http://www.w3.org/2004/Talks/0914-tbl-speech/text
Director, World Wide Web Consortium
SpeechTek New York
2004-09-14
Good morning, welcome, and thank you for inviting me to speak today. I'm going to use speech today but without much technology. I won't be using slides, you'll just have an audio channel. So even though I'm not an expert on speech technology -- you all probably know more about it than I do -- I am putting my faith in speech itself as a medium for the next few minutes.
So, as I'm not a researcher at the forefront on speech technology, I'm not going to be telling you about the latest and greatest advances. Instead I come to you, I suppose, with four different roles. One, as someone who spent a a lot of effort getting one new technology, the Web, from idea into general deployment, I'm interested in how we as a technical community get from where we are now to where we'd like to be. Two, as director of the World Wide Web Consortium, I try to get an overall view of where the new waves of Web technology are heading, and hopefully how they will fit together.
With my third hat on I'm a researcher at MIT's Computer Science and Artificial Intelligence Laboratory (CSAIL). MIT, along with ERCIM organization in Europe, and Keio University in Japan, plays host to the Consortium, and I get an office in the really nifty new CSAIL building, the Stata Center. That I like for lots of reasons, one of which is the people you get to talk to. I have chatted to some of my colleagues who actually are engaged in leading edge research about the future.
And fourth, I come as a random user who is going to be affected by this technology and who wants it to work well. It is perhaps the role I'm most comfortable in, because I can talk about what I would like. I don't normally try to predict the future - that's too hard: but talking about what we would like to see is the first step to getting it, so I do that a lot.
When you step back and look at what's happening, then one thing becomes clearer and clearer -- that things are very interconnected. If you are a fan of Douglas Adams and/or Ted Nelson, you'll know that all things are hopelessly intertwingled, and in the new technologies that in certainly the case. So I'm going to discuss speech first and then some of the things it connects with.
Speech is a form of language. Language is what its all about, in fact. Languages of different sorts. Human languages and computer languages. This conference is, in a way, about the difference between them.
Let's think about natural language first. Human language is an amazing thing. Anyone who is a technologist has to be constantly in awe of the human being. When you look at the brain and what it is capable of, and you look at what people are capable of (especially when they actually put their brains into use), it is pretty impressive. And in fact I'm most impressed by what people can do when they get together. And when you think about that, when you look at how people communicate, and you find this phenomenon of Natural Language -- this crazy evolving way words and symbols splash between different people, and while no one can really pin down what any word means, and while so many of the utterances don't even parse grammatically, still the end effect is a medium of great power. And of course among the challenges for speech technology, is that Natural Language varies from place to place and person to person, and, particularly, evolves all the time. That is speech.
Now what is technology? Computer Technology is mostly made up of languages, different sorts of language. The HTML, URIs, HTTP make the web work, all the technology which we develop at the World Wide Web Consortium, not to mention Speech technology, involves sets of languages of a different kind. Computer languages.
The original Web code I wrote in 1990, and the first simple specs of URLs (then UDIs), HTML and HTTP. By 1993 the Web was exploding very rapidly, and the Information Technology sector had got wind of it and was planning how to best use this huge new opportunity. Now, people realized that the reason the Web was spreading so fast was that there was no central control and no royalty fee. Anyone could start playing with it -- browsing, running a server, writing software, without commitment, without ending up in the control of or owing money to any central company. And they knew that it all worked because the standards HTML, URIs and HTTP were common standards. Now I'd written those specs originally and they worked OK, but there was a huge number of things which we all wanted to to do which were even more exciting. So there was a need for a place for people, companies, organizations to come together and build a new evolving set of standards. And still it was important to keep that openness.
The answer was the World Wide Web Consortium, W3C, and all you have to do to join is go to the web site and fill in some forms, pay some money to keep it going, and find some people who can be involved in developing or steering new technology. You'll need engineers, because we build things here, and you'll need communicators because you need to let the community know what your needs are, and you need to make sure your company understands whats happening in W3C, and how it will affect them at every level. The Consortium was around 350 members, and we work in a lot of interconnected areas, from things like HTML and graphics, mobile systems, privacy, program integration which we call Web Services and data integration which we call Semantic Web, ...too many things to name -- go to the web site w3.org for details -- just look at the list of areas in which Web technology is evolving. Speech technology -- recognition and synthesis -- is one of these areas.
