When a URI appears in data intended for consumption by applications, sometimes the data gives information about the content that can be retrieved from that URI, such as a biography or an image, while in other cases it gives information about the entity described or depicted by what is retrieved, such as a person or a farm. It's always useful to be able to retrieve the content at the URI, since the application can get either the entity or its description, and thus learns more about what is being talked about. While humans can usually discriminate between these different modes of using URIs based on what "makes sense", applications cannot in general do so. Therefore, in standard formats for data, where we want reliable conclusions to be drawn from the data by an application, the context in which the URI occurs must make clear which mode is intended in each case.
This document addresses this problem by describing how to define data formats and publish the information necessary to support an application in determining which of mode is intended when it encounters a URI in data.
This is an Editor's Draft which the TAG intends to become a Working Draft on the Recommendation track at W3C.
Introduction
Applications operate based on data that they receive or collect. For example, an application that works as an HTTP server might be sent data through an HTTP POST or PUT request. A mobile app might collect data by requesting it through GET requests on a web API.
The data that an application receives is a sequence of bits. The application interprets those bits through a series of processes — decoding, parsing, transforming and so on — to create an internal model based on which it can act. When the data includes URIs, those URIs may be used to inform the processing that builds the internal model, and the internal model may eventually include things that are named using the URIs that appeared in the data. Most importantly, the internal model may include content retrieved by resolving the URIs in the original data, and associate properties with that content based on the information associated with the URI in the original data.
For example, Paul Downey has created an image of his poster The URI Is The Thing and made it available on a photo sharing site. Let us imagine that the photo sharing site exposes information about the poster in a number of ways, including through a JSON API. The JSON might look something like:
In this case, say the URI http://photo.example.com/psd/12345/original.jpeg resolves to a sequence of bits that encodes a JPEG image, and the JSON provided by the photo sharing site is intended to inform applications that that JPEG image was created by Paul Downey and can be reused elsewhere as long as it is attributed (as indicated by the licence). Knowing this, an application that accessed JSON from the site that included the above data could retrieve, store and process the bits retrieved from http://photo.example.com/psd/12345/original.jpeg (for example to extract EXIF data from the JPEG).
In other cases, as described in , URIs used within data might point to landing pages which describe the thing that has the properties specified in the data rather than being the thing that has those properties. To communicate effectively, data providers and applications need to have an agreed understanding about whether a given property provided in some data applies directly to the content at the given URI or to the thing that content describes. This document provides terminology and best practices to facilitate that shared understanding.
This document purposefully does not address the question of what a context-free URI (for example, one on the side of a bus) identifies, or how this might be discovered. It is purely concerned with how an application can work out whether an assertion about a URI within some data is an assertion about the content found at that URI or about the thing described by that content.
Terminology
There are lots of different ways of expressing data about things, the main standard ones currently in use on the web being JSON, XML and RDF. These are interpreted by applications into internal models. For the purpose of this document, we use the term entity for a thing about which we're passing information, and property as an asserted fact about an entity. An entity commonly has a corresponding data structure within an application, and properties are fields of that data structure.
In this document, we mostly use JSON to express information about entities, using the JSON-LD convention of using @id as the means of providing a URI to name the entity. The same information could equally be expressed in XML in a variety of ways, such as:
The same considerations apply when URIs are used to name entities, regardless of the format that is used to express the data.
Landing Pages and Records
A landing page is any page whose primary purpose is to contain a description of something else. Landing pages often provide summaries or additional information about the thing that they describe. Examples are landing pages for images on Flickr or videos on YouTube, which are HTML pages that embed the media that they describe and provide access to comments and other metadata about it. Landing pages for documents are often tables of contents or abstracts.
