
[ Slides ]
Kaz asked attendees if it's OK to (1) take pictures for workshop home pages, (2) record discussion for minutes taking and (3) copying presentations to his USB memory, and got approval.
[ Slides ]
Debbie gives a talk on the workshop and asks attendees to introduce themselves.
Everybody introduces themselves starting with Debbie.
dan: this session includes introductory papers, kurt will talk about an overview of conversational systems
[ Slides (TBD) ]
kurt: conversational systems are
bi-direction
... for example, recognition and synthesis (for example,
question and answer)
... both have common vocabulary, and therefore, may be useful
to have a common lexicon
... for example, a number of transformations may be done from a
question to an answer
... interrogative -> declarative, append 'no' as vocative,
change tense, change plurality
... simple transformations at the parse tree level, complex at
string level
... implies that conversation requires a parse tree (syntactic
or morthologic)
... need systematic morphological transformations (grammatical
feature tags)
... bi-directional and reversible, possible to compose and
decompose
... morphology is a shared resource
... several levels of processing (syntactic, morphologic,
phonologic / prosodic)
... levels should be definable, progammable and
reversible
... Standardization issues: Phonemes vs. Allophones, Standard
phoneme set, Standard parts of speech, Standard grammatical
tags
[ context and aligning system and user behavior
kim: disabled users as speech
testbed
... started using speech reco 16 years ago and was frustrating
in many ways
... the community of disabled users can provide valuable
insights into whats needed
... desktop speech interface study: 45% abandonment rate after
one year
... complaints: frustration, vocal fatigue, couldn't use in
group setting
... same issues for disabled and able users
... need consistent focus and feedback, let users anticipate a
problem and solve it, discovery, adjustment, organization and
sharing (afterthought: correcting vs. changing)
Information transfer from dialog response generation His use case is this -- that dialogue has information that should be available during speech synthesis There are many things you can give the system -- but some things you can't figure out -- speech acts, fleeing localization, semantic rules. There is currently no way for that information there is a role attribute and SSML. There is no standard interpretation of what the role attribute are. There's a structure required of it but there's no expressed interpretation of what the values are. Dialog system, speech generator. Each has its own internal categorizations. Each of these has their own classification that is appropriate for the task they do. The dialogue system is doing certain things, the speech generation system is doing certain things. The way they take about the content they have. It must be possible to provide a map between these rather than forcing either to change. His request is to not attempt to normalize categorizations or tag sets. Instead provide a map. It doesn't need to know whether it's a noun, verb or adjective, because from for prospective there all the same. Discussion: ------------ Kurt: where would you put attribute Dan: that is something the synthesizer already knows how to use -- a particular engine knows what it cares about. A dialog system does what it cares about. What's important is the categorization for the dialogue system needs to be made known in a standard. The TTS system may sit out. There needs to be a mapping language. You then have the complete path from the dialogue system to the speech generation system without forcing either one to change the way it thinks about the information has to process. David: the map is not bidirectional in this case Dan: I believe the way he presents it is that one direction because it's the speech generation. You could conceive of this concept being used in the other direction as well -- maybe. But that's beyond my ability to speculate. Jerry: attribute is assigned to each one for each utterance because granularity Dan: I think you go on the token level Paolo: permission given to the lexicon -- can play other roles of the SSML. For prosody Dan: there is no requirement that it be tied to lexicon Dan: perhaps it needs to be expanded -- if it can be applied to a larger section of the attribute and not just the Tokien they could have a larger use:
[ Paper, Slides (TBD) ]
need for morphology current system doesn't allow us to relate those words even though there's an obvious relationship between the two we need a higher level of abstraction -- a way that we can tokenize words much more powerful for applications because they can work on a higher more abstract level perhaps closer to a semantic level group that those tags mostly for European some plurality in terms of morphology, and some languages and not other languages. The great thing about using tags is we let the engine render it, however that language expresses it Concorde: ---------- if we do that we can automatically get defined in the parse tree three components on the lexical level for morphology morphology engine carries out in implements morphology formalism is grammar that represents morphology we need to think along the terms of handling each of these Lexicon contents: ------------------ Parts of Speech -- noun versus verb and usage irregular or irregular, how does it formats plural sometimes there are multiple ways of forming plurality it's complicated -- I don't want to oversimplify it but we can do a lot in that area Parts of Speech: ----------------- very important for computational reasons that we have no more than 15 Parts of Speech Grammatical features: --------------------- P: does the language included Asian language or Indian languages Kurt: it does include many languages. There are complications. Prepositions exist in some languages, others post positional. These terms are broader than the label may represent -- there are more complications. Chronicle feature tags ----------------------- Japanese is very different in terms of plurality and specificity we need to have feature sets that are appropriate we need to represent the values of family in different languages -- English plural or not plural. Arabic three values because there's the dual. Similarly transitivity is expressed differently in different languages. There's a lot we can do with that Phonemes --------- Google -- mixed British English phoneme set is different than American set it's a mess we need standards Slappy Formalisms Have to be reversible. It is possible to use totally and create reversible -- computationally feasible we could consider summary: slide we need to standardize Discussion: ------------ Simona: the need for morphological tags. They semantic tags, but I still be the morphology tags? I would say no Kurt: internally in the lexicon you're going to need to know that this is a verb and Parts of Speech for other reasons. David: could you elaborate more on the internationalization. You are stating that somehow we can create a way of coming across languages easier if these constructs are there. I'm not sure that I see the ROI that much. How much help is a provide -- what sort of problem does it address? Kurt: mobile applications developers are our primary target. These are small teams of people. They don't have a whole to invest so they can port to 12 languages. How are these folks went to create mobile applications that work across the space. The ROI issues if you can create this game in such a way that makes it easy to port these applications now you can have thousands of application developers porting to images were otherwise you only have a handful -- maybe it doesn't that actually ported to 20 language. Raj: Kurt: if the morphology is written once -- a company like look window or nuance written for French, the application developer doesn't have to redo, use the shared resource. We just have to agree on what that standard is. It minimizes the work because it makes reusability on the morphology prosodic level. Even semantic. If we can make these components reusable and I think the ROI is there that we can make this economically feasible or currently it's not for most small teams. David: I'm not questioning the value but application development most time is spent at least in the speech part of it on right of the grammar, designing the dialogue and a lot of those things. I'm just trying to see how these lower-level important key connections would map themselves into the higher-level. I'm not questioning that cannot be done, just trying to push to see how it can be done. Paolo: not so detailed that you don't need more -- to pronounce certain words the way you want them pronounced -- is there a gap? That is why we were ambiguous at the time. Kurt: why we need the phonetic and a. If you don't have phonemes representing you can write rules, you can only represent on the phoneme level. Paolo: I suspect they would say we need more Kurt: internally change the phoneme to allophones before rendered it if not you have to reverse it and figure out what the phonemes are Kurt: there's no way in the world that developers can work on the allophonic level -- way too confusing David: it should never sharpen the higher-level -- question is why does it show up on the higher-level. The assumption is speech recognition has a role to take the speech and gives you a sequence of words. Now you have to work on the meaning -- all kinds of other. Why do you need the phonemes Kurt: someone has to write the rules for prosody and phrenology because they interact with morphology. I'm analyzing prosody as well -- you need to figure out where the focus is, what the reflection is -- you need to be able to get these tags so that you can process them and know what someone said. David: we have always said that the small bit of information. I'm not saying there's no value to it but we've are restated as so little information -- in the past we have ignored it in the future, well. Paolo: use cases behind this description. It would be nice at that level to just semantics Kurt: if you create a lexicon and events a speech engine they should be able to work together. Different languages -- Swedish. We need to agree on what those phonemes are. David: phonemic -- especially when you talk about the use of technology for. If you decode it as a given word thereby to remove the value of the human brain that can actually look the phonetic sequence and say I understand this word where the speech recognition can't. A scenario that's useful for very limited vocabulary.Debbie: Debbie: standards process. I had a list of things where -- general categories of use cases. possible to do now. Things are very difficult to do now. Things that can be done now but not in the standard way. Things that can be done now but are not very efficient. Taking larger space -- not more than 15 characters because of space efficiency. I wanted to bring that out is another type of use case. Very interesting to distinguish between what our parts, for example the motion -- names of the motion, but there are many different vocabularies describing. They can agree there needs to be that vocabulary, but they have to think about different ways to accommodate different sets of emotions. It might be easy to agree that part of speech itself is useful. To distinguish between needing a