...are natural, more accessible (people-wise and device-wise)
And so are becoming more and more popular: call centres, voicemail, etc.
Progress on speech recognition and synthesis makes it work even better now.
Voice is an easy way to access information, and the Web is the biggest source of information ever
But there are things missing to make it work:
The Web needs voice: it is too visual right now, not quite accessible to all devices, all users
And voice applications (any application in fact) needs the Web: who wants to use a computer that's not connected to the Net?
So people are taking the matter in hand and are working at W3C to define standards to make voice work with the Web.
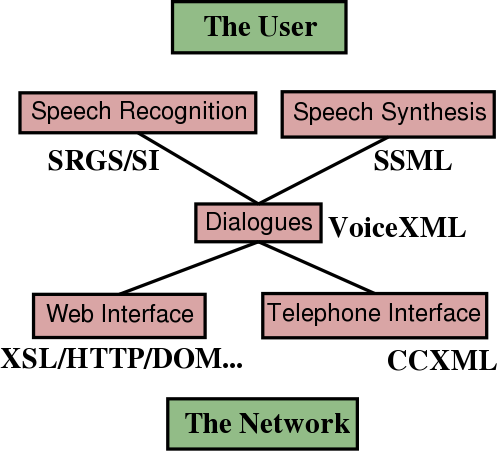
Need to divide and conquer: very different disciplines: speech recognition/synthesis, interpretation, interaction etc.
Dividing the framework also allows it to be used for other purposes.
The first goal of standardising a paradigm is to split the problem in workable units. Because speech technology is quite different disciplines, it's important to divide the work and assign parts to specialists in those parts.
If each part is independent enough, it could be used for different goals than the Web: voice synthesis in train stations
We'll quickly go through each of SRGS, SSML, VoiceXML and CCXML and we'll follow on to the Web interface.
The Speech Synthesis Markup Language
A W3C Recommendation soon (now in PR)
TTS works well, but need help.
Speech Synthesis demo1, demo2.
Text-to-speech gets better and better, but it is never sufficient in some situations (and a human would not do better in the same situation): pronouncing proper names, other languages, etc. It is also useful to specify the voice type: male/female, age, etc.
<speak version="1.0" xmlns="http://www.w3.org/2001/10/synthesis" xml:lang="en-US">
<voice gender="female">
Hi, this is Max's computer...
</voice>
<voice age="6">
Hello <prosody contour="(0%,+20Hz)(10%,+30%)(40%,+10Hz)">world</prosody>
</voice>
</speak>
Speech Recognition Grammar Specification
Speech recognition needs hints on what to expect when recognising voices.
<grammar xmlns="http://www.w3.org/2001/06/grammar">
<rule id="yes">
<one-of>
<item>yes</item>
<item xml:lang="fr-CA">oui</item>
</one-of>
</rule>
<rule id="state" scope="public">
<one-of>
<item>Florida</item>
<item>North Dakota</item>
<item>New York</item>
</one-of>
</rule>
</grammar>
A language adapted to voice interaction
Instances of VoiceXML, basically, a finite state automaton:
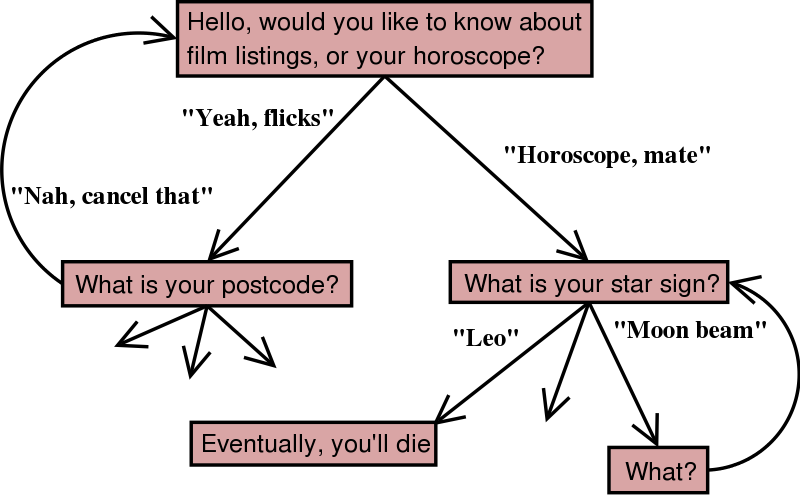
Features: menus, form filling (variables), tapered prompts, sessions.
