The primary mission of the W3C Internationalization work, and of the W3C itself, is to create a Web for All. The W3C works with and relies on other organizations and initiatives to complement this work: the Unicode Consortium creates the characters needed for language support, and algorithms for their use; font designers and developers around the world provide fonts to support the world's languages; ICANN and the IETF are leading work on International Domain Names and Universal Acceptance to domain names and email addresses.
A particular area of interest and focus for the W3C is styling the layout of content, in web pages and in digital publishing. Much of this can be addressed in CSS, but there are other technologies that also need to take such factors into account, such as Timed Text, WebVTT, SVG, XSL, and to some extent markup models such as HTML, etc. It is particularly concerned with the mechanics of text, such as rules for line-breaking & justification, local approaches to expressing emphasis or decorating text, localising counter styles, supporting bidirectional text in markup, initial-letter styling, hyphenation, page layout, etc.
This area is one where it is typically difficult to find information, especially in English, about user expectations. There are few experts actively involved in ensuring that these typographic mechanisms are well supported on the Web. It is also an area where there may be some degree of fluidity, as people in many cultures are still trying to establish for themselves how their previous traditions translate into the world of Web-based content.
Recently the W3C has been making additional efforts to better understand the needs of the various writing systems and cultures around the world, and communicate those to specification and browser developers. Let's look at some of the things that are currently in progress or beginning, as well as possible future directions.
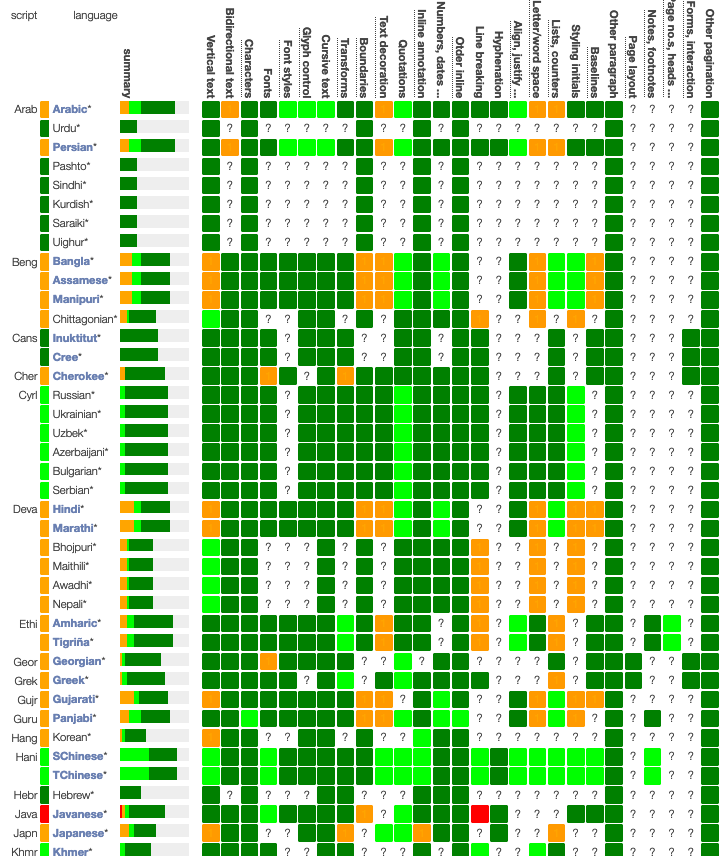
The Language Matrix
The language matrix is a recent innovation. We plan to use it as a heat map to show how well languages are supported on the Web. We started tracking around 80 languages, but are open to add others if there are experts available to provide the necessary information about them.
The columns of the matrix represent various typographic features that need to be supported by Web technologies in order for people to use the Web. The colours of the matrix show whether, for a given language, those features are well supported, need additional work for advance publications, need additional work for basic web use, or are problematic enough to make it difficult to use the Web in that language.
At the time of writing this, 33 languages need work for advanced publishing; 27 need work for basic features, and 1 doesn't work well on the Web. However, 41% of the cells in the matrix carry question marks: indicating that we need to do some research in order to know the status for that feature.