feature and agreeing on different value of that feature Paolo: agree. The point is who wants to do that. David: comment to what you said -- standardizing features but not being able to standardize on the value. How has the W3C up to now dealt with this issue Debbie: lots of different ways. Example, future like emotion vocabulary = URL that points to someone else's vocabulary. If you can agree in a few features you put this in and say it's extensible -- you can add your own. Other things have been tried. Paolo: Registry -- needs a community behind the registry Dan: IETF, example media types. They allow a media type -- specified process that you go through in order to get a new media type registered. Whether it's text, MPEG format etc. there is a way to get it defined. Its planned extensibility -- planned, somewhat extensive. It's new for W3C, but it's something we are doing or will be doing. Debbie: it's a good way you can make progress without putting off the whole problem. It doesn't solve the complete problem but at least it moves you forward. David: this is a real issue. Because the developers you want to be able to try everything. You need extensibility at the ultimate. Then deployment some kind of standard form would be valuable. Kaz: SSML 1.1 strongly discussed that kind of extension -- registry. Dan: W3C does not like the x-* style because it is not standard. Usually that means put whatever you want there's no standard for this, which is useful. You want to use the standard, but you want to use a format that either is proprietary -- okay because you're using within your own organization anyway. Provides a way for that. But the registry is the next level. Here's this thing, I want other people to know about this so they can use it. Dan: use case representing Paul there is information that the dialogue system could be used to produce better spoken output access to that the speech synthesizer cannot determine on its own using current text standards. And there should be a way for that information to be passed on. Kurt: why couldn't you specifically tag that -- doesn't matter what it means as long as you tag it prosidy Dan: just a use case -- no solution There is knowledge being lost it seems to me that that way of passing information requires customization -- that information will be interpreted differently for every TTS engine. And it will actually require either the dialogue system or the TTS engine to understand the other one. So this format -- we can use the role attribute, what information goes in there? If it's something generated by the dialogue system than the TTS engine needs to understand. There is no way to do that using the system -- whatever parses SSML or whatever parses. There has to be a contact established between the two about what the meaning of that is -- that will require some customization on the part of one or the other of those components. David: I think we are ignoring the role of the technologist. As a TTS person -- it's fine statement that you're making that how much of the internal formation of the dialogue system Dan: talking about role, there is no way for this information to be passed that does not require an explicit contract to be established between those two components -- the dialogue system or the TTS system which will require one or the other of them to make changes in what it does. David's question -- there is a use case that I want to make sure gets captured. From the paper: Discourse information and information related to word disambiguation. David: some thinking about the problem -- there's this one that produces lots of information and there's this one that depending on the design could use all of it are some of it -- we don't know. That seems an obvious statement -- if this group decides there is a way of making it available -- it looks like an extensible methodology so put it there and if I'm an engine person I use it or don't use it. It's not clear to me that it requires both sides to agree. I guess the dialogue side can describe. Dan: the TTS system cares about the form of the word, the dialogue system cares about the function. So if the dialogue system says I have all this great information about the function of this word the TTS system will look at that and say that's nice but all I care about is the form of the word that the function. So I want you to give me the form of the word. By doing that you are requiring the dialogue system that only cares about the function of the word to care about the form. Or you enhance the TTS system so it understands how to map function into form. The category is what he propose which is a standardize way to create a mapping between function and form -- that doesn't exist today. David that is the conclusion I was arriving at -- that's the piece that's missing. Dan: for maximum operability among compliments you can't require anyone to understand the others format. Raj: which one is he seeking -- standards, interpretation and a standard way, a way to pass that information on -- what is the mechanism that needs to be standardized. Which aspect? Dan: there may already be a mechanism for passing the information. Raj: with prosody information tags you could already today make it understood. Dan: what system captures Raj: prosody Dan: key is whether you're going to require the dialogue system to generate that war whether there is a way for the dialogue system or the person is using to create a second mapping that does that for you so the dialogue system does not have to be responsible for the presiding information for the TTS engine. David: a little more complicated. Dialogue -- all these functional tags as output. Speaking different languages. So you need a map. But you might want to argue that an engine needs to be there which takes input and that's it to the output. Standard at the interfaces. Right now it's happening -- each vendor is doing a little bit of that mapping right now. Dan: it may not be simple -- it may be code that needs to do this mapping and because of the nature. Paul thinks we won't agree on how to draw those boundaries, because linguists don't agree. The issue is the interface.
[ Paper, Slides (TBD) ]
kurt: want to address mobile
market
... different requirements, multiple apps, should have only one
ASR to service multiple apps
... want info from one app to be available to other apps, e.g,
antecedents for reference resolution
... use case: routing speech input to the right app?
... if user is talking to device
... traditional approach is to explicitly say what app you
want, users won't accept this, so there should be a shared
environment with a shared syntactic grammar
... need comprehensive grammar to do syntactic analysis, then
semantic routing to identify which app is being used
... need to decouple grammar and vocabulary so that grammar can
be scalable
... CFG's are not adequate for NL, no concord
... need agreement, features and inheritance
... need grammar, dynamic vocabulary, ... (see slides)
paolo: mixing dictation and
grammar, context sensitive grammars
... use cases -- context-sensitive grammars,long distance
dependencies, boolean constraints on semantics, enable and
disable branches of grammar, mix DTMF and speech in the same
input
... more natural language kinds of things, e.g. partial
results, pass results on to other levels of analysis
... integration with other standards, IANA language registry,
EMMA, metadata like age, gender, emotion, SNR
kurt: what about ISO639-3 language codes?
paolo: IANA does include updated
language codes
... will check
[ Paper, Slides (TBD) ]
kurt: conversational semantic
standards
... need for routing to support unified front end to all
applications
... should be language-independent
... need semantic standard, rich, language-independent,
inferenceable
...closed-class complete
... open-class extensible
... verbal valency
debbie: seems to be a specific solution
michael: there's a lot of syntax in this semantic representation
kurt: (gives Interling
example)
... rich semantics enables proper representatation of NL,
reduces complexity, allows language-independence
dan: need use cases, not sure
what they are
... from syntax paper, I have multiple speech apps running
concurrently on a device
kurt: must be reversible
david: need to specify "use case
for what", e.g. want a developer to be able to develop apps in
multiple languages or port applications
... automatic would be great, but simplifying is good, too
simona: value of abstracting
semantics from rendering, e.g. for multimodal rendering, but
this use case is very tied to language
... will propose more abstract semantics that's not tied to
language
dan: hard to get a standard adopted that covers everything
kurt: no way to implement English auxiliary system in a generalized way
dan: this ties back to multiple speech apps running concurrently use case
paolo: the point is what do you want to do with SRGS, it wasn't meant to be a general grammar formalism, but just a way to constrain recognizer
kurt: now we want to get a parse tree, so why shouldn't we just have one grammar
paolo: SRGS has a logical parse
structure that could be exposed
... we should abstract from the solution, because there might
be multiple solutions
simona: as soon as you're going after rich semantics you're looking at natural language applications, no causal linking between SRGS and another grammar formalism
kurt: could come up with falsely constrained recognition
paolo: actual speech isn't like a grammar of formal English
david: whatever you introduce as
a formal construct you should have a statistical layer to make
the system robust
... whenever we introduce complexity, you have to ask the
question of the ROI
... you have to show the value, we all agree that we can make
things more complex
michael: layers we're talking about here are collapsed in ngram models. you're getting syntax, semantics, and pragmatics all at once from the annotator
dan: thinks paolo/debbie's use case is to use technology improvements
paolo: no standards for SLM
debbie: we used to think that some technologies were impossible that now might be reasonable because of changes in computational efficiency
kim: support for low tech
examples, support for user choice is low-tech but extremely
useful
... MIT Common Sense database, e.g. "bark" near a tree probably
not talking about a dog, common-sense facts, some studies
improved speech with common sense but improved perception of
speech was even more
... multiple application use case -- clients with CP would like
to control entire device with speech, people would like to
control device with speech as well as applications
david: should consider anything
that can improve conversational applications, not just
technology
... can use other things, like common sense, technology,
simona: would this workshop define standard commands for doing things
paolo: ETSI did that for defining simple commands
david: those standards only
happen over a long period of time
... as behavior is adopted by people over time
paolo: the accessibility group could promote guidelines for the speech interface
simona: running multiple apps would benefit from standard commands
kim: could come up with a default
and allow people to change it
... different users have different requirements
dan: paolo's second use case is to update SRGS to integrate better with new specifications
david: too many use cases, what
is missing in the language to support use cases?