A dialogue language is necessary, HTML won't do: voice is linear, needs special kind of navigation (repeat), markup needs information on what to expect as input (DTMF, Voice), voice reco needs several trials.
But VoiceXML has been a satisfactory solution for voice applications (original requirements for VoiceXML)
<vxml version="2.0" lang="en">
<form>
<field name="city">
<prompt>Where do you want to travel to?</prompt>
<option dtmf="1">Edinburgh</option>
<option dtmf="2">New York</option>
<option dtmf="3">London</option>
<option dtmf="4">Paris</option>
<option dtmf="5">Stockholm</option>
</field>
<field name="travellers">
<grammar type="application/srgs+xml" src="/grammars/number.grxml"/>
<prompt>How many are travelling to <value expr="city"/>?</prompt>
</field>
<block>
<submit next="http://localhost/handler" namelist="city travellers"/>
</block>
</form>
</vxml>
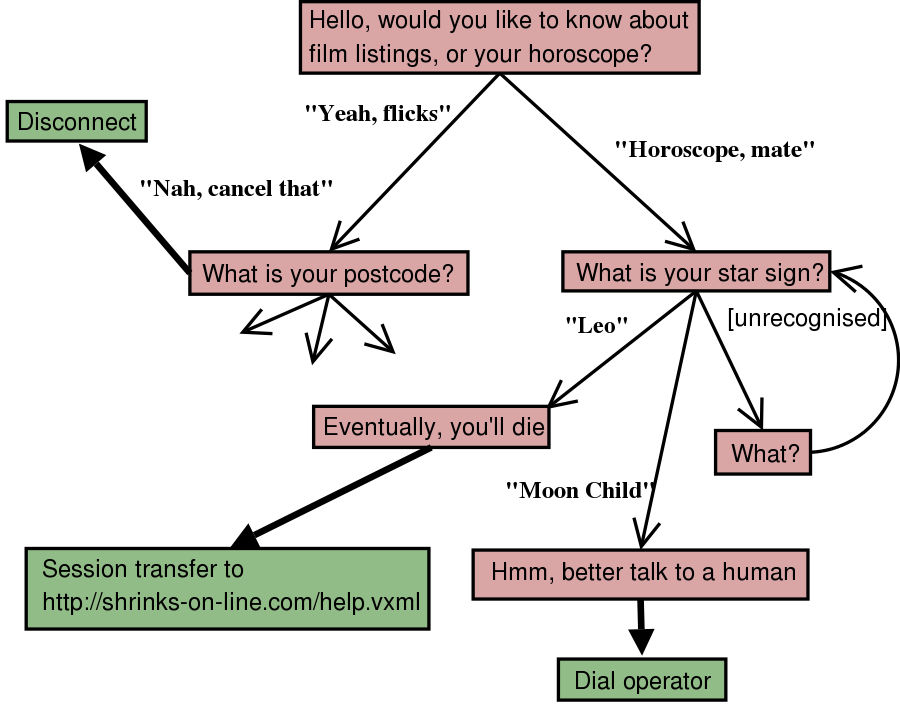
(currently in Last Call)
CCXML adds even more telephony feature to CCXML, mostly through event support
Allows prefetch control, error handling when executing a VoiceXML session, user hangup, conferences, callout, etc.
Calling Card Application: Caller calls an 800 number and after some interaction with an IVR system places and outbound call to a friend.
