
Meeting minutes
Agenda
laurens: we will start action items from yesterday, assigning people who want to refine the questions we discussed
… then discuss Authorization
… In the afternoon, we will discuss authentication, and continue the discussions on core operations
… then we will set a road map and further discuss action items
Action items from yesterday
aaron: we discussed a couple of topics, and seem to have general consensus on how to express this in specifications
… the next step would be to have some text that the whole group could discuss, before merging it
… we could start with PRs on the spec, or with issues, depending on how complicated the topic is
… we should have a person responsible to each topic
… - a section that describes the conceptual entities
… - a section that starts to unpack the type index
… for the type index I believe that definitions need to be clarified, so better start with an issue
… I can take the first one. I'll probably go with several PR, one for each entity kind
… I'm not convinced that the names will remain
… This would provide an outline for the main parts of the specification
laurens: yes, then additional PRs could be proposed on each section
… I would have a section with conceptual entities and abstract operations
… then another section with RESTful implementation of these operations
aaron: the HTTP bindings would be in a separate PR (even though HTTP operations can be informally mentioned in the abstract operations)
ben: I expect that discussion on metadata will be more extensive
aaron: I agree
… a lot of what we have been discussing, especially the linked data features, will be important for the metadata
ben: we don't need to follow how Dropbox or Google drive are doing things, but it can be a good source of inspiration
… we should look at existing APIs to decide what we want to take from them as inspiration
… I can do this research
aaron: Erich Bremer has already written something about metadata, largely based on linksets
… I expect this to be a big part of the section on metadata
ben: updating metadata can have a number of side effects (like renaming, moving...)
aaron: I'm hoping we can discuss details about metadata before we get into authorization
… Is anyone interested in taking the lead about the type index?
laurens: I can try that
… there might be relations to LDES, or even other ontologies
aaron: there was two thing I was hoping to discuss yesterday
… - the structure and data model of containers
… - other kinds of metadata
eric: I prefer to start with containers, this would ground our conversation on metadata
Containers
aaron: the current spec says the containers are RDF
… no guidance about JSON representation, about what properties to include
… no facility for extremely large containers that you might want to page through
ben: another one is the need to list the files without needing access to them
laurens: what's important to me: paginating the "contains" relationships
… there's the question of what other metadata we want to include
… some metadata are part of system-management
ben: should it include something like "controller"?
laurens: that's tricky to define. Could be several people? Should this be the owner?
bartb: by owner, do you mean the owner of the whole pod?
laurens: we are veering into the authorization discussion, this is a complicated subject
… another metadata is type. Should it be system- or user-manage, or both?
aaron: imagine you want to list only the JSON files in a container. With opaque names, you need a HEAD on each resource, not practical.
[aaron writes some JSON-LD on the paper board]
… without presuming the exact format we will use for containers, we will have a list of "items"
… each object in this list may contain the id of the resource
… a type, which would be an array containing system defines (e.g. "Container") and user-defined (which may be set via the metadata)
ben: could be multiple, could be 50,000
aaron: could be, though servers could add constraints on this
… items could have a size value, last-modified, created
… in principle, any item in the link-set metadata could just be here
laurens: and what would be present could be negociable by the client
aaron: yes, with Prefer: headers. LDP does that, I like it, but I'm not sure how widely this is used.
ben: this would be ACL managed, right? the list is generated based on your permissions?
laurens: it should be. Note that having read access to a container should probably allow you to see what's in it.
aaron: I've worked on 2 LDP servers that did things differently
… Fedora had an ACL aware container. If you have access to only 1 of the 3 items in a container, the 2 other entries would be there but obfuscated.
… There is a huge performance penalty for that.
… The other approach is: if you have read access to the container, you can see all that it contains.
<ryey> present
aaron: If you have privacy concerns, you can use a 2-levels hierarchy.
ben: 2nd option seems reasonable
s: ryey: could there be a middle-ground, with 2 read permissions for containers?
laurens: I suggest we park this for the Authorization discussion.