... we need to list what is missing to support these
things
... should be able to point to an implementation and say where
the limitations are
dan: e.g. Chinese people added "tone" element in SSML
michael: use case for interspersing DTMF, could make that more general by saying that you could intersperse multiple modalities
Simona: Challenge to find Use
Cases
... Motivation behind, shift change in application from
traditionally
... directed prompt single-slot: create frustration
... beyond call routing applications
... Future is address complex problems and succesfull integrate
other modalities
... Examples: What's my first meeting with Peter?
... negotiation: I want to Montreal sometime tomorrw to be back
at 6pm
... Problem solving (slide 3)
... dynamic call flow, multi-turn decision logic.
... Deep NLU (slide 4)
... ASR SRGS insufficient need generic language model
... I don't want traditonal NLU
... riche semantic representation beyond slot-value pair
... example: quantifier
... example: relation / frames
(tomorrw but before .. after ..)
... standard ontologies / knowledge-bases
... E.g. apple has a standard commonly knowledge bases
... Multimodality (slide 5)
... EMMA: can't wait it to be a requirement
... abstract semantics: independent modality, work with common
concepts
... e.g. don't care modality, I just need a concept
... Abstract funcionality: independent modality can we define a
limited common I/O
... Multi-source input:
speech/text/touch/history(conversation,appplication,user
profile, ...)
... Multi source of confidence to be combined
... Complexity (slide 6)
... Maximise re-use: ontoloigies, VXML, grammars
... R&D agility (slide 7)
... easy to vehiculate vendor-specific information
... need to experiment and hack if not present in standard
<claps>
Dan: Mention competition with SmartPhones
Simona: you touch, speech is not needed
Michael: If you function of speech is to select, type few character and restrict
simona: Voice and language has competition more
kurt: Express desire of ontology, something in mind
simona: in another startup, built
on top of wordnet
... have these resources general available
[ Paper ]
raj: not legal clearance to speak
on details
... describe the application context. Broker solutions
... company merging and remerging.
... Normal grammar were not adequate, we need portable SLMs
across vendors
... Second requirements: Programmatically assign weight, but
spec is deliberately ambiguous
... we need to have a programmatically way to assign
weights
... It is very difficult for us to manage that
... especially in mobile, where the speed is important
... There could be other way, but weights will be fine
<ddahl> the paper that paolo and I gave talked about assigning weights to regions, but I think Raj is talking about assigning weights to specific words as well
raj: Reqs: Enabling and disabling
grammar
... based on the context disable certain grammars to increase
accuracy
... Reqs: intermediate results will be very nice, to start
showing while coming.
... Last point: personalization
... It could be that the choice of personal to global address
book. This is personalization.
... Have it louder.
... Acoustic profile, based on that we will change the
parameters.
... Looked around, difficult move from vendor to vendor.
... Combine speech to DTMF, it can be another media stream, not
just combine DTMF
... Give application developer perspectives to help apply
technology in different contexts.
<claps>
David: Features on multiple devices or not
raj: multiple engines
Dan: You give volume as an
example
... In VoiceXML 3.0 ...
raj: It is not here today.
dan: Got it.
kurt: Multiple applications, how you deal input?
raj: We identify all the
applications (news readaer, etc)
... Depending on what applications are active, there is a
policy to keep active
... It will activate grammar, but we might be wrong
... Promotion of grammar, pluggabilities, these days are
configurations
... There are thing you can keep active ...
kurt: can you extend no, of applications?
raj: You can but it is not guarantee.
kurt: Sharing across apps
raj: No
Chiori: NICT is born in 2006
from ATR speech group
... 25 years of speech translation (9 speech to speech)
... Target is travel domain
... Collect speech data, annotate tags,
... Goals of SDS
... accept spotaneous speech and mimic dialog behaviour
... Corpus-based dialog management
... Our is a general approach statistical
... Scenario WFST
... Origin destination FST
... Sytem navigate and asks confirmation and questions
... Spoken Language Understanding side
... Very simple word-class for word Kyoto and Tokyo, and origin
destination
... Construct Hum-Hum dialog using to contruct WFST
... combine two WFST together
... for spontaneous speech we can combine two oner for speech
input and then speech to concept
... see the context, the slot filling
... Problems:
... 1. We need Context Sensitive ASR, change SLM time to
time
... 2. Separation of ASR and NLU
... add weights, label semantic annotation on ASR result,
weight for state
... 3. SLU using WFST
<claps>
michael: Not just model precompiled, but dynamic change of the model
chiori: Yes everything has state
simona: can go in the VXML
chiori: you will use SLM
michael: related to that,
existing SRGS, in a particulare entity is relevant
... as it stands you can have rules that can change
paolo: syntactically you can but engine might not support
simona: agrees
paolo: to simona, need higher VXML dialog communicate a state to change slm
simona: yes
kaz: is it implemented?
<kaz> [ actually, I asked more specifically about whether this is not only a research prototype but an actual product/service or not ]
chiori: there are implementation
on iPhone for state-based, we want to go to spontaneous
... Should any SLM be incorporated in WFST
simona: can explode?
chiori: It can be handled,
recognizes 2.000.000 words
... robust, but users can break shifting the topics
paolo: Chiori suggest there is need of a standard SLM language to be able to exchange
michael: <nods>
... Portable SLM, another pieces is another approach to
dialog
... it might difficult to agree, but we might think a correct
interface damong different approaches
simona: targeted to slm
michael: either one
david: you have an idea?
michael: No but it is interesting
to discuss
... problem of shift of topic, a lot of weight to respond
question, but more is possible.
chiori: In our case we use back-off, unigram
paolo: n-gram on dialog states?
chiori: yes, we need an history
of dialog to model it
... User can input, but the system never ask the same
question
... simple but effective strategy
david: what are the use cases?
kim: I think raj was talking of
control, people frustrated want use the comments either
application specific
... nice to have user control have control on grammar
michael: I can see that, support
many appls and system keep answering in wrong context
... you can switch off
dan: turn off navigation when you are close home, then on highway you need
kurt: try to track what user will know to avoid repeating.
michael: it is interesting idea to people give commands to activate or deactivate
david: Problem solver, question is: what aspect cannot be implemented with existing standard
simona: complexity of the state,
miss all the possible states and strategies
... description of the states, ..., all combinations SCXML can
put in parallel
... but can be more complex and not able to represent in state
chart
dan: you can implement your strategy
simona: I'll use Java
david: do we need a new language or extension of some?
simona: Trivial VXML to play and recognize, then all the interface is on the server
david: Anything that is not directed dialog, VXML becomes in an interface
simona: my point was that I don't
think we know how ...
... can I use SCXML? No I can't
david: My problem is that I cannot fill the gap of standard and implementation
dan: We are aware of it in W3C.
Even V3 makes easier the state based dialog, but even the
transition controller
... only language that we have is SCXML. We might not require
to use it.
... You might list in VXML your information, it is still
outside.
simona: Why should I split it?
dan: If it can help for high
level understanding, allow for transition controllers do in a
generic way people might use it.
... Whether it will be sophisticated I don't know.
... About gap, there is a big gap to drove state, there is a
big gap of rule-based. What I hear that there is desire
... that you won't manually manage individual states.
david: states?
dan: Practically speaking the state is where the grammar are the same.
david: coming back to problem of
Simona, I see following passes. We benefit separating
complexity of dialog and understanding.
... I think of problem solving, I can't even think about a
direct dialog implementation of figuring out the problem
solving.