For example, say that the photo sharing site from the earlier example published an HTML page about The URI Is The Thing at http://photo.example.com/psd/12345 which acts as a landing page for the photo, enabling people to add comments about it and providing links to other pictures by Paul Downey and so on. In this scenario, the site might publish the JSON:
Unlike the previous example, here it is not the case that the content an application gets when it resolves the value of the @id property (http://photo.example.com/psd/12345) is an image (contrary to the assertion of the type property) — it is an HTML page. Similarly, the content of the HTML page is not created by Paul Downey — it is created by the photo sharing site. The HTML page is not available under the CC-by licence — the photo sharing site holds the copyright. Thus the properties that are associated with the URI http://photo.example.com/psd/12345 within the data do not apply to the content provided at that URI, but to the image for which the HTML page is the landing page.
This pattern also occurs with URIs that resolve to content that is not HTML: APIs that provide data in JSON, XML or RDF usually use URIs within that data which provide locations from which further information about the entities associated with the URIs can be discovered, again in JSON or XML or RDF. These JSON, XML or RDF records are the machine-readable equivalent of HTML landing pages: they describe the image, video or other thing rather than being a sequence of bits that is that thing.
Thus the same considerations would apply if the photo sharing site published the JSON above at the URI http://photo.example.com/psd/12345. The JSON that's published at that URI is not an image, it is a record. The site could alternatively use content negotiation to determine whether a given application receives the JSON or the HTML or some other format.
If the URI http://photo.example.com/psd/12345 supported content negotiation such that a request with Accept: text/html provided an HTML page but a request with Accept: image/jpeg returned the image, the URI is being used to identify two distinct resources: the image and the landing page. As discussed in The Architecture of the World Wide Web [[WEBARCH]], this pattern should be avoided: different resources should be named with different URIs.
The photo sharing site may add information that is about the HTML landing page at the URI to the JSON data that it publishes. For example they might add a last-modified date that indicates the date and time that the landing page was last modified:
Doing this is potentially confusing because a developer simply looking at the output of the API and trying to make sense of it might assume that because the rest of the properties associated with http://photo.example.com/psd/12345 (such as creator or license) apply to the image described by the landing page at that URI, the last-modifiedproperty must apply to that image as well, when in fact it applies to the HTML landing page. Later sections describe methods for publishers to avoid confusing developers in this way.
While the above example is of a landing page for an image where the image itself is available elsewhere on the web, publishers also provide landing pages for things that aren't available on the web, such as people or pieces of furniture. For example, the photo sharing site might publish a landing page for Paul Downey:
When data is about something like a person or piece of furniture, it is usually obvious (to developers, who understand the world) that a given property, such as nickname or dimensions, doesn't apply to the landing page but to the person or piece of furniture that it describes. On the other hand, when the data is about something whose content could exist as data on the web, such as a photograph or a book or a film, that thing will often have properties that could equally apply to the landing page itself, such as creator or last-modified.
Documenting Properties
As we have seen, the properties used within data need to be documented to avoid developer confusion about what entities they apply to. A data format that mixes properties about landing pages or records and properties about the things those landing pages or records describe is not necessarily ambiguous: all that's required for developers to understand what the properties actually apply to is for the meaning of the property to be documented.
We recommend the use of the following terms to describe properties within such documentation:
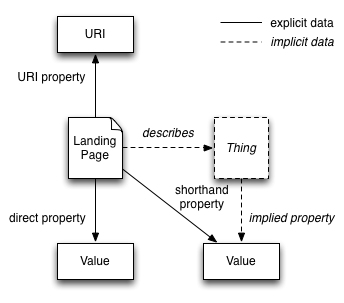
URI property
a property that holds a URI for an entity to which the properties in the data are associated, often named something like @id or url
direct property
a property that applies to the content retrieved from the URI given in the URI property for an entity (which may or may not be a landing page or record)
The following diagram shows how these properties interact:
Property categories
The term shorthand property can be used in a variety of cases, and documentation about shorthand properties needs to be particularly explicit about how they should be interpreted, as described in the following sub-sections.
