Warning:
This wiki has been archived and is now read-only.
Final Report Ontological Patterns & Solutions
Contents
Ontological Patterns & Solutions
This chapter contains some descriptions of the work process and analysis of the requirements and use cases that was carried out as a part of this incubator. The purpose is to give the reader and idea on one hand of how the incubator worked in order to reach its conclusions, and on the other hand to illustrate and exemplify the general process of proceeding from requirements to modelling solutions.
As basic sources of solutions, we used the Content ODPs available from the ODP Portal. Other interesting resources to reuse would be the LOD vocabularies (a list of common vocabularies is available here), however these were not considered at this time.
Information Flow Use Case Solution
Approach
The Measuring Info Flow use case requires tracking the user's progress (transitions) through a series of relevant decision states. This requirement was similar to the generic Transition pattern already well designed and available in the ontologydesignpatterns.org repository of content patterns. Our approach then was to follow the eXtreme Design (XD) methodology and use the Neon Toolkit modelling environment to import and specialize the pattern as needed, then create instances useful for testing and finally create some SPARQL queries as unit tests to ensure the ontology includes what we need for this use case.
Progress
The Neon Toolkit was used to import the Transition pattern into a new ontology file. The pattern already included classes representing transitions which included states, time intervals, and triggering events. The pattern was specialized by subclassing states to create decisionStates and then further to create states relevant to Information Flow, such as info gathering, info analysis, making a decision product (an information output), sharing the decision (time spent communicating the decision to others), waiting, and gathering feedback.
Instances of the pattern were created for testing. The specific decision concept instantiated is shown in the conceptual diagram below, which shows the time intervals at the bottom, the states, the transitions and the triggering events.
A sample SPARQL unit test was then created showing that we can recover the start and end times of all of the decision states. A screendump of the Neon toolkit below shows the SPARQL query being executed and the returned results.

Impact
This state and time information is key to determining amount of time spent in each state which can then be used to determine how much time is spent in states gathering, digesting and communicating as compared with actual analysis and decision-making. If the right information were available quickly to the right person at the right time, a greater amount of time could be spent analyzing and decision-making. An information format which can represent this information can help with the instrumentation of tools for collection to support a metric for measuring decision flow.
Using Open Linked Data for Decision-Making
Let's say I need to write a report about recent significant earthquakes. To begin, I need to decide what earthquakes are significant. What are my options? First, I note that there is a nice dataset called "Dataset 34" of earthquake data already available in RDF format. (Much thanks and credit to RPI for doing the excellent work on the open linked data. The RDF data representation and sample SPARQL query below are from their page.) The dataset itself is here. The data consists of a list of earthquake "entries" in the following format:
<rdf:Description rdf:about="#entry00002"> <src>ci</src> <eqid>10622493</eqid> <version>1</version> <datetime>Monday, April 19, 2010 05:10:36 UTC</datetime> <lat>32.6808</lat> <lon>-115.8198</lon> <magnitude>1.9</magnitude> <depth>0.10</depth> <nst>27</nst> <region>Southern California</region> <rdf:type rdf:resource="http://data-gov.tw.rpi.edu/2009/data-gov-twc.rdf#DataEntry"/> </rdf:Description>
So this data set looks good and appropriate for helping me with my decision. My decision "options" will be these entries. Now what are my "metrics" for making my decision? Let's assume that I decide that significant earthquakes for my report will be ones within the last 7 days, with a magnitude greater than 3, and a depth of less than 50 miles. And then let's assume I would like to rank those by magnitude. From this assessment of significance, I will choose the earthquakes I wish to include in my report.