... IT help desk no context, go in the whole exercise to
extract info to people who has no idea.
... Today this is a huge exercise to turn it in standards.
dan: VoiceXML 3 always start from
dialog flow presentation framework. It is the view. Not complex
problem solving.
... It is there to speak and listening. There might be more
ways.
... That separation might be appropriate: dialog (back and
forth), application in generative (world knowledge)
... The last is where we have no standard at all.
david: There is a third piece: in a given node, I want to be able to address multiple slots at the same time.
paolo: a sort of, can return several slots and fill different fields
david: each intention has more information and intent.Is it allowed
simona: the same question I put
in meaning representation: independent slots with
predicates.
... this is not possible today
michael: EMMA is only the container
dan: You can represent words, not support
debbie: multi intent utterance, I
see EMMA very nested. You could represent them in EMMA, e.g.
tree structure.
... The problem is how to unpack it in VXML
michael: there is a problem of correlating data
david: that is dialog part
... My experience that when we try it, we jump out VXML
michael: There is a higher level:
bottom line level is dialog in any point I can give one piece
of information,
... second you specify several at once, next level (multi
intent) series of separate intentions
simona: question of complex sematics goes beyond to the multi intention
dan: current standards we are
mixing several things
... standards offer on input: how system can know what people
say, currently are CFG grammars,
... if you can represent complex grammar and then map results
to meaning in ECMA, here there is
... an interesting question on what happen next, which entity
decides what happen next
... It is likely not your VXML code. It has to extract meaning
and precess them, these are submitted to a server
... to process and say something else. Very lilttle computation
is done in VXML.
david: this is dialog
michael: One are capabilities of
dialog system, another is having more sophistication within the
way you represent semantic intent
... disjunctions (no sushi today), another one is the ability
to maintain multiple hypotheses from
... recognition and understanding (if said X or Y, and then
must be Y)
... Can we create a system able to go back?
david: I'd like to restate the
challenge: when we build direct dialog we enforce simplicity
and clarity and we find way
... to do repairs. When you start to allow multiple slots, then
the process becomes very complex.
... It becomes a difficulty of application design, but I still
think that we come to multiple intent/slots, the standard
... grammar we have it is not sufficient. At least in our
experience, grammar combines, how to assemble things
together,..
simona: I'm not sure that it is easily handle, and I'm not sure we can represent the output.
dan: This is EMMA. Can an author effectively describe the language model to do the capturing the semantic information
simona: s there a powerful way to represent it.
david: This is our experience in last few years applications.
dan: This two questions are coming to the use cases.
simona: let's take a complex
sentence:
... e.g. " Can I leave today in the afternoon or tomorrow
morning, and arrive before 3 pm?"
michael: Part of your grammar to
recognize citynames, you can use SRGS, for multiple you go to
SLM, then multiintent who know?
... Dealing with utterance with complex semantics there are not
good models
simona: there are three levels
dan: Is not representable in EMMA?
michael: that is how to represent
it in XML, not EMMA.
... maybe how broke SRGS will become.
simona: yes
debbie: EMMA might provide more guidelines on how to represent.
dan: If it is XML it will be transported.
michael: There is not construct to represent ambiguities
dan: We will need to come back to this and find the use cases
<kaz> david: we need to clarify: scenario -> implementation -> issue
david: I was not aware of what to expect. Also the presenters themselves should clarify use cases because they know about their idea best
dan: proposal to find more time to think on use cases
david: four question presenters
express
... 1. Use scenarios
... 2. This is my implementation
... 3. What standard I used or failed (limitation of
standards)
... 4. Recommendations on extend standards
... Suggest in Section6 take one scenario and do 1/2/3/4
<kaz> [ afternoon break ]
[ Paper, Slides (TBD) ]
kurt: When I talk about
architecture here, I'm not referring to whether it's in the
cloud or on device, etc.
... Single sentence means a sentence that applies to multiple
applications
... Developers won't be able to develop this level of
applications, so semantics are required
Each of the levels of engines pass information between them. Inferencing level passes meaning representation. Syntactic to morphologic would be a parse tree. And Morphologic to prosodic would require some transfer too.
David: What do you mean by multiple applications?
Are they just there or are they spawned?
kurt: I mean they are concurrently active. Probably an agent listening to the entire conversation, which then invokes the right one. The agent would have to listen to everything though and convey the semantics to the next step.
Simona; The agent would become huge, having to track everything plus history, etc., though
kurt: I don't know how else to do it.
Simona: How about each app keeps track of it's own needs?
David: We'll come back to this during the question section.
Rahul is next with "Beyond the Form Interpretation Algorithm"
rahul: Browser based, markup driven multimodal applications reusing existing Web developer paradigms.
VoiceXML 2.1 had the FIA, but any complicated control of the dialog probably required dynamic generation on the server side and not in VoiceXML.
VoiceXML 3 requires richer dialog management within the browser itself, in combination with other modalities, and to try to align the voice and visual webs.
rahul: Some simple use cases:
Visit form items in reverse document order -- FIA can't handle it
XHTML + VoiceXML
using just native VoiceXML 3.0 constructs and eventing.
rahul: The basis for the richer dialog management is recursive MVC or as we sometimes call it DFP.
We have transition controllers which exist at multiple levels of dialog granularity that provides localized control over transitions.
We use DOM events as the glue. This gives us well defined integrations as well as application level integrations.
[[example of a TC written in SCXML within a v3 form using DOM events to transition to another state ]]
[[ compound document example that mixes XHTML and VoiceXML using DOM events as glue ]]
David: Opening for questions now.
Michael: This multiple application sentence bits can be looked at in a few ways: you're interacting with many applications, or you're interacting with just one.
kurt: Nothing in my presentation
was about this agent, I was just talking about how I might
implement it based on a question.
... You don't know necessarily what you're going to be facing
as the 'agent' in this scenario, you are going to be loading
things dynamically.
Michael: That's one way you could do it, or each application could have it's own grammar that's for that app, and then there's a meta level that handles data exchange with each application.
kurt: The complexity comes from
tracking the conversation. We have to keep track of what was
said. These rules are language specific.
... The only way I know how this would work would be a rich
lexicon.
Simona: So what if we had a
requirement on each application that they each had a mode,
where they didn't act on input, but that they return a score
about how relevant parts of the utterance are. Then there'd be
agent based AI programming that decides which bits go
where.
... All applications are running all the time, with each one
maintaining it's own history.
David: You've suggested a
solution, but I want to clear up the problem.
... It looks like each application has business logic, some
data, a grammar/dialog/interface for the upper layer/agent,
then there's a global application layer on top.
... The fact that the application layer goes and calls the
interface on the telephone @@.
... It's similar to call routing.
... Looking at it that way, where is the problem? Why can't you
do it with current standards?
kurt: Each of the apps are written by different companies.
David: But what about them is written by a different company?
kurt: Yes.
David: Then this is the tricky part. If I'm at the top, I almost have to import the grammars of each.
Simona: No! If you have to do that you're doomed. We don't have a standard currently that has a "read this input, tell me what you can handle".
David: I understand, but there are complexities. If we can abstract it out, the problem is that "grammars exist, you're having difficulties seeing inside and then you want a layer on top that has to make them work in unison" -- that's the problem.
burn: The assumption is that the higher level agent can do this for any set of apps.
kurt: They're all written for English say, and now there are three parts that have to be aggregated.
David: Kurt's case is not dynamic, his is twelve apps that he knows about.
Kurt: We have to aggregate the vocabularies of each app at load time.
The grammars should be derived from the same grammar. Say, a master grammar of English that each sub-grammar is derived from.
(Also a dynamic lexicon at load time too.)
Then there's the dynamic routing.
I'm assuming one recognizer running, not 12.
Kim: Example?
kurt: "Hold my calls while I am at the restaurant?"
burn: What do you envision having to be done to add "hold my calls, except for my wife"?
matt: Was it clear to everyone that the example means "Hold my calls" goes to the phone and "at the restaurant" talks to say, the GPS app?
kim: Yes.
Michael: This seems like a very difficult/impossible problem to solve.
David: You almost need to have
something like SOA that describes to the outside world
information about it's behavior.