… but this middle-ground already exists.
… Also, changing the view of the container based on your permissions on the contained resource makes its hard to cache.
ericP: is this the same problem with the type index?
… if someone makes a resource confidential, it would have an impact on the type index and on the container.
… Same caching issues.
laurens: for me the type index is eventually consistent, different from containers. Maybe others have other expectations.
ericP: I guess some people might want to debate that.
… My point is: we may need to consider the issues on containers and the issues on type index all at once.
ben: you can still use sub-container to hide confidential resources
ericP: this forces people to use a specific organization of their resources
laurens: what is the meaning of the READ permission on a container?
ericP: I would argue that to see an item in the container, you need READ persmission on both the container and the item.
… I wonder if the performance issues mentioned by Aaron were implementation issues, or deeper.
aaron: back to serialization, I would like to discuss which metadata are part of the container's description
laurens: I would expect a "containedBy" link available on the resource
pchampin: shoud the container include the media type plus the RDF type?
ben: I would suggest 3 different properties for different kinds of type: LWS type (container/resource), media type, additional types
s: ryey: how do we get the media type?
aaron: I would expect that the server keeps track of the media type of each resource
… this is a MUST in the current Solid spec
ben: back to the Prefer: header, this could be used to deal with the scalability when we have a large number of types
aaron: I think this discussion will be informed by the higher level discussion on description format
… Activity Streams has a notion of Collection, LDP has a notion of container
laurens: I would avoid overloading LDP containers, I suspect we are going to diverge from it
… but I appreciate the need to be backward compatible
aaron: I expect that we will define a JSON-LD context for LWS, which could include the AS context
… so we will reuse existing vocabulary when available
… for last-modified and created, probably Dublin Core
laurens: is there something for size?
jeswr: stat:size is already in the spec
aaron: but stat: is explicitly for POSIX filesystems... talk about overloading
ben: defining our own terms is not that bad
aaron: I would include a size predicate; I would make it a SHOULD because exposing the size of large files could be a security issue (attack target)
… and only for non-container resources
… id would be a MUST
laurens: as well as resource type and media type
… all the rest would be SHOULD, imo
s: ryey: the size is not the only one that would be security sensitive, names can sometimes be
aaron: that's why I would suggest most metadata would be SHOULD
bartb: also, some resources might be generated, so the size is not known in advance
aaron: that's a good point. We may have a notion of "projected resource", or views.
pchampin: as we are discussing MUSTs and SHOULDs
… I suggest that we not only make JSON-LD contexts but also JSON-schemas of sorts for the LWS serializations
… more friendly to developers who are not comfortable with Linked Data
ben: I would also suggest a "label" field
jeswr: why put it here rather than in the metadata resource?
ben: yes, I'm mixing the two, but the metadata in the container are related to the metadata of the data resource
jeswr: I would suggest that the user-defined types are more appropriate for the metadata than for the container medatata
s: ryey: every metadata should be in the metadata associated resource (except maybe size)
… and in this associated resource, you would specify which would show in the containers
ben: that's what I was suggesting
jeswr: this raises the question of the resource-level metadata that you are authorized to see
pchampin: LWS containers and AS collections are similar, but we need more discussion; they should maybe not be conflated
Resource-level metadata
aaron: Erich Bremer has written some text, based on RFC 9264 (LinkeSet resources)
… it follows the RFC 8288 (Web Linking)
… a link has a target (a URI), a relation type ('rel=...'), and a number of relation types are predefined
… additionally, a link can have a title (text)
… you can put an arbitrary URI in the rel= attribute
… LDP defines its own relation types as URIs
… this relying on LinkSet puts constraints on what could be in the metadata
… adding properties to the link is allowed but not recommended
laurens: one problem is that Web Linking only expects URIs as the target of the links
aaron: the title attribute allows for text, title* allows for internationalized text
pchampin: but that's an indirection, that "the title of the target itentified by the URI"
laurens: we discussed yesterday about opaque identifiers
… this would make it important to be able to add user-friendly labels
… which this method can not capture
… an RDF document with the resource as primary topic would be more flexible
aaron: the advantage, on the other hand, is the ability to convey the metadata as link headers
laurens: there is also the question of server-managed vs user-managed
… with RDF, system-managed could be enclosed in a named graph, making things easier for developers
aaron: I get the point about labels and literals
… about server-managed, I don't think there would be too many of them
… namely: describes / describedBy, acl (potentially)
… the current specification has a relation to the root of the storage; that also would be server-managed
… also a relation pointing to a storage description would be server-managed
… apart from that, I think everything else is good for users to manipulate
pchampin: could we simply add spurious attributs to the LinkSet documents, where we would shove some JSON-LD with literal properties?