So the business we're in is making open common infrastructure which will make the base of a new wave of technology, new markets, and whole new types of business in the future. We all are or should be in that business, and whether we do it well will determine how big a pie the companies here will be sharing in the future.
Hard unbending languages with well defined grammars. Yes, the technical terms in something like VoiceXML are defined in English, typically, which is a natural language -- but English which has been iterated over so much that effectively, for practical purposes, the technical term -- each TAG in VoiceXML, say -- becomes different from a word. While the meaning of english words flows with time, the technical term is an anchor point. The meanings of the terms have been defined by working groups, labored over, established as a consensus and described beyond all reasonable possibility of practical ambiguity in documents we call standards -- or at W3C, Recommendations.
Last Tuesday, we added a new one to that set. After many months of hard work by the Voice Browser Working Group, the Speech Synthesis Markup Language, SSML, became a W3C Recommendation. So now two machines can exchange bits in SSML, and by that can communicate how to synthesize speech. Now speech synthesis systems can be built out of components from different manufacturers because there is a standard bus by which they can be connected. Now you can invest in speech synthesis, in SSML data, and your own in-house applications which produce SSML knowing that the data will retain its value; that it won't commit you to a single technology supplier. This is the sort of thing which builds a market. It is added to the VoiceXML 2.0 spec, and the Speech Recognition Grammar Specification which became Recommendations in March. Coming up, we have Semantic Interpretation ML, and Call Control ML from the Voice Browser working group, and from the MultiModal Working Group, InkML for pen-written information, and the Extended MultiModal Annotation language. So a lot is happening, and it is an exciting time.
I know and you know that the standards picture in this area isn't all that rosy. In the area of integration with HTML, he fact that SALT and HTML+Voice are competing and are not being developed openly in common is one of the major concerns which I hear from all sides -- (except perhaps from those who are betting on taking control of part of the space by controlling a proprietary specification.!)
This sort of tension is the rule for standards. There is always much to be gained by a company that can take control of a space using proprietary languages, and then changing them slightly every year. There is always a lot to be gained by all in terms of a larger market by having open standards. I note that in yesterday's announcement by IBM that some of its speech software will be going open source, Steven Mills says he wants to "spur the industry around open standards". He talks about the need to "get the ecosystem going. If that happens, it will bring more business to IBM". In fact, of many of the areas of W3C work, speech used to have standards but little open source support. It will be interesting to see hoe the IBM contribution affects the take-off of the whole area.
All I'll say about the SALT/HTML+Voice situation now is that a conference like this is a good time to think strategically, to weigh the importance of a solid common foundation for a potentially huge new market area, against short term benefits there might be from developing your own standards, if you are a supplier, or of purchasing non-standard technology, if you are a user.
The infrastructure for the connected technology is made up from such standards, and these standards are written in computer languages, and those are very different from natural language. The difference between natural language and computer languages are the chasm which speech technology is starting to bridge. Speech technology takes on that really difficult task of making computers communicate with people using human speech, trying to enter the world of fuzziness and ambiguity. It is really difficult, because understanding speech is something which human brains can only just do -- in fact you and I learn to talk just slow enough and just plain enough to be just understood well enough by a person. When we are understood very reliably, we tend to speed up or make new shortcuts. So the computer is chasing the human brain, and that is a challenge at the moment.
I'd end this comparison of the two types of language by noting that computer languages do also evolve, though in a different way from natural languages. One of the design goals for the semantic web for data integration is to allow evolution of data systems, to that the new terms can be introduced which are related to but different to the old terms, and to get the maximum interoperability between old and new data and old and new systems. This is one of the uses of the web ontology language, OWL.
So you know where I am as a user, my last conversation with a machine was with a home appliance repair center and was something like the following:
- It
- What would you like to do? You can make, change or cancel an appointment, order a part ...
- me
- [interrupting] make an appointment
- it
- You want to make an appointment, right?
- me
- Right.
- It
- (pause) I'm sorry. Please say "yes" or "no"
- me
- Yes.
- It
- Ok, what sort of a product needs the service? For example, say "refrigerator", or "furnace"
- me
- Washer
- It
- Ok, so you want to make an appointment to service a washer, right?
- me
- Yes
- It
- I'm sorry, I didn't get that.
- me
- Yes!
- It
- Please say yes or no. You want to make an appointment to service a washer, right?
- me
- Yes!!
- It
- I'm sorry. Thank you for calling ____ Customer Service. Have a nice day.
- The good news is, I called back and learned to say yeup, and got through. (The bad news is my washer still isn't working!)