... Now once you have this information available, can you
imagine being able to snap all of this together?
... Without the first part, the knowledge about the
application, this can't be done. After that, to make it
dynamic, to reconfigure itself, that's a very hard problem.
Raj: Let's make it less nebulous.
Let's use a limited example.
... What we do is each app defines a top level grammar, not
everything. That grammar gets promoted to the top level at
different times.
... Otherwise it's NP hard.
Kurt: No, it's not, we are doing it.
David: I don't know how you touch
that for dialogs.
... I think Raj is saying you know what you're starting with,
and that's fine.
burn: If the agent is written with a mechanism to say "the agent will only talk to these 12 apps" that's different.
Raj: So, make it generic. Say, you add another app, it could be plugged in.
kurt: Dan asked if I'm talking about a generic framework for any app. I am saying yes, as long as the grammar is a subset of the master grammar and the @@ is a subset of the lexicon.
David: How do you do that? That says you know the union.
burn: He has stated that his universe is all of English.
kurt: No, but a large subset, that's fairly comprehensive.
David: I want to talk about two
scenarios: what it is and how complex.
... Let's set difficulty aside and clearly define the
problem.
kurt: The problem isn't 12 vs 200 node grammar, but whether the grammar is reversible and @@. Right now SRGS isn't sufficient as it doesn't allow me to do inversion, it's got hardcoded ?? in it, etc.
ddahl: In the scenario, let's talk about this: everything is configured, etc, an utterance comes in, what is given to the apps to do their job?
kurt: all register themselves at
startup, then there's a merged grammar that has been
dynamically configured, but other than that it's just an
ordinary grammar.
... Once the parse is done, I've got a parse tree.
ddahl: Before any app works, we already have a parse tree.
paolo: How general is the grammar?
kurt: I don't want an over generative grammar. I want tags that let me say things like: I only want a transitive verb, or a noun, etc. That makes the universe much smaller and a much more tractable problem.
ddahl; So, once you have a parse tree what happens?
kurt: You take the parse tree, transform it step by step and convert it into Interling.
ddahl: This happens before the apps are working?
kurt: Correct.
... I have a comprehensive grammar for English, then a
translation grammar that translates the parse tree to
Interling. Then I have semantics for determining routing.
burn: Where do the semantics for routing come from?
Kurt: The apps tell me.
Simona: Based on score?
Kurt: No, logical.
David: I'm back a few steps.
Someone says something. The ASR comes up with the "top end
text".
... Just to do that, are you saying any intelligence is going
to be applied to this level to the recognizer as to what the
scope is? 2 or 3 apps active or you just have a huge grammar or
language model that you've built and the recognizer is on it's
own to give you the text?
kurt: It's not huge, it's kind of
small actually. The great thing is that we can hone our grammar
because we can have tags and the formalism for this means it's
not overgenerative.
... If we have a formalism that allows us to write
comprehensive grammar. I need a start mechanism, tags,
etc.
... The only reason I am not using SRGS, is because I don't
have those things.
David: If we're talking text, what would your issues be?
kurt: If I did it, I couldn't run against SRGS.
burn: He doesn't expect any restraints. Effectively you "or" those grammars together.
David: For the reco part, the
union of the grammars are put in there and the ASR goes to work
and gives you 1 or the n-best.
... The reco isn't the issue.
kurt: I can do the unionization, I just need a better formalism.
Michael: On one hand we're
talking about multiple apps, but on another we're talking about
more complex speech, handling @@ and ellipses, etc.
... I've never seen that done well within a single domain, much
less over more than one.
... Being able to do that, then also adding being able to add a
dynamic app in, I can't imagine it's done.
... For instance Siri, it fuses many apps. Tries to juggle
between a few apps. There's a little anaphora. Imagine that
app, if all the underlying things are under that.
David: Siri is in VoiceXML?
Simona: No, no no...
... Siri builds all it's own building blocks. Making it then
work for any arbitrary speech app.
kurt: But we're doing that now, we're forcing people to use SRGS, we can improve it.
burn: I can see for combinations,
that we have multiple grammars or-ed together.
... But your example was overlapping bits of grammars. Neither
of the or-ed grammars would match.
kurt: Exactly, that's my point.
That's why you can't leave it up to the apps themselves to
write their own grammars.
... Yet, they've got all the functionality to implement it.
Michael: In terms of standardization, I'd like to see some existence proofs to better understand how they might interoperate. Those individual pieces are not there yet.
David: That's why I jumped on
Siri, that's the lowest denominator of the things we've
discussed. Setting aside the quality, from the standard point
of view, that's a good example to figure out what standards
they could have used, what was missing etc.
... Anything else takes it to the next level of complexity.
David; If I'm designing an application that has to do with time, and someone else is doing an app that has something to do with time, then how do you resolve that conflict?
kurt: Those are all post-parse problems, those are complex, but I'd like us to have a formalism that allows us to parse.
Simona: Another example: deep NLU
cannot only be done by parsing your text. You need prior
probabilities, data, profile, in order to chose amongst all the
possible parses, which may be full or partial to chose which is
appropriate given context, etc.
... I can't make the decision purely on the parse tree.
... I'll parse it, match it with my data and then decide.
kurt: But you wouldn't parse it?
Simona: Yes, but even the parse could be biased by the data.
David: I think the area of the
problem you're proposing is real, and going to become more and
more real as deployment happens.
... The problem is real, and it has many layers of
complexity.
... Based on this feedback, maybe you could make it more
concrete in different layers.
matt: I think he's suggesting that we start with the parse formalism, right?
kurt: Yes.
David: But the pushback then is how does it fit in the bigger picture.
burn: You've said it's or-ing them together, and then you've said it's not just that.
kurt: If they're both derivative of the master grammar, then it works.
Michael: You might want it such that the lexicons can be unioned together.
kurt: We could do it with SRGS, but it doesn't handle dynamic stuff and scalable.
David: Is it clear that this statement that SRGS isn't dynamic?
burn: Dynamic and scalable, I don't know what those words mean within the context of SRGS.
Michael: If we want to dig into
it, we should separate between grammatical categories for
example. SRGS is a formalism for writing rules and expressing
things about sequences. There's nothing in there dictating rule
names.
... It is the case that the things Kurt would want to do is
capture agreement on those. The only way to do that in SRGS is
to extend the atomic names of rules. @@
kurt: 15 rules.
Michael: If you wanted to
distinguish between say, singular and plural nouns, then you'd
have to have a grammar with n singular nouns listed and then n
plural nouns listed, etc. I don't think you'll ever get
anywhere trying to define the categories in a universal
way.
... That would involve, even in the world of rule based
grammars, to get people to agree and accept.
... I think we could define in SRGS a mechanism beyond atomic
categories into more complex categories.
David: I think Kurt's problem is
real, but I think most of us feel the problem is complex and
difficult. I would ask that you figure out how to remove many
layers of complexity.
... I would need it to be a lot more specific in order to see
the real problem we are talking about.
... Capture a simple example and address it tomorrow in a
track.
kurt: I'm glad to do that and
I'll have it ready for tomorrow.
... To be clear, we're talking about extensions to the semantic
formalism.
David: Yes, but make sure it doesn't bring in telling application developers to conform for instance. Make a lot of assumptions, you are Siri for instance, putting together four applications, what has to be done, what extensions, what new languages have to be introduced?
burn: Better, just two.
David: Regarding Rahul, I don't see the scenario.
What is the new scenario that would require a change?
Rahul: Primarily in the way
VoiceXML does two things:
... It's approach to the order in which presentation elements
manifest themselves (at any granularity). What is the component
that is controlling that layer?
... The second part is the cases where you want to use some of
the "events" out of speech modality in other modalities, and
use them in meaningful ways in other modalities, then you need
an eventing model that other modalities can listen to.
burn: Why do we need a component?
David: Isn't the answer the browser?
rahul: At the programming model
level, how do you describe it? Dialog manager is this nebulous
term. There is some level of intelligence being used for what
information you want to collect. There's no reason that logic
should have to reside on the server.