aaron: I re-read the spec, they discourage that
… Note that if you have a binary object that can not self describe and you want a rich set of metadata about it
… I would encourage that you create a data resource that is RDF, and then you link to that as "additional description"
laurens: that's what I discussed yesterday with additional secondary resource
s: ryey: I'm looking at RFC 9264, we need to serialize this to JSON
aaron: the RFC defines 2 formats, one of them is JSON. We would require the JSON, we would authorize contebnt-negotiation to Turtle
laurens: but updating the resource should use the JSON standard format
aaron: I would not prevent SPARQL update of the resource, but not require it
ericP: you can do a PUT with an etag, the etag depending on the serialization
ben: aren't we painting ourselves in a corner with this serialization? shouldn't we discuss what metadata we need more generally first?
… the ability to convey the metadata in HTTP Link headers is an optimization
aaron: you are right
… start with describes / describedBy, linking between a resource and its metadata resource
… acl
… parent
s: ryey: is parent an array or a single value?
aaron: type (server defined, e.g. container/resource)
… media-type
… label (a.k.a. user defined type)
… storage
… storage metadata
laurens: about 'storage metadata', could be discoverable with .well-known (like OpenID)
aaron: as we are doing linked data, I prefer explicit links
laurens: acl would be server managed in most implementations, even though there is a slight chance that some implementations would want to allow users to set it
aaron: I imagine that we can define a number of mandatory fields, users could add their own
laurens: server implementations could also
beau: I suggest adding a link to a shape file
aaron: +1, although I would suggest "schema"
s: ryey: label should be renamed to user-defined-type
ben: but a text label property should be there
Wonsuk: having a version marker would be useful, because the metadata format may evolve
jeswr: could be achieved by a version number in the JSON-LD context
pchampin: I like aaron's suggestion earlier "additional-medatata" (a data resource that further describes the resource)
s: ryey: about 'parent', should the concept of "transitive container" be possible?
