See also: IRC log
... let's try to agree on the server-side/client-side thing
ivan: I think we are in agreement
leonard: I think if we get rid of this one
fragment it's OK
... remove the sentence at the end of the definition of server "this is
not defined by this doc"
tzviya: why?
leonard: I don't think we've decided that as a statement yet
ivan: ok, so it's an editting change to the
doc
... all the other issues are now formally on the issue list.
... let's look at the list of issues on the tracker
<bjdmeest> https://github.com/w3c/dpub-pwp-loc/issues/3
ben: let's follow the tracker's order
ivan: these are 2 different issues
<bjdmeest> https://github.com/w3c/dpub-pwp-loc/issues/4
ivan: for me, I think that the answer is an
absolute yes
... the package and unpackaged state s/b identical in terms of the
structure
leonard: I agree, everything else is gonna
complicate things
... the only thing to remember is that ZIP is a conceptual hierearchy
ivan: right, we don't even need to know that
ben: ok closed.
ivan: that's a much less obvious thing
... pwp is not necessarily a hierarchical tree in my view
leonard: right, just like a website
ivan: we have to leave this issue open,
postpone it. then we have to look at the way a PWP processor would take
care of that
... the current desc is based on the approach that out of the locator
you get the base URL, then when you want a specific resource you
extrapolate on the base URL
... what we may have at the end is that the manifest can also include
some kind of URL mapping
leonard: I think that having hierarchy doesn't matter. A locator to a resource is just base+name, it doesn't change the implementation.
ivan: what happens if the PWP has resources that are on 2 different domains?
leonard: that has nothing to do with the
hierarchy.
... we haven't specified what the syntax looks like
... just like a website, if you want to reference things on other domain
you just use absolute URLs to another domain
ivan: ok
tzviya: perhaps we need to decide in the
PWP if we need a hierarchy, before we look at the locators. It's almost
a philosophical matter.
... we need to have that discussion at the PWP level
leonard: I agree
... can you bring it up on the mailing list?
ben: so what we agree on:
... if we have resources in other domains we need absolute URLs to these
domains
ivan: right, you have no choice
leonard: let's stick to that at the general non-implementation level
ben: ok, so we're in agreement, let's close #4
<bjdmeest> https://github.com/w3c/dpub-pwp-loc/issues/5
ivan: my personal feeling is it's none of
our business
... whether cache is used is implementation detail of the PWP processor
leonard: I agree
ben: I added that issue because we had the
question whether the PWP could be updated, but maybe that's for another
group
... we can close #5
<bjdmeest> https://github.com/w3c/dpub-pwp-loc/issues/6
<bjdmeest> https://w3c.github.io/dpub-pwp-loc/#pwp-processor
ben: about the various priorities of the
different manifests
... basically rdeltour says we shouldn't, ivan says it might be
important
ivan: there's another issue that rdeltour put on the list an hour ago about the algorithm aspect of this
<bjdmeest> \me tells tzviya: ok! :)
ivan: this algorithm is currently
incomplete unless we define the priority of things
... currently it's unpredictable
... the priority is part of the definition of the PWP Processor
... whether we do it right now or not I don't know.
leonard: right. I think it can wait until we know better what these things look like
rdeltour: I agree but IMO the algorithm cannot be define unless we make technical choices
ivan: I don't think I understand, the
algorithm can be defined precisely
... then a profile can say "if the link element is not there, then skip
this step"
... I think the abstract specification can and has to be described
rdeltour: would you agree that if we want an algorithm we need a list of all the technical solution? (link elements, link header, manifest format, etc)
ivan: we can list the options and priority
... in an abstract but very precise manner
... we are not talking about all the manifest formats, what are the
syntax, etc
... what we say is "the manifest includes all the locators, if they come
twice, here's the priority"
rdeltour: if you have a manifest in XML and JSON, as a payload to a GET request, you need to know the priority in the algorithm?
ivan: no, you just know that you get a
manifest
... there's an underlying assumption that the content is exactly the
same regardless of the syntax
... therefore if the manifest comes as a payload there's no ambiguity
leonard: even if you get it through the link header
ivan: but there you can get two different
manifests, and you have to merge them
... if I get the manifest as a direct payload, I get that only once
rdeltour: let's take a manifest linked with a link element, you can also say that it's the same manifest?