... The use case is developing richer implications without
having to rely on the server side.
burn: That's a use case: "applications with richer, more flexible selection of presentation units within the language itself"
David: But I keep hearing from you a division of role between server and client.
rahul: This is about enabling some intelligence to reside on the client, rather than within the FIA or the server.
David: Is it available today? Or in 3.0?
rahul: The target is 3.0, not available today.
David: So there is a need for the logic on the client and 3.0 will have it. Is there anything else that this would require?
rahul: There is no magic here.
There's a lot of inherent complexity in what the user is
saying, and someone has to figure out what that means, and how
you fill slots based on the utterance you receive. Most of that
isn't covered in my paper.
... Assuming you could take what the user said and translate it
into a given number of slots, then I can provide you with
greater flexibility without going to the server.
David: So you don't see any specific short coming of the list of items that were put up this morning?
rahul: yes, in a way they are
orthogonal.
... SISR for instance, I assume the semantic interpretation is
juts done.
David: Since you are moving some aspect to the client, then what are the dependencies?
rahul: If all you are using VoiceXML for is a thin shim to play a prompt and retrieve a response, then you will be able to use with these improvements be able to generate a more sophisticated VoiceXML dialog.
ddahl: I think your proposal is saying that the language that needs to change is VoiceXML, and that the changes are already on the path to support what you want to do, then the interesting question is if there is something else that VoiceXML needs that isn't already on the path?
matt: I think we're not actually supporting some of the use cases that rahul mentioned. I don't think what is already planned adequately services the use case of bringing the development in line in a way that that common web developers will be able to develop voice web apps.
ddahl: You're saying that what we've said should be a template for how to describe a use case. You've tried to implement things, flexible dialogs you had in mind, you had to do something else using server logic, etc. That's exactly what we're saying motivates changes to the standards.
rahul; Yes, that's part of the difficulty again, once you head over to the server side and you don't know what it's doing, then it's even more difficult to compose multiple pieces together. Who knows what's in there? It's a black box.
rahul: If you have two VoiceXML documents authored using TCs then those are things you could envision making sense of them and being able to combine them.
burn: You listed two use cases
one that we worked in detail on.
... One of the use cases was specifically about combining XHTML
and VoiceXML. That use case I understand. Is that a sufficient
description of a use case for people here?
... We want to make VoiceXML documents that can interact with
XHTML documents -- that's the use case at a minimum.
David: And that integration is at an event level.
burn: That's just one possible way to do it and what we are pursuing.
rahul: And my proposal is that
that is the right way to do it.
... For example the XHTML + Voice pizza example. As you say
stuff ordering a pizza it appears on the screen, etc.
... There was magic involved in X+V, there was no real contract
between the XHTML page and the voice bits.
... A VoiceXML 3.0 presentation element can be activated by
receiving an event. And in the other direction, when a form
field is filled it could now generate a complete event that
could be listened for by anyone in the ancestors and take
whatever action it needs to take.
... Could be any markup, doesn't have to be XHTML, could be SVG
or something.
David: Both of these ideas have
been in the community for a few years and are being pursued as
we speak.
... So that's good, but is there any badness?
rahul: Apart from the time it's taking? No.
David: Not minimizing your paper, but I think your stuff is in good hands right now.
[ short break ]
dan: question
... anybody not sure what 4 template questions mean?
... if anybody not sure, we can walkthrough one example
... pick one example up
... e.g. the one from Paolo and Debbie
... or the one from Simona
( take Simona's presentation as an example )
( Dan puts "Sample use case template for each presenter to use" as the title)
David: 1. Describe a use
schenario:
... The problem of the IT Help Desk.
... Person says "My laptop is broken. Help me fix it."
... 2. Describe your implementation:
raj: points out something
debbie: interoperability is out of scope here
david: use scenario doesn't mean
"user interaction"
... use scenario for each person's use case
simona: 2. Describe your
implementation: Interfacing with a rule-based diagnostic
engine.
... possible diagnosis
... we don't describe the (diagnosis) logic within
VoiceXML
... that's one of the problems
dan: put the folllowing:
... 2. Describe your implementation:
... A rule-based diagnostic engine is used to do conversational
logic, with VoiceXML used only as a means of playing audio to
the caller and returning a recognized result.
simona: fine
dan: and put the following:
... 3. Why were you not able to use only existing standards to
accomplish this?
simona: optimizing strategy
david: we couldn't see a direct
methodology
... "it's not broken"
... the listener may say "maybe the problem is something
else"
... it's issue of dialog management
... the question is on the semantic interpretation as well
simona: the system pinpoints the cause based on the dialog exchange
david: too many situations
michael: interactin of dialog
logics
... what is underlying problem?
... first to do is collecting symptoms
... e.g., I need to ask another question to clarify the
situation
simona: yes, need to ask further
questions to pinpoint the problem
... we can not do that FSM which VoiceXML currently
provides
dan: put the following:
... 3. Why were you not able to use only existing standards to
accomplish this?
... This is an issue of dialog management.
... We could not determine how to encode in VoiceXML the
reasoning needed to work towards identifying and aligning
symptoms with a solution. The best approaches to this are
data-driven and probabilistic in nature.
( dan asks if the above is ok )
simona: ok
( dan moves forward to item 4 )
dan: put the following:
... 4. What might you suggest could be standardized?
... I don't know
... there are lots of non-comercial systems in research
institutes etc.
david: the problem is...
... I have to iterate questions to clarify the problem
dan: ok
( go to the written-up description )
dan: there are many customer dependent approaches
david: we needed to put complicated knowledge into the system
dan: start to add some description to the 3 (=issues)
michael: there are lot of technologies are involved even in kitchen sink problem
david: complexity glows
... even this case is beyond multi-intent multi-slot
dan: (updates the description a
bit)
... In addition, it was not clear how to map within VoiceXML
from the output of the natural language piece (e.g., SLM +
robust parsing + statistical semantic models) to the reasoning
engine. We could not represent any aspect of the state other
than just the specific slots filled during recognhition
david: we could not do those things
dan: not clear how to map VoiceXML
david: not clear how to implement with existing standards
michael: it's not coming from just one place
dan: is this (=the description on the screen) sufficient as an example?
michael:
one question is:
... would we get a benefit from having an extension to the standard
to make it easier to maintain the set of hypotheses?
... not of recognition hypotheses
... but hypotheses as to what is underlying...
dan: will send out the writtenup text
( Dan will send the writtenup to Kaz, and Kaz will distribute it to the attendees )
Sample use case template for each presenter to use:
The problem of the IT Help Desk. Person says "My laptop is broken. Help me fix it."
A rule-based diagnostic engine is used to do conversational logic, with VoiceXML used only as a means of playing audio to the caller and returning a recognized result.
This is an issue of dialog management. We could not determine how to encode in VoiceXML the reasoning needed to work towards identifying and aligning symptoms with a solution. The best approaches to this are data-driven and probabilistic in nature. In addition, it was not clear how to implement with existing standards from the output of the natural language piece (SLM + robust parsing + statistical semantic models) to the reasoning engine. We could not represent any aspect of the state other than just the specific slots filled during recognition.
I don't know.
dan: gives instructions for the
exercise
... please get prepared for the exercise with your own idea
(Dan asks attendees for their own use cases)
paolo: Cover SLM inside the standards
rahul: Browser-based dialog
management
... Interaction with other modalities in the browser
kurt:
Syntactic formalism
... Feature inheritance and concord
... Start/resume mechanism
... Non-increment mechanism
simona: Problem solving
... Richer semantic representation
... Abstract semantics
... R&D agility
david: integrated conversational interface to multiple applications/
raj: Programmatically assigning weights, enabling/disabiling parts of grammars
kim: Speech commands are hard to
remember
... It's difficult to get users to correct speech
commands
... It frustrates people when the computer gets things wrong
that they would not get wrong
... People who can't use their hands need to be able to use
speech for all input
chiori: Multiple hypotheses of ASR and Spoken Language understanding manipulation based on dialog context context for dialog management
michael: Grammars or models that support parsing and understanding of inputs distributed over multiple modes
debbie: Being able to say
something that includes a grammar-recognized phrase as well as
SLM
... Being able to take into acocount characteristics of the
user such as age, gender and emotional state in making dialog
decisions
paolo: Pass features of different kinds to TTS, ASR where needed
kurt: Reversible morphology
engine and formalism
... Grammatical tags
debbie: Dictation
Rough list of use cases to discuss on Day2:
(dan explains what to do tomorrow)
dan: not how you solve, but why
do you need to create new standards
... e.g., Chinese people wanted to add <tone> element for
SSML
... but it would have not been appropriate to just create a new
<tone> element
... people tend to solve their problems using their ways...
debbie: e.g., there are many possible solutions when I'm tired :)
dan: use case is "You're tired"
david: go to bed could be a solution
[ Day1 ends ]
( Reception + Dinner !!! )
Break discussions by the following teams
Applications need to be sensitive to certain (arbitrary, dynamically extracted) features, s.a gender, age, etc. Example : adjust voice, phrasing, etc. based on those features. Current limitation : current VSML infrastructure only allows words/interpretations/confidence are standard requirements. We need a place to these info somewhere so that they get transmitted.