jeswr: this has impact on authorization
aaron: if A contains B contains C, the metadata for C would say: "parent=B", it would not talk about A
… one might allow an alias of a resource to be in multiple containers
aaron: maybe we could have a "hierarchy" field that gives an array of all ancestors, from direct parent to storage root
… could be useful
<Zakim> ericP, you wanted to say that LDP Containers did double duty as server-managed and user-managed containers. if we want to enable both UML:owned members and polyhierarchy, we might want to consider the user-managed containers as their emulations of the server Container interface, but entirely not our problem
ryey: could be useful, but that's different from my question
ericP: in LDP, contains is server managed (you POST to a container, it contains the resource)
… we can allow to emulate our container model in userland
… rather then defining complicated things such as polyhierarchies
pchampin: we assume that the server manages the presence in a container but we could decouple that from the side effect that the server *has* to deal with (regarding ACL)
Authorization
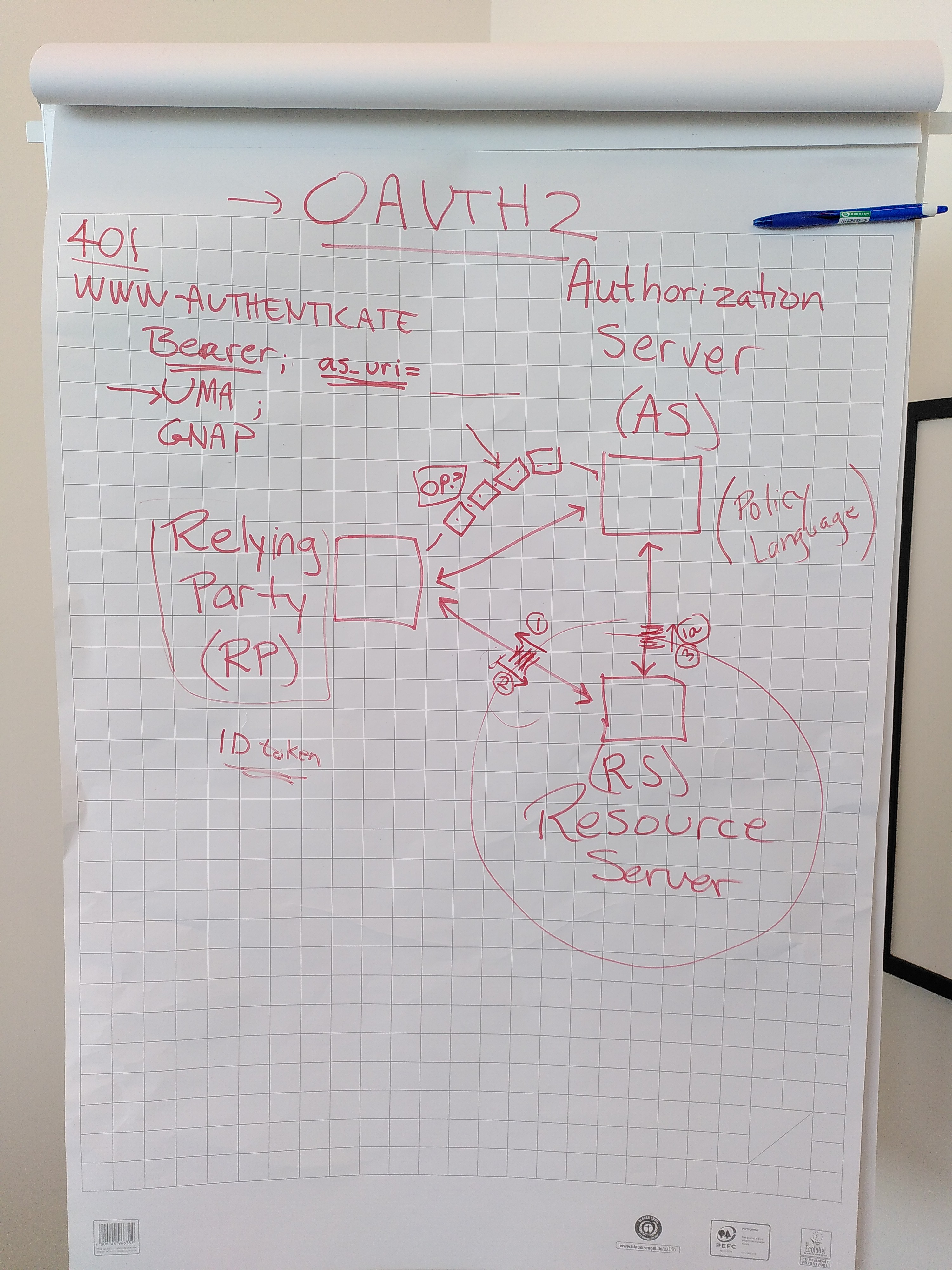
acoburn: (writing Authorization Server and Resource Server/AS and RS on the white board)
… (and Relying Party/RP)
… I'm not suggesting OAuth2 is the only framework we should use
… but it gives us an abstract model to think about it
… so it should at least work with this
… for SAML, the names are different, but the structure is the same
… at the very least, we need to describe the interface RS/AS and RS/RP
… question is: to what extent do we describe the other interactions?