<ccxml xmlns="http://www.w3.org/2002/09/ccxml"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.w3.org/2002/09/ccxml
http://www.w3.org/TR/ccxml/ccxml.xsd" version="1.0">
<!-- Create our ccxml level vars -->
<var name="in_callid" expr="''" />
<var name="out_callid" expr="''" />
<!-- Set our initial state -->
<assign name="currentstate" expr="'initial'" />
<eventhandler statevariable="currentstate">
<!-- Deal with the incoming call -->
<transition state="initial"
event="connection.ALERTING" name="evt">
<assign name="in_callid" expr="evt.callid" />
<accept callid="in_callid" />
</transition>
<transition state="initial" event="connection.CONNECTED"
name="evt">
<assign name="currentstate" expr="'in_vxml_session'" />
<!-- VoiceXML dialog is started on a separate
thread - see pin.vxml -->
<dialogstart callid="in_callid" src="'pin.vxml'" />
</transition>
<!-- happens when pin.vxml VoiceXML dialog thread exits -->
<transition state="in_vxml_session" event="dialog.exit" name="evt">
<createcall dest="evt.values.telnum" name="out_callid" />
<assign name="currentstate" expr="'calling'" />
</transition>
<transition state="calling" event="connection.FAILED" name="evt">
<!-- tell the caller there was a error -->
<dialogstart callid="in_callid" src="'error.vxml'" />
<assign name="currentstate" expr="'oub_failed'" />
</transition>
<!-- happens when called party picks up the phone -->
<transition state="calling" event="connection.CONNECTED"
name="evt">
<assign name="out_callid" expr="evt.callid" />
<!-- tell the callee he is receiving a call -->
<dialogstart callid="out_callid" src="'callee.vxml'" />
<assign name="currentstate" expr="'outb_ready_to_join'" />
</transition>
<transition state="oub_failed" event="dialog.exit" name="evt">
<exit />
</transition>
<!-- happens when callee's vxml dialog (callee.vxml exits) -->
<transition state="outb_ready_to_join" event="dialog.exit"
name="evt">
<join id1="in_callid" id2="out_callid" />
<assign name="currentstate" expr="'wtg_for_joined'" />
</transition>
<transition state="wtg_for_joined" event="ccxml.joined"
name="evt">
<assign name="currentstate" expr="'active'" />
</transition>
<!-- Lets clean up the call -->
<transition state="active" event="connection.DISCONNECT"
name="evt">
<if cond="evt.callid == in_callid">
<disconnect callid="out_callid"/>
<exit />
</if>
<assign name="currentstate" expr="'in_vxml_session'" />
<!-- start VoiceXML dialog again to see
if caller wants to make another call -->
<dialogstart callid="in_callid" src="'pin.vxml'" />
</transition>
<!-- Catch disconnects in unexpected states -->
<transition event="connection.DISCONNECT">
<exit />
</transition>
</eventhandler>
</ccxml>
From hand-written static applications, to database-backed dynamic generation.
The standards are open, so applications are free to use them in any way they like, in particular generate them from other sources, like databases.
So far we've described closed systems though, which is currently what VoiceXML is currently most used for. But what about accessing the Web by voice? Well, the Web is a "database" after all...
VoiceXML is not HTML! So how are we going to make voice work on the Web? How is the Web going to be accessible?
VoiceXML works better for voice dialogues, while HTML works better for visual documents.
So each works great for its purpose, yet it is possible to make them work together...
HTML is not a language designed for voice interaction. Pages can be read, but more interaction than with HTML is necessary. Go back, repeat, help, etc. It could be done with several HTML pages with links and forms, but it would be much more complex than a single VoiceXML file.
No adaptation: two versions of the same page, one in VoiceXML and one in HTML.
VoiceXML and (X)HTML have lots in common already. XML syntax, URIs.
Therefore Web technology can be applied: HTTP (VoiceXML server by Web servers), XSLT, DOM.
Making it possible to transform and adapt content.
For instance one could easily convert a simple HTML page into VoiceXML:
<transform xmlns="http://www.w3.org/1999/XSL/Transform" version="1.0>
<template select="html">
<vxml><apply-templates/></vxml>
</template>
<template select="p">
<block><apply-templates/><block/>
</template>
</transform>
One position is that Voice and Visual are too different and that it's pointless to try and have a common content (written in a modality independent fashion). But writing and maintaining two versions of the individual information is costly.
However, the two languages do have a lot in common: the XML syntax, their use of URIs. And this makes it easier to either produce them from a single source, or convert one to the other.
