Warning:
This wiki has been archived and is now read-only.
Issues
From Media Fragments Working Group Wiki
This page aims at capturing the various issues that are discussed on the WG public mailing list.
We will use more formally the issue tracker after having discussed these issues.
Following Jack's suggestion, we distinguish the issues regarding the functionality from the representation of the media fragments.
Contents
Ghent face-to-face meeting resolutions
- Time dimension: local to the media, so we do not care about the time zones for example
- WG will provide either informally or in the spec a mapping between Media Fragment URI and the standards covered in the Technological Survey
- Frame precision access: always jump to the last I-Frame that precedes the time point requested?
- we cannot define an algorithm that says that a time point corresponds to a particular frame for all encoding formats;
- we might want to provide some guidelines for some specific formats
- Track definition: we consider only what the container (encapsulation) format is exposing
- Should we define a simple vocabulary for describing the media (e.g. which track is available?), à la ROE like it is used in Metavid?
Cannes face-to-face meeting resolutions
- Continuity / Discontinuity: postponed, but keep it mind
- Spatial Fragment shape: rectangle for now
- Container and substreams: postpone decision, but certainly create syntax that is extensible to incorporate this at a later time
- In-context / Out-of-context: we want to make sure that fragment is aware of "full" resource
Functionality
Continuity / Discontinuity
- Should we address non-temporally connected sequences of a video?
- Use Case 1: a video content contains an interview, edited in two parts cut by some advertisements. One would like to address in a single media fragment the two parts which are not temporally connected
- Use Case 2: see the Media PlayList UC
- Multi-fragment URIs: Silvia points out that the temporalURI specification can take multiple parts together, but creates a new resource. See also the related discussion regarding the status of a media fragment discussion.
- The question boils to: can a multi-fragment URI be implemented as a playlist? is it the same thing?
- See also the xspf playlist format
- Should we address non-spatially connected regions of an image?
- Use Case: highlight a group of people, or more generally a group of objects within an image
- Image Maps: see various examples of clickable images implemented with an image map, its CSS version and javascript
Spatial Fragment shape
- Do we want simple bounding box rectangle shape or arbitrary free shapes (e.g. the shape of a tiger in a still image) for a spatial media fragment?
- Image Maps allows defining rectangular (rect), circular (circle) and polygonal (poly) regions
- Spatial references is really tricky to resolve efficiently. Most of our discussion have already identified the support for spatial references in compressed domains of jpeg etc is technically almost impossible, and to optimize transfer in such cases the object needs to be recoded which creates another object with it's own representation. Should we specify a different semantics for spatial media fragment? For example, when a UA request a spatial fragment, it will receive the whole picture but might decide to highlight the region specified by the fragment. Should we consider an automatic transformation between spatial fragment and image map?
Container and substreams
- http://lists.w3.org/Archives/Public/public-media-fragment/2008Oct/0010.html: We are working towards a format-independent URI-based fragment identifier mechanism, but what do we mean coding formats, container formats, or both?
- http://lists.w3.org/Archives/Public/public-media-fragment/2008Sep/0022.html: Do we want to be able to select substreams of a media, e.g. ask the server to get the video track and the caption track from a certain video resource and ignore all other tracks (in particular sound tracks)
- Use Cases: Video and Audio
- Glossary: see the video model and the basic assumption of a single unified timeline.
- See the list of coding formats and container formats.
In-context / Out-of-context
- Do we want to be able to jump outside (before or after) the media fragment?
- http://lists.w3.org/Archives/Public/public-media-fragment/2008Oct/0007.html: absolute vs relative timestamps
- http://lists.w3.org/Archives/Public/public-media-fragment/2008Oct/0012.html: with Annodex, the resource that is returned upon a temporal URI request knows whether it starts at an offset of 30s or not (stored in the "presentationtime" header field). http://annodex.net/TR/draft-pfeiffer-temporal-fragments-03.html#anchor6 describes the protocol aspect of it. If we ask for an offset of 30s we have to expect the first frame to be at 30s and a 404 otherwise (in the I-D an additional exception is mentioned for the case where the server decides to dishonor the query and serve the resource without the offset).