The matrix should allow us to get an overall idea of how well the Web is supported for local users around the world, and help identify and prioritise areas where work is needed.
Layout requirements documents
A few years ago, a group of experts from the Japanese publishing industry came together with others at the W3C to produce a set of requirements for support of Japanese layout. The resulting document, Requirements for Japanese Text Layout, known as 'jlreq' and published in both English and Japanese, was a resounding success, and was even published in book form in Japan.
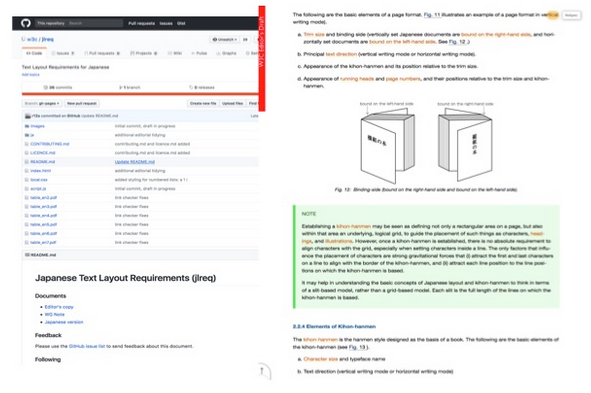
Following the publication of jlreq, groups of other experts came together to work on similar documents for Hangul (klreq), Simplified & Traditional Chinese (clreq), Ethiopic (elreq), Arabic (alreq), and Mongolian (mlreq). There are also embryonic developments related to Tibetan (tlreq) and Hebrew, and the Digital Publishing WG at the W3C is working on a 'Latin req' document.
It is important to note that an lreq document only describes what you are expected to see when reading text, and not what applications or authors are expected to do. By describing only how a writing system appears to users, the document avoids becoming out of date. Information that describes specific technologies (such as CSS) related to a writing system, or that describes how current browsers or e-readers handle the writing system, belongs in a separate place. Which brings us to...
Gap analysis
Writing the layout requirements documents is hard, and we were finding that the crucial step of matching the requirements to reality was really only taking place via adhoc means, if at all. We wanted a quicker way to start the analysis and resolution of gaps.
To address this, we developed a gap-analysis development framework, common across all language enablement groups. The framework reduces the set up phase for a group, helps them develop effective documents, and supports them with pertinent information.
The goal of documenting gaps is to provide an increased sense of momentum for participants. Individual gaps can be documented one at a time, and immediately provide information of use to spec and browser developers.