bendm: do we expect to support one authz protocol?
acoburn: personal feeling: authz protocols keep changing
… OAuth2 and SAML are around for a long time, but there's OIDC/GNAP/... thinks keep changing
… being too rigid would hurt us
laurens: but OAuth2 will probably not go anywhere soon
acoburn: pinning to OAuth2 isn't too bad, but being too open brings complexity
laurens: I've seen OAuth2 in very performant systems, and a lot of caching or optimizations is possible
acoburn: also, this is an abstract model
pchampin: can we go through the responsibilities?
acoburn: generally speaking:
… simplest case:
… 1 app (RP), 1 RS, 1 known AS
… RP: if no token, do request to AS (client credentials, via browser or backend), get token
… token is sent from RP to RS (JWT or something else), RS validates token (token introspection via roundtrip from AS, or via key material from AS without roundtrip)
… RP is an application, client,...
… the thing that is trying to do the GET/...
… 1st problem: how to find the AS? you go to the RS first
… you get a 401 with WWW-AUTHENTICATE header that hints to the AS
… could just be 'Bearer', meaning 'just fetch it at the AS, you know where it is'
… given we're decentralized, we probably we want 'Bearer; <as_uri>'
… we can do this without requiring UMA
… this is on the HTTP level
… scheme and series of properties
… I'm pretty sure GNAP uses the same thing
laurens: yes, there's a convention
acoburn: if it was UMA: it would include a ticket and state 'UMA' instead of 'Bearer'
… basically what is stated is 'follow the semantic of the scheme that is presented', ie Bearer, UMA, GNAP
… I don't think we need to specify one
… but if we must (eg for testing), I would go for OAuth2
… there might be more steps between RS and AS, eg OIDC provider
laurens: token exchange is a good fit for some problems we might have, RDF8693
<laurens> https://
laurens: RFC8693
acoburn: with self-souvereign, the RP merges with _some_ of these intermediate steps between RP and AS
… so there will always be some kind of distinction between the AS and the RS
… and always some kind of distinction between RP and RS, even if deployed on the same server
acoburn: RP could have done some authn beforehand, but that's not necessary
… an RS could have different authz setups
laurens: Solid uses an OIDC ID token, so it's cleaner to have a distinct authz server
… also for token lifetimes etc
ryey: so there's no consdering of exposing sensitive info?
acoburn: so far, everything is public
… any token _should_ be opaque, but it's often a signed JWT etc
… so what kind of info that goes into that JWT needs to be considered
… simple model is that we define the RS, and the interaction boundaries between RP and AS, and that's it
… more complex is that we also include all interactions between RP and AS
… eg if you do it like X, you must do it like <ref>
laurens: I see a lot of complexity when dynamically being able to manage AS
… AS signifies the protocol, not implies anything about the policies used
… AS check whether you have the right authn and credentials
bendm: but then who does the authz?
acoburn: there's different models
… to be defined: the token sent by the AS: how does that look like?
… first define the data model of that token
laurens: I suggest splitting course-grained authz via the AS with fine-grained authz via the RS
acoburn: model 1: token contains a yes or no
… model 2: token contains a partial decision, and the RS roundtrips to the AS for the fine-grained decision
… historically, model 1 was used (eg via scopes)
… i.e. you have scope read:X, RS says 'write:X is not allowed'
… justin richter from GNAP has lots of experience why scopes are not sufficient
laurens: currently, scopes are defined by the RS
acoburn: yes, and tend to be very app-specific, thus not interoperable
laurens: so ACL rules with has:scope would be horrible for interop
… example: you have a public resource
… you don't get an AS redirect
… for a private resource: you get a token via AS that _might_ give you access
… RS is tasked with the decision: can you do XYZ?