a shorthand property that implies the thing the landing page describes has the specified type
creator
a shorthand property that implies the thing the landing page describes has the specified creator
license
a shorthand property that implies the thing the landing page describes has the licence whose content is found at the location given
last-modified
a direct property which indicates when the content of the landing page was last modified
In this cases, "has type", "has creator" and "has license" are implied properties which might not be described explicitly in the documentation. Graphically, we have:
Implied properties
URI Values
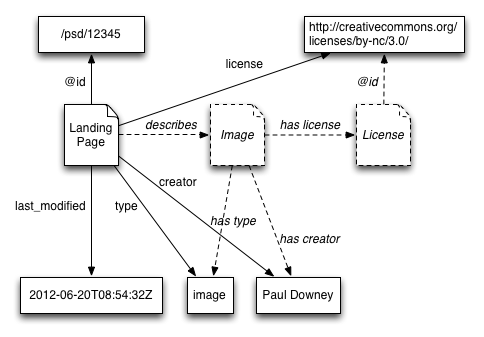
Properties may have values that are themselves URIs. In these cases, the property documentation should make clear whether the entity URI (provided by the URI property such as @id) points to a landing page or record, or the value URI (given in the value of the individual property) points to a landing page or record, or both. For example, in a case such as:
both the creator and the license properties are shorthand properties of the image described by the landing page at the entity URI http://photo.example.com/psd/12345. However, the value of the creator property is also a landing page, this time for Paul Downey, whereas the value of the license property actually points to the content of the licence.
Properties between entities that are implied due to a property asserted between two landing pages or records are called parallel properties because in a diagram that shows the relationships between the landing pages and between the entities, these kinds of implied properties will appear parallel to the shorthand property.
The following diagram shows the creatorshorthand property, whose value is a URI that points to a landing page, and how this property implies the existence of two entities — an image and a person — and a "has creator" relationship between those entities.
URI Values
Multi-Faceted Landing Pages and Records
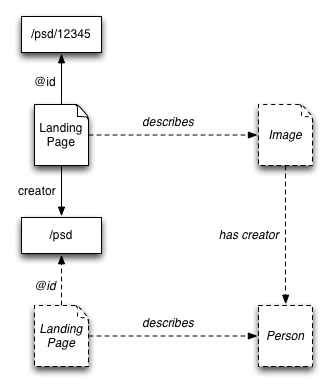
Sometimes landing pages or records are about more than one thing, or the thing that they describe is functionally related to other things. In the example we've been using, the image http://photo.example.com/psd/12345/original.jpeg is actually a photograph of a poster which is about the web. What if the photograph of his poster had been taken by someone other than Paul Downey, and this was captured within the data? The JSON about its landing page might be:
In this case, the photographer property relates to the photograph described by the landing page at http://photo.example.com/psd/12345 whereas the creator property relates to the artwork that was photographed.
As this example shows, it is helpful to document the kind of the thing described by a landing page or record that a given property relates to. This enables an application, if it chooses to, to build an internal model of the data that includes separate entities for the landing page, each of the things that are described by the landing page, and the ways in which they are related.
In the example above, the documentation might include:
photographer
a shorthand property that implies the landing page is about a photograph that was taken by a photographer with the given name
creator
a shorthand property that implies the landing page is about a creative work that was created by someone with the given name
Combining Data
One of the benefits of naming an entity with a URI is that it enables multiple sources of information to associate data with that entity by referring to the same URI. For example, a social networking site may provide JSON that states that someone likes the image described by http://photo.example.com/psd/12345:
Here we assume that the likes property is defined as a shorthand property that implies that the content of the page at http://photo.example.com/psd/12345 describes the thing that is liked. Without such documentation, some applications might adopt an alternative interpretation: that Dirk likes the web page at http://photo.example.com/psd/12345.
A review site might similarly provide JSON that describes a review of the image at http://photo.example.com/psd/12345 (again we assume here that the documentation of the subject property describes that the review is about the thing described by the landing page at the given URI):
As discussed in , the landing page at http://photo.example.com/psd/12345 may describe many things. If a search engine or other application were to merge the information from the three sites, it would need to associate both the "like" and the review to the same entity — the image.