SPARQL For Decision Assessment
If I had an ontology that represented these decision concepts (question, options, metrics, assessments, answers), then I could perhaps associate them with the open linked data in a manner that allows me to utilize the open linked data, not just this earthquake data, but any data, to represent and help me make decisions. In fact, SPARQL would allow me to do my "assessment" in this case with the following query:
PREFIX dgp32: <http://data-gov.tw.rpi.edu/vocab/p/32/> PREFIX xsd: <http://www.w3.org/2001/XMLSchema#> SELECT ?id ?label ?datetime ?lat ?lon ?magnitude ?depth ?region ?src ?uri FROM <http://data-gov.tw.rpi.edu/raw/34/data-34.rdf> WHERE { ?uri dgp32:eqid ?id. ?uri dgp32:eqid ?label. ?uri dgp32:region ?region. ?uri dgp32:datetime ?datetime. ?uri dgp32:magnitude ?magnitude. ?uri dgp32:depth ?depth. ?uri dgp32:lat ?lat. ?uri dgp32:lon ?lon. ?uri dgp32:src ?src. filter ( xsd:float(?magnitude) >= 3 && xsd:float(?depth) <= 50 ) } ORDER BY DESC (xsd:float(?magnitude))
In this query, we are pulling out all of the fields from the earthquake data for every earthquake entry where the magnitude is greater than 3 and depth is less than 50 and ordering by magnitude. (NOTE: You can run this query by pasting it into the online SPARQL Query engine at http://www.sparql.org/sparql.html. The dataset itself only contains data within the last week.) If we had an ontology with decision labels, how would this add anything to what is already available? First, they help to make explicit and categorize what is being done with the data. Second, there are aspects of decision-making which involve some extra components or attributes. For example, for many decisions I would like to weight my metrics. In other words, I might not want to weight "magnitude", "depth" and "recency" all the same.
Weighting Metrics
Perhaps I want to give magnitude more weight than depth and depth more weight than recency. Also note that these "metrics" are properties (owl:DatatypeProperty) that associate an object (in this case an earthquake entry) with a literal value (like a float or integer, which is useful for ordering and assessment). So in the general case, consider that a decision-maker might potentially use any owl:DatatypeProperty as a metric (for this data, this might include lat, lon, magnitude, etc.) A user might want a list of the possible "metrics" and then be able to pick and choose. So in the general case, perhaps it would be handy to create an ancillary ontology to an open data ontology and import the latter and say that any owl:DatatypeProperty is a type of "metric". So here's a minimal first step on this "metric" portion of the ontology as it might be used in an application:
1) Define a new class "Metric" and state that "owl:DatatypeProperty" is a subclass of "Metric" 2) Define a property "metricWeight" with domain "Metric" and range "float". 3) Import an open data ontology, like the earthquake dataset. 4) Allow a user to browse through the "metrics", selecting and setting thresholds. 5) Create a SPARQL query as the first cut assessment and ordering of the options. 6) Run the query and present the ordered assessment for user selection & refinement
Metrics for Assessment of Options
The "Metrics for Automatic Assessment" use case requires representing the basic components for describing and utilizing a measurable property for filtering and ordering decision options. These components include the name of the metric, the datatype, the lower and upper thresholds and the ordering (low-to-high or high-to-low) of the measured value. Once a user chooses a given set of options for a given decision question, any DatatypeProperty of those options could be a possible metric. For example, if the question is "What computer should I buy?", then the set of options are available computers and the properties include measurable values such as cost, disk space, cpu speed, and warranty period. If the question is "What city is best for establishing my new business?", then the set of options are cities in the country or region and the properties are things like cost of living, taxes, population size, available facilities, and growth potential. If the question is "What earthquakes are significant in my region for my weekly report?", then the set of options are earthquakes in the last week and the the properties are things like magnitude, depth, and region.
No particular "metric pattern" was identified from the repository of patterns at ontologydesignpatterns.org; however, this particular approach to metrics is still being fleshed out, and the potentially useful patterns still being identified. Some initial thought was put in to some potential patterns, but none were identified at this point. Instead, the basic metric components were modeled directly.