In fact I found the system worked after I'd learned to say Yeup.
(It beat a comparable experience I had with DTMF tones trying to trace an order for a some computer equipment. I called the 1-800 number, went through a DTML tree -- if you want to do this press 1, ... and so on ..if you want to track an order press 9, (9) if it was for a computer press 1 (1), if you want to talk to somebody about it press one (1), and talked to somebody about the problem for 25 minutes, after which she decided to transfer me to someone else. Thoughtfully, she gave me a number to call if I was disconnected. Inevitably, I got disconnected almost immediately. I realized the number she had given me was just the same 1-800 number, so I hit redial. The redial didn't seem to send enough digits, so I had to hang up and dial again. I found my way painfully though the tree to the place I should have been, and talked for another 40 minutes about how to convert my order from something they could not deliver to something that they could deliver. And by the end of the process when I was almost exhausted, and just giving the last element of personal information so they could credit check the new order, my wife came in, "Tim, the police are here", and sure enough in come the local police. They'd had a 911 call, and hadn't been able to call back the line, and so presumed it must be an emergency. Yes, when I had hit redial, my phone had forgotten the 1-800 number, but remembered the DTMF tones from the phone tree; 9-1-1. An interesting system design flaw.)
Now I've talked to a few people before coming here to give this talk. I've chatted with people like Hewlett-Packard's Scott McGlashan, very involved in speech at W3C, and I've also talked to researchers like Stephanie Seneff and Victor Zue at the Spoken Language Systems (SLS) research group at MIT's Computer Science and Artificial Intelligence Laboratory, CSAIL, just along the corridor from my office.
And when I just talked to these people a few things emerge clearly. One is that speech technology itself has a very long way to go. Another thing is that it the most important thing may turn out to be be not the speech technology itself, but the way in which speech technology connects to all the other technologies. I'll go into both those points.
Yes, what we have today is exciting, but it is also very much simpler than the sorts of things we would really like to be able to do.
Don't get me wrong. VXML and SSML and company are great, and you should be using them. I much prefer to be able to use english on the phone to a call center than to have to type in touch-tones. However, I notice that the form of communication I'm involved in cannot be called a conversation. It is more of an interrogation. The data I am giving has the rigidity of a form to be filled in, with the extra constraint that I have to go through it in the order defined by the speech dialog. Now, I know that VoiceXML has facilities for me to interrupt, and to jump out from one dialog into another, but the mode in general still tends to be one of a set of scripts to which I must conform. This is no wonder. The job is to get data from a person. Data is computer-language stuff, not natural language stuff. The way we make machine data from human thoughts has been for years been to make the person talk in a structured, computer-like way. Its not just speech: "wizards" which help you install things on your computer are similar: straightjackets which make you think in the computer's way, with the computer's terms, in the computers' order.
The systems in research right now, like the SLS group's Jupiter system which you can ask about the weather, and its Mercury system which can arrange a trip for you, are much more sophisticated. They allow keep track of the context, of which times and places a user is thinking of. They seem to be happy both gently leading the caller with questions, or being interrogated themselves..
Here is one example recorded with a random untrained caller who had been given an access code. The things to watch for include the machine keeping track context, and of falling back when one tack fails.
[speech audio example of Mercury]
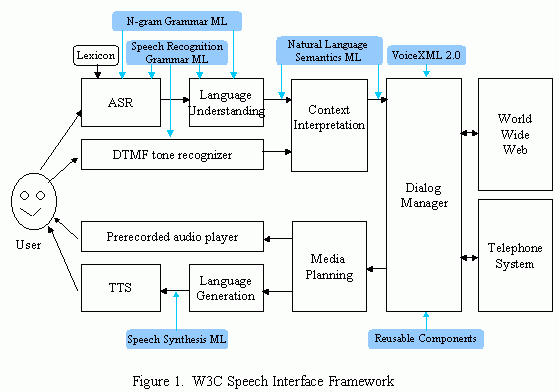
Now In understand that when a machine tries to understand a fragment of speech, or a partly formed sentence, or mumbled words, that the actual decision it makes about which word must have been said is affected by the context of the conversation. This is normal also for people: it is just impossible to extract the information from the noise without some clues. A person sometimes misunderstands a word if he or she is thinking about the wrong subject -- sometimes with amusing consequences, like a Freudian slip in reverse. So this means that speech systems become complex many-layered things in which the higher layers of abstraction feed down information about what the person is likely to be saying. (Or maybe what we would like them to be saying?). So I understand that this is the way speech recognition has to work. But this architecture prevents the speech system from being separated into two layers, a layer of speech to text and a layer of natural language processing. It means that the simple speech architecture, in which understanding is a one-way street from audio to syllables to words to sentences to semantics to actions breaks down.