The publishers of the image could help applications to combine information about the image across the sites accurately by supplying a separate URI for the image itself, linked to from the landing page with a specific relationship (such as describesImage) through a Link: HTTP header or a <link> element within the landing page. To be clear about what is being liked or reviewed, the social media site and the review site could either reference that image directly, or describe their shorthand properties in terms of the describesImage property of the landing page.
Locating Property Documentation
The previous sections have discussed how important it is to have documentation that includes information about how URIs used within data should be interpreted and specifically whether properties within the data apply to the content found at a URI or to something that content describes. This documentation should be published somewhere such that it's possible for those developers to find it. Possible routes for doing this explicitly include:
if the data is provided through a protocol that supports it, such as through HTTP, by explicitly indicating the media type of the data, and registering that media type such that documentation can be found for it through the IANA media type registry
if the media type is generic (such as application/json), by providing supplementary documentation through a profile link relationship, for example within a HTTP Link: header
embedding links to the documentation within the data itself, for example through a resolvable XML namespace or @xsi:schemaLocation attribute in XML or by using resolvable URIs for classes and properties in RDF
Developers should be able to locate this documentation through a mechanism that isn't a search against the Internet. If the property documentation should be accessed through resolving URIs within the data (the last of the options above), this mechanism should be specified within the media type definition or the documentation provided through the profile link relationship.
What if the data isn't made available by HTTP and you therefore don't have a media type: how does follow-your-nose work in that case? For example, if the data is provided via FTP or embedded within a textual email message.
Recommendations
This section makes concrete recommendations for data consumers, data publishers and the authors of specifications that use URIs, based on the discussion above.
Authoring Specifications
Data formats that include URIs should specify what properties an application can associate with the entities named by those URIs, based on how the URIs are used within the document and on the other data found within the document. They should also specify what applications can expect to find at the end of these URIs: in particular whether the URI is being used to reference the content found at that URI, or something described by that content.
For example, the XML Recommendation [[XML10]] specifies that URIs used within the <!DOCTYPE> declaration must resolve to documents that are well-formed external subsets: this places some clear expectations on what publishers should publish at these URIs, and on implementers in terms of how applications should process them.
By contrast, the Namespaces in XML Recommendation [[XML-NAMES]] does not specify how the URIs used within XML namespace declarations should be processed, over and above how to compare them. It does not say whether applications can resolve them, or what should be found if they are resolved. The Architecture of the World Wide Web states that these URIs should resolve to "namespace documents", but leaves open whether these should be machine-readable schemas, or landing pages from which schemas can be located, as described in the TAG Finding Associating Resources with Namespaces.
Formats that are designed to be used to provide metadata about HTML pages, images, video and other information on the web should default to an interpretation in which properties are associated with the content that is found by resolving the URIs. Those that are designed to encode data about things that are not found on the web should default to an interpretation in which the properties are associated with the things that described by the documents located by the URIs.
Specifying Metaformats
Metaformats such as RDF that incorporate URIs as part of their core information model should document the default interpretation of those URIs: whether properties for which no other information is available should be interpreted as applying to the content available at those URIs or the things those documents describe.
Metaformats may delegate how properties are interpreted to individual vocabularies that use the metaformat, such that different properties within a vocabulary using the metaformat fall into different categories, as described in . Making the interpretation of a URI dependent on the property with which it is used requires applications to have information about the particular vocabulary being used in order to know what to do with a URI. Most applications need to understand a vocabulary being used to take relevant action on the basis of a set of data, but generic applications will benefit from schema languages that encode this information in a machine-readable way, as described in .
Specifying Vocabularies
Authors of vocabularies that are used with metaformats such as XML, JSON or RDF and that reference URIs should document how data expressed in those vocabularies should be interpreted. The vocabulary should be documented in terms of the entities that data using that vocabulary describes, and how the properties within the vocabulary should be interpreted, whether as being properties of content on the web located at the referenced URIs or of the things described by landing pages or records located at those URIs. This interpretation may vary on a property-by-property basis, in which case the properties should be documented using the terminology given in .