- Do we want client-side selection?
- With Annodex, queries and fragments enable server-side selection and client-side selection
- There should be a way to get the context of the fragment through an out-of band measure for applications, and a simple change of the URI for users.
Representation and Implementation
URI Fragment / URI Query
- Question: should we use # in URIs to identify media fragments?
- Rule of thumb: Everything that is specified in a URI fragment is only local to the client and cannot be transferred to the server. It can be sent via other means (custom header, Range request, etc...) if the client knows how to convey the relevant information to the server.
- temporalURI spec uses queries ? instead of fragments.
- Discussions:
- http://lists.w3.org/Archives/Public/public-media-fragment/2008Oct/0022.html: fragment identifiers follow a "#" in URIs, and they are interpreted by the user-agent. The syntax and semantics of the fragment identifier are defined by the resource type. That is, what constitutes a legal fragment for say HTML may look very different from a legal fragment for say MP4. The fact that they are interpreted by the UA does NOT mean that the entire resource is automatically downloaded and then the fragment interpreted, however. For example, in a media file that has an index and is in time-order, a user-agent wanting a time-based subset may be able to use byte-range requests to get the index, and then the part(s) of the file containing the desired media. We do this today for MP4 and MOV files.
- http://lists.w3.org/Archives/Public/public-media-fragment/2008Oct/0022.html: query identifiers follow a "?" and are interpreted by the server. The syntax and semantics are defined by the server you are using. To the UA, the result is "the resource". Annodex servers can do time-based trimming of media files. Metavid is making extensive use of this.
- http://lists.w3.org/Archives/Public/public-media-fragment/2008Oct/0023.html: By definition of URI fragements, the fragment identifier is not being communicated to the Web server. Instead, it is only interpreted locally by the UA. Silvia has had this discussion extensively with the URI working group as they were trying to formalise temporal URIs (http://lists.w3.org/Archives/Public/uri/2003Jul/0016.html). Therefore, using only URIs and HTTP, there is no other means of communicating the fragment specification to the server than using the "?" query component of URIs.
- http://lists.w3.org/Archives/Public/public-media-fragment/2008Oct/0041.html: "#" cannot work for communicating the time range to the server. "#" is stripped off before it reaches the server. "#" only works in communicating a time range to the UA. After the time range has been communicated to the server and the server has told the User Agent which byte ranges to get, it is indeed possible to get the fragment through a range request. However, we first need to communicate the time range to the server (as discussed with Dave).
- http://lists.w3.org/Archives/Public/public-media-fragment/2008Oct/0045.html: Range requests are for now defined as using byte ranges, but it is extensible, nothing prevents the creation of custom range units, like seconds, absolute time ranges, or whatever useful. The UA can see there is a #, and using the context of the request, do the relevant HTTP request to get only what's needed. There is no need to always delegate the processing to the server, one because it avoids a round trip, second because you still have to process something client-side (in that case parse a custom header to generate an HTTP byte range request), if you are using the two requests solution.
- Interaction with the Server: special case for MP4 and MOV files (it won't work with all media resources though)
- http://lists.w3.org/Archives/Public/public-media-fragment/2008Oct/0028.html: The MP4 and MOV files store all the frame size, timestamp, and location information NOT interleaved with the actual compressed data, but in run-length compacted tables in a separate area. In there, there is a table that indexes from time to frame number, and another table that indexes frame number to frame size, and another that effectively gives you absolute file-offsets for each frame (actually, they are collected into chunks of frames, but that's not terribly important). So, once you have these tables -- and they are all together in one place -- you have all you need to map time to byte-ranges, and you can go ahead and do byte-range requests to any http 1.1 server. Finding the table is not all that hard. They are all in the moov atom which is at top-level of the file, and in any file that's been properly laid out, it's either first, or after a very small 'file type' atom. So, read a decent chunk of the beginning of the file, and you'll probably get it. It has a size indicator (second word of it), and if it exceeds what you read, you can issue a second read for the rest.