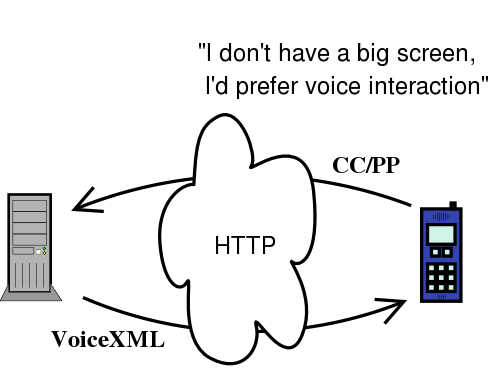
This adaptation could happen in the client, or on the server, or be adapted to the device using the whole Web infrastructure

Content Capabilities/Preference Profiles
<ccpp:component>
<rdf:Description
rdf:about="http://www.example.com/profile#TerminalHardware">
<rdf:type
rdf:resource="http://www.example.com/schema#HardwarePlatform" />
<ex:displayWidth>320</ex:displayWidth>
<ex:displayHeight>200</ex:displayHeight>
</rdf:Description>
</ccpp:component>
A profile such as above can be passed along with an HTTP request to help the server adapt its content
W3C has a solid platforms for all voice applications, there are just a couple of specifications to finalise. However the group will not stop there. New requirements arise, to keep up with both developments of the Web, and developments of voice platforms
VoiceXML 2.1. New features: dynamic grammar/script references, fetching external data, recording utterances, etc.
Say-as: one particular element of SSML: how to specify regional/foreign accents is difficult, and more control is requested than what's the current spec.
Lexicons, n-grams, VoiceXML session transfer, etc.
The next generation of dialogue languages
So far only requirements have been expressed: ongoing integration with ongoing web technology (CSS3 speech), integrating Voice controls within voice languages (XHTML+Voice, SALT).
Need a more general idea of interacting, and a more general way to access the Web using any device.
Not just Voice but also pens, gestures, etc. all together.
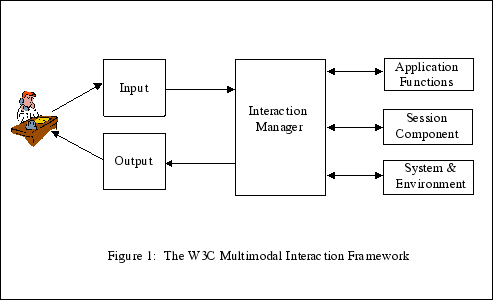
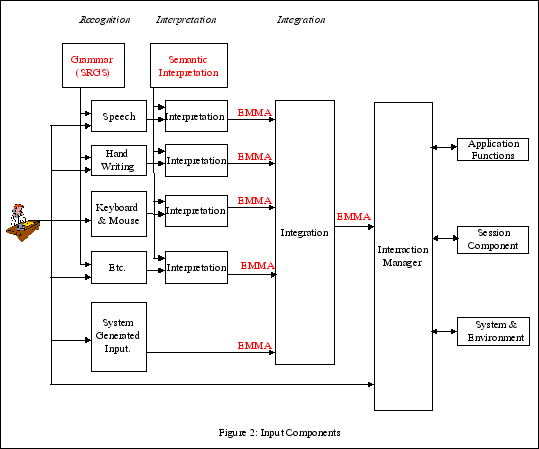
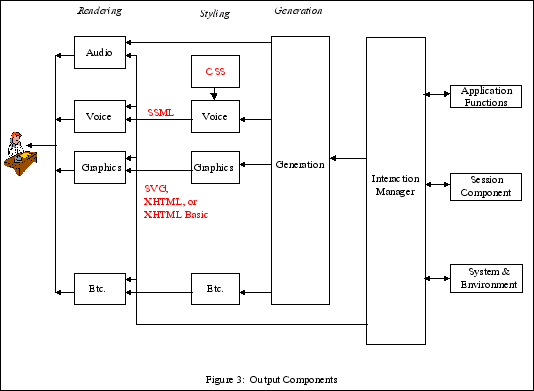
In terms of human interaction, voice the easiest and fastest means, when it comes to requesting information.
With computers, it should be the same, but it isn't yet because voice synthesis and recognition is hard.
However, because of the growing mobile phone market and the progress in voice technologies, things are getting better and interacting with computer by voice is becoming a reality.