The following ontology in Turtle format was used for the initial modeling:
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>. @prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#>. @prefix dc: <http://purl.org/dc/elements/1.1/>. @prefix xsd: <http://www.w3.org/2001/XMLSchema#>. @prefix dm: <http://www.emAdopters.info/2010/Decisions#>. @prefix ex: <http://www.emAdopters.info/2010/Decisions/purchase/computers/metrics#>. @prefix d34: <http://data-gov.tw.rpi.edu/raw/34/data-34.rdf#>. @prefix dgp32: <http://data-gov.tw.rpi.edu/vocab/p/32/>. @prefix dgtwc: <http://data-gov.tw.rpi.edu/2009/data-gov-twc.rdf#>. @prefix owl: <http://www.w3.org/2002/07/owl#>. #------------------ # CLASSES: Metric #------------------ dm:Metric rdf:type rdfs:Class. #------------------ # PROPERTIES: weight, dataProperty, subMetric, options, lowerThresh, # upperThresh, orderLowToHigh #------------------ dm:weight a owl:DatatypeProperty; rdfs:domain dm:Metric; rdfs:range xsd:float. dm:dataProperty a owl:ObjectProperty; rdfs:domain dm:Metric; rdfs:range owl:Thing. dm:subMetric a owl:ObjectProperty; rdfs:domain dm:Metric; rdfs:range dm:Metric. dm:dataSet a owl:ObjectProperty; rdfs:domain dm:Metric. dm:options a owl:ObjectProperty; rdfs:domain dm:Metric; rdfs:range owl:Thing. dm:lowerThresh a owl:DatatypeProperty; rdfs:domain dm:Metric; rdfs:range xsd:float. dm:upperThresh a owl:DatatypeProperty; rdfs:domain dm:Metric; rdfs:range xsd:float. dm:stringMatch a owl:DatatypeProperty; rdfs:domain dm:Metric; rdfs:range xsd:string. dm:orderLowToHigh a owl:DatatypeProperty; rdfs:domain dm:Metric; rdfs:range xsd:boolean. #--------------------- # INSTANCES: Metrics for a decision assessing earthquake significance # Magnitude, Depth, Region #--------------------- dm:Magnitude a dm:Metric; dc:title "magnitude"; dm:weight 1.5; dm:dataProperty dgp32:magnitude; dm:dataSet <http://data-gov.tw.rpi.edu/raw/34/data-34.rdf>; dm:options dgtwc:DataEntry; dm:lowerThresh 3.0; dm:orderLowToHigh true. dm:Depth a dm:Metric; dc:title "depth"; dm:weight 1.0; dm:dataProperty dgp32:depth; dm:dataSet <http://data-gov.tw.rpi.edu/raw/34/data-34.rdf>; dm:options dgtwc:DataEntry; dm:upperThresh 50.0; dm:orderLowToHigh false. dm:Region a dm:Metric; dc:title "region"; dm:weight 1.0; dm:dataProperty dgp32:region; dm:dataSet <http://data-gov.tw.rpi.edu/raw/34/data-34.rdf>; dm:options dgtwc:DataEntry; dm:stringMatch "Southern California".
A sample SPARQL unit test was then created showing that we can recover the metric components from the sample instances. The query is shown below:
PREFIX : <http://www.w3.org/2002/07/owl#> PREFIX dm: <http://www.emAdopters.info/2010/Decisions#> PREFIX data-gov-twc: <http://data-gov.tw.rpi.edu/2009/data-gov-twc.rdf#> PREFIX dc: <http://purl.org/dc/elements/1.1/> PREFIX owl: <http://www.w3.org/2002/07/owl#> PREFIX p: <http://data-gov.tw.rpi.edu/vocab/p/32/> PREFIX raw: <http://data-gov.tw.rpi.edu/raw/34/> PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> PREFIX xsd: <http://www.w3.org/2001/XMLSchema#> SELECT ?s ?weight ?orderLowToHigh ?dp ?ds ?options ?lt ?ut WHERE { ?s rdf:type dm:Metric; dm:weight ?weight. OPTIONAL {?s dm:orderLowToHigh ?orderLowToHigh.} ?s dm:dataSet ?ds; dm:dataProperty ?dp; dm:options ?options. OPTIONAL { ?s dm:lowerThresh ?lt.} OPTIONAL { ?s dm:upperThresh ?ut.} }
The results of running the query are shown in both Protege and Neon. A screendump of the Neon toolkit below shows the SPARQL query being executed and the returned results. (The results are there but not quite matched up correctly with the columns due to the optional elements not being aligned correctly when some are missing.)