Figure 1. Speech Interface Framework, from browsing, Introduction to and Overview of W3C Speech Interface Framework. The one-way flow in the top half ignores context information sent back to ASR, which complicates the architecture.
One of the interesting parts of feedback context is when it is taken all the way back to the user by an avatar. Human understanding of speech is very much a two-way street: not only does a person ask questions of clarification, as good speech dialog systems do today. A human also gives low-level feedback with the wrinkling of the forehead, inclining or nodding of the head, to indicate how well the understanding process is going.
What are the effects of having this context feedback in the architecture? One effect is that when a call is passed to a subsystem which deals with a particular aspect of the transaction, or for that matter to a human being, it is useful to pass the whole context. Instead of, "Please get this person's car plate", it is more like "Please take the car plate of a southern male, who likes to spell out letters in international radio alphabet, and is involved in trying to pay his car tax on this vehicle for 2005, and is still fairly patient. The plate numbers of two cars he has registered before are on in this window, and its probably the top one."
Well, because a speech system is not an island.
In fact, these systems also have keyboards. They also have pens.
The big drive, it seems, at the moment, toward speech is the cellphone market. Mobile phones speech is the dominant mode of communication. While they have buttons and screens, they are rather small, and also people tend to use phones when it would be even more dangerous to be looking at the the screen and using the buttons. However, a phone is in fact a device which supports a lot more than voice: you can type, it has a camera, and it has screen. Meanwhile, the boundary of the concepts of "phone" and "computer" are being pushed and challenged all the time by new forms of PDA. The blackberry and the sidekick are between computer phone. The PDA market is playing with all kinds of shapes. Computer LCDs are getting large enough to make a separate TV screen redundant -- and they can be easier to use and program, and accept many more formats, than typical DVD players. PCs are coming out which look more like TVs. France telecom now proposes TV over an ADSL (originally, phone, now internet) line. The television would be delivered by IP. The Internet model is indeed that everything runs over IP, and IP runs over everything. The result is a platform which embraces IP becomes open to very rapid spread of new technologies. This is very powerful. On my phone, for example, I didn't have an MP3 player -- so I downloaded a shareware one written by someone in Romania.
So in the future, we can expect phones, like TVs, to become indistinguishable from small personal computers, and for there to be a very wide range of different combinations of device to suit all tastes and situations.
In fact the ability to view the same information on different devices was one of the earliest design principles of the web: Device Independence. Whereas the initial cellphone architectures such as the first WAP tended to be vertical stacks, and tended to give the phone carrier and the phone supplier a monopoly channel of communication, the web architecture is that any device should be able to access any resource. The first gives great control and short-term profits to a single company; the second creates a whole new world. This layering is essential to the independent strong markets for devices, for communication and for content.
From the beginning, this device independence was a high priority -- you may remember early web sites would foolishly announce that they were only viewable by those with 800x600 pixel screens. The right thing to do was to achieve device independence by separating the actual content of the data from the form in which it happened to be presented. On screens this is done with style sheets. Style sheets allow information to be authored once and presented appropriately whatever size screen you have. Web sites which use style sheets in this way would find that they were more accessible to people using the new devices. Also, they would find that they were more accessible to people with disabilities. W3C has a series of guidelines on how to make your web site accessible as possible to people who for one reason don't use eyes or ears or hands in the same way that you might to access your web site. So the principle of separation of the form and content, and that of device independence, are very important for the new world in which we have such a diversity of gadgets.
However, this only allows for differences in size of screen. Yes, a blind person can have a screen reader read a window - but that isn't a good speech interface.
There is a much more fundamental difference between a conversational interface and a window-based one. It was actually the conversational one which came first for computers. For years, the standard way to communicate with a computer was to type at a command prompt, for the computer to respond in text, and wait for your to type again. As you typed, you could list and change the contents of various directories and files on your system. You'd only see one at a time, and you'd build a mental image of the whole system as a result of the conversation.