Gap analysis documents are not focused on solutions – only on clarifying barriers to use. They also provide important information for prioritising work on solutions, based on the pain they create for the local community. They contain quite specific information, and parts of that information will hopefully be obsoleted and updated as time goes by and issues are addressed. (See Setting up a Gap Analysis Project for more information.)
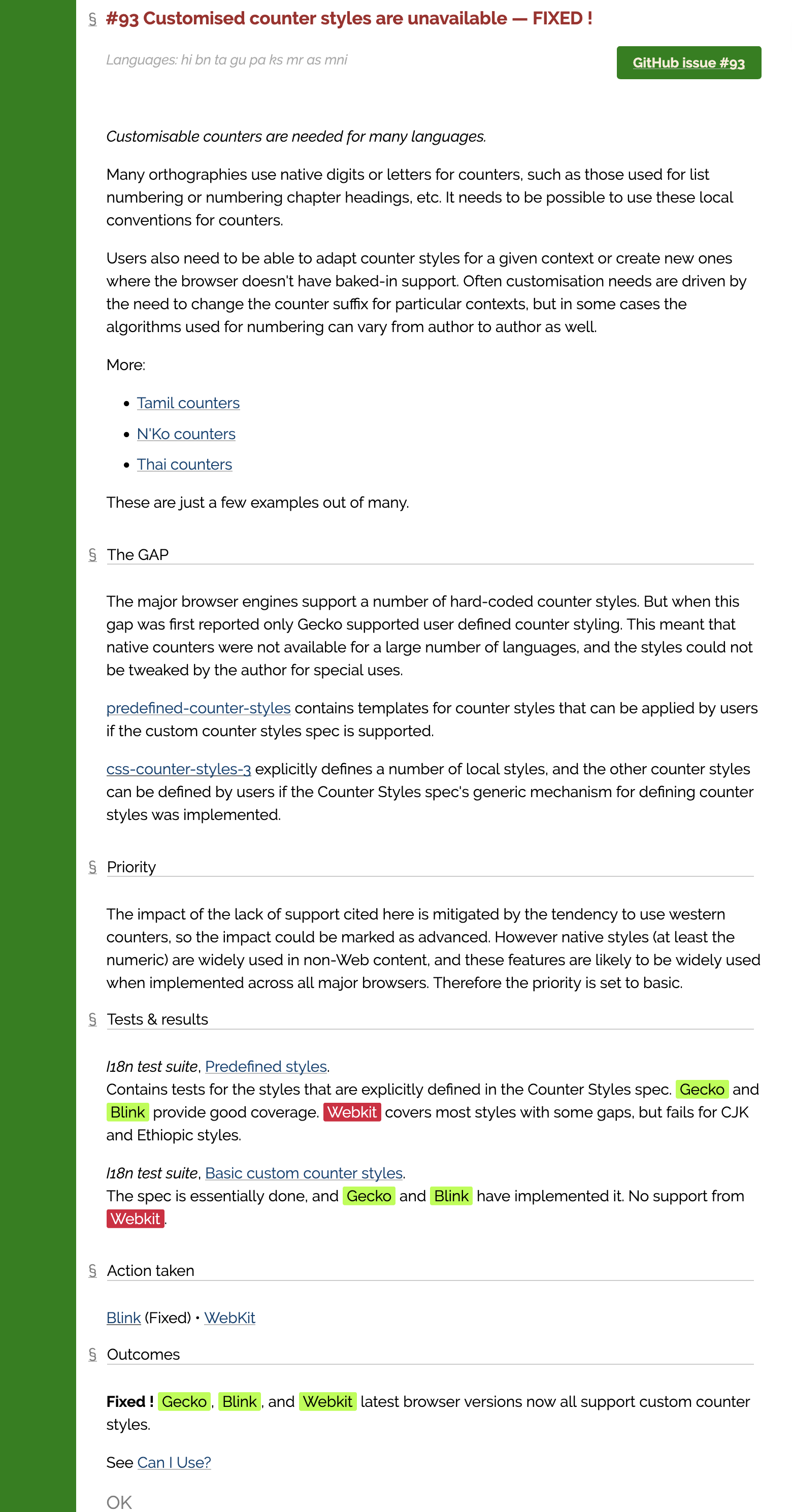
The priority is documenting the gaps, but a group may build a separate requirements document at the same time, added to as gaps are identified, in order to communicate what is needed to bridge that gap. Gap analysis work should also be supported by small tests or screenshots – to show where features are broken, and help implementers check that fixes are producing what is needed.
There is a close correspondence between the structure of the language matrix and the gap-analysis documents, so that you can link between them.

Expert networks
The most fundamental aspect of this work involves bringing experts together to discuss the issues. The main problem we face at the moment is that experts don't know how to tell the W3C what problems exist for support of their language on the Web, and the W3C doesn't know how to contact people who can help when questions arise.
To address this problem we are aiming to create networks of experts, focused on particular writing systems or regions. Our goal is to significantly lower barriers to participation at the W3C, and to significantly increase participation in W3C's work – especially from regions that have been under-represented in the past.
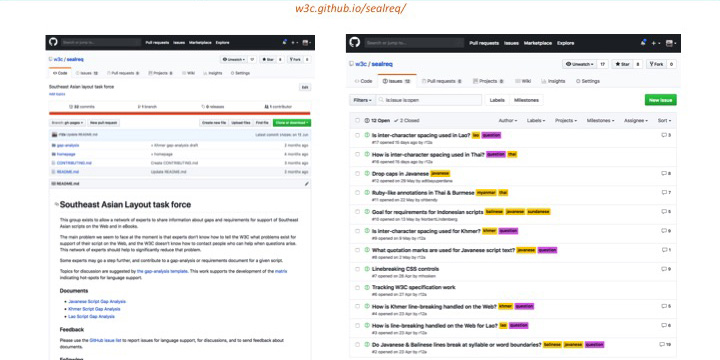
The sealreq (Southeast Asian) task force was the trail blazer here. We started the group without editors, but just focused on discussion on GitHub issue lists. W3C staff capture the information that is coming out of that forum, and we have gap analysis documents in progress for Khmer, Lao, and Javanese.