ivan: that's not what you want, these
things are not identical
... it gives the publisher 3 or 4 different ways to send information
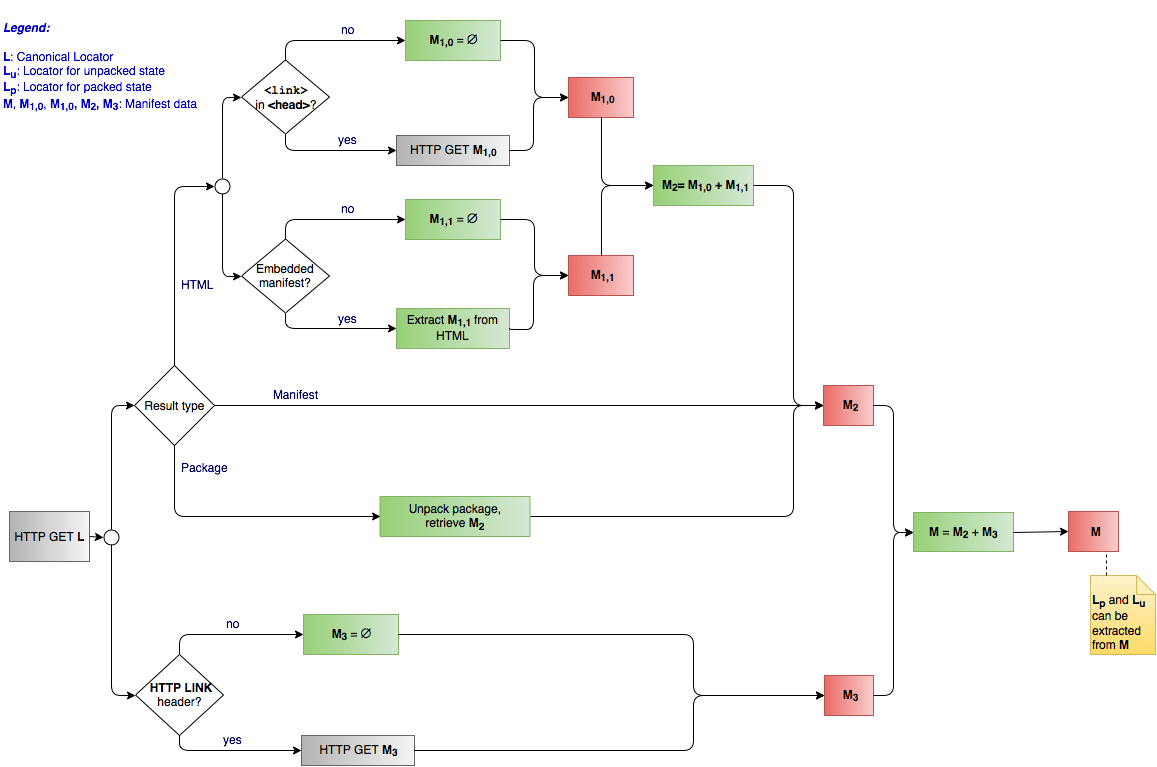
... if I refer to the diagram I made, M1 M2 M3 can potentially all be
different
<Daniel_Weck> http://w3c.github.io/dpub-pwp-loc/drafts/PWPClient3.png
<Daniel_Weck> http://w3c.github.io/dpub-pwp-loc/#fig-flow-get-l
rdeltour: OK, I better understand now. I need to think about it
ben: so we can leave this issue open and
postponed it
... it closely relates to the algorithm
ivan: we can postpone it in the sense that
we don't need to define the priority right now
... but at some point we'll need to define the priority
... in a sense this is a use case issue
... the question is: how would a publisher make use of these various
possibilities
rdeltour: we need to better identify the
abstract concepts
... currently there are 4:
... 1. manifest linked from the HTML
... 2. manifest embedded in the HTML
... 3. direct payload
... 4. linked from HTTP link header
... we have to define these explicitly in the Note's prose
ivan: for me the fact that these 4 Ms have different levels mean that they are potentially different manifests
tzviya: it sounds that lots of issues we're
talking about today are about unresolved issues in the master document
... we can solve everything for locators because we have unresolved
issues there
... ben, ivan or I need to open issues in the master doc
ivan: it's a general thing indeed, but the
way it came up is that we were looking at how to get the manifest
... and the situation that may come is
... I want to publish a doc on my web site, which may have internal
information
... but I don't have the possibility or the permissions to open the PWP
because it's packaged
... how do I add these extra info without changing the package?
... it's really a use case situation
ben: OK so let's add this as an issue on the use cases?
rdeltour: right, it's a known issue for the UC&R doc
<bjdmeest> ?q
ivan: that's a use case
<bjdmeest> https://github.com/w3c/dpub-pwp-loc/issues/7
ivan: we have know 4 different ways of
conveying a manifest
... whether there can be more or others I have no idea
ben: the document currently says that this
is not exhaustive
... we can leave it like this at the moment
ivan: right. there 4 cases are the more or less obvious ones
<bjdmeest> https://github.com/w3c/dpub-pwp-loc/issues/8
ivan: my impression is this is heading for
conneg
... whether a specific PWP implementation is smart enough is an
implementation stuff
... we agree that we do not require conneg, but we do not exclude it
either
ben: do we also need to specify what (?)
... we don't have to specify what happens for conneg, neither for client
or server side, and we can close #8
ben: I added this issue after a discussion with Leonard, but not sure I got the idea
leonard: the client has to be aware of how
smart the server is
... you'd never get a package as the result of a resource
... we haven't walked through exactly the whole process
... the process attempts to get thing, gets a 404 or other error, then
decides to get the whole packed version
ivan: we should not reinvent the standard
web mechanism
... there is quite a usual way defined by HTTP status codes
leonard: I agree.
... the only thing we may want to specify is whether there are
priorities
ivan: I'm not sure, let's see when we write down the algorithm
ben: ok, so let's keep this one open?
ivan: I think we can remain silent. but leave it open until we do more with the document.
ben: I propose to do it
ivan: I'll try to see if I can write down properly the retrieval algorithm in a more detailed way
(that's #16)
{kind=link}