… the RP gets the response of the RS whether the action is succesful
… part of the decision could be via the AS, but the RS is in control
bendm: that feels like bad separation of concerns?
laurens: let's say you have A and B, you have access to A
… you want A, you go via AS, and get a token for A
… you cannot reuse that for B
… also, AS, doesn't know what type of operation you want to perform
bendm: but then, you can't solve that with scopes?
laurens: this has been a long-standing issue, RFC9396 is a solution to that: rich authz request
acoburn: JWT has a couple of claims (headers, sub, iss, and aud)
… RDF9396 suggests additional claim 'authz details'
… adds locations/actions/privileges/datatypes
… this gets sent to the AS to check whether you can do all of this
… and gets mirrored back to the JWT
bendm: so basically, this is an alternative to more specialized/formalized scopes
laurens: this allows the RS to fully know what to do
… ie. say yes or no to specific requests
… you can have an array of authz details
ryey: do you need to specify these datatypes details?
laurens: no
… for LWS, we could specify for actions the modes we allow in the authorization model
pchampin: so, once authenticated, this can happen under the hood, without me noticing?
acoburn: this is specifically for the RP talking to the RS what they want
pchampin: so, we are constraining the connections between RP and AS?
acoburn: we mostly want to give guidance: RP and AS interactions keep changes
ericP: RP/AS links change more frequently than the other links?
acoburn: historically, RP/RS link is entirely app-defined
… first step is to create an abstract model for what that looks like
… to get interop foor OAuth and JWT, wichi is the majority of things that work
bendm: so maybe first next topic is to see how we can align this with current status quo?
<laurens> rssagent, draft minutes
[we reconvene after lunch, gibsonf1 joins]
acoburn: to recap, the Relying Party (RP) asks for a resource to the Resource Server (RS), and gets a 401 with a link to the Authorisation Server (AS)
… that requires the RS to be aware of the AS (RS-AS interface in the diagram)
… another aspect of the RS-AS interface is whether the AS has access to the policies on the RS (the 'acl' resource)
laurens: I think it should have access
acoburn: depends on the path we are taking
… the policy might be hosted on the AS, or at least in a location that is aware of the AS
laurens: either it is going to be on the RS as a regular RDF resource, or a specific resource managed by the AS
acoburn: ESS does the latter; both models could work, with pros and cons
laurens: I would not mandate one or the other in the spec
ben: I don't think that the RS needs to know what is in the policy
laurens: it does not need it in the model we are discussing; in the current model of Solid, this is different
… in the current Solid model, the RS makes the final decision about authorization
pchampin: by "current Solid model", you mean...
laurens: ... Solid with Solid OIDC
… the only thing that the RS has to make the decision is the identity of the user
… I think we want to cleanup the separation of concerns
ben: with this separation the Policy language is not anymore in scope of the spec
acoburn: this is tricky, because this would kill interop when it comes to manage policies
… on the other hand, I have low confidence in WAC or ACP being long term solutions for LWS
… but that's all we have today, so I would like to make do with what we have, but leave the door open for other policy languages in the future
laurens: to play the devil's advocate: we don't need the policy language to be the interface to policy management
… we could define an interface to request/grant/revoke access
… it is a big step from the current state
acoburn: this would be a middle ground
… this amounts to ask "can you answer these questions" (fields in "Authorization details")
laurens: this is a form of discretionary access control
… role-based access control would be more general
… attribute-based access control is yet something entirely different
ben: WAC maps an identity to the different operations; ACP maps a VC to the different operations
acoburn: in JWT, sub is the agent (as a person)
… iss is the issuer
… aud (audience) is your app, the Relying Party
… actually, there are two ways of defining "audience". It is "the entity to which you are sending the token"
… different based on your PoV
laurens: I don't think that aud is always the RP in OAuth
acoburn: aud can be a single value or an array
… if you want it to be the RP and the RS, you would put both
… there is also "authorized party" (azp), which would be the client; it needs to be in aud
[discussion on the respective role of the JWS claims in OAuth]
acoburn: we could say the 'aud' must contain both the RP and RS, and that 'azp' must be 'RP'
… arguably this is most complete, and less subject to interpretation
ben: who is expected to generates that?
acoburn: the AS. You could use any AS you want, but it must produce a JWT that satisfies these constraints.