- OK, so the tables are in the MOV file and therefore not available to the client without talking to the server. Therefore, you need to do at least one communication between client and server to get the information how to map time to byte-ranges.. BUT, in that case, you can do the URI fragment address conversion to a byte-range request fully on the UA side.
- http://lists.w3.org/Archives/Public/public-media-fragment/2008Oct/0046.html: There's still the issue of dealing with time ranges in Web proxies who should not have to deal with the whole complexity of media formats and who will not be able to know for individual files how to map time to byte ranges. Ultimately, byte ranges are the only way of safely determining whether the Web proxy has all the bits it needs to hand on the data to the client or not.
- Summary: http://lists.w3.org/Archives/Public/public-media-fragment/2008Oct/0060.html
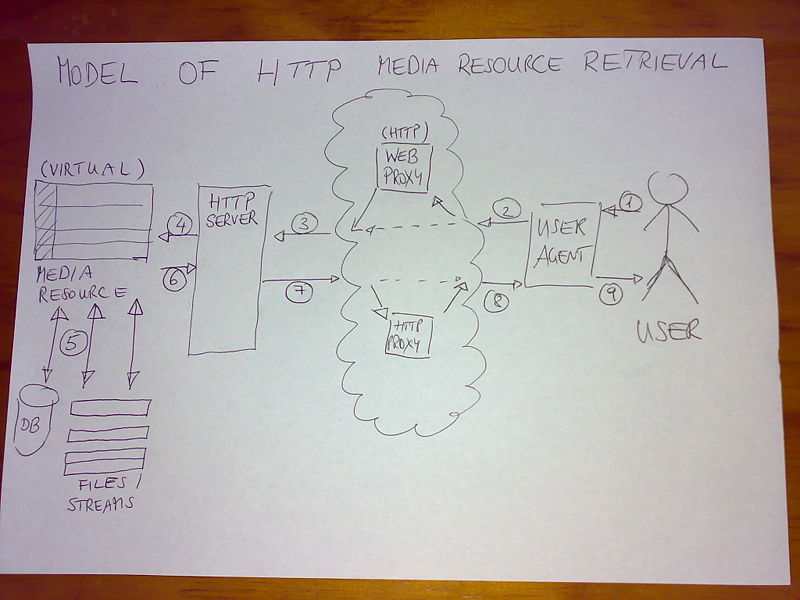
- More opinions:
- Squid expert: Semantically the URI fragment identifier is imho the correct place for this kind of information if placed within the URI, and also provides the better compatibility with agents who don't know about the syntax or protocol extension (they will get and play the whole referenced media, not knowing the meaning of an anchor).
- Using an fragment identifier requires the user-agent to be able to resolve this into suitable ranges etc one way or another, which in most cases is an entirely realistic requirement. This could be by parsing the media file and seeking until the correct location is found (i.e. using range requests if using an HTTP transport), or optimized using a sideband method/object, or integral in the transport method used whatever that is for the resource in question.
Fragment Name and Description
- http://lists.w3.org/Archives/Public/public-media-fragment/2008Sep/0012.html: Raphael advocates to distinguish the syntax of the media fragment from its description (or semantics)
- http://lists.w3.org/Archives/Public/public-media-fragment/2008Sep/0015.html: Silvia makes a case to have the possibility to give a name (or a label) to a fragment. The name would just be a random string that stands for a time interval, a spatial area, or a spatial area over a time interval. The name could also be generated using a service such as tinyurl.
Status of a Media Fragment
- Is a media fragment a new resource?
- URI fragment (#) does not create a new resource.
- temporalURI spec uses queries and thus creates a new resource. This is an issues if one wants to reconstruct the whole document. See also the related discussion regarding the in-context/out-of-context functionality.
