 W3C
W3C  XML
XMLNote [August 2005]: this document is an essay, not a specification. XML's syntax wasn't finalized when it was written and now differs slightly from this essay.
The data model for XML is very simple - or very abstract, depending on one's point of view. XML provides no more than a baseline on which more complex models can be built. All those more restricted applications will share some common invariants, however, and it is those that are given below.
Think of an XML document as a linearization of a tree structure. At every node in the tree there are several character strings. The tree structure and the character strings together form the information content of an XML document. Almost everything will follow naturally from that. Some of the characters in the document are only there to support the linearization, others are part of the information content.
For a different, and much more formal approach, see `ADT and marshalling for XML.'
Note [August 2005] also that this document discusses one possible data model for XML. A more recent document, The XQuery 1.0 and XPath 2.0 Data Mode, describes another data model for XML.
The main structure of an XML document is tree-like, and most of the lexical structure is devoted to defining that tree, but there is also a way to make connections between arbitrary nodes in a tree. For example, in the following document there is a root node with three children, but one of the children has a link to one of the other children:
<p> <q id="x7">The first q</q> <q id="x8">The second q</q> <q href="#x7">The third q</q> </p>
The tree corresponding to this document can be visualized as follows:
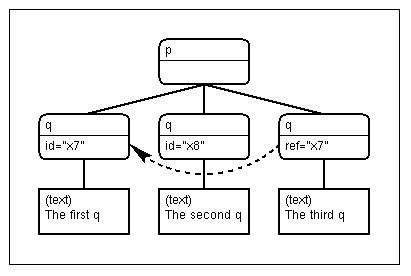
The last q has an `href' attribute and it points to an element with an `id.' In this case the first q has an id with the same value as the href (minus the `#'), so the third q points to the first. (Note that this is a generalization of a similar mechanism in HTML.) The linking model is explained in the XML-link draft.
The tree that an XML document represents has a number of different types of nodes:
An element node is created by expressions like the following:
<p a1="A1" . . . an="An">c1 . . . cm</p> for n>=0, m>=0
or these:
<p a1="A1" . . . an="An"/> for n>=0
Such an element node has a type p, an ordered list of children ci, and a set of attributes, which are pairs of attribute names ai and attribute values Ai.
In contrast to the children, the order of the attributes doesn't matter. Thus, the same node can be linearized with different expressions. Furthermore, all the ai are different, but the Ai don't have to be.
Note that if m=0, the two expressions above are equivalent, and indeed one can use either one at will.
The type, attribute names and attribute values consist of strings of characters. There are restrictions on the lexical structure of the type and attribute names: they must consist of (Unicode) letters, (Unicode) digits, dashes and dots, they must be at least one character long and they must start with a letter or a dash. There are no restrictions on attribute values, in particular they may be empty (but see under `Escape mechanism' below).
The attribute name "id" (upper or lower case) is reserved for something called the ID of the element. See the XML-link draft. Furthermore, attribute names may not start with the four letters "xml-" (upper or lower case), as these are also reserved for xml-link.
A document node is a specialized kind of element node. It has a type p but no attributes. Instead it has an optional URL u. The intent of the URL is to specify a specialized data model for this node and its children. A document node looks like this:
<!doctype p "u">c1 . . . cm for m>0
Exactly one of the ci must be an element node and furthermore it must have type p, the same as the document type. The other children, if any, must be either comment nodes or processing instruction nodes; data nodes are not possible.
Also, if this document node is not the root node of the document, then i=m. In other words, if this document node is not the root, its one child that is an element node must be its last child.
The type and URL are again character strings. The type has the same lexical constraints as the type of an element and the URL has no constraints.
There is one exception to the rule that a document node must have a type. The root node of the XML tree may be an anonymous document node, without a type and without a URL. Such a document node is represented in the document by the absence of a `<!doctype>' expression. In other words, if the first expression in the document is not `<!doctype...>', the document has an anonymous root.
[Actually, I am leaning towards the idea that we don't need PIs at all, apart maybe from the <?xml default...?> and <xml encoding...?> ones.]
A processing instruction (PI) node is always a leaf node. It only has an instruction i associated with it. The instruction is a sequence of zero or more characters, without any restrictions, except that the sequence may not start with the three characters `xml' (upper, lower or mixed case) followed by a space or newline. It looks like this in the XML document:
<?i?>
Processing instructions that start with `xml' + whitespace have special meaning to XML. They look like this:
<?xml i?>
Their meaning is explained below.
A comment node is similar to a processing instruction. It is also a leaf node and has only a comment c:
<!--c-->
The intention is that comment nodes are used to include explanatory notes for human consumption, while processing instructions are for consumption by some application [the XML parser itself, I guess?]. In the XML data model, however, there is no difference between them (apart from the processing instructions that start with `<?xml').
[XML-link cannot address comment nodes, so do we (1) add them to XML-link, or (2) remove them from this data model?]
Data nodes are also always leaf nodes. They have a single characteristic: the data d. Since all the other nodes have delimiters to distinguish them, data nodes don't need them: everything that is not between `< and `>' is data. (With one exception, explained below: at certain places newlines may be inserted for the benefit of people editing XML by hand, and those newlines are not part of any node.)
Data nodes cannot be empty, that is, their data characteristic contains at least one character.
The expressions for nodes other than data nodes all start and end with `<' and `>'. Element nodes that have children even have two pairs of them. The term mark-up refers to those expressions: everything from a `<' to the matching `>' is called mark-up. Everything else is data, with one exception:
The data that is encoded in an XML document may or may not have embedded newlines. If it doesn't, and you still want to edit it by hand, the document may be difficult to handle with a simple text editor. XML therefore allows the insertion of newlines at certain places, which are not part of either the mark-up or the data.
There are two such places: immediately before mark-up (before a `<') and immediately after mark-up (after a `>') The example shows ignored newlines as $ and newlines that are part of the data as #:
<tag1>$ Some text# more text# and more text$ <tag2>blah</tag2>$ </tag1>$
Inside the mark-up, all whitespace (outside attribute values) is ignored. So breaking lines there is also possible:
<tag1$ >Some text# more text# and more text<tag2$ >blah</tag2$ ></tag1>$
The above means that if a data node starts or ends with a newline character, this newline either has to be escaped (see below), or has to be doubled.
Above it was said that there are no restrictions on what characters can occur in attribute values, data nodes, etc., but in the linearization some characters have to be escaped to avoid ambiguities. Consider an attribute value that contained double quotes, it cannot be written like this:
... a="value with a " in the middle"...
Instead, the dangerous character must be escaped:
... a="value with a " in the middle"...
This expression, ", contains the Unicode code of the double quote character.
Indeed all characters that are not needed to delimit the nodes can be written like this, but for a few it is obligatory. Those are: `"' (", only obligatory inside attribute values), `&' (&), `<' (<) and `>' (>).
It is also possible to use hexadecimal numbers instead of decimal. The expressions then become &u-0022;, &u-0026;, &u-0050;, resp. &u-0052;.
What has been called a newline above actually can take three different forms. For XML, all of the following are considered newlines (and are thus ignored immediately before or after mark-up):
[Uses <?xml default name... ?>]
[Just an abbreviation, applications cannot attach meaning to this PI]
[Scoping rules: scoped by enclosing element or document node]
[Especially handy for XML-link]
[UCS2 or any superset of ASCII, UTF8 is default]
[Uses <?xml encoding...?>]