… the most complicated thing we have to do right now is to define the structure of the token sent from RP to RS.
laurens: one problem with Solid today is that we are relying on OpenID Connect providers, who act both as Authentication and Authorization servers
… we reuse the identity token as an auhtorization token
… with Token-Exchange, we could define how to exchange the identity token for a complying access token, scoped to the operations you want to perform
… the most common use-case is backend for frontend
… the backend is taking the identity token from the user to get an access token for itself, limiting security risks
acoburn: some people in the DPop world consider it an anti-pattern to associate a DPop key with an identity token, and they are not wrong
… currently, identity tokens in Solid are very powerful, could be reused in a malicious way
… by requiring this exchange of token, the security scope becomes much more narrow
laurens: suppose you have a malicious Solid server, it gets an ID token; it can be reused with any other server you have access to
… mechanisms like Token-Exchange allow you to prevent that
acoburn: the trick is that it is the application that the user uses that does the token exchange to scope it
gibsonf1: the way we do it is to restrict the token to the user AND the application
… so the server can not reuse it as such
laurens: this addresses impersonation, but not the replay attack
bendm: does the RP not know where the request come from?
acoburn: no
laurens: in the authorization problem, we need to assume the token can come from anywhere
acoburn: the RP starts with the ID token, but it will never send it to the RS
… (although that's what is happening right now)
ryey: if we are considering malicious RS, shouldn't we also consider malicious AS?
laurens: we should indeed.
… If you have an ID token, it will be bound to the POST operation on the AS.
… The malicious AS server can not replay this ID token on another AS server.
… At least that's the threat model of Dpop.
… Still, the problem with ID token is that they contain many claims about the identity of the user, and they are not properly restricted to the target audience.
acoburn: ryey, you were talking a malicious RS sending a legitimate RP to a malicious AS
… that's a real problem
… the way I would mitigate that: rather than sending the ID token directly to the AS,
… the user controlling has a set of trusted token exchange servers
… you exchange your ID token with this trusted server for a more restricted access server, that you then send to the AS
… this protects the user even if the RS-AP pair is malicious
… in this first exchange, the iss would be your token exchange server, the aud would be the AS you have been sent to
… so it can not be reused anywhere
<Zakim> bendm, you wanted to ask about scope between interactions AS/RP, why not trust the AS?
bendm: is it necessary to do it like this in every use case?
… if I trust the AS, can I skip the first step?
laurens: I'm assuming that the RP is not the owner of the RS.
… In the case of the Flemish government, they are one and the same, so it is a simple case.
acoburn: in the use-cases we have addressed at Inrupt, it was more a federation than a distributed system
… so the notion of malicious AS is moot in this context
… there are cases where, even in a Federation, you would require this first token-exchange
… I would make it possible but not mandatory
bendm: do we really need to describe these different levels of complexity?
… what part of it is in our scope? should this be just a note?
acoburn: in my opinion, it is all out of scope, but we need to consider it.
… It would be material for a primer, a best-practices document, but out-of-scope for the protocol document.
laurens: I tend to disagree.
