![]()
Tim Berners-Lee, Dan Connolly, Lynn Andrea Stein, Ralph Swick
http://www.w3.org/2000/Talks/0815-daml-sweb-tbl
This text corersponds approximately to the intent of the slides.
The essential property of the World Wide Web is its universality. The power of a hypertext link is that "anything must be able to link to anything". This requires that anything must be able to be put on the web. The web technology, then, must not discriminate between cultures, between media, between the scribbled draft and the polished performance, between commercial and academic information, and so on. Information varies along many axes. One of these is the difference between information produced primarily for human consumption, and that produced primarily for machines. At one end of the scale we have the 5 second TV commercial and poetry. At the other end we have the database. To date, the web has developed most rapidly as a medium of documents for people rather than data which can be processes automatically. In this article we look toward the Semantic Web, in which data with well defined meaning is exchanged, and computers and people work side by side in cooperation.
We are looking for a web in which data has processable qualities typical of databases and mathematical formulae, but which is still weblike. Weblike things are, like the Internet, decentralized. They typically involve a lot of fun at every level, and provide benefits on a macroscopic scale which are hard or impossible to predict in advance. To actually build such systems typically requires some compromises, just as the Web initially had to throw away the ideal of total consistency, thus ushering the infamous Error 404 not found message but allowing unchecked exponential uncontrolled growth. The semantic web must be weblike in that, to be universal -- to ask any information which may be useful to be easily available -- it must be minimally constraining. Like good government, it must require only that which is essential for everything to work. If you think of the web today as turning all the documents in the world into one big book, then think of the Semantic Web as turning all the data into one big database, or one big mathematical formula. The semantic web is not a separate web - it is a new form of information adding one more dimension to the diversity of the one web we have today.
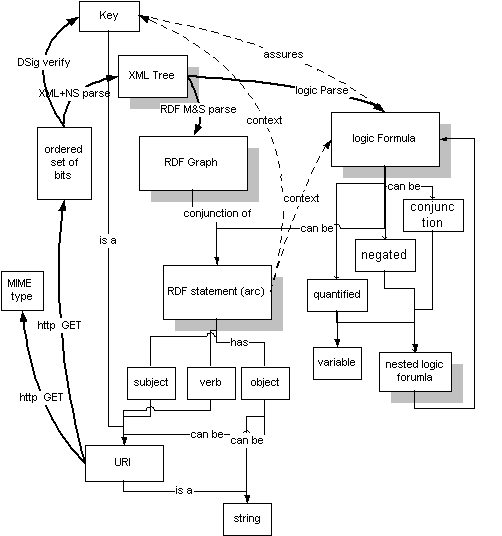
Two important technologies for the semantic web are already in place. The XML language for expressing information gives the community a common way of creating structured documents, thoug it doesn't have a way of saying in any sense what they mean. However, a starting point for talking about meaning comes from developments in the metadata world of information about information such as library cards and catalogs of web resources. This was the initial impetus behind the development of the Resource Description Framework (RDF) which provides a simple model of conveying the meaning of information as sets of triples rather like the subject, verb and object in a sentence.
[Sidebar: In RDF, the subject and object of the triple are identified, as with anything on the web, but Universal Resource Identifiers. Things in general are known in RDF as resources. The verb, or RDF "property", is also a resource, so anyone can define new concepts just by giving them URIs. These triples form "directed graphs" - webs of information about related things. When XML is used to encode this information in a document, XML namespaces technology ensures that concepts used are not just words in a document but are tied to definitive URIs which uniquely identify them. This gets over the original problem with XML that <name> could mean different things to different people and in different context]
In RDF, a document makes assertions that particular things (people, web pages, or whatever) have properties (such as "sister, author", etc) with certian values (another person, webpage, etc., etc.). This turns out to be a natural way of describing the vast majority of the data processed by machines.
[Figure: Example: Encoding a database table in RDF. Each row in a table corresponds to an RDF resource, each column to a property, and each cell gives the value for that property of that resource.]
Of course, the representation of knowledge in general has been the subject of many systems and research ideas in the past. Knowledge Representation as a field is indeed in a state rather similar to the state of Hypertext technology before the web: it is clearly a good idea, and some very nice demonstrations exist, but it has not yet changed the world. In both cases, the idea is good but to be powerful, they must form a single global system.
Historical knowledge representation systems did not scale for a number of reasons. Some had a centralized technology which required all data to be stored in the same place. Others were conceptually centralized in that everyone had to share the same definition of any common concepts like "person" or "vehicle". An essential weblike quality is that a scalable system must allow one group to think up "zip" and another "zipcode" and for them to be retrospectively linked. Some systems used fuzzy reasoning systems which would work in practice on a small scale, but where the effects of the fuzziness would get out of hand when repeated over many steps globally.
Another barrier to interoperability was that knowledge was typically separated into basic data, and rules. For example, family tree information might be the data, and then rule might be that a sister of a mother is an aunt. The data typically transfers easily between systems, but the rules did not. There is a good reason for this. Each system had a specific "inference engine", a program which would try to answer questions sensibly based on the data and rules. As there is no practical way for a machine to answer general questions, the art of computer science for a long time has been to limit the questions,or the domain of discourse, so that in fact the computer could answer at all. Tackling that problem has led to each KR system having, for very good reasons, its own particular sorts of rules, and its own sorts of question it could typically answer. Real compromises had to be made. If the rule language was to simple, it could not express the knowledge of the real case. If it were to powerful, then a computer could not predictably answer questions about it.