Specifying Schema Languages
Schema languages should include mechanisms for indicating the category of a property as described in . This encourages vocabulary authors to be explicit in their property documentation, and it enables applications to automatically create a suitable internal model, without prior knowledge of the vocabulary.
In some cases, vocabulary authors may wish to provide names within a vocabulary for implied properties in order to express the relationship between them and shorthand properties. Alternatively, the presence of shorthand properties within data that uses one vocabulary may imply the existence of entities with properties from a different vocabulary. Schemas may provide the facility to specify the implications of the presence of each shorthand property in terms of implied entities and their properties.
Consuming Data
Applications that consume data on the web may need to determine, based on a given set of data, which properties can be associated with the content found on the web at a given URI. Applications that commonly need to do this include crawlers that need to work out the licence that applies to a particular piece of content, or to whom it should be attributed. Applications should work out which properties apply to a piece of content based on the media type of the data that contains the information about the URI. Media types for structured syntaxes such as JSON, XML or Turtle may delegate how to interpret data to a vocabulary, defined in a schema or in separate documentation.
Applications should be wary, in the absence of explicit indications within specifications or vocabularies, about associating properties with the content located at a given URI used within a URI property for an entity. Some publishers may intend the properties to be associated with the content an application gets when it resolves the URI, while others intend them to be associated with an entity described by the content. Applications should be particularly careful in interpreting properties that could be associated with content retrieved from the web, such as "like" or "creator".
HTTP Responses
The response received when resolving a http: or https: URI does not affect how a given piece of data that refers to that URI is interpreted, but applications may use it to infer additional properties. For example, the HTTP headers that are included in an HTTP response encode properties, such as the last modification date, which are usually associated with the HTTP entity body contained within the response. The Link: header in particular provides additional data which may be about the specific HTTP entity body, a more abstract notion of the document located by the URI (which may change over time or be available in multiple content-negotiated variants), or something described by that document. The documentation of the link relation used within the Link: header should provide specific information about how the relation should be interpreted in relation to the resolved URI.
The most important property of a URI, whose value can only be discovered through resolution, is its content. The actual content located through resolving a URI may change over time or based on aspects of the request (such as Accept: headers). Where data makes assertions about the content of a URI, these assertions are taken to apply to those aspects of the content that remain constant across these variants. Applications can only sample this content at any particular point in time, and some HTTP responses may only provide a portion of the content associated with the URI.
URIs that include fragment identifiers are known as hash URIs. When presented with a hash URI, such as http://photo.example.com/psd/12345#comment-67890 or http://photo.example.com/psd#me, applications can locate its content by resolving the base URI (before the fragment identifier) and interpreting the fragment identifier based on the fragment identifier rules specified for the media type of the the response. In some cases this will resolve to some content (such as an XML or HTML element); in other cases it may not. In cases where the fragment identifier does not resolve to any content in a given response, applications can infer that the content at the base URI describes the entity named with that hash URI.
When resolving a URI results in a 303 See Other response, applications can infer that the content found at the URI given in the Location: header of that response describes the entity named with the original URI. Other redirections (such as 301 Permanent Redirect or 307 Temporary Redirect) imply that applications can get the content of the original URI by looking instead at the content retrieved from the URI given in the Location: header. Error status codes such as 404 Not Found do not imply anything about the content associated with a given URI, except that it cannot be provided by the server.
The ability to have URIs that do not have associated content (hash URIs that do not resolve to a document fragment or URIs that give a 303 See Other response) means that direct properties, which refer to the content retrieved from a given URI, can be used to describe things which are not yet on the web. For example, if the property creator were defined as a direct property that specifies the creator of the content found at a given URI, it could also be used in data that described a book whose content is not currently on the web. In this case, the URI used for the book must be a hash URI that does not resolve to a document fragment, or give a 303 response.
