Disintermediation through Aggregation
(Making your Data your Own)

"We will never have LCD screens - they will need too many connectors"
"Vector graphics are the future; raster graphics need too much memory"
"Full audio on computers will need too much bandwidth"
"Digital photography will never replace film"
"Moore's Law hasn't got much longer to go" (1977, 1985, 1995, 2005)
We all know this one. But often people don't understand its true effects.
Take a piece of paper, divide it in two, and write this year's date in one half:
Now divide the other half in two vertically, and write the date 18 months ago in one half:
Now divide the remaining space in half, and write the date 18 months earlier (or in other words 3 years ago) in one half:
Repeat until your pen is thicker than the space you have to divide in two:
This demonstrates that your current computer is more powerful than all other computers you have had put together (and the original Macintosh (1984) had tiny amounts of computing power available.)
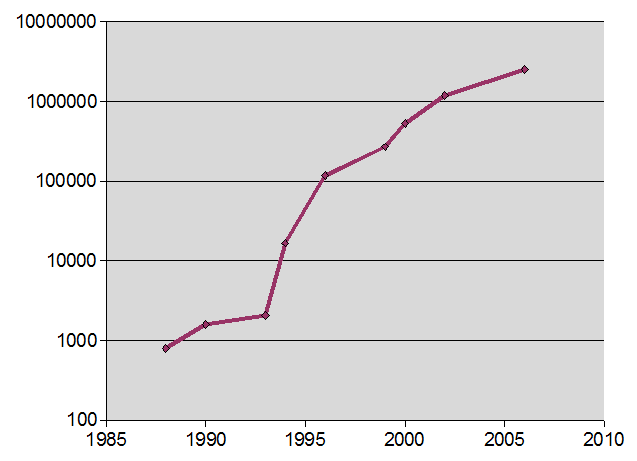
In the 1980's the most powerful machines were Crays

And people used to say "One day we will all have a Cray on our desks!"
Sure: in fact current workstations are about 120 Craysworth.
Even my previous mobile phone was 35 Craysworth...