When the Xerox Parc machines and the Apple Lisa came out with a screen of "folders", what was revolutionary was that you could see the state of the things your were manipulating. the shared context - the nest structure of folders and files, or the document your are editing, were displayed by the computer and seen at each point by the user, so they were a shared information space with a mutually agreed state. This was so much more relaxing to use because you didn't have to remember where everything was, you could see it at each point. That "wysiwyg" feature is something which became essential for any usable computer system. (In fact I was amazed on 1990 that people would edit HTML in the raw source without wysiwyg editors.)
Now, with speech, we are in the conversational model again. there is no shared display of where we are. The person has to remember what it is that the computer is thinking. The computer has to remember what it thought the person was thinking. The work at SLS and the clip we heard seem to deal with the conversational system quite effectively. So what's the problem?
The challenge in fact is that people won't be choosing one mode of communication, they will be doing all at once. As we've seen, a device will have many modes. and we have many devices. Already my laptop and phone are becoming more aware of each other, and starting to use each other -- but only a little. They are connected by bluetooth - but why can't I use the camera on my phone for a video chat on my PC? Why can't I use my PC's email as a voicemail server and check my email from my phone while I drive in, just as I check my voicemail? To get the most out of computer-human communications, the system will use everything at once. If I call about the weather and a screen is nearby, a map should come up. If I want to zoom in on the map, I can say "Zoom in on Cambridge", or I can point at the map, or I can use a gesture with a pen on the surface -- or I can type "Cambridge", I can use the direction keys, or click with a mouse. Suddenly the pure conversational model, which we can do quiet well, is broken, and so is the pure wysiwyg model. Impinging on the computer are spoken and typed words, commands, gestures, handwriting, and so on. These may refer to things discussed in the past, to things being displayed. The context is partly visible, partly not. The vocabulary is partly well-known clickstream, partly english which we are learning to handle, and partly gestures for which we really don't have a vocabulary, let alone a grammar. The speech recognition system will be biasing its understanding of words as a function of where the user's hands are, and what his stance is.
System integration is typically the hairiest part of a software engineering project: glueing it all together. To glue together a multimedia system which can deal with all the modes of communication at once will need some kind of framework in which the very different types of system can exchange state. Some of the state is hard (the time of the departing plane -- well the flight number at least!), some soft and fuzzy (the sort of time the user was thinking of leaving, the fact that we are talking travel rather than accommodation at the moment). So speech technology will not be in a vacuum. It will not only have to make great strides to work at all -- it will have to integrate in real time with a host of other very different technologies.
I understand now, that there are a number of people here involved in call center phone tree systems? I will not hold your personally responsible for all the time I spend with these systems -- in fact, I know that speech technology will actually shorten the amount of time I spend on the phone. I won't even demand you fix my washing machine.
But while we are here, let me give you one peeve. I speak, I suspect, for millions when I say this. I am prepared to to type in my account number, or even sometimes my social security number. I am happy, probably happier, to speak it carefully out loud. However, once I have told your company what my account number is, I never ever on the same call want to have to tell you again. This may seem peevish, but sometimes the user experience may have been optimized within a small single region, but as a whole, on the large scale, is a complete mess. Sometimes it is little things. Track who I am as you pass me between departments. Don't authenticate me with credit card number and zipcode before telling me your office is closed at weekends. Try to keep you left hand aware of what the right hand is doing.
Actually, I know that this is a difficult problem. When I applied to have my green card extended, I first filed the application electronically, then I went to the office to be photographed, fingerprinted again, and I noticed that not only did each of the three people I talked to type in my application number, but they also typed in all my personal details. Why? Because they were different systems. When I talk to CIOs across pretty much any industry, I keep hearing the same problem - the stovepipe problem. Different parts of the company, the organization, the agency, have related data in different systems. You can't integrated them all but you need to be able to connect them. The problem is of integrating data between systems which have been designed quite independently in the past, and are maintained by different groups which don't necessarily trust or understand each other. I mention this because this is the problem the semantic web addresses. The semantic web standards, RDF and OWL, also W3C Recommendations, are all about describing your data, exporting it into a common format, and then explaining to the world of machines how the different datasets are actually interconnected in what they are about, even if they were not physically interconnected. The Semantic Web, when you take it from an enterprise tool to a global system, actually becomes a really powerful global system, a sort of global interconnection bus for data. Why do I talk about this? Because the semantic web is something people are trying to understand nowadays. Because it provides a unified view of the data side in your organization, it is important when we think about how speech ties in with the rest of the system. And that tying in is very important.