Publishing Data
Publishers can help enable more accurate merging of data from different sites if they support separate URIs for the different entities that other sites may wish to reference. If these additional URIs are provided, the HTTP response given when resolving a landing page or record should include a Link: header indicating the URI of the entity the landing page or record describes using the describes relationship. Similarly, if there are pages that describe the entity associated with a given URI, then:
if the URI is a hash URI, the base URI should be that of the document that describes the entity
if the content of the entity is available on the web, the response should include a Link: header with the describedby relationship, linking to the landing page or record
otherwise, the URI should result in a 303 See Other HTTP status code, redirecting to the landing page or record
Acknowledgements
Many thanks in particular to Jonathan Rees and Henry Thompson for the technical work behind this draft, and to Robin Berjon for ReSpec.js.
Concrete Recommendations
There are many existing data formats, metaformats, vocabularies and schema languages that do not document their use of URIs in the ways described in this document. This section lists them.
RDF
URIs are used to name RDF "resources", and RDF makes statements about these resources. RDF does not state whether the properties apply to the content found by resolving those URIs or to the things described by that content.
microdata
URIs are used to give global identifiers to microdata "items" using the @itemid attribute, and as values for properties when the @href or @src attribute is used. The meaning of the identifier and of the values of properties is specified as determined by the vocabulary that's used with microdata. No change is need here, although the specification could make it clearer that the interpretation of URIs used in these contexts should be specified within the vocabulary.
schema.org
The schema.org vocabulary includes the url property, and when expressed in microdata publishers may use the @itemid attribute or in RDFa the @resource attribute to provide a URI. Most properties appear to be designed to apply to the thing described by the document found at the URI given by the url property, but this is not made explicit in the documentation.
Link: headers
The Link: header expresses a property with a URI value, like those described in . The documentation for each link relation should describe whether the property relates to the HTTP entity body included in the response, to the more abstract notion of the content retrieved from the URI as described in , or to something described by that content. Similarly, the documentation should describe whether the value of the property is the content of the target URI or the thing described by that content.
XML Namespaces
As discussed in , the XML Namespaces Recommendation [[XML-NAMES]] does not specify how URIs used within XML namespace declarations should be interpreted by applications.
Background
This document is one output from the TAG's (re)consideration of
ISSUE-14 (otherwise known as httpRange-14) which asks "What is the range of the HTTP dereference function" or in other words "what kind of things can URIs dereference to"
ISSUE-57 which asks for "Mechanisms for obtaining information about the meaning of a given URI"
That we provide advice to the community that they may mint
"http" URIs for any resource provided that they follow this
simple rule for the sake of removing ambiguity:
a) If an "http" resource responds to a GET request with a
2xx response, then the resource identified by that URI
is an information resource;
b) If an "http" resource responds to a GET request with a
303 (See Other) response, then the resource identified
by that URI could be any resource;
c) If an "http" resource responds to a GET request with a
4xx (error) response, then the nature of the resource
is unknown.
Experience since that decision has highlighted problems with this resolution, such as:
confusion over the meaning of "information resource"
implementation issues with using 303 See Other responses
This issue has traditionally been seen as only a problem for philosophers and the Semantic Web / Linked Data community. However, there is growing adoption of RESTful APIs that provide data describing web-based documents and real-world things and that use URIs to refer to the entities that are described by the data, and who face the same issues.
The TAG has, over the past several years, put significant effort into both exploring the implications of the 2005 TAG decision and the various alternatives that have been espoused.
The TAG put together a number of use cases and assessed the various proposals against those use cases within a matrix. Based on this analysis, the most promising direction was identified to be the "parallel properties" proposal. At the June 2012 F2F, the TAG discussed this approach and agreed that it was the right direction. Further work was then done prior to the October 2012 F2F, where it was discussed again.
At that point, the TAG resolved to:
Go back to community with perspective from background section on what URIs can or can't be known to identify as the response to change proposals
publish URIs in Data primer (this document) as a rec
publish a note base on proposal 27 with intention to transition to RDF WG