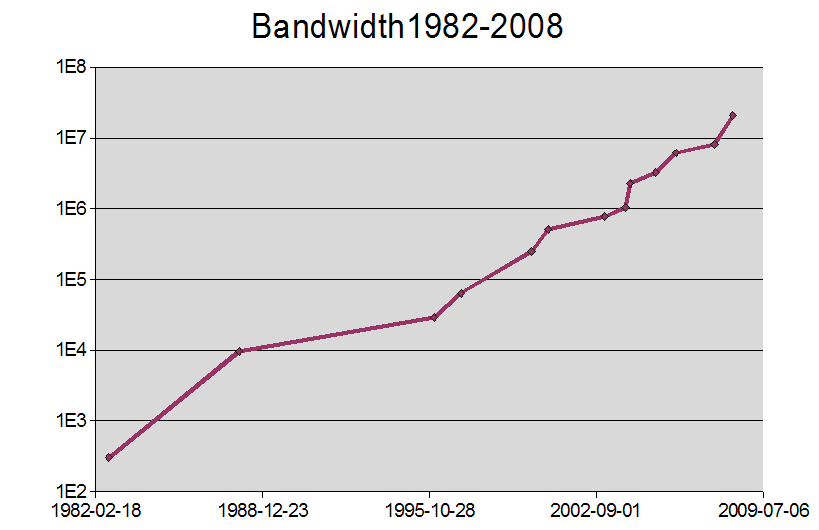
What is less well-known is that bandwidth is also growing exponentially at constant cost, but the doubling time is 1 year!
(Actually 10½ months according recently to an executive of one of the larger suppliers)
Put another way, in 7 years we could have 1 Gigabit connections to the home.
Sapir-Whorf Hypothesis: Connection between thought and language.
If you haven't got a word for it, you can't think it.
If you don't perceive it as a concept, you won't invent a word for it.
For example: Dutch Gezellig
The Deeper Meaning of Liff: A Dictionary of Things There Aren't Any Words for Yet — But There Ought to Be
By Douglas Adams and John Lloyd
Such as:
PEORIA (n.): the fear of peeling too few potatoes
ABINGER (n.): Person who washes up everything except the frying pan, the cheese grater and the saucepan which the chocolate sauce has been made in.
DUNGENESS (n.): The uneasy feeling that the plastic handles of the over-loaded supermarket carrier bag you are carrying are getting steadily longer.
The term Web 2.0 was invented by a book publisher (O'Reilly) as a term to build a series of conferences around.
It conceptualises the idea of Web sites that gain value by their users adding data to them, such as Wikipedia, Facebook, Flickr, ...
But the concept existed before the term: Ebay was already Web 2.0 in the era of Web 1.0.
By putting a lot of work into a website, you commit yourself to it, and lock yourself in to their data formats too.
This is similar to data lock-in with software: when you use a proprietary program you commit yourself and lock yourself in. Moving comes at great cost.
This was one of the justifications for creating XML: it reduces the possibility of data lock-in, and having a standard representation for data helps using the same data in different ways too.
But there is no standard way of getting your data out of one Web 2.0 site to get it into another.
As an example, if you commit to a particular photo-sharing website, you upload thousands of photos, tagging extensively, and then a better site comes along. What do you do?
How do you decide which social networking site to join? Do you join several and repeat the work? I am currently being bombarded by emails from networking sites (LinkedIn, Dopplr, Plaxo, Facebook, MySpace, Hyves, Spock...) telling me that someone wants to be my friend, or business contact.
How about geneology sites? You choose one and spend months
creating your family tree. The site then spots similar people in your tree on
other trees, and suggests you get together. But suppose a really important tree
is on another site?
How about if your chosen site closes down: all your work is lost.
This happened with MP3.com for instance. And Stage6. And Pownce. And Ficlets. And Jaiku. And Google Video.
How about if the site has a disk crash and discovers it hadn't backed up properly: Magnolia for instance.
How about if your account gets closed down? There was someone whose Google account got hacked, and so the account got closed down. Four years of email lost, no calendar, no Orkut.
Here is someone whose Facebook account got closed. Why? Because he was trying to download all the email addresses of his friends into Outlook.
Or the woman whose account was closed for the heinous crime of posting a photo of her breastfeeding.
Metcalfe proposes that the value of a network is proportional to the square of the number of nodes.
v(n)=n2
 Simple maths shows that if you split a
network into two, it halves the total value:
Simple maths shows that if you split a
network into two, it halves the total value:
(n/2)2 + (n/2)2 = n2/4 + n2/4 = n2/2
This is why it is good that there is only one email network, and bad that there are so many Instant Messenger networks. It is why it is good that there is only one World Wide Web.
The Web 2.0 examples are all examples of Metcalfe's law in action
Web 2.0 partitions the Web into a number of topical sub-Webs, and locks you in, thereby reducing the value of the network as a whole.
What should really happen is that you have a personal Website, with your photos, your family tree, your business details, and aggregators then turn this into added value by finding the links across the whole web.
Firstly and principally, machine readable Web pages.
When an aggregator comes to your Website, it should be able to see that this page represents (a part of) your family tree, and so on.
One of the technologies that can make this happen has the catchy name of RDFa.
You could describe it as a CSS for meaning: it allows you to add a small layer of markup to your page that adds machine -readable semantics.
It allows you to say "This is a date", "This is a place", "This is a person", and uniquely identify them on your web page: it turns your page into data.
Comparable to microformats, but then generalised.
Relational databases: Isolated data; the data can be joined, but usually isn't.
We could create a Metcalfe law for data
RDF is a future for data: a web of data
Data is automatically joined. You really don't (need to) know the structure. You can just add a new piece of data (a new fact) with no extra work.
If a page has machine-understandable semantics, you can do lots more with it.
So rather than putting all your data on someone else's website, and the fact that it is there implying a certain semantics, you should put your own data on your own website with explicit semantics.
Then you get the true web-effect, with its full Metcalfe value.
You can still use software to create your site (think how Blogger works)
If Ebay was Web 2.0 in the era of Web 1.0, is there already some Web 3.0 out there now?
Yes, I think so: Google news is an example, even though the semantics are not explicit, but implicit.
It doesn't really matter, because on the whole Websites are largely interoperable, but I am particularly charmed by this sort of device:
 2
2 They are wireless routers
containing network storage and a media server for in your house, while offering
FTP and a world-class Webserver for outside. So you can switch off all your
machines, and still serve webpages to the outside world, with rather low energy
use.
They are wireless routers
containing network storage and a media server for in your house, while offering
FTP and a world-class Webserver for outside. So you can switch off all your
machines, and still serve webpages to the outside world, with rather low energy
use.
Web 2.0 is damaging to the Web by dividing it into topical sub-webs.
With machine-readable pages, we don't need those separate websites, but can reclaim our data, and still get the value.
Web 3.0 sites will then aggregate data from the web, and in so doing add value that will attract users.
Full text at: http://www.cwi.nl/~steven/vandf/2008.03-website.html