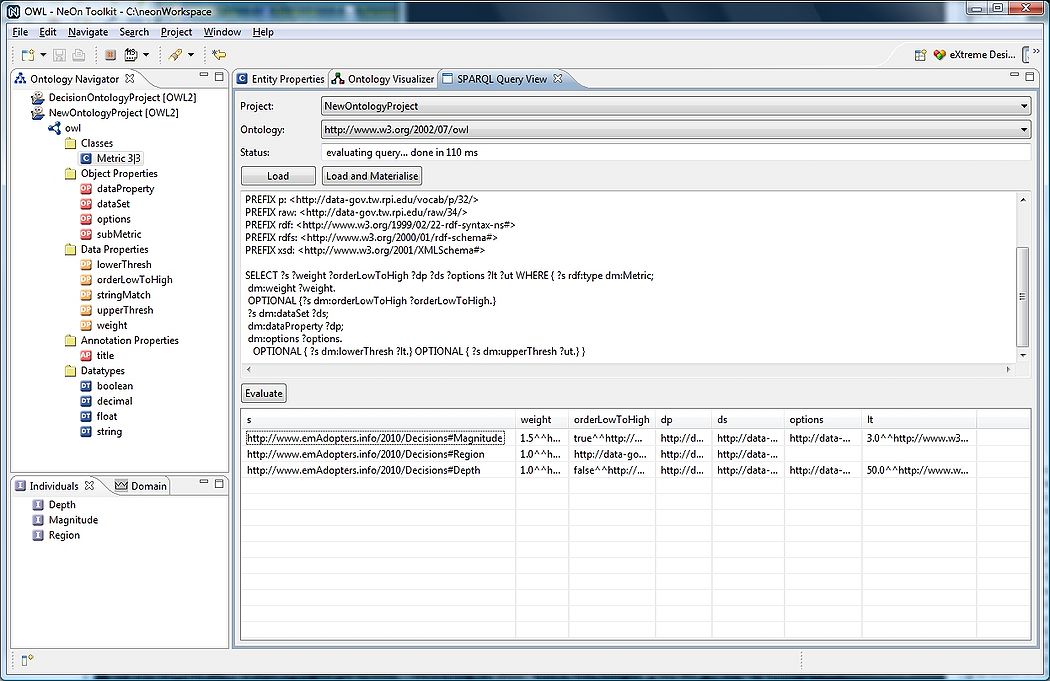
A screendump of the Protege tool below shows the SPARQL query being executed and the returned results.
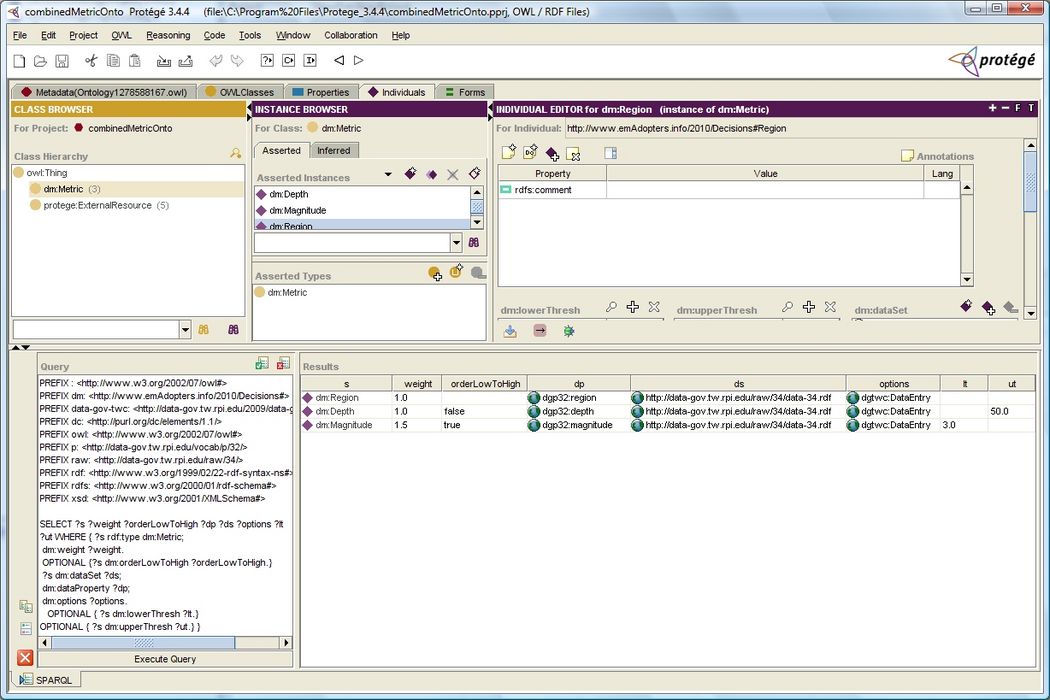
Impact
An appropriate representation of a metric is key to providing important understanding of how a decision is reached. The ability to quantify the metric with appropriate filtering thresholds and weighting allows the metric to be combined with others for an assessment which can be automated as a first-cut ordering of the options. The ability to specify which property of which resource of which dataset corresponds to this metric is important for integrating with and utilizing open linked datasets. The effective representation of metrics will allow them to be documented, accessible, reused and generally managed for improved understanding of how decisions were reached and for training on effective and consistent decision processing.