The fundamental point at which the semantic web diverges from the KR systems of the past is that it puts to one side -- for later -- the problem of getting computers to answer questions about the data. The trick is to make the rules language as expressive as we need to really allow the web to express what is needed. Pushing the analogy with the early web, there were many detractors who pointed out that the web, with no central database and tree structure, could never be a well-organized library, and that it would never be possible to find everything. They were, of course, right. However, the expressive power of the system allowed vast amounts of information to be put out there, and now search engines -- which would have seemed quite impractical a decade ago -- in fact make remarkably complete indexes of a vast proportion of the material out there.
The challenge of the semantic web, therefore, is to provide a language in which data and rules can be expressed, and which allows rules from any existing KR or database system to be exported onto the web. It is true that the rules from one system won't import again into every other system, but the semantic web philosophy is that that isn't the point: the point is to make the information available losing as little of it as possible.
We can look at how this works in detail with an imaginary rule "if you find a daughter, check whether she has a daughter, and if so you have a granddaughter". You can think of that as being made of two parts. The first is the logical assertion that the daughter of a daughter is a granddaughter (see box). The second is the hint that the inference engine should use this fact whenever it finds a fact about a daughter. The first part is an assertion in classical logic, which can be exported to the semantic web, if we give it the power of logic - first order predicate calculus for example. The second is a hint which allowed a particular KR system to answer particular set of queries well. From the point of view of the semantic web we throw the hint away.
Adding logic to the web is the task before the semantic web community at the moment. It is complicated by the fact that there a mixture of mathematical and engineering decisions which have to be made. The logic must be powerful enough to able to describe for example the properties of properties but not so powerful that can be confused by paradoxes. It is simplified by the fact that a large majority of the information out there is along the lines of "hex-head-bolt is-a-sort-of machine-bolt" which do not stretch the expressive power of the logic, and can be done in RDF with a little extra vocabulary.
[Sidebar Figure: When two databases use the same concept, as often happens, this information is lost until a semantic link is made. In this case, two tables are both about people use an equivalent zipcode property. Linking the data allows a query on one to be resolved by following links to other tables.]
An example is equivalence statement which can do so much to simplify processing as knowledge evolves. So often, a vocabulary or a form or a standard is derived from one or more older versions with much directly in common. being able to express this relationship is essential to the smooth evolution or our knowledge, guided by the tension between small, fast, grass-roots changes and slower but wider commonality in concepts.
[Sidebar figure:
Information in the semantic web is found by following links. A document is parsed, yielding a logical formula, which may refer to a document by URI. This may confer trust on such a document, which may cause it to be in turn fetched from the web. Any piece of information has a context, so nothing has to be taken at face value.]
We do not have to put off all the benefits of the semantic web to the time of future software agents which can navigate the wealth of its rich representations. There is an important way in which applications can be linked now, even though they may use different inference engines. Suppose one system, say some sort of search engine, uses its own algorithm to find a solution to a given query. The logical essence of every rule used in the process can be expressed in the unifying classical logic. The inference engine can therefore at each stage generate an explanation in classical logic of how that step follows from its input data including rules. The sequence of these explanations forms a proof which can be exchanged across the internet.
Another agent, which may not have the same -- or any -- system of inference, when presented with the conclusion can ask the question,"Oh, yeah?". In response, the first agent sends the proof. The second agent now has a choice of believing the outcome or disbelieving the assumptions on which it was based.
For example, W3C might say that anyone authorized by the representative of a member organization may access our internal web site. Each member organization may use a different system for defining who is authorized, and how authority is further delegated. The actual rules used by IBM for example may be so complex and even private that the W3C web server cannot determine for an arbitrary person whether IBM counts them as an employee. However, the IBM system does know an algorithm, and provides them with a proof which their browser can present to the W3C web server. This is a proof based on assumptions which have been digitally signed by the IBM representative, and therefore trusted for this purpose by the W3C web server.
In fact, the combination of logical proof and digital signature will be very powerful. In fact, to be able to check a standard proof and to validate a digital signature may be prerequisites of citizenship of the world of electronic commerce agents.
[diagram: inference engine generates the proof, other agents checks it.]
Once a language is powerful enough to describe features of the real world, then in general the art of finding a proof of something is not a tractable problem for a computer. Dropping this need as an initial requirement is a fundamental step in the semantic web. The authors belive that once this language enables a vast amount of interconnected information to be made available, then in practice great use will be made of it, by a mixture of simple agents operating in a predicatable way in limited domains, and heuristic agents (like search engines) providing very valuable, though formally unpredictable, results in other domains.
A final aspect of the semantic web which is essential to design in is its ability to smooth the evolution of human knowledge. Human endeavor is always caught in the eternal tension between operating rapidly as a small group and taking the time to communicate in wider way. The first way is more efficient but produces a subculture whose concepts results are not understood by others. the second is painfully slow as establishing a wider culture takes enormous amounts of communication. The world works with a spectrum between these extremes, with a tendency to start small - from the personal idea - and filter over time toward wider commonality of concept. An essential process is the joining together of subcultures when there is a need for a wider common language. The standards process is one form of this. In many cases two groups have independently found the same or very similar concepts and there is great benefit in being able to describe the relation between them. Like the formal version of a french-english dictionary, or a weights and measures conversion table, the relationships allow communication when the commonality of concept has not [yet] led to a commonality of terms. The semantic web, in naming every concept simply by a URI, allows anyone to invent new ones at will. Its unifying logical language will allow these concepts to be progressively linked into a universal web. This will lay open to analysis by software agents the logical aspects of the knowledge and workings of humankind. It will be the be the basis for another form of tools for us to live and work and learn together.