Réponse détaillée
Appliquer un encodage à votre contenu
Lorsque vous créez du contenu, vous devriez déclarer l’encodage de caractères de vos pages à l’aide de l’une des méthodes décrites dans notre article Déclarer un encodage de caractères en HTML.
Toutefois, il est important de comprendre que le simple fait de déclarer un encodage à l’intérieur d’un document ou sur un serveur ne modifiera pas les octets ; vous devrez enregistrer votre texte dans cet encodage pour l’appliquer à votre contenu. (La déclaration aide simplement le navigateur à interpréter les séquences d’octets dans lesquelles le texte est stocké.)
Si nécessaire, définissez UTF-8 comme encodage par défaut des nouveaux documents dans votre éditeur de texte. L’image ci-dessous montre comment procéder dans les préférences d’un éditeur comme Dreamweaver.
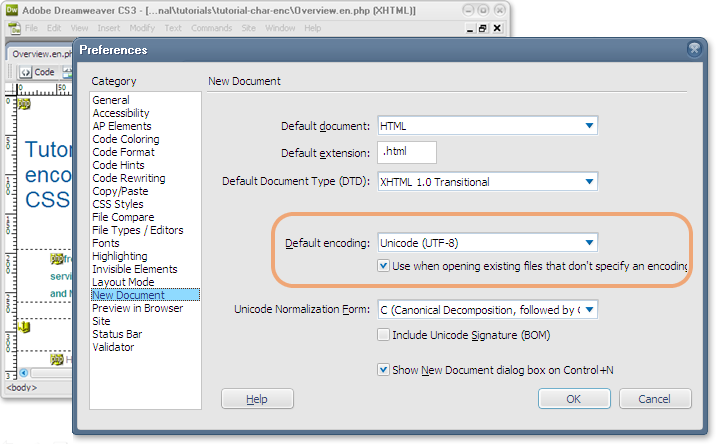
Vous pourriez aussi avoir besoin de vérifier que votre serveur envoie les documents avec les bonnes déclarations HTTP, car celles-ci prévalent sur les informations figurant à l’intérieur du document (voir ci-dessous).
Les développeurs et développeuses doivent aussi s’assurer que les différentes composantes du système peuvent échanger entre elles. Les pages Web doivent pouvoir échanger sans heurt avec les scripts backend, les bases de données, et ainsi de suite. Bien sûr, eux aussi fonctionnent mieux avec UTF-8. Vous trouverez une liste détaillée des choses à prendre en compte dans notre guide Migrer vers Unicode.
Pourquoi utiliser UTF-8 ?
Une page HTML ne peut avoir qu’un seul encodage. Vous ne pouvez pas choisir différents encodages pour différentes parties d’un document.
Un encodage basé sur Unicode, comme UTF-8, répond aux besoins de nombreuses langues. Il est également compatible avec les pages et les formulaires qui combinent plusieurs langues. De plus, son utilisation élimine le besoin de logique côté serveur pour déterminer individuellement l’encodage de caractères de chaque page envoyée ou de chaque soumission de formulaire entrante. Ainsi, elle réduit considérablement la complexité d’un site ou d’une application multilingue.
Un encodage Unicode permet aussi d’utiliser sur une même page un nombre de langues beaucoup plus important que tout autre encodage.
Aujourd’hui, les obstacles à l’utilisation d’Unicode sont très rares. En janvier 2012, Google a d’ailleurs annoncé que plus de 60 % du Web (d’après un échantillon de plusieurs milliards de pages) utilisait désormais UTF-8. Si on y ajoute le nombre de pages web utilisant uniquement ASCII (qui est un sous-ensemble d’UTF-8), ce pourcentage passe à environ 80 %.
Il existe trois encodages de caractères Unicode différents : UTF-8, UTF-16 et UTF-32. Parmi les trois, seul UTF-8 doit être utilisé pour les contenus Web. Comme l’indique la spécification HTML5, « nous recommandons l’utilisation d’UTF-8 aux créateurs et créatrices de contenus. Les systèmes de vérification de la conformité peuvent leur déconseiller d’utiliser d’autres encondages. Les outils de création devraient utiliser par défaut l’encodage UTF-8 pour les nouveaux documents. »
Remarque : en UTF-8, tous les caractères ASCII utilisent exactement les mêmes octets qu’un encodage ASCII, ce qui facilite souvent l’interopérabilité et la compatibilité descendante.
Prise en compte de l’en-tête HTTP
Toute déclaration d’encodage de caractères effectuée dans l’en-tête HTTP prévaut sur les déclarations présentes sur les pages individuelles. Si l’en-tête HTTP déclare un encodage différent de celui que vous souhaitez utiliser pour votre contenu, cela posera problème, sauf si vous pouvez modifier les paramètres du serveur.
Il est possible que vous n’ayez aucun contrôle sur les déclarations qui accompagnent l’en-tête HTTP et que vous deviez demander de l’aide aux personnes qui gèrent le serveur. Toutefois, si vous avez un accès limité aux fichiers de configuration du serveur ou générez des pages à l’aide de langages de script, vous aurez peut-être des moyens de résoudre les problèmes sur le serveur. Par exemple, consultez l’article Configurer le paramètre d’encodage HTTP pour plus d’informations sur la manière de modifier les informations d’encodage, que ce soit en local pour un ensemble de fichiers sur un serveur, ou pour du contenu généré à l’aide d’un langage de script.
Généralement, avant de procéder, vous devez vérifier que l’en-tête HTTP déclare bien l’encodage de caractères. Pour découvrir quel encodage de caractères (le cas échéant) est spécifié dans l’en-tête HTTP, vous pourriez utiliser le Vérificateur d’internationalisation du W3C. Sinon, l’article Vérifier les en-têtes HTTP renvoie vers d’autres outils qui permettent de vérifier les informations d’encodage transmises par le serveur.