Más detalles
Aplicar una codificación al contenido
Los autores de los contenidos deben declarar la codificación de caracteres de sus páginas utilizando uno de los métodos descritos en Declaración de codificaciones de caracteres en HTML.
Sin embargo, es importante entender que el simple hecho de declarar una codificación dentro de un documento o en el servidor no cambiará los bytes; es necesario guardar el texto en esa codificación para aplicarlo a su contenido. (La declaración sólo ayuda al navegador a interpretar las secuencias de bytes en los que se almacena el texto.)
Si necesario, configure UTF-8 como el valor predeterminado para los nuevos documentos en su editor. La siguiente imagen muestra cómo lo haría en las preferencias de un editor como Dreamweaver.
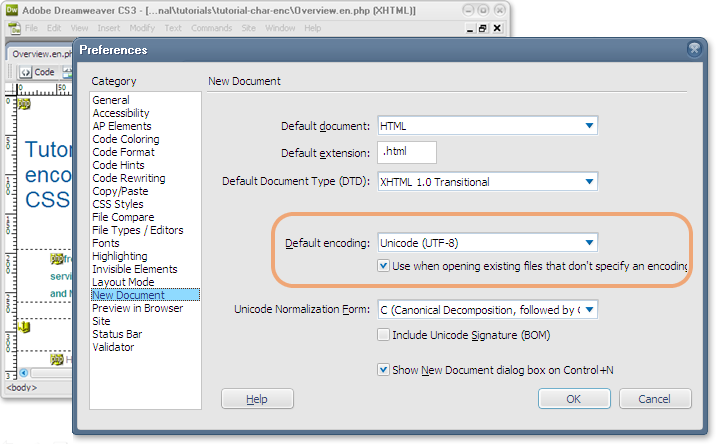
También es posible que tenga que comprobar que su servidor está entregando documentos con las declaraciones HTTP correctas, ya que, de lo contrario, anulará la información contenida en el documento (véase más adelante).
Los desarrolladores también necesitan asegurarse de que las diversas partes del sistema puedan comunicarse entre sí. Las páginas web deben ser capaces de comunicarse perfectamente con los scripts de back-end, bases de datos, etc. Estos, por supuesto, todos ellos funcionan mejor con UTF-8, también. Los desarrolladores pueden encontrar un conjunto detallado de cosas a considerar en el artículo Migración a Unicode.
¿Por qué usar UTF-8?
Una página HTML sólo puede estar en una codificación. No se pueden codificar diferentes partes de un documento en diferentes codificaciones.
Una codificación basada en Unicode como UTF-8 puede soportar muchos idiomas y puede acomodar páginas y formularios en cualquier mezcla de esos idiomas. Su uso también elimina la necesidad de que la lógica del server-side determine individualmente la codificación de caracteres para cada página servida o cada envío de formulario entrante. Esto reduce significativamente la complejidad de tratar con un sitio o aplicación multilingüe.
Una codificación Unicode también permite mezclar muchos más idiomas en una sola página que cualquier otra opción de codificación.
Cualquier barrera para usar Unicode es muy baja en estos días. De hecho, en enero de 2012 Google informó que más del 60% de la Web en su muestra de varios miles de millones de páginas estaba usando UTF-8. Agregue a esto la cifra de páginas web sólo ASCII (ya que ASCII es un subconjunto de UTF-8), y la cifra se eleva a alrededor del 80%.
Hay tres codificaciones de caracteres Unicode diferentes: UTF-8, UTF-16 y UTF-32. De estos tres, sólo UTF-8 debe utilizarse para el contenido de la Web. La especificación HTML5 dice "Se anima a los autores a utilizar UTF-8. Los verificadores de conformidad pueden aconsejar a los autores que no utilicen codificaciones heredadas. Las herramientas de autoría deberían usar UTF-8 por defecto para los documentos recién creados"
Tenga en cuenta, que todos los caracteres ASCII en UTF-8 utilizan exactamente los mismos bytes que una codificación ASCII, lo que a menudo ayuda a la interoperabilidad y a la compatibilidad con versiones anteriores.
Tener en cuenta la cabecera HTTP
Cualquier declaración de codificación de caracteres en el encabezado HTTP anulará las declaraciones dentro de la página. Si el encabezado HTTP declara una codificación que no es la misma que la que desea utilizar para su contenido, esto causará un problema a menos que pueda cambiar la configuración del servidor.
Es posible que no tenga control sobre las declaraciones que vienen con el encabezado HTTP y que tenga que ponerse en contacto con las personas que administran el servidor para obtener ayuda. Por otro lado, a veces hay formas de arreglar las cosas en el servidor si tiene acceso limitado a los archivos de configuración del servidor o si está generando páginas utilizando lenguajes de scripting. Por ejemplo, véase Configuración del parámetro de conjunto de caracteres HTTP para obtener más información sobre cómo cambiar la información de codificación, ya sea localmente para un conjunto de archivos en un servidor o para contenido generado utilizando un lenguaje de scripting.
Normalmente, antes de hacerlo, debe comprobar si la cabecera HTTP está declarando la codificación de caracteres. Puede utilizar el W3C Internationalization Checker para averiguar qué codificación de caracteres, si existe, se especifica en el encabezado HTTP. Alternativamente, el artículo Comprobación de cabeceras HTTP apunta a otras herramientas para comprobar la información de codificación pasada por el servidor.