Language enablement index
As information is generated and stored in issue lists, gap-analysis documents, and layout requirements, it is important for developers of specifications and browser or ereader implementers to be able to find it. This is where the Language enablement index comes in.
The structure of the index has been harmonised with the matrix and gap-analysis documents. The index provides links to script-specific pages that, in turn, link to resources such as requests for information, related discussions, requirements information, type samples, tests, gap analysis documents, and specifications.
The links to GitHub discussions point to threads in the relevant Language Enablement groups, but also point to discussions in W3C repositories used by CSS, SVG, HTML, etc working groups.

Issue tracking
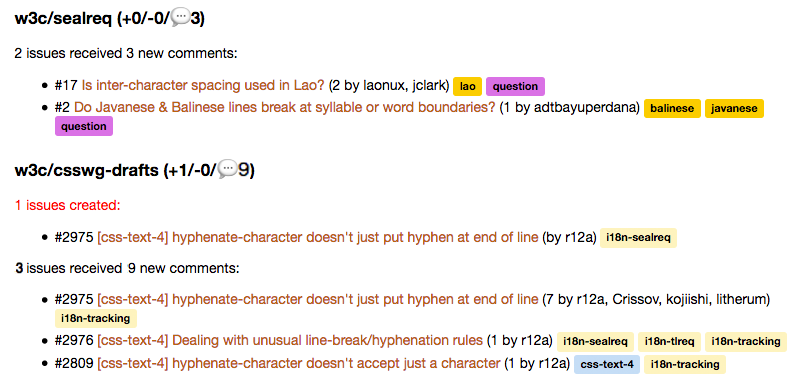
Various mailing lists belonging to the W3C Internationalization Interest Group receive notifications about GitHub activity. For example, whenever a GitHub issue is raised, commented, or closed in the Southeast Asian Layout repository, the public-i18n-sealreq mailing list is notified via daily digests. The digest notifications not only capture activity in that repository, but also report changes to issues in the CSS, HTML, etc, repositories that have a sealreq label.
Type samples
Another recently added resource, the Type Samples Repo, provides a place to store pictures or scans of text layout features in the wild. Again, you can filter the results by the standard feature types, by language, and by medium.

International issue repository
As an experiment, we set up a repository on GitHub where people can log problems they are encountering when deploying or using the Web globally. This helps the W3C be more aware of the issues people are experiencing. For example, someone could tell us that vertical text isn't working quite as expected, or that webfonts take up too much bandwidth for mobile users in developing countries, or that browsers need to recognise native calendars or time and date formats for a particular community.
Layout requirements groups
Work on defining gap-analysis and requirements is carried out in a number of 'lreq' groups. See the current list of groups. Some groups are only expert networks, discussing issues on GitHub issue lists. Others are principally working on gap analysis documents. Yet others are heavily focused on producing layout requirements documents. Groups can move between these categories, depending on the available contributors.
A typical group producing documents would have one or more chairs and meet regularly for teleconferences. Key contributors to the group's deliverables form a core. They include document editors, but also those who regularly contribute time for review and discussion.
Beyond that group lie any number of people who follow the work by subscribing to the notification emails and occasionally contributing comments to issues. The W3C has made participation in these groups as easy as possible. These people can comment on and track developments related to a particular script or group of scripts.
Help us do more
The W3C has recently been looking for partners to help develop the work described above. We need experts to come forward from around the world to contribute their knowledge so that we can better understand, quantify and address the remaining work to support a Web for All. We are also looking for organizations would can contribute funding and resources to support an expansion of the internationalisation work.