Interaction between lexicon and grammar don't include addition info such as POS, Grammatical, or other: Example : I'd like to annotate a name with the region (location) to influence pronunciation.
Dialogue system that contains discourse and WSD that could be used to improve rendering. Example : "record" (noun vs. vb). Need a mechanism to convey the information between those components without having to modify the categorization either of the dialogue or the synthesis system.
[ The upper in the following picture is UC4. ]

(click to enlarge)
Phomeme sets. an author can't create a component (app, lexicon, asr engine, tts engine, etc.) which is assured to be interoperable with other components in the terms of the phoneme set. The author should be able to use and specify a pre-defined standard phoneme set.
[ The lower in the following picture is UC5. ]

(click to enlarge)
Syntactic Formalism. Today an author cannot create a syntactic grammar for comprehensive NL because e the formalism lacks features inheritance, POS terminals, concord, inversion, etc. A new formalism should be created.
[ The upper in the following picture is UC6. ]

(click to enlarge)
Morphology engine Kim: what would it allow authors to do? Kurt : could use a higher level abstraction to create applications or engines
[ The lower in the following picture is UC7. ]

(click to enlarge)
Shared Syntactic Grammars (for simultaneously running applications) (please fill in UC description)
(from Kim) Focus change - users need a way to tell the device how to control focus. (speech commands don't automatically reorient mouse. There's no standard way to do this.
(from Kim) Users are afraid of speech : users need a way to undo both actions and text events
mix constrained and unconstrained recognition. Debbie : this can't be done today within SRGS
Combine reco constraints when multiple apps are active simultaneously and transfer focus. Kurt: What are reco constraints? Raj: A more general name for "grammar".Raj proposed a mechanism to solve this by exporting top-level reco grammars. Simona remark : Raj's solution proposed is not necessarily the only solution for that problem.
Kim: need for resolving conflicting commands, as well. Need for a way to organize and share commands, for the user to have a way to remember and prioritize commands. So , one solution might be to have user-configuration for conflict resolution. Users can't find them, adjust, organize them, or share them.
Enabling/Disabling grammars/reco constraints. should be able to be context specific (Activated/deactivated/weighted) Where context, means anything (including user profile, history, etc)
Dynamic on the fly activation deactivation or combination of any SRGS or SLM grammars There are application that in intelligent conversation combine open-ended and restricted language, so we need a mechanism to specify how to combine any recognition constraint. Moreover we need to be able to dynamically weight those recognition constraint based on context. Proposed mechanism to specify weights in range 0-1 in each recognition step.
EMMA Extension or Richer Semantic Representation We want to be able to represent the semantic of complex NL. Example give all those topping except onions, or I want to leave today afternoon or tomorrow morning to arrive before noon. In current standards we can represent attr-value pairs and there is hierarchy in EMMA, but there is no way to specify modifiers, quantifiers between slots. Propose to look at existing formalism such as RDFs and maybe extend EMMA
R&D Agility As we do research we develop new algorithms that need new information and we would like to experiment them before standardization process. We need a reliable mechanism in VXML to carry these information. Examples: add location information, new DSR signal features. Today solution is to add value to a parameters, if we had a standard way to do set vendor specify we will be happy.
Problem Solving We want to be able to do application that solve complex problems, like IT problem solving. The call control logic of such application cannot be today efficently describe as a state machine therefore available standard (VXML, SCXML) are insufficient to implement these applications, e.g. probabilistic rule engine, or task agent system. I'm not sure it can be efficiently put in standard, but I want to point out that there is another category of application not handled by standard.
EMMA Extension: Multi source input and corresponding confidence In multimodal applications and more advanced applications, input might come from a variety of simultaneous source such as text, speech, GPS, world knowledge, user profile, etc, for instance I might say: "I want to go to Denver" and appl can know from GPS where I am. I'd like for each concepts or slots to have possibly a multiple set of input sources with corresponding values and confidence score.

(click to enlarge)

(click to enlarge)
Semantic representation of dialogue state that can include any kinds of data (e.g. history slot conditions, user models, expectation of next system actions). The problem is that current VXML 2.0 specification does not support a container of dialog state that contain multiple hypotheses of dialogue state. Most simple example is: Sys1: HMYHY User1: kyoto ASR: Kyoto (0.7) or Kobe (0.3) SLU: from and to so 4 dialog states Multiple dialogue states should be returned/represented in VXML Sys2: Can generate a prompt ...
Combine Use Cases: Kurt: Propose to combine (7) and (11) called 7+11 ** Decision: Merge 7+11 Raj: Combine (10) and (13) and (14) Simona: Thinks that (14) is a superset of other two Debbie: Prefer to keep them split ** Decision: Aggregated 10-13-14 ====================================== TODO for the next session: Vote with 10 points
dan: (shows the following result of the priority/interest vote)
| Use case number | Tally |
|---|---|
| 10/13/14 | 18 |
| 1 | 12 |
| 5 | 12 |
| 19 | 9 |
| 7/11 | 8 |
| 3 | 7 |
| 16 | 7 |
| 12 | 6 |
| 18 | 6 |
| 8 | 5 |
| 9 | 5 |
| 2 | 4 |
| 15 | 4 |
| 4 | 3 |
| 17 | 3 |
| 6 | 2 |
dan: natural breaking point should be the top three?
... the result is sorted by the number of tally
... next to do is discussing the three topics
 (click to enlarge)
(click to enlarge)
 (click to enlarge)
(click to enlarge)
 (click to enlarge)
(click to enlarge)
debbie: putting comments from Simona directly onto the editor
paolo: draw a picture about Grammar and SLM
question: how to dynamically update SLM?
raj: let's think about simple case with grammar
paolo: we have a set of
grammars
... I want to enter deep in the grammars
dan: there is a naming
problem
... an example is from city to city
... there is a referencing issue
simona: naming conflict could be solved
raj: it's about categorization
paolo: the point is compiling/optimizing all the related grammars is difficult
dan: weights are available with SRGS, but how to attach rules to weights?
( Dan goes to the flipchart and draw some example rule )
TRIP:= from CITY to CITY
( Debbie adds clarification to the proposal on "mechanism to specify weights in range 0-1..." )
dan: this mechanism is available not only for engine developers/applications author but for users
paolo: even if same weights are given, if different engines, e.g., Loquendo and Nuance, are used, the results are different
debbie: couples of issues mentioned
( Debbie reads the updated notes )
( Debbie adds "nonterminals could be the points of control" under Proposed mechanism..." )
( also adds "or at least enable and disable" to the end of Proposed mechanism to....")