- Annodex has proposed a complex process for the user agent to request cachable sections of the original resource. This requires a slightly more informed protocol to allow caching of video fragments that use URI fragments. There is no actual implementation of this protocol, but got to it through intensive discussions with Squid developers and thus in theory it should work. See http://annodex.net/TR/draft-pfeiffer-temporal-fragments-03.html#anchor8.
- See the Internet Draft: HTTP Header Linking
- It's a rebirth of the Link header that was dropped more or less by mistake during the rfc2068->2616 transition and issues between the use of link in HTML and in Atom. In that way, one could specify that a temporal URI with a query would be a related resource to the one without the query. Would need a "supersection" - or "parent resource", similarly as "subsection" exists.
Server, Caches and Proxies
- Caches are a different matter to servers. While servers know for a given media type how to map time to byte ranges, a cache may not have such information and should only deal with byte ranges. This is particularly true for Web proxies. In that case, we need a special protocol to deal with this situation. Silvia had a plan with Ogg resources and temporal hyperlinks. It would work within the existing Web proxy specifications, but required some extra HTTP message headers, see http://annodex.net/TR/draft-pfeiffer-temporal-fragments-03.html#anchor8.
- Silvia had a discussion with a squid expert and one technical point that was made is that doing time ranges in proxies may be really difficult since time is inherently continuous and so the continuation from e.g. second 5 to second 6 may not easily be storable in a 2-way handshake in the proxy. Instead there was a suggestion to create a codec-independent media resource description format that would be a companion format for media resources and could be downloaded by a Web client before asking for any media content.
- Davy's answer states that codec-independent media resource description (and also adaptation) is a very nice and elegant technique to tackle the coding format heterogeneity, but it only works if the media resources support the addressing of structural elements such as tracks, time, spatial, and named fragments in terms of bits and bytes so that extraction of these fragments can occur in the compressed domain.
- Jack discusses the pro and cons of caching byte ranges vs time ranges ... but the former seems preferable.
- Davy's scenario:
- We use byte ranges to cache the media fragments:
- The media resource meets the two requirements (i.e., fragments can be extracted in the compressed domain and no syntax element modifications are necessary) -> we can cache media fragments of such media resources, because their media fragments are addressable in terms of byte ranges.
- Media fragments cannot be extracted in the compressed domain -> transcoding operations are necessary to extract media fragments from such media resources; these media fragments are not expressible in terms of byte ranges. Hence, it is not possible to cache these media fragments.
- Media fragments can be extracted in the compressed domain, but syntax element modifications are required -> these media fragments seem to be cacheable :-) . For instance, headers containing modified syntax elements could be sent in the first response of the server (as already discussed on this list).
- We use time ranges to cache the media fragments,
- Pro: i) caching will work for the three above described scenarios (i.e., for fragments extracted in the compressed domain and for transcoded fragments). Hence, the way of caching is independent of the underlying formats and adaptation operations performed by the server; ii) four-way handshake can be avoided.
- Cons: i) no support for spatial fragments; ii) concatenation of fragments becomes a very difficult and in some cases maybe an impossible task. To be able to join media fragments, the cache needs a perfect mapping of the bytes and timestamps for each fragment. Furthermore, if we want to keep the cache format-independent, such a mapping is not enough. We also need information regarding the byte positions of random access points and their corresponding timestamps. This way, a cache can determine which parts are overlapping when joining two fragments. Note that this kind of information could be modeled by a codec-independent resource description format. Of course, this works only when it is possible to extract the media fragments in the compressed domain. For joining fragments which are the result of transcoding operations, transcoders are needed in the cache. As you said, the latter operation could introduce a loss of quality, but note that this is always possible with transcoding operations (thus, also if they are transcoded at server-side).
- We use byte ranges to cache the media fragments:
- A summarization page regarding proxies and media fragments is available at HTTP_Fragment_Caches (based on [1] and [2]).