When you use speech grammars and VoiceXML, you are describing possible speech conversaions. When you use XML schema, you are describing documents. RDF is different. When you use RDF and OWL, you are talking about real things. Not a conversation about car, or a car licence plate renewal form, but a car.
The fact that a form has one value for a plane number will pass with the form. The fact that a car has one unique plate number is very useful to know - it constrains the form, and the speech grammars. It allows a machine to know that two cars in different databases are the same car.
Because this information is about real things, it is much more reusable. Speech apps will be replaced. Application forms will be revised, much more often than a car changes its nature. The general properties of a car, or a product of your company, of real things, change rarely. They are useful to many applcations. This background information is called the ontology, and OWL the language it is written in.
And data written in RDF labels fields not just with tag names, but with URIs. This means that each concept can be allocated withou clashing with someone else's. It also means that when you get some semantic web data, anyone or anything can go look up the terms on the web, and get information about it. Car is a subclass of vehicle.
It is no use having a wonderful conversation with a computer about the sort of vacation you would like to have, if at the end of the day you don't have a very well-defined dataset with precise details of the flights, hotels cars and shows which that would involve. Data which can be treated and understood by all the different programs which will be involved in bringing that vacation into existence. There is a working draft Semantic Interpretation for Speech Recognition which is in this area, although hit does not ground the data in the semantic web.
At the moment speech technology is concentrated in business-consumer (b2c) applications, where it seems the only job is to get the data to the back-end. But I'd like to raise the bar higher. When I has a consumer have finished a conversation and committed to buying a something, I'd like my own computer to get a document it can process with all the details. My computer ought to be able to connect it with the credit card transaction, and tax forms, expense returns and so on. This means we need a common standard for the data. The semantic web technology gives us RDF as a base language for this, and I hope that each industry will convert or develop the terms which are useful for describing products in their own area.
In fact, the development of ontologies could be a a great help in developing speech applications. The ontology is the modeling of the real objects in question -- rental cars flights and so on, and their properties - number of seats, departure times and so on. This structure is the base of understanding of speech about these subjects. It needs a lot of of added information about the colloquial ways of talking about such things. So far I've discussed the run-time problem -- how a computer can interact with a person. But in fact limiting factors can also be the problems designers have creating all the dialogs and scripts and so on which it takes to put together a new application. In fact the amount of effort which goes into a good speech system is very great. So technology which makes it easier for application designers can also be a gating factor on deployment.
The picture I end up when I try to think of the speech system of the future is a web. Well, maybe I think of everything as a web. In this case, I think of a web of concepts, connected to words and phrases, connected to pronunciation, connected to phrases and dialog fragments. I see also icons and style sheets for physical display, and I see the sensors that the computer has trained on the person connected to layers of recognition systems which, while feeding data from the person, are immersed in a reverse stream of context which directs them as to what they should be looking for.
Speech communication by computers has always been one of those things which seemed to more difficult that they seemed at first - though five decades.
It happens that as I was tidying the house the other day I just came across a bunch of Isaac Azimov books, and got distracted by a couple of stories from Earth is Room Enough. In most Azimov stories, computers either communicate very obscurely using teletypes, or they have flawless speech. He obviously thought that speech would happen, but I haven't found any stories about the transition time we are in now. The short story Someday is one of the ones of the post-speech era. At one point the young Paul is telling his friend Niccolo how he discovered all kinds of ancient computer -- and these squiggly things (characters) which people had to use communicate with them.
"Each different squiggle stood for a different number. For 'one', you made a kind of mark, for 'two' you make another kind of mark, for 'three' another one and so on."
"What for?"
"So you could compute"
"What for? You just tell the computer---"
"Jiminy", cried Paul, his face twisting in anger, "can't you get it though your head? These slide rules and things didn't talk."
So Asimov certainly imagined we'd get computers chatting seamlessly, and the goal seems, while a long way off no, attainable in the long run. Meanwhile, we have sound technology for voice dialogs which are developed part prototypes the level of standards. The important thing for users is to realize which is possible and what isn't, as it is easy to expect the world and be disappointed, but also a mistake to realize that here is a very usable technology which will save a lot of time and money. And please remember that when you think about saving time, its not just your call center staff time, it is the user's time. It may not show up directly on your spreadsheet, but it will show up indirectly if frustration levels cause them to switch. So use this conference to find out what's happening, and remember to check about standards conformance.
In the future, integration of speech with other media, and with semantic web for the data, will be a major challenge, but will be necessary before the technology can be used to its utmost.