… the AS may provide you with a token-exchange grant, and if they do, the semantics needs to be defined
… otherwise, this is a hindrance to interop.
acoburn: I don't think we want to require anything about token-exchange,
… but I would agree that some document somewhere should explain:
… "if you are to use token-exchange, this is what you need to do"
laurens: if you are to implement an LWS client that is authenticated,
… what do you need to provide?
acoburn: how do you build interoperable clients? that's fair
laurens: currently, Solid OIDC is very simple (with security implications)
acoburn: in my mental model: you can configure your client to use a proxy server, without the client's developer being aware
… in a way this is similar here
… all the token-exchange part can be configured independently of the client
… but I agree that we need to describe it somewhere
ericP: we need to specify how a client that can do token-exchange knows where and how to use it
laurens: what we have right now is an ill-designed solution
… what we should avoid doing is throwing everything out of scope, and leave it to the implementers to discover what to use
… we should strive for interoperable ecosystems
… token-exchange is just one way to solve this problem
… yes, we need to afford for evolutions, but we should not leave it entirely unspecified
bendm: I think what you are saying is that we must specify the RP-AS interaction, which I understood was out-of-scope
laurens: I don't think we have consensus that it is out-of-scope
… the current Solid spec somehow specifies that
… if we don't specify that part, different community will chose different non-interoperable solutions
… we need some normative description of that part, maybe reusing an existing one
acoburn: I think we could define in abstract terms: "you need to provide a credential in some form, that contains this information: ..."
laurens: we are probably going to specify the identifiers of RP, and restrict the interactions between RP and AS
… the interaction between RP and AS is essentially about authentication
acoburn: maybe we should switch the discussion to authentication, then
… jeswr and I discussed during lunch, I would like to volunteer to make some proposal about what is needed here
… I would like to volunteer Dmitri as well
laurens: there are several levels to which we could specify authorization
… but specifying a policy language is probably scope for a WG in and of its own
acoburn: we have 6 months
… I think it is out of the question to invent something new
… I think it is out of the question to hack an existing solution to our needs
… we can abstractly describe what we need, allowing future specifications to be used
laurens: I think defining an API for requesting/granting/revoking access is something we *can* do
… it means a deviation from what we have in Solid right now
acoburn: there are different ways of scoping this
… one way is to specify the "box" that stands bewteen RP and AS. I think this is doable.
… and it may be swapable in the future
laurens: we could even reuse something existing here
pchampin: I think the decoupling mentioned in our charter puts all 3 edges in scope
jeswr: I'm supporting of that
… I think the LWS spec should speak abstractly of the policy graph
acoburn: there is prior art for access request (SAI, the interop group, Inrupt's implementation)
laurens: there is also something that the Verifiable Credential people are doing
… OpenID4VP
jeswr: does OpenID4VP involve an access request?
laurens: the Presentation Request is similar
jeswr: my understanding of OpenID4VP is that it is a closed flow; it does not allow for a user to intervene to consent to grant access
laurens: agreed; asynchronous access grant is something that OpenID wants to solve, and there are potential solutions to that, but that's complicated
bendm: do we also want to solve that?
laurens: they have similar use-cases to ours?
bendm: do we not run the risk of designing a competing solution, then?
laurens: they are also referring to 'Authorization details', we might try to solve some of these problems together, but as we have the same timeline, that may not be practical
<laurens5> https://
bendm: should we spend the 6 months left solving something that others will solve in 1y?
ericP: do we have reasons to believe that our use-cases are unique?
laurens: I believe that we are looking at more affordances than they do.
jeswr: my naive hypothesis is that the pre-conditions around authorizations are going to be the same, but the effects might differ.
laurens: "me requesting access to a resource you control" is not something they are trying to solve
… their use-case is "me giving access to an agent to some service over which I have some control"
bendm: we need to build something that is swapable
laurens: any protocol we define should be made in a generic way, with a concrete binding to a specific technology, similar to what we do for operations
bendm: do I understand correctly: I have my pod with my AS, and I give you access; how do we ensure that your client can interact with my AS
laurens describes some affordances in OAuth
laurens: what we want to avoid is each AS implementation inventing their own scheme
bendm: but we have existing schemes
laurens: yes but they are very generic
… e.g. token-exchange is one specific grant of OAuth2, and requires more specification to be useful
… it is not part of core OAuth2, so you need to specify "use OAuth2 + token-echange in this specific way"
photo of the flipchart: https://
{kind=link}