mecanismos capazes de solucionar o problema quando seu acesso ao servidor é limitado ou está gerando páginas dinamicamente. Por exemplo, consulte Configurando a codificação de caracteres no HTTP header para informações de como configurar codificação tanto localmente para um conjunto de arquivos no servidor como para conteúdos gerados dinamicamente.
Depois de usar um dos métodos descritos para configurar a codificação no cabeçalho HTTP você deverá verificar se o HTTP header está declarando a codificação de caracteres correta. Use a ferramenta W3C Internationalization Checker que informa a codificação, caso ela conste do HTTP header. Outra alternativa é descrita no artigo Verificando HTTP Headers que aponta para outras ferramenta de verificação das informações passadas pelo servidor com respeito à codificação de caracteres.