-------------- Debbie's note -------------- UC10: mix constrained and unconstrained recognition. UC13: Enabling/Disabling grammars/reco constraints. should be able to be context specific (Activated/deactivated/weighted) Where context, means anything (including user profile, history, etc) UC14. Dynamic on the fly activation deactivation or combination of any SRGS or SLM grammars There are applications that in intelligent conversation combine open-ended and restricted language, so we need a mechanism to specify how to combine any recognition constraint. Moreover we need to be able to dynamically weight those recognition constraint based on context. Proposed languages and language extensions: - Proposed mechanism to specify weights in range 0-1 in each recognition step dynamically, or at least enable and disable interesting issues with compiled grammars that have been optimized need ways to specify weights in the grammar that might change so that the compiler knows what might change need ways to tell grammar dynamically what the weights are nonterminals could be the points of control - Allow nonterminals in SRGS to refer to SLM's or dictation rules - Allow SLM to refer to grammar, e.g. class-based SLM's, this requires a standard for SLM's possible extensions: SRGS, and VoiceXML (this might also imply changes to protocols like MRCP) possible new languages: SLM
paolo: one possibility is extending EMMA to have a place for this info
simona: in a standardized way
dan: we rather make things for
the author
... do we need to have a way to ask for specific return
rsults?
paolo: do we want to add anything to SRGS/SISR about this?
debbie: maybe VoiceXML?
( Debbie add the following note )
Possible change to SRGS to say "please collect some specific metadata, e.g., gender, age"
dan: to use this info within
VoiceXML, we would need to require that the entire EMMA result
be available in VoiceXML
... applications' last result is EMMA
... need to take care not to pollute namespaces
-------------- Debbie's note -------------- UC1: Applications need to be sensitive to certain (arbitrary, dynamically extracted) features, such as gender, age, etc. Example: adjust voice, phrasing, etc. based on those features. Current limitations: current VXML infrastructure only allows words/interpretations/confidence are standard requirements. We need a place to this info somewhere so that it gets transmitted Possible extensions: Extend EMMA to have a place to put this information in a standardized way Do we need to have a way to ask for specific return results? (VoiceXML) We never have done this before, we just get everything Possible change to SRGS to say "please collect some specific metadata, e.g. gender, age" To use this information within VoiceXML we would need to require that the entire EMMA result be available in VoiceXML
debbie: clarification about semantic grammar vs. syntactic grammar?
kurt: not an extension to SRGS
but new mechanism for inheritance of category
... part-of-speech in both in lexicon and grammar should be
co-related
... here I don't mean any semantics, just thinking about
syntactic information
( Debbie adds the following )
Proposal: new language
kurt: I don't see any model which includes feature inheritance capability, etc.
debbie: proposing an XML?
dan: not necessarily
debbie: maybe CSS is an example of non-XML specs?
( extension for SRGS vs. completely new language? )
paolo: reducing searching space
has been important for recognition
... I'm a bit concerned
-------------- Debbie's note -------------- UC5: Syntactic Formalism. Today an author cannot create a syntactic grammar for comprehensive NL because the formalism lacks features inheritance, POS terminals, concord, inversion, etc. Proposal: new language that can capture syntactic natural language requirements, could look at NL literature, anything in XML?
[ short break ]

(click to enlarge)
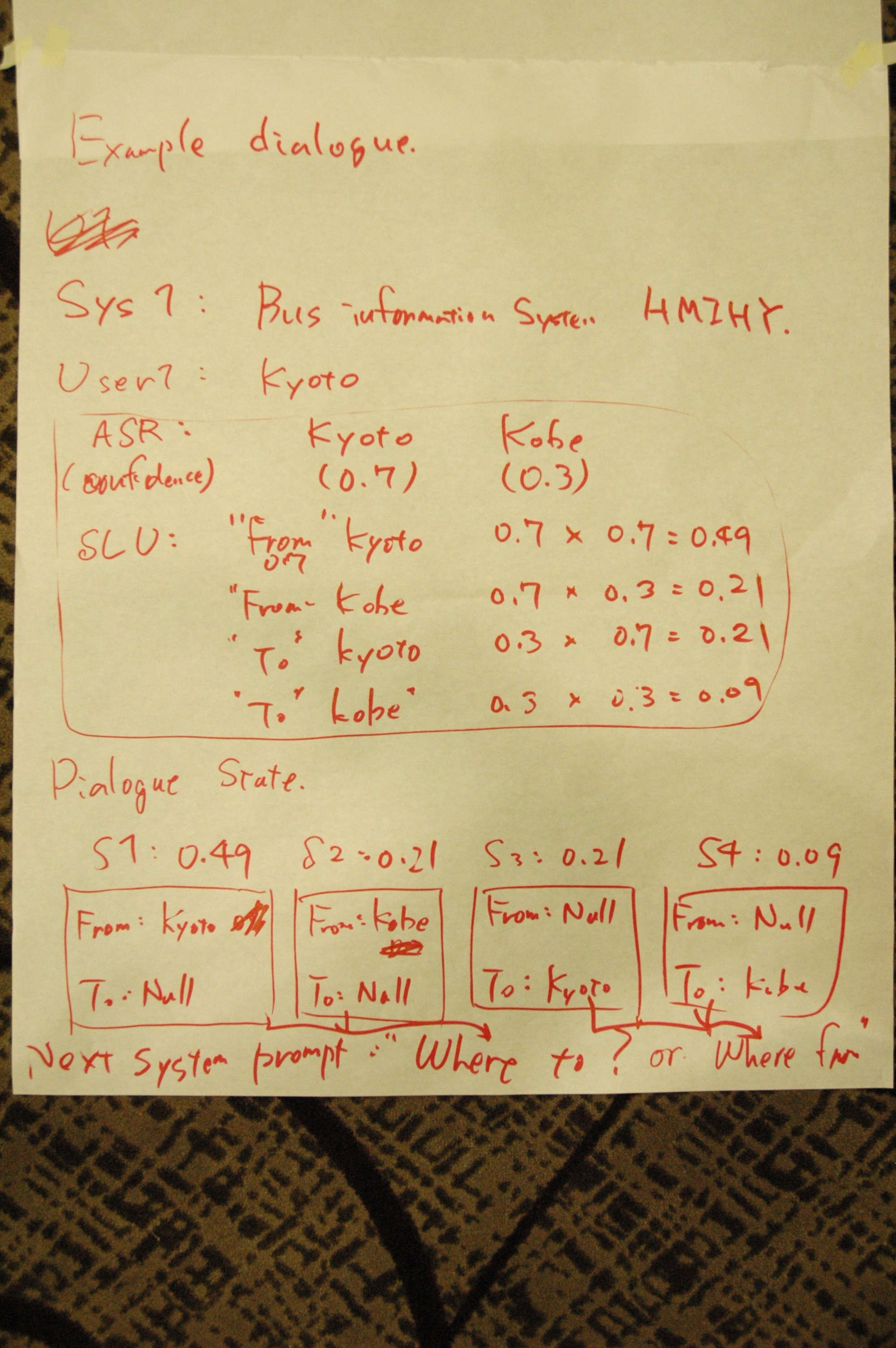
(click to enlarge)
-------------- Debbie's note -------------- UC19. Semantic representation of dialogue state that can include any kinds of data (e.g. history slot conditions, user models, expectation of next system actions). The problem is that current VXML 2.0 specification does not support a container of dialog state that contains multiple hypotheses of dialog state. Most simple example is: [[ Sys1: HMIHY User1: kyoto ASR: Kyoto (0.7) or Kobe (0.3) SLU: from and to so 4 dialog states Sys2: Can generate a prompt ... ]] Proposal: Multiple dialogue states should be returned/represented in VXML. How to represent states? EMMA? New language: an XML data structure for representing one or more alternative dialog states, not necessarily linked to any other spec, or VoiceXML could ask for what to say or ask for next, and the server consults the new data structure.

(click to enlarge)

(click to enlarge)
-------------- Debbie's note -------------- UC 7/11 UC11: Combine reco constraints when multiple apps are active simultaneously and transfer focus. UC7: Shared Syntactic Grammars (for simultaneously running applications) Proposals: authoring: runtime: we need a method for an arbiter to query an application about what its capabilities are arbiter also allows user to discover, share, etc. capabilities of the applications aggregate grammars from several applications into a common grammar ensure that grammars that share the same syntactic formalism can be unified
[End of minutes]
The Call for Participation, the Logistics, the Presentation Guideline and the Agenda are also available on the W3C Web server.
James A. Larson, Deborah Dahl, Daniel C. Burnett and Kazuyuki Ashimura, Workshop Organizing Committee
$Id: minutes.html,v 1.47 2010/06/30 19:24:46 ashimura Exp $










